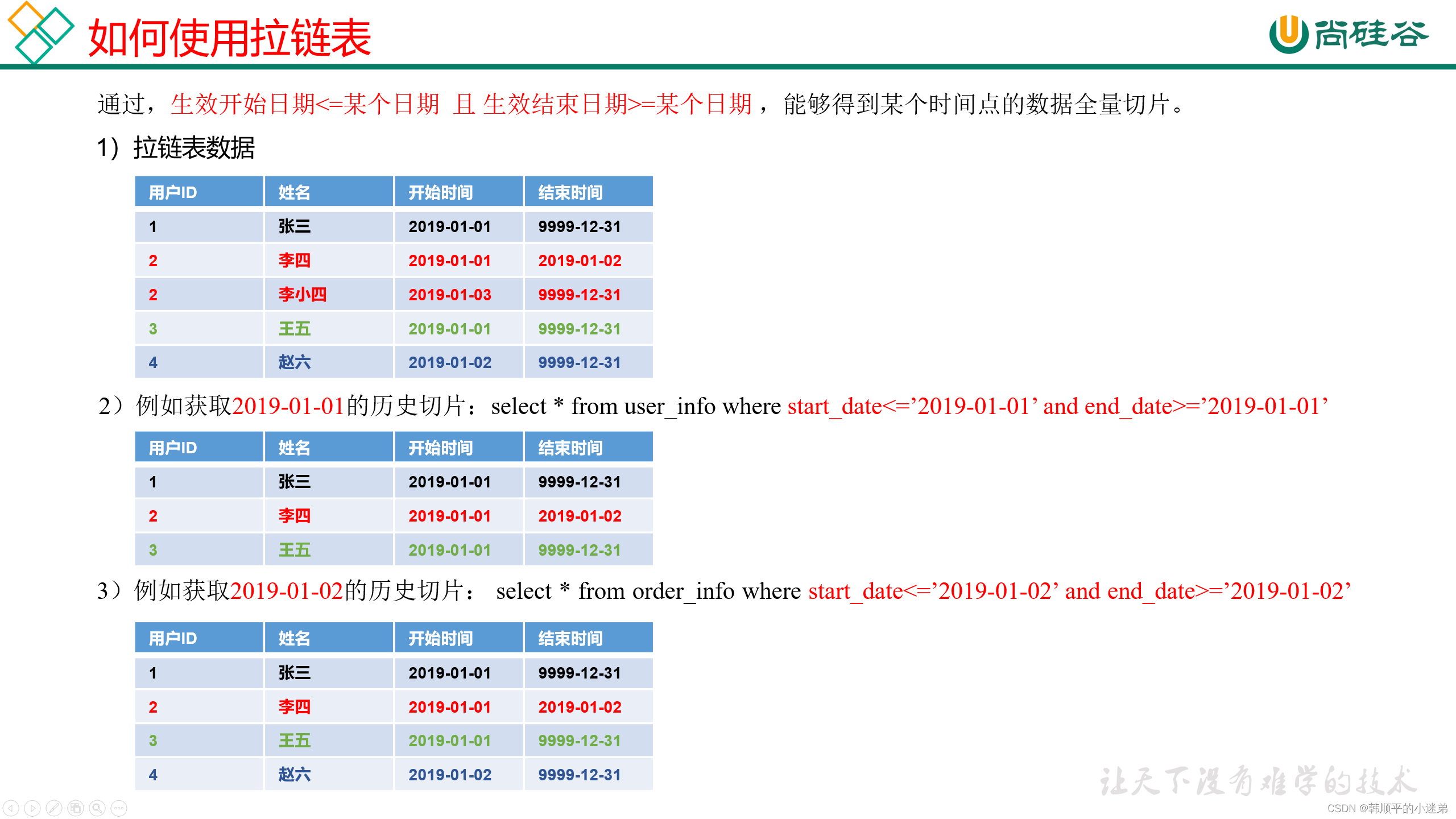
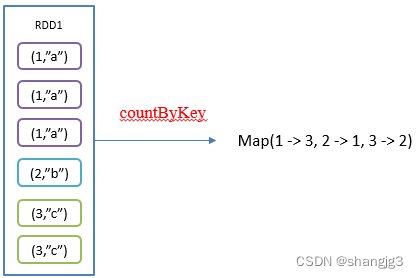
神经网络
微信小程序
计算机视觉
固态硬盘
picgo
进程
.net
ssl
编程
医学统计学
aws
池化
下载视频方法
医院运营
Pascal
PMP项目管理
ERP
翻译
权限控制
hackthebox
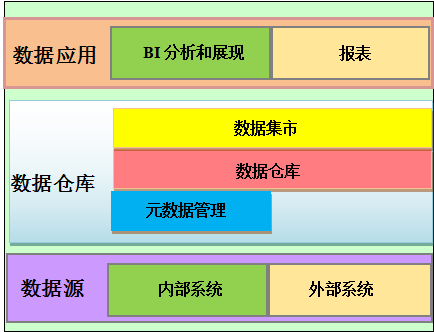
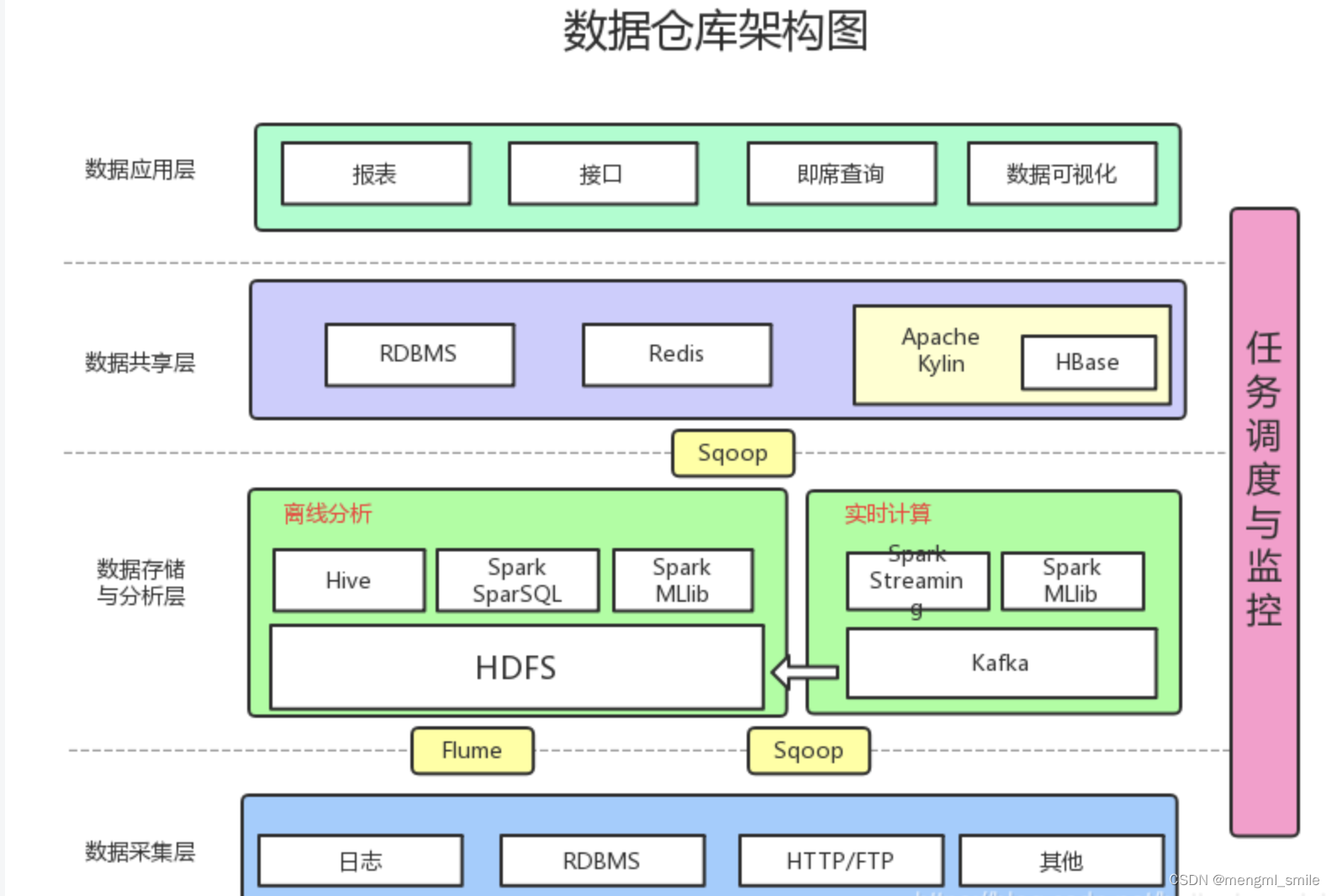
数据仓库
2024/4/11 14:45:08
CRM助力医药行业通路建设
CRM助力医药行业通路建设 为什么CRM 医药市场是一个非常大的市场,医药企业只有规范化、规模化发展才有出路。但是规模越大,管理成本就越高,对于地点分散的医药销售公司与连锁医药商店等更加明显。因此,企业之间的竞争将主要集…
Hive学习 第四课 创建表并load 数据到表
本章将介绍如何创建一个表以及如何将数据插入。创造表的约定在Hive中非常类似于使用SQL创建表。
CREATE TABLE语句
Create Table是用于在Hive中创建表的语句。语法和示例如下:
语法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name…
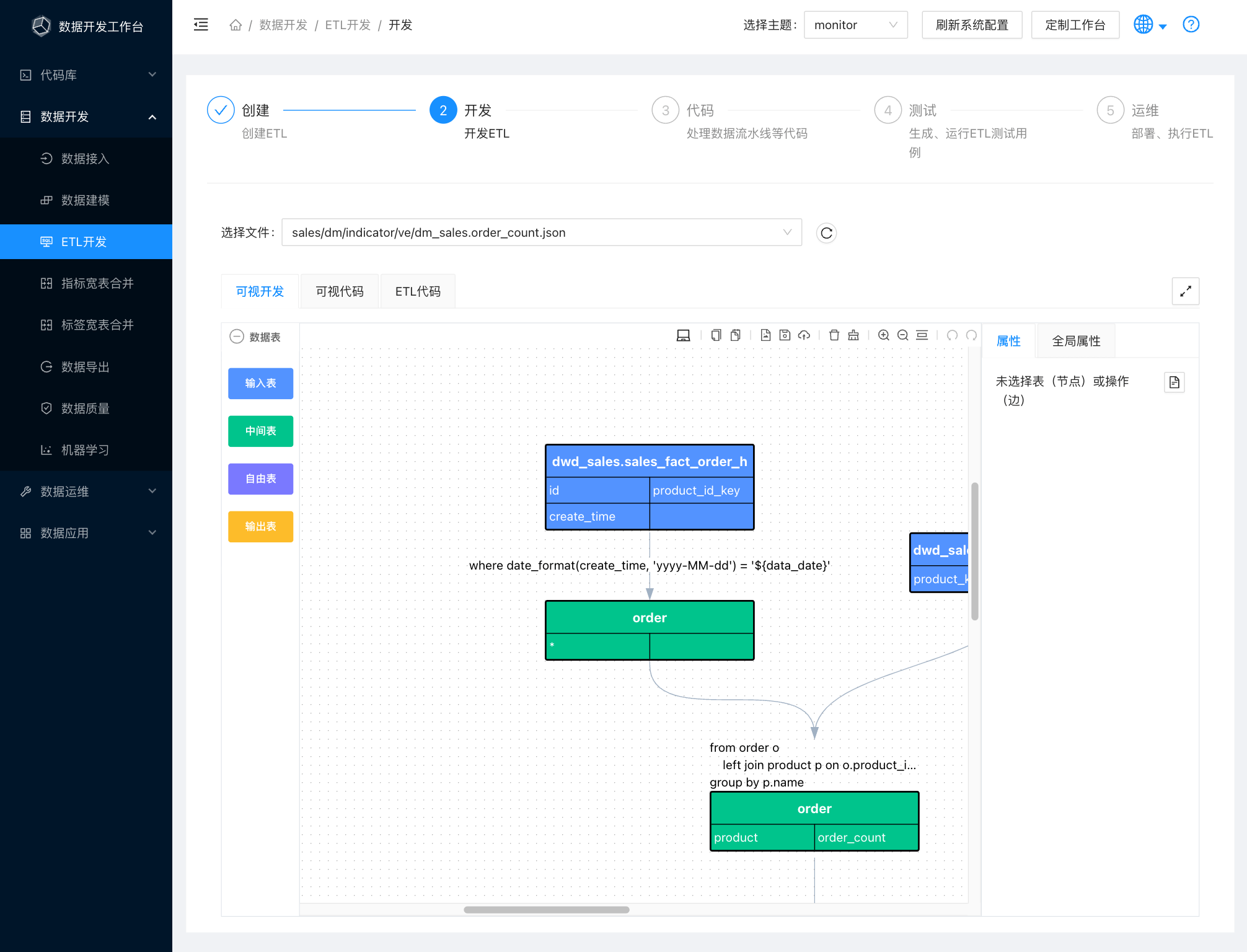

即刻报名,企业服务与新经济论坛亮点提前揭秘!
峰会官网已上线,最新议程请关注:doris-summit.org.cn
即刻报名 Doris Summit 是 Apache Doris 社区一年一度的技术盛会,由飞轮科技联合 Apache Doris 社区的众多开发者、企业用户和合作伙伴共同发起,专注于传播推广开源 OLAP 与实…
元数据、数据元、元模型、数据字典及数据模型的区别
整理不易,转发请注明出处,请勿直接剽窃! 点赞、关注、不迷路! 摘要: 元数据、数据元、数据模型、元模型、数据字典 定义
元数据:描述数据的数据 数据元:数据的最小单元(字段元数据值…
数据仓库_模型设计_学习目录
前言: 1、问什么要写这篇博客? 随着自己在数仓岗位工作的年限增加,对数仓的理解和认知也在发生着变化 所有用这篇博客来记录工作中用到的知识点与经验 2、这篇博客主要记录了那些内容? 主要会记录一些数仓建设方法论和工作技巧 目…
海豚调度(dolphinsheduler)离线安装
1. 简介 1.1 DolphinScheduler 是什么 Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。 Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系…
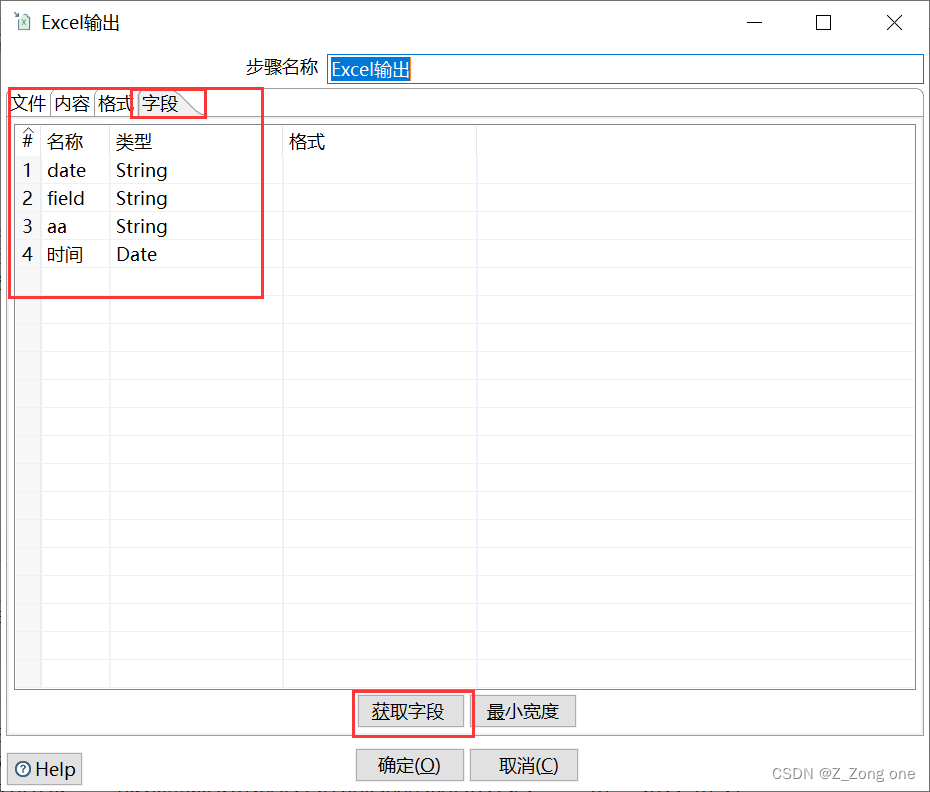
kettle 生成随机数
简单的kettle组件生成随机数操作 组件: 生成记录 组件:生成随机数 组件:Excel输出 最后获取一下字段就OK了
[Hive] CTE 通用表达式 WITH关键字
在Hive中,CTE代表的是Common Table Expression(通用表达式),这是一种SQL语句结构,使用WITH关键字定义的子句。
CTE
CTE提供了一种在查询中定义临时结果集的方式,以便后续查询可以引用这些临时结果集&…

大数据项目实战---电商埋点日志分析(第六部分,ADS层之用户活跃主题)
大数据项目实战---电商埋点日志分析(第六部分,ADS层之用户活跃主题)
创建用户活跃汇总表ads_uv_account并加载数据。 下一章 https://blog.csdn.net/hailunw/article/details/118609254
大数据项目实战---电商埋点日志分析(第八部分,用户留存主题(DWS层+ADS层)
1)创建每日留存用户明细表dws_user_retention_day并加载数据。 2)创建每日留存用户数表ads_user_retention_day_count并加载数据。 3)创建每日留存用户比例表ads_user_retention_day_rate并加载数据 为了能够尽快地找到新工作,这个项目先到这…
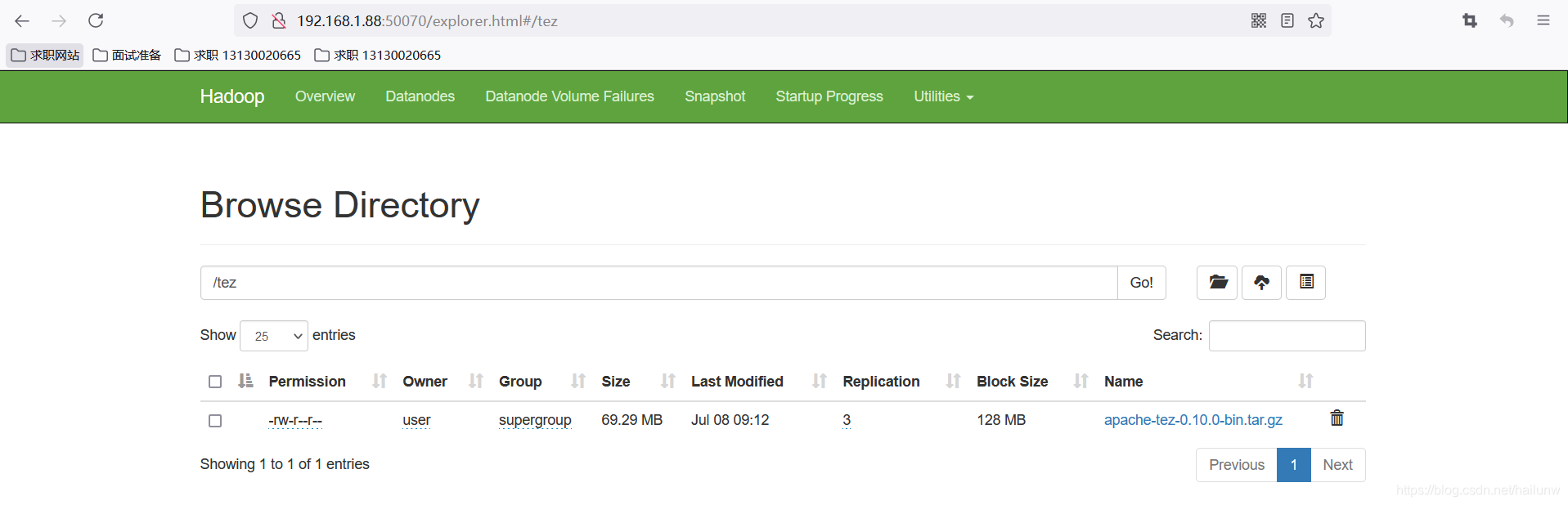
Tez的简介以及安装配置
Tez简介
Tez是一个Hive的运行引擎,由于没有中间存盘的过程,性能优于MR。Tez可以将多个依赖作业转换成一个作业,这样只需要写一次HDFS,中间节点少,提高作业的计算性能。 Tez的安装步骤
1)下载安装包到hive所在的66服务…

国产数据库人大金仓sql与mysql对比
反引号与双引号
kingbase不支持mysql中的 反引号 与其相对应的是 双引号 mysql中的语法:name kingbase中的语法:“name” 正则表达式
kingbase 正则表达式 与mysql中 的语法不通 : mysql 中的语法:name regexp ‘^b.’ kingbase…

Hive安装配置 - 内嵌模式
文章目录 一、Hive运行模式二、安装配置内嵌模式Hive(一)下载hive安装包(二)上传hive安装包(三)解压缩hive安装包(四)配置hive环境变量(五)关联Hadoop&#x…
educoder中Hive综合应用案例 — 学生成绩查询
第1关:计算每个班的语文总成绩和数学总成绩
---------- 禁止修改 ----------drop database if exists mydb cascade;set hive.auto.convert.join = false;
set hive.ignore.mapjoin.hint=false;
---------- 禁止修改 ----------
---------- begin ----------
---创建mydb数据…
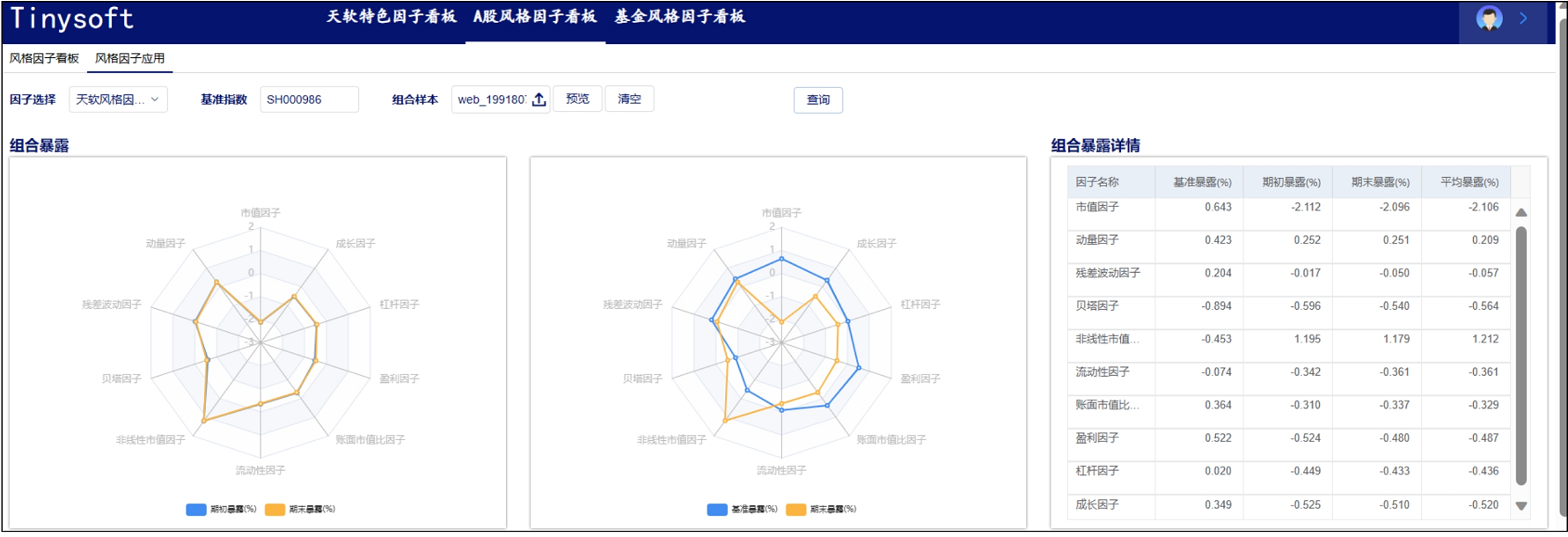
A股风格因子看板 (2023.10 第11期)
该因子看板跟踪A股风格因子,该因子主要解释沪深两市的市场收益、刻画市场风格趋势的系列风格因子,用以分析市场风格切换、组合风格暴露等。 今日为该因子跟踪第11期,指数组合数据截止日2023-09-30,要点如下 近1年A股风格因子检验统…
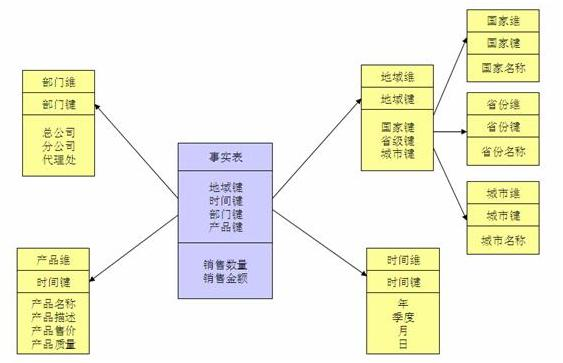
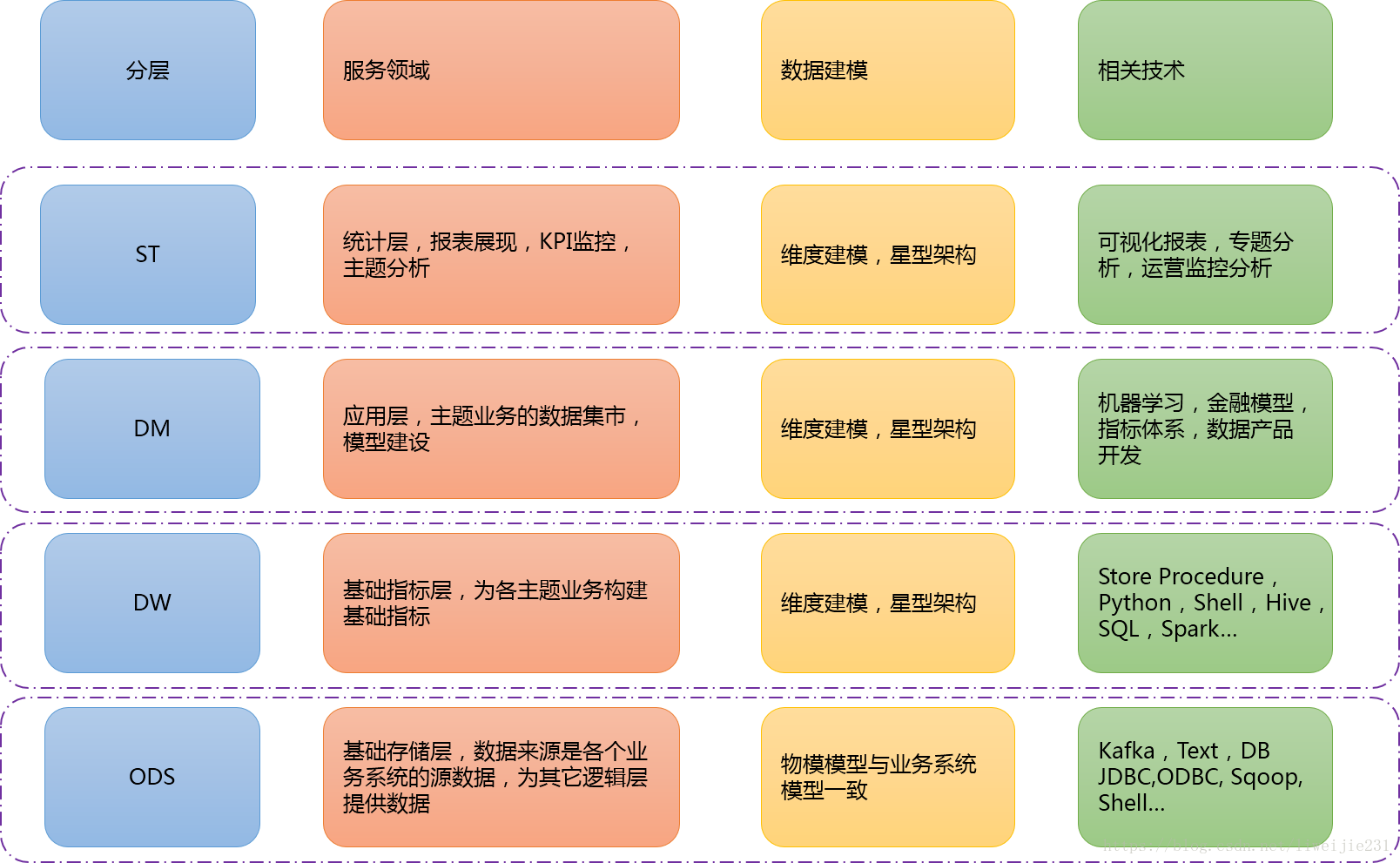
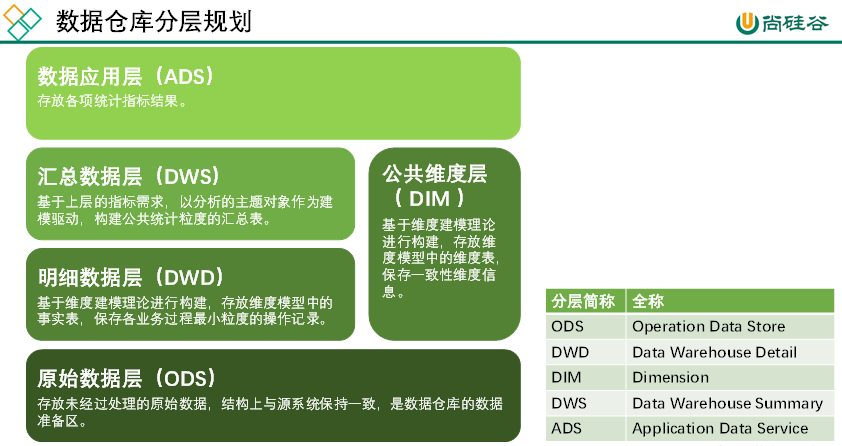
大数据数仓建模基础理论【维度表、事实表、数仓分层及示例】
文章目录 什么是数仓仓库建模?ER 模型三范式 维度建模事实表事实表类型 维度表维度表类型 数仓分层ODS 源数据层ODS 层表示例 DWD 明细数据层DWD 层表示例 DIM 公共维度层DIM 层表示例 DWS 数据汇总层DWS 层表数据 ADS 数据应用层ADS 层接口示例 数仓分层的优势 什么…

漆包线工厂生产管理MES系统解决方案
漆包线行业老板痛点:
1.漆包线比较传统的行业,一般都是靠人工去管理,老板想及时知道工厂的生产,销售、出入库、库存情况;
2.型号多称重打印易错,没有系统前 :称重打印,出入库&…
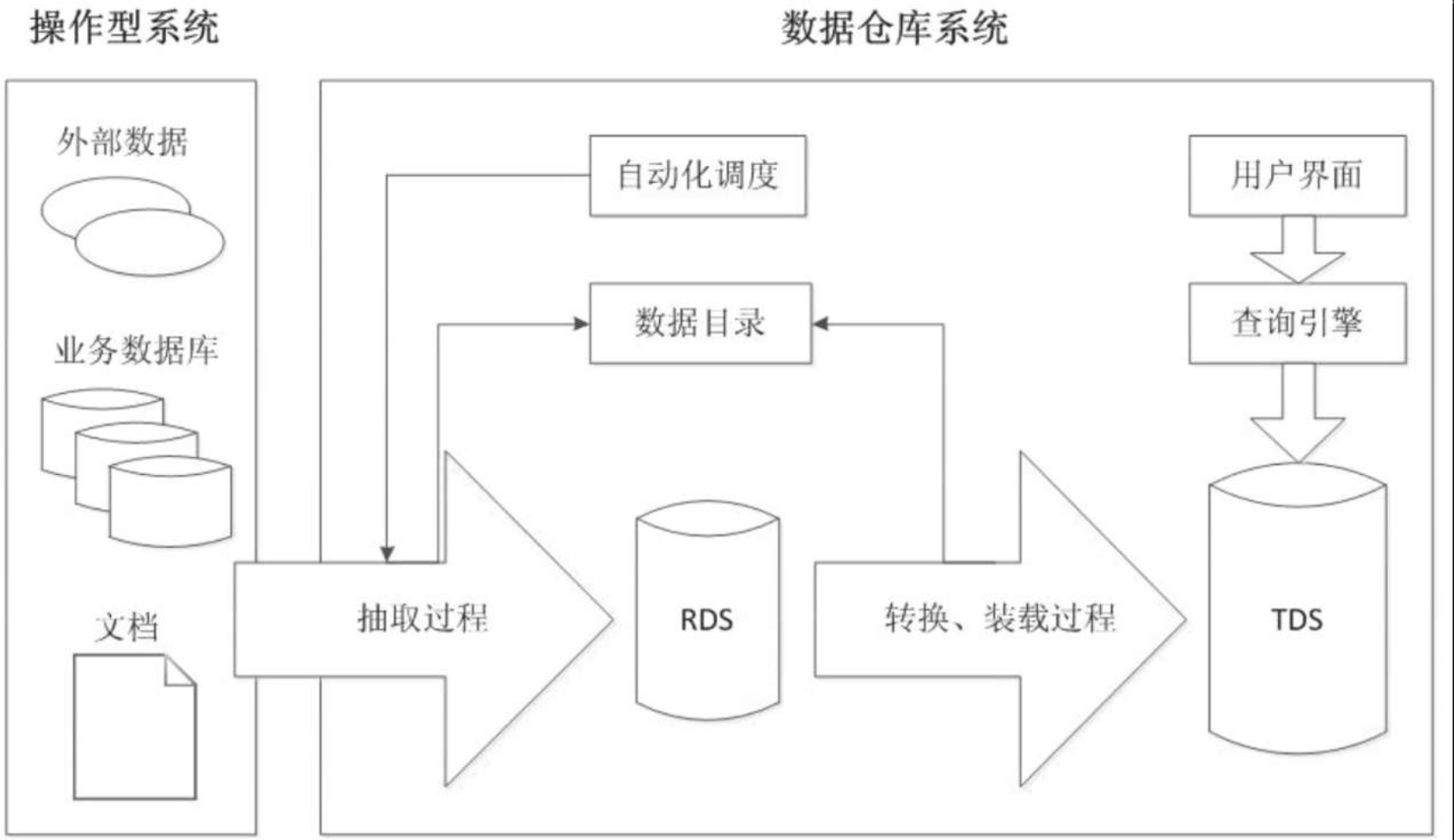
【数据仓库】hadoop生态圈与数据仓库
文章目录 1.大数据定义2. Hadoop与数据仓库3. 关系数据库的可扩展性瓶颈4. CAP理论5. Hadoop数据仓库工具5.1. RDS和TDS5.2. 抽取过程5.3. 转换与装载过程5.4. 过程管理和自动化调度5.5.数据目录(或者称为元数据管理)5.6.查询引擎…
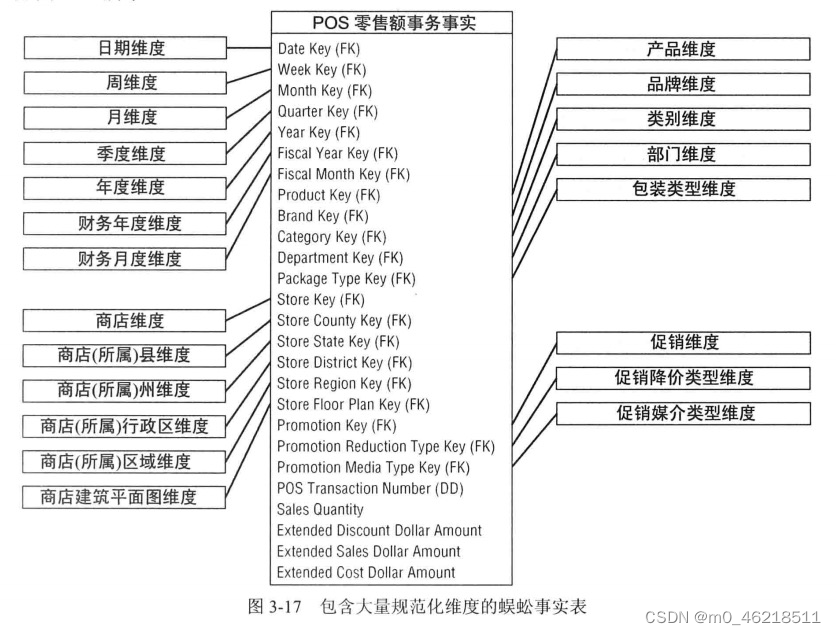
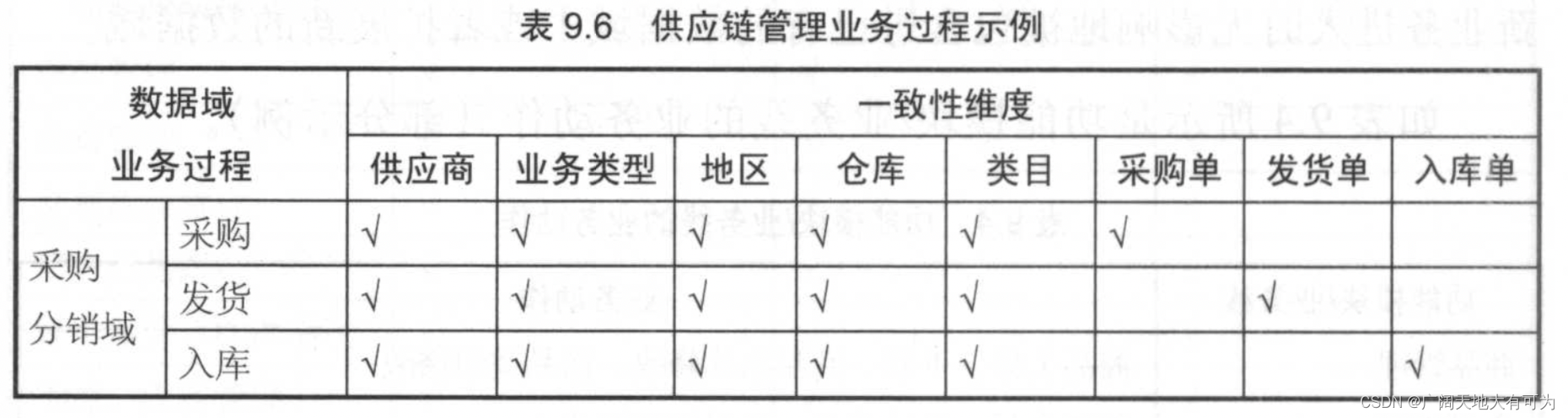
数据仓库工具箱-零售业务
文章目录 一、维度模型设计的4步过程1.1 第一步:选择业务过程1.2 第二步:声明粒度1.3 第三步:确定维度1.4 第四步:确定事实 二、零售业务案例研究2.1 第一步:选择业务过程2.2 第二步:声明粒度2.3 第三步&am…
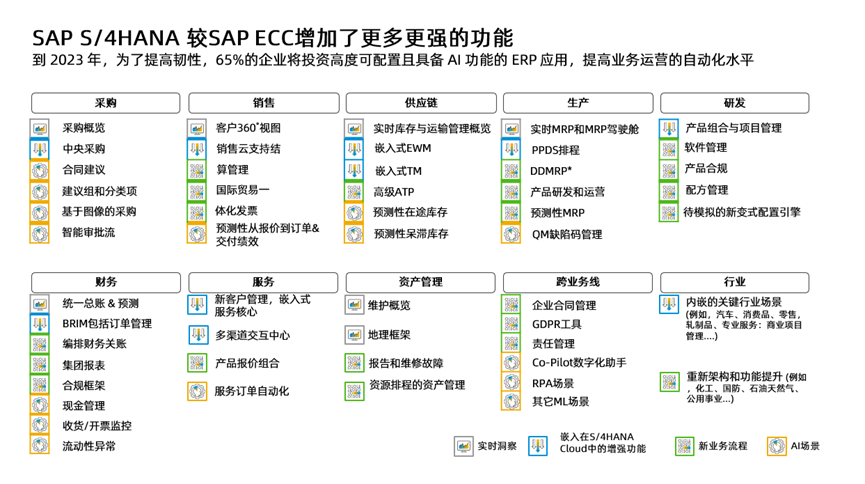
SAP业务从ECC升级到SAP S/4HANA有哪些变化?有哪些功能得到增强?
SAP在2015年推出了新一代商务套件SAP S/4 HANA。 SAP S/4 HANA (全称SAP Business suite 4 SAP HANA),这款新产品完全构建于目前先进的内存平台SAP HANA 之上,同时采用现代设计理念,通过SAP Fiori 提供精彩的用户体验 (UX)。提供比ECC更强大的功能。S/4h…
HashData携手XSKY 助力企业构建数据智能底座
近日,酷克数据联合XSKY星辰天合共同推出了云原生数据平台解决方案(以下简称“解决方案”)。基于双方核心产品技术特性和优势,该解决方案采用湖仓一体、存算分离架构,融合数据仓库、数据湖、对象存储的优势,…
Excel 时间戳和时间格式的互相转换
日常工作中经常需要处理数据表格,但数据来源比较复杂,有时需要从数据库导出部分数据,会出现时间格式不统一的问题,有的是时间戳、有的是日期文本,为保持统一格式,便于统计计算,需要对格式进行转…
hudi系列-基于cdc应用与优化
1. CDC是个好东西
曾经做数据同步受存储引擎和采集工具的限制,经常都是全量定时同步,亦或是以自增ID或时间作为增量的依据进行增量定时同步,无论是哪种,都存在数据延时较大、会重复同步不变的数据、浪费资源等问题。后来刚接触canal时还大感惊奇,基于mysql的binlog可以这…
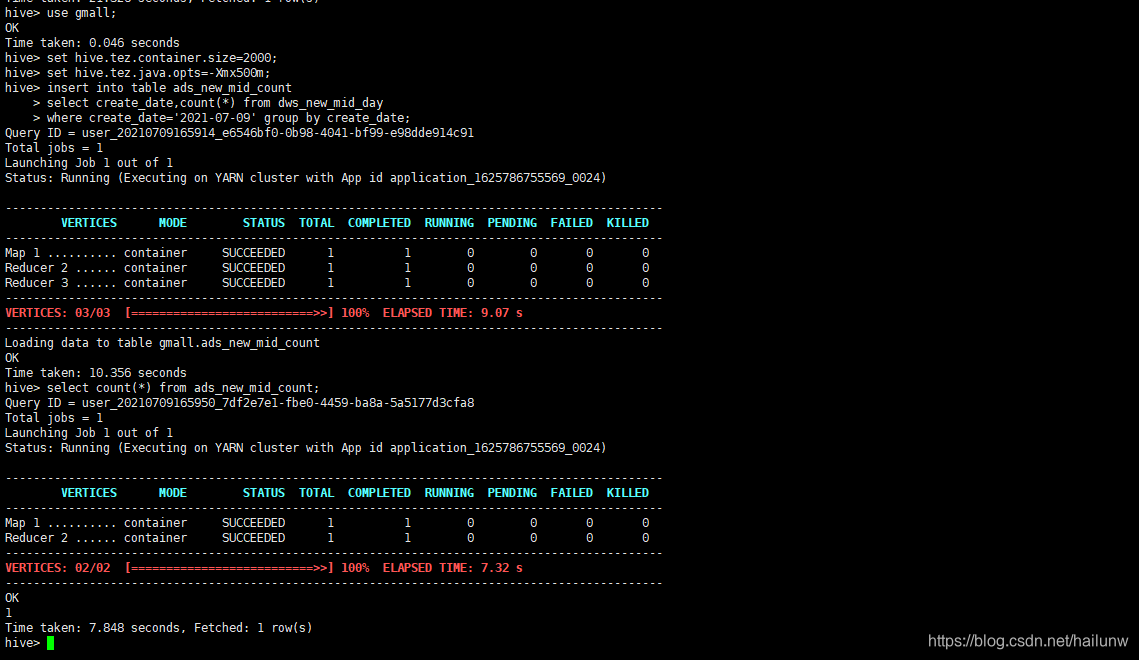
大数据项目实战---电商埋点日志分析(第七部分,每日新增设备主题(DWS层+ADS层)
1)创建设备按天明细表,dws_new_mid_day并加载数据。 2)创建每日新增设备表,ads_new_mid_count并加载数据。 下一章 https://blog.csdn.net/hailunw/article/details/118611510
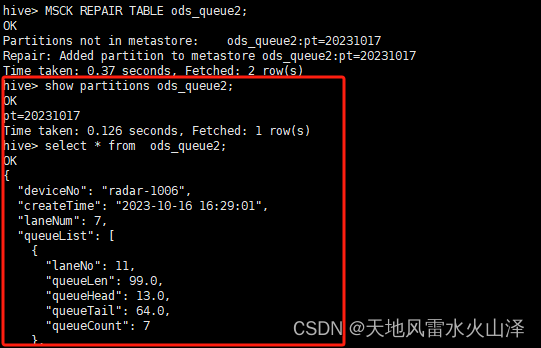
一百九十、Hive——Hive刷新分区MSCK REPAIR TABLE
一、目的
在用Flume采集Kafka中的数据直接写入Hive的ODS层静态分区表后,需要刷新表,才能导入分区和数据。原因很简单,就是Hive表缺乏分区的元数据
二、实施步骤
(一)问题——在Flume采集Kafka中的数据写入HDFS后&am…

大数据项目实战---电商埋点日志分析(第三部分,DWD层初步解析)
构建DWD层
1)创建表dwd_start_log 2)创建表dwd_event_log 往DWD层加载数据
1)往表dwd_start_log中加载数据。 2)往表dwd_event_log中加载数据。
2.1)创建UDF和UDTF ,将生成的jar 传到hive所在的服务器88。 https://blog.csdn.n…

数仓分层能减少重复计算,为啥能减少?如何减少?这篇文章包懂!
很多时候,看一些数据领域的文章,说到为什么做数据仓库、数据仓库要分层,我们经常会看到一些结论:因为有ABCD…等等理由,比如降低开发成本、减少重复计算等等好处
然后,多数人就记住了ABCD。但是࿰…
数据仓库工具箱-第三章-零售业务
文章目录 一、维度模型设计的4步过程1.1 第一步:选择业务过程1.2 第二步:声明粒度1.3 第三步:确定维度1.4 第四步:确定事实 二、零售业务案例研究2.1 第一步:选择业务过程2.2 第二步:声明粒度2.3 第三步&am…

Flume的简单案例二 读取本地文件
1)创建Flume Agent配置文件 flume-file-logger.conf 2)在配置文件中添加以下内容 参照https://flume.apache.org/FlumeUserGuide
# example.conf: A single-node Flume configuration# Name the components on this agent
a2.sources r2
a2.sinks k2
…
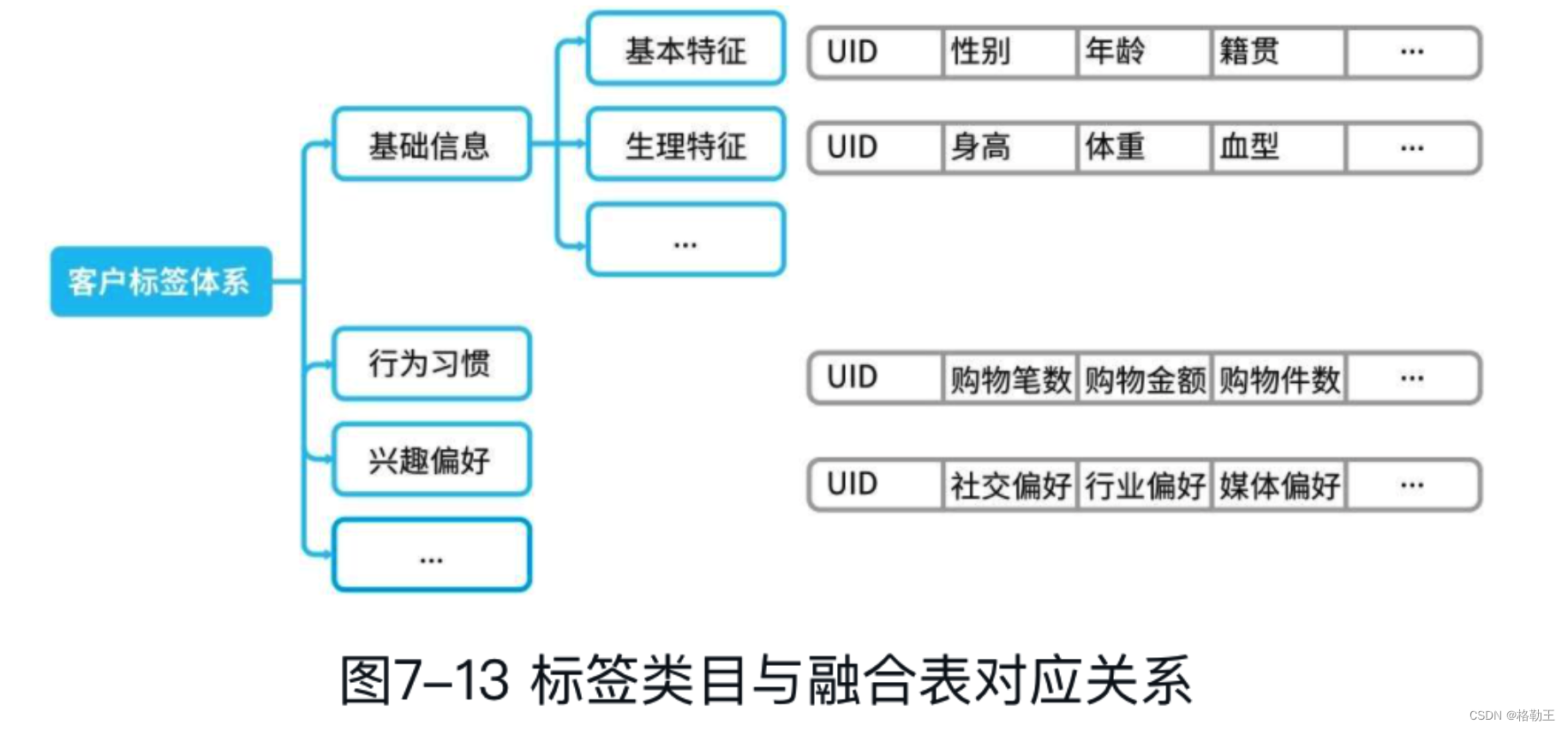
数据体系建设-ODS|DW|TDM|ADS介绍
参考书目《数据中台:让数据用起来》 ODS:各业务生成的基础数据存表,如log日志数据等DW:在ods基础上,分主题整合数据TDM:存储标签数据ADS:基于上面的数据源整合而成的供业务应用的指标报表等
贴…
一、数据仓库详细介绍
随着信息化的不断深入,越来越多的人开始意识到数据的重要性。数据支持决策,数据支持运营,数据变现,数据营销等等数据应用,开始越来越多的在各大中小型公司普及。 联机事物处理(On-Line Transaction Process…
恒驰服务 | 华为云数据使能专家服务offering之数仓建设
恒驰大数据服务主要针对客户在进行智能数据迁移的过程中,存在业务停机、数据丢失、迁移周期紧张、运维成本高等问题,通过为客户提供迁移调研、方案设计、迁移实施、迁移验收等服务内容,支撑客户实现快速稳定上云,有效降低时间成本…
【大数据 - Doris 实践】数据表的基本使用(四):动态分区
数据表的基本使用(四):动态分区 1.原理2.使用方式3.动态分区规则参数3.1 主要参数3.2 创建历史分区的参数3.3 创建历史分区规则3.4 创建历史分区举例3.5 注意事项 4.示例4.1 创建动态分区表4.2 查看动态分区表调度情况4.3 查看表的分区4.4 插…
【踩坑】hive脚本笛卡尔积严重降低查询效率问题
前一阵子查看我们公司的大数据平台的离线脚本运行情况, 结果发现有一个任务居然跑了一天多, 要知道这还只是几千万量级的表, 且这个任务是每天需要执行的
于是我把hive脚本捞出来看了下, 发现无非多join了几个复杂的子查询, 应该不至于这么久, 包括我又检查了是不是没有加上每…

A股风格因子看板 (2023.10 第02期)
该因子看板跟踪A股风格因子,该因子主要解释沪深两市的市场收益、刻画市场风格趋势的系列风格因子,用以分析市场风格切换、组合风格暴露等。 今日为该因子跟踪第02期,指数组合数据截止日2023-09-30,要点如下 1) 近1年A股风格因子检…
BI与数据治理以及数据仓库有什么区别
你可能已经听说过BI、数据治理和数据仓库这些术语,它们在现代企业中起着重要的作用。虽然它们都与数据相关,但它们之间有着明显的区别和各自独特的功能。数聚将详细探讨BI(商业智能)、数据治理和数据仓库之间的区别,帮…

Hive 的函数介绍
目录
编辑
一、内置运算符
1.1 关系运算符
1.2算术运算符
1.3逻辑运算符
1.4复杂类型函数
1.5对复杂类型函数操作
二、内置函数
2.1数学函数
2.2收集函数
2.3类型转换函数
2.4日期函数
2.5条件函数
2.6字符函数
三、内置的聚合函数
四、内置表生成函数
五、…

HiveQL中case when..........then.......else的用法总结
核心内容: 1、两个实例 2、case语句中的the关键字可以理解为select关键字 3、两个group by的实例 4、线性维表的实现方式 优惠前金额:before_prefr_unit_price 实例1、从表gdm_m04_ord_det_sum提取如下数据: 求出在2014年11月11日这天的全…

万界星空科技SMT行业生产管理MES系统解决方案
一、SMT行业特点:
SMT(Surface Mounted Technology)作为电子组装行业里首先的技术和工艺,选择合适的MES解决方案来保障SMT生产的成功至关重要。 电子行业涉及的范围非常广,包含了汽车、电脑、电视、手机等产品上&…

企业上商业智能BI前要建数据仓库吗?
大家都知道,企业要做数据分析,商业智能BI和数据仓库二者缺一不可。许多人在疑惑,我的数据仓库还没有建立起来,怎么做商业智能BI呢?真得在做商业智能BI之前先建数据仓库吗?
无论哪一种BI项目,都…
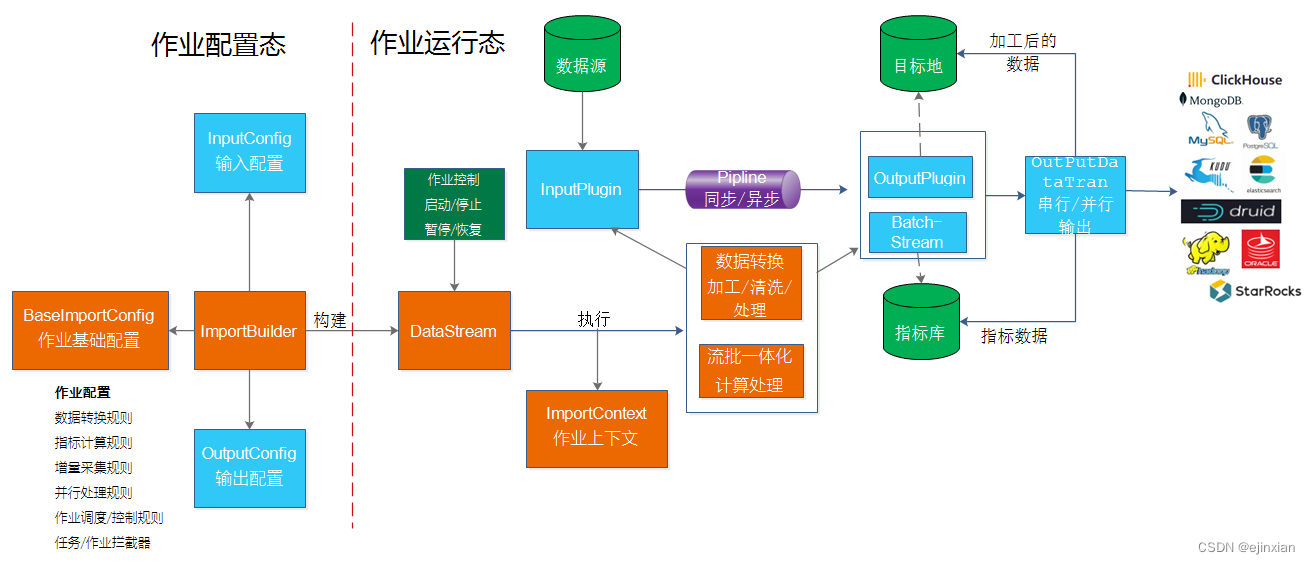
bboss 流批一体化框架 与 数据采集 ETL
数据采集 ETL 与 流批一体化框架
特性: 高效、稳定、快速、安全
bboss 是一个基于开源协议 Apache License 发布的开源项目,主要由以下三部分构成:
Elasticsearch Highlevel Java Restclient , 一个高性能高兼容性的Elasticsea…
Hive常见的面试题(十二道)
Hive
1. Hive SQL 的执行流程
⾸先客户端通过shell或者Beeline等⽅式向Hive提交SQL语句,之后sql在driver中经过 解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 ANTLR&…
ClickHouse 语法优化规则
ClickHouse 的 SQL 优化规则是基于RBO(Rule Based Optimization),下面是一些优化规则 1 准备测试用表 1)上传官方的数据集 将visits_v1.tar和hits_v1.tar上传到虚拟机,解压到clickhouse数据路径下 // 解压到clickhouse数据路径 sudo tar -xvf…

Hive用户中文使用手册系列(四)
Python Client
在github 上上可以使用 Python client 驱动程序。有关安装说明,请参阅设置 HiveServer2:Python Client 驱动程序。
Ruby Client
一个 Ruby client 驱动程序在https://github.com/forward3d/rbhive的 github 上可用。
与 SQuirrel SQL …

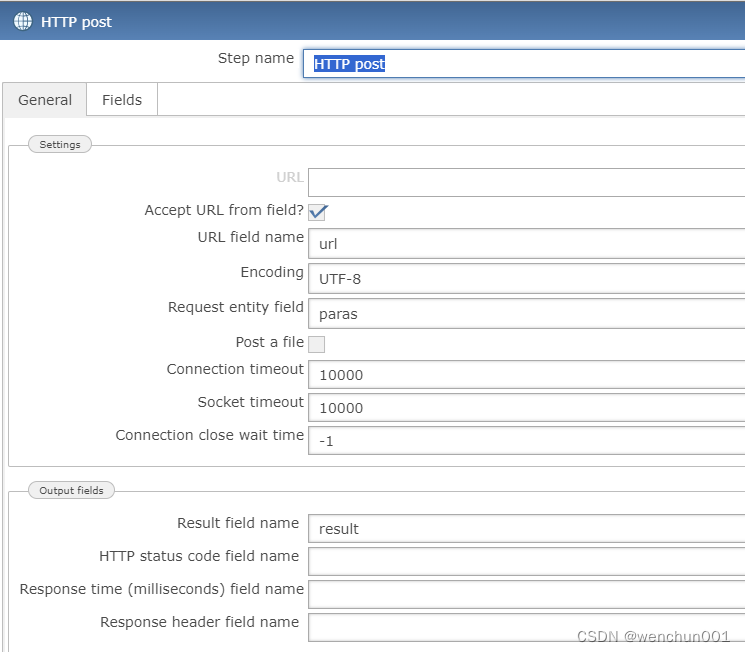
【ETL】Kettle清洗任务异常提醒,Spoon作业异常通知
清洗作业如果挂在第三方任务平台或比较多的任务,执行失败无法跟踪,需要给任务添加异常提醒,这里用钉钉的群消息机器人。 钉钉机器人文档
自定义机器人接入 - 钉钉开放平台 作业示例 通过请求触发告警消息
HiveSql语法优化二 :join算法
Hive拥有多种join算法,包括Common Join,Map Join,Bucket Map Join,Sort Merge Buckt Map Join等,下面对每种join算法做简要说明: Common Join Common Join是Hive中最稳定的join算法,其通过一个M…
SAS认证与数据挖掘、商业智能职业发展
SAS认证与数据挖掘、商业智能职业发展 何为数据挖掘和商业智能? 与数据挖掘相关的词汇有例如数据仓库,数据装载(ETL),数据挖掘(Data Mining), 客户关系管理(CRM),SAS,PeopleSoft, SAP等。到上个世纪…
这些行业已经开始用数据挖掘了,我们的前途光明
从数据中挖掘更多的业务信息、对未来的发展做出辅助分析,这就是数据挖掘的强大功能之一。那么,企业是否已经开始对数据挖掘感兴趣甚至开始运用了呢?近日,我们对国家统计局、中国地质调查局等单位的CIO进行了调查。 让数据像人脑…
Hive建表语法和参数记录
Hive是一个基于Hadoop的数据仓库工具,可以将结构化数据映射到HDFS存储(建表对应在HDFS建了一个文件夹),并提供类SQL查询语言-HiveQL,Hive可以将HQL语句转换为MR任务执行。 本文记录Hive建表的常用语法和参数。
建表语…
数据仓库-日期维度表的设计与实现
时间维度表的制作
1 需求背景
在大数据分析模块中,我们需要从不同的维度分析主题表,包括常用的公用维度:时间维,地区维度,教育信息维…以及各种各样的业务维度:员工维度,部门维度…࿰…
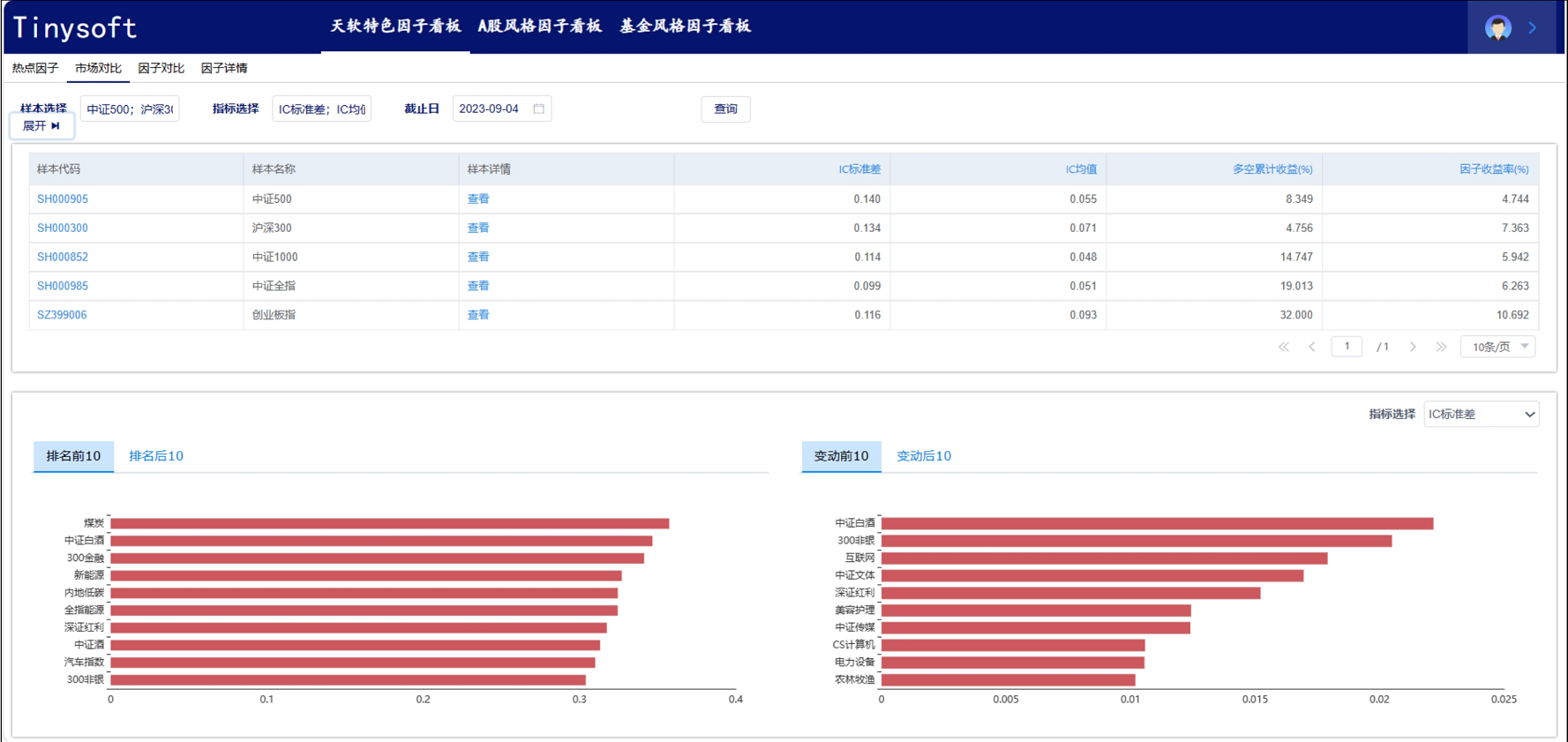
天软特色因子看板 (2023.09 第02期)
该因子看板跟踪天软特色因子A02002(近一月尾盘成交占比(%),该因子为近一个月尾盘成交量占比均值因子,用以刻画股票在收盘时,主力资 金的流动影响。 今日为该因子跟踪第02期,跟踪其在SH000905 (中证500) 中的表现,要点如…

BI 知识大全,值得收藏的干货
01、什么是商业智能BI?
商业智能BI可以实现业务流程和业务数据的规范化、流程化、标准化,打通ERP、OA、CRM等不同业务信息系统,整合归纳企业数据,利用数据可视化满足企业不同人群对数据查询、分析和探索的需求,从而为…
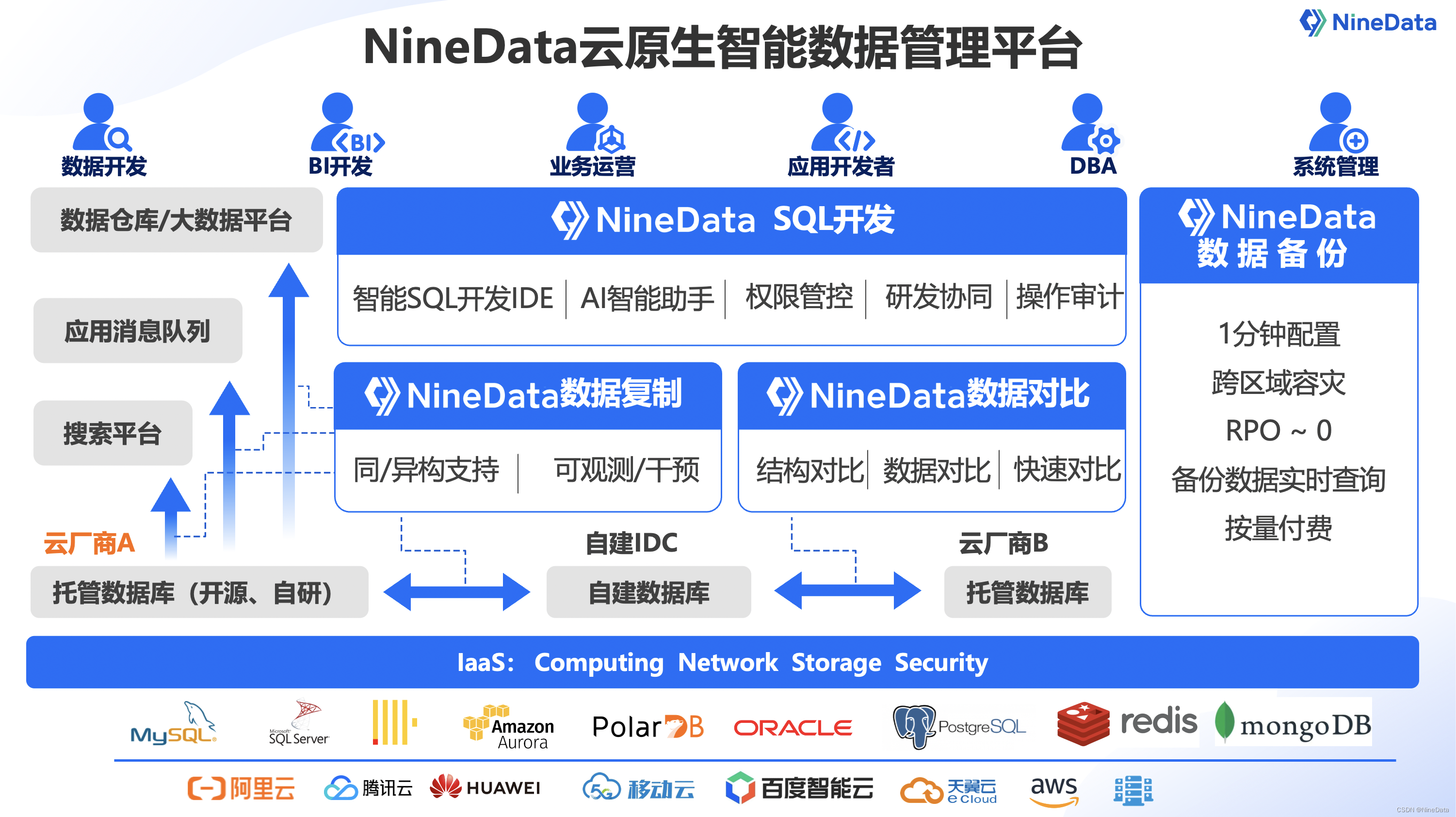
NineData x SelectDB 完成产品兼容互认证
近日,新一代实时数据仓库厂商 SelectDB 与云原生智能数据管理平台 NineData 完成产品兼容互认证。经过严格的联合测试,双方软件完全相互兼容、功能完善、整体运行稳定且性能表现优异。基于本次的合作,双方将进一步为数据管理与大数据分析业务…

接口优化的目录(建议收藏)
目录 前言
编辑
批处理
优点
缺点
场景
同步转异步
优点
缺点
场景
空间换时间
优点
缺点
场景
预处理
优点
缺点
场景
池化技术
优点
缺点
场景
串行改并行
优点
缺点
场景
索引
优点
缺点
场景
避免大事务
优点
缺点
场景
深度分页
优…
SQL中通过QUALIFY语法过滤窗口函数简化代码
MaxCompute和hive都支持使用QUALIFY语法对窗口函数的数据进行过滤,该语法类似于HAVING对聚合和GROUP BY之后的结果的处理。这个语法在很多场景中都可以用到,可以用于简化代码,少写一个子查询,如统计排名,分组内部排序等…
数据仓库介绍及应用场景
数据仓库(Data Warehouse)是一个用于存储、管理、检索和分析大量结构化数据的集中式数据库系统。与传统的事务处理数据库不同,数据仓库是为了支持决策支持系统(Decision Support Systems, DSS)和业务智能(B…
Hive学习第三课 创建数据库和删除数据库
Hive是一种数据库技术,可以定义数据库和表来分析结构化数据。主题结构化数据分析是以表方式存储数据,并通过查询来分析。本章介绍如何创建Hive 数据库。配置单元包含一个名为 default 默认的数据库。
CREATE DATABASE语句
创建数据库是用来创建数据库在…

数据挖掘的价值:寿险行业数据挖掘应用分析
数据挖掘的价值:寿险行业数据挖掘应用分析北京理工大学 刘勇 张丽平2003-12-9 14:47:04 寿险是保险行业的一个重要分支,具有巨大的市场发展空间,因此,随着寿险市场的开放、外资公司的介入,竞争逐步升级,群雄…
数据挖掘在CRM中的运用
数据挖掘在CRM中的运用 来自:中国计算机 作者:江华 日期:2002年05月23日 浏览次数:1758 在客户关系管理(CRM)理论中有一个经典的2/8原则,即80%利润来自20%客户。那么,这20%的客户都…
打破数据围墙 加速金融创新
“ 2018百度云智峰会首站ABC Inspire智能金融峰会在上海成功举行,在本次峰会的金融大数据论坛上,来自百度金融、杰贝斯、大地保险、文思海辉等公司的多位金融领域专家分享了大数据在金融行业的应用趋势和实践经验,百度云重点分享了鲁班大数据…

Hive学习 第一课
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 Hive 不是
一个关系数据库一个设计用于联机事务处…
modelarts二
一、导入数据 创建声音分类项目 数据标注(分标签)后进行模型训练 训练完成后进行部署 二、对于文本分类 进入更多,文本、标签分开
之后再 之后部署然后检测
【黑马甄选离线数仓day04_维度域开发】
1. 维度主题表数据导出
1.1 PostgreSQL介绍
PostgreSQL 是一个功能强大的开源对象关系数据库系统,它使用和扩展了 SQL 语言,并结合了许多安全存储和扩展最复杂数据工作负载的功能。
官方网址:PostgreSQL: The worlds most advanced open s…

2023.11.24 海豚调度,postgres库使用
目录
海豚调度架构dolphinscheduler
DAG(Directed Acyclic Graph),
个人自用启动服务 DS的架构(海豚调度) 海豚调度架构dolphinscheduler 注:需要先开启zookeeper服务,才能进行以下操作 通过UI进行工作流的配置操作, 配置完成后, 将其提交执行, 此时执行请求会被…
【Hive 基础】-- 数据倾斜
1.什么是数据倾斜?由于数据分布不均匀,导致大量数据集中到一点,造成数据热点。常见现象:一个 hive sql 有100个 map/reducer task, 有一个运行了 20分钟,其他99个 task 只运行了 1分钟。2.产生数据倾斜的原…
[Hive] 查询结果保存
文章目录 1.插入新表追加 2.插入hdfs文件系统 1.插入新表
使用INSERT OVERWRITE语句的情况:
整个表:可以使用INSERT OVERWRITE TABLE table_name语句将查询结果直接覆盖整个表中的数据。
INSERT OVERWRITE TABLE table_name
SELECT * FROM ...特定分区…
2023.11.12 hive中分区表,分桶表与区别
1.分区表 分区表的本质就是在分目录
当Hive表对应的数据量大、文件多时,为了避免查询时全表扫描数据。比如把一整年的数据根据月份划分12个月(12个分区),后续就可以查询指定月份分区的数据,尽可能避免了全表扫描查询。…
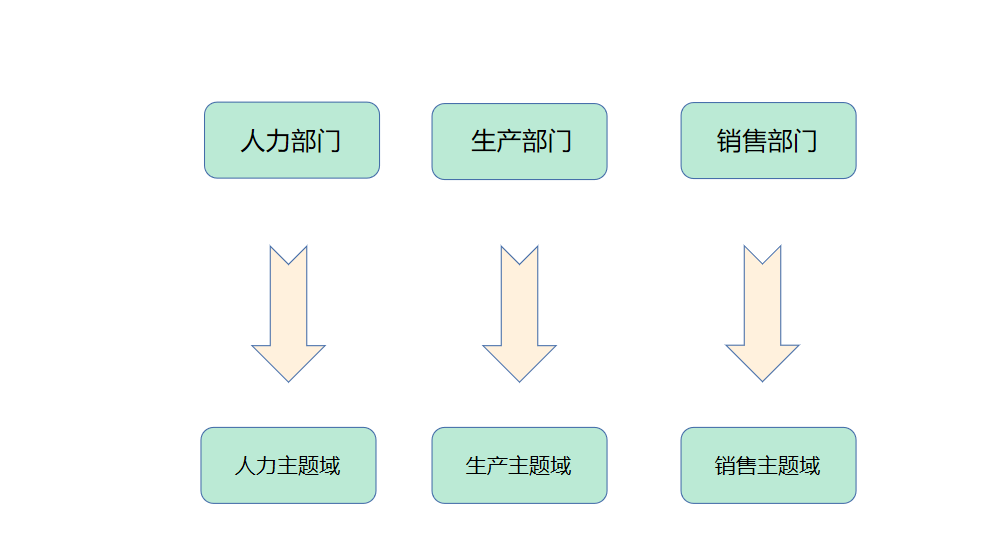
数仓建模—主题域和主题
主题域和主题
前面在这个专题的第一篇,也就是数仓建模—数仓初识中我们就提到了一个概念—主题,这个概念其实在数仓的定义中也有提到 数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。 今天我们主要来探究一下,数仓的主题到底是…
为什么hive会出现_HIVE_DEFAULT_PARTITION分区
问题:
为什么hive表中出现_HIVE_DEFAULT_PARTITION分区?
解答:
因为在业务sql中使用的是动态分区,并且hive启用动态分区时,对于指定的分区键如果存在空值时,会对空值部分创建一个默认分区用于存储该部分…
clickhouse导入数据 DBeaver大坑
测试数据有一亿条需要导入数据库,使用DBeaver自带导入数据功能,结果放置一晚才导入一千万条,估计导入设置有问题。于是寻找合适方式,记录如下:
首先将待导入的csv数据表45G 传输到clickhouse所在的服务器在数据库中提…
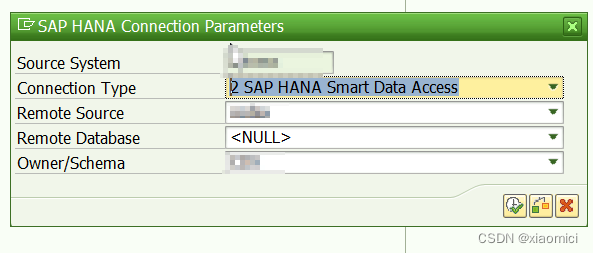
HANA SDA连接外部数据库到BW的步骤
咱都知道,我们不能直接从BW连接到外部数据库。第一步得从HANA database通过SDA去建一个到外部DB的连接。 数据库连接好了,那么接下来别忘了,还得建一个源系统。
也就是说第一步,我们要用HANA SDA通过Linux ODBC driver去连接外部…

kettle数据库链接共享(或本地配置文件)
在一个文件里,新建所有需要共享的数据库链接。 然后右键数据库链接,点共享。
之后重启Kettle可以完成共享,或者重复共享,取消共享操作。
共享操作主要是修改了,kettle本地的配置文件shared.xml 有需要的小伙伴&…

kettle报错 GC overhead limit exceeded(内存溢出问题)
遇到了线上运行kettle运行kettle脚本时,报错 java.lang.OutOfMemoryError: GC overhead limit exceeded 原因是本地测试的内存设置和线上内存设置不同,可以修改下线上配置的内存大小。
Spoon.bat(windows端)和Spoon.sh࿰…
数仓之 数据埋点简单了解
主流埋点方式:
目前主流的埋点方式,有代码埋点(前端/后端),可视化埋点,全埋点三种。
代码埋点:是通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点…

核音智言数据中台,让行业数据“动”起来
一、前言
数据中台不是简单的一套软件系统或者标准化产品,更多的是一种强调资源整合、集中配置、能力沉淀、分部执行的运作机制,是一系列数据组件或模块的整合,为企业数据治理效率的提升、业务流程与组织架构的升级、运营与决策的精细化赋能…

kettle连接上oracle却不能浏览数据库缺少orai18n.jar
Centos8系统,kettle8.3版本,今天用kettle连接oracle数据库成功,但浏览时报错: 这个一看就是缺少包,所以想着去网上下一个,谁知全是某s某n的文件,要积分,都不知道这种积分拿着烫手不&…
数据的搬运工——ETL
作者 | 李谦恒数据工程师。逻辑重于代码,高效胜过勤奋。崇尚life work balance。ETL 开发是数据工程师必备的技能之一,在数据仓库、BI 等场景中起到重要的作用。但很多从业者连 ETL 对应的英文是什么都不了解,更不要谈对 ETL 的深入解析&…
QUERY_REWRITE_ INTEGRITY的设置
QUERY_REWRITE_ INTEGRITY的设置。QUERY_REWRITE_INTEGRITY参数有三个取值:
STALE_TOLERATED表示即使细目表中的数据已经发生了变化,也仍然使用物化视图。
TRUSTED 表示物化视图未失效时才使用该视图。但是,查询改写可以使用信任关系&…
Apache Doris 入门教程35:多源数据目录
概述
多源数据目录(Multi-Catalog)功能,旨在能够更方便对接外部数据目录,以增强Doris的数据湖分析和联邦数据查询能力。
在之前的 Doris 版本中,用户数据只有两个层级:Database 和 Table。当我们需要连接…
Hive面试题系列第一题-连续登录问题
视频讲解地址:https://www.bilibili.com/video/BV1iV4y1x7yo?spm_id_from333.999.0.0&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第一题-连续登录问题 题目:求连续7天登录的用户 表结构:
CREATE TABLE logtable( uid int, dt s…
Hive面试题系列第三题-用户留存问题
视频讲解地址:https://www.bilibili.com/video/BV1Rd4y1T7iU/?spm_id_from333.788&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第三题-用户留存问题
题目:求用户1日、3日、7日留存率 概念问题: 第N日活跃用户留存率&am…
Hive面试题系列第七题-同时在线问题
视频讲解地址: https://www.bilibili.com/video/BV1Tg411r7Jz/?spm_id_from333.788&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第七题-同时在线问题 题目:计算主播最高同时在线人数(pcu) 表结构:
create t…

BW Delta (增量)更新方法
BW Delta (增量)更新方法 . 我们都知道,对于BW来说,很多ECC的标准数据源自带了增量更新功能,每天各种凭证产生的增量数据会自动堆积到增量队列里,然后BW端做一个增量信息包按天把这些增量抽取到数据仓库里&…
荐] java数据库设计中的14个技巧[问题点数:100分]
下述十四个技巧,是许多人在大量的数据库分析与设计实践中,逐步总结出来的。对于这些经验的运用,读者不能生帮硬套,死记硬背,而要消化理解,实事求是,灵活掌握。并逐步做到:在应用中发…
mysql编译安装及PHP配置
一、编译安装mysqld 服务 1、将安装mysql 所需软件包传到/opt目录下2、安装环境依赖包3、配置软件模块4、编译及安装5、创建mysql用户 6、修改mysql 配置文件7、更改mysql安装目录和配置文件的属主属组 8、设置路径环境变量9、初始化数据库 10、添加mysqld系统服务11.修改mys…

《Greenplum构建实时数据仓库实践》简介
#好书推荐##好书奇遇季#《Greenplum构建实时数据仓库实践》,京东当当天猫都有发售。定价89元,网店打折销售其实没多少钱。
Greenplum分布式数据库具有可选存储模式、事务支持、并行查询与数据装载、容错与故障转移、数据库统计、过程化语言扩展等方面的…
电商API接口-电商OMS不可或缺的一块 调用代码展示
电商后台管理系统关键的一环就是实现电商平台数据的抓取,以及上下架商品、订单修改等功能的调用。这里就需要调用电商API接口。接入电商API接口后再根据自我的需求进行功能再开发,实现业务上的数字化管理。其中订单管理模板上需要用到如下API:seller_ord…
SQL解惑 - 谜题2
文章目录 一、谜题描述二、分析三、答案四、总结 一、谜题描述
创建一个记录雇员缺勤率的数据库。使用的表结构如下:Absenteeism 主键:PRIMARY KEY (emp_id, absent_date)
字段名字段类型字段中文名字段描述emp_idINTERGER雇员id-absent_dateSTRING缺勤…


HDFS Namenode是如何工作的?
来自:http://www.csdn.net/article/2012-07-03/2807066 HDFS(Hadoop Distributed Filesystem)客户端通过被称之为Namenode单服务器节点执行文件系统原数据操作,同时DataNode会与其他DataNode进行通信并复制数据块以实现冗余&#…
API接口接入电商数据平台获取lazada来赞达商品详情、销量、价格等参数调用示例
商品详情API接口在电商平台和购物应用中的作用非常重要。它提供了获取商品详细信息的能力,帮助用户了解和选择合适的商品,同时也支持开发者进行竞品分析、市场研究和推广营销等工作,以提高用户体验和促进销售增长。
lazada.item_get-获得laz…
ClickHouse的分片和副本
1.副本 副本的目的主要是保障数据的高可用性,即使一台ClickHouse节点宕机,那么也可以从其他服务器获得相同的数据。 Data Replication | ClickHouse Docs 1.1 副本写入流程 1.2 配置步骤 (1)启动zookeeper集群 (2&…
Trino 与Hive 有差异的函数
日常使用中发现trino和hive中的有一些函数存在差异,所以开此帖记录一下 这里只是记录trino和hive有差异的函数,遇到了就会记录一下,不定期更新
1. 查看集合中元素个数
hive:size() trino:cardinality()
2. map取值 …

数据仓库卸数(网银系统数据库)
网银系统卸数
概念
ETL中文名为数据抽取、转换和加载。ETL负责将分布的、异构数据源中的数据,如关系数据、平面数据文件等抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或者数据集市中,成为联机分析处理、数据挖掘的基础。ET…
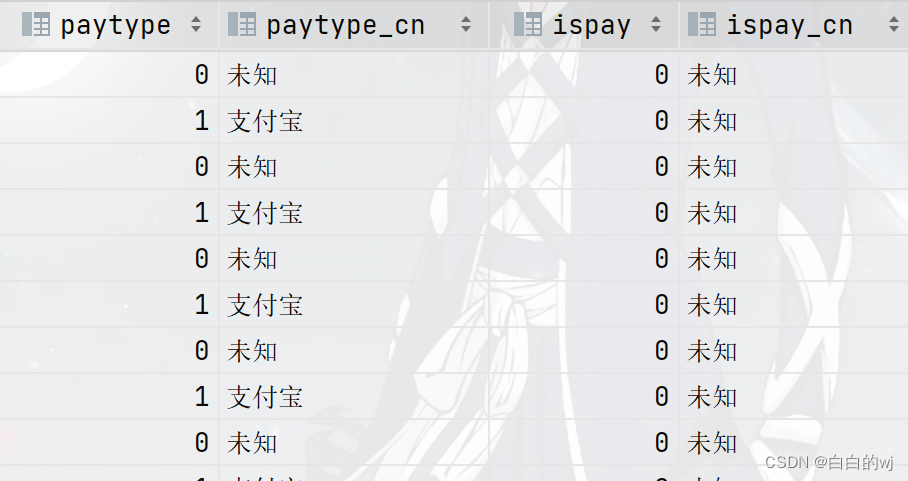
2023.11.16 hivesql之条件函数,case when then
目录 一.Conditional Functions条件函数
二.空值相关函数
三:使用注意事项
3.1 then后面不能接子查询
3.2 then后面只能是结果值
3.3 then后面能不能接两列
四.用于建表新增字段使用场景 一.Conditional Functions条件函数 -- 演示条件函数
-- if(条件判断,t…
Hive(17):Hive Show显示语法
Show相关的语句提供了一种查询Hive metastore的方法。可以帮助用户查询相关信息。
1 显示所有数据库 SCHEMAS和DATABASES的用法 功能一样
show databases;
show schemas; 2 显示当前数据库所有表/视图/物化视图/分区/索引
show tables;
SHOW TABLES [IN database_name]; --指…
Hive窗口函数详细介绍
文章目录 Hive窗口函数概述样本数据表结构表数据 窗口函数窗口聚合函数count()SQL演示 sum()SQL演示 avg()SQL演示 min()SQL演示 max()SQL演示 窗口分析函数first_value() 取开窗第一个值应用场景SQL演示 last_value()取开窗最后一个值应用场景SQL演示 lag(col, n, default_val…
数据仓库与数据湖的区别以及数据入湖方式
数据仓库与数据湖的区别
1)从使用对象来看,数据仓库主要是给 BI分析的数据分析师使用的,而数据湖是给AI处理的数据科学家使用,数据仓库也可以给AI使用,但是侧重点是 BI.
2)从数据处理的过程来看,数据仓库是ETL&#…
Hive UDF自定义函数上线速记
0. 编写hive udf函数jar包
略
1. 永久函数上线
1.1 提交jar包至hdfs
使用命令or浏览器上传jar到hdfs,命令的话格式如下 hdfs dfs -put [Linux目录] [hdfs目录] 示例:
hdfs dfs -put /home/mo/abc.jar /tmp1.2 将 JAR 文件添加到 Hive 中
注意hdfs路径前面要加上hdfs://na…

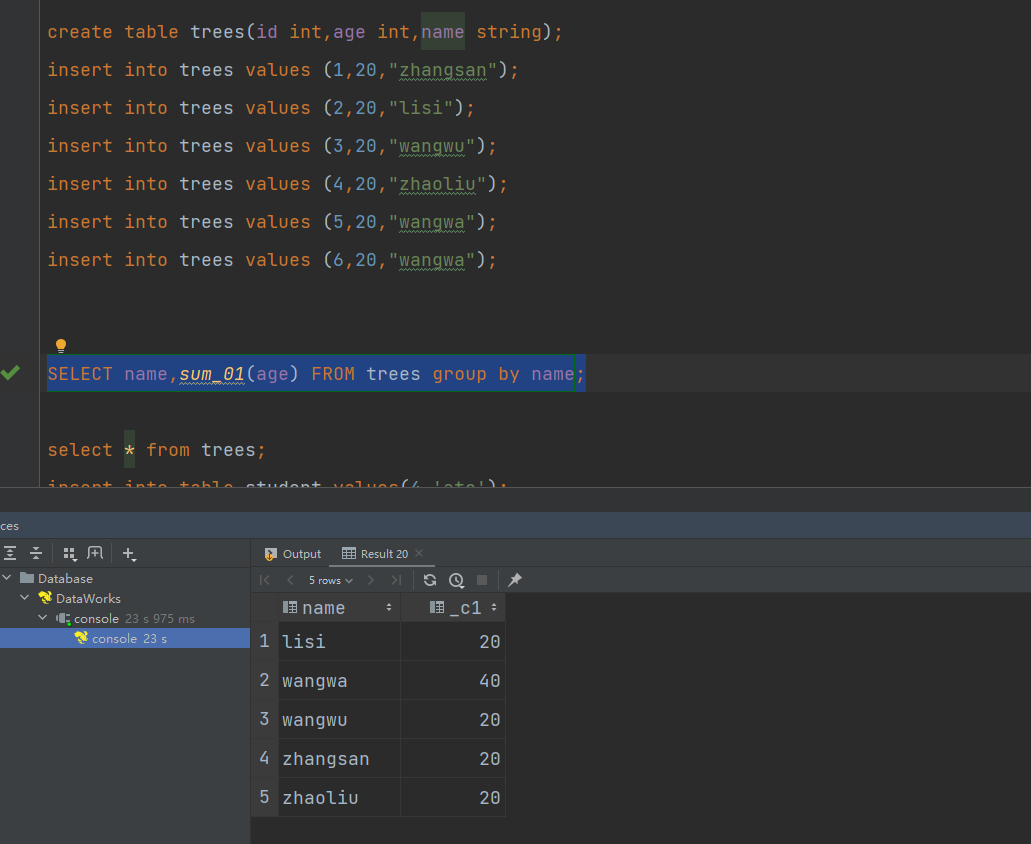
hive自定义函数及案例
一.自定义函数
1.Hive自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
2.当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数。
3.根据用户自定义…
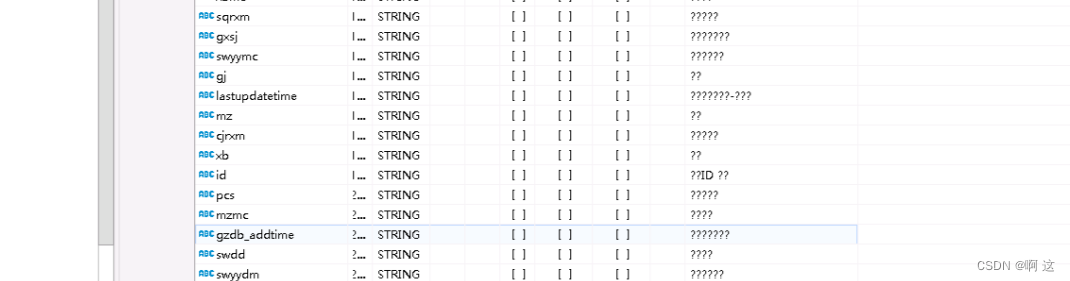
CDH 之 Hive 中文乱码平定通用法则
一、乱象
1.1 中文注释乱码 hive> DESCRIBE test;
OK
# col_name data_type comment
id string ??ID ??
pcs string ????? …

全球汽车行业的数字化转型:产品和后端的渐进之旅
如何管理汽车行业的数字化转型?在我们本篇文章中了解更多有关如何设定长期目标的信息。 正在改变汽车行业的26个数字化主题 最近一篇关于汽车行业数字化转型的论文确定了26个数字技术主题(论文详情请点击阅读原文),分为三个主要集群:
1)驾驶…
Hive -- 基本概念
1、什么是Hive:
Hive是数据仓库建模的工具之一,通过向hive中写一个交互式的sql,在海量数据中查询分析得到结果的平台。
2、Hive的优缺点: 1、优点:
1、操作接口采用类sql语法,提供快速开发的能力&#x…
Doris中分区和分桶使用教程
1 分区与分桶 Doris中有两层的数据划分,第一层是分区(Partition),第二层是分桶(Bucket), Partition又能分为Range分区和List分区。 Bucket仅支持Hash方式。
1.1 Partition 只能指定…

Airbyte,数据集成的未来
Gartner 曾预计,到 2025 年,80% 寻求扩展数字业务的组织将失败。因为他们没有采用现代方法来进行数据和分析治理。数据生态是基础架构生态的最重要一环,数据的处理分发与计算,从始至终贯穿了整个数据流通生态。自从数据集中在数据…
【Hive-Partition】Hive添加分区及修改分区location
【Hive-Partition】Hive添加分区及修改分区location 1)整表修复数据2)单独分区修复 当我们在 Hive 中创建外表时,需要映射 HDFS 路径,数据落入到 HDFS 上时,我们在 Hive 中查询时会发现 HDFS中有数据,Hive …

为什么要数字化转型?挑战是什么?
对大多数企业来说,稳步发展才是首要目的,所以企业数字化转型的最主要的原因还是无法坚持发展路径,只能通过转型来获取新的生命力,而在数字化时代,数字化转型就是最好的转型方式。
1、市场竞争加剧
经过几十年现代化的…
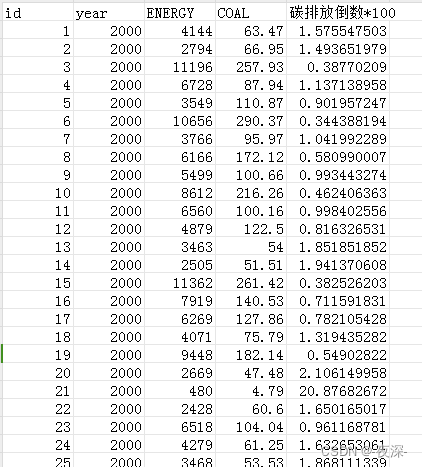
2000-2018年各省能源消费和碳排放数据
2000-2018年各省能源消费和碳排放数据
1、时间:2000-2018年
2、范围:30个省市
3、指标:id、year、ENERGY、COAL、碳排放倒数*100
4、来源:能源年鉴
5、指标解释:
2018年碳排放和能源数据为插值法推算得到
碳排放…
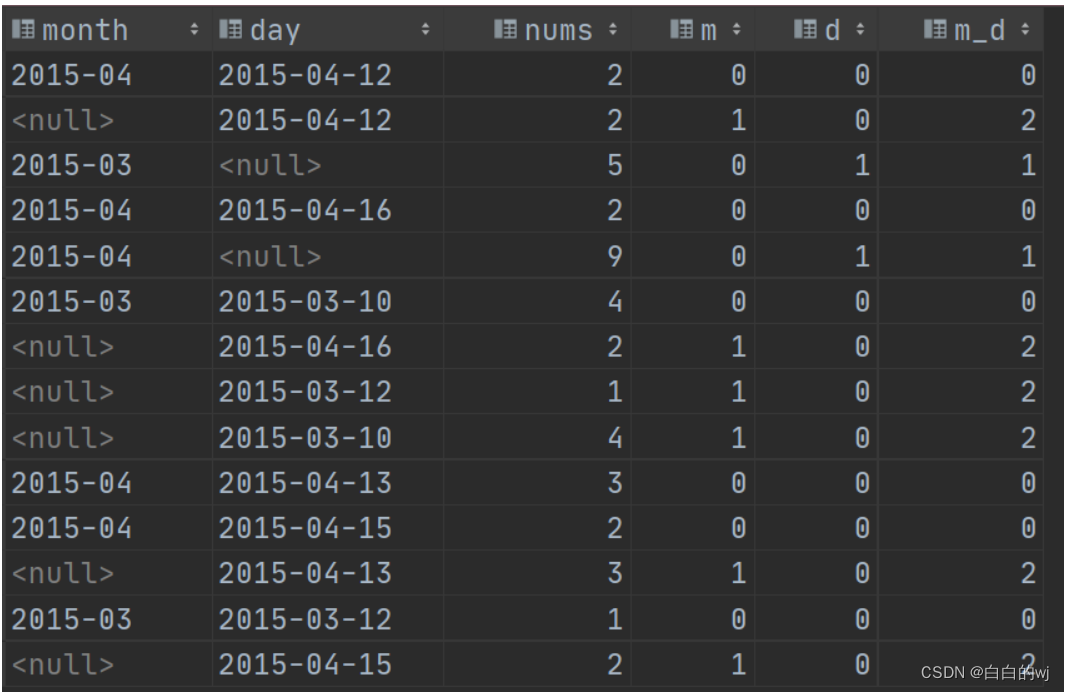
2023.12.14 hive sql的聚合增强函数 grouping set
目录 1.建库建表 2.需求 3.使用union all来完成需求 4.聚合函数增强 grouping set 5.聚合增强函数cube ,rollup 6.rollup翻滚
7.聚合函数增强 -- grouping判断 1.建库建表
-- 建库
create database if not exists test;
use test;
-- 建表
create table test.t_cookie(month …
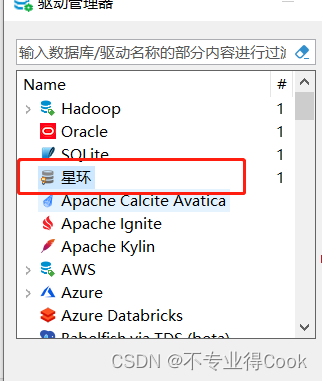
【DBeaver】驱动添加-Hive和星环
驱动
Hive驱动
hive驱动可以直接去官网下载官网地址,填一下个人信息。
如果想直接下载可以去我上次的资源下地址,需要用zip解压。
星环驱动
星环驱动是我第一次接触,是国产的基于开源Hive驱动自研的产品,我看到官网上有很多类…
HDFS配置lzo压缩
参考 https://www.cnblogs.com/caoshouling/p/14091113.html, 做了验证,很好的文档。 1) 停止hdfs集群
2)安装配置maven
https://blog.csdn.net/hailunw/article/details/117996934
3)生成lzo压缩程序包
3.1)安装前…

Mybatis-plus的分页查询
Mybatis-plus的分页查询1. 简单说明2. 介绍说明3. 完整配置类代码:4. 示例代码5. 最后总结1. 简单说明
嗨,大家好!今天给大家分享的是Mybatis-plus 插件的分页机制,说起分页机制,相信我们程序员都不陌生,今…

率先拿下512节点测试,华为GaussDB表示“很轻松”
近日,在中国信息通信研究院和数据中心联盟发起的分布式分析型数据库测试中,华为GaussDB分析型数据库率先通过512节点集群规模能力评测。与此同时,中国某世界级银行也完成了采用华为GaussDB分布式分析型数据库对国外顶级数据仓库产品的完全替代…
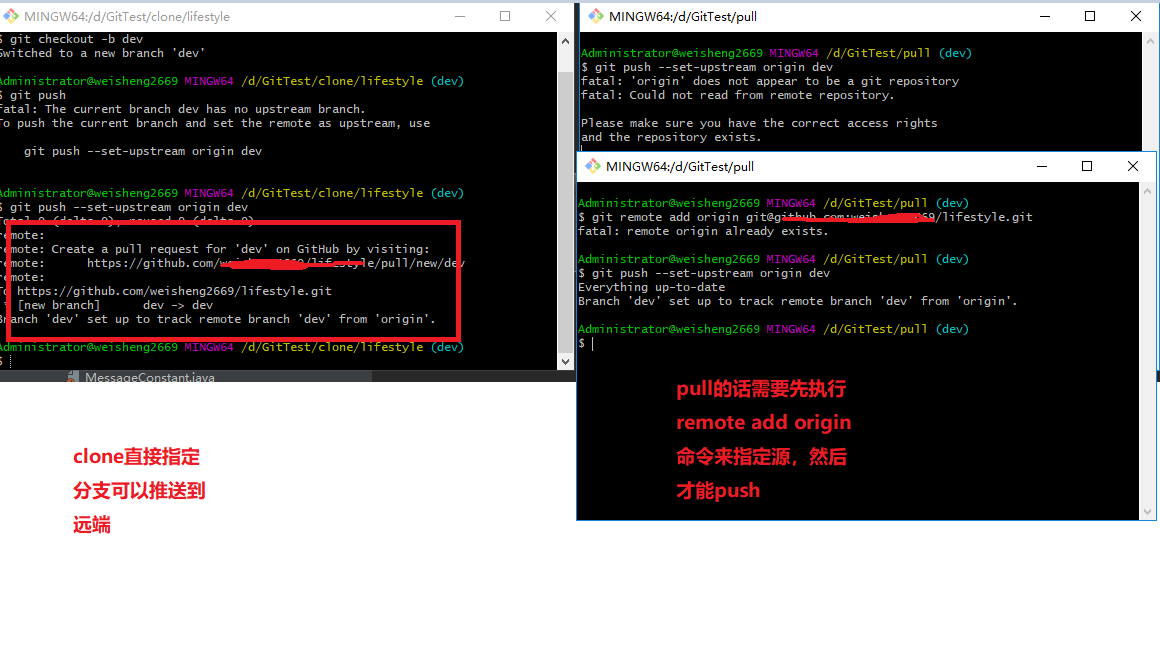
仓库管理工具Git之git clone和git pull的区别
实际应用项目:http://github.crmeb.net/u/long 1.需不需要本地文件夹是仓库 git clone是将整个工程复制下来所以,不需要本地是仓库(没有.git文件夹) git clone
git pull需要先初始化本地文件夹文一个仓库 git pull 2.切换分支的问…

【Hive】位于Hadoop顶层的数据仓库——Hive知识点总结(图解)
content Hive简介Hive工作原理Hive系统架构Hive HAHive编程 Hive简介
▍初见
Hive是一个构建于Hadoop顶层的数据仓库工具某种程度上的用户编程接口——因为Hive本身不存储和处理数据Hive依赖分布式文件系统HDFS存储数据Hive依赖分布式并行计算模型MapReduce处理数据定义了简单…
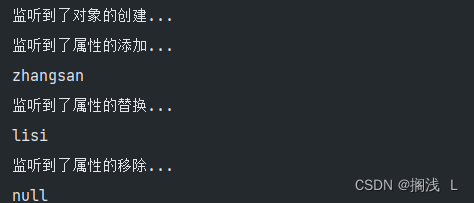
Filter与Listener(过滤器与监听器)
1.Filter
1.过滤器概述
过滤器——Filter,它是JavaWeb三大组件之一。另外两个是Servlet和Listener
它可以对web应用中的所有资源进行拦截,并且在拦截之后进行一些特殊的操作
在程序中访问服务器资源时,当一个请求到来,服务器首…
BDCC - 闲聊数据仓库的架构
文章目录 典型数据仓库架构图数据仓库ETL vs ELTETLELT区别联系 数据仓库分层(1)数据仓库ODS层(2)数据仓库CDM层DWD数据明细层DWS数据汇总层 (3)数据仓库ADS层 典型数据仓库架构图 按自下而上的顺序&#x…

数据仓库的一些常用概念
什么是SKU?
SKU, Stock Keeping Unit,库存量基本单位,现在引申为产品统一编号的简称。每种产品均对应有唯一的SKU号。 什么是SPU?
SPU,Standard Product Unit,是商品信息聚合的最小单位。是一组可复用的易检索的标准化信息集合。表示一类商…

【黑马甄选离线数仓day02_数据采集】
1. 数仓工具使用-DataX
1.1 DataX介绍
DataX 是阿里推出的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
将DataX安装好之后, 仅需要配置Json的采…
分布式与集群的定义及异同
分布式与集群的定义及异同 分布式定义优点不足 集群优点不足 异同 分布式
定义
分布式是指将一个系统或应用程序分散到多个计算机或服务器上进行处理和管理的技术。它是指多个系统协同合作完成一个特定任务的系统。例如,可以将一个大业务拆分成多个子业务…


记一次CDH集群迁移产生的问题——HIVE
背景
生产环境CDH集群迁移到新的环境,迁移之后使用Hive Client方执行任务一直失败。
问题1:metadata.SessionHiveMetaStoreClient
产生报错:
FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.Ru…
【大数据 - Doris 实践】数据表的基本使用(二):数据划分
数据表的基本使用(二):数据划分 1.列定义2.分区与分桶2.1 Partition2.1.1 Range 分区2.1.2 List 分区 2.2 Bucket2.3 使用复合分区的场景 3.PROPERTIES3.1 replication_num3.2 storage_medium3.3 storage_cooldown_time 4.ENGINE 1.列定义
列…
educoder中Hive -- 索引和动态分区调整
第1关:Hive -- 索引 ---创建mydb数据库
create database if not exists mydb;
---使用mydb数据库
use mydb;
---------- Begin ----------
---创建staff表
create table staff(
id int,
name string,
sex string)
row format delimited fields terminated by ,
stored…
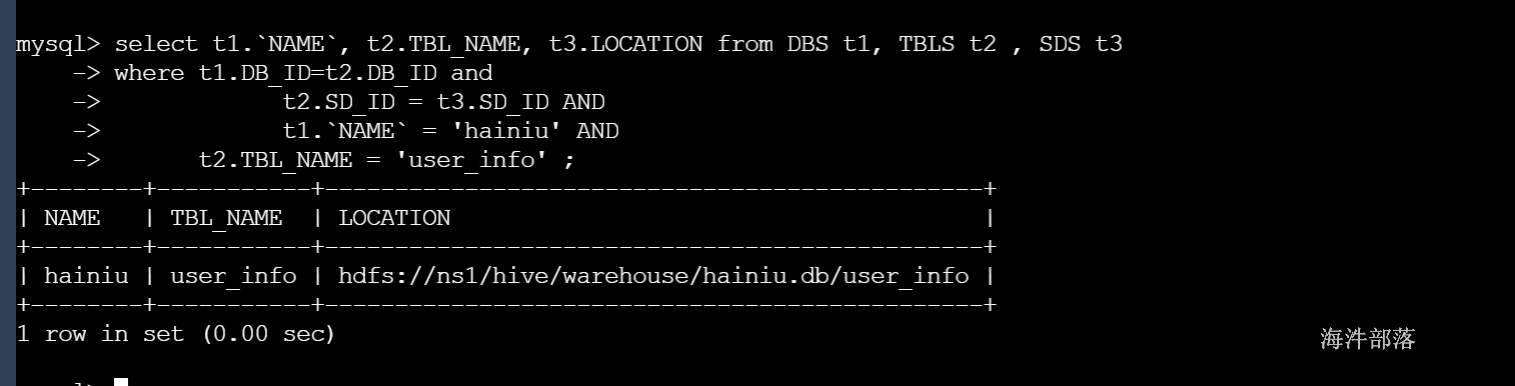
hive或者impala如何根据字段找到表
hive或者impala如何根据字段找到表
举个例子,我想在知道有一个字段叫做user_ip,但是我不知道这个字段存放在哪个表里面,怎么办呢? 我希望有一种可以通过字段名称,反向查找表名的功能。 这个功能在mysql中已经有了。 但…
软件离岸外包商模式转型应基于客户分布特征
事件背景
近日文思公司(NYSE:VIT)宣布为3M中国在沪设立软件外包服务中心,承接3M中国部分IT项目,为3M中国运营提供电子商务解决方案。文思公司的3M软件外包服务中心为3M中国承担包括eBusiness应用系统、数据仓库开发在内的部分应…
Doris 数据导入二:Stream Load 方式
Stream load 是一个同步的导入方式,用户通过发送 HTTP 协议发送请求将本地文件或数据流导入到 Doris 中。Stream load 同步执行导入并返回导入结果。用户可直接通过请求的返回体判断本次导入是否成功。 1 适用场景 Stream load 主要适用于导入本地文件,或通过程序导入数据流中…
国家开放大学平时作业 练习题
试卷代号:1377 理工英语3 参考试题 一、交际用语(共计10分,每小题2分)
1-5题:选择正确的语句完成下列对话,并将答案序号写在答题纸上。
1.-1 won the first prize in todays speech contest.
- …
Hive(16):Partition(分区)DDL操作
1 Add partition
分区值仅在为字符串时才应加引号。位置必须是数据文件所在的目录。
ADD PARTITION会更改表元数据,但不会加载数据。如果分区位置中不存在数据,查询将不会返回任何结果。
--1、增加分区
ALTER TABLE table_name ADD PARTITION (dt=20170101) location /use…
Fink Data Sink
Flink Sink
一、Data Sinks
在使用 Flink 进行数据处理时,数据经 Data Source 流入,然后通过系列 Transformations 的转化,最终可以通过 Sink 将计算结果进行输出,Flink Data Sinks 就是用于定义数据流最终的输出位置。Flink 提供了几个较为简单的 Sink API 用于日常的开…
Apache Doris (十六) :Doris分区和分桶2-List分区
目录
1. List分区
1.1 创建List分区方式
1.2 增删分区
1.3 多列分区 进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道,获取高质量博客内容! 1. List分区
业务上,用户可以选择城市或…
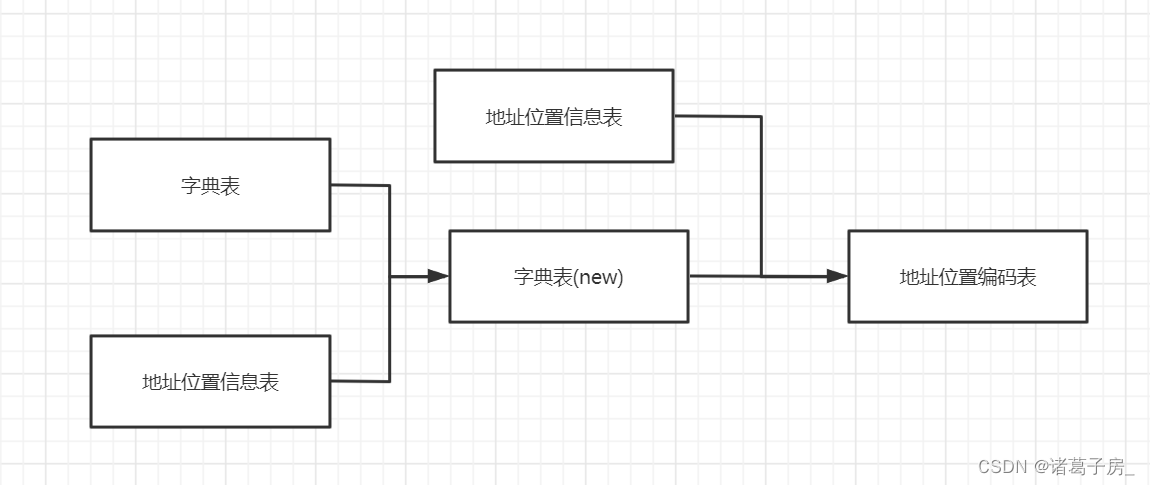
离线表数据敏感字段自动id化处理
一、背景
对于一些表数据包含的铭感字段需要id 化处理,比如说:用户搜索了某个关键词,或者用户的购物地址是某个城市,这种都需要进行模糊化处理,但是直接模糊化处理不利于使用,比如说:在三四线城…

什么是数据湖技术数据湖和数据仓库的区别(好文转载)
原文链接:什么是数据湖技术 - xuzhujack - 博客园
什么是数据湖?有什么用?终于有人讲明白了……_大数据-CSDN博客 数据湖(Data Lake)是Pentaho公司创始人及CTO James Dixon于2010年10月在2010年10月纽约Hadoop World大会上提出来的一种数据…

与创新者同行,Apache Doris in 2023
在刚刚过去的 Doris Summit Asia 2023 峰会上,Apache Doris PMC 成员、飞轮科技技术副总裁衣国垒带来了“与创新者同行”的主题演讲,回顾了 Apache Doris 在过去一年所取得的技术突破与社区发展,重新思考了在面对海量数据实时分析上的挑战与机…
小白也能看懂,解读数据中台
不同的企业对数据有不同的需求。企业数据应用不断更新迭代,企业的中台系统也需要不断变化。从数据处理与数据治理两个维度出发,可以设计一个解耦的数据中台体系架构。该数据中台体系架构具有一定的柔性,可按照企业应用需求进行组合࿰…
【Hive实战】Hive 物化视图
Hive 物化视图 (Materialized views) 始于Hive3.0.0 文章目录 Hive 物化视图 (Materialized views)目标Hive中物化视图的管理创建物化视图物化视图管理的其他操作 基于物化视图的查询重写物化视图的维护物化视图的生命周期 目标
传统上,用于…

基于数据湖的多流拼接方案-HUDI概念篇
目录
一、为什么需要HUDI?
1. 传统技术选型存在哪些问题?
2. Hudi有什么优点?
基于 Hudi Payload 机制的多流拼接方案:
二、HUDI的应用场景
1. 什么场景适合使用hudi?
2. 什么场景不适合使用hudi?
…
大数据常见应用场景及架构改进
大数据常见应用场景及架构改进大数据典型的离线处理场景1.大数据数据仓库及它的架构改进2.海量数据规模下的搜索与检索3.新兴的图计算领域4.海量数据挖掘潜在价值大数据实时处理场景大数据典型的离线处理场景
1.大数据数据仓库及它的架构改进
对于离线场景,最典型…
数据仓库研究的目的与意义
数据仓库是一种用于存储和管理大量历史数据的系统。它旨在为企业和组织提供一个数据的集中存储和管理的平台,以便进行数据分析和报告。 数据仓库的目的是帮助企业和组织更好地管理和利用其历史数据,以提高决策效率并提升业务绩效。数据仓库可以支持多种不…
2022年福建省安全员B证(项目负责人)最新解析及福建省安全员B证(项目负责人)考试总结
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:福建省安全员B证(项目负责人)最新解析是安全生产模拟考试一点通总题库中生成的一套福建省安全员B证(项目负责人)考试总结࿰…
数据中台OneID:详解ID-Mapping!
01 | ID-Mapping 简介
在推进用户画像和风险控制时,遇到的最大的问题是用户身份信息的混乱:
相同设备,不同账号间切换相同用户,不同渠道下账号不相同,如微信小程序和APP同个用户,在不同的设备商登录…
I…
家中闲置旧电脑改装家用NAS(入门教程)
家中闲置旧电脑改装家用NAS(纯小白入门教程)什么是NAS?NAS的基本知识在国内的常用品牌NAS品牌的配置问题作者的硬件配置装机正文准备工作旧电脑的准备工作(已经完成或无这方面问题的可跳过)引导盘的制作旧电脑的设置调…
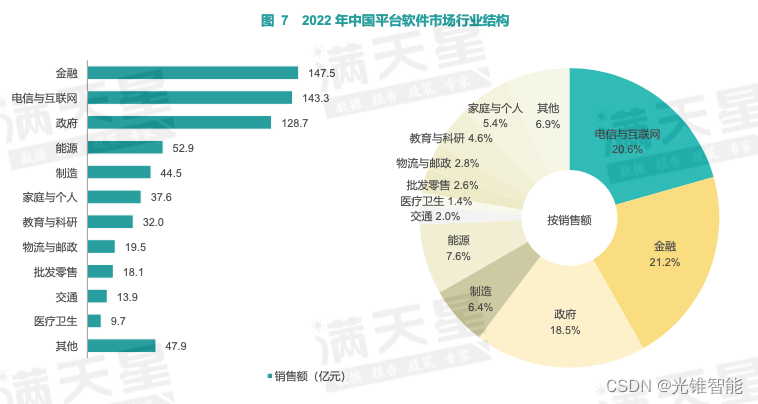
中国平台软件市场研究报告:OceanBase为金融行业国产分布式数据库销售额第一
近日,《2022-2023年度中国平台软件市场研究报告》(以下简称“报告”)发布,报告对包括数据库、操作系统等在内的平台软件市场发展进行了分析。报告指出,在对平台软件需求增长最快的金融行业,OceanBase已占据…
2023-数仓常见问题以及解决方案
01 数据仓库现状
小 A 公司创建时间比较短,才刚过完两周岁生日没多久;业务增长速度快,数据迅速增加,同时取数需求激增与数据应用场景对数据质量、响应速度、数据时效性与稳定要求越来越高;但技术能力滞后业务增长&…
Hive 用户访问路径明细表计算
用户访问路径分析: 用户访问路径明细记录表 源表:DWD_APP_TFC_DTL_DEMO 目标表:DWD_APL_RUT_DTL
源表DWD_APP_TFC_DTL_DEMO表结构:
hive>create table DWD_APP_TFC_DTL_DEMO(
guid bigint,
eventid String,
event Map<String…
Hive面试题系列第二题-行转列问题
视频讲解地址:https://www.bilibili.com/video/BV1BG4y1v7Ps/?spm_id_from333.788&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第二题-行转列问题 题目:求语文课程成绩大于英语课程成绩的学生的学号 表结构:
create table score_t…
快速入门数据仓库(Data WareHouse)
在很久很久之前,异世界里生活着许许多多的种族,有人类、有精灵、有兽人,还有哥布林、魔王… 这个异世界的神想要统一的管理这些种族,于是神打造了多个象征权力的戒指,分发给每个种族的首领——这个戒指可以帮助他们更…

【数据仓库与联机分析处理】数据仓库工具Hive
目录
一、Hive简介
(一)什么是Hive
(二)优缺点
(三)Hive架构原理
(四)Hive 和数据库比较
二、MySQL的安装配置
三、Hive的安装配置
1、下载安装包
2、解压并改名
3、配置环…

精彩回顾|VMware Explore大会Greenplum相关演讲视频
11月18日,VMware Explore 2022 中国线上大会圆满落下帷幕。在大会上,多场 Greenplum 主题演讲通过不同角度进行了产品的介绍以及技术的分享,内容丰富,干货满满。现在,通过这篇文章我们一起回顾一下本次大会演讲的精彩…
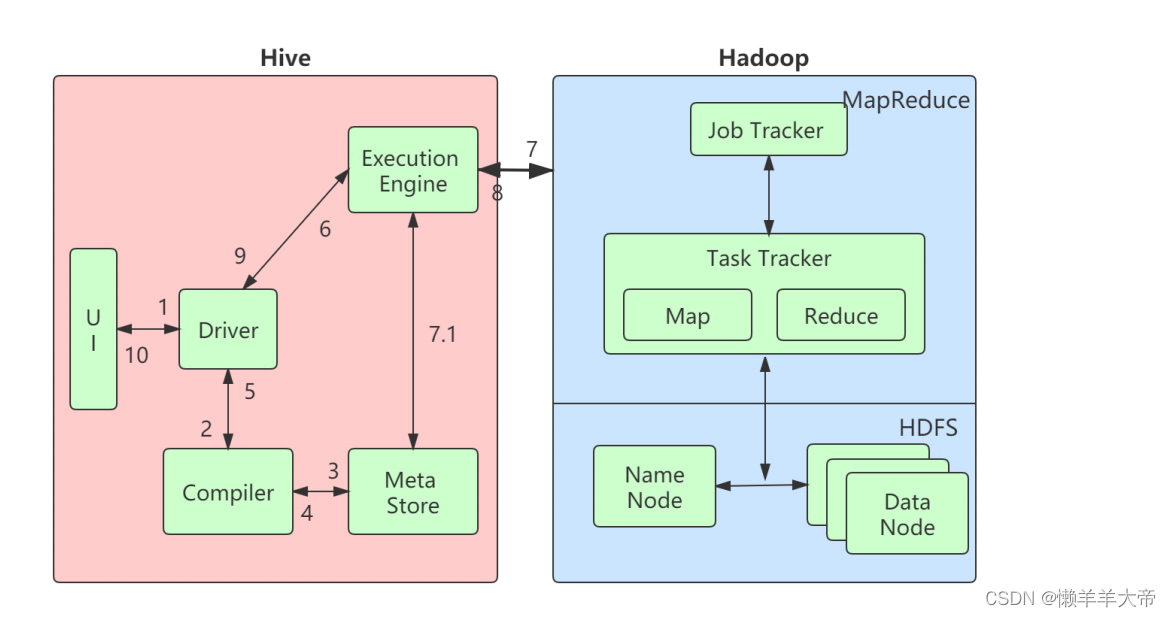
hive数据仓库--Hive介绍
1 什么是HiveHive是基于Hadoop的⼀个数据仓库⼯具,⽤来进⾏数据提取、转化、加载,这是⼀种可以存储、查询和分析存储在Hadoop中的⼤规模数据的机制。Hive数据仓库⼯具能将结构化的数据⽂件映射为⼀张数据库表,并提供类SQL的查询功能ÿ…
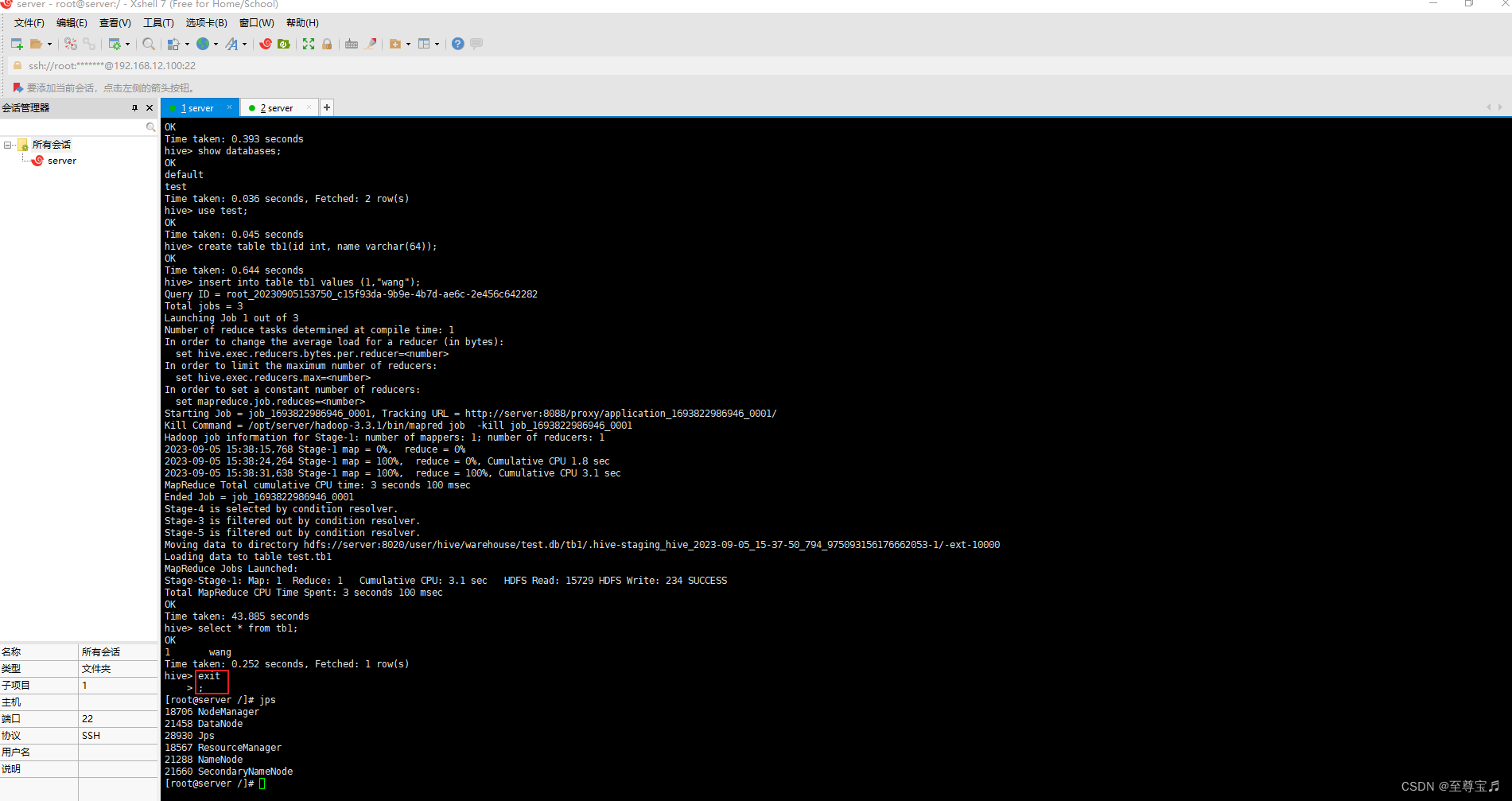
centos7上hive3.1.3安装及配置
1、安装背景;
hive是基于hadoop的数据仓库软件,部署运行在linux系统之上,安装之前必须保证hadoop环境运行正常,hive本身不是分布式软件,它的分布式主要是借助hadoop实现,存储是hdfs,计算是mapr…

大数据 Hive 数据仓库介绍
目录
一、数据仓库概念
二、场景案例:数据仓库为何而来?
2.1 操作型记录的保存
2.2 分析型决策的制定
2.3 OLTP 环境开展分析可行吗?
2.4 数据仓库的构建
三、数据仓库主要特征
3.1 面向主题性(Subject-Orient…

2024.1.2 Spark 简介,架构,环境部署,词频统计
目录 一. Spark简介
二 . Spark 框架模块
三. 环境准备
3.1 Spark Local模式搭建
3.2 通过Anaconda安装python3环境
3.3 PySpark库安装 四 . Spark集群模式架构介绍
五. pycharm远程开发环境 六. Spark词频统计 一. Spark简介 1. Spark 和MapReduce MR:大量的磁盘反复…

Iceberg学习笔记(1)—— 基础知识
Iceberg是一个面向海量数据分析场景的开放表格式(Table Format),其设计的目的是解决数据存储和计算引擎之间的适配的问题
表格式(Table Format)可以理解为元数据以及数据文件的一种组织方式,处于计算框架&…
数据治理-数据仓库环境
数据仓库环境包括一系列组织起来以满足企业需求的架构组件,从源系统流动到数据暂存区,数据可以在这里被清晰,当数据集成并存储在数据仓库或操作数据存储中时,可以对其进行补充丰富。在数据仓库中,可以通过数据集市或数…
免密码方式获取Hive元数据
前言
开发中可能用到hive的元数据信息 ,如获取hive表列表、hive表字段、hive表数据量大小、hive表文件大小等信息,要想获取hive元数据信息即需要hive元数据库的账号及密码,此次提供的是一种不需要hive元数据库密码及可获取元数据信息的方式&…

TPM管理工作应该如何开展?
在制造行业,Total Productive Maintenance(TPM)管理被广泛认为是提高生产效率和设备可靠性的有效方式。然而,实施TPM管理需要深入的专业知识和经验。本文将探讨如何开展TPM管理工作,以确保制造企业的生产效率和设备可靠…

【hive-解决】HiveAccessControlException Permission denied: CREATEFUNCTION
文章目录 一.任务描述二. 解决 一.任务描述 Error while compiling statement: FAILED: HiveAccessControlException Permission denied: Principal [nameroot, typeUSER] does not have following privileges for operation CREATEFUNCTION [ADMIN PRIVILEGE on INPUT, ADMIN…

SeaTunnel StarRocks 连接器的使用及原理介绍
作者:毕博,马蜂窝数据平台负责人,StarRocks 活跃贡献者 & Apache SeaTunnel 贡献者
Apache SeaTunnel(以下简称 SeaTunnel)是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步…
Excel-VLOOKUP函数
vlookup函数主要用于查找核对数据。VLOOKUP(lookup_value, table_array, col_index_num, range_look)上面参数的含义分别是:参数含义lookup_value用谁去找table_array匹配对象范围col_index_num返回第几列的值range_look匹配方式例子:想要在 H2 单元格中…
[Hive] Map类型在表中是如何存储的
在 Hive 中,Map 类型是指键值对的集合,其中键和值都可以是任意数据类型。
在 Hive 表中,Map 类型通常被存储为结构体或者键值对列表。
具体来说,在表中,Map 类型通常分为以下两种存储方式: 文章目录 结构…
Doris初识(01)
Doris初识 初识
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景…
数据仓库项目从来不是技术项目
数据仓库是什么?
还是得先从定义开始:数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。
这里的“支持决策”往往是面向分析的&#…
数据湖和数据仓库区别介绍
从数据仓库到数据湖
仓库和湖泊
仓库是人为提前建造好的,有货架,还有过道,并且还可以进一步为放置到货架的物品指定位置。 而湖泊是液态的,是不断变化的、没有固定形态的,基本上是没有结构的,湖泊可以是由…
Hive知识梳理(好文)
Hive是建立在 Hadoop 上的数据仓库基础构架。可以将SQL查询转换为MapReduce的job在Hadoop集群上执行。 元数据
Hive元数据信息存储在Hive MetaStore中,或者mysql中。 分隔符
Hive默认的分格符有三种,分别是(Ctrl/A)、࿰…

Hive学习 第二课 hive安装
第1步:验证JAVA安装
在Hive安装之前,Java必须在系统上已经安装。使用下面的命令来验证是否已经安装Java:
$ java –version
如果Java已经安装在系统上,就可以看到如下回应:
java version "1.7.0_71"
Ja…

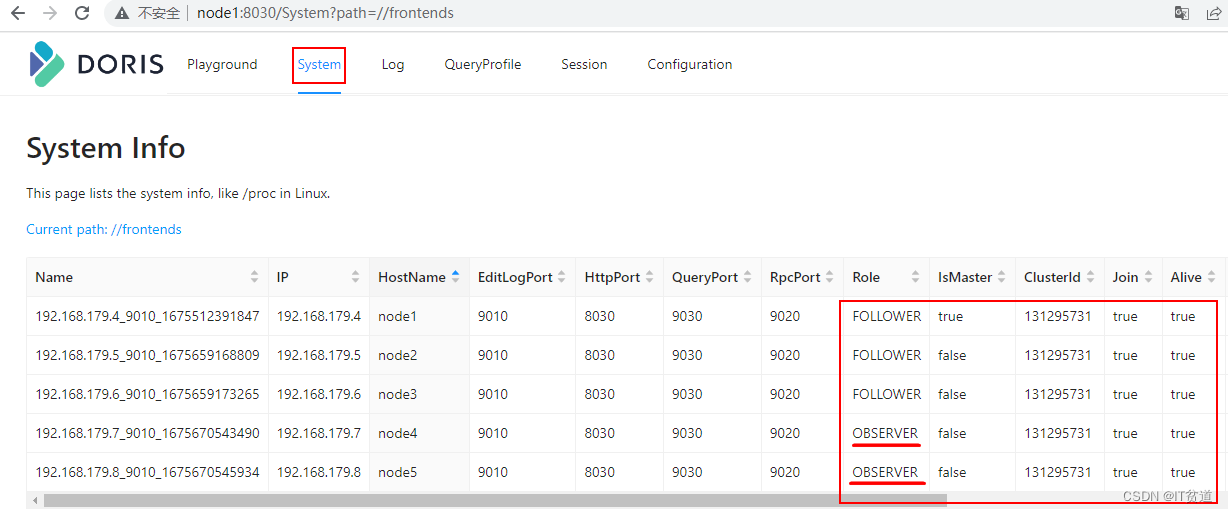
Apache Doris (五) :Doris分布式部署(二) FE扩缩容
目录
1. 通过MySQL客户端连接Doris
2. FE Follower扩缩容
3. FE Observer 扩缩容
4. FE扩缩容注意点 进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道&#…
卷王亲授,8个低门槛副业,适合普通人
这里写目录标题1. 卷王亲授,8个低门槛副业,适合普通人1.1. Plan A 传统升学考试打工1.2. Plan B 开公司、创业、小生意1.3. Level-1 摆地摊:打破社交恐惧1.4. Level-2 持续较久的副业1.5. Level-3 全职开店/全职自媒体1.6. Level-4 环节链路多…

如何做好企业数据治理?
过去两年,国家各部委纷纷出台针对全行业的数字化转型、数据要素等方面的政策。2019年,工信部提出:“将加强数据治理,扎实推进国家大数据发展战略”,将数据治理重要性上升到新的高度。作为数字化建设的基石,…
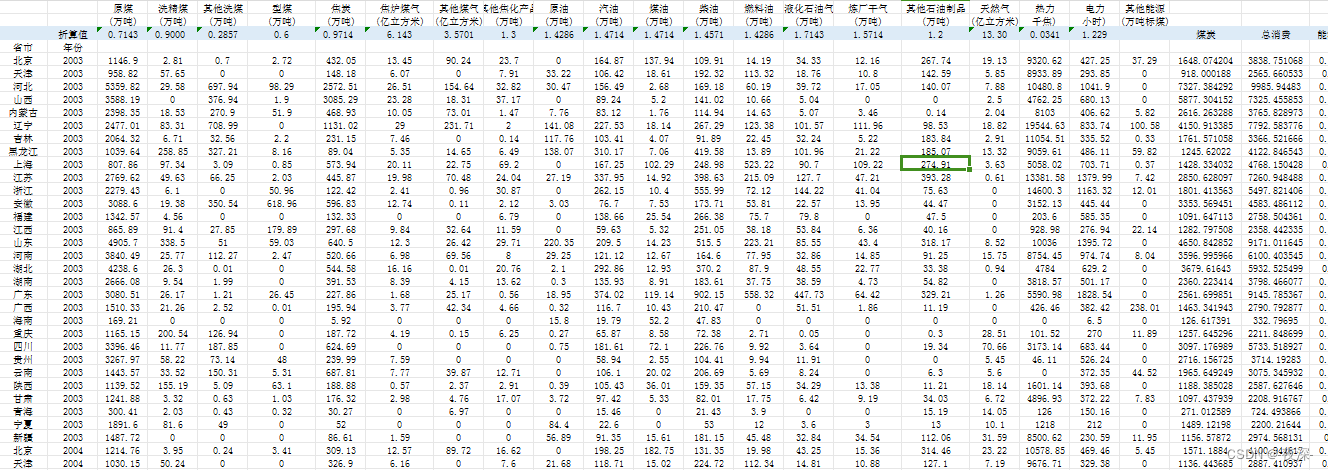
2003-2018年各省能源结构(煤炭占比)(含原始数据和计算过程)
2003-2018年各省能源结构(煤炭占比)(含原始数据和计算过程)
1、时间:2003-2018年
2、指标:原煤、洗精煤、其他洗煤、型煤、焦炭、焦炉煤气、其他煤气、其他焦化产品、原油、汽油、煤油、柴油、燃料油、液…
Greenplum5推出跨云能力,并与阿里云和腾讯云合作落地
Pivotal于本月隆重推出世界上第一个开源的大数据平台----Pivotal Greenplum5,帮助客户在私有云或公共云中进行出色的数据分析的云平台。 Greenplum可以在亚马逊AWS,微软Azure,谷歌云GCP,VMware vSphere和OpenStack等多种云平台上无…
火山引擎 ByteHouse:如何提升 18000 节点的 ClickHouse 可用性?
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 ClickHouse 是业内被广泛使用的 OLAP 引擎。当集群规模过大时,ClickHouse 则面临使用局限性的问题。如何提升 ClickHouse 的可用性,成为困扰…
小步快跑激活数据要素市场
数据是数字经济发展的核心,也是人工智能迭代发展的关键,对各行各业都会产生深远的影响,这是各国大力推动促进数据要素市场发展的主要原因。但客观来看,数据要素市场是一个极新的领域,而且对于数据要素市场的内涵&#…

3.完成ODS层数据采集操作
将原始数据导入mysql 1 选中mysql 运行脚本 2 验证结果 数据存储格式和压缩方案 存储格式 分类 1.行式存储(textFile) 缺点:可读性较好 执行 select * 效率比较高 缺点:耗费磁盘资源 执行 select 字段 效率比较低 2.列式存储(orc) 优点:节省磁盘空间. 执行 select 字段…

一条慢SQL引发的改造
前言闲鱼服务端在做数据库查询时,对每一条SQL都需要仔细优化,尽可能使延时更低,带给用户更好的体验。但是在生产中偶尔会有一些情况怎么优化都无法满足业务场景。本文通过对一条慢SQL的真实改造,介绍解决复杂查询的一种思路&#…
【数据中台建设系列之二】数据中台-数据采集
【数据中台建设系列之二】数据中台-数据采集 上篇文章介绍了数据中台的元数据管理,相信大家对元数据模块的设计和开发有了一定的了解,本编文章将介绍数据中台另一个重要的模块—数据采集。 一、什么是数据采集
数据采集简单来说就是从各种数据源中抓…

大数据可能是一场骗局
编者按:本文作者冯大辉,丁香园CTO,雷锋网特约撰稿人,想要联系的读者可以在微波Fenng。 几乎每天都能看到有人在谈论大数据,让人好生厌烦。什么是大数据(Big Data) ? 简单一点可以理解为超出传统数据管理工具处理能力的…

重磅!大数据知识总结和调参技巧开放下载了
大数据被誉为“新石油”,如何管理并洞悉数据的价值,是企业未来发展的核心竞争力。进入大数据时代,数据规模与日俱增。另一方面,数据仓库的市场份额被其他技术蚕食,比如大数据、机器学习和人工智能。这种趋势给我们造成…
读书笔记---蛤蟆先生去看心理医生
读书笔记---蛤蟆先生去看心理医生读后感作者:罗伯特-戴博德
读后感
这本书对我非常有用,让我豁然开朗。我也经历过自我否定的阶段,现在在寻找自我的路上~~~
文中的故事线多数是对话形式展开的࿰…
读书笔记--数据治理之术
继延续上一篇文章,对数据治理之术进行学习思考,这部分内容是本书整体内容的核心细节,内容比较多比较杂,通读了好长时间才动手总结整理,因此更新的慢了一些。数据治理之术是操作层面的技术或方法,数据治理相…
关于数据中台,这家外企的观点恰恰值得深思
数据中台并非舶来品,而是中国互联网巨头制造出来的概念。
事实上,在国内各行各业掀起一股所谓的数据中台热之际,国外用户却对之鲜有提及。但是,这并不代表国外市场对于数据价值不重视。恰恰相反,在欧美等数字化程度很…
Hive命令调优大全
– explain语法查询**
– explain解析执行计划
– 以下优化为hive层面优化,常开****
– 读取零拷贝 set hive.exec.orc.zerocopy=true; – 默认false – 关联优化器 set hive.optimize.correlation=true; – 默认false – fetch本地抓取 set hive.fetch.task.conversion=min…

【2021年新书推荐】Snowflake Cookbook
各位好,此账号的目的在于为各位想努力提升自己的程序员分享一些全球最新的技术类图书信息,今天带来的是2021年2月由Packt出版社最新出版的一本关于云数据仓库的书,涉及的平台为Snowflake。
Snowflake Cookbook 作者:Hamid Mahmoo…

用户管理系统 - 用户权限设计从入门到精通
用户管理是每个产品必备的管理后台,最基础的用户管理只要有账号增删这两个功能就够了。不过一旦用户开始增多,权限稍微复杂一些,我们就需要认真思考用户管理权限的逻辑问题。避免在未来用户突然增长时,埋下无法解决的深坑。
如果…
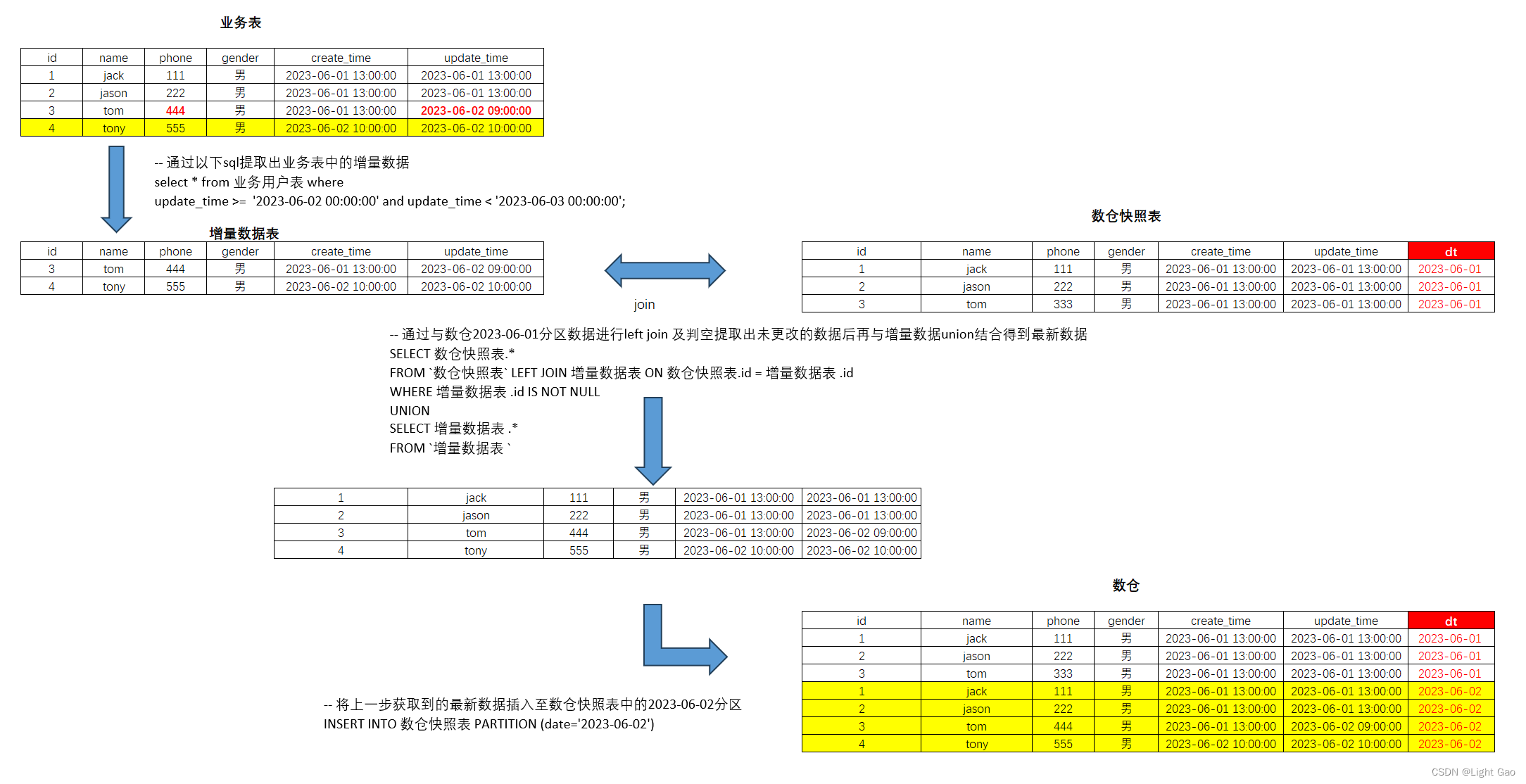
数仓日常维护:剖析每日增量同步的内部机制
数仓日常维护:剖析每日增量同步的内部机制
一、前言
在现代企业中,离线仓库扮演着不可或缺的角色。它充当着一个数据的中心枢纽,存储和管理着海量的信息。作为企业数据分析、业务决策和预测的基石,离线仓库的重要性不言而喻。
…

Hive内置表生成函数
Hive内置UDTF 1、UDF、UDAF、UDTF简介2、Hive内置UDTF 1、UDF、UDAF、UDTF简介 在Hive中,所有的运算符和用户定义函数,包括用户定义的和内置的,统称为UDF(User-Defined Functions)。如下图所示: UDF官方文档…
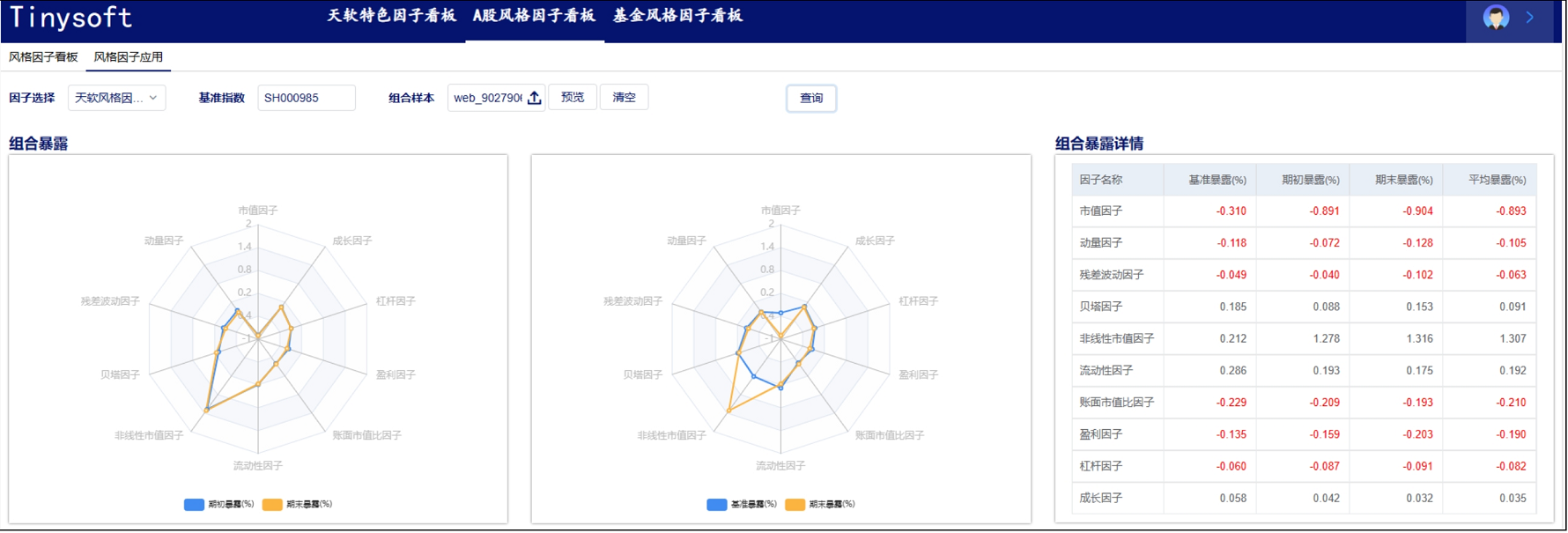
A股风格因子看板 (2023.09 第02期)
该因子看板跟踪A股风格因子,该因子主要解释沪深两市的市场收益、刻画市场风格趋势的系列风格因子,用以分析市场风格切换、组合风格暴 露等。 今日为该因子跟踪第02期,指数组合数据截止日2023-08-31,要点如下 近1年A股风格因子检验…
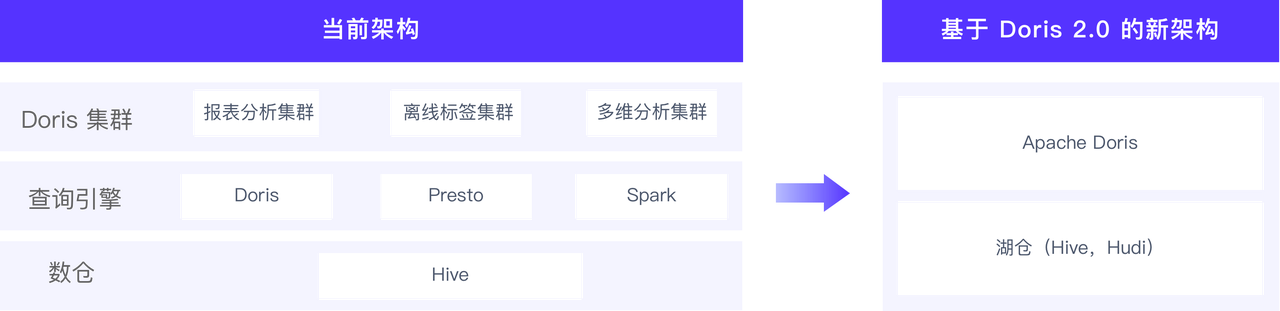
Apache Doris 在奇富科技的统一 OLAP 场景探索实践
导读:随着消费信贷规模快速增长,个人信贷市场呈现场景化、体验感强的特征,精准营销、精细化风险管理以及用户使用体验的优化愈发重要。作为中国卓越的由人工智能驱动的信贷科技服务平台,奇富科技选择将 Apache Doris 作为整体 OLA…
Doris 案例篇——长安汽车基于 Doris 的车联网数据分析平台建设实践
Doris 案例篇——长安汽车基于 Doris 的车联网数据分析平台建设实践
随着消费者更安全、更舒适、更便捷的驾驶体验需求不断增长,汽车智能化已成必然趋势。长安汽车智能化研究院作为长安汽车集团有限责任公司旗下的研发机构,专注于汽车智能化技术的创新与研究。为满足各业务部…

【Hive】——DML
1 Load(加载数据)
1.1 概述 1.2 语法
LOAD DATA [LOCAL] INPATH filepath [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1val1, partcol2val2 ...)]LOAD DATA [LOCAL] INPATH filepath [OVERWRITE] INTO TABLE tablename [PARTITION (partcol…

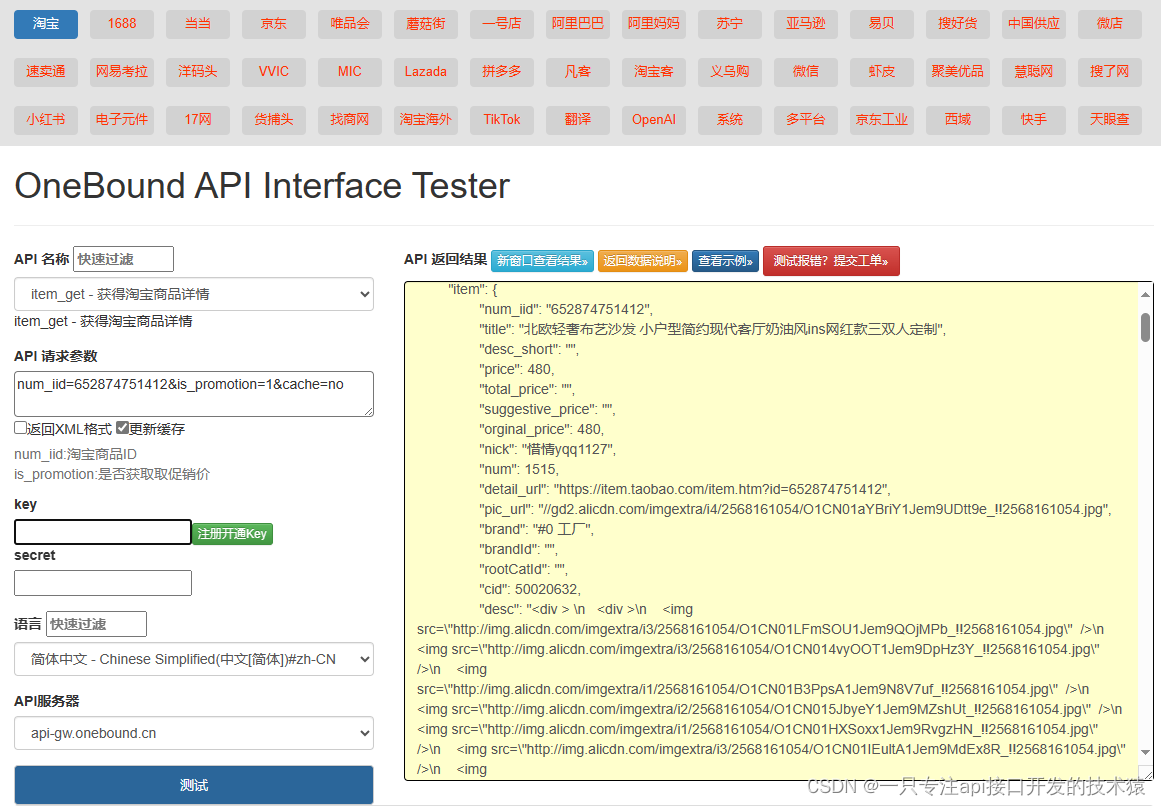
API接口如何接入电商平台获取商品实时数据,通过商品ID获取商品名称,主图,价格,颜色规格尺寸,库存,SKU等案例
要接入电商平台获取商品实时数据,您需要使用电商平台提供的API接口。以下是一般步骤:
注册电商平台账号并获取API权限:您需要在电商平台上注册一个账号,并申请API权限。在申请API权限时,您需要提供一些信息࿰…
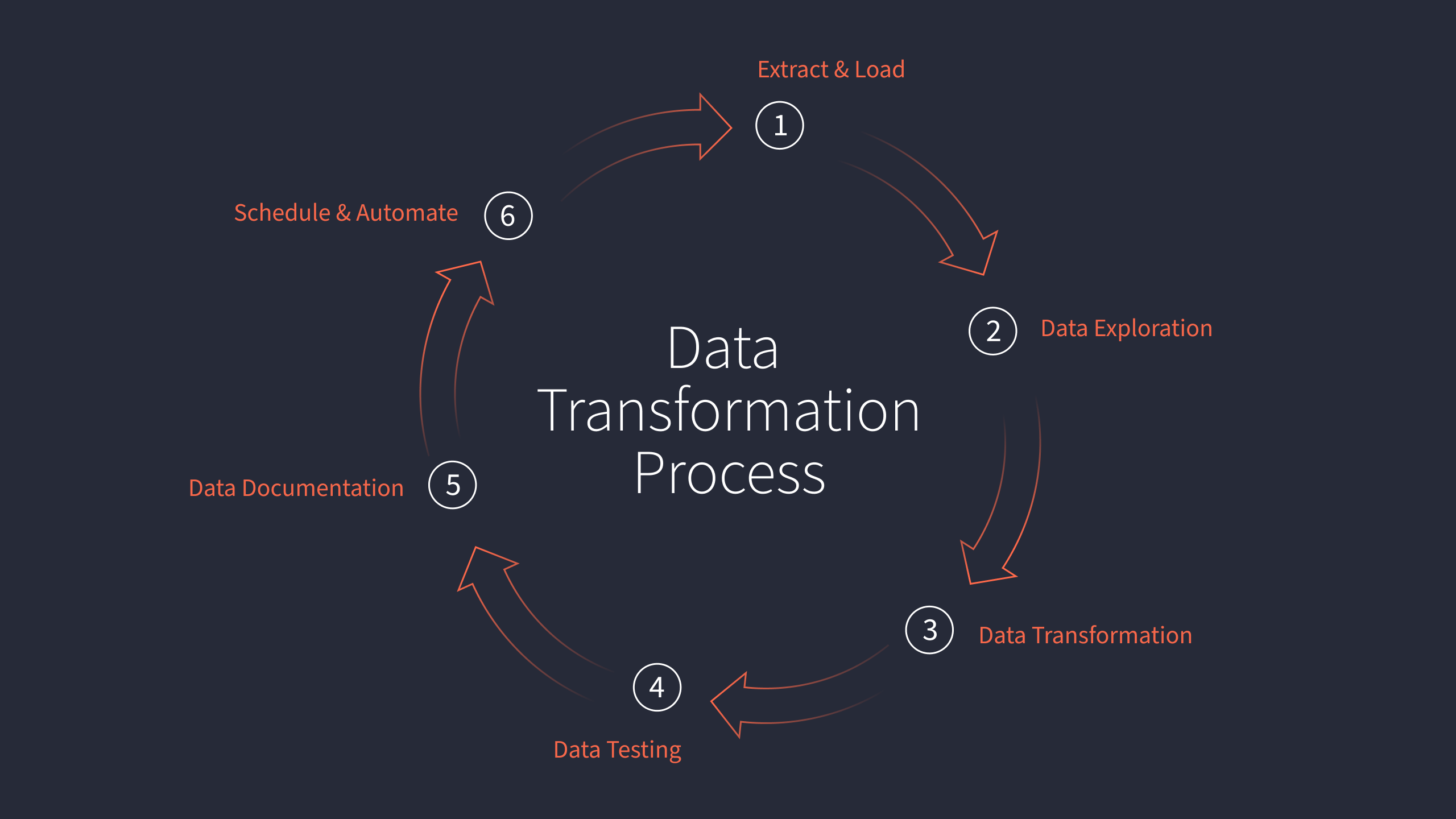
数据工程:ELT 工作流中的 6 个步骤
数据转换过程可以分为六个步骤:提取extraction和加载loading、探索exploration、转换transformation、测试testing、文档documentation和部署deployment。 数据转换是获取原始数据并从中获取意义的过程;它构成了所有分析工作的基础,并代表了数据从业者如…
数据仓库的 RDBMS 性能优化指南
全文请参考http://www.microsoft.com/china/technet/prodtechnol/sql/2000/maintain/c2061.asp

数据仓库-数仓优化小厂实践
一、背景 由于公司规模较小,大数据相关没有实现平台化,相关的架构都是原生的Apache组件,所以集群的维护和优化都需要人工的参与。根据自己的实践整理一些数仓相关的优化。
二、优化 1、简易架构图 2、ODS层优化 2.1 分段式解析 随着业务增长…

哪一些企业用户可以只用手机移动OA实现办公?
手机OA移动办公是协同办公的组成部分之一,重要性不容小觑。手机OA移动办公的优势,主要是:安装部署容易、操作高效便捷,因其无时间和地域限制,不同使用场景下可以与PC端办公互补。企业用什么样的OA进行协同办公…
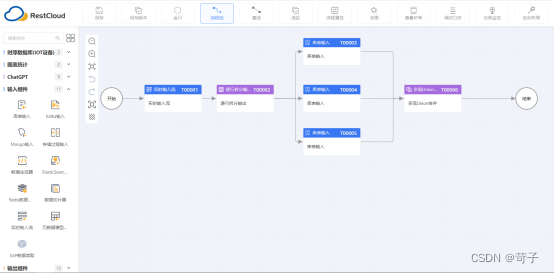
零代码ETL+聚水潭,实现销售出库单同步到数仓
一、聚水潭单据同步需求
聚水潭作为领先的电商ERP有很多快销、零售企业使用,同时作为以订单为核心的电商ERP系统企业还需要在本地配合其他业务系统一起使用完全整个业务的协同和财务结算,作为中大型企业随着业务发展企业会在聚水潭中沉淀大量的业务数据…
电子商务时代的CRM
电子商务时代的CRM 来自:sybase 日期:2002年05月15日 浏览次数:1435 引言 Internet的诞生爆发了一场信息和商业革命。它不仅被当作一个公共的、廉价的、快速的信息传送手段,同时随着各种分布式计算标准(例如CORBA&…
前台与后台,为什么要分离?
如果你经历过快速迭代业务,经历过用户量不断上涨,经历过访问并发越来越大,你一定会遇到以下系统问题:
用户访问页面越来越慢系统性能下降,数据库扛不住,连接数经常打满,最终数据库挂掉…
Hive / Presto 行转列 列转行
Hive / Presto 行转列 列转行 行转列1、Hive:2、Presto: 列转行Hive1、split将order_ids拆分成数组,lateral view explode将数组炸裂开 Presto1、split将order_ids拆分成数组,cross join unnest将数组炸裂开2、炸裂 map 行转列
…
企业信息化战略与实施(五) 练习题
第一题
商业智能是指利用数据挖掘、知识发现等技术分析和挖掘结构化的、面向特定领域的存储与数据仓库信息。它可以帮助用户认清发展趋势、获取决策支持并得出结论。以下(1)活动,并不属于商业智能范畴。
(1)A. 某大型…
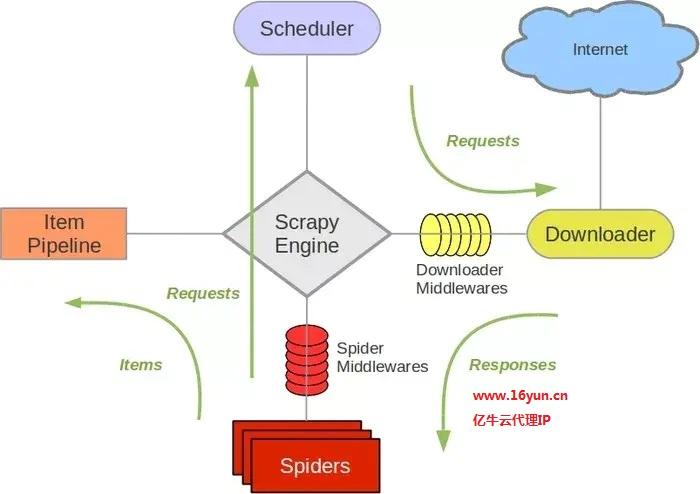
爬虫代理Scrapy框架详细介绍4
Scrapy 框架 Scrapy实例 下载安装 pip install scrapy Hello World 创建工程 在 cmd 下切换到想创建 scrapy 项目的地方,然后使用命名 scrapy startproject tutorial 注:tutorial 为工程名 然后就会发现在当前位置会多出一个文件夹,名字是 tu…

小型企业必备:工单管理系统的关键作用与优势
良好的客户体验是将刚接触的客户变成长期客户的关键。建立忠实的客户群是企业蓬勃发展的必备要素,所以企业必须随时能为客户提供满意的服务。
客户投诉可能会落入你的收件箱,也可能通过网络表单或电话进来,或者直接在社交媒体上传播。因此&a…
3、如何从0到1去建设数据仓库
1、数仓实施过程 1.1 数据调研 数据调研包括:业务调研、需求调研 业务调研 需要调研企业内有哪些业务线、业务线的业务是否还有相同点和差异点 各个业务线有哪些业务模块,每个模型下有哪些业务流程,每个流程下产生的数据 是怎样存储的 业务调…
关于数据仓库那点事,一文捋清
借助海量的数据,企业进行了深层次的数字化改革,把数据当成了企业发展的核心,但无效的数据即使规模再大,也对企业没有意义,所以数据质量也就愈发重要。
数据仓库
事实上,很多人在看到数据仓库的第一眼&…
数据仓库分层设计——分层定义
数据分层设计
数仓分层设计可以按照以下层次来划分:
数据源层(Source Layer):该层是数仓的数据来源,包含一些原始系统、外部数据源,这些数据需要进行ETL处理后才能被加载到数仓中。
数据提取层ÿ…
bigdata1234.cn 大数据开发基础课堂测试
数据容量单位: 1 byte 8 bits 1 kilobyte (KB) 1024 bytes 1 megabyte (MB) 1024 KB 1 gigabyte (GB) 1024 MB 1 terabyte (TB) 1024 GB 1 petabyte (PB) 1024 TB 1 exabyte (EB) 1024 PB 1 zettabyte (ZB) 1024 EB 1 yottabyte (YB) 1024 ZB
. 当前大数据…
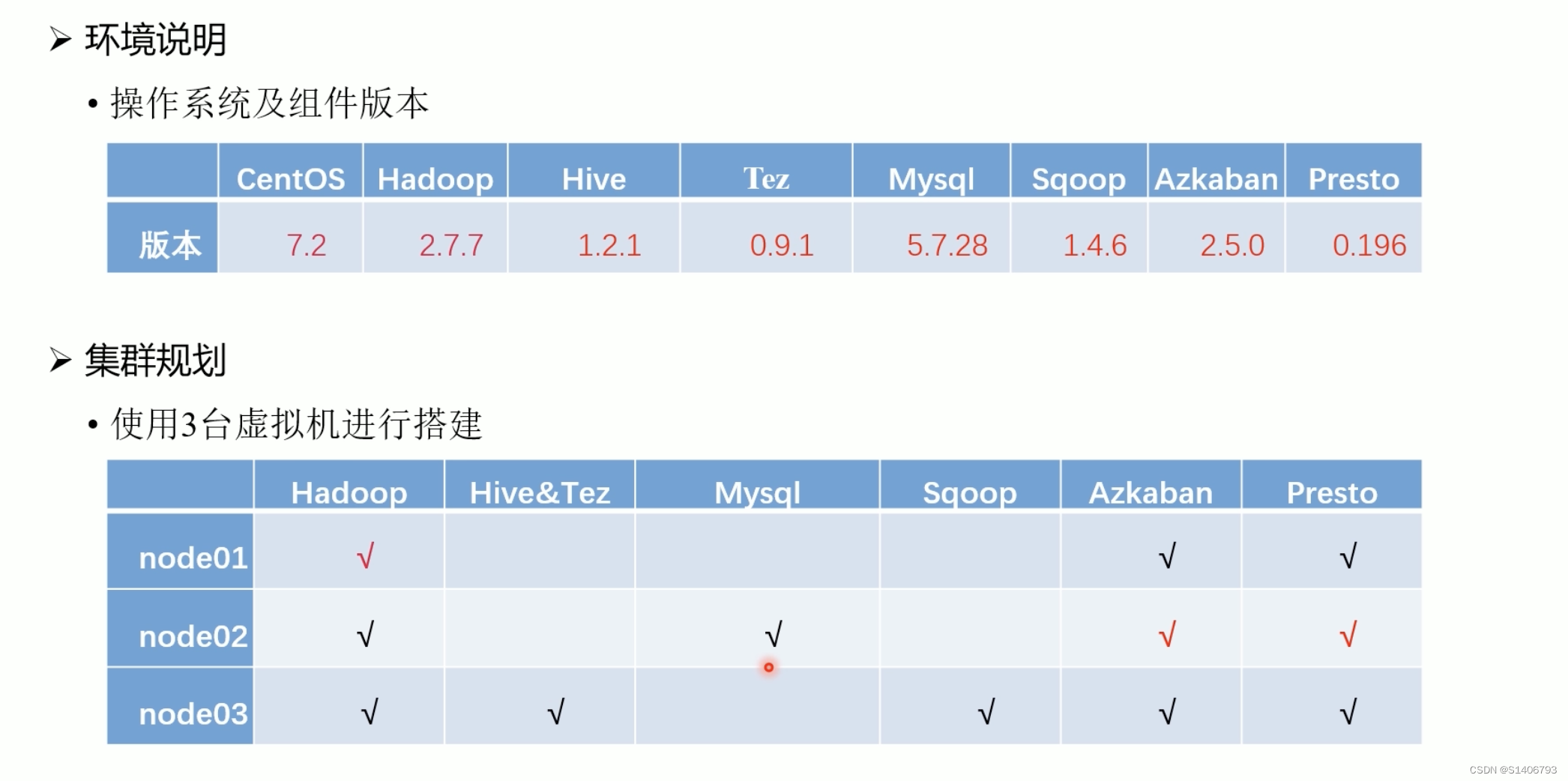
数据仓库——原理+实战(一)
一、数据仓库概述
1. 数据仓库诞生原因
(1)历史数据积存(存放在线上业务数据库中,当数据积压到一定程度会导致性能下降,所以需要将实用频率低的冷数据转移到数据仓库中)
(2)企业数…
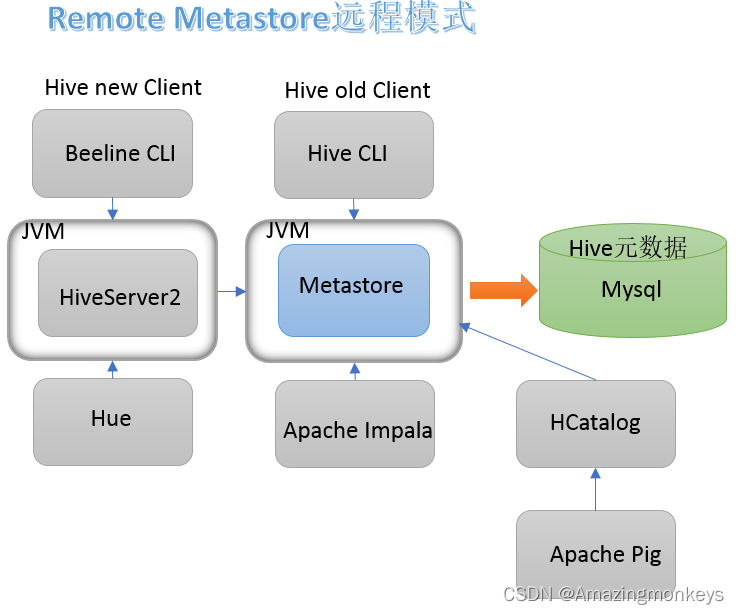
Hadoop 4:Hive
数据仓库概念 数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。 数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support&#x…

为什么是API而不是文件,对于数据中台的开放如此重要? by 傅一平
数据中台相对于数据仓库,最大的特征就是业务化,但业务化非常抽象,那么如何衡量数据中台的业务化水平呢?如何比较两个公司的数据中台水平高低呢?我有一个简单直接的方法,就是A和B公司列出对外开放的API的数量…

5分钟看懂:如何构建一个数据仓库?
实用干货来了!有朋友私信我,说希望了解数仓的整体建设中的细节及模板。那有啥说的,上干货!数仓全景图镇楼 00 建设过程 数仓建模的过程分为业务建模、领域建模、逻辑建模和物理建模,但是这 些步骤比较抽象。为了便于…
你的报表和别人家报表的区别
【与数据同行】已开通综合、数据仓库、数据分析、产品经理、数据治理及机器学习六大专业群,加微信号frank61822701 为好友后入群。新开招聘交流群,请关注【与数据同行】公众号,后台回复“招聘”后获得入群方法。正文开始前两天在微博吐槽了一…

【大数据】Doris 构建实时数仓落地方案详解(三):Doris 实时数仓设计
本系列包含:
Doris 构建实时数仓落地方案详解(一):实时数据仓库概述Doris 构建实时数仓落地方案详解(二):Doris 核心功能解读Doris 构建实时数仓落地方案详解(三)&#…
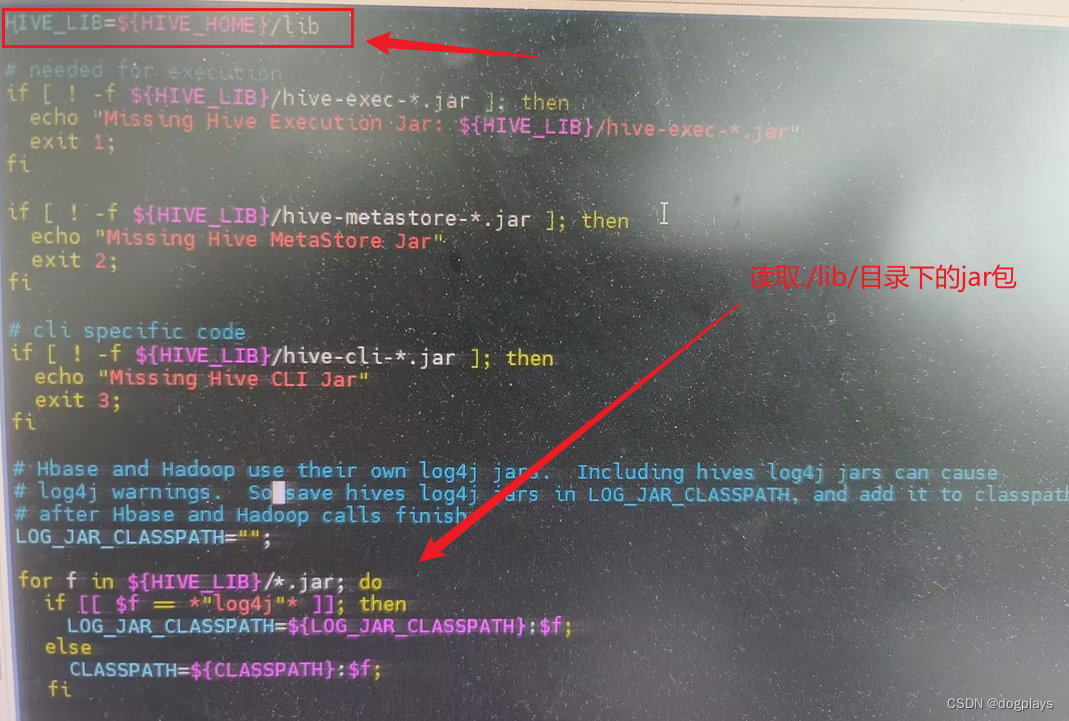
hive命令启动出现classnotfound
环境:ambari集群三个节点node104、node105和node106,其中node105上有hiveserver2,并且三个节点均有HIVE CLIENT
注意:“./”指hive安装目录 其中装有hiveserver2的node105节点,由于某种需要向lib目录下上传了某些jar包…

Hive精选10道面试题
1.Hive内部表和外部表的区别?
内部表的数据由Hive管理,外部表的数据不由Hive管理。 在Hive中删除内部表后,不仅会删除元数据还会删除存储数据, 在Hive中删除外部表后,只会删除元数据但不会删除存储数据。
内部表一旦…

为什么免费OA不能深入应用于企业?
免费OA(如钉钉)很大的存在价值在于:可以让用户熟悉OA软件,帮助企业积累信息化的经验,降低企业信息化过程中的风险和成本。在企业中实施协同办公OA不仅需要购买软件,而且更需要所有员工共同使用,…

《Kettle构建Hadoop ETL系统实践》大数据ETL开发工具选择Kettle的理由
ETL一词是Extract、Transform、Load三个英文单词的首字母缩写,中文意为抽取、转换、装载。ETL是建立数据仓库最重要的处理过程,也是最能体现工作量的环节,一般会占到整个数据仓库项目工作量的一半以上。建立一个数据仓库,就是要把…
clickhouse 系列1:clickhouse v21.7.5.29 源码编译
1.gcc10安装 安装依赖 yum update
yum install -y gcc gcc-c++
yum install -y bzip2 下载gcc 源码包并解压 wget -P /data/base https://mirrors.aliyun.com/gnu/gcc/gcc-10.2.0/gcc-10.2.0.tar.gz
cd /data/base && tar -xzvf /data/base/gcc-
SQL server 限制返回行数
撰写时间:2022 年 4 月 7日 SQL server 限制返回行数一、 SQL Server Select Top语句 Select top字句用于限制查询结果集中返回的行数或百分比。由于存储在表中的行的顺序是不可预测的,因此 SELECT TOP 语句始终与 ORDER BY 子句一起使用。 结果…
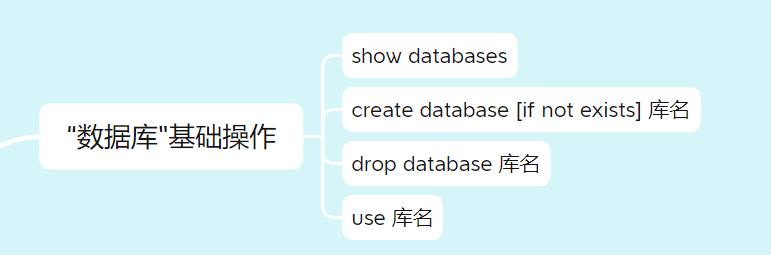
【MySQL数据库系列】一、认识数据库、建库建表操作
文章目录一、初识数据库二、MySQL基本数据类型三、MySQL基本逻辑运算符四、“数据库”的基本操作五、“表”的基本操作一、初识数据库
数据库:能更有效的管理数据,数据库可以提供远程服务,也就是说可以通过远程连接来使用数据库,…
SQL server 连接表
撰写时间:2022 年 4 月 17日 SQL server 连接表在关系数据库中,数据分布在多个逻辑表中。 要获得完整有意义的数据集,需要使用连接来查询这些表中的数据。SQL Server支持多种连接,包括 [内连接],[左连接],[…
商务智能(BI)的四大关键技术
商务智能的支撑技术主要包括ETL(数据的提取、转换与加载)技术和数据仓库与数据集市技术、OLAP技术、数据挖掘技术与数据的发布与表示技术。 1.数据仓库技术 实施BI首先要从企业内部和企业外部不同的数据源,如客户关系管理(CRM)、供应链管理(SCM)、企业资源规划(ER…
hive- 18~18区间找最晚批次
开始时间:14:20 15:20 16:20 17:20 19:20 计算【18,18)内的最晚时间 开始时间大于等于18点,开始时间减去18小时; 开始时间小于18点,开始时间加上(24-18)小时 select
from_unixtime(if(unix_timestamp(t0.start_…
亚马逊国际获得AMAZON商品详情 关键字搜索API 调用案例分享
item_get-获得AMAZON商品详情item_search-按关键字搜索商品公共参数名称类型必须描述keyString是调用key(获取测试key)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,item_search_s…

如何编写BI项目之ETL文档
XXXXBI项目之ETL文档 xxx项目组 ------------------------------------------------1---------------------------------------------------------------------- 目录 一 、ETL之概述 1、ETL是数据仓库建构/应用中的核心…


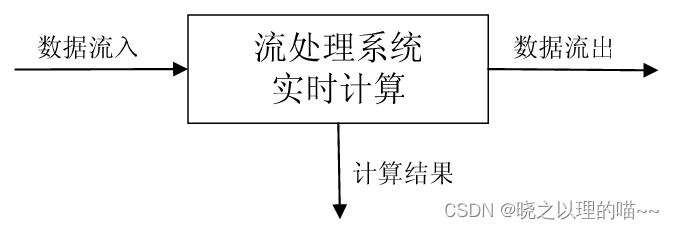
Spark Streaming基本概念
Spark Streaming是构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。Spark Streaming可结合批处理和交互式查询,因此,可以适用于一些需要对历史数据和实时数据进行结合分析的应用场景。 流计算是一种典型的大数据计算模式…
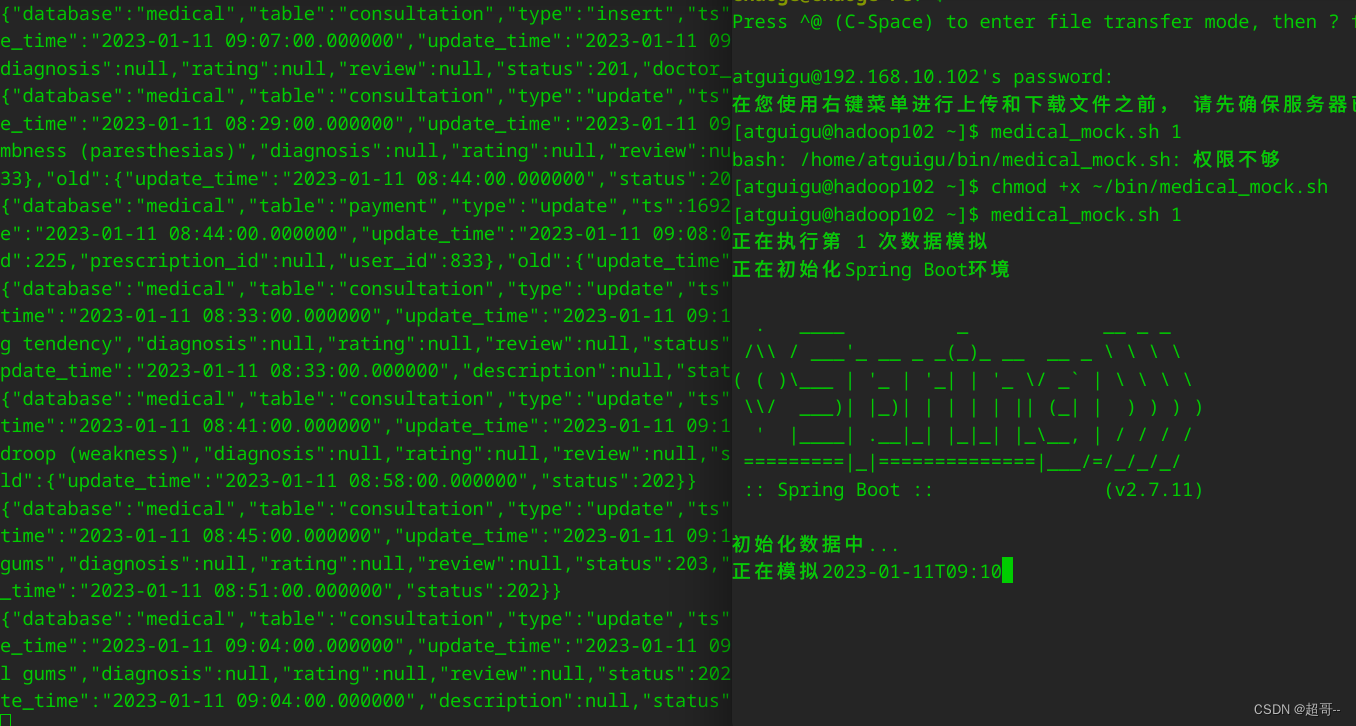
线上问诊:业务数据采集
系列文章目录
线上问诊:业务数据采集 文章目录 系列文章目录前言一、环境准备1.Hadoop2.Zookeeper3.Kafka4.Flume5.Mysql6.Maxwell 二、业务数据采集1.数据模拟2.采集通道 总结 前言
暑假躺了两个月,也没咋写博客,准备在开学前再做个项目找…
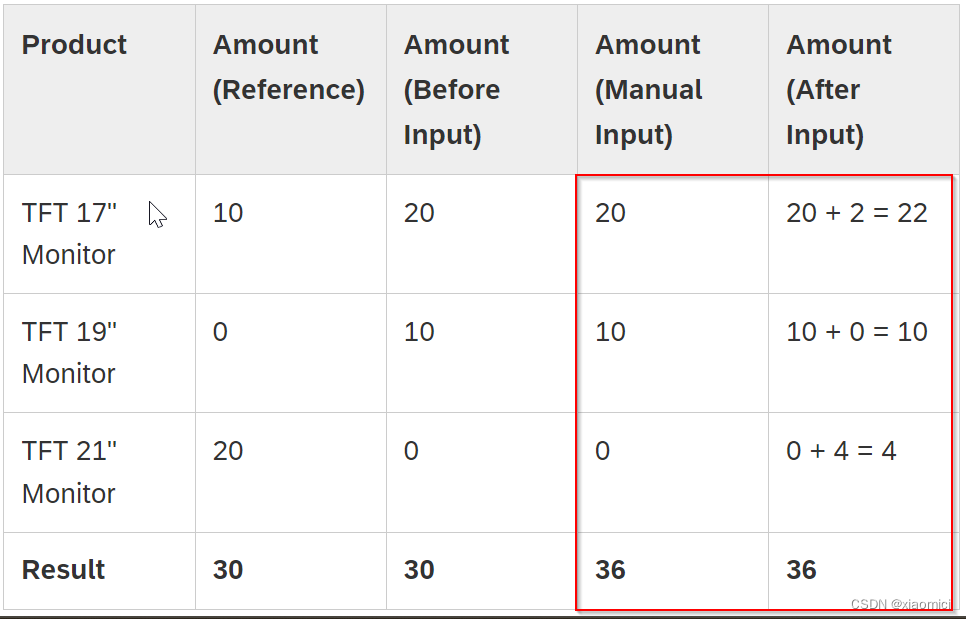
input-ready query
手动填计划值要用到的。
在query运行时通过手动输入值或者文本。可以更改或者增加新行。
目录
1. 什么是input-ready query
下钻到最底层
过滤到单一值
自动解集填充
2.解集
不使用解集:
解集输入的值:
平均分配:
模拟分配&#x…
2022年大型游乐设施操作考试试卷及大型游乐设施操作考试总结
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:2022年大型游乐设施操作考试试卷为正在备考大型游乐设施操作操作证的学员准备的理论考试专题,每个月更新的大型游乐设施操作考试总结祝您顺利通过大型游乐设施操作考试…
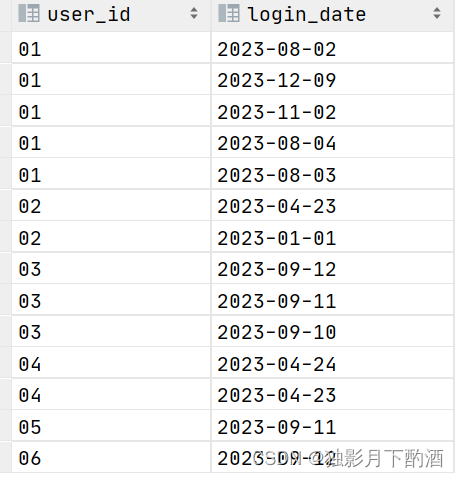
HQL解决连续三天登陆问题
1.背景
统计连续登录天数超过3天的用户,输出信息包括:用户id,登录天数,起始时间,结束时间;
2.准备数据
-- 建表
create table if not exists user_login_3days(user_id STRING,login_date date
);--插入…

Hive 之 管理表、外部表、分区表
欢迎大家扫码关注我的微信公众号: Hive 之 管理表、外部表、分区表一、 管理表(内部表):二、 外部表:三、 管理表与外部表转换:3.1 内转外:3.2 外传内:四、 分区表:4.1 …
数据仓库建模与ETL实践技巧
数据仓库建模与ETL实践技巧北京迈思奇科技有限公司 戴子良
专家简历
戴子良,北京迈思奇科技有限公司(www.minesage.com)咨询顾问,微软MCP,ETL专家,在数据仓库,数据清洗,数据整合和…
Hive操作命令上手手册
内容来自于《大数据Hive离线计算开发实战》 Hive原理
Hive是一个基于Hadoop的数据仓库和分析系统,用于管理和查询大型数据集。以下是Hive的原理:
数据仓库:Hive将结构化的数据文件映射成一张表,并提供类SQL查询功能。用户可以使…
基于OneData的数据仓库建设模型设计
1. 数据分层
业界对数仓分层的看法大同小异,大体上认为分为接入层、中间层和应用层三层,不过对中间层的理解有些差异。
2. 接入层(ods)
业务数据一般是采用dataX或者sqoop等以固定频率同步到数仓中构建ODS层;
如果是日志数据则通过flume或…


Hive集群高可用配置与impala集群高可用配置
Hive 高可用配置与impala高可用
1. HiveServer2高可用及Metastore高可用
使用Zookeeper实现了HiveServer2的HA功能(ZooKeeper Service Discovery),Client端可以通过指定一个nameSpace来连接HiveServer2,而不是指定某一个host和p…

数据仓库层Repository(CrudRepository、PagingAndSortingRepository、JpaRepository)
什么是数据仓库层Repository?
数据仓库接口的作用:Repository原意指的是仓库,即数据仓库的意思。Repository居于业务层和数据层之间,将两者隔离开来,在它的内部封装了数据查询和存储的逻辑。 Repository接口ÿ…
JACKRABBIT入门(1)
代码示例
import org.apache.jackrabbit.commons.JcrUtils;
import org.apache.jackrabbit.core.RepositoryImpl;
import org.apache.jackrabbit.core.config.RepositoryConfig;
import org.apache.log4j.Logger;import javax.jcr.*;
import java.net.URL;public class FiveHo…

内推|香港外企急招ETL工程师!数据分析师+Python开发+运营专家
2月已过半还在找工作?快来看看有没有适合你的岗位!01公司:友邦科技 工作地点:成都市高新区OCG国际中心招聘岗位:ETL工程师 15-18k该岗位为香港项目,需要有数仓或者大数据经验。本科IT或数据相关专业&#…

企业数字化管理中,数据治理到底怎么“治”
随着信息化、数字化的理念、技术及其应用在社会的方方面面进行扩散,数据的规模和丰富程度已经达到了一个新的高度,所以当下如何更进一步利用好数据,充分发挥数据的价值,将其真正变为高质量的数据资产成为了企业要面对的重要问题&a…

全景天窗式科普数据仓库
数据仓库是一个面向主题的、集成的、随时间变化但信息本身相对稳定的数据集合,用于支持管理决策过程。其本质就是完成从面向业务过程数据的组织管理到面向业务分析数据的组织和管理的转变过程,也是商业智能BI中数据仓库的主要作用。 数据仓库 - 派可数据…

分析型数据库:分布式分析型数据库
分析型数据库的另外一个发展方向就是以分布式技术来代替MPP的并行计算,一方面分布式技术比MPP有更好的可扩展性,对底层的异构软硬件支持度更好,可以解决MPP数据库的几个关键架构问题。本文介绍分布式分析型数据库。 — 背景介绍—
目前在分布…
Hive面试题系列第四题-Pv累加趋势图问题
视频讲解地址:https://www.bilibili.com/video/BV1L14y1b7Ur/?spm_id_from333.788&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第四题-pv累加趋势图问题 题目:求每个用户截止到每月月底(累计到该月)的总访问…
大数据系列——Hive理论
概述
Hive是一个数据仓库管理工具,将结构化的数据文件映射为一张数据库表,并提供类SQL(HQL)查询功能。由Facebook实现并开源,最后捐赠给Apache发展为顶级项目。
以RDBMS数据库为元数据存储服务,
以Hadoop HDFS来存储…
SCRM系统可以帮助企业实现哪些方面的目标?
SCRM系统是指基于“以用户为中心”的数据价值实现体系,旨在帮助企业与用户建立更加紧密的联系,提供更加个性化的服务。根据提供的文章和信息,SCRM系统可以帮助企业实现以下方面的目标:
从企业为中心到“用户为中心”的转变。SCRM…
10倍性能优势!TDengine在云洋物联智慧农业业务中替代MongoDB
作者介绍
叶红伟,北京云洋物联技术有限公司软件研发经理,主要从事智慧农业平台开发及应用,负责平台的架构设计以及主要业务代码开发工作。
关于云洋物联
作为国内领先的数字农业产品与解决方案服务商,云洋物联自成立以来便始终…
数据仓库之建模理论以及仓库设计思想
1、数据仓库
1.1、数据仓库概述
数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数…

BI、大数据、数据中台三者关系,搞不懂的看看这篇文章
大数据、数据中台都是商业智能BI发展到一定阶段的产物,核心都是围绕数据,数据采集、数据处理能力、算力的提升催生了大数据,数据资产和数据服务催生了数据中台,核心的数仓建模自商业智能BI一脉相承未曾改变,最终出口还…

ACDC:开箱即用的多租户数据集成平台
ACDC 是什么?
ACDC 的由来
新东方的一些核心业务存在单元写、中心入仓的场景,因此需要将数据从各单元的关系型数据库同步到中心,并异构存储到数据仓库之中。
技术团队最初使用 Apache Sqoop 以批的方式实现了这个能力。随着数据量的增长&a…
Hive之set参数大全-8
指定LLAP(Low Latency Analytical Processing)的执行模式
hive.llap.execution.mode 是Apache Hive中的一个配置属性,用于指定LLAP(Low Latency Analytical Processing)的执行模式。该属性用于决定Hive查询是否使用LL…

Hive的几个重要表
1.metastore数据库的DBS表
包含各表存储信息等 2.metastore数据库的TBLS表
包含各表是否是外部表等 3.metastore数据库的TABLE_PARAMS表
查看numFiles、numRows
(1)如果是刚建表,numFiles、numRows都为0;
(2&…
基于数据湖的多流拼接方案-HUDI实操篇
目录
一、前情提要
二、代码Demo
(一)多写问题
(二)如果要两个流写一个表,这种情况怎么处理? (三)测试结果
三、后序 一、前情提要
基于数据湖对两条实时流进行拼接࿰…
【论文翻译】使用变更数据捕获方法通过提取-转换-加载过程实时更新数据仓库
Real Time Data Warehouse Updates Through Extraction-Transformation-Loading Process Using Change Data Capture Method DOI目录1 介绍2 相关工作2.1 现有系统当前变化数据捕获方法3 方法/建议的系统3.1 时间戳3.2 使用时间戳修改日期3.3 Attunity 工具复制3.4 使用增量负载…
java和大数据开发该选择哪个好就业?
java开发和大数据开发无疑都是当前很热门的语言,很多小伙伴在选择方向的时候也是难以取舍~ 其实无论选择哪个语言作为工作的语言,都是要看你个人的兴趣点和未来想发展的方向的~下面给你列举下两个岗位的发展前景以及岗位,就可以根据自己的兴趣…
数据湖与数据仓库的根本区别,在于前者是“市场经济”,而后者是“计划经济”...
这是傅一平的第356篇原创【与数据同行】已开通综合、数据仓库、数据分析、产品经理、数据治理及机器学习六大专业群,加微信号frank61822702 为好友后入群。新开招聘交流群,请关注【与数据同行】公众号,后台回复“招聘”后获得入群方法。正文开…
【hive】报错累积
6.1 创建新表 错误1:FAILED: SemanticException [Error 10006]: Line 1:63 Partition not found "20210919" 场景:在创建例行表时,报错。这种情况是先创建了多级分区表(date,product),…

论文学习——水文时间序列相似性查询的分析与研究
文章目录1 摘要2 引言3 问题描述4 理论方法5 基于特征点的分段线性表示5.1 分段线性表示5.2 特征点的定义6 时间序列的相似性度量6.1 动态模式匹配距离(DPM)6.2 算法步骤6.3 本文采用的模式距离7 实验分析7.1 数据预处理7.2 模式表示7.3 步骤描述8 小结写在前面:《水…

ETL工具-pentaho企业实战部署
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…
Hive 建表语句解析
前言
在上篇文章《Hive 浅谈DDL语法》中我留了一个小尾巴,今天来还债了,为大家详细介绍一下Hive的建表语句。
建表语句解析
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)</…
数字化时代,探寻BI本质与发展趋势
可能和很多人想象的不同,商业智能BI虽然是信息化、数字化领域内的重要的数据类技术解决方案,但是商业智能BI并不是在当前时代突然冒出来的新应用,而是经过数十年积累的成熟产品。
早在1958年,IBM研究员就将商业智能BI的早期形态定…

【数据湖仓架构】数据湖和仓库:Databricks 和 Snowflake
是时候将数据分析迁移到云端了。我们比较了 Databricks 和 Snowflake,以评估基于数据湖和基于数据仓库的解决方案之间的差异。 在这篇文章中,我们将介绍基于数据仓库和基于数据湖的云大数据解决方案之间的区别。我们通过比较多种云环境中可用的两种流行技…
Hive ---- 分区表和分桶表
Hive ---- 分区表和分桶表 1. 分区表1. 分区表基本语法2. 二级分区表3. 动态分区 2. 分桶表1. 分桶表基本语法2. 分桶排序表 1. 分区表
Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中…
从7天到1天,Kyligence 和亚马逊云科技助力欣和提高数据应用价值
当今,各行业数字化转型大势所趋。但是,庞大的数据、信息孤岛和复杂的运维,都成为了企业数字化转型道路上的绊脚石。如何拨开这些障碍,实现高效的数字化转型并为业务增长提供助力,是摆在企业面前的紧迫难题。 烟台欣和企…
如何打造BI数据中台
在数字化时代,数据已成为企业的重要资产之一,但如何高效地利用数据仍然是一项挑战。在这个过程中,数据中台显得尤为重要。那么,什么是数据中台? 数据中台的概念最早由淘宝提出,是指企业将所有的业务数据进行归集、存储…

【数据管理架构】OLAP 与 OLTP:有什么区别?
这些术语经常相互混淆,那么它们的主要区别是什么?您如何根据自己的情况选择合适的术语? 我们生活在一个数据驱动的时代,使用数据做出更明智决策并更快响应不断变化的需求的组织更有可能脱颖而出。您可以在新的服务产品(…
中国最容易和最难被GPT所代替的TOP25职业!
OpenAI 研究人员曾发文称「约 80% 美国人的工作将被 AI 影响」。
文章的结论是,至少80%的美国劳动力会受到影响,他们的工作的10%会被GPT所替代。其中甚至有19%的美国劳动力的50%工作会被替代。
但需要注意的是,OpenAI的研究是对于美国职业来…

Hive 之 查询 02-join 语句
欢迎大家扫码关注我的微信公众号: Hive 之 查询 02-join 语句一、 只支持等值 join二、 表的别名三、 内连接四、 左外连接五、 右外连接六、 满外连接八、 笛卡尔积九、 连接谓词中不支持 or一、 只支持等值 join
Hive 支持通常的 SQL JOIN 语句, 但是…


数据湖还没玩明白,就别想着湖仓一体了! by 傅一平
数据湖的热还没褪去,湖仓一体就被炒起来了,有人问要不要入局湖仓一体,我的观点:先把自家的数据湖玩明白了再说吧,事实上,大多数的数据湖用得名不副实,更别提湖仓一体了。为什么这么说呢…

DBT构建和部署机器学习模型预测订单退货
DBT构建和部署机器学习模型预测订单退货 DBT构建和部署机器学习模型预测订单退货 DBT构建和部署机器学习模型预测订单退货 DBT构建和部署机器学习模型预测订单退货 DBT构建和部署机器学习模型预测订单退货 DBT构建和部署机器学习模型预测订单退货 DBT构建和部署机器学习模型预测…
数据治理目标 -必考
目标和原则数据治理的目标是使组织能够将数据作为资产进行管理。数据治理提供治理原则、制度、流程、整体框架、管理指标,监督数据资产管理,并指导数据管理过程中各层级的活动。为达到整体目标,数据治理程序必须包括以下几个方面。࿰…

常用的hive sql
细节:sql 中有涉及到正则匹配函数的,要注意转义符号 因为在不同语言下正则匹配规则是否需要加转义符号是不同的,举例,regexp_replace 函数,在hive sql的正则匹配规则的 \d 需要前面给它加上转义符号\,而在j…
关于rollup和cube等高级函数
Oracle提供了很多高级的统计函数,如rollup、cube、grouping、grouping sets,同时在数据库层还提供了维、立方等对象,可以通过定义维和立方实现查询重写,提高数据仓库的 select 批次号,种类,单位类型,sum(金额),count(1) from 数据…
Hive表操作及管理
转载请注明出处:http://blog.csdn.net/u012842205/article/details/72765667Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。…
HIVE 复制行n次直到某一列等于200
例如需要复制tmp_1表n次,每复制一次,gday1,直到gday200,
借助 lateral view posexplode,首先用space复制多个空格字符串,复制次数200-gday
然后split将字符串分割成数组,此时该数组大小为200-gday
然后l…

数据中台是什么,不是什么,就这么拨乱反正吧 by 傅一平
现在讲数据中台跟数据仓库、数据湖、数据平台等区别的文章很多了,新人与老人看了这些文章后,对于数据中台的态度往往是不一样的。数据新手更愿意接受数据中台这个新概念,但由于缺乏实践,往往抓不住本质,特别容易将其与…

鹏城,我们来啦!“Greenplum走进深圳” 火热报名中
在激烈的数字化市场竞争中,众多企业都迫切需要一个可靠稳定、灵活易用、高性能的数据仓库解决方案,支持企业数据分析战略,提升业务的敏捷性。 与此同时,被广泛应用于数据仓库领域的Greenplum平台,正在凭借其优秀的数据…
【Hive基础】-- Hive Catalog
目录
1.介绍
1.1 什么是 Hive Catalog
1.2 Hive Catalog 的作用
2.Hive Catalog 的基础知识
2.1 Hive Catalog 的类型

到底什么是数据湖?全面解读数据湖的缘起、特征、技术、案例和趋势
正文开始本文有1.5万字,预计阅读30分钟,可以先收藏数据湖近几年迅速蹿红,今天笔者做一个综述,包括数据湖的缘起、数据湖的定义、数据湖的特征、数据湖的技术、数据湖的趋势和数据湖的案例六大部分,如果你要入门数据湖&…
大数据项目之数仓相关知识
第1章 数据仓库概念
数据仓库(DW): 为企业指定决策,提供数据支持的,帮助企业,改进业务流程,提高产品质量等。
DW的输入数据通常包括:业务数据,用户行为数据和爬虫数据等 ODS: 数据…
如何基于DataWorks构建数据中台?
【提醒:公众号推送规则变了,如果您想及时收到推送,麻烦右下角点个在看,或者把本号置顶】正文开始阿里妹导读:为了应对众多业务部门千变万化的数据需求和高时效性的要求,阿里巴巴首次提出了数据中台的概念&a…
除了报表和取数,我还有多少大数据应用的机会呢?
正文开始最近有读者问了一个很好的问题:“大鱼先生,我们企业已经从0到1建立了数据仓库,应该怎么样才能更好地做好整个数据产品从0到1的规划和工作呢?”“现在日常的主要工作是报表、提数和数据稽核工作,我这边的初步想…

2023版最新最强大数据面试宝典
此套面试题来自于各大厂的真实面试题及常问的知识点,如果能理解吃透这些问题,你的大数据能力将会大大提升,进入大厂指日可待!目前已经更新到第4版,广受好评!复习大数据面试题,看这一套就够了&am…
企业为什么需要数据可视化报表
数据可视化报表是在商业环境、市场环境已经改变之后,发展出来为当前企业提供替代解决办法的重要方案。而且信息化、数字化时代,很多企业已经进行了初步的信息化建设,沉淀了大量业务数据,这些数据作为企业的资产,是需要…
hive left join 字段不一致
两个hive表left join时,由于关联字段类型不同导致的数据错误(bigint、string),结果会多出来一批数据。
select a.id as id1
,b.id as id2
from table1 a
left join table2 b
on a.id b.id
where a.id 1257829907772824682
-- 1…

离线和实时数仓技术架构梳理
1.离线数仓
离线数仓架构基本都是基于 Hive进行构建,数据分层方式如下: ODS Operational Data store,贴源层(原始数据层) 从各个业务系统、数据库或消息队列采集的原始数据,只做简单处理,尽可能…
商业智能BI中的OLAP是什么
人们在谈商业智能(BI)时,经常会提到OLAP,有的人可能认为OLAP工具就是BI。其实OLAP仅是BI的一部分,是很重要的一项分析技术。那什么是OLAP呢?
OLAP(Online analytical processing)&a…

直播内容精华:Greenplum 分布式数据库内核揭秘
3月16日,和示说社区合作,Greenplum中文社区开展了新年第一场直播活动,在直播中,原厂内核工程师李正龙进行了《Greenplum分布式数据库内核揭秘》主题演讲。介绍了将 PostgreSQL 改造成 MPP 数据库所涉及的主要工作。 相关视频已上…
现代数据栈MDS应用落地介绍—MozartData数据驱动从未如此简单
Dazdata MDS
Mozart Data创立于2020 年,已成功为 Clover Health、Eaze、Opendoor 和 Yammer 等高增长初创企业构建和实施数据管道和工具,是用于集中、组织和分析数据的一体化现代数据平台。
背景
随着公司跨部门积累更多数据——用户资料、订单详…

大数据之数据治理架构 —— Atlas
文章目录什么是数据治理?什么是 Atlas?Atlas 的作用Atlas 架构Atlas 架构解析Atlas 大数据集群搭建JDK 与 Hadoop 搭建MySQL 与 Hive 搭建Zookeeper 与 HBase 搭建Kafka 搭建Solr 搭建Atlas 搭建与集成Atlas 启动Hive 元数据导入Atlas 模拟生成血缘依赖什么是数据治…

到底什么叫作数据集成?
?作者丨石秀峰全文共2956个字,建议阅读需12分钟笔者08年就开始参与企业应用集成项目建设,经历了点对点数据集成、总线式数据集成、离线批量数据集成,流式数据集成等数据集成方式。所以,没有人比我更了解数据集成。数据…
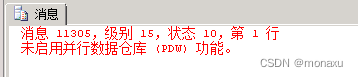
在Microsoft SQL Server 2008中,语法生成错误“并行数据仓库(PDW)功能未启用“
案例:
原表有两列,分别为月份、月份销售额,而需要一条 SQL 语句实现统计出每个月份以及当前月以前月份销售额和 sql 测试数据准备: DECLARE Temp Table
( monthNo INT, --- 月份 MoneyData Float --- 金额
) insert INTO TEM…
SQL - limit
介绍:
limit 是限制的意思, 用于限制返回的查询结果的行数(可以通过limit指定查询多少行数据). MySQL支持limit语法, 用来完成分页.
用法:
select 字段1, 字段2, ...
from table_name
limit offset, length;参数说明:
offset: 起始行数, 从0开始计数, 如果省略, 则默认为…
网易实时数仓实践与展望
【与数据同行】已开通综合、数据仓库、数据分析、产品经理、数据治理及机器学习六大专业群,加微信号frank61822701 为好友后入群。新开招聘交流群,请关注【与数据同行】公众号,后台回复“招聘”后获得入群方法。正文开始分享嘉宾:…
如何有效设计业务指标体系?
【与数据同行】已开通综合、数据仓库、数据分析、产品经理、数据治理及机器学习六大专业群,加微信号frank61822702 为好友后入群。新开招聘交流群,请关注【与数据同行】公众号,后台回复“招聘”后获得入群方法。正文开始在很多的工作场景中&a…
Oracle9i的物理内存管理
在Oracle9i以前的版本中,你只能在启动数据库的时候控制Oracle使用的UNIX内存。Oracle提供了一些INIT.ORA参数来检测系统全局区(system global area,SGA)的RAM大小。一旦启动了数据库,你将不能再改变SGA的大小和配置。 …
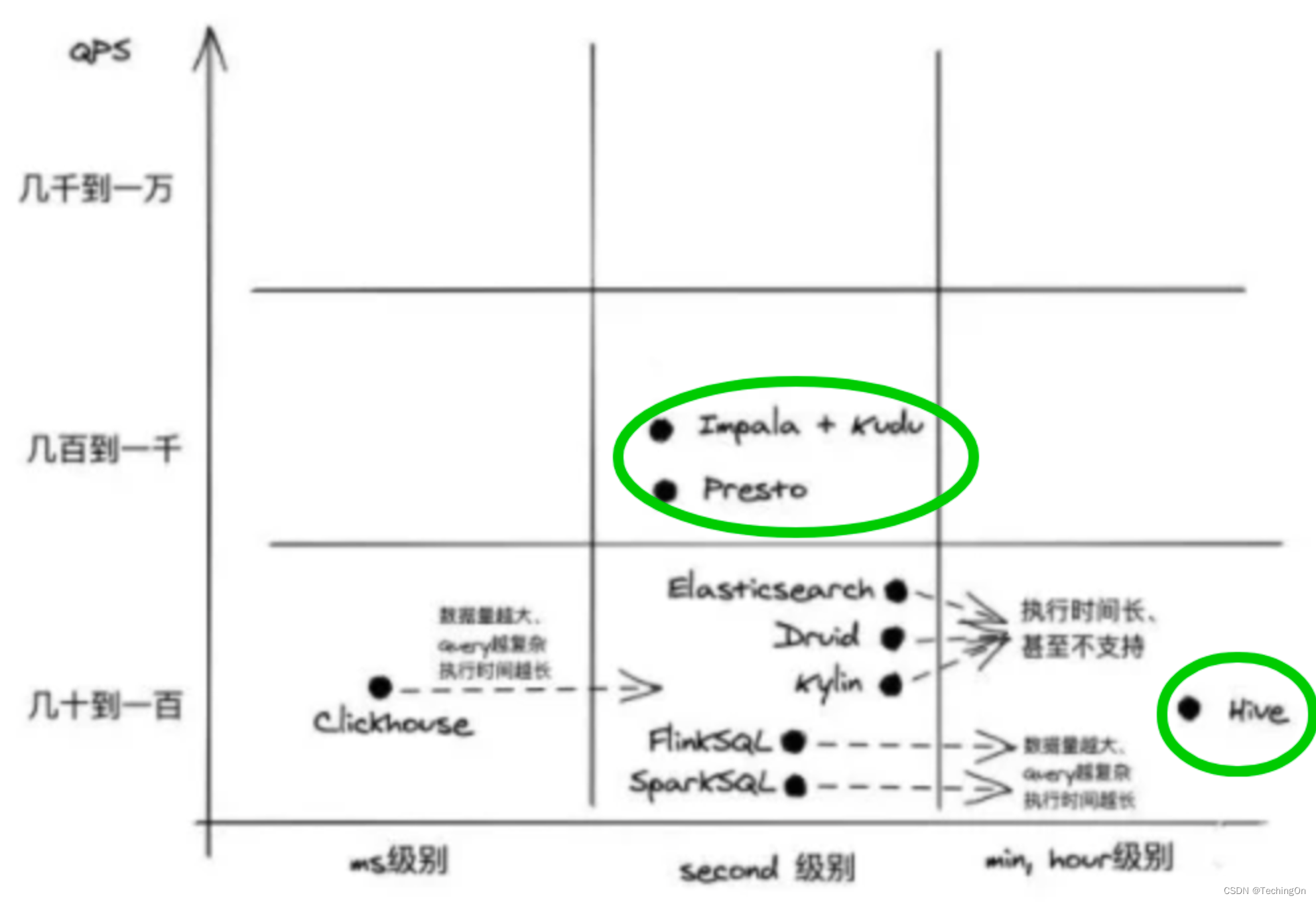
OLAP系统林林总总
大数据需求通常可分为三大类:离线数据统计,实时数据计算,即席查询。
离线数据统计,通常是T1出数,是最典型的数据仓库解决的问题。计算复杂性最高,所以是时间就不能要求太高,否则对资源的要求将…
精准水位在流批一体数据仓库的探索和实践
作者 | 浮生若梦的石头 导读 随着实时计算技术在大数据中的广泛应用,数据的时效性得到大幅度,但是实际应用场景中,除了时效性,还面临着更高的技术要求。 本文结合实时计算的水位技术在流批一体数据仓库中的探索和实践,…
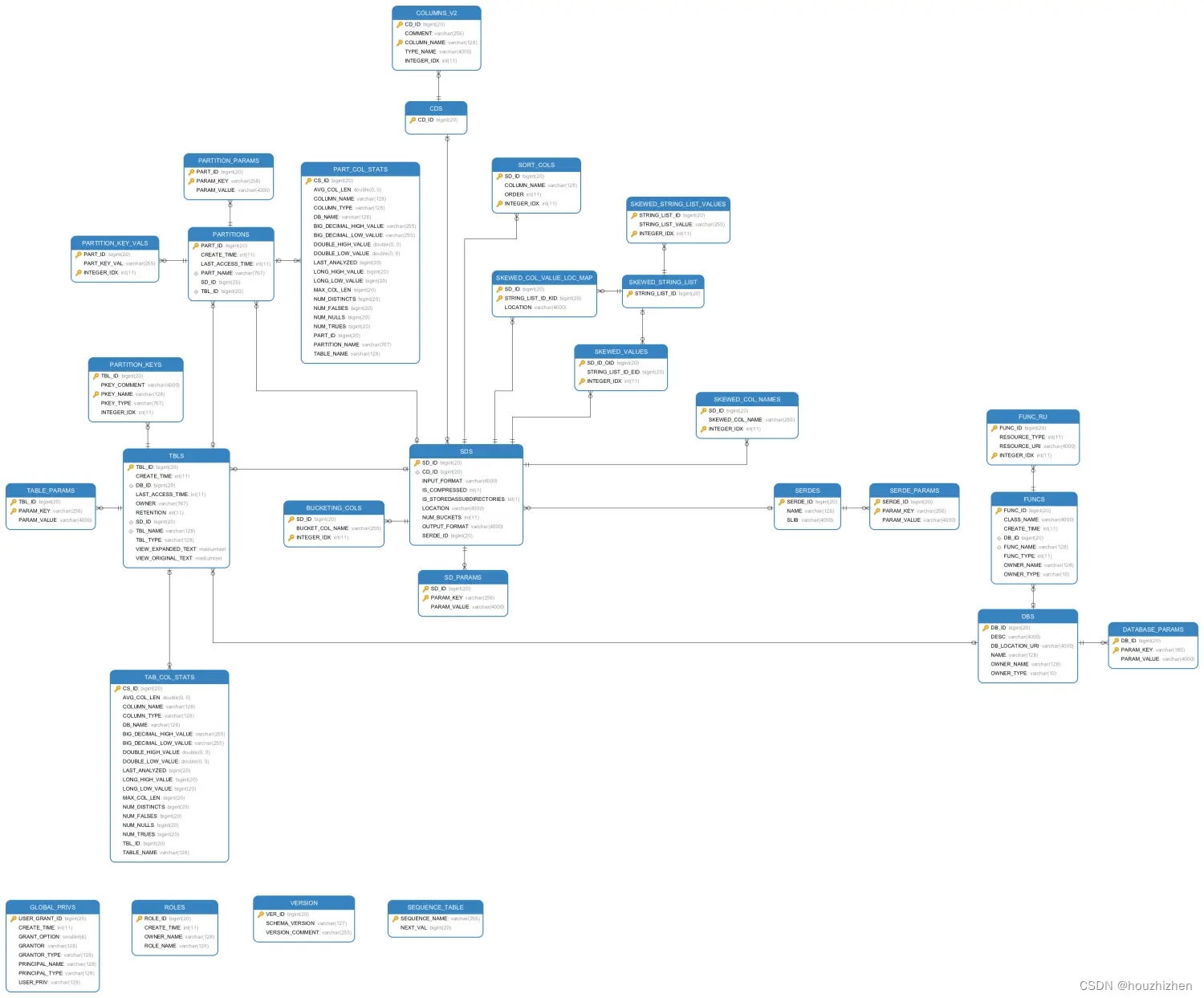
Hive Metastore 表结构
Hive MetaStore 的ER 图如下。 部分表结构和说明。
CTLGS(CATALOGS)
catalogs 可以隔离元数据。默认只有1行。一个 CATALOG 可以有多个数据库。
mysql> DESC CTLGS;
--------------------------------------------------------
| Field | Type | Null |…
实时业务时代:现代数据基础设施不进行ETL
企业是24小时运作的。这包括从网站、后勤办公、供应链等各个方面。过去,一切都是通过批处理运行的。就在几年前,操作系统会暂停以便将数据加载到数据仓库中并运行报告。现在的报告则关注事物的实时状况。已经没有时间进行 ETL。
许多 IT 架构仍然基于中…

中小企业面临怎样的数字化转型局面
当前,我国经济长期向好的基本面没有改变,但承受着“需求收缩、供给冲击、预期减弱”的三重压力,中小企业的数字化转型之路较之以往更加艰难、曲折。为帮助中小企业纾困解难、平稳渡过危机,需进一步优化政策“组合拳”,…
基于MySQL的DAT-A应用
基于MySQL的DAT-A应用 来自:http://www.dwreview.com 作者:张玉颖 日期:2004年03月22日 浏览次数:867 数据挖掘的发展经历了相对多变的过程,这更多地源于软件设计和架构上的限制,而不是技术上的限制。大多…
运营-18.积分体系概念
积分体系是一种通过平台补贴来提升用户忠诚度、为平台各项业务的导流的运营手段; 作用 1. 积分体系可以引导用户逐渐投入沉没成本,包括时间、精力和金钱; 2. 沉没成本越高,用户越难以离开; 3. 积分体系可以给其他业务导…
Hive学习---5、分区表和分桶表
1、分区表和分桶表
1.1 分区表
Hive中的分区就是把一张大表的数据按照业务需求分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择查询所需要的分区,这样的查询效率会提高很多。
1.1.1 分区表基本语法
1、创建…

阿里云如何帮助企业进行数据迁移和数据同步?有哪些应用案例?
阿里云如何帮助企业进行数据迁移和数据同步?有哪些应用案例? [本文由阿里云代理商[聚搜云www.4526.cn]撰写] 阿里云数据迁移与数据同步解决方案 阿里云为企业提供了一系列高效、安全并应对不同场景需求的数据迁移与同步服务。这些服务旨在最大范围减少企…
使用DataX,从Greenplum将数据传输到Hive分区表中
我司使用Greenplum作为计算库,实时计算统计数据,但是数据量大了之后影响计算速度。所以将每天的数据通过Datax传输到Hive的按日分区的分区表中,用于备份,其他数据放在Greenplum中作为实时数据计算。 Greenplum内核还是PostgreSQL&…


Hive 之 查询 01-基本查询、where子句、分组
欢迎大家扫码关注我的微信公众号: Hive 之 查询 01-基本查询、where子句、分组一、 基本查询1.1 全表和特定列查询(select ... from)1.1.1 全表查询:1.1.2 特定列查询:1.2 列别名1.2.1 重命名一个列;1.2.2…
2021年煤炭生产经营单位(一通三防安全管理人员)最新解析及煤炭生产经营单位(一通三防安全管理人员)新版试题
题库来源:安全生产模拟考试一点通题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:2021年煤炭生产经营单位(一通三防安全管理人员)最新解析为正在备考煤炭生产经营单位(一通三防安全…
阿里云-数据仓库-全链路大数据开发治理平台-DataWorks的数字世界
一、前言
上文我讲到 阿里云-数据仓库-数据分析开发神器-ODPS ,今天我带领大家一起走进神器的成长环境及它的数据世界。
二、 DataWorks是什么
DataWorks基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等…
关于数据分析和数据指标,企业还需要做什么?
数据虽然已经成为了各行各业对未来的共识,也切实成为了各领域企业的重要资产。但真正谈到发挥数据的价值,就必须从规模庞大的数据中找出需求的数据,然后进行利用。这个过程光是想想就知道很麻烦,更别提很多数据都是经常会用到的&a…
2021年光气及光气化工艺报名考试及光气及光气化工艺考试资料
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:光气及光气化工艺报名考试参考答案及光气及光气化工艺考试试题解析是安全生产模拟考试一点通题库老师及光气及光气化工艺操作证已考过的学员汇总,相对有效帮助光气及光…
2021年大型游乐设施操作考试及大型游乐设施操作证考试
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:2021年大型游乐设施操作考试为正在备考大型游乐设施操作操作证的学员准备的理论考试专题,每个月更新的大型游乐设施操作证考试祝您顺利通过大型游乐设施操作考试。
支…
基于 Flink SQL 构建流批一体的 ETL 数据集成
【提醒:公众号推送规则变了,如果您想及时收到推送,麻烦右下角点个在看,或者把本号置顶】正文开始摘要:本文整理自云邪、雪尽在 Flink Forward Asia 2020 的分享,该分享以 4 个章节来详细介绍如何利用 Flink…
我的数据生涯没有规划
这是傅一平的第348篇原创注:本文为重新修改发布的文章,看过的可以忽略正文开始有群友让我谈谈自己的职业发展,就简要讲下吧,其实自己的发展很普通,即使看到偶偶的转折,那首先也要要感谢这个时代带来的一点机…
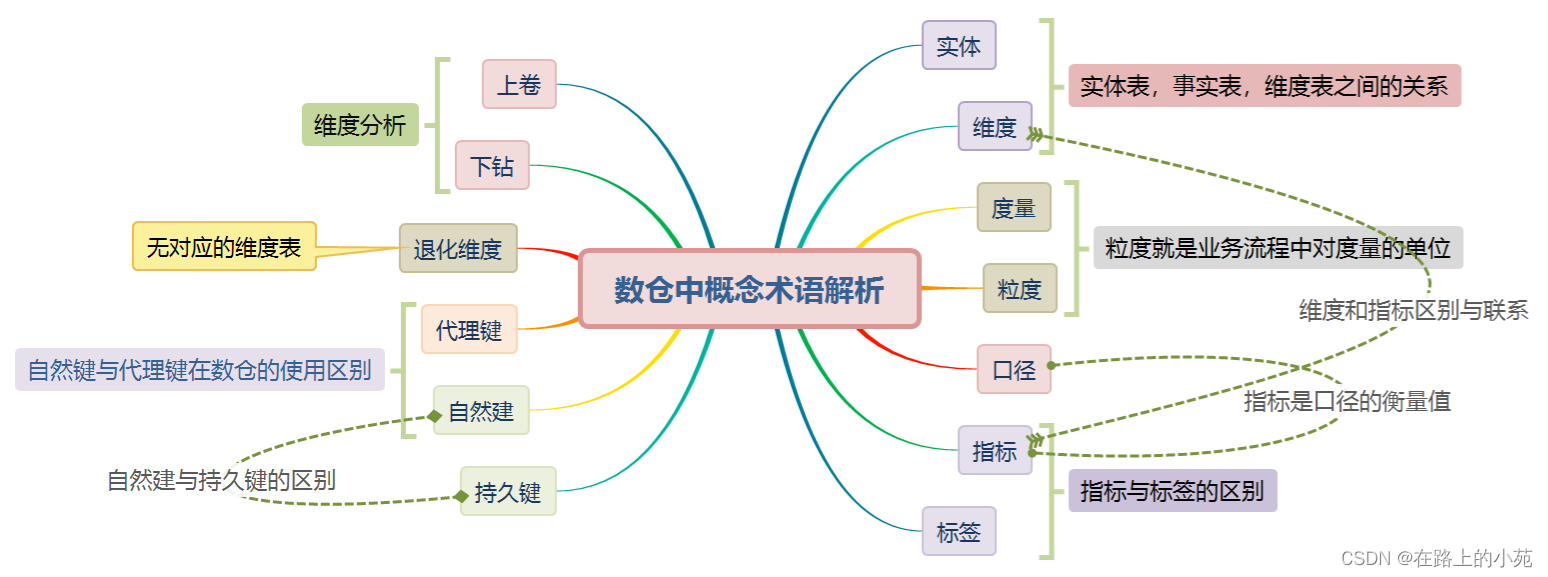
数仓中指标-标签,维度-度量,自然键-代理键等各名词深度解析
作为一个数据人,是不是经常被各种名词围绕,是不是对其中很多概念认知模糊。有些词虽然只有一字之差,但是它们意思完全不同,今天我们就来了解下数仓建设及数据分析时常见的一些概念含义及它们之间的关系。 本文首发于公众号【五分钟…
一文解读数据中台的十大问题
正文开始数据中台是比较快能够产生业务价值,能够绕过沉重的流程,遗留系统改造的包袱,去识别业务创新,智能赋能的路径所以很多CEO都在问CIO或者CDO各种关于数据中台的问题,我这里用大家喜闻乐见的PPT的方式予以回答&…
数据团队演进的五个层级,你处于哪一级?
这是大鱼先生的第7篇原创正文开始随着公司数字化转型的加快和多年的大数据运营,我们数据团队的职能终于能超越部门的限制,成为整个企业大数据的实际管理者,数据团队能走到现在非常不容易,今天就来聊聊其演进过程,可划分…


运营-20.产品社区化和内容化
产品社区化和内容化
为什么现在很多产品都在往社区化、内容化发展?
1.拓展产品线,满足用户的多元需求
分享、交流、炫耀、虚荣,这些是人类永恒的情感需求,社区是一个能很好的满足这些需求的工具;
2.打造归属感&…
商业智能BI中的ETL到底是什么?
商业智能BI中有许多定义,诸如数据仓库、数据挖掘、OLAP等,还有一个不得不提的定义,那就是ETL。在BI工程师或相关的职位招聘中,ETL也是必不可少的一项技能。那么,ETL到底是什么呢?
ETL 的英文全称叫做 Extr…

数据仓库经典销售案例
文章目录一、业务库1.1 数据模型1.2生成数据二、数据仓库2.1 模型搭建2.1.1 选择业务流程2.1.2 粒度2.1.3 确认维度2.1.4 确认事实2.1.4.1 建立物理模型2.1.4.2 建库、装载数据三.编写脚本配合 crontab 命令实现 ETL 自动化一、业务库
1.1 数据模型
源系统是 mysql 库&#x…
【Spark SQL】3、大数据数据仓库Hive的学习
大数据数据仓库Hive
产生背景
MapReduce编程的不变性HDFS上的文件缺失schema
用于处理海量结构化的日志数据统计问题
构建在Hadoop之上的数据仓库
Hive定义了一种类SQL查询语言:HQL(类似SQL但不完全相同)
通常用于进行离线数据处理
支持多种不同的压缩格式(GZIP、LZO、S…
利用维对象来优化数据仓库的高级技巧
利用维对象来优化数据仓库的高级技巧 作者: AnySQL.net, 转载时请务必以超链接形式标明文章原始出处和作者信息.链接: http://www.anysql.net/oracle/oracle_olap_dimension.html在Oracle的数据仓库(OLAP)中, 实体化视图(MVIEW), 查询重写(Query Rewrite)和维(Dimension)是非常…
深入浅出亚马逊AWS数据湖
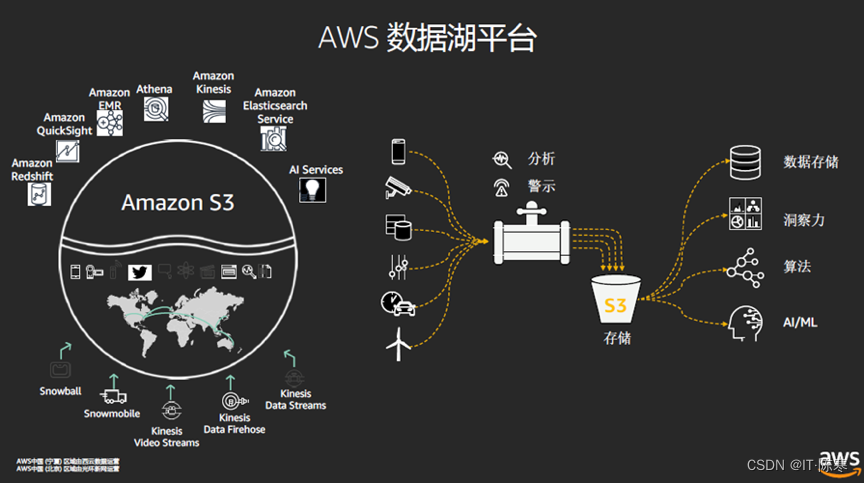
【与数据同行】已开通综合、数据仓库、数据分析、产品经理、数据治理及机器学习六大专业群,加微信号frank61822701 为好友后入群。新开招聘交流群,请关注【与数据同行】公众号,后台回复“招聘”后获得入群方法。正文开始一、认识数据湖1、初识…
实时数仓在滴滴的实践和落地
【与数据同行】已开通综合、数据仓库、数据分析、产品经理、数据治理及机器学习六大专业群,加微信号frank61822701 为好友后入群。新开招聘交流群,请关注【与数据同行】公众号,后台回复“招聘”后获得入群方法。正文开始桔妹导读:…

【实战】Greenplum平台扩展框架PXF与Hadoop的数据交互
了解更多Greenplum相关内容,欢迎访问Greenplum中文社区网站 本文转自掌数科技 一、与HADOOP HDFS的交互 01 PXF是什么 PXF是 Greenplum平台扩展框架(PXF),通过内置连接器提供对外部数据的访问。PXF作为Greenplum与hadoop集群数据交…
jackrabbit入门实例2
代码示例
逐行阅读,该例子的目标是遍历节点 import org.apache.jackrabbit.commons.JcrUtils;
import org.apache.jackrabbit.core.RepositoryImpl;
import org.apache.jackrabbit.core.config.RepositoryConfig;
import org.apache.log4j.Logger;import javax.jcr…

报表到底应该归谁管,OLAP or OLTP? by 傅一平
很多企业的报表质量备受业务人员诟病,要么数据不准确、不一致或不及时,诸如此类困扰着数据团队的表哥表姐,有些问题是数据团队自己能解决的,无非是资源问题,如果老板真想解决,总是能逐步推进解决࿰…

读写分离(主从复制)简介
什么是mysql的主从复制?
MySQL主从复制,是指数据可以从一个MySQL数据库服务器主节点复制到一个或者多个从节点。MySQL默认采用异步复制算法,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行&…
1.数据仓库基本理论
1.数据仓库
概念: 数据仓库是一个用于存储、分析、报告的数据系统 数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策
特点: 数据仓库本身并不“生产”任何数据,其数据来源与不同外部系统 同时数据仓库自身…
5.Hive参数配置与函数、运算符使用
1.Hive客户端与属性配置
1.1 CLIs and Commands
1.1.1 Hive CLI
$HIVE_HOME/bin/hive是第一个shell Util,其主要功能有两个 1.交互式或批处理模式运行Hive查询 2.hive相关服务的启动 可以运行“hive -H”或者“hive --help”来查看命令行选项
-e <quoted-que…

数据湖,比“数据中台”更需要重视的概念|腾研识者
作者火雪挺 腾研识者、腾讯CSIG资深架构师一件事物若能经得起时间的推敲,经得起历史的选择,回过头去看仍能矗立在长河之中,那我们通常会称它为“经典”。10年前,Pentaho公司(一家开源BI公司)的CTO詹姆斯迪克…
【Hive实战】Hive的逻辑视图
Hive视图使用 Hive的逻辑视图使用视图的目的视图规则视图的问题Hive中的视图使用定义视图查询视图详细查询引用视图修改视图查询删除视图 Hive的逻辑视图
视图是在SQL标准协议中是一种信息模式,是根据定义模式的基础表定义的视图表。 The views of the Information…
花了几百万,仍然无法消除「数据孤岛」,这份数字化建设方案下载
中国信息化建设发展了几十年,像政府和央企、国企这类不差钱的,很多系统购买的原因之一就是“消除数据孤岛”。这个口号喊了几十年,结果系统是越来越多,数据孤岛也越来越严重。就像给裤子打补丁,哪里破了个洞࿰…
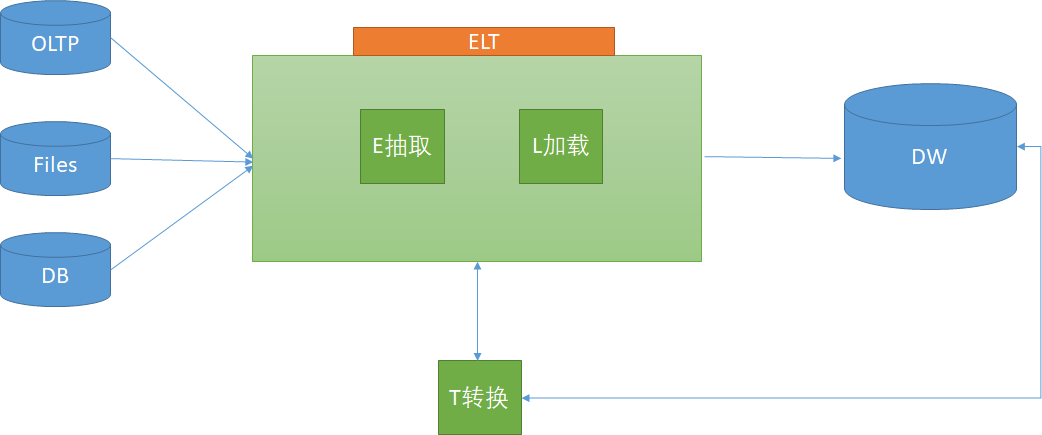
关于ETL的两种架构(ETL架构和ELT架构)
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象…
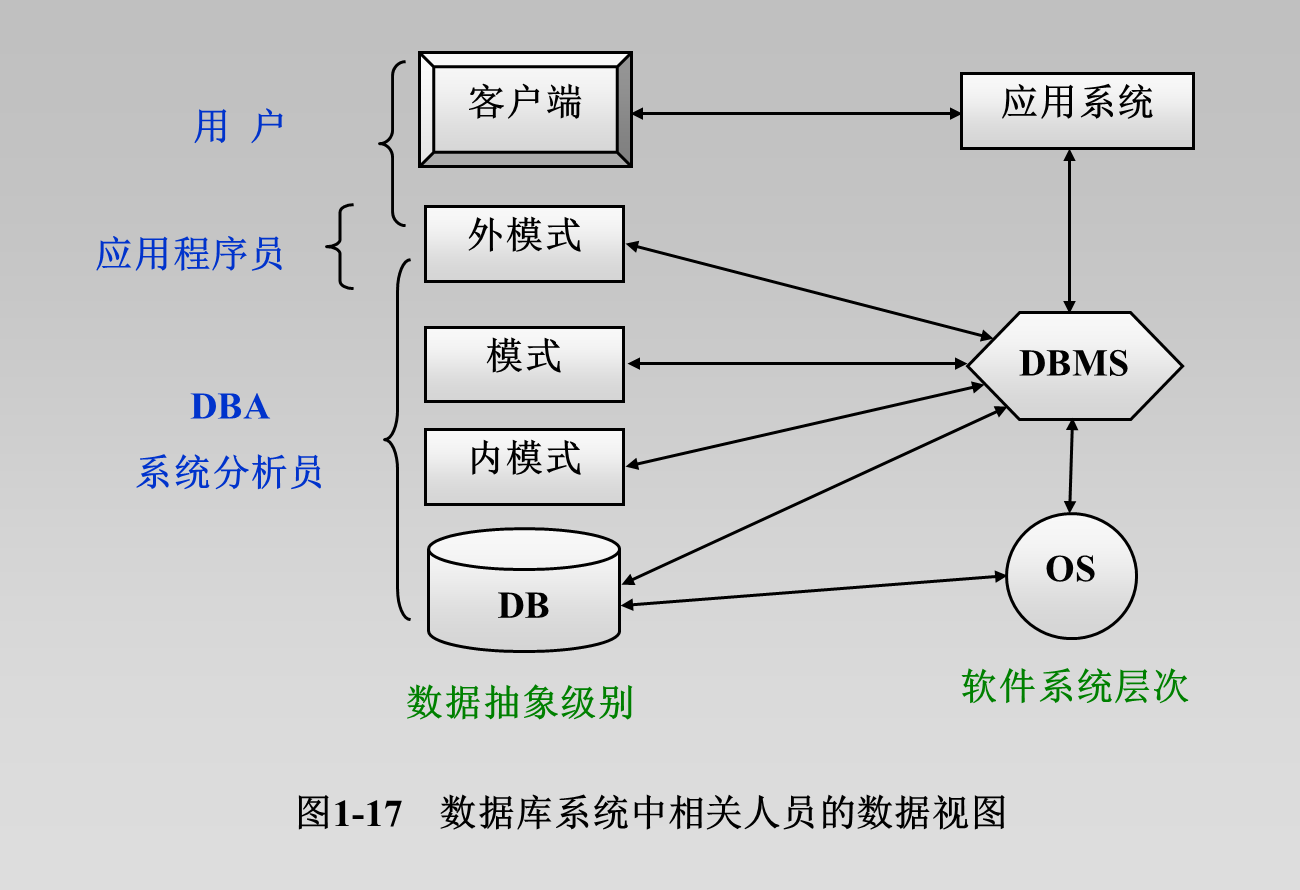
《数据库》第1章 数据库系统概论
知识点
1.1 数据库系统的作用 1.1.1 数据与数据管理1.1.2 数据管理技术的产生与发展 1.2 数据模型 1.2.1 数据模型的分类 1、概念模型2、逻辑模型3、物理模型4、适用对象 1.2.2 数据模型的组成要素1.2.3 层次模型1.2.4 网状模型1.2.5 关系模型 1、关系数据模型的数据结构 &…
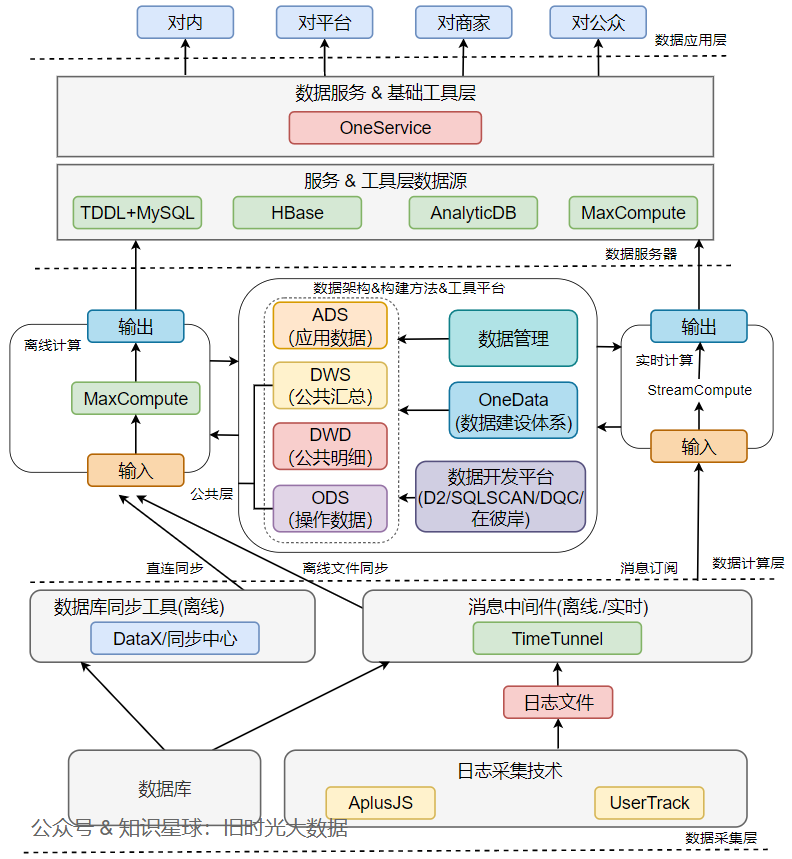
《阿里大数据之路》读书笔记:第一章 总述
阿里巴巴大数据系统体系架构图
阿里数据体系主要分为数据采集、数据计算、数据服务和数据应用四大层次。 一、数据采集层
阿里巴巴建立了一套标准的数据采集体系方案,致力全面、高性能、规范地完成海量数据的采集,并将其传输到大数据平台。
数据来源主…
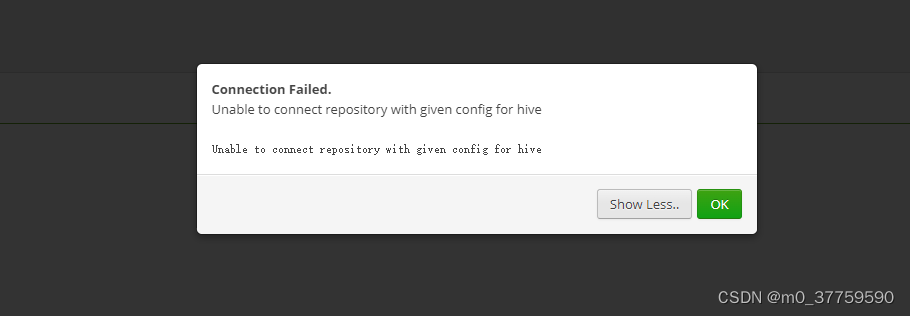
ranger配置hive出錯:Unable to connect repository with given config for hive
ranger配置hive出錯:Unable to connect repository with given config for hive 我一開始我以為是我重啟了ranger-admin導致ranger有點問題,後面排查之後發現是我之前把hiveserver2關閉了,所以只需要重新開啟hiveserver2即可

数据挖掘——第四章:数据仓库和OLAP
文章目录1. 数据仓库基本概念1.1 数据仓库的定义及特征1.2 数据仓库体系结构1.3 数据模型1.4 粒度2. 数据仓库设计2.1 概念模型设计4.2 逻辑模型设计2.3 物理模型设计3. 数据仓库实现4. 联机分析处理4.1 OLAP相关概念4.2 OLAP操作5. 元数据模型5.1 元数据库5.2 元数据类型5.3 元…

数据挖掘——第三章:数据预处理
文章目录1. 数据存在的问题1.1 原始数据存在的问题1.2 数据质量要求1.3 预处理主要任务2. 数据清洗2.1 空缺值处理2.2 噪声处理3. 数据集成3.1 集成过程中涉及的实体识别3.2 冗余问题3.3 检测冗余方法4. 数据归约4.1 数据归约的标准:4.2 数量归约:直方图…

【注册倒计时】第四届Apache HAWQ技术研讨会
第四届Apache HAWQ技术研讨会下周五(1月12日)即将在上海举行,注册截止已经进入倒计时。 在这次技术研讨会中Pivotal中国研发中心的嘉宾们将为大家奉上技术干货,同时,我们还邀请了阿里巴巴计算平台架构师刘奎恩博士和大…
ETL数据集成和数据仓库的关键步骤
导言:
在当今数据驱动的世界中,ETL(提取、转换和加载)过程在构建可靠和高效的数据仓库中扮演着关键角色。ETL数据集成和数据仓库的关键步骤对于数据质量和决策支持至关重要。本文将介绍ETL数据集成和数据仓库构建的关键步骤&…
不会python怎么办,这样大数据数据分析,小白也能上手
最近老板让我进行大数据数据分析,但是我只是做业务的,咋做专业的大数据数据分析。赶紧咨询之前的做数据分析的好朋友,好朋友一听说,说大数据数据分析也不是一定要用我想象的python这种编程工具才能搞定,还有其他更简单…
数据运营是什么,怎么做,在哪做
数据运营也是在公司的常常被领导提到的词了,开个会就会提到我们要用数据驱动运营,但是真的工作执行起来该怎么做呢?那么今天就给跟大家谈谈说数据运营究竟是什么,怎么做,在哪做。 数据运营是什么
数据运营,…
大数据主流技术框架及概述
大数据技术框架1. 简介 大数据技术体系主要涉及方面:数据采集,数据处理,数据存储以及分布式协调服务; 数据采集:etl,kettle,flume 数据处理:离线处理hadoop,实时处理spa…
数据仓库为什么要分层
离线数仓中为什么要分层? 简单概述一下:
解耦提高数据复用性(最重要)将复杂需求简单化,从原本的需要执行十几步,分层之后只需做一步两步防止重复计算可以屏蔽敏感数据 建设实时数仓的目的,主要…
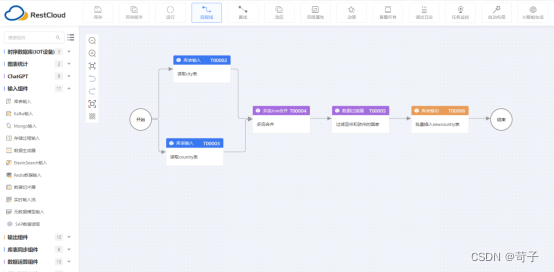
数据集成到可视化分析,轻松驾驭数据洞察力:ETLCloud与帆软BI完美结合
在当今数据驱动的业务环境中,企业需要快速而准确地获取、处理和分析大量的数据。为了满足这一需求,ETLCloud通过和帆软BI的集成提供了一种强大的数据采集和数据分析解决方案,通过可视化的ETL工具和灵活的BI功能,帮助企业快速实现高…

为什么《DAMA数据管理知识体系》这么晦涩难懂? by 傅一平
自己有近20年的数据管理实践,很早就接触DAMA,DMBOK,然后陆续学习DCMM、数据资产白皮书、工业数据治理等相关规范和书籍,也获得了很多启示,但其实有一个问题始终没解决,就是虽然这些规范和书籍都提出了一个框…

【快递时效明细接口不通】BUG修复
昨晚上线了一个新功能,快递时效明细获取快递的预计到达时间。
这个接口,我之前已经写好了,原本传参中需要fromCity(出发地城市)和toCity(目的地城市),这两个字段原本是让采购录入的…
数据团队要用数据驱动业务,首先得学会用数据驱动自己!
【与数据同行】已开通综合、数据仓库、数据分析、产品经理、数据治理及机器学习六大专业群,加微信号frank61822701 为好友后入群。新开招聘交流群,请关注【与数据同行】公众号,后台回复“招聘”后获得入群方法。正文开始数据驱动业务是数据从…
数据挖掘分类算法比较
数据仓库,数据库或者其它信息库中隐藏着许多可以为商业、科研等活动的决策提供所需要的知识。分类与预测是两种数据分析形式,它们可以用来抽取能够描述重要数据集合或预测未来数据趋势的模型。分类方法(
Classification
)用于预…

MySQL本地登录出现10061错误
参考的是方法2 https://www.php.cn/mysql-tutorials-473799.html 启用服务出现的是服务名无效猜测是MySQL的版本问题。 链接中删除my.ini步骤不需要。 采用方法2的原因是试过了此电脑-管理-服务-启动mysql服务的这个方法,但是由于我的服务里没有mysql-5.7.17这个选项…

对于数据仓库你了解多少?
今天我们要说的是主题是——数据仓库,注意是仓库,不是数据库哦。
首先我们要知道,数据仓库的建立为行业高层主管门系统的地组织、理解和使用他们的数据进行了战略决策提供了体系结构和工具。在当今充满竞争和快速发展的世界,数据…
大数据项目实战之数据仓库:电商数据仓库系统——第3章 维度建模理论之事实表
第3章 维度建模理论之事实表
3.1 事实表概述
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计。其包含与该业务过程有关的维度引用(维度表外键)以及该业务过程的度量(通常是可累加的数字类型字段)。
3.…

BI财务智能分析,让企业管理更上一层楼
智能财务建设既可以看作是财务管理工作在经济社会数字化转型的全面开启,也可以看作是财务职能在以数字化技术为支撑,形成对内提升单位管理水平和风险管控能力、对外服务财政管理和宏观经济治理的会计职能拓展,究其本质则是在财务数字化转型升…

如何从Teradata迁移到Greenplum(上篇)
我们在之前的文章中介绍了如何从Oracle迁移到Greenplum。与Oracle迁移类似,作为在世界范围内有广泛用户的数据仓库产品,在综合评估了多种因素后,Teradata的很多用户选择迁移到Greenplum。我们将从为什么迁移和如何迁移两个层面来讨论如何从Te…
数据治理-元数据度量指标
要想测量元数据的影响,就需要验证缺少元数据导致的影响,作为风险评估的一部分,将数据使用者搜索信息所花费的时间作为评估指标,以便在实施元数据解决方案后体现改进过程。元数据管理实施的有效性可以根据元数据本身的完整性、与其…
Hive hql 经典5道面试题
最近在深入了解Hive,尚硅谷的这5道题很经典,有引导意义,分步解题也很有用,故记录之,方便回看 1.连续问题
如下数据为蚂蚁森林中用户领取的减少碳排放量 找出连续 3 天及以上减少碳排放量在 100 以上的用户 id dt lowc…
数据清洗考虑的几个个方面--阿宏
阿宏-数据清洗考虑的几个方面
1、预处理
在实际业务处理中,数据通常是脏数据。所谓的脏,指数据可能存在以下几种问题(主要问题): 1.数据缺失 (Incomplete) 是属性值为空的情况。如 Occupancy “ ” 2. 数…
详解零售行业供应链管理核心KPI指标(四)
现在零售行业的供应链管理越来越复杂了,复杂的原因是因为市场的变化、商业模式、销售模式的变化。
比如在以往传统的线上电商平台、线下渠道,现在线上电商还增加直播带货,线下渠道又增加了O2O模式。从一线城市的供应链还是做到供应链下沉到二…
iceberg系列之 hadoop catalog 小文件合并实战
背景 flink1.15 hadoop3.0pom文件 <?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://mave…
【dbeaver】win环境的kerberos认证和Clouders集群中Kerberos认证使用Dbeaver连接Hive和Phoenix
一、下载驱动
cloudera官网
1.1 官网页面下载
下载页面 的Database Drivers 挑选比较新的版本即可。
1.2 集群下载
Hive可能集群没有驱动包。驱动包名称:HiveJDBC42.jar。41结尾的包也可以使用的。注意Jar包的大小一定是十几MB的。几百KB的是thin包不可用。 …
S4HANA - Cost Elements成本要素
2014年 SAP就发布了Simple Finance。到2015年,Simple Finance 2.0发布的时候,名字就改了,改成S/4HANA Finance了。
那这个和传统的FICO有啥区别呢?
所有实际行项目都被存到新表ACDOCA里了,没有冗余,不需要…
数仓开发常用hive命令
在做数仓开发或指标开发时,是一个系统工程,要处理的问题非常多,经常使用到下面这些hive命令: 内部表转外部表
alter table ${tablename} set tblproperties (EXTERNALTrue); 外部表转内部表
alter table ${tablename} set tblpr…


大数据平台与数据仓库的五大区别
随着大数据的快速发展,很多人难以区分大数据平台与数据仓库的区别,两者傻傻分不清楚。今天我们小编就给大家汇总了大数据平台与数据仓库的五大区别,希望有用哦!仅供参考! 大数据平台与数据仓库的五大区别
一、概念不同…
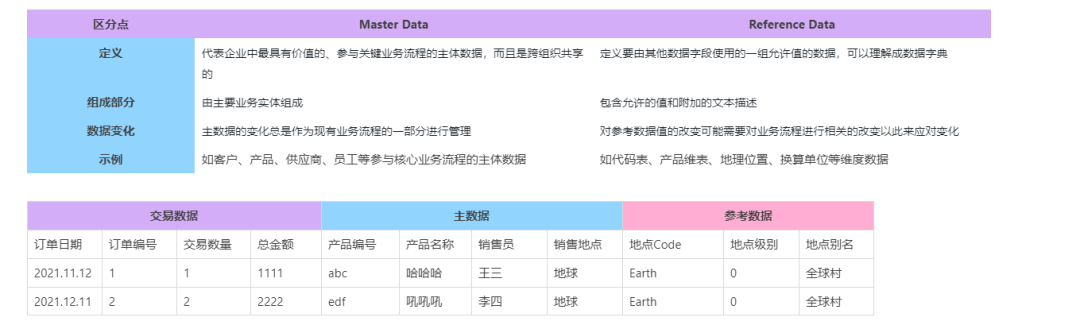
一文理解主数据和参考数据
如果你准备要开展推动数据治理或者是数据质量的项目,那么你就有可能会听说到几个词:主数据和参考数据。一开始听到主数据这一词听起来就很高大上,而且非专业人士肯定不理解(即便是从事数据行业的朋友也很难参透)。这一…
51款BI产品、80种可视化工具、80张图(总有一款适合你)
后台回复【“可视化”】领取PDF版本
BI(Business Intelligence)即商业智能,它是一套完整的解决方案,用来将企业中现有的数据进行有效的整合,快速准确的提供报表并提出决策依据,帮助企业做出明智的业务经营决策,商业智…
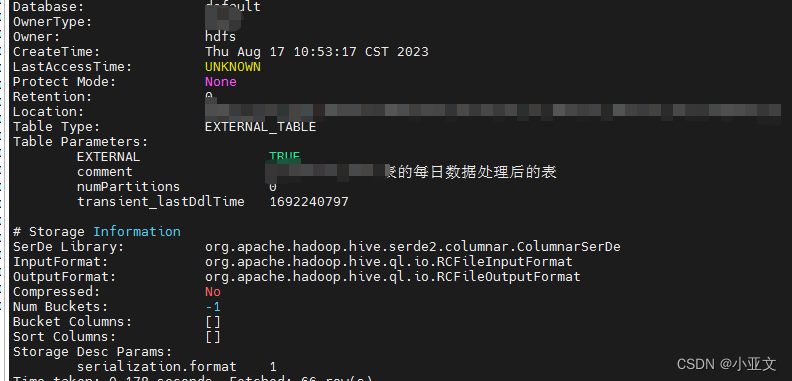
hive--给表名和字段加注释
1.建表添加注释
CREATE EXTERNAL TABLE test(loc_province string comment 省份,loc_city string comment 城市,loc_district string comment 区,loc_street string comment 街道,)COMMENT 每日数据处理后的表
PARTITIONED BY (par_dt string)
ROW FORMAT SERDEorg.apache.had…

hadoop构建数据仓库实践 数据仓库简介和数据仓库设计基础章节 读书笔记
1.数据仓库简介
1.0演变 1.1什么是数据仓库
本质:数据仓库试图提供一种从操作型系统到决策支持环境的数据流架构模型。
要解决的问题:多重数据复制带来的高成本问题(在没有数据仓库的时代,需要大量的冗余数据来支撑多个决策支持…
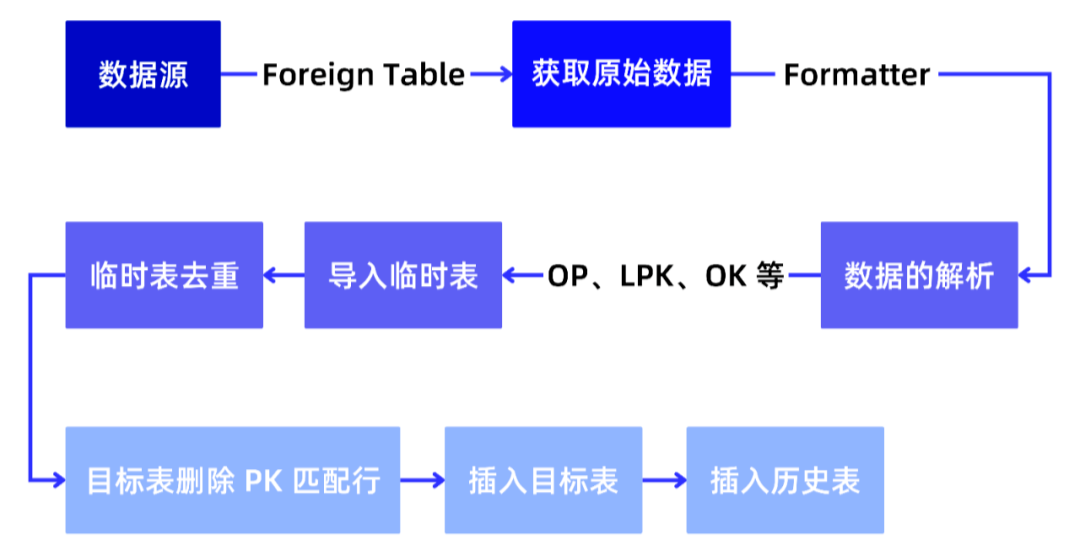
DTCC 2023丨云原生环境下,需要什么样的 ETL 方案?
2023年8月16日~18日,第14届中国数据库技术大会(DTCC 2023)于北京隆重召开,拓数派受邀参与本次大会,PieCloudDB 技术专家邱培峰在大会做了《云原生虚拟数仓 PieCloudDB ETL 方案设计与实现》的主题演讲,详…
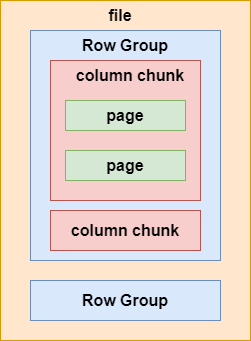
Hive底层数据存储格式
前言
在大数据领域,Hive是一种常用的数据仓库工具,用于管理和处理大规模数据集。Hive底层支持多种数据存储格式,这些格式对于数据存储、查询性能和压缩效率等方面有不同的优缺点。本文将介绍Hive底层的三种主要数据存储格式:文本文件格式、Parquet格式和ORC格式。
一、三…
如何在工作中体现数据开发的业务敏感度?
chatgpt对该问题的回答:
数据同学的业务敏感度是指数据同学对业务需求的理解、分析和满足能力,以及从数据角度为业务提供洞察和建议的能力。以下是一些提高业务敏感度的方法: 深入了解业务:了解公司的业务模式、产品线、目标用户…

数字化时代,数据仓库和商业智能BI系统演进的五个阶段
数字化在逐渐成熟的同时,社会上也对数字化的性质有了进一步认识。当下,数字化除了前边提到的将复杂的信息、知识转化为可以度量的数字、数据,在将其转化为二进制代码,引入计算机内部,建立数据模型,统一进行…
Apache Doris 入门教程34:Join 优化
Bucket Shuffle Join
Bucket Shuffle Join 是在 Doris 0.14 版本中正式加入的新功能。旨在为某些 Join 查询提供本地性优化,来减少数据在节点间的传输耗时,来加速查询。
它的设计、实现和效果可以参阅 上面的图片展示了Bucket Shuffle Join的工作原理…
关于hive sql进行调优的理解
这是一个面试经常面的问题,很不幸,在没有准备的时候,我面到了这个题目,反思了下,将这部分的内容进行总结,给大家一点分享。 hive其实是基于hadoop的数据库管理工具,底层是基于MapReduce实现的&a…
10分钟学会Hive之用户自定义函数UTF开发
1. 用户自定义函数概述 用户自定义函数简称UDF,源自于英文user-defined function。自定义函数总共有3类,是根据函数输入输出的行数来区分的,分别是:
UDF(User-Defined-Function)普通函数ÿ…
postgresql 内核源码分析 btree索引的增删查代码基本原理流程分析,索引膨胀的原因在这里
B-Tree索引代码流程分析 专栏内容: postgresql内核源码分析手写数据库toadb并发编程 开源贡献: toadb开源库 个人主页:我的主页 管理社区:开源数据库 座右铭:天行健,君子以自强不息;地势坤&…
技术实践|Hive数据迁移干货分享
导语
Hive是基于Hadoop构建的一套数据仓库分析系统,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能。它的优点是可以通过类SQL语句快速实现简单的MapReduce统计,不用再开发专门的MapReduce应用程序,从而降低…
Hive用户中文使用手册系列(二)
命令和 CLI
语言手册命令
命令是 non-SQL statements,例如设置 property 或添加资源。它们可以在 HiveQL 脚本中使用,也可以直接在CLI或Beeline中使用。
命令描述退出使用 quit 或 exit 退出交互式 shell。重启将 configuration 重置为默认值(从 Hive…
Hive 中级练习题(40题 待更新)
前言
最近快一周没更了,主要原因是最近在忙另一件事情(关于JavaFX桌面软件开发),眼看大三上一半时间就要过去了,抓紧先学Hive,完了把 Spark 剩下的补了,还有 Kafka、Flume,任务还是…
Hive insert插入数据与with子查询
1. insert into 与 insert overwrite区别
insert into 与 insert overwrite 都可以向hive表中插入数据,但是insert into直接追加到表中数据的尾部,而insert overwrite会重写数据,既先进行删除,再写入
注意:如果存在分…
大数据项目实战之数据仓库:电商数据仓库系统——第10章 数仓开发之DWS层
文章目录 第10章 数仓开发之DWS层10.1 最近1日汇总表10.1.1 交易域用户商品粒度订单最近1日汇总表10.1.2 交易域用户商品粒度退单最近1日汇总表10.1.3 交易域用户粒度订单最近1日汇总表10.1.4 交易域用户粒度加购最近1日汇总表10.1.5 交易域用户粒度支付最近1日汇总表10.1.6 交…
Greenplum 5正式发布:世界上第一个用于高级分析场景的开源、跨云数据平台
世界上规模最大、创新最多的组织均已部署了先进的大规模并行数据分析平台-Pivotal Greenplum,以帮助其解决战略性数据处理和分析面临的挑战。因为技术局限,传统数据平台几乎无法承受重要的分析工作负荷,无法应对欺诈管理和风险分析对网络安全…

数据库系统概论--精简版
数据库精简版
第一章
数据&数据库&数据库管理系统&数据库系统
数据:描述事物的符号记录称为数据,数据库存储的基本对象
数据库:长期存储在计算机内,可共享、有组织的大量数据,数据库中的数据按一定的数…
大数据存储架构详解:数据仓库、数据集市、数据湖、数据网格、湖仓一体
前言
本文隶属于专栏《大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据理论体系 思维导图 数据仓库
数据仓库是一个面向主题的&…
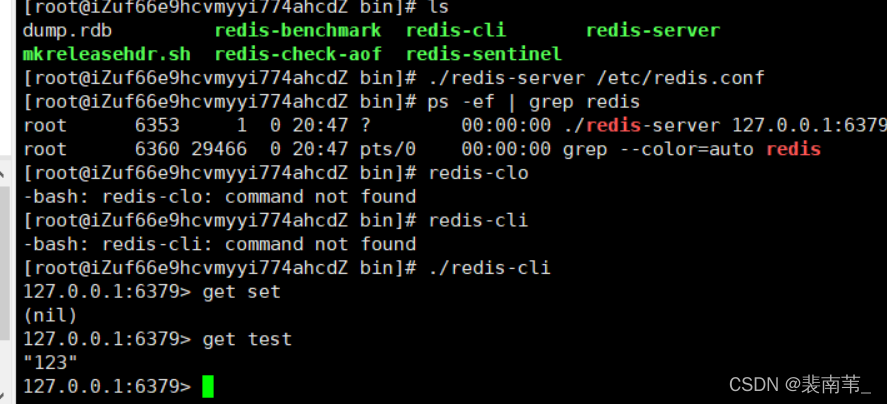
redis配置后台启动
如果我们redis一直是前台启动的话,操作非常的不方便,一旦关闭此会话,redis就自动断开了
所以我们需要将redis配置后台启动 我们启动redis的时候,默认采用他自带这这个redis.conf文件,而conf文件中默认设置不能后台启动…
电商数据分析——基于hive数仓,实现大数据分析
1. 需求
以电商数据为基础,结合hive数仓,实现大数据分析。
数据源可通过日志取得,数据清洗转换导入数据仓库,通过数仓中数据分析得到数据总结,用于企业决策。本项目基于以下表类进行电商数仓分析,分用户信…

数据挖掘技术的来源、历史、研究内容及常用技术
数据挖掘技术的来源、历史、研究内容及常用技术
1 数据挖掘技术的由来
1.1网络之后的下一个技术热点 我们现在已经生活在一个网络化的时代,通信、计算机和网络技术正改变着整个人类和社会。如果用芯片集成度来衡量微电子技术,用CPU处理速度来衡量计…
一步一步学Streams 第一部分(1)基础之概述篇
一、Streams概述 Oracle 的Streams提供了信息共享的一种方式,区别于其它数据共享的方式,Streams甚至允许不同类型的数据库之间传递数据,实现这点的根本在于Streams的复制流程,通过捕获,传播,应用三个步骤&a…
OCM 10G 考试安排
考试安排
OCM考试一共有9个section,具体的安排如下:
第一天:
section 0:
创建一个数据库 45分钟
section 1:
数据库和网络配置 120分钟
section 2:
Gridcontrol安装配置 120分钟
section 3:
数据库备份恢复 60分钟
sectio…
在china-pub上订购了几本书
《数据仓库(原书第4版)》:作者William H Inmon,数据仓库之父,这本书也是数据仓库方面的经典教材了。不过不知道这么偏理论性的书能不能坚持看下去。
《深入浅出Oracle--DBA入门、进阶与诊断案例》:作者eyg…

智能电话机器人的出现,能够解决哪些问题?
经济的繁荣与高速的发展,使得电销这个方式快速地融合在房地产与金融投资等大部分行业上。在电销人员与客户的沟通上,难免会出现很多问题,毕竟所面对的客户都是各行各业,他们有着不同的经历和身份。
对于时常需要处理客户投诉、安…
百度智能云数据仓库Palo免费试用啦!
构建单个分析数仓需要维护5-6个组件;明细数据查询和聚合查询只能二者选一;高并发场景和大吞吐即席查询不能兼得;每个组件都需要单人独立负责,运维成本居高不下;单表查询性能稳定性欠佳,复杂查询场景下计算引…
尚硅谷大数据项目《在线教育之实时数仓》笔记001
视频地址:尚硅谷大数据项目《在线教育之实时数仓》_哔哩哔哩_bilibili 目录
P001
P002
P003
P004
P005 P001 以在线教育采集系统和离线数仓为前置基础,分为三个部分讲解:实时数仓架构介绍、数仓模型搭建、Suger可视化大屏展示。 P002 P0…
不断总结DBA到底需要会些什么?
下面是摘抄某公司的要求:
1、负责Oracle数据库深度健康检查及性能分析2、Oracle 数据库性能优化方案的制定及调优实施3、负责数据库运行性能跟踪及故障处理,保证应用程序的运行,并分析故障原因,记录解决文档4、对Oracle数据库有较深理解和认识…
记录黑群晖使用问题及解决方法
目录
一、Video Station / DS video
1、不支持当前所选音频的文件或不支持EAC3音轨,导致不能播放或视频无声
2、不显示封面和简介
二、不显示视频缩略图
三、内网穿透
1、使用工具的选择
2、安装ZeroTier
3、远程访问
四、IPV6访问
1、确认是否支持IPV6
…
问诊住院医疗业务数仓建模实操案例
一、数仓建模实超案例
(一)前言 医疗业务系统比较复杂,有HIS:医院信息管理系统( Hospital Information System)、CIS:临床信息系统(Clinical Information System)、LIS&…
干货:数据仓库基础知识(全)
1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
1)数据仓库是用于支持决策、面向分析型数据处理;
2)对多个异构的数据源有效集…
数据中台之数据集成平台的数据抽取
目录
概述
面临的问题
设计思路
效果演示
关键技术点 概述
数据抽取是数据集成平台中一个非常重要的功能,主要负责不同数据源和不同数据库的数据同步。
互联网公司常用的数据抽取工具是datax,但是博主公司数据中台的服务对象主要是制造业公司。因此很多功能需要定制化…
ETL简介:数据集成与应用
导言:
在当今大数据时代,组织和企业需要处理和分析庞大的数据量。ETL(Extract, Transform, Load)是一种重要的数据集成和处理方法,它在数据管理和决策支持中起着关键作用。本文将介绍ETL的基本概念、作用和关键组成部…

尚硅谷大数据项目《在线教育之实时数仓》笔记002
视频地址:尚硅谷大数据项目《在线教育之实时数仓》_哔哩哔哩_bilibili 目录
第06章 数据仓库环境准备
P006
P007
P008
P009
P010
P011
P012
P013
P014 第06章 数据仓库环境准备
P006 P007 P008 http://node001:16010/master-status [atguigunode001 ~]$ …

【hive】hive中row_number() rank() dense_rank()的用法
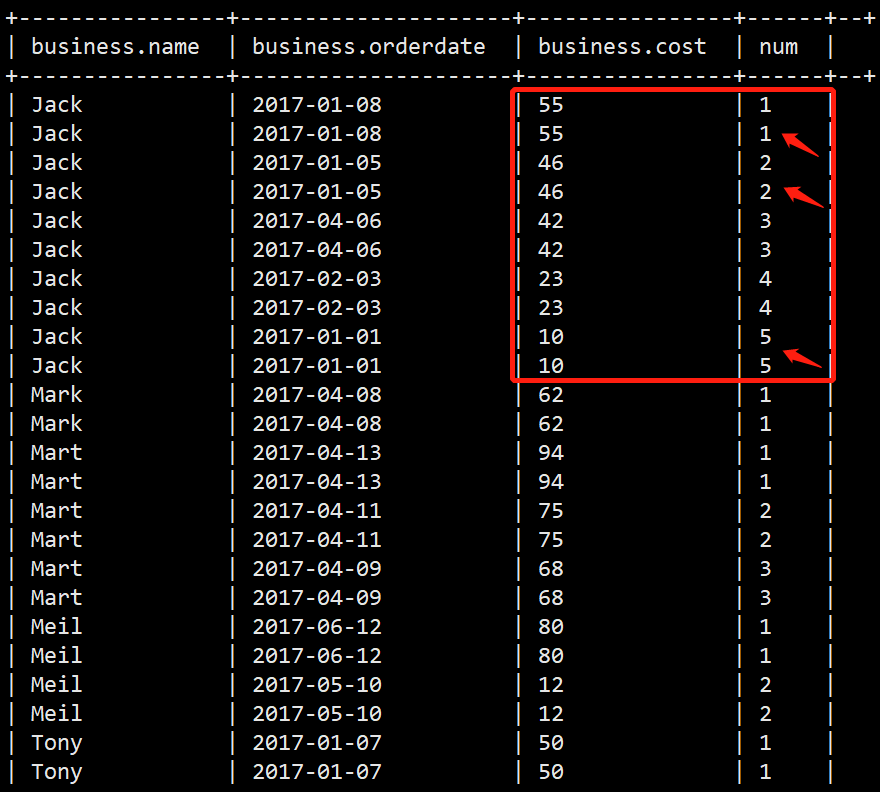
hive中row_number() rank() dense_rank()的用法
一、函数说明
主要是配合over()窗口函数来使用的,通过over(partition by order by )来反映统计值的记录。
rank() over()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)dense_rank() …
doris系列2: doris分析英国房产数据集
1.准备数据 2.doris建表 CREATE TABLE `uk_price_paid` (`id` varchar(50) NOT NULL,`price` int(20),`date` date
8月《中国数据库行业分析报告》已发布,聚焦数据仓库、首发【全球数据仓库产业图谱】
为了帮助大家及时了解中国数据库行业发展现状、梳理当前数据库市场环境和产品生态等情况,从2022年4月起,墨天轮社区行业分析研究团队出品将持续每月为大家推出最新《中国数据库行业分析报告》,持续传播数据技术知识、努力促进技术创新与行业生…

SAS® 针对制药行业的客户关系管理
SAS 针对制药行业的客户关系管理
通过全面的客户关系管理,帮助制药企业增加盈利。 焦点SAS处于CRM分析能力四象限中的领导者位置 今天,制药企业将面临维持历年盈利水平的挑战。渠道挑战、现有畅销药专利即将到期、严格的价格审查和激烈的竞争对制药…
DW amp; DM
数据仓库之路 http://www.dwway.com/数据挖掘研究院 http://218.22.25.142:8080/数据挖掘讨论组 http://www.dmgroup.org.cn/dmreview http://www.dmreview.com

免费玩云上大数据--海汼部落实验室
玩大数据遇到的问题 大家好,这次分享一个免费的大数据部署工具,并非是给人家打广告,试过了真的爽。 学习大数据的人都知道,如果用VMware模拟Linux搭建大数据集群的话我们需要很高的内存和硬盘内存,随随便便跑一下mapre…

定义现代化实时数据仓库,SelectDB 全新产品形态全面发布
导读:9 月 25 日,2023 飞轮科技产品发布会在线上正式召开,本次产品发布会以 “新内核、新图景” 为主题,飞轮科技 CEO 马如悦全面解析了现代化数据仓库的演进趋势,宣布立足于多云之上的 SelectDB Cloud 云服务全面开放…
【数仓基础(一)】基础概念:数据仓库【用于决策的数据集合】的概念、建立数据仓库的原因与好处
文章目录 一. 数据仓库的概念1. 面向主题2. 集成3. 随时间变化4. 非易失粒度 二. 建立数据仓库的原因三. 使用数据仓库的好处 一. 数据仓库的概念
数据仓库的主要作用:
数据仓库概念主要是解决多重数据复制带来的高成本问题。 在没有数据仓库的时代,需…
保险业信息化的两大趋势:数据挖掘+CRM
保险业信息化的两大趋势:数据挖掘+CRM 来自:中国商业智能网 作者:xynet 日期:2004年07月02日 浏览次数:98 作为我国金融市场中成长最为迅速的行业,保险公司借助信息化手段提高竞争能力也成为关…
寿险行业数据挖掘应用分析
寿险行业数据挖掘应用分析 寿险是保险行业的一个重要分支,具有巨大的市场发展空间,因此,随着寿险市场的开放、外资公司的介入,竞争逐步升级,群雄逐鹿已成定局。如何保持自身的核心竞争力,使自己始终立于不败…
CIO调查:数据挖掘并不遥远
CIO调查:数据挖掘并不遥远 赛迪网让数据像人脑一样智慧,具有自动分析、判断和预测能力,这看似不可思议的应用,正是数据挖掘的功能。数据挖掘正吸引着越来越多的企业的眼球。近日,北京长城仪器厂、国…
基于供应链管理的物流信息系统集成
1 供应链管理环境下物流信息的特点供应链是围绕核心企业,通过对信息流、物流、资金流的控制,从采购原材料开始,制成中间产品以及最终产品,最后由销售网络把产品送到消费者手中的将供应商、制造商、分销商、零售商、直…

年薪60w+,被腾讯、华为疯抢,这项技术越来越值钱!
刚刚过去的一年互联网公司的裁员规模可以用「前所未有」来形容。信息来源 | 百度资讯除了登上热搜的爱奇艺大裁员,字节跳动、快手、腾讯等大厂也纷纷传出人员精简、业务调整的消息......从某种意义上,这已经不是一两家公司的问题,而是整个行业…

数据治理之IT系统存量信息梳理
在大数据背景下,数据作为数字经济的关键要素已经得到广泛认可,企业要为众多数据消费需求提供优质的数据供给,必须要做好数据治理。数据治理的对象包含存量数据及增量数据,对存量数据的治理重点在于实现分而治之、建章立制…

数据的深海潜行:数据湖、数据仓库与数据湖库之间的微妙关系
导言:数据的重要性与存储挑战
在这个信息爆炸的时代,数据已经成为企业的核心资产,而如何高效、安全、便捷地存储这些数据,更是每个组织面临的重大挑战。 数据作为组织的核心资产 数据在过去的几十年里从一个辅助工具演变成企业的…
hive lateral view 实践记录(Array和Map数据类型)
目录
一、Array
1.建表并插入数据 2.lateral view explode
二、Map
1、建表并插入数据
2、lateral view explode()
3、查询数据 一、Array
1.建表并插入数据
正确插入数据:
create table tmp.test_lateral_view_movie_230829(movie string,category array&…
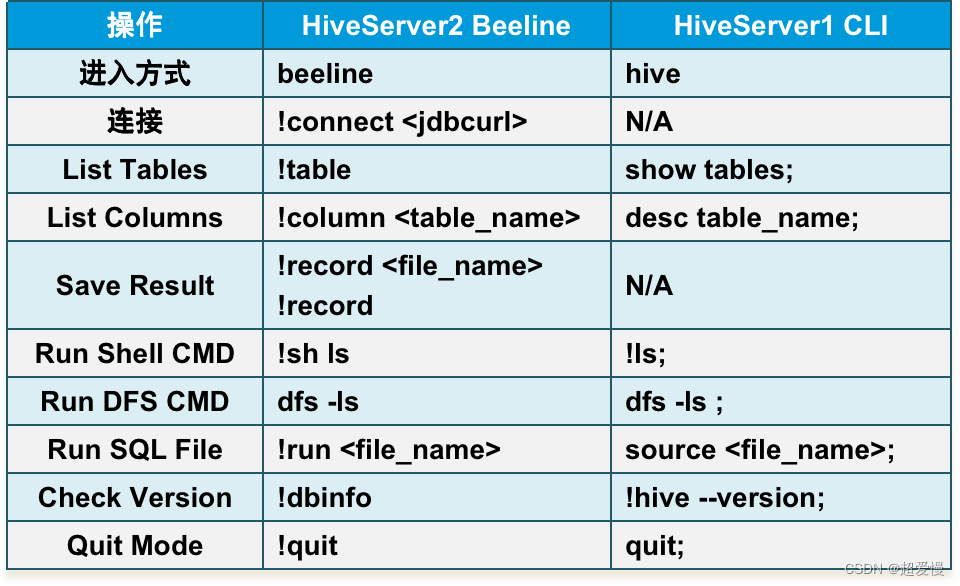
Hive用户中文使用手册系列(三)
JDBC
HiveServer2 有一个 JDBC 驱动程序。它支持对 HiveServer2 的嵌入式和 remote 访问。 Remote HiveServer2 模式建议用于 production 使用,因为它更安全,不需要为用户授予直接 HDFS/metastore 访问权限。
连接 URL
连接 URL 格式
HiveServer2 UR…
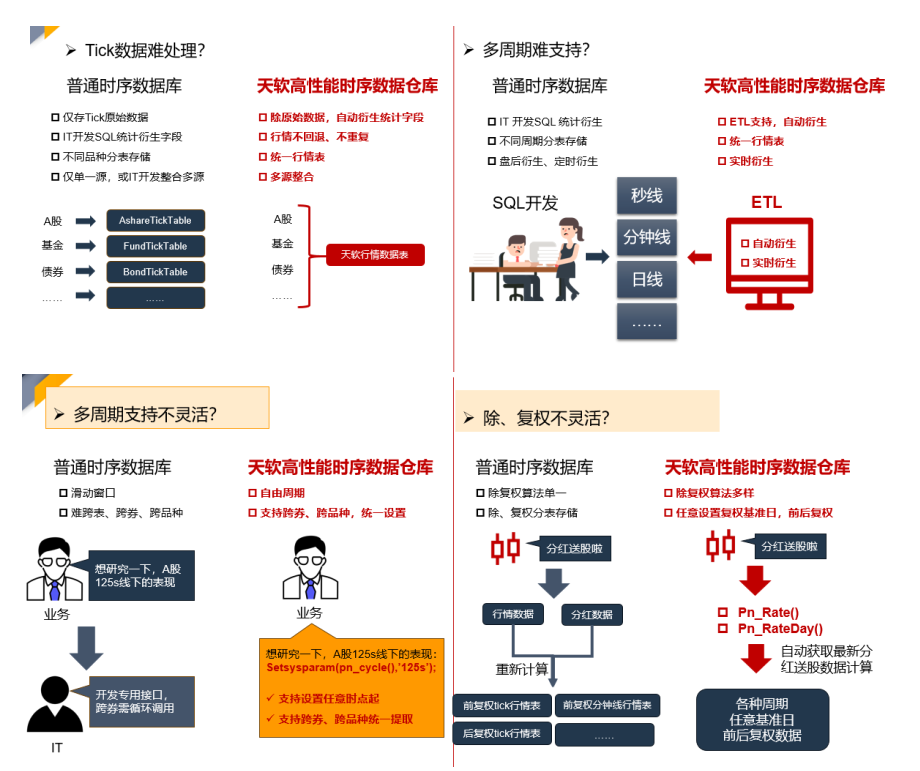
高频行情数据应用解决方案
高频行情数据的因子研发和相关策略,是在当前金融量化投资领域普遍关注的内容。由于高频行情数据量庞大(Level1的Tick每日10G,Level2的Tick每日40G)、以及高频数据时序化处理复杂、数据访问性能等问题,为研发工作的开展…
![[Hive] explode](https://img-blog.csdnimg.cn/89a7d7071c1345e6a89c9118c1d4edb9.png)
[Hive] explode
在 Hive 中,explode 函数用于将数组(Array)或者Map类型的列拆分成多行,
每个元素或键值对为一行。这允许我们在查询中对数组或 Map 进行扁平化操作。 下面是使用 explode 函数的示例:
假设我们有一个包含数组字段的表…
Apache Doris (十七) :Doris分区和分桶3-分桶及建议
目录
一、分桶Bucket
二、分区和分桶数量和数据量的建议 进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道,获取高质量博客内容! 一、分桶Bucket
Doris数据表存储中,如果有分区&…
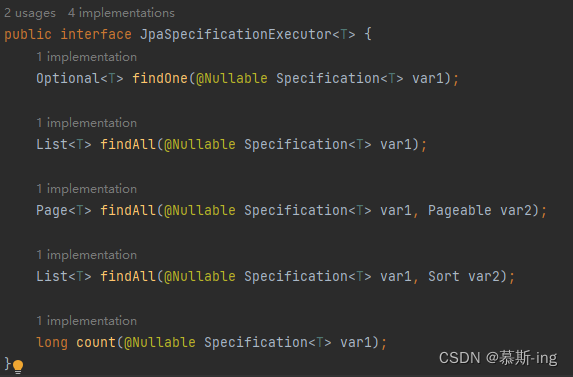
02.用户信息UserDetails相关入门
1. 前言
前一篇介绍了 Spring Security 入门的基础准备。从这篇开始我们来一步步窥探它是如何工作的。我们又该如何驾驭它。本篇将通过 Spring Boot 2.x 来讲解 Spring Security 中的用户主体UserDetails。以及从中找点乐子。
2. Spring Boot 集成 Spring Security
这个简直…
Apache Doris 入门教程31:计算节点
需求场景
目前Doris是一个典型Share-Nothing的架构, 通过绑定数据和计算资源在同一个节点获得非常好的性能表现. 但随着Doris计算引擎性能持续提高, 越来越多的用户也开始选择使用Doris直接查询数据湖数据. 这类场景是一种Share-Disk场景, 数据往往存储在远端的HDFS/S3上, 计…
Hive生成日期维度表
1、时间维表(完整版)
1)、 建表
-- 时间维表 完整版
create table if not exists dim.dim_date (date_id string comment 日期(yyyymmdd)
,datestr string comment 日期(yyyy-mm-dd)
…
商业智能BI是什么都不明白,如何实现数字化?
2021年下半年中国商业智能软件市场规模为4.8亿美元,2021年度市场规模达到7.8亿美元,同比增长34.9%,呈现飞速增长的趋势。数字化时代,商业智能BI对于企业的落地应用有着巨大价值,逐渐成为了现代企业信息化、数字化转型中…
电商数仓项目需求及架构设计
一、项目需求 1.用户行为数据采集平台搭建 2.业务数据采集平台搭建 3.数仓维度建模 4.统计指标 5.即席查询工具,随时进行指标分析 6.对集群性能进行监控,发生异常时报警(第三方信息) 7.元数据管理 8.质量监控 9.权限管理ÿ…
二、数据仓库和数据挖掘的OLAP技术
数据仓库和数据挖掘的OLAP技术 引言一、什么是数据仓库二、数据仓库的关键特征2.1、面向主题2.2、数据集成2.3、随时间而变化2.4、数据不易丢失三、数据仓库的构建和使用四、数据仓库与操作数据库系统五、多维数据模型引言 数据仓库中的数据清理和数据集成,是数据挖掘的重要数…
电商平台api对接货源
如今,电商平台已经成为了人们购物的主要途径之一。 然而,对于电商平台来说,货源对接一直是一个比较棘手的问题。为了解决这个问题,越来越多的电商平台开始使用API来对接货源。 API,即应用程序接口,是一种允…

天软高频因子日内及隔夜动量因子
天软因子序列课程再次启动,本周四(9月7日)下午4点相约腾讯会议,可直接扫描下方二维码,欢迎大家参会! 本次会议主要内容有: 1.介绍日内及隔夜动量因子的构造逻辑,如何选择市 场代理变…

基于c#的 EntityFramework搭建
一、数据库的建立
安装Navicat for MySQL,用于连接Mysq数据库,可以进行可视化操作 打开之后,新建连接,输入连接名(自定义),主机名(IP地址localhost也就是本地的IP地址,localhost127…
无限访问 GPT-4,OpenAI 强势推出 ChatGPT 企业版!
继 ChatGPT 收费大降价、推出 App 版等系列动作之后,OpenAI 于今日宣布正式发布面向企业的 AI 助手——ChatGPT Enterprise 版。
与 To C 端的 ChatGPT 版本有所不同的是,该版本可以以更快速度无限制地访问 GPT-4,还可以用来处理更长输入的上…
国家开放大学统一训练题
中级财务会计(二) 参考试题 一、单项选择题(从下列每小题的四个选项中选择一个正确的,将其序号填入题中的括号里。每小题3分,共30分)
1.资产负债表日,对预提的当期短期借款利息,贷…

【大数据】美团 DB 数据同步到数据仓库的架构与实践
美团 DB 数据同步到数据仓库的架构与实践 1.背景2.整体架构3.Binlog 实时采集4.离线还原 MySQL 数据5.Kafka2Hive6.对 Camus 的二次开发7.Checkdone 的检测逻辑8.Merge9.Merge 流程举例10.实践一:分库分表的支持11.实践二:删除事件的支持12.总结与展望 1…
什么是数据仓库,解释数据仓库的结构和ETL过程
1、什么是数据仓库,解释数据仓库的结构和ETL过程。
数据仓库是一种用于存储和管理数据的系统,它提供了一种统一的方式,将不同来源、不同格式和不同时间的数据集成在一起。数据仓库的结构如下:
主题域(Domain…
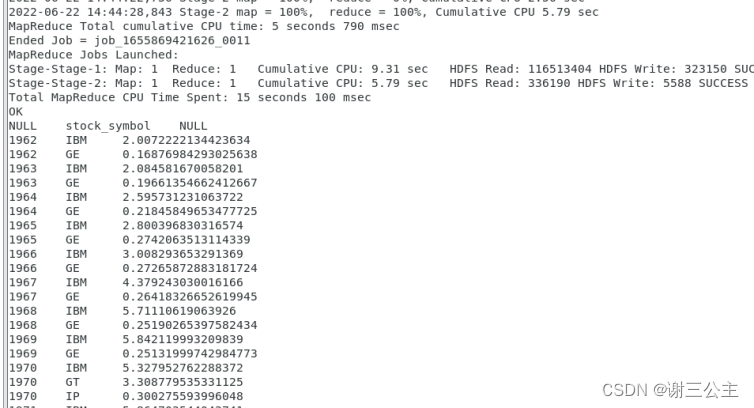
实验五 熟悉 Hive 的基本操作
实验环境: 1.操作系统:CentOS 7。 2.Hadoop 版本:3.3.0。 3.Hive 版本:3.1.2。 4.JDK 版本:1.8。 实验内容与完成情况:
(1)创建一个内部表 stocks,字段分隔符为英文逗号…
在Spark中集成和使用Hudi
本文介绍了在Spark中集成和使用Hudi的功能。使用Spark数据源API(scala和python)和Spark SQL,插入、更新、删除和查询Hudi表的代码片段。 1.安装 Hudi适用于Spark-2.4.3+和Spark 3.x版本。 1.1 Spark 3支持矩阵 Hudi
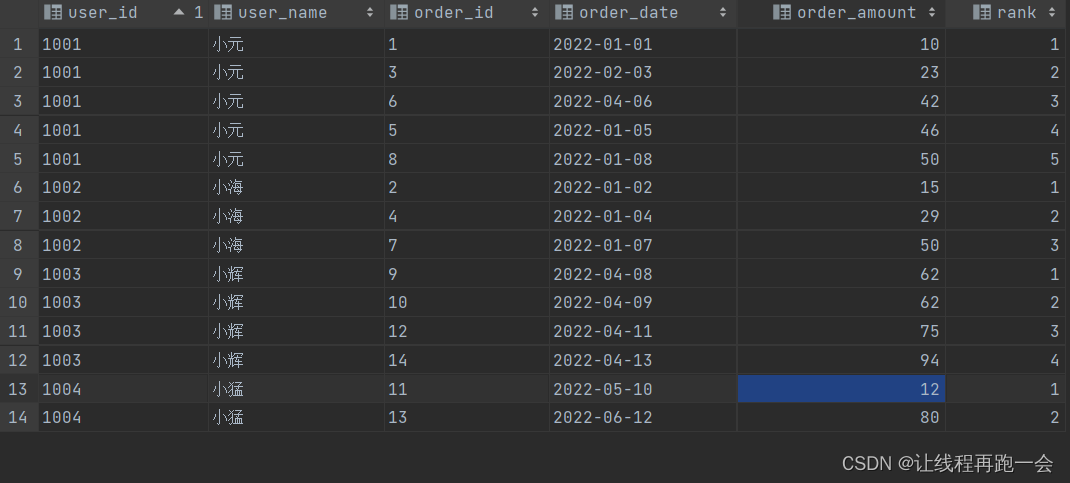
Hive 【Hive(七)窗口函数练习】
窗口函数案例
数据准备
1)建表语句
create table order_info
(order_id string, --订单iduser_id string, -- 用户iduser_name string, -- 用户姓名order_date string, -- 下单日期order_amount int -- 订单金额
);
2)装载语句
i…
Hive中生成自增序列的常用方法
在日常业务开发过程中,通常遇到需要hive数据表中生成一列唯一ID,当然连续递增的更好。
最近在结算业务中,需要在hive表中生成一列连续且唯一的账单ID,于是就了解生成唯一ID的方法
1. 利用row_number函数
语法:row_n…
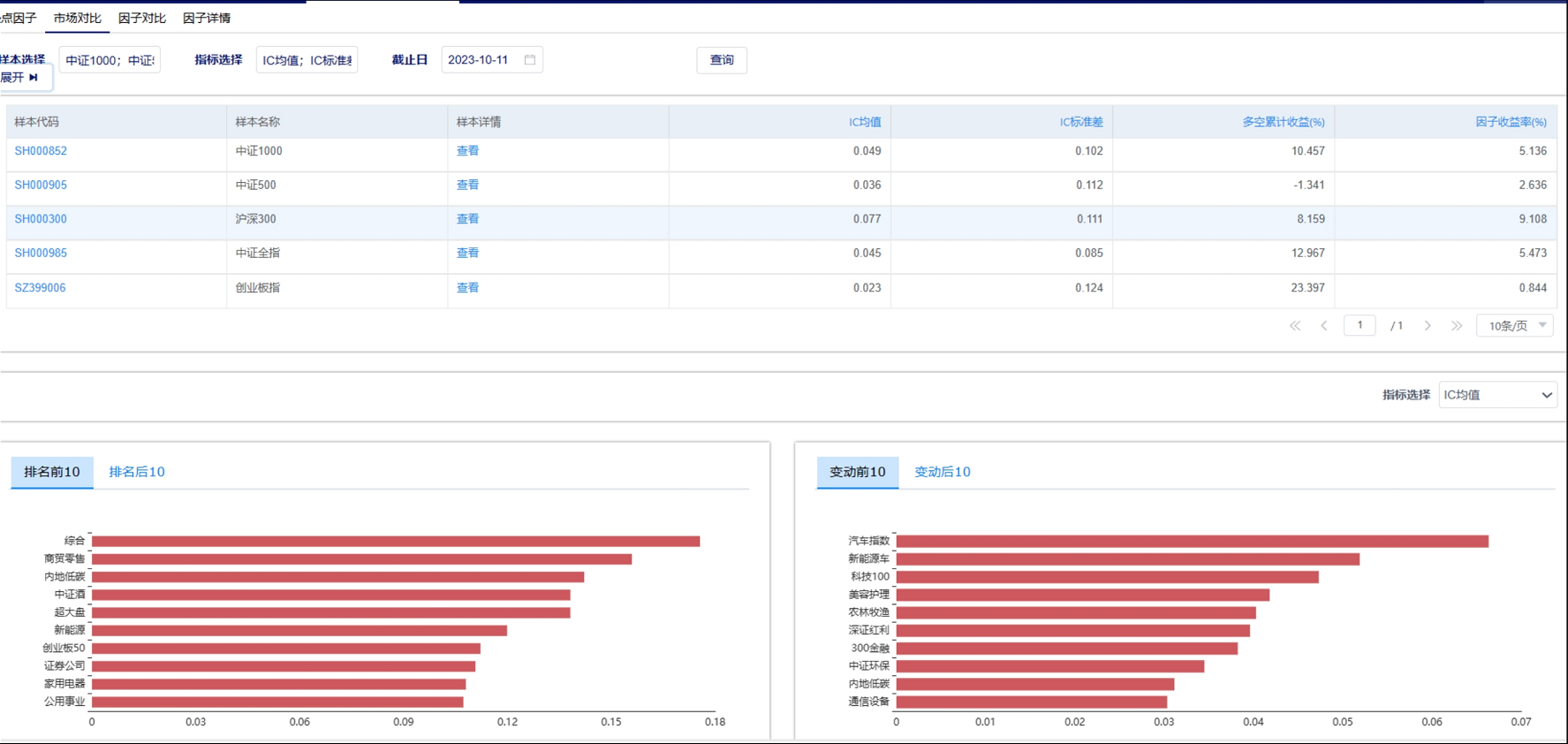
天软特色因子看板 (2023.10 第03期)
该因子看板跟踪天软特色因子A05005(近一月单笔流通金额占比(%),该因子为近一个月单笔流通金额占比因子,用以刻画股票在收盘时,主力资金在总交易金额中所占的比重。。 今日为该因子跟踪第03期,跟踪其在SH000852 (中证1000) 中的表现…
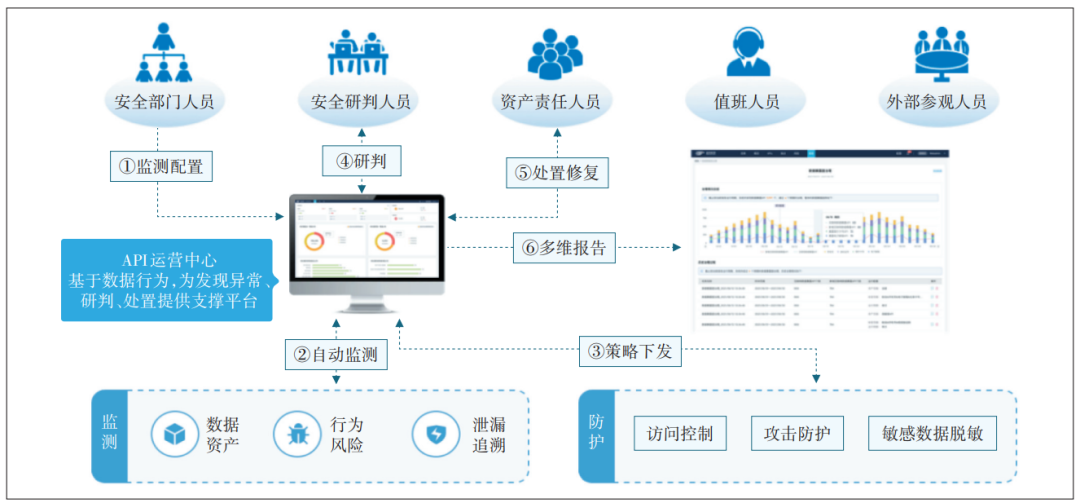
API接口安全运营研究(内附官方开发平台api接口接入方式)
摘 要 根据当前API技术发展的趋势,从实际应用中发生的安全事件出发,分析并讨论相关API安全运营问题。从风险角度阐述了API接口安全存在的问题,探讨了API检测技术在安全运营中起到的作用,同时针对API安全运营实践,提出…
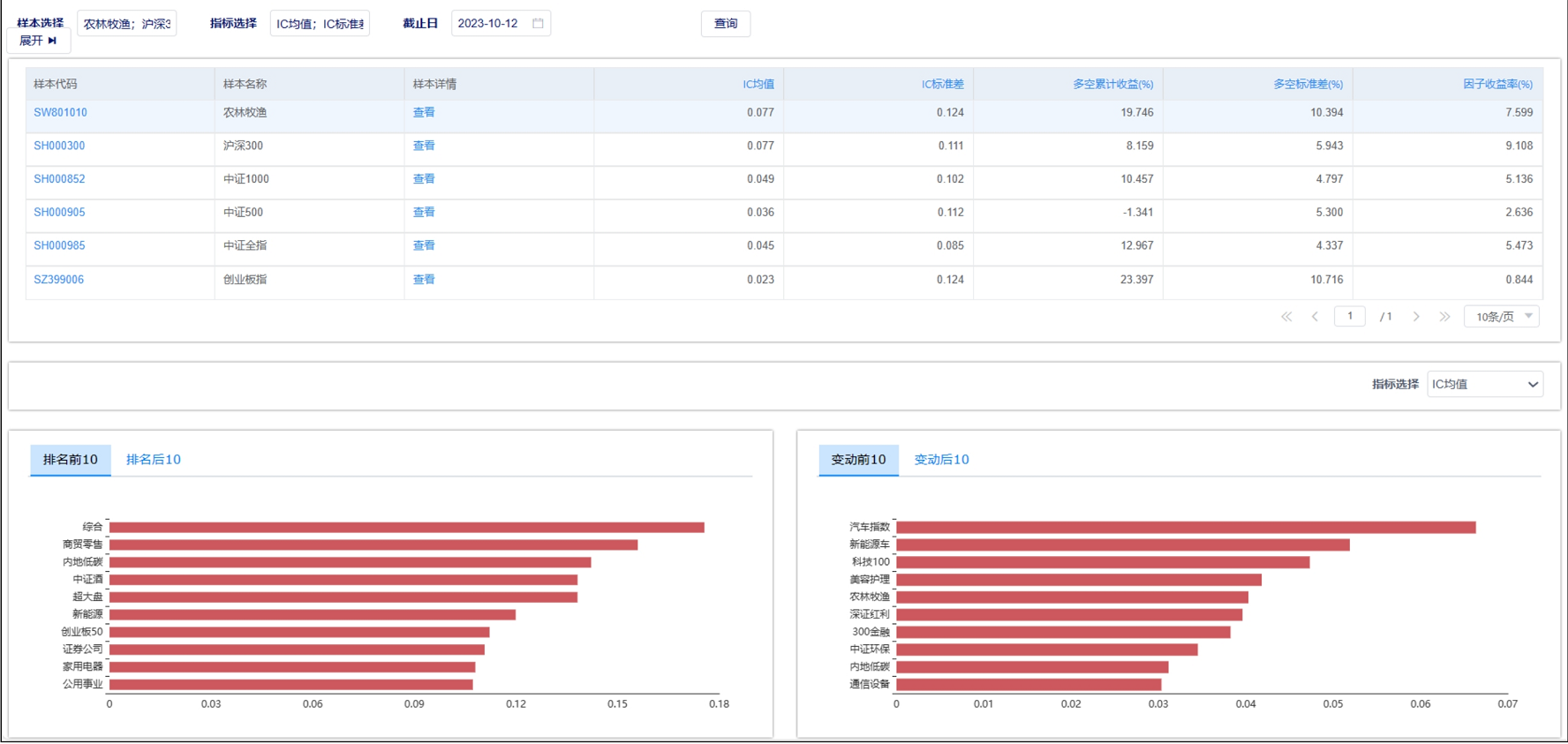
天软特色因子看板(2023.10 第04期)
该因子看板跟踪天软特色因子A05005(近一月单笔流通金额占比(%),该因子为近一个月单笔流通金额占比因子,用以刻画股票在收盘时,主力资金在总交易金额中所占的比重。。 今日为该因子跟踪第04期,跟踪其在SW801010 (申万农林牧渔) 中的…
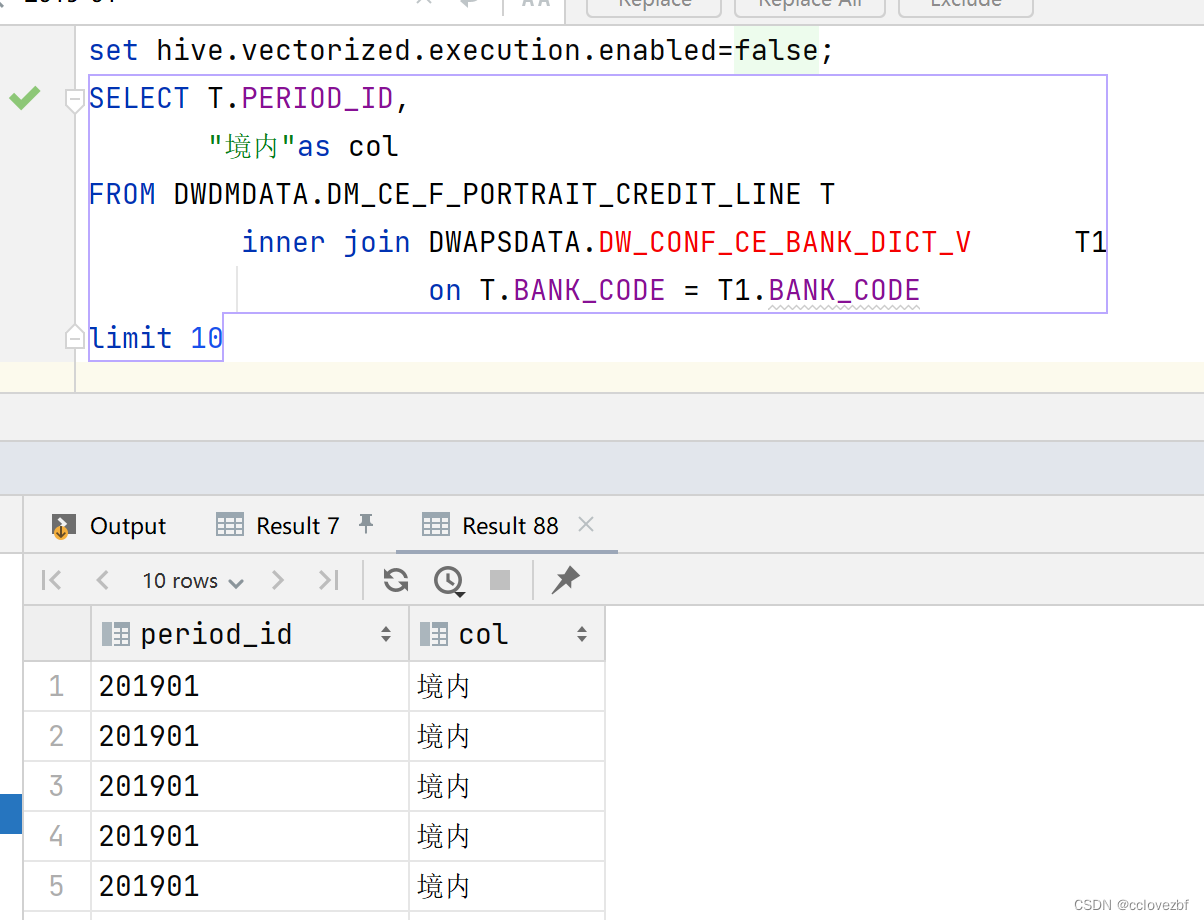
hive 之select 中文乱码
此处的中文乱码和mysql的库表 编码 latin utf 无关。
直接上案例。
有时候我们需要自定义一列,有时是汉字有时是字母,结果遇到这种情况了。 说实话看到这真是糟心。这谁受得了。
单独select 没有任何问题。 这是怎么回事呢? 经过一番检查&…
Spark的转换算子和操作算子
1 Transformation转换算子 1.1 Value类型 1)创建包名:com.shangjack.value 1.1.1 map()映射 参数f是一个函数可以写作匿名子类,它可以接收一个参数。当某个RDD执行map方法时,会遍历该RDD中的每一个数据项,并依次应用f函…
clickhouse系列4: clickhouse分析航班数据
1.准备数据集 2.clickhouse中建表 CREATE TABLE `ontime`
(`Year` UInt16,`Quarter` UInt8,`Month` UInt8,`DayofMonth`
S/4 HANA 大白话 - 财务会计-4 应付、应收账款
Business Partner 业务伙伴
业务伙伴现在包括供应商伙伴和客户伙伴。
只要不是个搞空壳玩泡沫的公司,你基本都得有从供应商那里拿原材料或者购买零部件,然后进行生产,再售卖给客户。你得和银行打交道,同时也得有员工。所有这些关…
基于Linux上MySQL8.*版本的安装-参考官网
本地hadoop环境安装好,并安装好mysql,下载hive安装包
mysql下载地址及选择包
MySQL :: Download MyS的QL Community Server (Archived Versions) mysql安装步骤
下载与上传解压给权限
#mysql安装包上传到/opt下
cd /usr/local/
#解压到此目录
tar -xvf /opt/mys…
spark3使用hive zstd压缩格式总结
ZSTD(全称为Zstandard)是一种开源的无损数据压缩算法,其压缩性能和压缩比均优于当前Hadoop支持的其他压缩格式,本特性使得Hive支持ZSTD压缩格式的表。Hive支持基于ZSTD压缩的存储格式有常见的ORC,RCFile,Te…
Apache Doris 2.0.2 版本正式发布!
峰会官网已上线,最新议程请关注:doris-summit.org.cn 点击报名 亲爱的社区小伙伴们,Apache Doris 2.0.2 版本已于 2023 年 10 月 6 日正式发布,该版本对多个功能进行了更新优化,旨在更好地满足用户的需求。有 92 位贡献…
汽车4S店如何在数字化管理下,提高市场竞争力
在所有人都认为疫情过后,经济形势会一路向阳,但是,实际情况出乎所有人的意料,各行各业举步维艰。
新闻爆出的各大房地产,恒大的2.4万亿让人瞠目结舌,还有碧桂园和融创,也是债台高筑了ÿ…

vuex——计算属性获取的getter值需要刷新才能更新
vuex——计算属性获取的getter值需要刷新才能更新
描述: // statestate: {leader: null},// gettersgetters: {getLead: state > state.leader}// mutationsmutations: {setLead (state, data) {state.leader data}},
// 页面中赋值
// 登录时改变state.leader…
Hive获取连续时间用 posexplode
获取连续的日期
假如我们需要获取2020-07-15至2020-07-21间所有的日期,可以像这样写
SELECTpos,date_add( start_date, pos ) dd
FROM( SELECT 2020-07-15 AS start_date, 2020-07-21 AS end_date ) temp lateral VIEW posexplode ( split ( space( datediff( end_date, sta…

MySQL知识笔记——初级基础(实施工程师和DBA工作笔记)
老生长谈,MySQL具有开源、支持多语言、性能好、安全性高的特点,广受业界欢迎。 在数据爆炸式增长的年代,掌握一种数据库能够更好的提升自己的业务能力(实施工程师)。 此系列将会记录我学习和进阶SQL路上的知识…
高效数据湖构建与数据仓库融合:大规模数据架构最佳实践
文章目录 数据湖和数据仓库:两大不同理念数据湖数据仓库 数据湖与数据仓库的融合统一数据目录数据清洗和转换数据安全和权限控制数据分析和可视化 数据湖与数据仓库融合的优势未来趋势云原生数据湖自动化数据处理边缘计算与数据湖融合 结论 🎉欢迎来到云…
Hadoop生态圈中的Hive数据仓库技术
Hadoop生态圈中的Hive数据仓库技术 一、Hive数据仓库的基本概念二、Hive的架构组成三、Hive和数据库的区别四、Hive的安装部署五、Hive的基本使用六、Hive的元数据库的配置问题七、Hive的相关配置项八、Hive的基本使用方式1、Hive的命令行客户端的使用2、使用hiveserver2方法操…

无代码:软件开发从代码语言到业务语言的拐点
在互联网巨头和中小企业纷纷追求移动互联和“上云”的今天,业务在线已成为众多企业数字化转型的必经之路。然而,传统的软件重装开发模式已经无法满足企业快速变化的需求,同时IT专业人才的成本也在不断攀升,使得企业的IT交付能力面…

Datax 数据同步-使用总结(二)
一、前言
这部分主要记录 datax 实现增量同步的方案。
二、核心思路
结合datax 提供的preSql、 postSql以及占位符,外加另外一张表同步日志表来记录相关同步信息。
三、版本迭代
3.1 初版本
where tbq.opera_date > cast(date_format(DATE_SUB(NOW(), inte…

【hive】列转行—collect_set()/collect_list()/concat_ws()函数的使用场景
文章目录 一、collect_set()/collect_list()二、实际运用把同一分组的不同行的数据聚合成一个行用下标可以随机取某一个聚合后的中的值用‘|’分隔开使用collect_set()/collect_list()使得全局有序 一、collect_set()/collect_list()
在 Hive 中想实现按某字段分组,…

Hive实战-表创建
Hive实战-表创建 使用ORC压缩储存空间 使用ORC压缩储存空间
什么是ORC? ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式。
ORC是列式存储,有多种文件压缩方式,并且有着很高的压缩比。文件…

Small Tip: 如何实现从Eclipse里面直接跳转到Analysis for Office
查看ADSO或者CP的数据时,一般情况下,预览只能有这两个选项。
可以扩展成以下这样: 方法:
SPRO-> 选参数,填文本。然后重启Eclipse.

Iceberg 基础知识与基础使用
1 Iceber简介
1.1 概述
为了解决数据存储和计算引擎之间的适配的问题,Netflix开发了Iceberg,2018年11月16日进入Apache孵化器,2020 年5月19日从孵化器毕业,成为Apache的顶级项目。 Iceberg是一个面向海量数据分析场景的开放表格…

电大搜题——搜索难题
添加图片注释,不超过 140 字(可选) 广东开放大学是一所素有口碑的知名学府,一直致力于为广大学员提供优质的教育资源和学习支持。随着科技的不断发展,电子学习成为了现代学习的主要方式之一。为了更好地满足学员的学习…
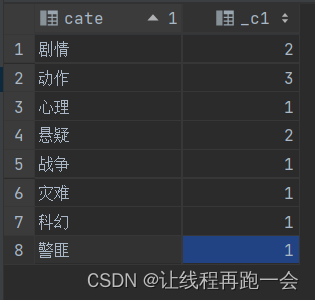
Hive【Hive(五)函数-高级聚合函数、炸裂函数】
高级聚合函数
多进一出(多行输入,一个输出)
普通聚合函数:count、sum ...
1)collect_list():收集并形成 list 集合,结果不去重
select sex,collect_list(job)
from e…
【数据仓库基础(三)】抽取-转换-装载
文章目录 一. ETL概念二. 数据抽取1.逻辑抽取2.物理抽取3.变化数据捕获 三. 数据转换四. 数据装载 一. ETL概念
ETL一词,它是Extract、Transform、Load三个英文单词首字母的简写,中文意为抽取、转换、装载。ETL是建立…
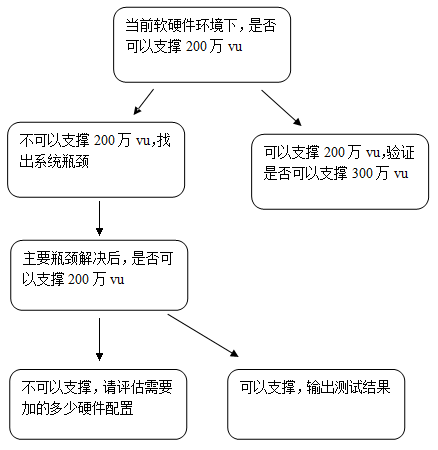
淘宝官方开放平台API接口获得店铺的所有商品、商品id、商品标题、销量参数调用示例
在电商平台中,获取店铺所有商品是一个非常常见的需求。这个功能允许用户一次性获取指定店铺中的所有商品信息,方便用户对店铺的商品进行浏览和筛选。下面将对获取店铺所有商品接口的功能进行介绍。
获取全部商品信息:通过调用获取店铺所有商…
电大搜题:开启智慧学习新时代
近年来,随着社会的发展和科技的迅猛进步,远程教育成为了广大学子继续教育的新选择。而在重庆,一所备受关注的远程教育学府——重庆开放大学,以其开放的教育理念和多元的学习方式,为广大学生提供了便捷而高效的学习平台…

玩转大数据7:数据湖与数据仓库的比较与选择
1. 引言
在当今数字化的世界中,数据被视为一种宝贵的资源,而数据湖和数据仓库则是两种重要的数据处理工具。本文将详细介绍这两种工具的概念、作用以及它们之间的区别和联系。
1.1. 数据湖的概念和作用
数据湖是一个集中式存储和处理大量数据的平台&a…

Hive 的权限管理
目录
编辑
一、Hive权限简介
1.1 hive中的用户与组
1.1.1 用户
1.1.2 组
1.1.3 角色
1.2 使用场景
1.2.1 hive cli
1.2.2 hiveserver2
1.2.3 hcatalog api
1.3 权限模型
1.3.1 Storage Based Authorization in the Metastore Server
1.3.2 SQL Standards Based …
尚硅谷大数据项目《在线教育之实时数仓》笔记005
视频地址:尚硅谷大数据项目《在线教育之实时数仓》_哔哩哔哩_bilibili 目录
第9章 数仓开发之DWD层
P031
P032
P033
P034
P035
P036
P037
P038
P039
P040 第9章 数仓开发之DWD层
P031 DWD层设计要点: (1)DWD层的设计依…
国家开放大学期末统一考试 测试题
试卷代号:1472 药剂学(本) 参考试题 一、单项选择题(每题2分,共60分)
1.阿司匹林水溶液的pH值下降说明其主要发生了( )。 A.氧化反应 B.水解反应…
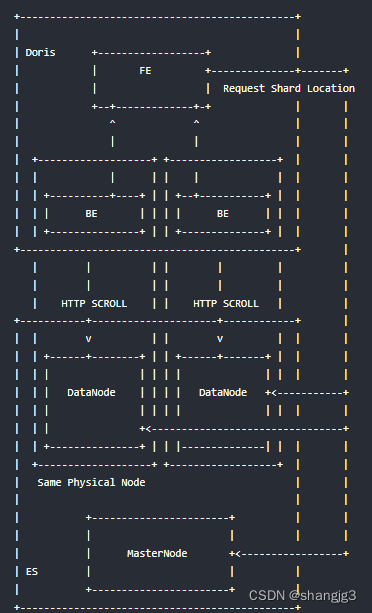
Doris 集成 ElasticSearch
Doris-On-ES将Doris的分布式查询规划能力和ES(Elasticsearch)的全文检索能力相结合,提供更完善的OLAP分析场景解决方案: (1)ES中的多index分布式Join查询 (2)Doris和ES中的表联合查询,更复杂的全文检索过滤 1 原理 (1)创建ES外表后,FE会请求建表指定的主机,获取所有…
【Hive-小文件合并】Hive外部分区表利用Insert overwrite的暴力方式进行小文件合并
这里我们直接用实例来讲解,Hive外部分区表有单分区多分区的不同情况,这里我们针对不同情况进行不同的方式处理。
利用overwrite合并单独日期的小文件
1、单分区
# 开启此表达式:(sample_date)?.
set hive.support.quoted.identifiersnon…

Python操作Hive数据仓库
Python连接Hive 1、Python如何连接Hive?2、Python连接Hive数据仓库 1、Python如何连接Hive? Python连接Hive需要使用Impala查询引擎
由于Hadoop集群节点间使用RPC通信,所以需要配置Thrift依赖环境
Thrift是一个轻量级、跨语言的RPC框架&…
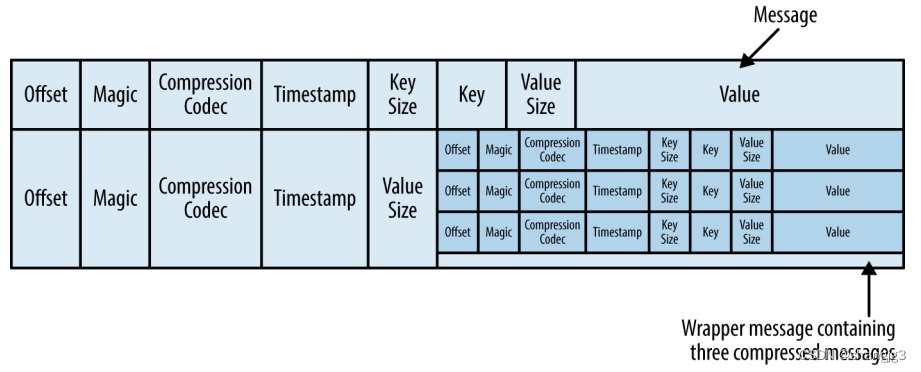
深入理解Kafka分区副本机制
1. Kafka集群 Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息。每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文件 server.properties 中进行配置,或者由程序自动生成。下面是 Kafka brokers 集群自…

浅谈关于数据仓库的理解,聊聊数据仓库到底是什么?
不知不觉间,我们的生活中已经充满了数据,各种岗位例如运营、市场、营销上也都喜欢在职位要求加上一条利用数据、亦或是懂得数据分析。事实上,数据已经成为了构建现代社会的基本生产要素,并且因为不受自然环境的限制,已…
hive anti join 的几种写法
t_a 表的记录如下
c1 | :———— | a | b | c |
生成 SQL 如下:
create table t_a(c1 string);
insert into t_a values("a"),("b"),("c");t_b 表的记录如下
c1bm
生成 SQL 如下:
create table t_b(c1 string);
in…
ETL数据转换方式有哪些
ETL数据转换方式有哪些
ETL(Extract, Transform, Load)是一种常用的数据处理方式,用于从源系统中提取数据,进行转换,并加载到目标系统中。
数据清洗(Data Cleaning)&am…
Hive字符串数组json类型取某字段再列转行
一、原始数据
acctcontent1232313[{"name":"张三","code":"上海浦东新区89492jfkdaj\r\n福建的卡"...},{"name":"狂徒","code":"select * from table where aa1\r\n and a12"...},{...}]...…

Hive 解析 JSON 字符串数据的实现方式
文章目录 通过方法解析现实示例 通过序列化实现示例 通过方法解析现实
在 Hive 中提供了直接解析 JSON 字符串数据的方法 get_json_object(json_txt, path),该方法参数解析如下: json_txt:顾名思义,就是 JSON 字符串;…
数据平台权限控制-基于猛犸
设置多项目: 专注本项目的逻辑和代码,不在本项目内的人员无法查看代码逻辑,但是可查询表 每张表的存储路径 如下 hdfs://cluster1/user/jmkx_data/hive_db/jmkx_data.db/ods_plm_newbudget_budgetcostreport_dd
在hive查询 两种方式都可以
…
三分钟,教你做出领导满意的可视化报表
数字化已然成为社会发展的共识,企业想要在未来的竞争中占据优势,获取不断发展的数字经济,就必须将数据看作企业的战略资源,利用数据可视化将数据转化为信息,促进企业发展。
数据可视化是什么
在早期数据分析领域&…
Hive的analyze
1、使用
分区表,无论字段
analyze TABLE td.pt_pmart_ceo_FIN_TRSF_CTR_SITE_MAP partition (dt) COMPUTE STATISTICS noscan
ps:一致报错的可能性在UDF函数建在了某个库下 ,只有在hue上的active database选择某个库的时候才能用UDF
2、目的
见名知意,它的目的就是为…
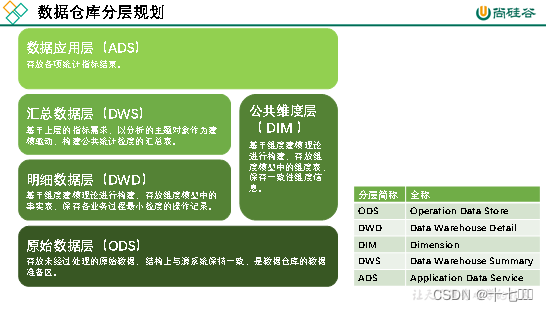
【数据仓库基础(四)】数据仓库需求:基本需求和数据需求
文章目录 一. 基本需求1. 安全性2. 可访问性3. 自动化 三. 数据需求1. 准确性2.时效性3.历史可追溯性 从基本需求和数据需求两方面介绍对数据仓库系统的整体要求。
一. 基本需求
1. 安全性
数据仓库中含有机密和敏感的数据。为了能够使用这些数据&…
国家开放大学 训练题
试卷代号:2044 教育研究方法 参考试题(开卷) 一、单选题(每题5分,共25分)
1.探索性研究常采用的研究方式包括( )。 A.文献调查、经验调查、典型情况或个案分析 B.调查性研究、…

BI是什么?想要了解BI需要从哪些方面入手?
企业为了执行数字化战略,实行数字化转型,实现数据价值,除了需要相关数字化技术及理念、人才等,还需要借助数字化相关应用,例如商业世界中广受企业欢迎的ERP、OA、CRM等业务信息系统,以及上升势头非常迅猛的…

2 快速上手使用Paimon数据湖
2.1 基于Flink SQL操作Paimon
在这里我们基于Flink 1.15(ON YARN)、Paimon 0.5版本开发一个案例。 注意:想要使用Paimon是非常简单的,不需要复杂的安装部署,只需要使用一个jar包即可对它进行操作。 我们在使用Paimon的时候其实也可以把它简单…
SQL Server SSIS ETL job执行相关操作
创建SSIS项目 Excel导入SQL Server
构建Excel源 配置Excel源信息 配置SQL Server目标
双击“ADO NET目标”
job执行
新建job
右键“SQL Server代理”的“作业”,点击“新建作业”,弹出“新建作业”的选项页 首先是“常规”选项页,…
国家开放大学 练习题
学前儿童社会教育活动指导 参考试题 一、单项选择题(每小题3分,共30分)
1.《规程》第三十二条规定:“幼儿园应当充分尊重幼儿的个体差异,根据幼儿不同的心理
发展水平,研究有效的活动形式和方法&am…

【hive】—原有分区表新增加列(alter table xxx add columns (xxx string) cascade;)
项目场景:
需求:需要在之前上线的分区报表中新增加一列。 实现方案:
1、创建分区测试表并插入测试数据
drop table test_1;
create table test_1
(id string,
score int,
name string
)
partitioned by (class string)
row format delimit…

工程建筑模板厂家货源,酚醛胶镜面胶合板实用型
作为工程建筑模板厂家,我们提供高品质的酚醛胶镜面胶合板,为建筑行业的模板需求提供可靠的货源。我们的产品以实用型为设计理念,旨在满足各类工程的施工需求并提供出色的性能。我们的酚醛胶镜面胶合板采用优质的木材作为原材料,经…
数智化,如何驱动高校的产教融合
高校数智驱动是指通过运用先进的技术和智能化的手段,推动高校的发展和创新。这包括利用大数据分析、人工智能、物联网等技术来提高高校的管理效率、教学质量和科研水平。 高校实施数智驱动考虑的几个方面
(1)建立数据驱动的决策机制…
【跟小嘉学 Apache Flink】二、Flink 快速上手
系列文章目录
【跟小嘉学 Apache Flink】一、Apache Flink 介绍 【跟小嘉学 Apache Flink】二、Flink 快速上手 文章目录 系列文章目录[TOC](文章目录) 一、创建工程1.1、创建 Maven 工程1.2、log4j 配置 二、批处理单词统计(DataSet API)2.1、创建 Bat…

hive和spark-sql中 日期和时间相关函数 测试对比
测试版本:
hive 2.3.4 spark 3.1.1 hadoop 2.7.7
1、增加月份
add_months(timestamp date, int months)add_months(timestamp date, bigint months)Return type: timestampusage:add_months(now(),1) 2、增加日期
adddate(timestamp startdate, int days)…
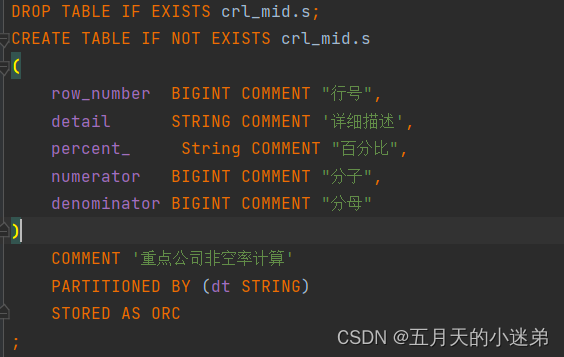
hive里因为列名用了关键字导致建表失败
代码 现象 ParseException line 6:4 cannot recognize input near percent String COMMENT in column name or primary key or foreign key 23/11/13 11:52:57 ERROR org.apache.hadoop.hive.ql.Driver: FAILED: ParseException line 6:4 cannot recognize input near percent …
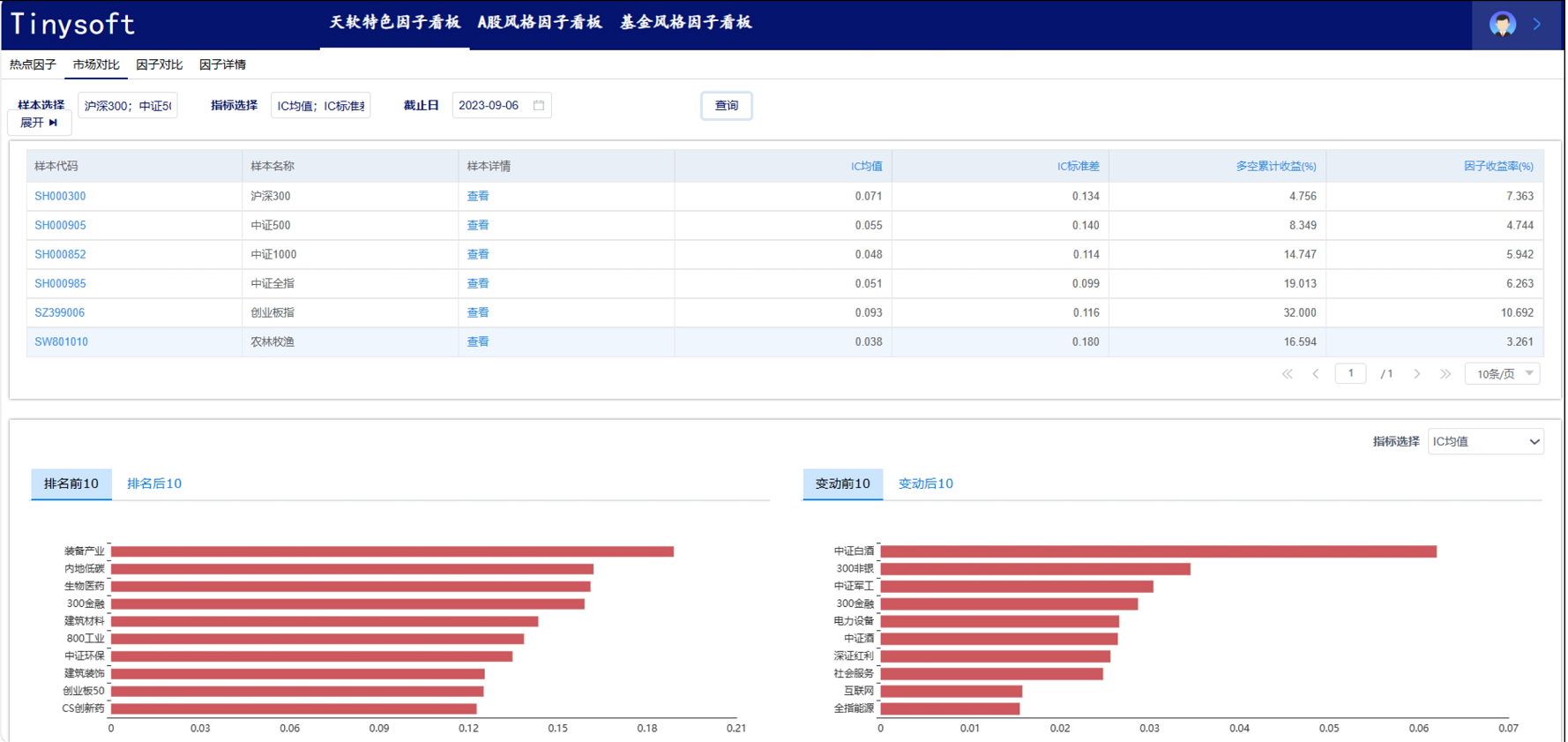
天软特色因子看板 (2023.09 第04期)
该因子看板跟踪天软特色因子A02002(近一月尾盘成交占比(%),该因子为近一个月尾盘成交量占比均值因子,用以刻画股票在收盘时,主力资金的流动影响。 今日为该因子跟踪第04期,跟踪其在SH801010 (农林牧渔) 中的表现,要点如…
hive 创建 s3 外表
背景
有个比较大的技术侧需求: 将数据从 HDFS 迁移到 s3。当然在真正迁移之前,还需要验证迁移到 s3 的数据,和上层查询器(hive、presto 之间的兼容性)
这里我们对一张业务表的数据做个简单的迁移测试
验证
数据迁移
为了让 h…
API调用展示,淘宝、天猫、拼多多商品页面详情实时数据API接口,APP端原数据参数返回
商品详情API接口可以提供商品的基本信息,如名称、描述、价格、图片等,帮助电子商务平台展示和推荐商品。此外,还可以提供商品的库存信息、销售数据、评论信息等,帮助平台进行数据分析和管理。
item_get_app_pro-根据ID取商品详情…
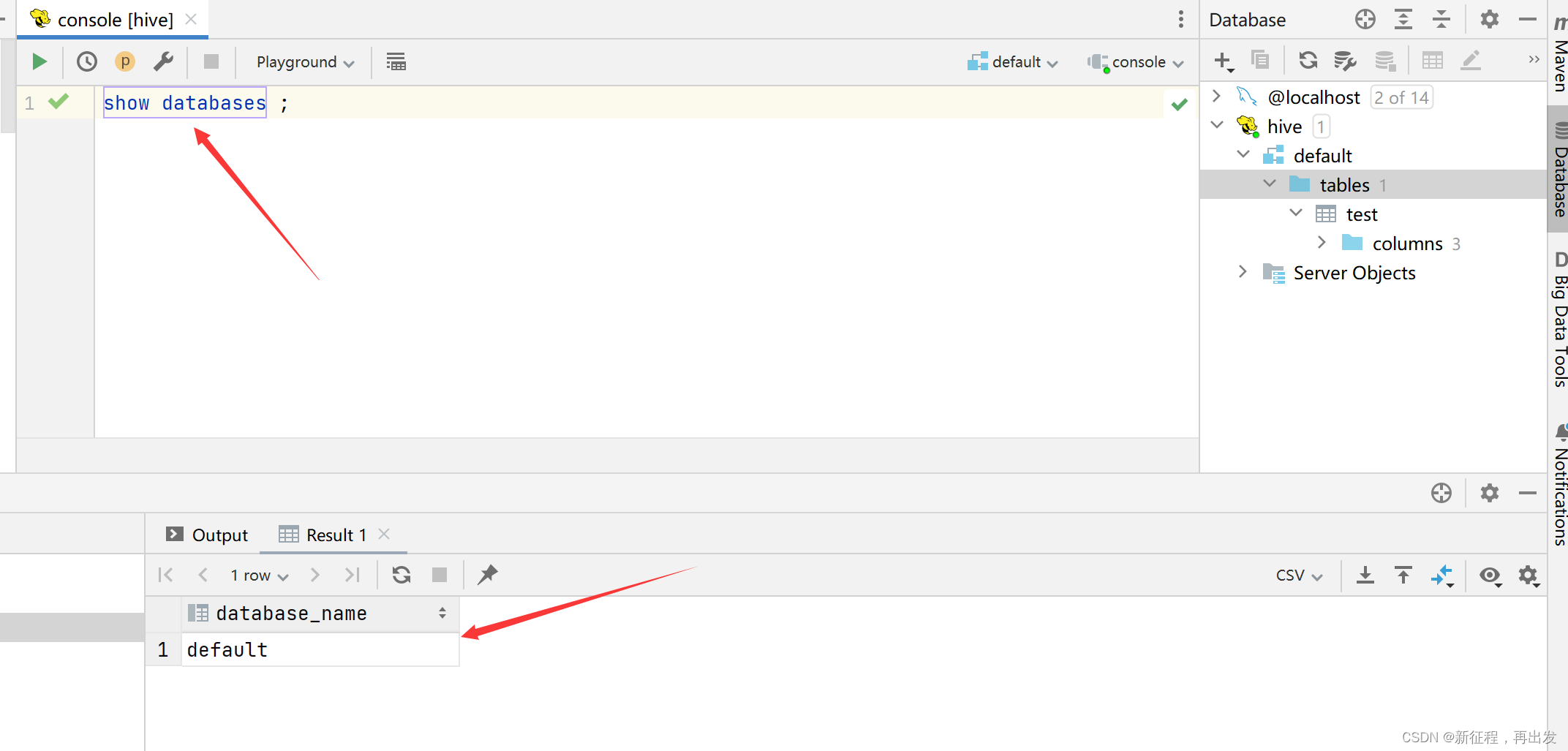
Hive部署,hive客户端
1、Hive部署
Hive是分布式运行的框架还是单机运行的?
Hive是单机工具,只需要部署在一台服务器即可。Hive虽然是单机的,但是它可以提交分布式运行的MapReduce程序运行。
1.1、规划
我们知道Hive是单机工具后,就需要准备一台服务…
元数据管理,数字化时代企业的基础建设
随着新一代信息化、数字化技术的应用,众多领域通过科技革命和产业革命实现了深度化的数字改造,进入到以数据为核心驱动力的,全新的数据处理时代,并通过业务系统、商业智能BI等数字化技术和应用实现了数据价值,从数字经…

2023.11.14-hive的类SQL表操作之,4个by区别
目录 1.表操作之4个by,分别是
2.Order by:全局排序
3.Cluster by
4.Distribute by :分区
5. Sort by :每个Reduce内部排序
6.操作练习
步骤一.创建表
步骤二.加载数据 步骤三.验证数据 1.表操作之4个by,分别是
order by 排序字段名
cluster by 分桶并排序字段名
dis…
在Flink中集成和使用Hudi
本文介绍在Flink 中集成和使用Hudi。介绍Flink如何将Streaming引入Hudi。在Hudi上使用Flink,并学习Flink读写Hudi的不同模式: Flink SQL客户端写入:Flink SQL客户端写入(读取)Hudi。 配置:对于全局配置,通过$FLINK_HOME/conf/FLINK-conf.yaml进行设置。对于每个作业配置…

如何做好互联网产品需求分析?看这里!
文章目录 🌟需求分析🍊领域知识分析🍊技术知识分析🎉人工智能技术的基本原理🎉开发工具和组件库🎉数据处理和模型训练🎉代码库和技术标准 🍊数据分析🎉准备数据…
hive复合类型的数据查询
hive数据表创建-CSDN博客 --第一个名字以M开头的 访问数组array 数组( array) 引用方式 列名 [ 元素索引 _ 以 0 开始 ] select * from emp
where emp_name[0] rlike "^M"; -- 出生日期是在 5 几年 访问 Map map 引用方式 列名 ["Key"] selec…
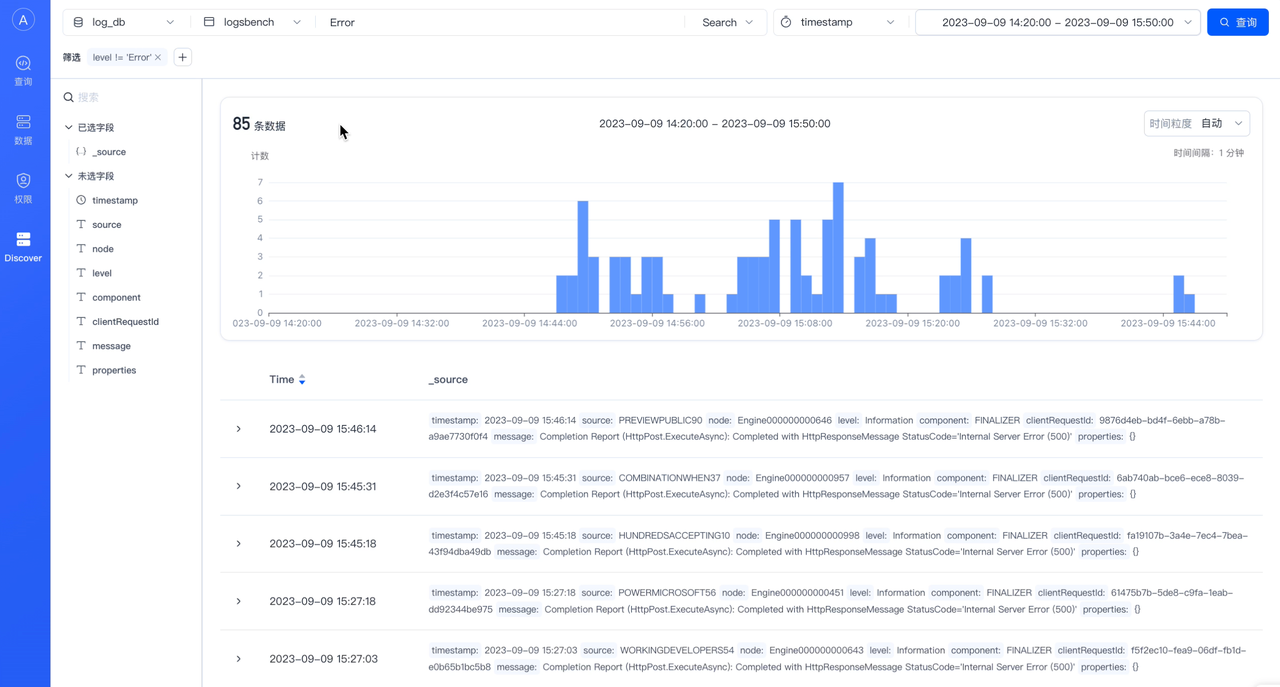
查询平均提速 700%,奇安信基于 Apache Doris 升级日志安全分析系统
本文导读:
数智时代的到来使网络安全成为了不可忽视的重要领域。奇安信作为一家领先的网络安全解决方案领军者,致力于为企业提供先进全面的网络安全保护,其日志分析系统在网络安全中发挥着关键作用,通过对运行日志数据的深入分析…

集团公司管控的三种模式:财务管控、运营管控、战略管
集团管控是集团公司通过对子公司采用层级的管理控制、资源的协调分配等策略和方式,使集团的组织架构和业务流程达到最佳运作效率的管理体系。 不同的集团管控模式决定了不同的财务管控方式。但不论采取何种管控模式,集团对财务的管理与控制都是其最为核心…
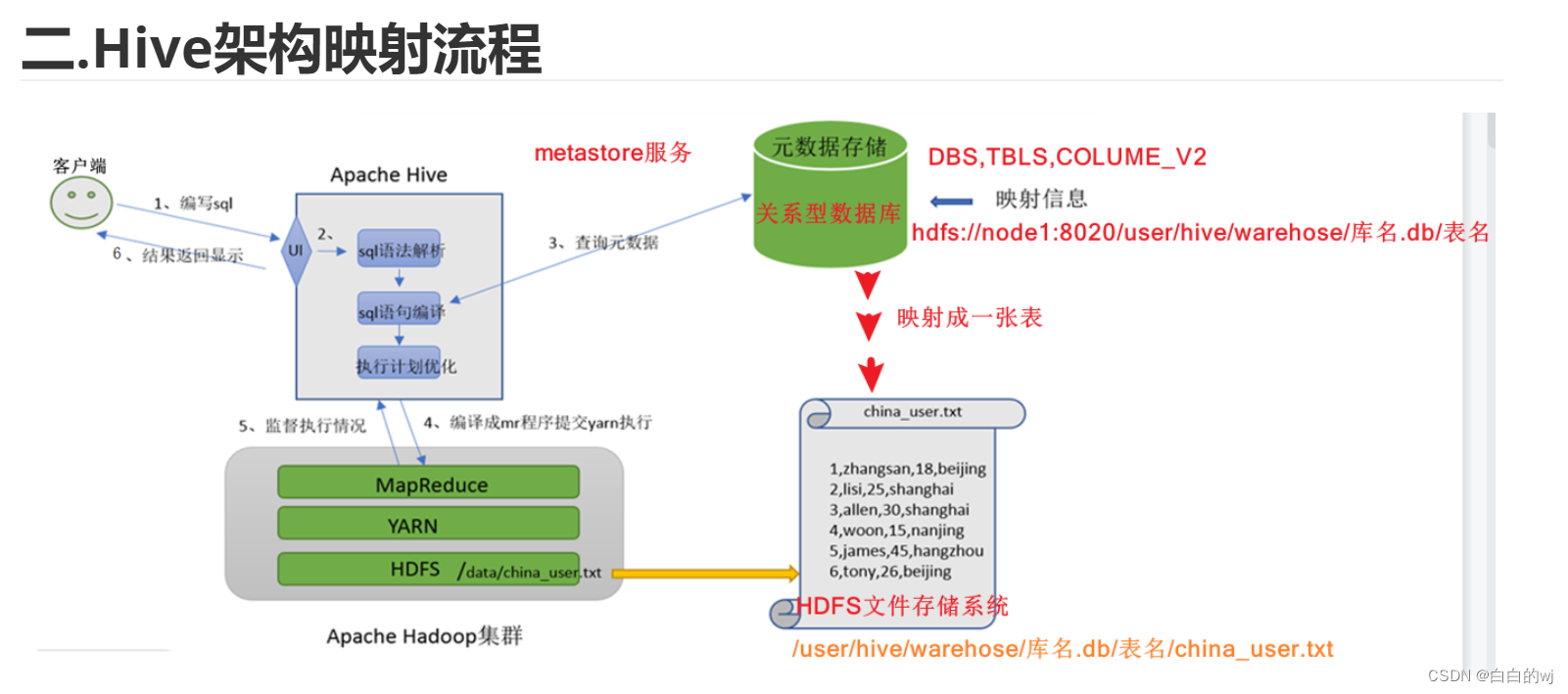
2023.11-9 hive数据仓库,概念,架构
目录
一.HDFS、HBase、Hive的区别
二.大数据相关软件
三. Hive 的优缺点
1)优点
2)缺点
四. Hive 和数据库比较
1)查询语言
2)数据更新
3)执行延迟
4)数据规模
五.hive架构流程
六.MetaStore元…
亚马逊云科技Zero ETL集成全面可用,可运行近乎实时的分析和机器学习
亚马逊云科技数据库、数据分析和机器学习全球副总裁Swami Sivasubramanian曾指出:“数据是应用、流程和商业决策的核心。”如今,客户常用的数据传输模式是建立从Amazon Aurora到Amazon Redshift的数据管道。这些解决方案能够帮助客户获得新的见解&#x…
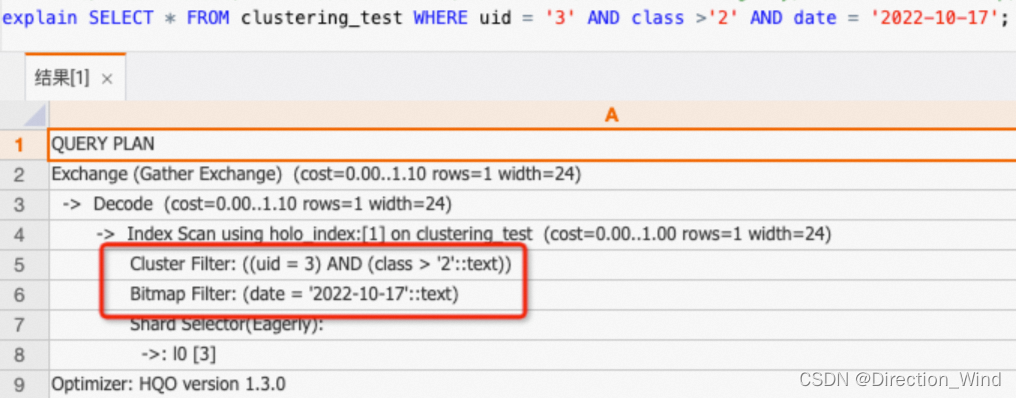
hologres 索引与查询优化
hologres 优化部分 1 hologres 建表优化1.1 建表中的配置优化1.1 字典索引 dictionary_encoding_columns1.2 位图索引 bitmap_columns1.2.2 Bitmap和Clustering Key的区别 1.3 聚簇索引Clustering Key 1 hologres 建表优化
1.1 建表中的配置优化
根据 holo的 存储引擎部分的知…

SNP应邀参加2023中国企业数字化转型峰会暨赛意用户大会
创新驱动科技,数智驱动未来。如今,我国产业数字化进程提速升级,数字产业化规模持续壮大。数据显示,2022年,我国数字经济规模达50.2万亿元,总量稳居世界第二。数字经济已经成为推动传统产业转型升级、促进高…

4 Paimon数据湖之Hive Catalog的使用
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html
Paimon提供了两种类型的Catalog:Filesystem Catalog和Hive Catalog。
Filesystem Catalog:会把元数据信息存储到文件系统里面。Hive Catalog:则会把元数据…
Doris DDL和DML
1 创建用户和数据库 1)创建test用户 mysql -h hadoop1 -P 9030 -uroot -p create user test identified by test; 2)创建数据库 create database test_db; 3)用户授权
Doris 数据导入一:Broker Load 方式
1.Doris导入数据的方式总结 导入(Load)功能就是将用户的原始数据导入到 Doris 中。导入成功后,用户即可通过 Mysql 客户端查询数据。为适配不同的数据导入需求,Doris 系统提供了6种不同的导入方式。每种导入方式支持不同的数据源,存在不同的使用方式(异步,同步)。 所有…
Educoder中Hive综合应用案例——用户学历查询
第1关:查询每一个用户从出生到现在的总天数
---------- 禁止修改 ----------drop database if exists mydb cascade;
---------- 禁止修改 -------------------- begin ----------
---创建mydb数据库
create database mydb;---使用mydb数据库
use mydb;---创建表user
create …
2023.11.12 hive中分区表,分桶表与区别概念
1.分区表 分区表的本质就是在分目录
当Hive表对应的数据量大、文件多时,为了避免查询时全表扫描数据。比如把一整年的数据根据月份划分12个月(12个分区),后续就可以查询指定月份分区的数据,尽可能避免了全表扫描查询。…
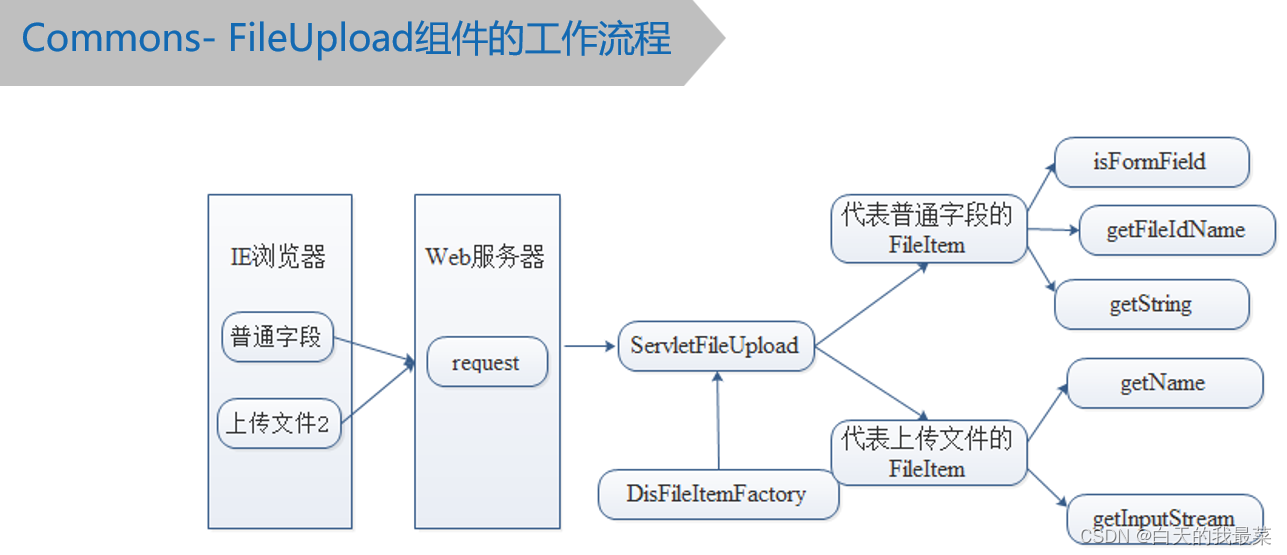
ke12Servlet规范有三个高级特性,,文件上传下载
1Servlet规范有三个高级特性
分别是Filter、Listener和文件的上传下载。Filter用于修改request、response对象,Listener用于监听context、session、request事件。 熟悉Filter的生命周期 了解Filter及其相关API 掌握Filter的实现 掌握Filter的映射与过滤器链的使用…

大数据数据仓库,Sqoop--学习笔记
数据仓库介绍
1. 数据仓库概念
数据仓库概念创始人在《建立数据仓库》一书中对数据仓库的定义是:数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、数据集成的(Integrated)、相对…
hivesql 将json格式字符串转为数组
hivesql 将json格式字符串转为数组 完整过程SQL在文末 json 格式字符串 本案例 json 字符串参考格式,请勿使用本数据 {"data": [{"province": 11,"id_card": "110182198903224674","name": "闾丘饱乾"…

【数据仓库】Apache Doris介绍
Apache Doris介绍 Apache Doris应用场景 Apache Doris核心特性 Apache Doris架构 Doris数据模型三种
Aggregate模型介绍 Uniq模型介绍 在某些多维分析场景下,用户更关注的是如何保证Key的唯一性Key 唯一性约束。因此,我们引入了 Unig 的数据模型。该模型本质上是聚…

【藏经阁一起读】(72)__《Hologres 一站式实时数仓客户案例集》
【藏经阁一起读】(72)
__《Hologres 一站式实时数仓客户案例集》 目录
【藏经阁一起读】(72)
一、实时数仓概念
二、Hologres
三、Hologres 一站式实时数仓客户案例集
3.1、电商
3.1.1、实时数仓 Hologres 首次走进阿里淘特…
使用Python创建faker实例生成csv大数据测试文件并导入Hive数仓
文章目录 一、Python生成数据1.1 代码说明1.2 代码参考 二、数据迁移2.1 从本机上传至服务器2.2 检查源数据格式2.3 检查大小并上传至HDFS 三、beeline建表3.1 创建测试表并导入测试数据3.2 建表显示内容 四、csv文件首行列名的处理4.1 创建新的表4.2 将旧表过滤首行插入新表 一…
[Hive] lateral view explode
当在Hive中使用 LATERAL VIEW EXPLODE 时,
它用于将一个复杂类型(如数组或Map)的列展开成多行数据,
并将这些展开后的数据与其他列进行关联。 下面是一个简单的例子来解释 LATERAL VIEW EXPLODE 的用法:
假设有一个…
为什么企业都在建立指标体系,有什么用途?
什么是指标体系
指标是指企业从不同角度梳理日常业务活动,把积累的庞大数据提炼成不同的业务指标,然后反过来用指标来指代具体的业务活动。
指标体系则是把这些从不同部门、业务、人员中提炼出的业务指标融合汇总到一起,形成一个指标系统&a…
【大数据 - Doris 实践】数据表的基本使用(三):数据模型
数据表的基本使用(三):数据模型 1.Aggregate 模型1.1 例一:导入数据聚合1.2 例二:保留明细数据1.3 例三:导入数据与已有数据聚合 2.Uniq 模型3.Duplicate 模型4.数据模型的选择建议5.聚合模型的局限性 Dori…
hive数据质量规范
当谈到大数据处理和分析时,数据质量成为至关重要的因素。Hive作为一种常用的大数据查询和分析工具,也需要遵循一定的数据质量规范以确保数据的准确性、一致性和可靠性。本文将介绍Hive数据质量规范的相关内容,并提供代码示例来说明如何在Hive…
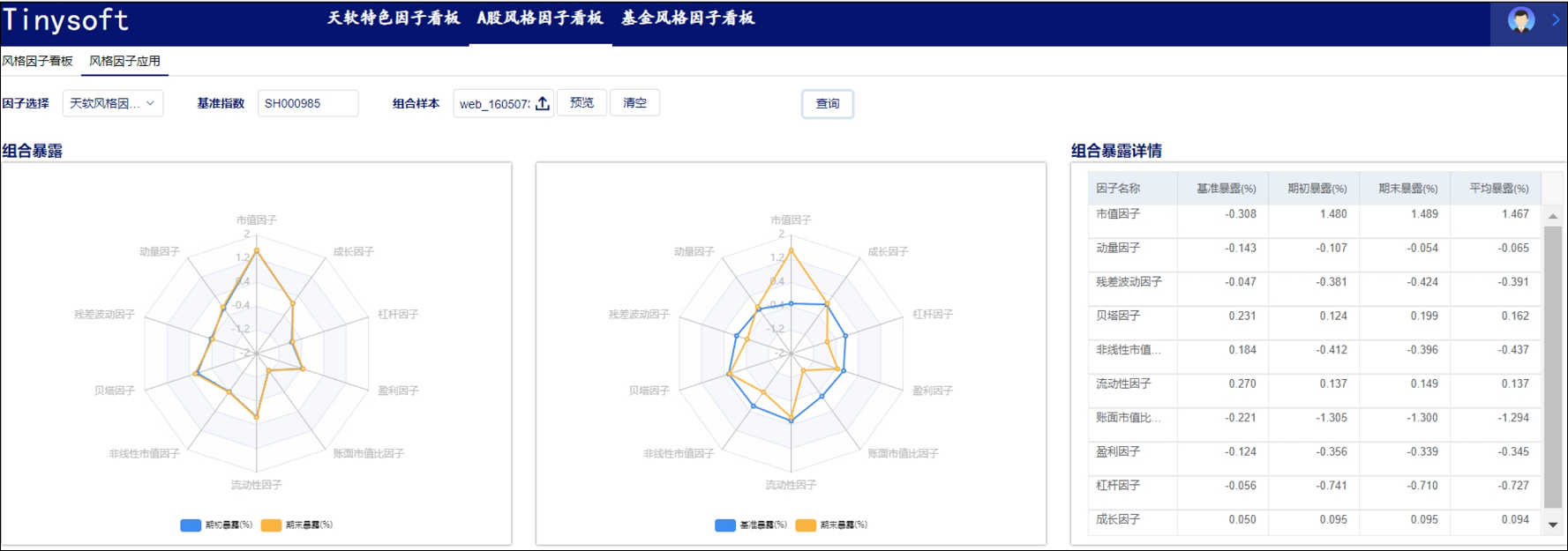
A股风格因子看板 (2023.11 第10期)
该因子看板跟踪A股风格因子,该因子主要解释沪深两市的市场收益、刻画市场风格趋势的系列风格因子,用以分析市场风格切换、组合风格暴 露等。 今日为该因子跟踪第10期,指数组合数据截止日2023-10-31,要点如下 近1年A股风格因子收益…
实时level2访问与策略研发
本周四下午4点,天软会聚焦“实时&level2访问与策略研发”开展我们的天软高频时序数仓会议,本次会议的报名客户,可以申请试用LEVEL-2数据测试账号哦~
iceberg建表与参数
CREATE TABLE catlog.database.table1( date INT COMMENT ‘’, id STRING COMMENT ‘’, status INT COMMENT ‘’, status_duration BIGINT COMMENT ‘’) USING iceberg PARTITIONED BY (date) COMMENT ‘’ LOCATION ‘’ TBLPROPERTIES( ‘current-snapshot-id’ ‘none’…

企业数字化过程中数据仓库与商业智能的目标
当前环境下,各领域企业通过数字化相关的一切技术,以数据为基础、以用户为核心,创建一种新的,或对现有商业模式进行重塑就是数字化转型。这种数字化转型给企业带来的效果就像是一次重构,会对企业的业务流程、思维文化、…
2023.11.16 hivesql 函数之类型转换,脱敏,与加密函数
1.类型转换函数
cast:主要用于类型转换,如果转换失败则返回null
select cast(3.14 as int); -- 3
select cast(3.14 as string) ; -- 3.14
select cast(3.14 as float); -- 3.14
select cast(3.14 as int); -- 3
select cast(binzi as int); -- null
很多时候,底层也默认做了…
大数据之Hive:regexp_extract函数案例
目录 一、正则的通配符简介1、正则表达式的符号及意义2、各种操作符的运算优先级: 二、案例数据要求分析实现 一、正则的通配符简介
1、正则表达式的符号及意义
符号含义实列/做为转意,即通常在"/"后面的字符不按原来意义解释如" * “匹…

从HDFS到对象存储,抛弃Hadoop,数据湖才能重获新生?
Hadoop与数据湖的关系 1、Hadoop时代的落幕2、Databricks和Snowflake做对了什么3、Hadoop与对象存储(OSD)4、Databricks与Snowflake为什么选择对象存储5、对象存储面临的挑战 1、Hadoop时代的落幕 十几年前,Hadoop是解决大规模数据分析的“白…
POSTGRESQL中如何利用SQL语句快速的进行同环比?
1. 引言
在数据驱动的时代,了解销售、收入或任何业务指标的同比和环比情况对企业决策至关重要。本文将深入介绍如何利用 PostgreSQL 和 SQL 语句快速、准确地进行这两种重要分析。
2. 数据准备
为了演示,假设我们有一张 sales 表,存储了销…
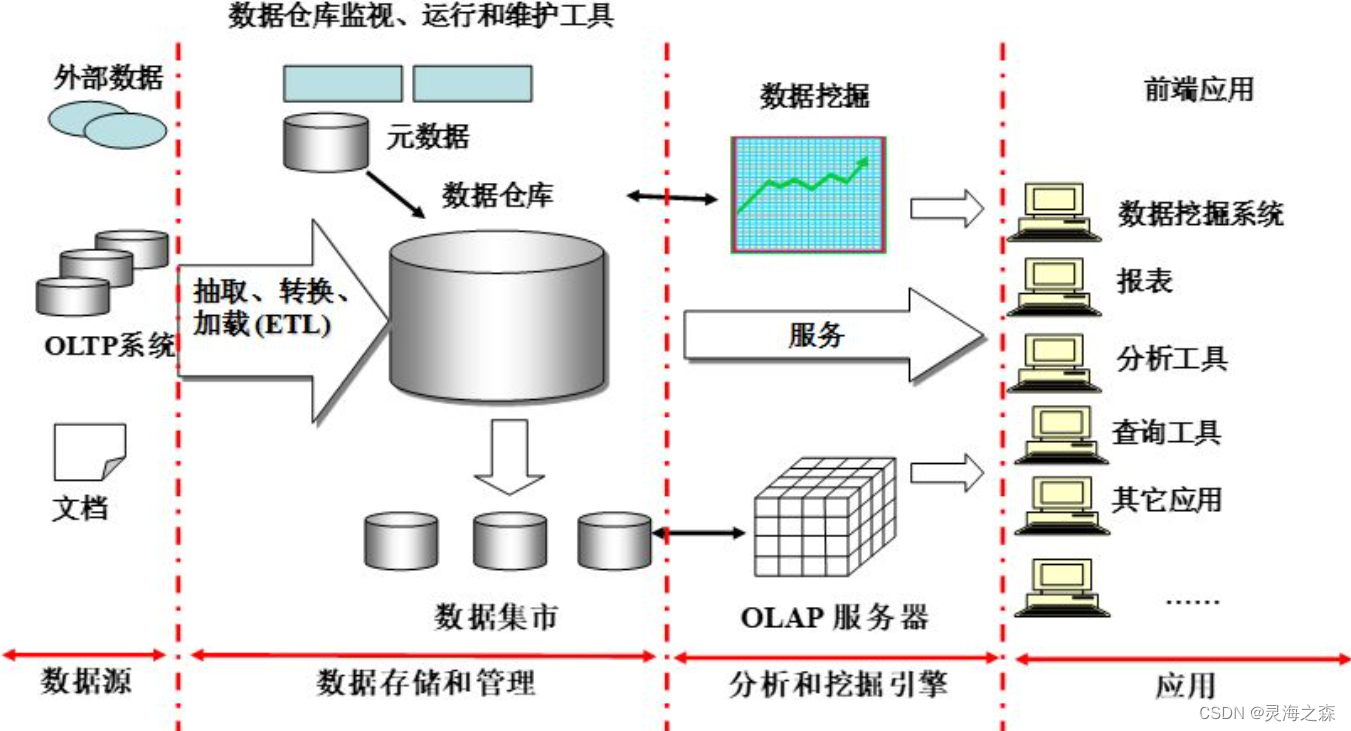
Hive进阶函数:inline() 和 struct() ,一列转多行
一、使用场景 如果存在一张表,记录的是每位学生的各科成绩,现在想把表转换为纵向存储 比如: name|english|math|history tom |80 |90 |100 转换为: name&…
GZ031 应用软件系统开发赛题第8套
2023年全国职业院校技能大赛
应用软件系统开发赛项(高职组)
赛题第8套 工位号:
2023年4月 竞赛说明
一、项目背景
党的二十大报告指出,要加快建设制造强国、数字中国,推动制造业高端化、智能化、…

2023.11.14-hive之表操作练习和文件导入练习
目录 需求1.数据库基本操作
需求2. 默认分隔符案例 需求1.数据库基本操作 -- 1.创建数据库test_sql,cs1,cs2,cs3
create database test_sql;
create database cs1;
create database cs2;
create database cs3;
-- 2.1删除数据库cs2
drop database cs2;
-- 2.2在cs3库中创建…
Hive使用max case when over partition by 实现单个窗口取两个窗口的值(单个开窗函数,实际取两个窗口)
一、Hive开窗函数根据特定条件取上一条最接近时间的数据(单个开窗函数,实际取两个窗口)
针对于就诊业务,一次就诊,多个处方,处方结算时间可能不一致,然后会有多个AI助手推荐用药,会…

Coles 五个月内推出SAP S/4HANA 财务核心
Coles是澳大利亚领先的零售企业,在全国拥有2,500多家零售店。100多年来,这家超市一直致力于为每周在Coles购物的2100万顾客提供优质、有价值的服务。 从Wesfarmers西农集团分拆之前,Coles抓住机会在其正在进行的数字化转型战略中向前迈进了一…
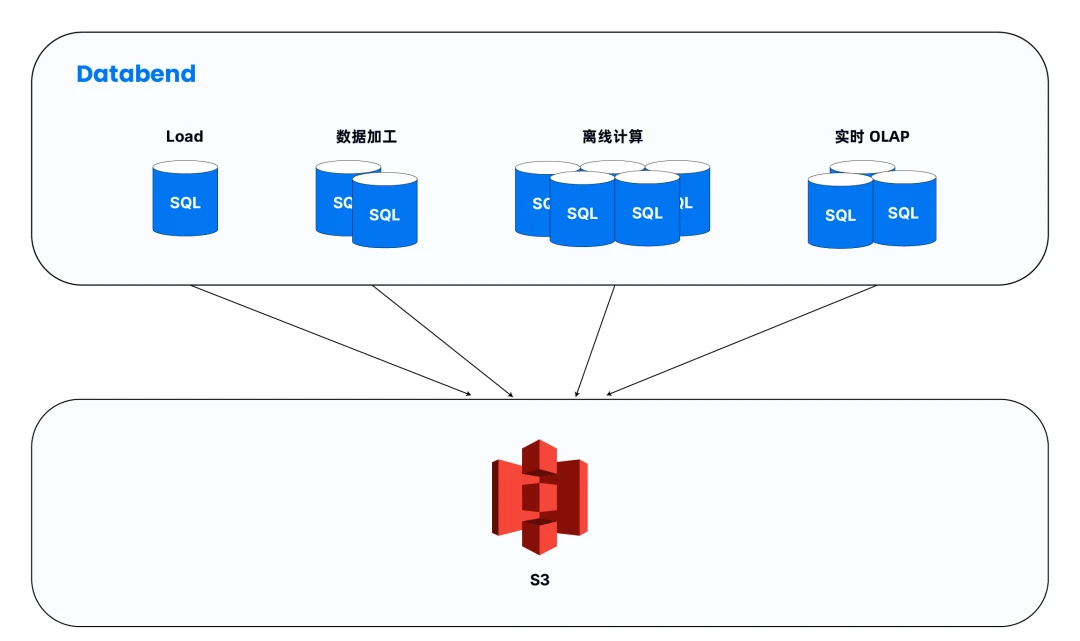
Databend 与海外某电信签约:共创海外电信数据仓库新纪元
为什么选择 Databend
海外某电信面临的主要挑战是随着业务量的增加,传统的 Clickhouse Hive 方案在数据存储和处理上开始显露不足。
原来的大数据分析采用的 Clickhouse Hive 方案进行离线的实时报表。但随着业务量的上升后,Hive的数据存储压力变大&…
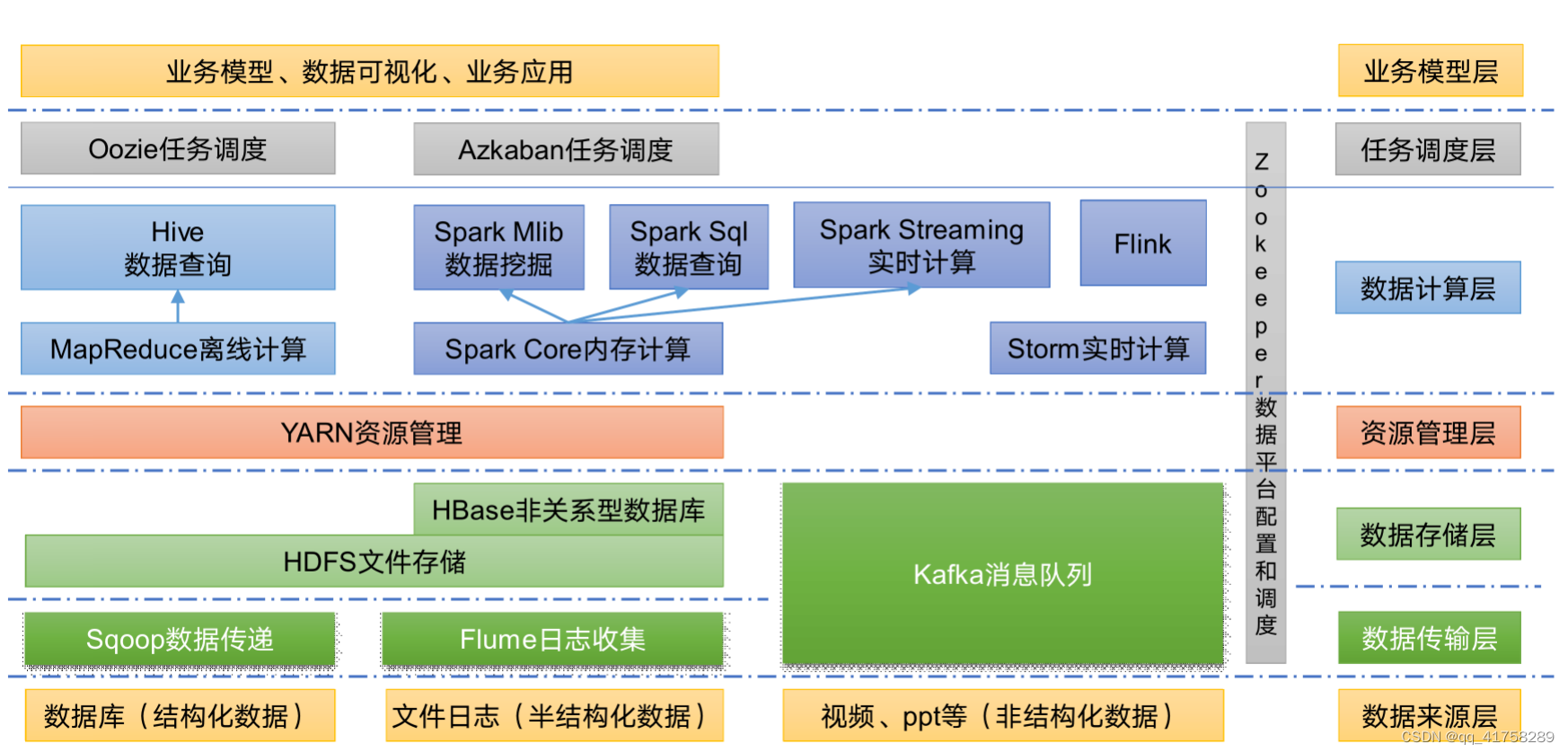
Hadoop数据仓库平台搭建
在这里是学习大数据的第一站 什么是数据仓库常见大数据平台组件及介绍 什么是数据仓库 在计算领域,数据仓库(DW 或 DWH)也称为企业数据仓库(EDW),是一种用于报告和数据分析的系统,被认为是商业智…

ETL数据转换工具类型与适用场景
ETL数据转换工具在企业数据管理中扮演着重要的角色,能够帮助企业从多个数据源中提取、转换和加载数据,实现数据整合和分析。以下是针对Kettle、DataX和ETLCloud这几个工具的详细介绍及其适用场景。
Kettle(Pentaho Data Integration…
天猫api接口,天猫详情api接口,天猫优惠券信息api接口,天猫到手价api接口,天猫商品详情接口操作演示案例
通过构建合适的请求参数,向API服务器发送数据请求,这些请求包括获取商品列表、商品详情、用户评价等。服务器将根据请求返回相应的数据响应,可以根据需要进行解析和处理。
taobao.item_get-获得淘宝商品详情 公共参数
名称类型必须描述keyS…
2023.11.18 - hadoop之zookeeper分布式协调服务
1.zookeeper简介
ZooKeeper概念: Zookeeper是一个分布式协调服务的开源框架。本质上是一个分布式的小文件存储系统 ZooKeeper作用: 主要用来解决分布式集群中应用系统的一致性问题。 ZooKeeper结构: 采用树形层次结构,没有目录与文件之分,ZooKeeper树中的每个节点被…

API接口接入1688电商数据平台获取商品详情数据示例
1688电商数据平台是一个提供海量商品信息的数据平台,通过API接口可以方便地获取商品详情数据。以下是一个示例,演示如何接入1688电商数据平台,获取商品详情数据。
步骤一:注册1688账号并获取API权限
首先需要在1688电商数据平台…
ClickHouse 物化视图
ClickHouse的物化视图是一种查询结果的持久化,它确实是给我们带来了查询效率的提升。用户查起来跟表没有区别,它就是一张表,它也像是一张时刻在预计算的表,创建的过程它是用了一个特殊引擎,加上后来 as select…
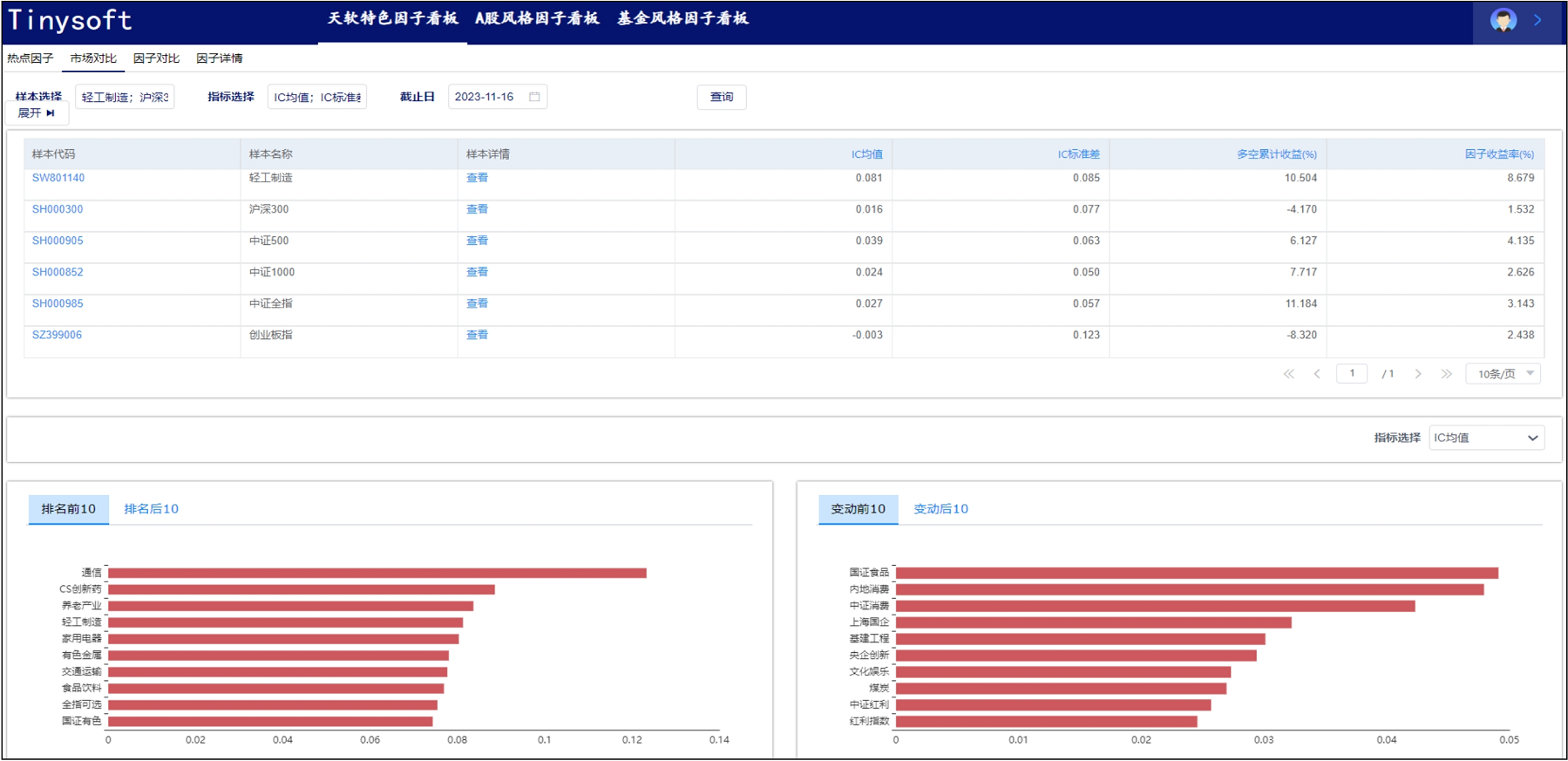
天软特色因子看板 (2023.11 第12期)
该因子看板跟踪天软特色因子A05006(近一月单笔流入流出金额之比(%),该因子为近一个月单笔流入流出金额之比(%)均值因子,用以刻画在 市场日内分时成交中流入、流出成交金额的差异性特点,发掘市场主力资金的作用机制。 今日为该因子跟踪第12期&…
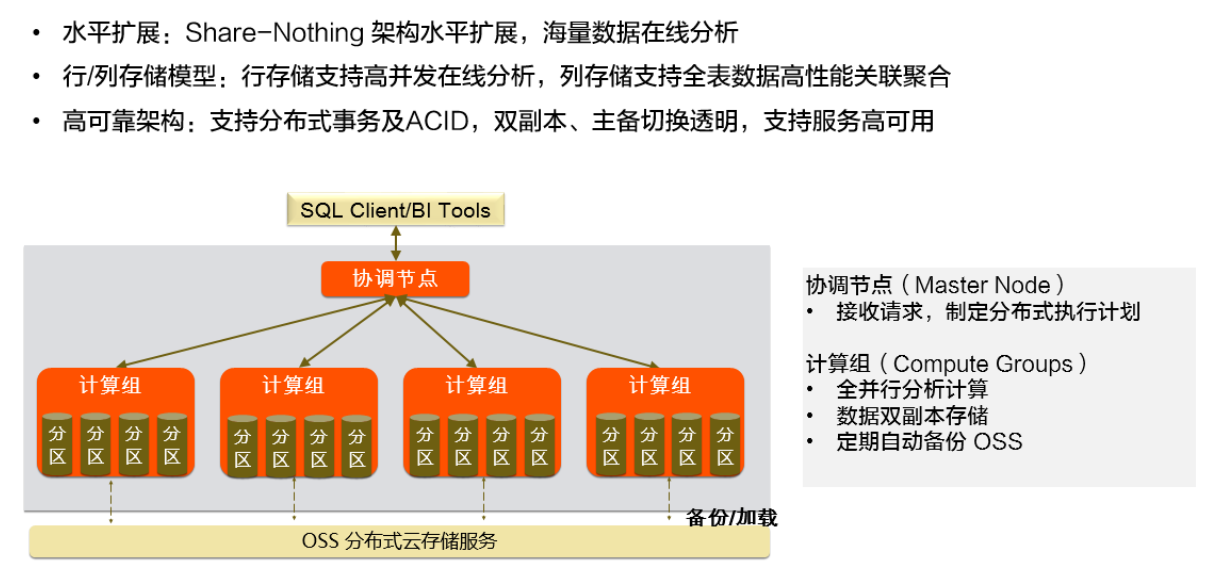
AnalyticDB for PostgreSQL 实时数据仓库上手指南
AnalyticDB for PostgreSQL 实时数据仓库上手指南
2019-04-016601
版权
本文涉及的产品
云原生数据仓库 ADB PostgreSQL,4核16G 50GB 1个月
推荐场景:
构建的企业专属Chatbot
立即试用
简介: AnalyticDB for PostgreSQL 提供企业级数…
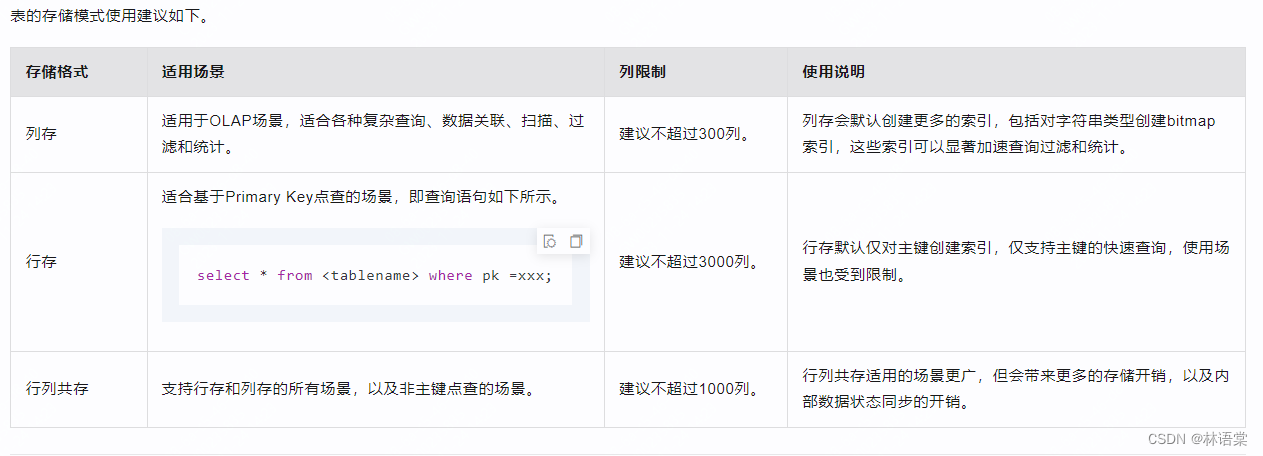
Hologres性能优化指南1:行存,列存,行列共存
在Hologres中支持行存、列存和行列共存三种存储格式,不同的存储格式适用于不同的场景。 在建表时通过设置orientation属性指定表的存储格式:
BEGIN;
CREATE TABLE <table_name> (...);
call set_table_property(<table_name>, orientation,…
Hive删除符合条件的记录
Hive在使用中不支持update和delete操作,那么如果想删除部分条件的记录需要怎么操作?本文记录下解决方法。 思路:使用selectwhere选出想要保留的数据,使用insert overwrite向原表覆盖插入数据.
insert overwrite table dbname.tab…
ClickHouse:真正的OLAP列式DBMS
ClickHouse 1、本文持续更新... 1、本文持续更新… ClickHouse官方文档:https://clickhouse.com/docs/zh
Spark Streaming的基本数据流
先来介绍一下按照动静对数据的区分
静态数据
静态数据(Static Data)指的是在一段时间内不会或很少发生变化的数据。这种类型的数据通常是固定的,并且不会随着时间的推移而更新或仅偶尔更新。静态数据的典型例子包括配置文件、参考表、历…

Presto:基于内存的OLAP查询引擎
Presto查询引擎 1、Presto概述1.1、Presto背景1.2、什么是Presto1.3、Presto的特性2、Presto架构2.1、Presto的两类服务器2.2、Presto基本概念2.3、Presto数据模型3、Presto查询过程3.1、Presto执行原理3.2、Presto与Hive3.3、Presto与Impala3.4、PrestoDB与PrestoSQL4、Presto…
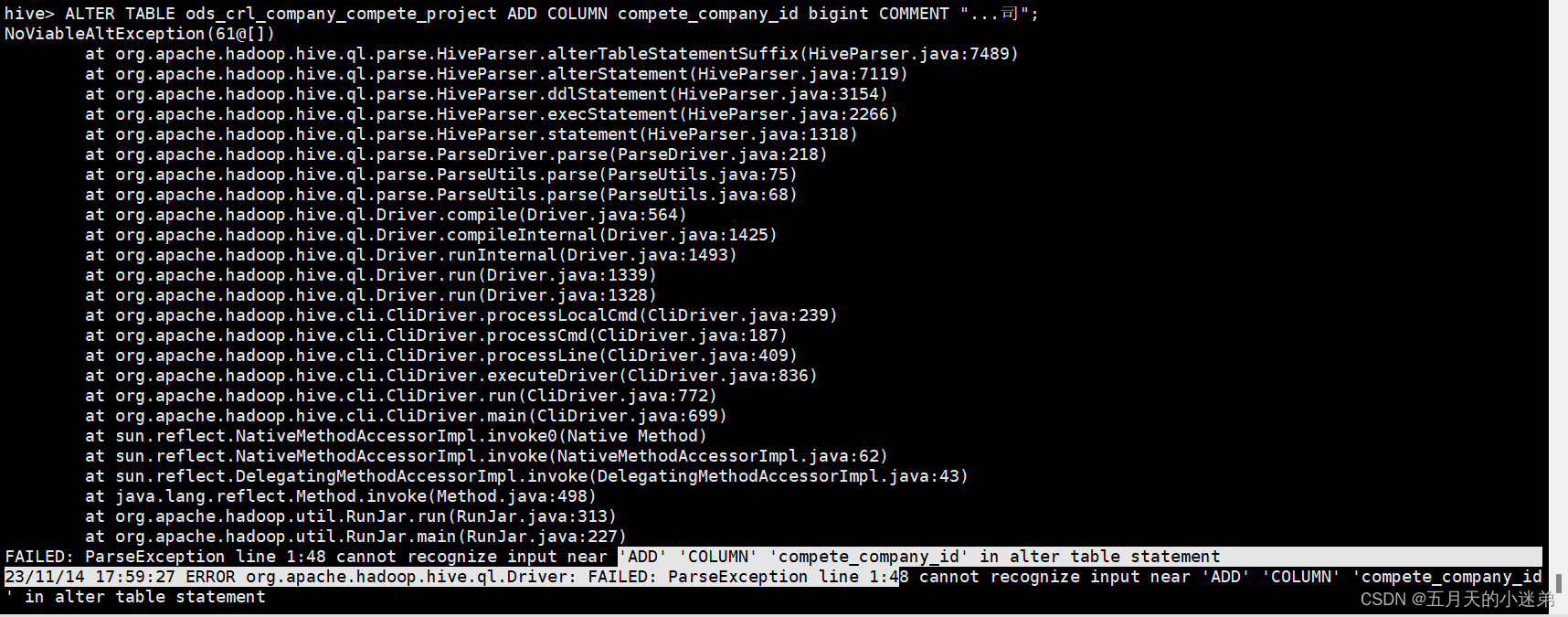
hive更改表结构的时候报错
现象 FAILED: ParseException line 1:48 cannot recognize input near ADD COLUMN compete_company_id in alter table statement 23/11/14 17:59:27 ERROR org.apache.hadoop.hive.ql.Driver: FAILED: ParseException line 1:48 cannot recognize input near ADD COLUMN compe…
ClickHouse查看执行计划
在clickhouse 20.6版本之前要查看SQL语句的执行计划需要设置日志级别为trace才能可以看到,并且只能真正执行sql,在执行日志里面查看。在20.6版本引入了原生的执行计划的语法。在20.6.3版本成为正式版本的功能。 本文档基于目前较新稳定版21.7.3.14。 1.基…
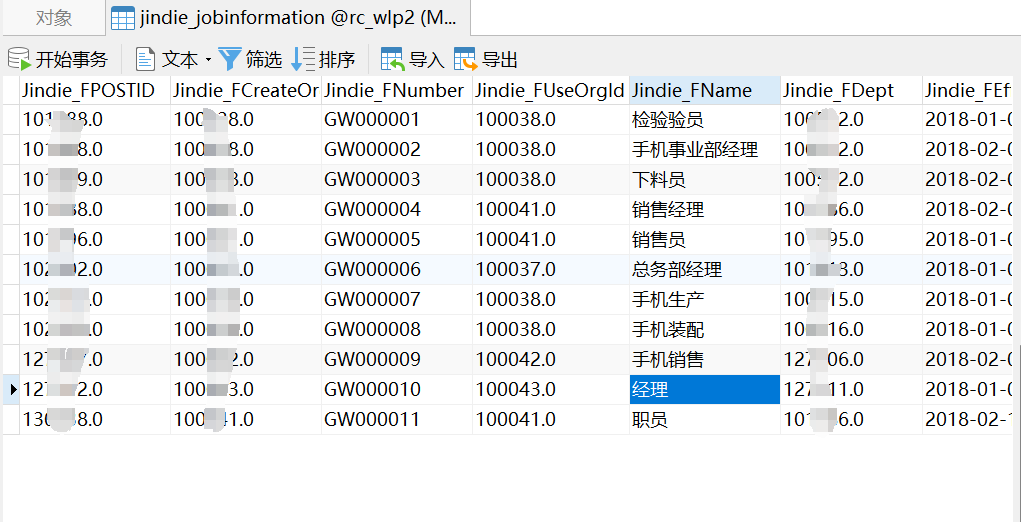
借助ETL快速查询金蝶云星空表单信息
随着数字化转型的加速,企业信息化程度越来越高,大量的数据产生并存储在云端,需要进行有效的数据管理和查询。金蝶云星空是金蝶云旗下的一款云ERP产品,为企业提供了完整的业务流程和数据管理功能,因此需要进行有效的数据…
2023.11.17 -hivesql调优,数据压缩,数据存储
目录 1.hive命令和参数配置
2.hive数据压缩
3.hive数据存储
0.原文件大小 18.1MB
1.textfile行存储格式, 压缩后size:18MB
2.行存储格式:squencefile ,压缩后大小8.89MB
3. 列存储格式 orc - ZILIB ,压缩后大小2.78MB 4.列存储格式 orc-snappy ,压缩后大小3.75MB
5…
物流实时数仓ODS层——Mysql到Kafka
目录
1.采集流程
2.项目架构
3.resources目录下的log4j.properties文件
4.依赖
5.ODS层——OdsApp
6.环境入口类——CreateEnvUtil
7.kafka工具类——KafkaUtil
8.启动集群项目 这一层要从Mysql读取数据,分为事实数据和维度数据,将不同类型的数据…
04数据平台Flume
Flume 功能 Flume主要作用,就是实时读取服务器本地磁盘数据,将数据写入到 HDFS。
Flume是 Cloudera提供的高可用,高可靠性,分布式的海量日志采集、聚合和传输的系统工具。
Flume 架构
Flume组成架构如下图所示:
A…
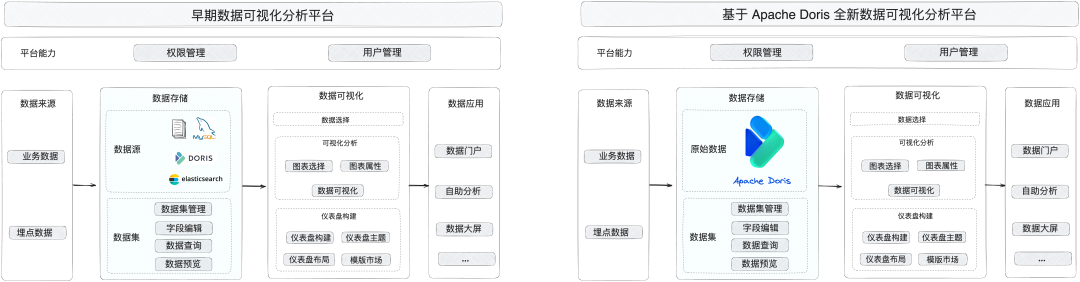
Apache Doris 在小鹅通的应用实践
峰会官网已上线,最新议程请关注:doris-summit.org.cn 点击报名 先到先得 本文导读: 随着网络直播规模的不断扩大,在线知识服务在直播行业中迎来了广阔的发展机遇。小鹅通作为一家以用户服务为核心的技术服务商,通过多平…
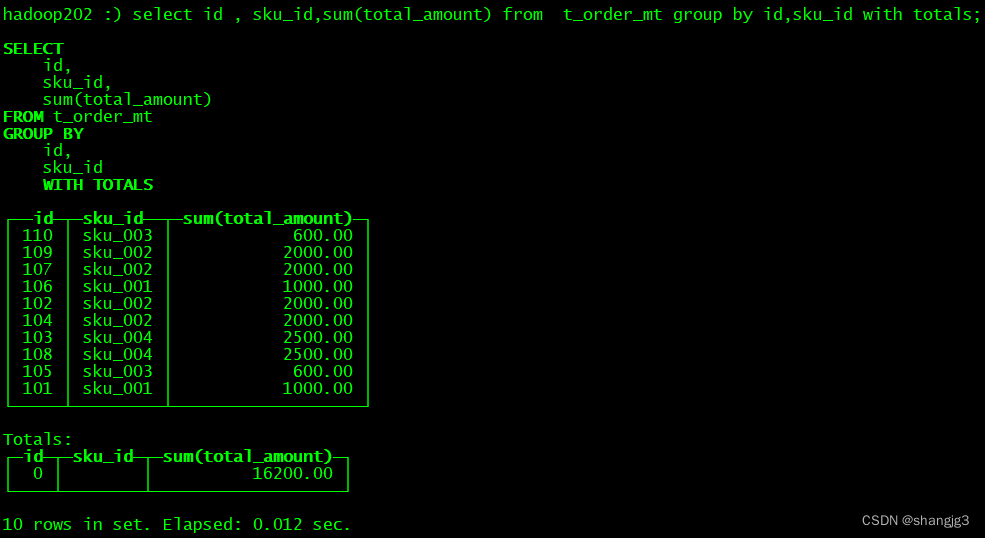
ClickHouse SQL操作
基本上来说传统关系型数据库(以MySQL为例)的SQL语句,ClickHouse基本都支持,这里不会从头讲解SQL语法只介绍ClickHouse与标准SQL(MySQL)不一致的地方。 1 Insert 基本与标准SQL(MySQL)…
2023.12.4 GIT的概念和组成
目录
目录
1.git的介绍
2.git的历史
开发者:Linus Torvalds
Linux的创始人 3.git和svn的对比
svn:集中式管理
git:分布式管理
4.git管理的组成结构
5.取消git文件夹追踪 1.git的介绍 git是项目版本管理工具,能自动的将多个版本进行管理存储,类似于快照,多个…
【大数据 - Doris 实践】数据表的基本使用(一):基本概念、创建表
数据表的基本使用(一):基本概念、创建表 1.创建用户和数据库2.Doris 中数据表的基本概念2.1 Row & Column2.2 Partition & Tablet 3.建表实操3.1 建表语法3.2 字段类型3.3 创建表3.3.1 Range Partition3.3.2 List Partition 1.创建用…


推动产业升级及创新,Doris Summit Asia 2023 先进智造与电信论坛提前揭秘
峰会官网已上线,最新议程请关注:doris-summit.org.cn
即刻报名
Doris Summit 是 Apache Doris 社区一年一度的技术盛会,由飞轮科技联合 Apache Doris 社区的众多开发者、企业用户和合作伙伴共同发起,专注于传播推广开源 OLAP 与…
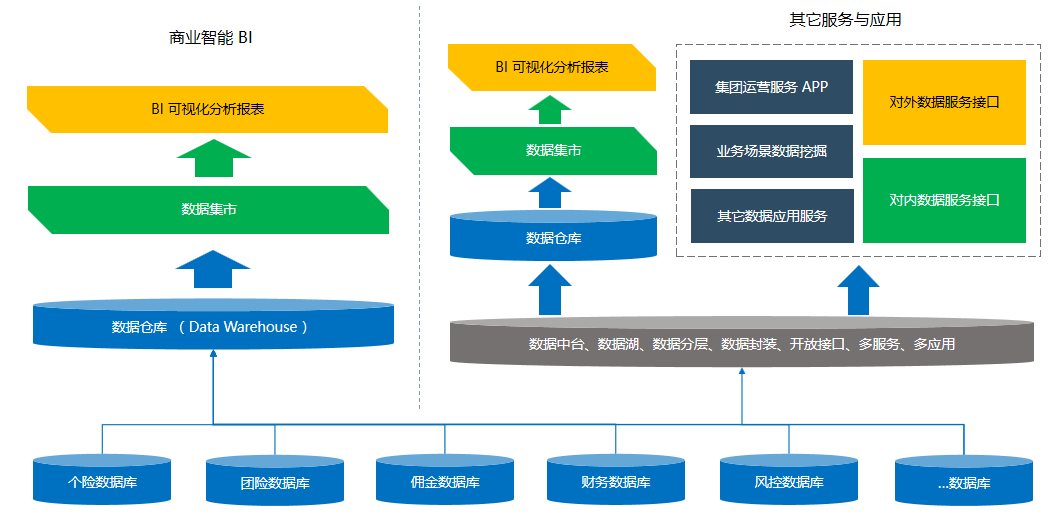
数字化时代,数据仓库是什么?有什么用?
在激烈的市场竞争和全新的数字经济共同作用下,数字化转型成为了大多数企业的共识,也是获取数字经济的最佳方式。在整个数据价值生产链路中,数据仓库的主要作用就是中心化分发,将原始数据与数据价值挖掘活动隔离。
所有的原始数据…
hive 问题解决 Class path contains multiple SLF4J bindings
hive输入命令时出现日志冲突提示(问题不复杂,是个warn,强迫症解决,做项目经常遇到,项目里是处理maven。这里处理方法思路类似。)
问题: SLF4J: Class path contains multiple SLF4J bindings. …
hive插入动态分区数据时,return code 2报错解决
目录
一、完整报错
二、原因
三、其他 一、完整报错 Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask 二、原因 大概率是因为没有开启允许动态分区或单次动态分区个数太小了。
-- 动态分区前…
Hive日志默认存储在什么位置?
在hive-log4j.properties配置文件中,有这么一段配置信息 hive.log.thresholdALL
hive.root.loggerWARN,DRFA
hive.log.dir${java.io.tmpdir}/${user.name}
hive.log.filehive.log hive.log.dir就是日志存储在目录/tmp/${user.name}(当前用户名)/下
而hive.log就是h…
hive里如何高效生成唯一ID
常见的方式: hive里最常用的方式生成唯一id,就是直接使用 row_number() 来进行,这个对于小数据量是ok的,但是当数据量大的时候会导致,数据倾斜,因为最后生成全局唯一id的时候,这个任务是放在一个…

2023.11.30 -hzmx电商平台建设项目05 - member会员主题建模开发
1.需求说明
1.11各类数据信息说明
说明:公司为了对不同会员进行不同的营销策略,对各类会员的数量都非常敏感,比如注册会员、消费会员、复购会员、活跃会员、沉睡会员。不仅需要看新增数量还要看累积数量。
9个指标:新增注册会员数,累计注册会员数(上一…
查看Hive表信息及占用空间的方法
一、Hive下查看数据表信息的方法
方法1:查看表的字段信息 desc table_name;
方法2:查看表的字段信息及元数据存储路径 desc extended table_name;
方法3:查看表的字段信息及元数据存储路径 desc formatted table_name;
方法4:…
2023.12.3 hive-sql日期函数小练习
目录 时间函数练习
时间戳 周,季度等计算 获取日期相关
获取当前时间 时间函数练习 --日期函数练习 ,sub是英文subtraction减法的简写, add是英文addition加法的简写
--获取今天是本周的第几天
select dayofweek(2023-12-3); --周日为一周的第一天
select current_timest…
头歌—Hive的安装与配置
第1关:Hive的安装与配置
在修改 conf 下面的hive-site.xml文件这里,题目给的信息是错误的,正确的内容如下:
<?xml version"1.0" encoding"UTF-8" standalone"no"?>
<?xml-stylesheet…
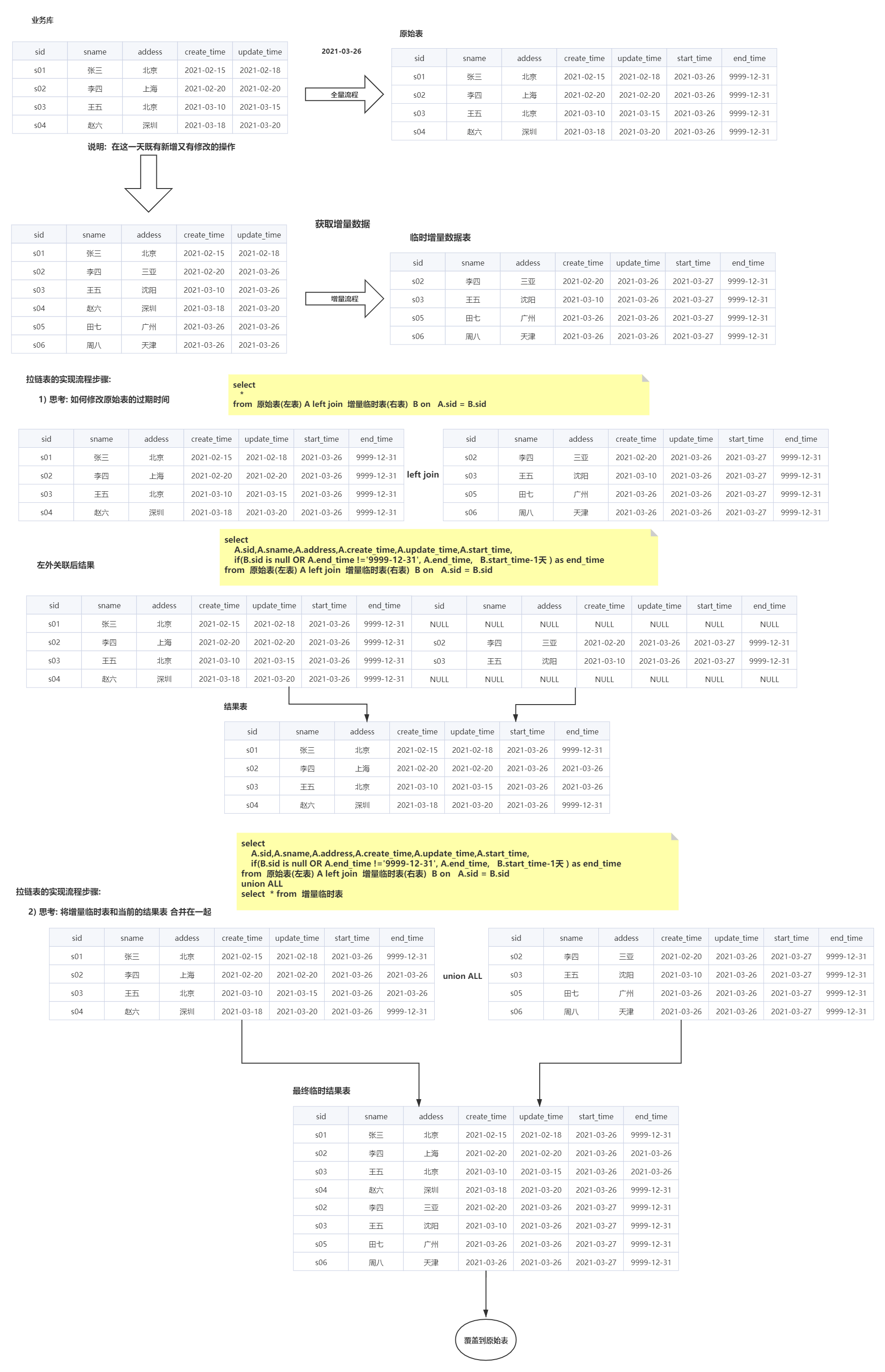
【黑马甄选离线数仓day08_会员主题域开发】
1. 会员主题域需求说明
1.1 各类会员数量统计
说明:公司为了对不同会员进行不同的营销策略,对各类会员的数量都非常敏感,比如注册会员、消费会员、复购会员、活跃会员、沉睡会员。不仅需要看新增数量还要看累积数量。
指标:新增…
ClickHouse建表优化
1. 数据类型 1.1 时间字段的类型 建表时能用数值型或日期时间型表示的字段就不要用字符串,全String类型在以Hive为中心的数仓建设中常见,但ClickHouse环境不应受此影响。 虽然ClickHouse底层将DateTime存储为时间戳Long类型,但不建议存储Long…
Presto集群安装部署
Presto集群安装部署 1、PrestoSQL2、PrestoSQL安装部署2.1、集群规划2.2、安装部署2.2.1、Presto Server安装2.2.2、Presto Server配置文件2.3、分发安装目录、配置环境变量2.4、启动运行Presto2.5、连接Hive和MySQL2.6、Presto资源组1、PrestoSQL 2020年12月27日,PrestoSQL为…
【数据仓库-零】数据仓库知识体系 ing
文章目录 一. 数仓基本概念二. 离线数仓建设方法论三. etl流程四. 数仓规范建设指南四. 数据仓库架构五. 数据可视化 通过熟悉构建数仓整体的过程,可以系统的了解 数仓构建理论:能够站在全局角度看数仓的运行架构,数仓执行流程。了解到构建数…
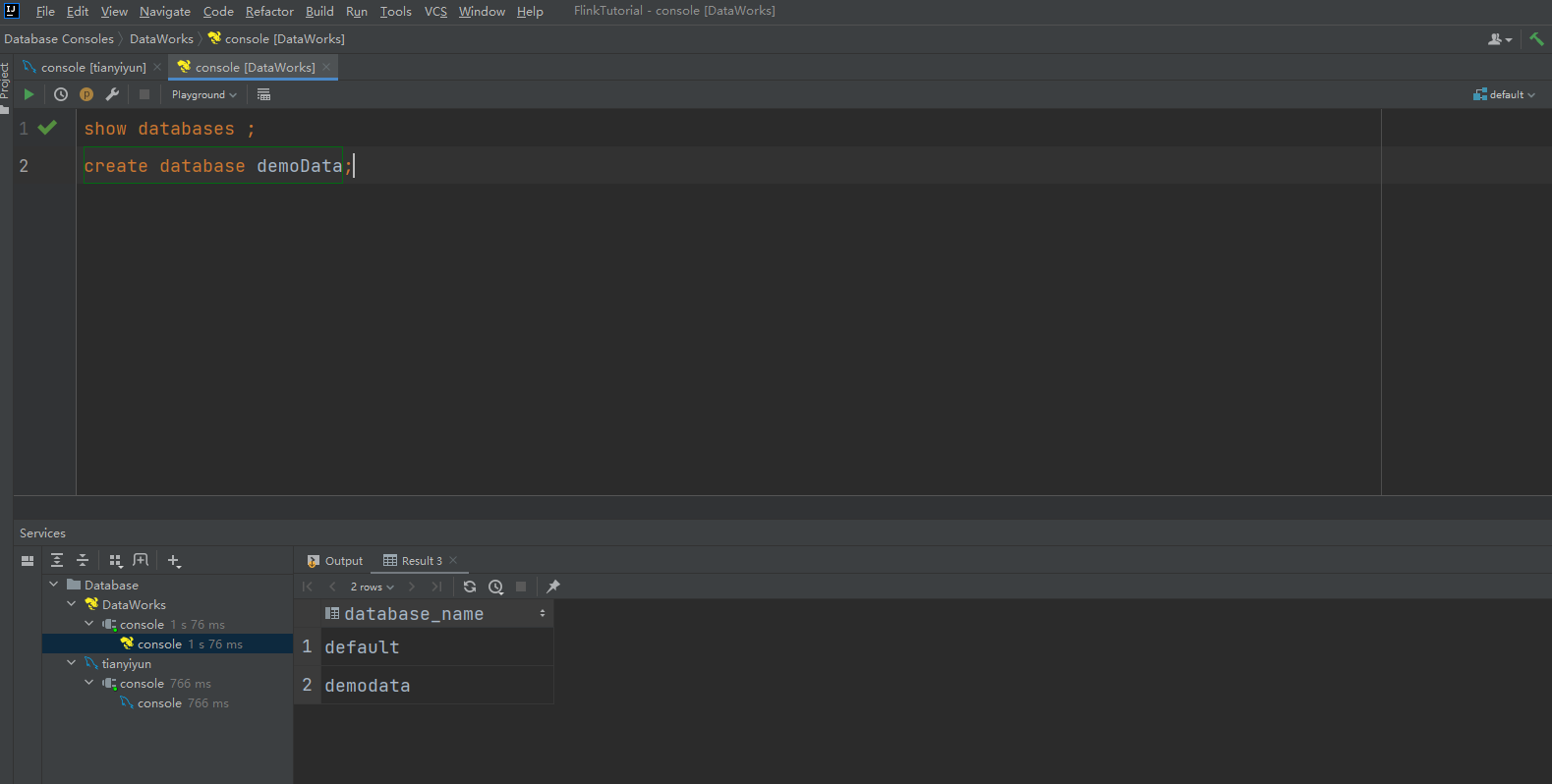
Hive的metastore服务的两种运行模式
Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口
1.metastore运行模式
metastore有两种运行模式,分别为嵌入式模式和独立服务模式。下面分别对两种模式进行说明:
(1)嵌入式模式 (2&#x…
淘宝商品价格变化监控,各大电商平台关键词搜索商品、商品详情API、品牌情报与品牌保护、价格监控、竞价比价API接入方案
淘宝关键词搜索商品API接口的作用主要是帮助开发者通过关键词搜索获取淘宝平台上的商品信息。通过这个接口,开发者可以在自己的应用或网站中实现类似淘宝平台的关键词搜索功能,让用户可以通过输入关键词来查找感兴趣的商品。
具体来说,淘宝关…

分布式数据库 GaiaDB-X 金融应用实践
1 银行新一代核心系统建设背景及架构
在银行的 IT 建设历程中,尤其是中大行,大多都基于大型机和小型机来构建核心系统。随着银行业务的快速发展,这样的系统对业务的支持越来越举步维艰,主要体现在以下四个方面:
首先…
【数据开发】Hive 多表join中的条件过滤与指定分区
1、条件过滤
left join 中 on 后面加条件 where 和 and 的区别
1、 on条件是在生成临时表时使用的条件,它不管and中的条件是否为真,都会保留左边表中的全部记录。2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有le…
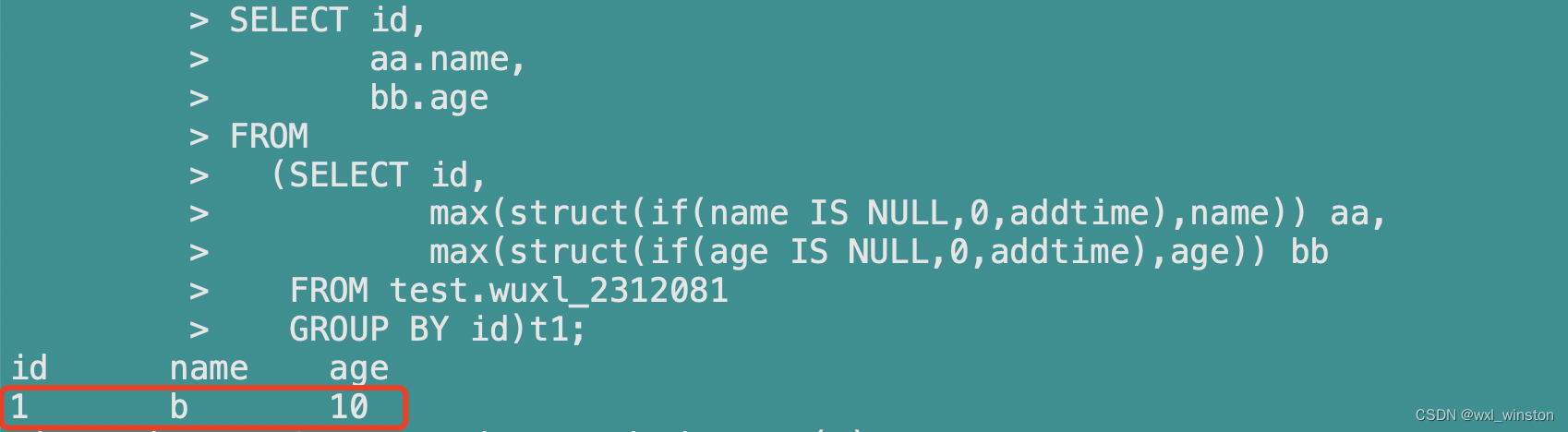
记录hive/spark取最新且不为null的方法
听标题可能听不懂我想表达的意思,我来描述一下我要做的事: 比如采集同学对某一网站进行数据采集,同一个用户每天会有很多条记录,所以我们要取一条这个用户最新的状态,比如用户改了N次昵称,我们只想得到最后…
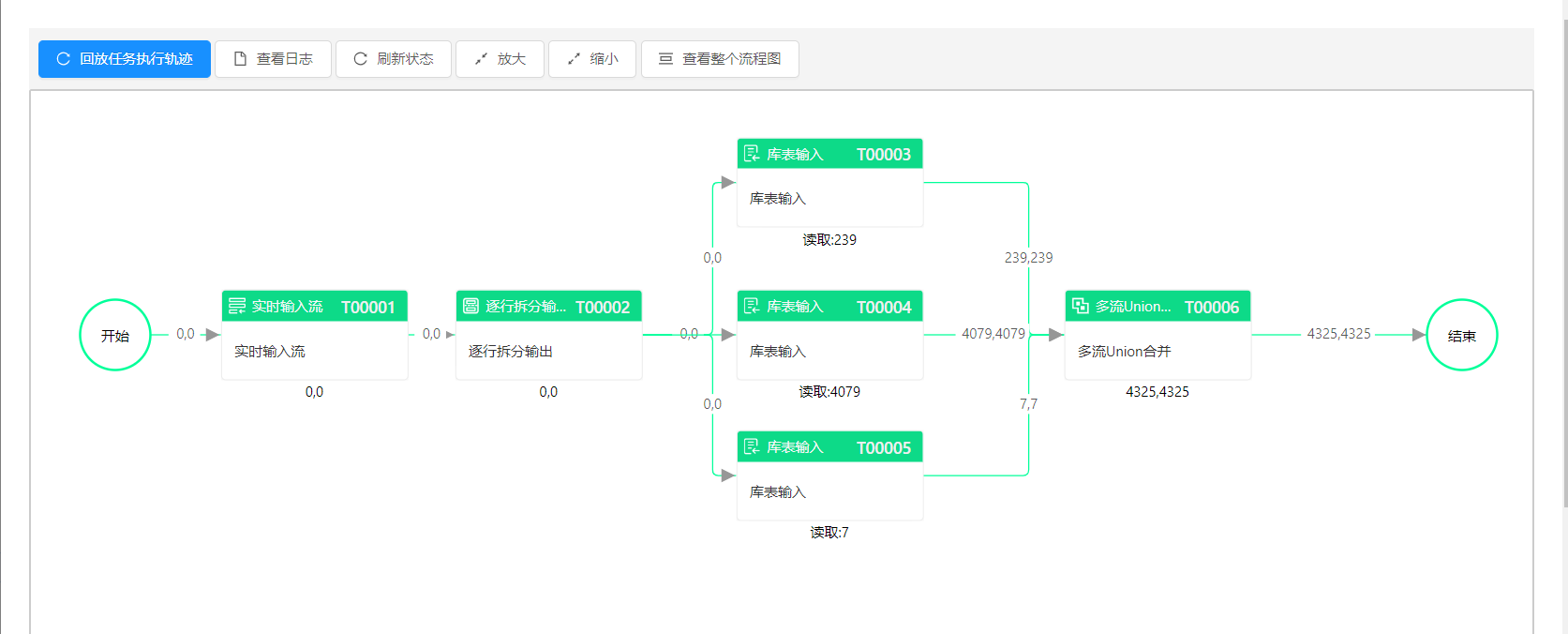
典型的ETL使用场景
典型的ETL使用场景
ETL( Extract,Transform,Load)是一种用于数据集成和数据转换的常用技术。它主要用于从多个数据源中提取数据,对数据进行清洗、转换和整合,最后加载到目标系统中。ETL 的使用场景非常广泛,下面将介绍…
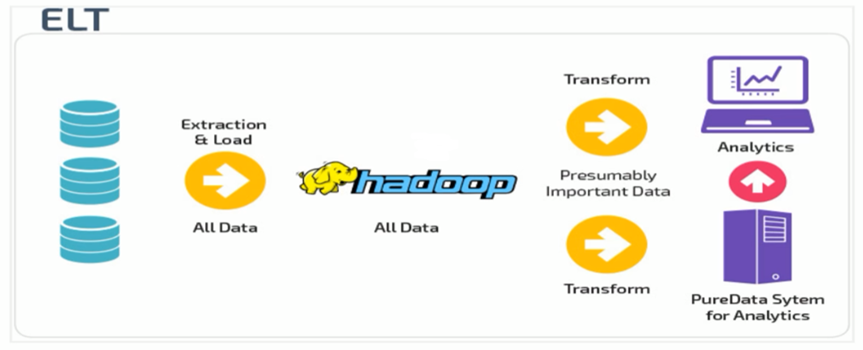
【Hive】——数据仓库
1.1 数仓概念
数据仓库(data warehouse):是一个用于存储,分析,报告的数据系统 目的:是构建面向分析的集成化数据环境,分析结果为企业提供决策支持 特点: 数据仓库本身不产生任何数据…

【大数据】Hudi 核心知识点详解(一)
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 &#x…

StarRocks上新,“One Data、All Analytics”还有多远?
K.K在《未来十二大趋势》中认为,我们正处于一个数据流动的时代。商业乃数据之商业。归根结底,你在处理的都是数据。
的确,当数据成为新的核心生产要素之际,数据分析就犹如最重要的生产工具之一,决定着企业在数字化时代…

数据仓库工具Hive
1. 请解释Hive是什么,它的主要用途是什么?
Hive是一个基于Hadoop的数据仓库工具,主要用于处理和分析大规模结构化数据。它可以将结构化的数据文件映射为一张数据库表,并提供类似SQL的查询功能,将SQL语句转换为MapRedu…
导入pgsql中的保存的html数据到hive时,换行符无法被repalce
数据如图所示: 当我使用replace函数 \r\n 、\r 、 \n替换时。无论如何都无法替换
最终发现可以使用chr(ASCII码) 可以匹配到,坑我好久。
replace(replace(replace(replace(replace(bid_html_con, chr(9),),chr(10),),chr(13),),chr(160),),chr(32),)
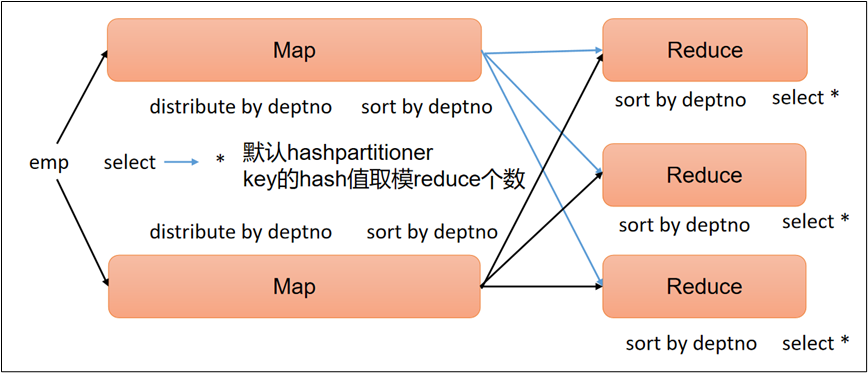
【Hive_02】查询语法
1、基础语法2、基本查询(Select…From)2.1 全表和特定列查询2.2 列别名2.3 Limit语句2.4 Where语句2.5 关系运算函数2.6 逻辑运算函数2.7 聚合函数 3、分组3.1 Group By语句3.2 Having语句3.3 Join语句(1)等值与不等值Join&#x…

hive企业级调优策略之小文件合并
测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511 本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
优化说明
小文件合并优化,分为两个方面,分别是Map端输入的小…
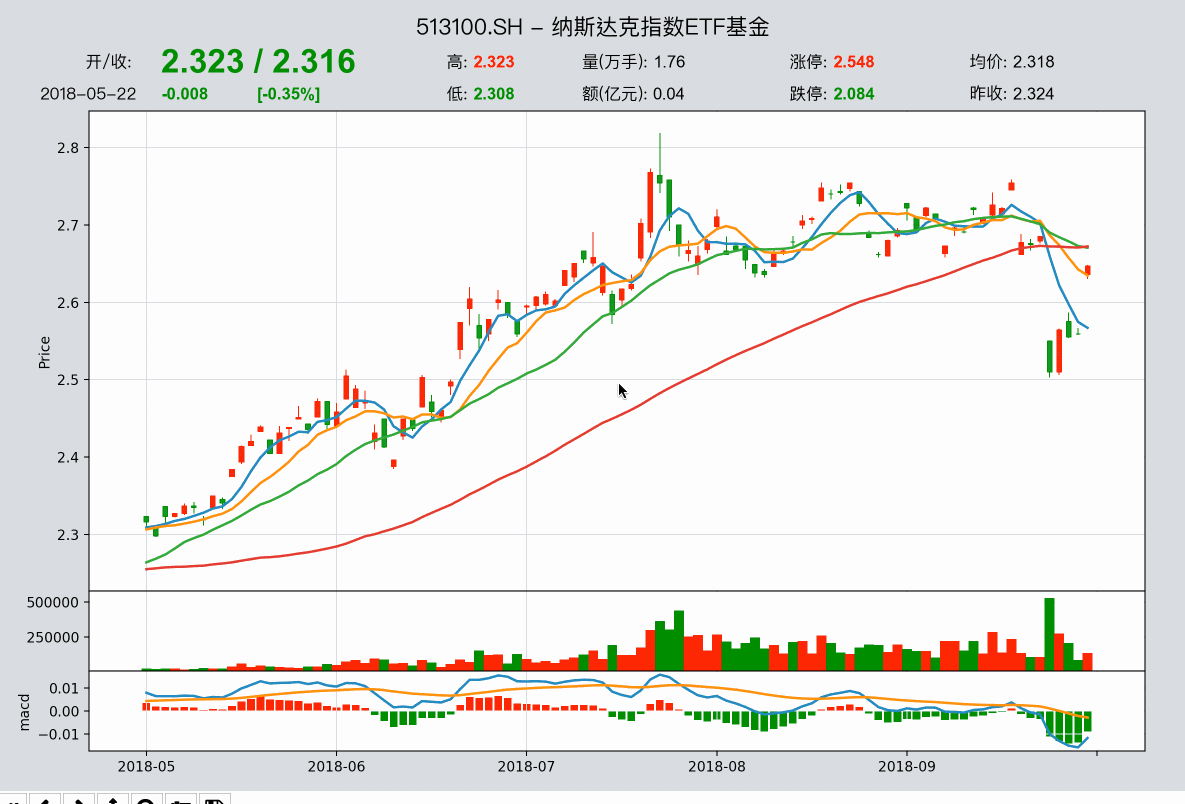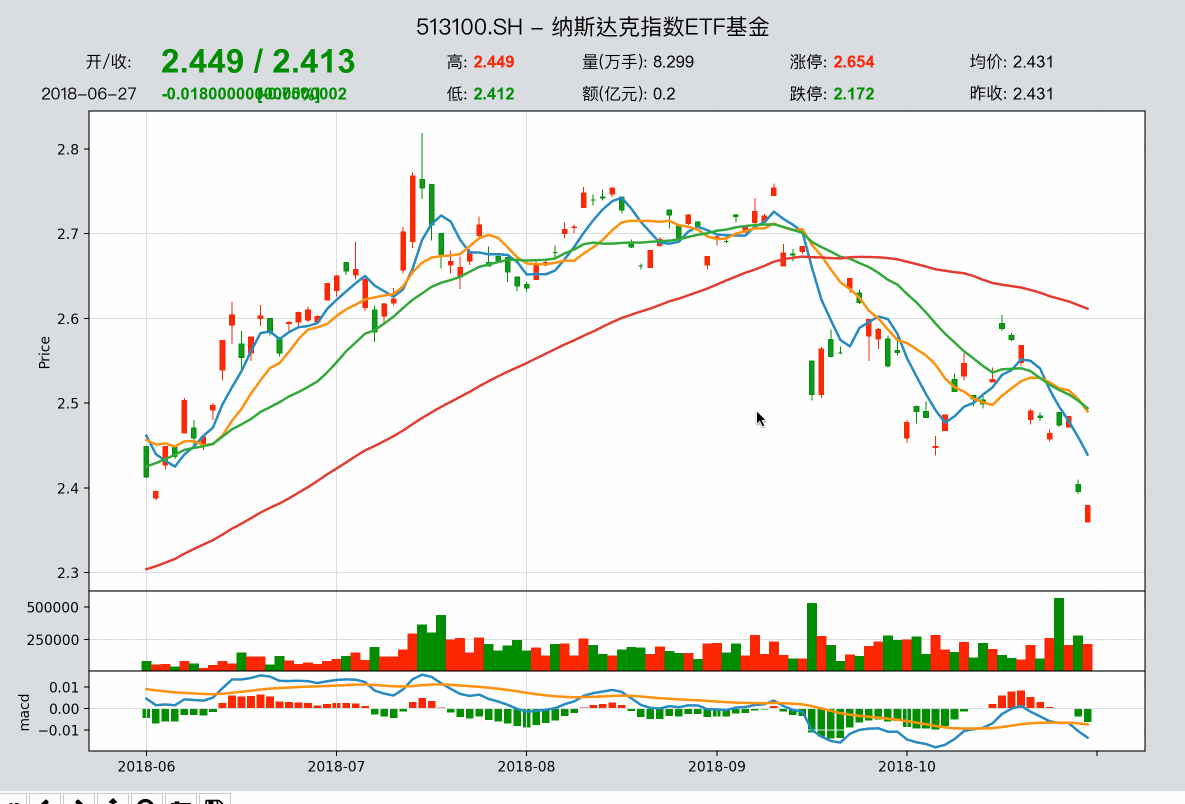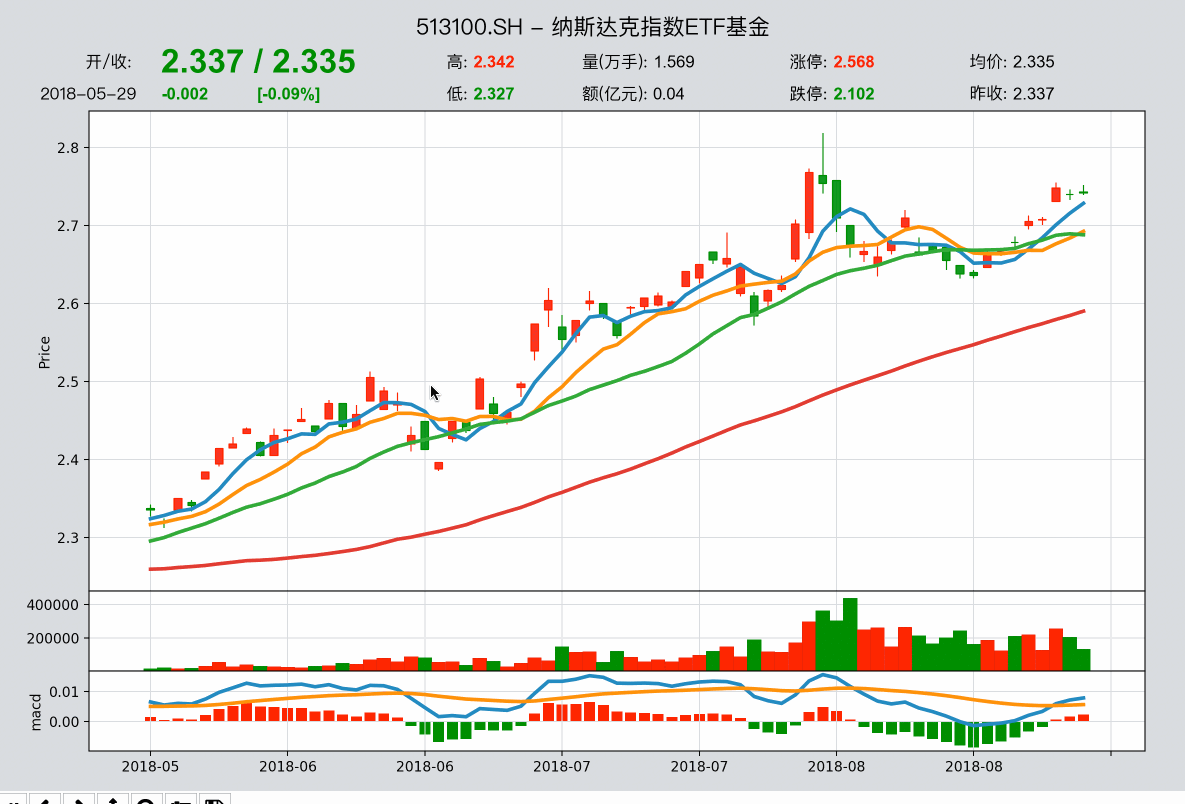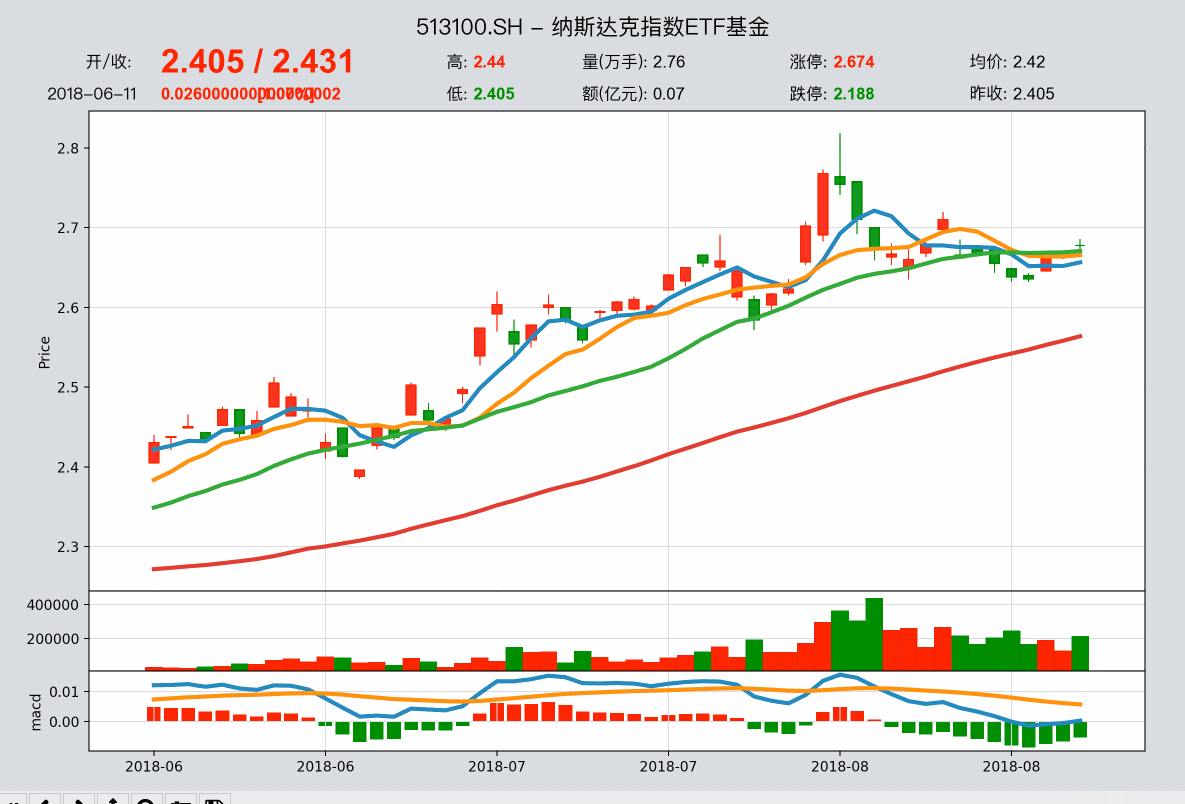
Python量化投资——金融数据最佳实践: 使用qteasy+tushare搭建本地金融数据仓库并定期批量更新【附源码】
用qteasytushare实现金融数据本地化存储及访问 目的什么是qteasy什么是tushare为什么要本地化使用qteasy创建本地数据仓库qteasy支持的几种本地化仓库类型配置本地数据仓库配置tushare 的API token 配置本地数据源 —— 用MySQL数据库作为本地数据源下载金融历史数据 数据的定期…

数据仓库【1】:简介
数据仓库【1】:简介 1、诞生背景1.1、数据仓库诞生原因1.2、历史数据积存1.3、企业数据分析需要 2、基本概述2.1、数据仓库(Data Warehouse,DW)2.2、数据仓库特点2.3、数据仓库 VS 数据库 3、技术实现3.1、数据仓库建设方案3.2、传…

数据仓库【3】:建模方法
数据仓库【3】:建模方法 1、基本概念1.1、OLTP系统建模方法1.2、OLAP(在线联机分析) 2、ROLAP2.1、ROLAP系统建模方法2.2、维度模型2.2.1、星型模型2.2.2、雪花模型2.2.3、星座模型2.2.4、什么是宽表模型? 3、MOLAP3.1、MOLAP系统…
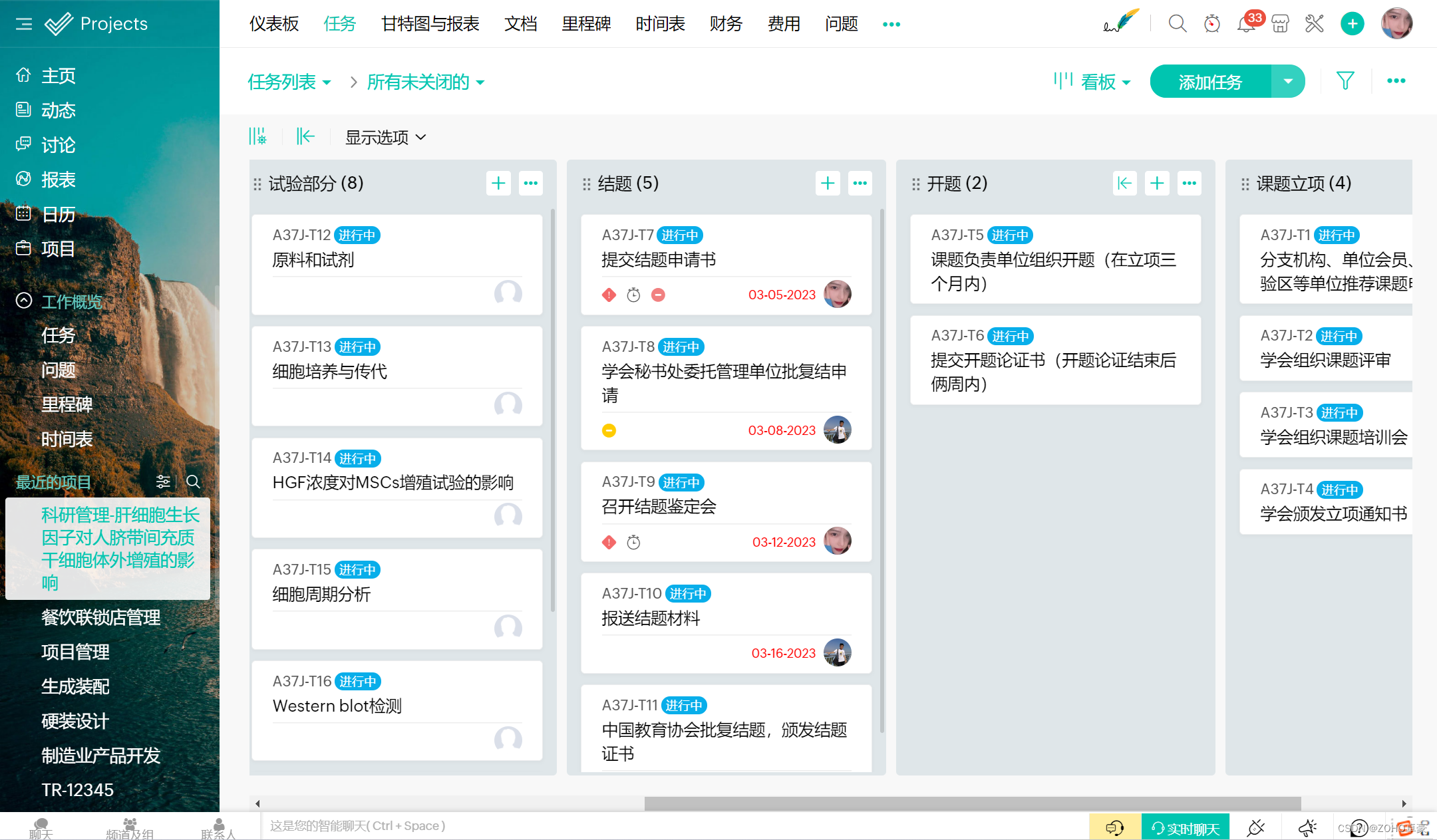
产品管理必备工具大公开:提升研发效率与项目管理水平的关键利器
Zoho Projects是一个能够帮助企业组织高效研发工作、快速推向市场并赢得用户青睐的有效工具。通过规划产品路线、收集整理需求、推动研发进程、跟踪产品运营、协助产品实施、管理产品文档,企业可以最大化地利用Zoho Projects,实现高效的产品研发和运营。…
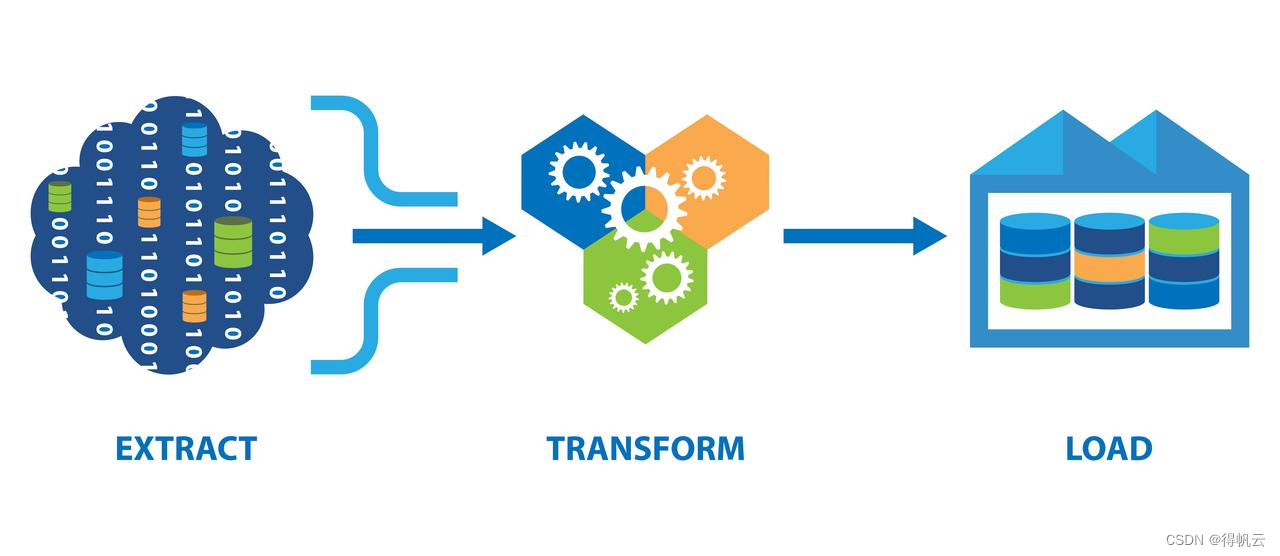
ETL是什么,有哪些ETL工具?就业前景如何?
ETL是什么 ETL(Extract-Transform-Load),用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目标端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。它可以自动化数据处理过程,减少…
hive 创建表 字段类型
hive 创建表 字段类型 在Hive中创建表时可以指定不同的字段类型。常见的字段类型包括:
数值类型(Numeric Types):
TINYINT:8位有符号整数
SMALLINT:16位有符号整数
INT:32位有符号整数
BIG…
解决hive表新增的字段查询为空null问题
Hive分区表新增字段,查询时数据为NULL的解决方案 由于业务拓展,需要往hive分区表新增新的字段,hive版本为2点多。
于是利用
alter table table_name add columns (col_name string )新增字段,然后向已存在分区中插入数据&#x…

Hive调优——合并小文件
目录 一、小文件产生的原因
二、小文件的危害
三、小文件的解决方案
3.1 小文件的预防
3.1.1 减少Map数量 3.1.2 减少Reduce的数量
3.2 已存在的小文件合并
3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…

TikTok 购物和直播的 5 个简单技巧
TikTok 的一切都很大:应用程序下载量、受众规模和病毒式营销活动。因此,该公司多方面进军社交商务也就不足为奇了。是的,这将是巨大的。自去年年底以来,TikTok Shopping 和TikTok 直播购物活动已在一些市场上线,并将于…
00Hadoop数据仓库平台
在这里是学习大数据的第一站 什么是数据仓库常见大数据平台组件及介绍 什么是数据仓库 在计算领域,数据仓库(DW 或 DWH)也称为企业数据仓库(EDW),是一种用于报告和数据分析的系统,被认为是商业智…
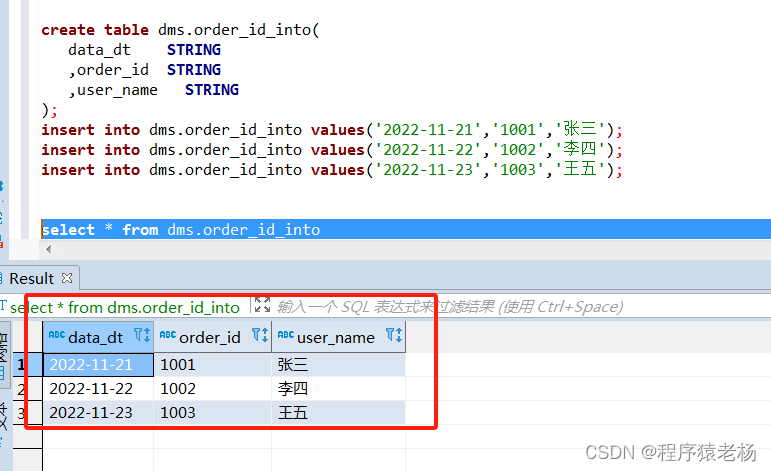
HIVE 中INSERT INTO 和 INSERT OVERWRITE 的区别,以及OVERWRITE哪些隐藏的坑
HIVE 中INSERT INTO 和 INSERT OVERWRITE 的区别,以及 overwrite 在分区表和非分区表中使用时的注意事项。
概要 1.hive中insert into 和 inset overwrite 的区别 2.hive中overwrite 在分区表和非分区表中使用时的注意事项
insert into 和 insert overwrite 我们都知道在hi…
Hive的安装配置、初始化元数据、启动
Hive的安装配置、初始化元数据、启动
1、解压hive到指定目录/usr/local/src 改名,将mysql的驱动包拷贝到hive的lib目录下 2、环境变量
1) vi /etc/profile export HIVE_HOME/usr/local/src/hive export PATH P A T H : PATH: PATH:HIVE_HOME/bin
echo…

数据仓库与数据挖掘复习资料
一、题型与考点[第一种]
1、解释基本概念(中英互译解释简单的含义); 2、简答题(每个10分有两个一定要记住): ① 考时间序列Time series(第六章)的基本概念含义解释作用(序列模式挖掘的作用); ② 考聚类(第五章)重点考…

数据仓库与数据挖掘小结
更加详细的只找得到pdf版本 填空10分 判断并改错10分 计算8分 综合20分 客观题 填空10分 判断并改错10分--错的要改 mooc中的--尤其考试题 名词解释12分 4个,每个3分 经常碰到的专业术语 简答题40分 5个,每道8分 综合 画roc曲线 …
3分钟带你了解:数据仓库能为你做点啥
一、数据仓库是什么
数据仓库(英语:data warehouse,也称为企业数据仓库)是用于报告和数据分析的系统,被认为是商业智能的核心组件。 数据仓库是来自一个或多个不同源的集成数据的中央存储库。数据仓库将当前和历史数据…
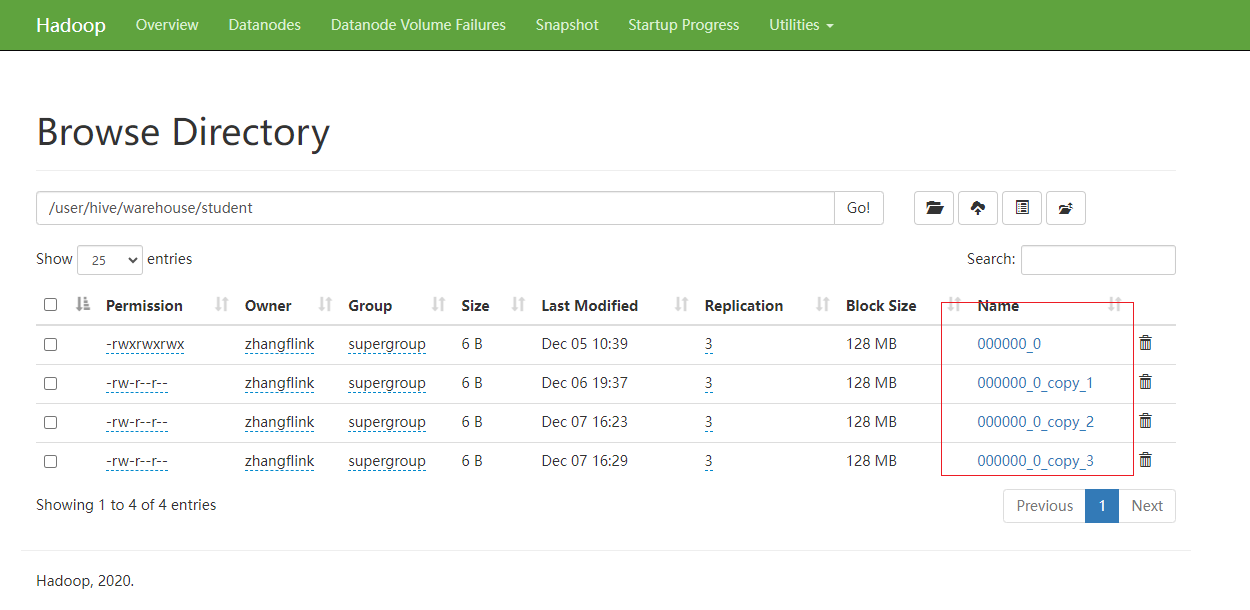
hive的分区表和分桶表详解
分区表
Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择查询所需要的分区,这样的查询效率会提高很多。
静态分区表基本语法
创建分区表
create table dept_p…
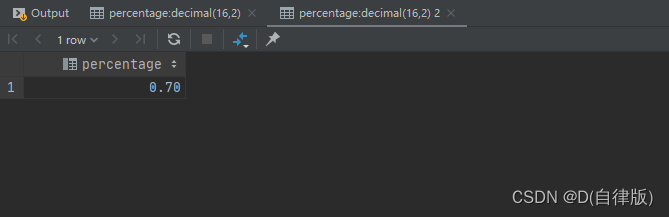
每日HiveSQL_统计即时订单_13
1.订单配送中,如果期望配送日期和下单日期相同,称为即时订单,如果期望配送日期和下单日期不同,称为计划订单。请从配送信息表(delivery_info)中求出每个用户的首单(用户的第一个订单)…
【Hive】启动beeline连接hive报错解决
1、解决报错2、在datagrip上连接hive 1、解决报错
刚开始一直报错:启动不起来 hive-site.xml需要配置hiveserver2相关的
在hive-site.xml文件中添加如下配置信息
<!-- 指定hiveserver2连接的host -->
<property><name>hive.server2.thrift.bin…
ClickHouse(18)ClickHouse集成ODBC表引擎详细解析
文章目录 创建表用法示例资料分享参考文章 ODBC集成表引擎使得ClickHouse可以通过ODBC方式连接到外部数据库. 为了安全地实现 ODBC 连接,ClickHouse 使用了一个独立程序 clickhouse-odbc-bridge. 如果ODBC驱动程序是直接从 clickhouse-server中加载的,那…
ClickHouse(17)ClickHouse集成JDBC表引擎详细解析
JDBC
允许CH通过JDBC连接到外部数据库。
要实现JDBC连接,CH需要使用以后台进程运行的程序 clickhouse-jdbc-bridge。
该引擎支持Nullable数据类型。
建表
CREATE TABLE [IF NOT EXISTS] [db.]table_name
(columns list...
)
ENGINE JDBC(datasource_uri, exte…
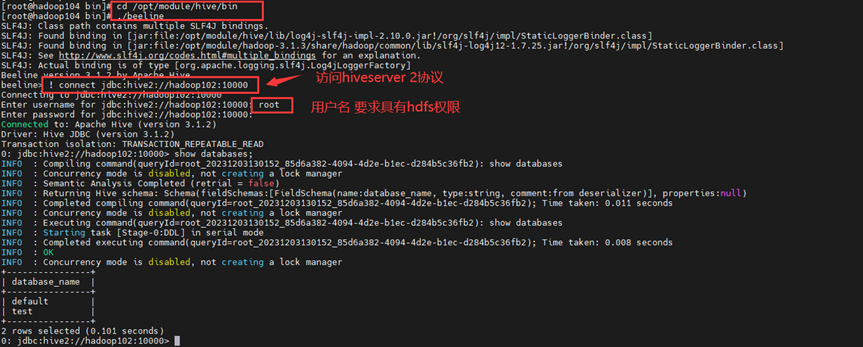
【Hive】——CLI客户端(bin/beeline,bin/hive)
1 HiveServer、HiveServer2 2 bin/hive 、bin/beeline 区别 3 bin/hive 客户端 hive-site.xml 配置远程 MateStore 地址
XML
<?xml version"1.0" encoding"UTF-8" standalone"no"?>
<?xml-stylesheet type"text/xsl" hre…

DAP数据集成与算法模型如何结合使用
企业信息化建设会越来越完善,越来越体系化,当今数据时代背景下更加强调、重视数据的价值,以数据说话,通过数据为企业提升渠道转化率、改善企业产品、实现精准运营,为企业打造自助模式的数据分析成果,以数据…

初识大数据应用,一文掌握大数据知识文集(1)
文章目录 🏆初识大数据应用知识🔎一、初识大数据应用知识(1)🍁 01、请用Java实现非递归二分查询?🍁 02、是客户端还是Namenode决定输入的分片?🍁 03、mapred.job.tracker命令的作用?…
ClickHouse(19)ClickHouse集成Hive表引擎详细解析
文章目录 Hive集成表引擎创建表使用示例如何使用HDFS文件系统的本地缓存查询 ORC 输入格式的Hive 表在 Hive 中建表在 ClickHouse 中建表 查询 Parquest 输入格式的Hive 表在 Hive 中建表在 ClickHouse 中建表 查询文本输入格式的Hive表在Hive 中建表在 ClickHouse 中建表 资料…

SpringBoot 3 集成Hive 3
前提条件:
运行环境:Hadoop 3.* Hive 3.* MySQL 8 ,如果还未安装相关环境,请参考:Hive 一文读懂
Centos7 安装Hadoop3 单机版本(伪分布式版本)
SpringBoot 2 集成Hive 3
pom.xml
<?xml ver…
Kafka(六)利用Kafka Connect+Debezium通过CDC方式将Oracle数据库的数据同步至PostgreSQL中
文章目录 背景解决方案场景一场景二场景三 CDC-Change Data Capture如何解决上述问题CDC工作原理Kafka Connect 和 Debezium简单介绍 场景二的例子,将Oracle数据库的数据通过CDC方式同步至PostgrSQL中使用Debezium时遇到问题的排查思路 场景一和场景三的实现思路ETL…
Doris 数据导出方式总结
1 Export导出 数据导出是Doris提供的一种将数据导出的功能。该功能可以将用户指定的表或分区的数据以文本的格式,通过Broker进程导出到远端存储上,如HDFS/BOS等。 1.1 基本原理 用户提交一个 Export 作业后。Doris 会统计这个作业涉及的所有 Tablet。然后对这些 Tablet 进行分…

十八、本地配置Hive
1、配置MYSQL
mysql> alter user rootlocalhost identified by Yang3135989009;
Query OK, 0 rows affected (0.00 sec)mysql> grant all on *.* to root%;
Query OK, 0 rows affected (0.00 sec)mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)2、…
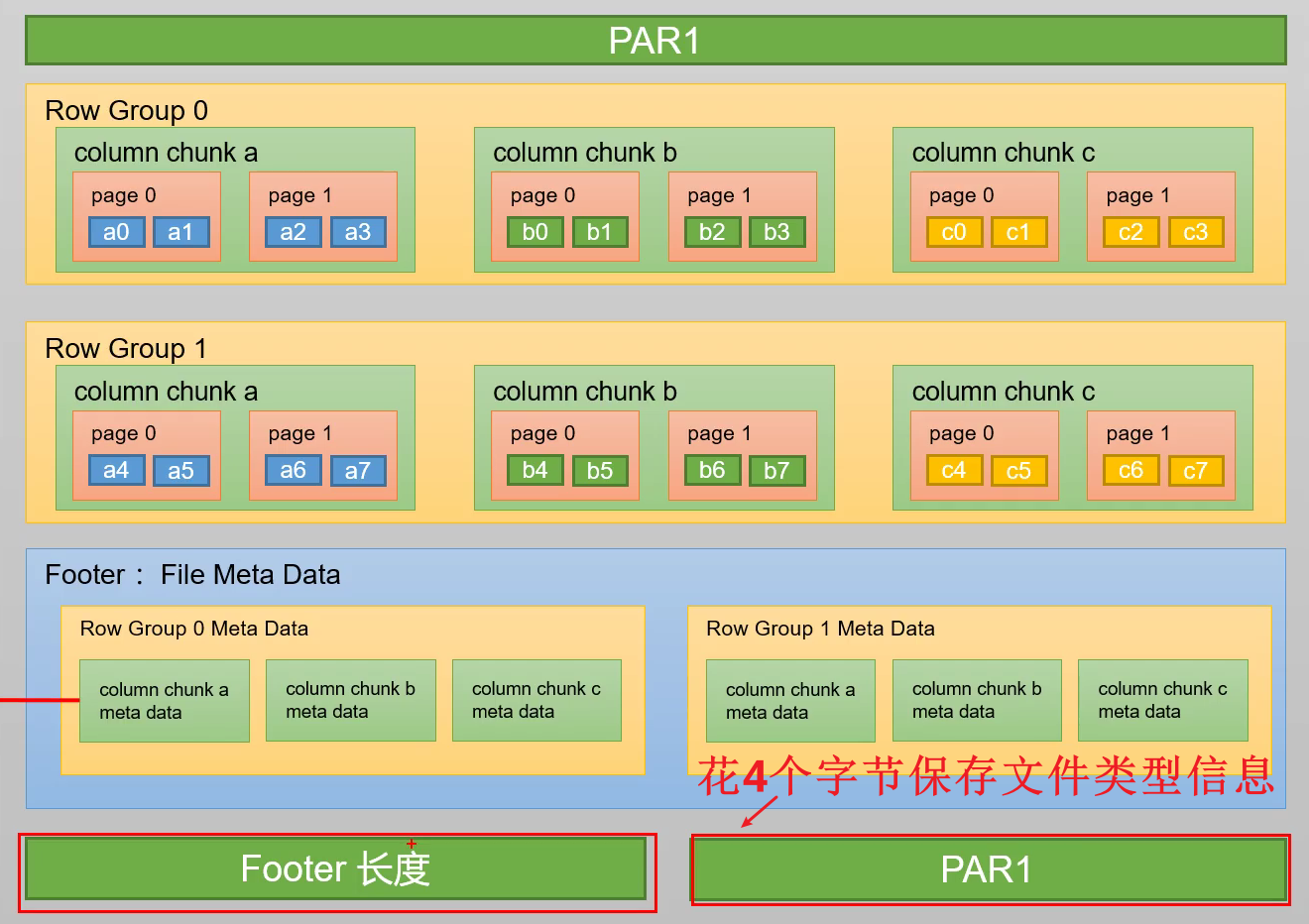
【Hive_04】分区分桶表以及文件格式
1、分区表1.1 分区表基本语法(1)创建分区表(2)分区表读写数据(3)分区表基本操作 1.2 二级分区1.3 动态分区 2、分桶表2.1 分桶表的基本语法2.2 分桶排序表 3、文件格式与压缩3.1 Hadoop压缩概述3.2 Hive文件…

【Hive】——DQL
1 SELECT
1.1 语法
从哪里查询取决于FROM关键字后面的table_reference。可以是普通物理表、视图、join结果或子查询结果。
[WITH CommonTableExpression (, CommonTableExpression)*]
SELECT [ALL | DISTINCT] select_expr, select_expr, ...FROM table_reference[WHERE wh…
数据治理-元数据定义
元数据是一个包含了许多潜在主题领域的广义术语,这些主题领域包括:
(1)业务分析:数据定义、报表、用户、使用方法和绩效
(2)业务架构:角色和组织、目的和目标。
(3&am…
自动化在线客服系统选择指南:关键要素与最佳实践分享
售后服务是企业整个运营流程的重要一环,而自动化在线客服系统又在售后服务中占据着举足轻重的位置。它为客户解决售后难题,帮助企业搭建完善高效的客户服务体系,在整个服务流程中发挥着巨大的作用。而市场上的客服系统厂家百花齐放࿰…

Hive参数操作和运行方式
Hive参数操作和运行方式
1、Hive参数操作
1、hive参数介绍
hive当中的参数、变量都是以命名空间开头的,详情如下表所示:
命名空间读写权限含义hiveconf可读写hive-site.xml当中的各配置变量例:hive --hiveconf hive.cli.print.headert…
从零开始的 dbt 入门教程 (dbt-core 基础篇)
最近一直在处理数据分析和数据建模的事情,所以接触了 dbt 等数据分析的工具,国内目前对于 dbt 比较详细的资料不多,所以打算写四道五篇 dbt 相关的文章,本文属于 dbt 系列的第一篇,本篇主要阐述 dbt 一些基本概念&…
解决Hive在DataGrip 中注释乱码问题
注释属于元数据的一部分,同样存储在mysql的metastore库中,如果metastore库的字符集不支持中文,就会导致中文显示乱码。
不建议修改Hive元数据库的编码,此处我们在metastore中找存储注释的表,找到表中存储注释的字段&a…
hive多分隔符外表支持
在hive 外表关联文本的时候 有时会遇到不是一个长度的分割符比如"~" 这种。这个时候使用shell命令多处理一步处理成单分隔符也可以,但是会有出错的风险。我们可以通过hive中指定的序列类来完成多分隔符的识别。 CREATE EXTERNAL TABLE text_mid1(
id STRI…
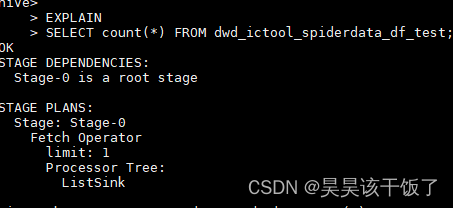
提升Hive效能:实用技巧与最佳实践
导读:帮助大家更有效地使用这个强大的数据仓库工具。
目录
优化Hive查询性能
分区(Partitioning)
代码示例
分桶(Bucketing)
代码示例
使用合适的文件格式
ORC文件格式
使用Vectorization
管理和优化表结构 …

【Hive_05】企业调优1(资源配置、explain、join优化)
1、 计算资源配置1.1 Yarn资源配置1.2 MapReduce资源配置 2、 Explain查看执行计划(重点)2.1 Explain执行计划概述2.2 基本语法2.3 案例实操 3、分组聚合优化3.1 优化说明(1)map-side 聚合相关的参数 3.2 优化案例 4、join优化4.1…
hive中map相关函数总结
目录 hive官方函数解释示例实战 hive官方函数解释
hive官网函数大全地址: hive官网函数大全地址
Return TypeNameDescriptionmapmap(key1, value1, key2, value2, …)Creates a map with the given key/value pairs.arraymap_values(Map<K.V>)Returns an un…
如何通过ETL实现快速同步美团订单信息
一、美团外卖现状
美团作为中国领先的生活服务电子商务平台,其旗下的美团外卖每天承载着大量的订单信息。这些订单信息需要及时入库、清洗和同步,但由于数据量庞大且来源多样化,传统的手动处理方式效率低下,容易出错。比如&#…
Bug2- Hive元数据启动报错:主机被阻止因连接错误次数过多
错误代码:
在启动Hive元数据时,遇到了以下错误信息:
Caused by: java.sql.SQLException: null, message from server: "Host 192.168.252.101 is blocked because of many connection errors, unblock with mysqladmin flush-hosts&qu…

ClickHouse的优缺点和应用场景
当业务场景需要一个大批量、快速的、可支持聚合运算的数据库,那么可选择ClickHouse。
选择ClickHouse 的原因:
记录类型类似于LOG,读取、运算远远大于写入操作选取有限列,对近千万条数据,快算的运算出结果。数据批量…
HiveQL——不借助任何外表,产生连续数值
注:参考文章:
HiveSql一天一个小技巧:如何不借助其他任何外表,产生连续数值_hive生成连续数字-CSDN博客文章浏览阅读1.3k次。0 需求描述输出结果如下所示:12345...1001 问题分析方法一:起始值(…

数据仓库【5】:项目实战
数据仓库【5】:项目实战 1、项目概述1.1、项目背景1.2、复购率计算 2、数据描述3、架构设计3.1、数据仓库架构图 4、环境搭建4.1、环境说明4.2、集群规划4.3、搭建流程 5、项目开发5.1、业务数据生成5.2、ETL数据导入5.3、ODS层创建&数据接入5.4、DWD层创建&…
Hive的小文件问题
目录 一、小文件产生的原因
二、小文件的危害
三、小文件的解决方案
3.1 小文件的预防
3.1.1 减少Map数量 3.1.2 减少Reduce的数量
3.2 已存在的小文件合并
3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…
Hive的排序——order by 、sort by、distribute by 、cluster by
Hive中的排序通常涉及到order by 、sort by、distribute by 、cluster by
一、语法 selectcolumn1,column2, ...
from table
[where 条件]
[group by column]
[order by column]
[cluster by column| [distribute by column] [sort by column]
[limit [offset,] rows];
…
hive中struct相关函数总结
目录 hive官方函数解释示例实战 hive官方函数解释
hive官网函数大全地址:添加链接描述
Return TypeNameDescriptionstructstruct(val1, val2, val3, …)Creates a struct with the given field values. Struct field names will be col1, col2, …structnamed_str…
Hive窗口函数详解
一、 窗口函数知识点
1.1 窗户函数的定义 窗口函数可以拆分为【窗口函数】。窗口函数官网指路:
LanguageManual WindowingAndAnalytics - Apache Hive - Apache Software Foundationhttps://cwiki.apache.org/confluence/display/Hive/LanguageManual%20Windowing…
scala 整合 springboot
scala 整合 springboot
新建spingboot项目 pom.xml
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocati…
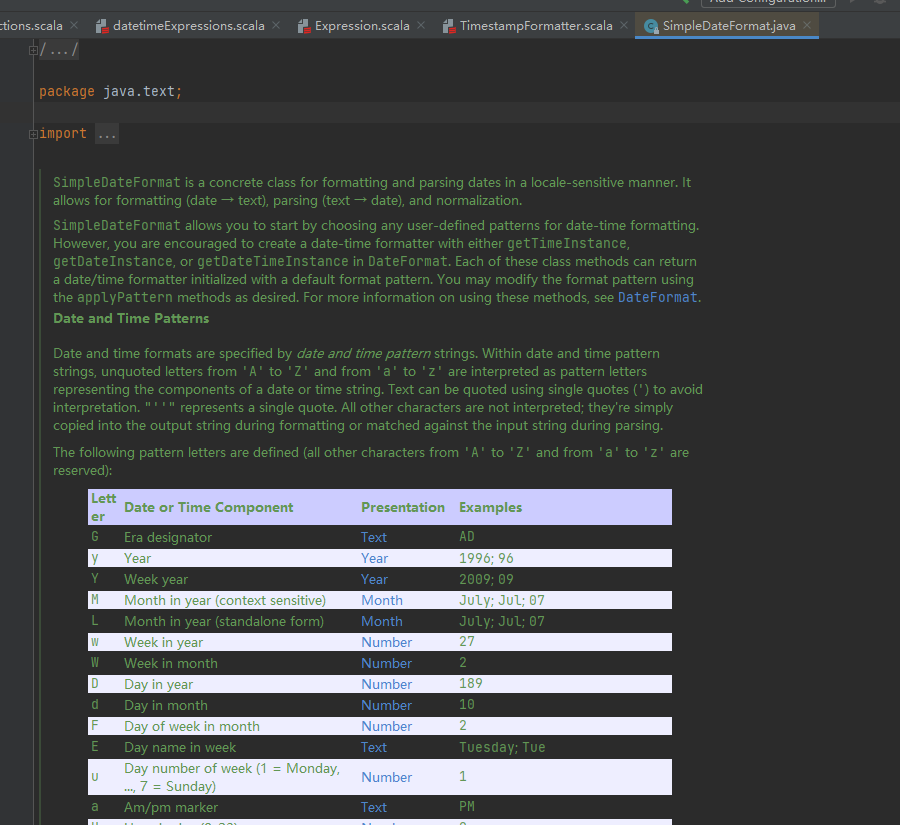
spark dateformat源码排错
背景
有一个任务 yyyy写成了YYYY,导致年份不对触发告警
select from_unixtime(unix_timestamp(),YYYY-MM-dd HH:mm:ss)
第一时间用spark dateformat搜索下看看官网,发现spark 官网也没有描述YYYY的信息
Datetime patterns - Spark 3.5.0 Documentati…
Chunjun纯钧(Flinkx)同步任务开发通用配置参数详解
Chunjun纯钧(Flinkx)是一款稳定、易用、高效、批流一体的数据集成框架,目前基于实时计算引擎Flink实现多种异构数据源之间的数据同步与计算,支持JSON模版配置任务,兼容FlinkSQL语法。本文对chunjun同步任务的配置文件进行详细的介绍和总结。 文章目录 配置文件结构详解Conte…
数据仓库系列01-规划篇
企业在构建数据仓库时,首先需要整体上对数据仓库进行规划,制定规范。数仓架构师需要对数仓分层、业务分类、数据域、业务过程、数据集市、主题域进行设计。这样模型设计时,可以将模型关联到数仓分层、业务分类、数据域、业务过程等对所建模型…
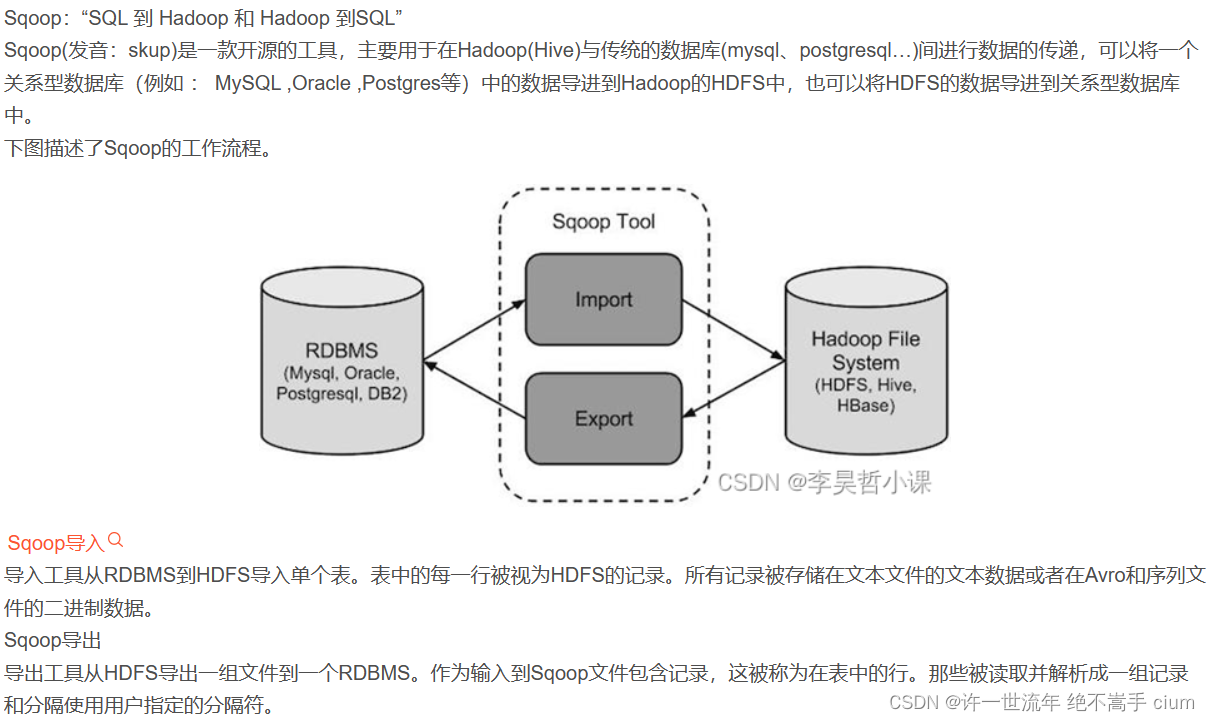
hql、数据仓库、sql调优、hive sql、python
SQL/HQL
HQL(Hibernate Query Language) 是面向对象的查询语言 SQL的操作对象是数据列、表等数据库数据 ; 而HQL操作的是类、实例、属性
#FROM
String hql "from com.demo.bean.User" "select * from user"
#WHERE
"form User u where u.id 1…
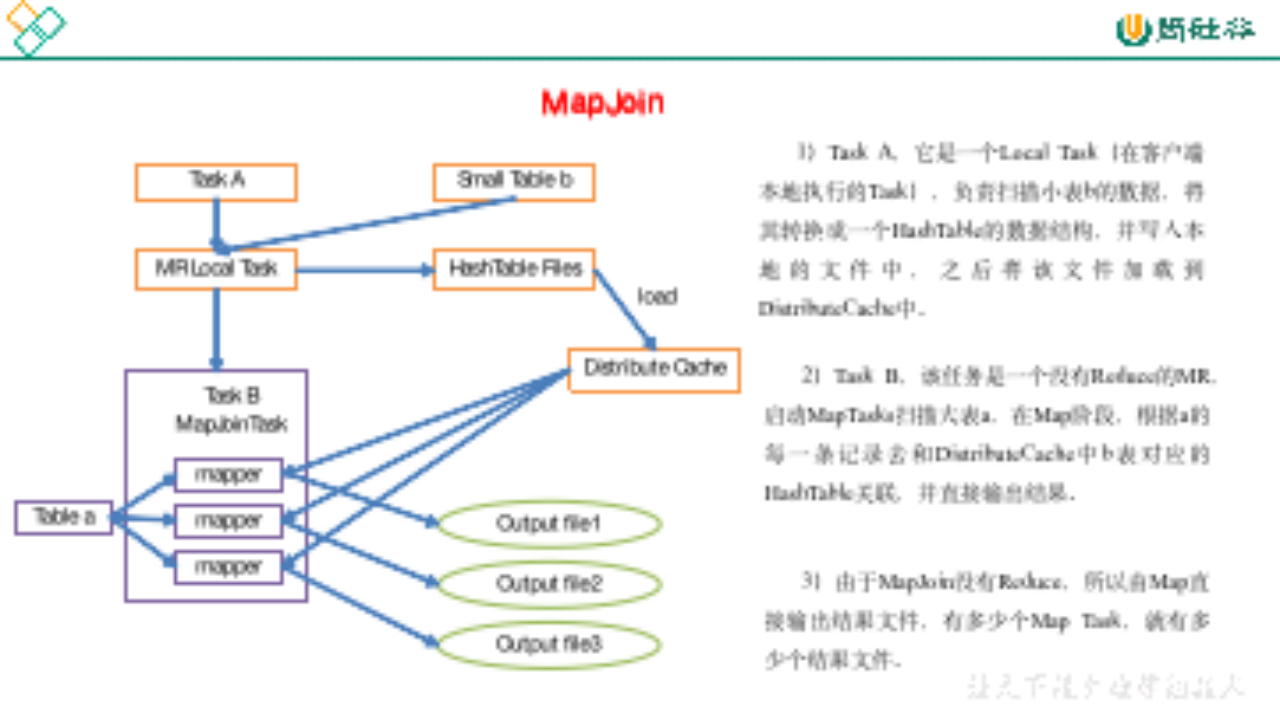
Hive生产调优介绍
1.Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。 在hive-default.xml…

Hive中left join 中的where 和 on的区别
目录
一、知识点
二、测试验证
三、引申 一、知识点 left join中关于where和on条件的知识点:
多表left join 是会生成一张临时表。on后面: 一般是对left join 的右表进行条件过滤,会返回左表中的所有行,而右表中没有匹配上的数…

2024年热门项目管理软件推荐:提升项目管理效率的工具集合
项目管理系统软件有哪些?本文将根据项目管理系统软件的功能、选择项目管理系统软件对公司的好处,根据国际上知名软件评测网站G2 Grid的评测结果对8款2024年好用的项目管理软件:Zoho Projects、Smartsheet、monday、Asana、ClickUp、Notion、A…
【美团】交易系统平台-数据仓库研发工程师
更新时间:2024/01/28|工作地点:北京市|事业群:到家事业群|工作经验:3年 部门介绍
到家研发平台秉承“零售科技”战略,致力于推动餐饮、零售需求侧和供给侧数字化升级,构…
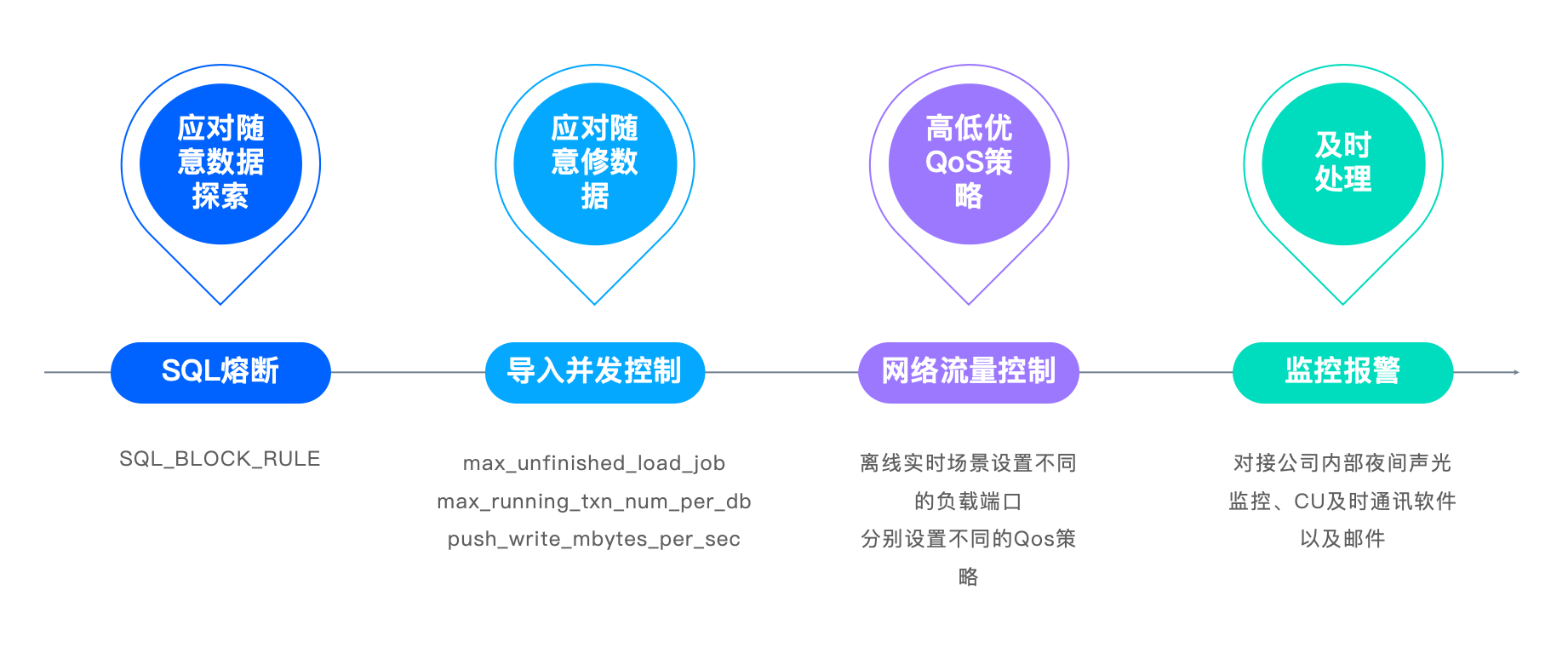
查询速度提升15倍!银联商务基于 Apache Doris 的数据平台升级实践
本文导读:
在长期服务广大规模商户的过程中,银联商务已沉淀了庞大、真实、优质的数据资产数据,这些数据不仅是银联商务开启新增长曲线的基础,更是进一步服务好商户的关键支撑。为更好提供数据服务,银联商务实现了从 H…
hive中如何求取中位数?
目录 中位数的概念代码实现准备数据实现 中位数的概念
中位数(Median)又称中值,统计学中的专有名词,是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值,其可将数值集合…
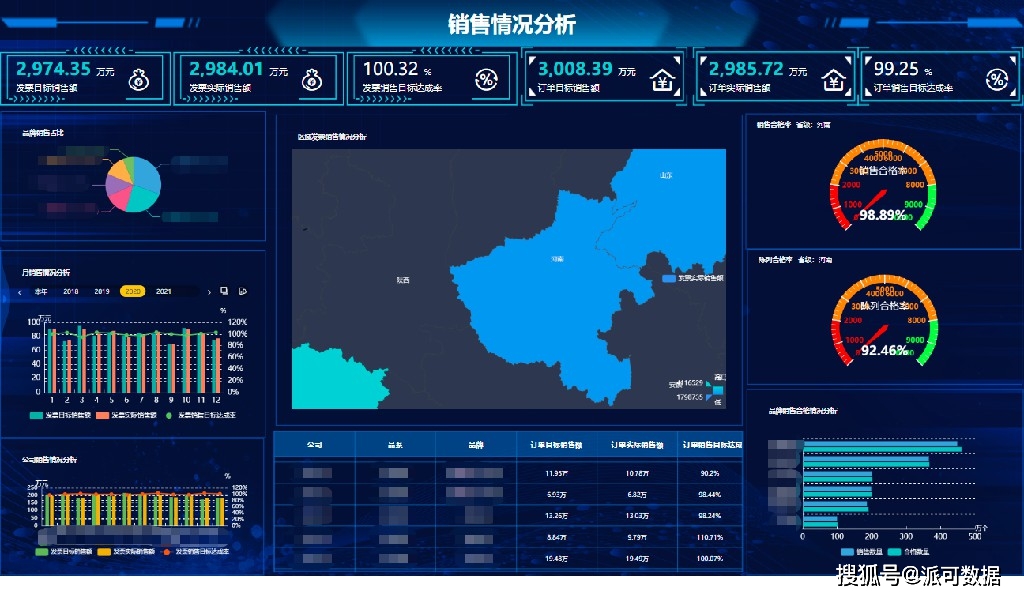
到底什么是商业智能 BI?BI能为企业带来什么, 企业又为啥上BI,全在这里?
随着人工智能、云计算、大数据、互联网、物联网等新一代信息化、数字化技术在各行各业内开始大规模的应用,社会上的数字化、信息化程度不断加深,而数据价值也在这样的刺激下成为了个人、机构、企业乃至国家的重要战略资源,成为了继土地、劳动…
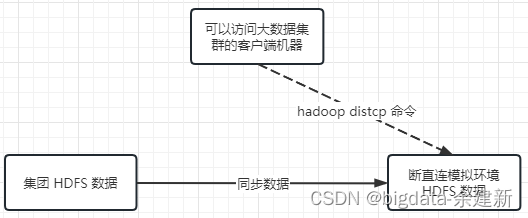
ETL详解--数据仓库技术
一、ETL简介
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程,是数据仓库的生命线。它…
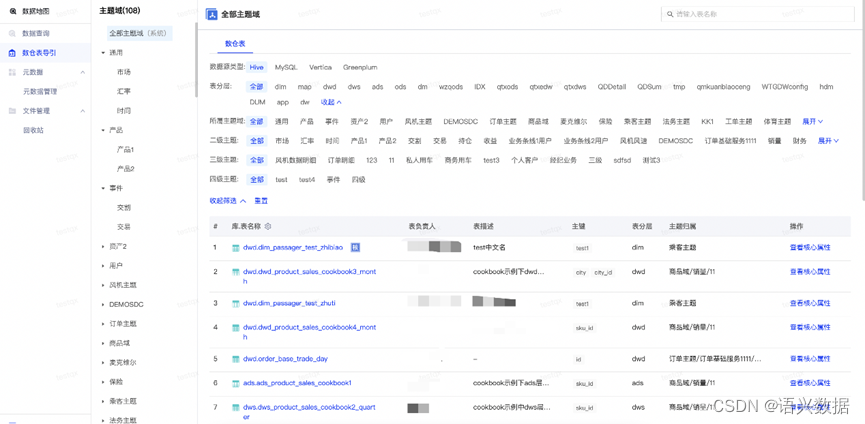
数仓建设学习路线(三)元数据管理
什么是元数据?
简单来说就是描述数据的数据,更直白来说就是描述表名、表制作者、表字段、表生命周期、表存粗等信息的数据 元数据该如何管理
工具化 开源: 可通过atlas获取表依赖及信息做二次开发,或者完成可视化界面 平台化&am…

hive 用户自定义函数udf,udaf,udtf
udf:一对一的关系 udtf:一对多的关系 udaf:多对一的关系
使用Java实现步骤
自定义编写UDF函数注意: 1.需要继承org.apache.hadoop.hive.ql.exec.UDF 2.需要实现evaluete函数 编写UDTF函数注意: 1.需要继承org.apache…

数据仓库 Apache Hive
一、数据分析
1、数据仓库 数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。 数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(…
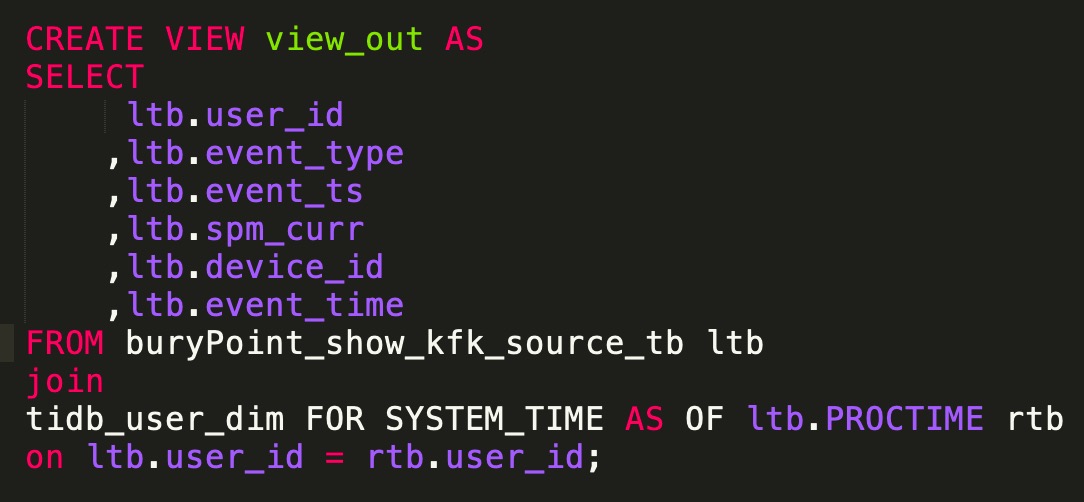
伴鱼实时数仓建设案例
伴鱼实时数仓建设案例 文章目录 伴鱼实时数仓建设案例伴鱼实时作业应用场景伴鱼实时数仓的建设体系DWD 层复杂场景数据处理方案1. 数据的去重2. join场景两条实时数据流相关联对于关联历史数据 3. 从数据形态观查join DWS 数据层数据处理方案未来与展望 随着伴鱼业务的快速发展…
【数据开发】HiveSQL 临时表分步执行(with, as )与时间函数(时间戳unix_timestamp)
1、分步执行(with…as…)
Hive SQL中的WITH…AS…语句可以用于分步执行,即将一个大的查询语句拆分成多个小的查询语句,每个小的查询语句都可以使用WITH…AS…语句定义一个临时表,然后在后面的查询语句中使用这些临时表…

熟悉 Hive 的基本操作
4、实验步骤
(一)创建一个内部表 stocks,字段分隔符为英文逗号,表结构下所示。 col_namedata_typeexchangestringsymbolstringymdstringprice_openfloatprice_highfloatprice_lowfloatprice_closefloatvolumeintprice_adj_closefloat创建内部表stocks:
create table if …
(12)Hive调优——count distinct去重优化
离线数仓开发过程中经常会对数据去重后聚合统计,count distinct使得map端无法预聚合,容易引发reduce端长尾,以下是count distinct去重调优的几种方式。
解决方案一:group by 替代
原sql 如下:
#7日、14日的app点击的…
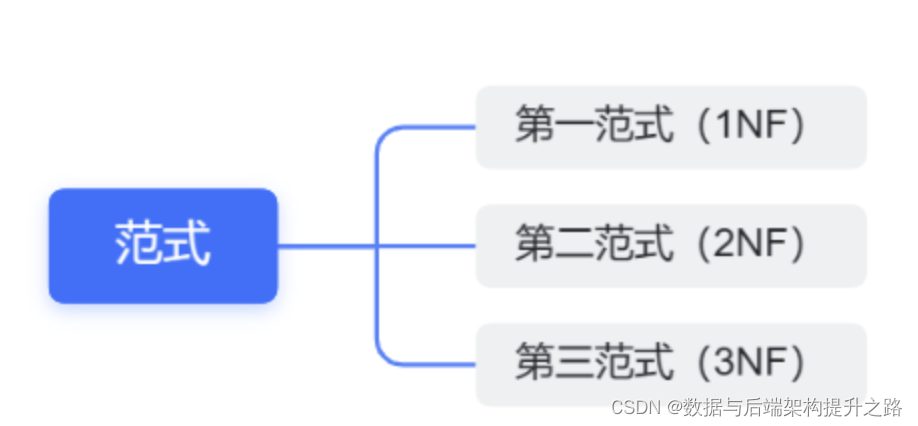
从实践角度优化数据库设计:深入解析三范式的应用
总述 第一范式(1NF):要求关系模式中的每个属性都是不可分的数据项,即属性具有原子性。第二范式(2NF):在满足1NF的基础上,要求关系模式中的所有非主属性都完全函数依赖于整个候选键(或主键)。第三范式(3NF):在满足2NF的基础上,要求关系模式中的每个非主属性都不传…
Hive用户自定义函数之UDF开发
在进行大数据分析或者开发的时候,难免用到Hive进行数据查询分析,Hive内置很多函数,但是会有一部分需求需要自己开发,这个时候就需要自定义函数了,Hive的自定义函数开发非常方便,今天首先讲一下UDF的入门开发…


hive企业级调优策略之CBO,谓词下推等优化
测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511 本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
CBO优化
优化说明
CBO是指Cost based Optimizer,即基于计算成本的优化…
数据仓库【2】:架构
数据仓库【2】:架构 1、架构图2、ETL流程2.1、ETL -- Extract-Transform-Load2.1.1、数据抽取(Extraction)2.1.2、数据转换(Transformation)2.1.3、数据加载( Loading ) 2.2、ETL工具2.2.1、结构…
银行数据仓库体系实践(6)--调度系统
调度系统是数据仓库的重要组成部分,也是每个银行或公司一个基础软件或服务,需要在全行或全公司层面进行规划,在全行层面统一调度工具和规范,由于数据类系统调度作业较多,交易类系统批量优先级高,为不互相影…

银行数据仓库体系实践(11)--数据仓库开发管理系统及开发流程
数据仓库管理着整个银行或公司的数据,数据结构复杂,数据量庞大,任何一个数据字段的变化或错误都会引起数据错误,影响数据应用,同时业务的发展也带来系统不断升级,数据需求的不断增加,数据仓库需…
ClickHouse(21)ClickHouse集成Kafka表引擎详细解析
文章目录 Kafka表集成引擎配置Kerberos 支持 虚拟列 资料分享参考文章 Kafka表集成引擎
此引擎与Apache Kafka结合使用。
Kafka 特性:
发布或者订阅数据流。容错存储机制。处理流数据。
老版Kafka集成表引擎参数格式:
Kafka(kafka_broker_list, kaf…
Hive自定义函数支持国密SM4解密
当前项目背景需要使用到国密SM4对加密后的数据进行解密,Hive是不支持的,尝试了华为DWS数仓,华为只支持在DWS中的SM4加密解密,不支持外部加密数据DWS解密 新建Maven工程
只需要将引用的第三方依赖打到jar包中,hadoop和…
(11)Hive调优——explain执行计划
一、explain查询计划概述 explain将Hive SQL 语句的实现步骤、依赖关系进行解析,帮助用户理解一条HQL 语句在底层是如何实现数据的查询及处理,通过分析执行计划来达到Hive 调优,数据倾斜排查等目的。 官网指路:
https://cwiki.ap…
SparkSQL和Hive语法差异
SparkSQL和Hive语法差异
1、仅支持Hive
SparkSQL关联条件on不支持函数rand()创建零时表时,Spark不支持直接赋值nullSpark无法读取字段类型为void的表SparkSQL中如果表达式没有指定别名,SparkSQL会将整个表达式作为别名,如果表达式中包含特殊…

Hive基础知识(十六):Hive-SQL分区表使用与优化
1. 分区表
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区&…
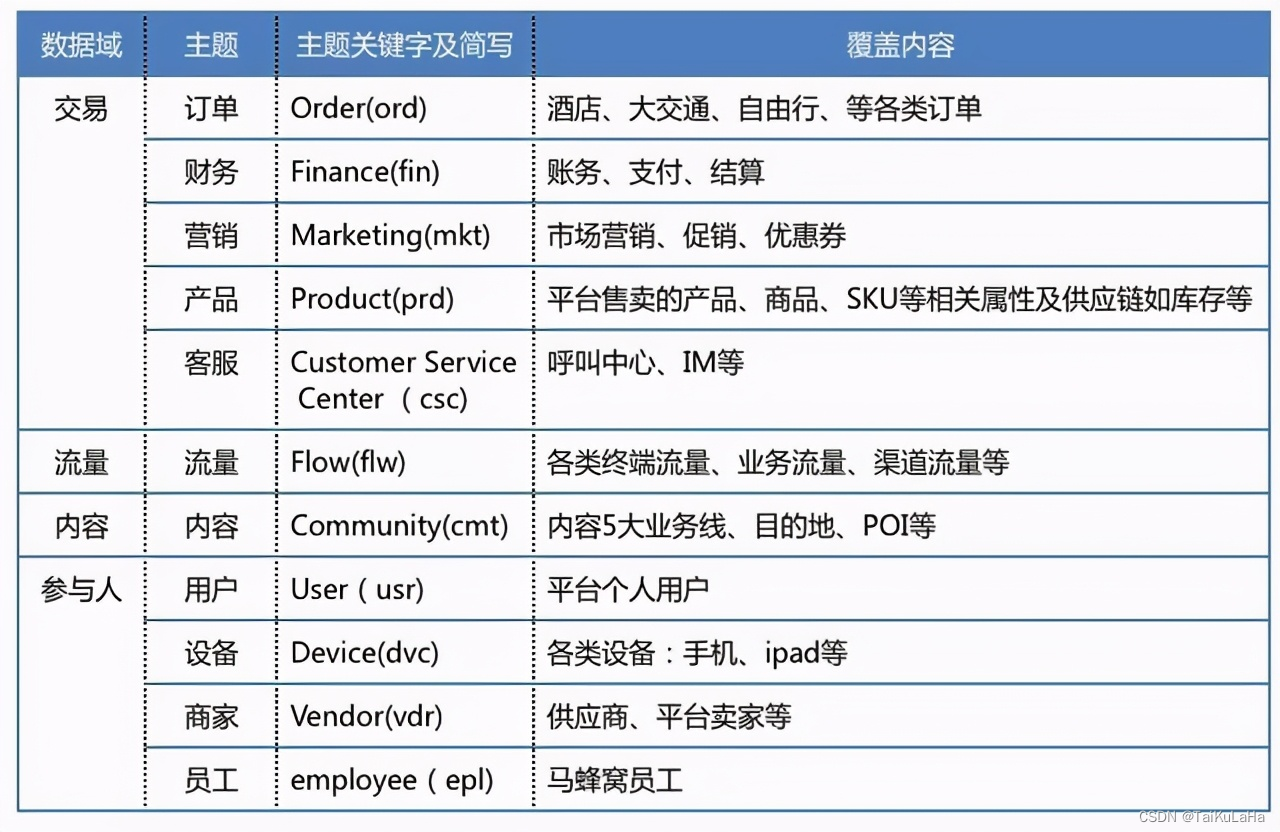
【数据仓库】主题域和数据域
数据域与主题域区别 https://www.cnblogs.com/datadance/p/16898254.html
数据域是自下而上,以业务数据视角来划分数据,一般进行完业务系统数据调研之后就可以进行数据域的划分。针对公共明细层(DWD)进行主题划分。主题域则自上而…

Hive-high Avaliabl
hive—high Avaliable
hive的搭建方式有三种,分别是
1、Local/Embedded Metastore Database (Derby)
2、Remote Metastore Database
3、Remote Metastore Server
一般情况下,我们在学习的时候直接使用hive –service metastore的方式…

离线数据仓库-关于增量和全量
数据同步策略 数据仓库同步策略概述一、数据的全量同步二、数据的增量同步三、数据同步策略的选择 数据仓库同步策略概述
应用系统所产生的业务数据是数据仓库的重要数据来源,我们需要每日定时从业务数据库中抽取数据,传输到数据仓库中,之后…
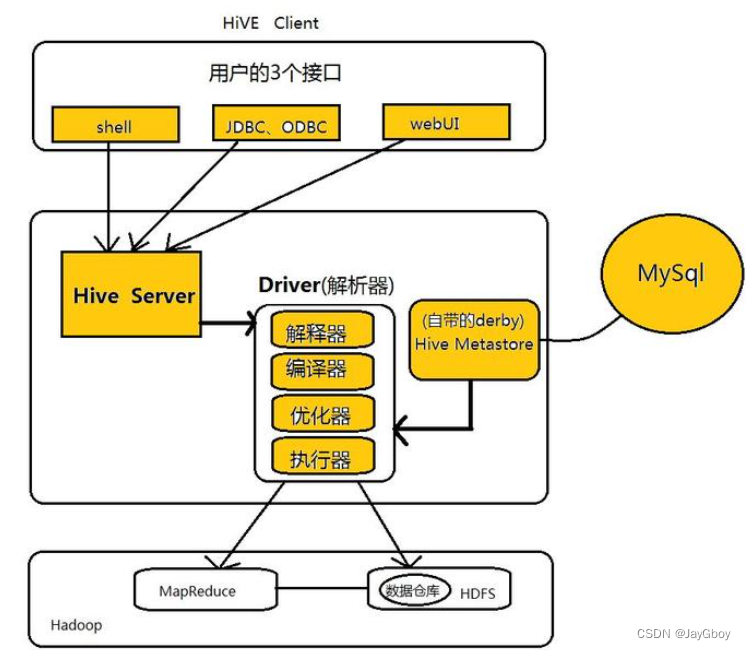
Hive入门,Hive是什么?
1.1Hive是什么?
Hive是一个开源的数据仓库工具,主要用于处理大规模数据集。它是建立在Hadoop生态系统之上的,利用Hadoop的分布式存储和计算能力来处理和分析数据。 Hive的本质是一个数据仓库基础设施,它提供了一种类似于SQL的查询…
2024.1.7 Spark SQL , DataFrame
目录 一 . SparkSQL简介
二 . Spark SQL与HIVE的异同 三 . DataFrame
1. 创建 DataFrame
2. RDD转换DataFrame
四 . 操作DataFrame SQL方式:
DSL方式: 一 . SparkSQL简介
Spark SQL只能处理结构化数据 ,属于Spark框架一个部分 Schema:元数据信息
特点: 融合性 ,统一数…
Hive建表时候用的参数及其含义
1.序列化与反序列化
序列化器(Serializer)和反序列化器(Deserializer)
SerDe 是两个单词的拼写 serialized(序列化) 和 deserialized(反序列化)。 什么是序列化和反序列化呢?
当进程在进行远程通信时,彼…
【成本价特惠】招募证书代理:工信部、PMP、阿里云、华为等认证,机会难得!
扫码和我联系
亲爱的读者朋友们,
今天,我想和大家分享一个难得的机会。我们目前正在积极招募各类证书的代理,包括工信部的证书、PMP(项目管理专业人士)证书、阿里云证书、华为证书、OCP 证书、CFA 证书等。这些证书在…
Hive 数仓及数仓设计方案
数仓(Data Warehouse)
数据仓库存在的意义在于对企业的所有数据进行汇总,为企业各个部门提供一个统一、规范的出口。做数仓就是做方案,是用数据治理企业的方案。
数据仓库的特点
面向主题集成 公司中不同的部门都会去数据仓库中拿数据,把独…
2024.1.30 Spark SQL的高级用法
目录 1、如何快速生成多行的序列
2、如何快速生成表数据
3.开窗函数
排序函数
平分函数
聚合函数 向上向下窗口函数 1、如何快速生成多行的序列
-- 需求: 请生成一列数据, 内容为 1 , 2 , 3 , 4 ,5 仅使用select语句
select explode(split(1,2,3,4,5,,)) as num;-- 需…

MySQL 图书管理系统
1.需求分析
1.1项目需求分析简介
1.1.1信息需求分析
(1) 图书信息:包括书籍编号,书籍名称,出版社,作者,库存量,出版日期,价格,库存,剩余量,类别等…
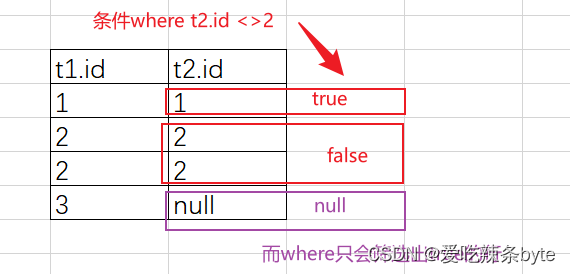
sql指南之null值用法
注明:参考文章:
SQL避坑指南之NULL值知多少?_select null as-CSDN博客文章浏览阅读2.9k次,点赞7次,收藏21次。0 引言 SQL NULL(UNKNOW)是用来代表缺失值的术语,在表中的NULL值是显示…
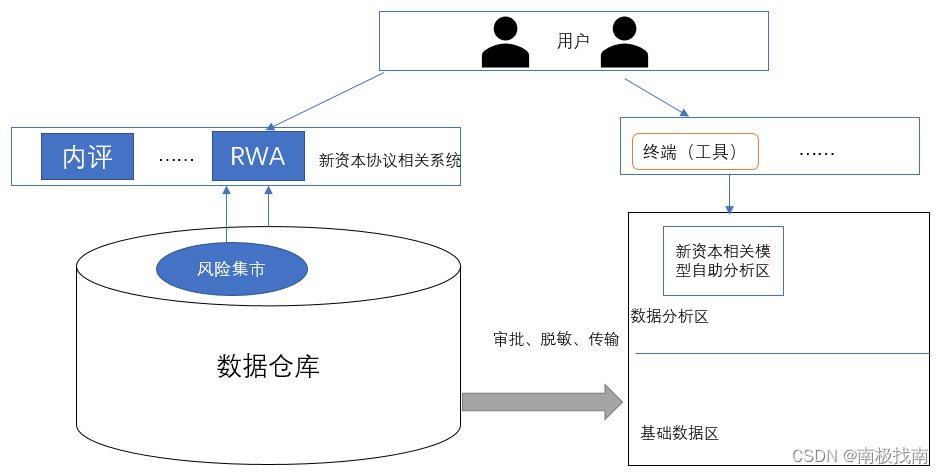
银行数据仓库体系实践(15)--数据应用之巴塞尔新资本协议
巴塞尔新资本协议介绍 在银行管理中经常会听到巴3、新资本协议等专用词,那这都是指《巴塞尔资本协议》,全称《关于统一国际银行资本衡量和资本标准的协议》。新资本协议的五大目标是:促进金融体系的安全性和稳健性(保持总体资本水…
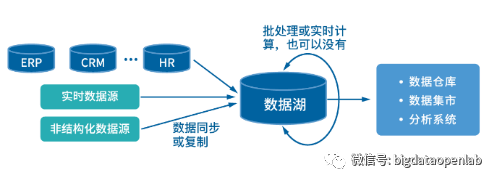
数据仓库、数据集市、数据湖,你的企业更适合哪种数据管理架构?
建设企业级数据平台,首先需要了解企业数据,确认管理需求,并选择一个数据管理架构。那么面对纷繁复杂的数据来源,多元化的数据结构,以及他们的管理使用需求,企业数据平台建设该从何处入手呢?哪个…
Hive 最全面试题及答案(基础篇)
基本知识 hive元数据存储 Hive 元数据存储了关于表、分区、列、分桶等信息。 在生产环境中,通常会将 Hive 的元数据存储在外部的关系型数据库中,如 MySQL 或 PostgreSQL。这样可以提供更好的性能、可扩展性和容错性。通过配置 Hive 的元数据存储为 MySQL 或 PostgreSQL,可以…
hive常用函数整理
关于日期datediff(date1, date2)返回date1与data2之间的天数;date_sub(start_day, num_days)返回start_day前num_days的日期;timestampdiff(): timestampdiff(year|month|day|hour|minute|second,date1,date2)#对于比较的两个时间…
数据集市是什么?数据集市和数据仓库有什么区别
前言
本文隶属于专栏《100个问题搞定大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见100个问题搞定大数据理论体系 WHAT
数据集市…

支持多模型数据分析探索的存算分离湖仓一体架构解析(上)
当企业需要建设独立的数据仓库系统来支撑BI和业务分析业务时,有了“数据湖数据仓库”的混合架构。但混合架构带来了更高的建设成本、管理成本和业务开发成本。随着大数据技术的发展,通过在数据湖层增加分布式事务、元数据管理、极致的SQL性能、SQL和数据…
EMR StarRocks实战——Mysql数据实时同步到SR
文章摘抄阿里云EMR上的StarRocks实践:《基于实时计算Flink使用CTAS&CDAS功能同步MySQL数据至StarRocks》
前言 CTAS可以实现单表的结构和数据同步,CDAS可以实现整库同步或者同一库中的多表结构和数据同步。下文主要介绍如何使用Flink平台和E-MapRed…
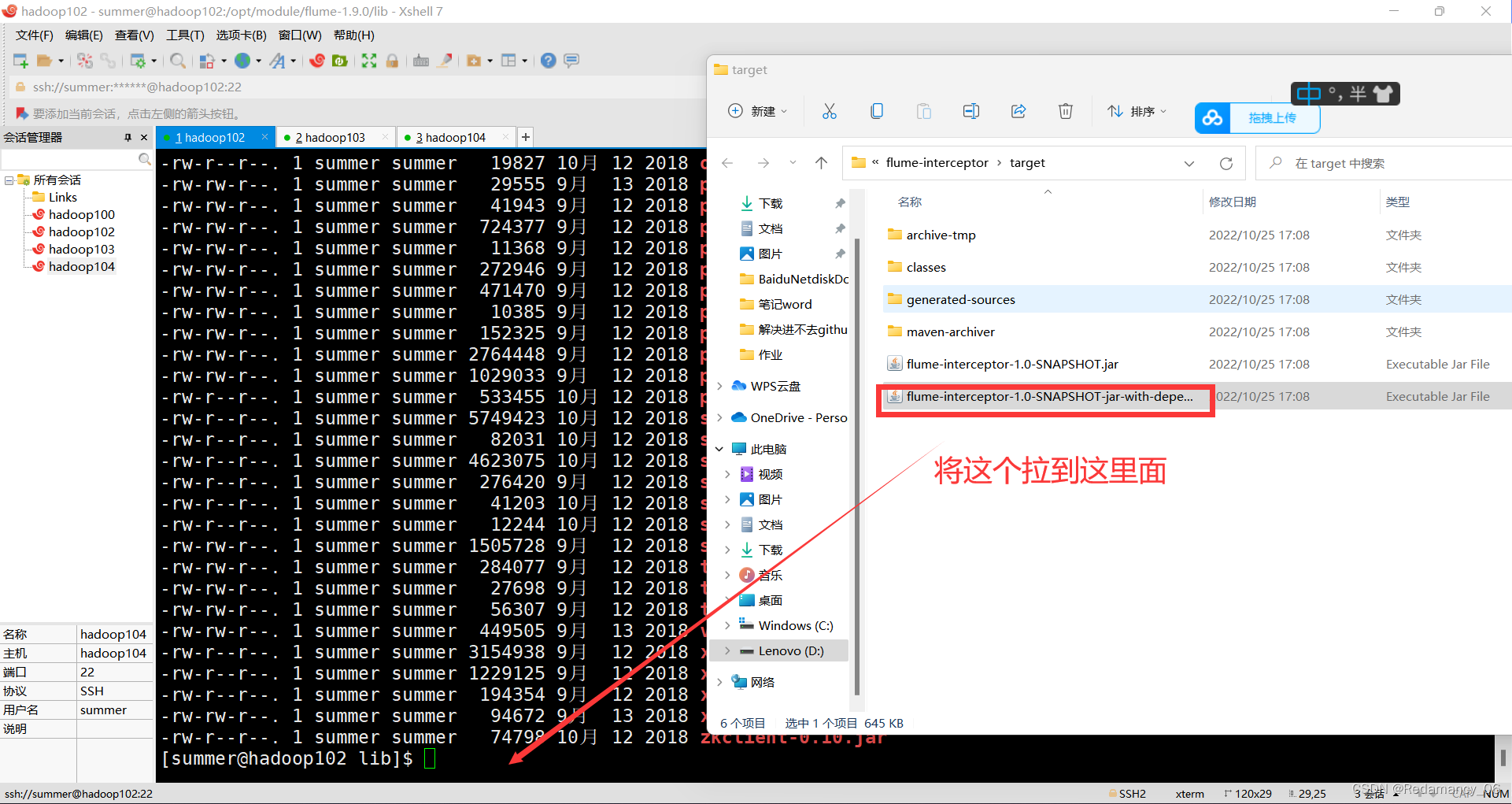
大数据项目之电商数仓、日志采集Flume配置概述、日志采集Flume配置实操
文章目录4. 用户行为数据采集模块4.3 日志采集Flume4.3.2 日志采集Flume配置概述4.3.2.1 TailDirSource4.3.2.2 KafkaChannel4.3.3 日志采集Flume配置实操4.3.3.1 创建Flume配置文件4.3.3.2 配置文件内容如下4.3.3.3 编写Flume拦截器4.3.3.3.1 创建Maven工程flume-interceptor4…

数字化时代,如何推动实体经济和数字经济的融合
实体经济是一国经济的立身之本和命脉所在,数字经济是当今世界科技革命和产业变革的阵地前沿,推动数字经济和实体经济融合发展,已经成为新形势下主动把握新机遇、打造新引擎、实现经济高质量发展的必然选择。
领域融合
真正能够成为现代社会…
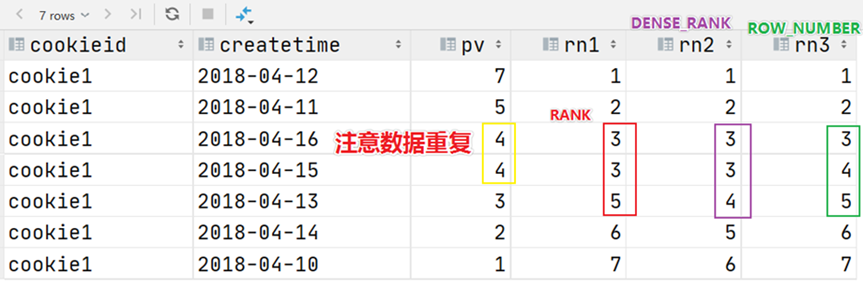
【Hive】——函数
1 概述 2 内置函数
内置函数(build-in)指的是Hive开发实现好,直接可以使用的函数,也叫做内建函数。官方文档地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManualUDF describe function extended get_json_obj…
数据库是否可以直接作为数据仓库的数据源
在数据仓库使用数据时,我们是否可以直接将数据库作为数据源?如果使用了,会存在哪些问题?
数据库中存储的是业务数据,存储方式是行式存储;而数据仓库中数据是以列式存储的;如果数据仓库要想使用…

Hive数据定义(1)
hive数据定义是hive的基础知识,所包含的知识点有:数据仓库的创建、数据仓库的查询、数据仓库的修改、数据仓库的删除、表的创建、表的删除、表的修改、内部表、外部表、分区表、桶表、表的修改、视图。本篇文章先介绍:数据仓库的创建、数据仓…

presto/trino 入门介绍实战
引言
Presto是一款分布式SQL查询引擎,它能够在大规模数据集上实现快速、交互式的查询。本文将介绍Presto的基本概念并结合一些实际的代码示例,能够让的大家快速入门并在实际项目中应用。
官网:Launch Presto: Local download, JDBC, Docker…

定向减免!函数计算让 ETL 数据加工更简单
业内较为常见的高频短时 ETL 数据加工场景,即频率高时延短,一般费用大头均在函数调用次数上,推荐方案一般为攒批处理,高额的计算成本往往令用户感到头疼,函数计算推出定向减免方案,让 ETL数据加工更简单、更…
Hive之set参数大全-11
设置 Map Join 操作中优化哈希表的工作集大小(working set size)
hive.mapjoin.optimized.hashtable.wbsize 是 Apache Hive 中的一个配置属性,用于设置 Map Join 操作中优化哈希表的工作集大小(working set size)。 …

【数据库原理】(38)数据仓库
数据仓库(Data Warehouse, DW)是为了满足企业决策分析需求而设计的数据环境,它与传统数据库有明显的不同。
一.数据库仓库概述 定义: 数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持企业管理和…

定向减免!函数计算让轻量 ETL 数据加工更简单,更省钱
作者:澈尔、墨飏
业内较为常见的高频短时 ETL 数据加工场景,即频率高时延短,一般均可归类为调用密集型场景。此场景有着高并发、海量调用的特性,往往会产生高额的计算费用,而业内推荐方案一般为攒批处理,业…
银行数据仓库体系实践(14)--数据应用之内部报表及数据分析
在银行日常经营中,每个部门、分支行随时随地都需要进行数据统计和分析,才能对银行当前业务状况及时了解,以进行后续经营策略、营销活动、风险策略的调整和决策。那在平时进行数据分析时除了各数据应用系统(如各类监管报表系统、财…

【Hive】——安装部署
1 MetaData(元数据) 2 MetaStore (元数据服务) 3 MetaStore配置方式 3.1 内嵌模式 3.2 本地模式 3.3 远程模式 4 安装前准备 <!-- 整合hive --><property><name>hadoop.proxyuser.root.hosts</name><v…
MaxCompute获取当前季度的第一天日期(odps sql)
工作中遇到获取当前季度的第一天,如下所示
SELECT CASE WHEN QUARTER(GETDATE()) 1 THEN DATETRUNC(GETDATE(),yyyy)
WHEN QUARTER(GETDATE()) 2 THEN DATEADD(DATETRUNC(GETDATE(),yyyy),3,mm)
WHEN QUARTER(GETDATE()) 3 THEN DATEADD(DATETRUNC(GETDATE(),…
GBASE南大通用 GCDW阿里云计算巢:自动化部署云原生数据仓库
目前,GBASE南大通用已与阿里云计算巢合作,双方融合各自技术优势,助力企业用户实现云上数据仓库的自动化部署,让用户在云端获取数据仓库服务“更简单”,让用户在云端使用数据仓库服务“更便捷”,满足企业用户…
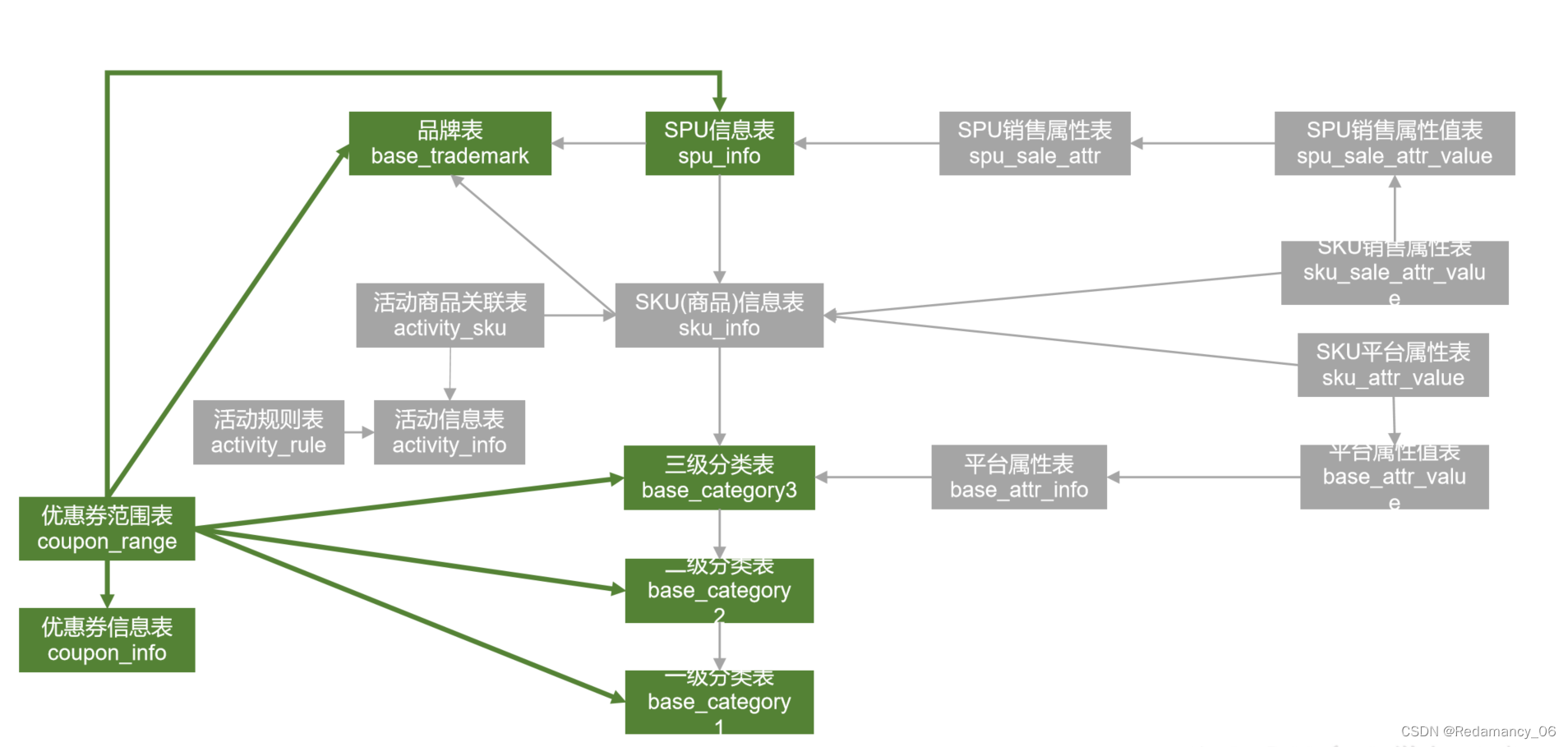
大数据项目之电商数仓、电商业务简介、电商业务流程、电商常识、业务数据介绍、电商业务表、后台管理系统
文章目录5. 电商业务简介5.1 电商业务流程5.2 电商常识5.2.1 SKU和SPU5.2.2 平台属性和销售属性5.2.2.1 平台属性5.2.2.2 销售属性6. 业务数据介绍6.2 电商业务表6.2.1 收藏商品6.2.2 加购物车6.2.3 领用优惠券6.2.4 下单6.2.5 支付6.2.6 退单6.2.7 退款6.2.8 评价6.3 后台管理…
大数据项目之电商数仓、实时数仓同步数据、离线数仓同步数据、用户行为数据同步、日志消费Flume配置实操、日志消费Flume测试、日志消费Flume启停脚本
文章目录8. 实时数仓同步数据9. 离线数仓同步数据9.1 用户行为数据同步9.1.1 数据通道9.1.1.1 用户行为数据通道9.1.2 日志消费Flume配置概述9.1.2.1 日志消费Flume关键配置9.1.3 日志消费Flume配置实操9.1.3.1 创建Flume配置文件9.1.3.2 配置文件内容如下9.1.3.2.1 配置优化9.…
数据治理中最常听到的名词有哪些?
开门见山,我们先来说说何为“数据治理”
数据治理就是实现数据价值的过程。通俗的理解就是让企业的数据从不可控、不可用、不好用到可控、方便易用且对业务有极大帮助的过程。
这个过程怎么实现?通过采集、传输、储存等一系列标准化流程将原本零散的数…

海豚dolphinscheduler 通过shell 调用.sql文件 传参
1. 准备sql文件
1.1 资源中心--创建文件 1.2 文件格式选择 sql, 文件内容 填要执行的sql内容 1.3 点击创建保存 2.shell调用.sql文件
2.1 拖拽一个shell 节点 2.2 编辑shell节点 hive -e:后面跟hivesql字符串 例如:hive -e "select * from studen…

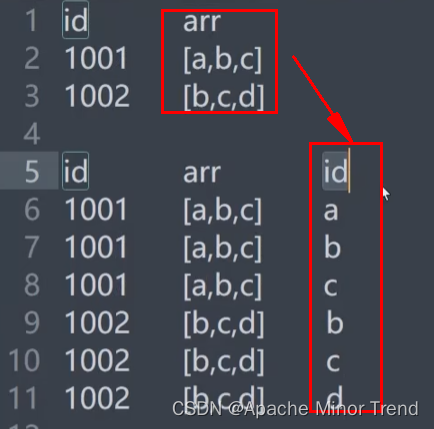
【离线数仓-8-数据仓库开发DWD层设计要点-工具域互动域流量域用户域相关事实表】
离线数仓-8-数据仓库开发DWD层-工具域&互动域&流量域&用户域相关事实表离线数仓-8-数据仓库开发DWD层设计要点-工具域&互动域&流量域&用户域相关事实表一、工具域相关事实表1.工具域优惠券领取事务事实表&使用(下单)事务事实…

如何理解元数据、数据元、元模型、数据字典、数据模型这五个的关系?如何进行数据治理呢?数据治理该从哪方面入手呢?
如何理解元数据、数据元、元模型、数据字典、数据模型这五个的关系?如何进行数据治理呢?数据治理该从哪方面入手呢?导读一、数据元二、元数据三、数据模型四、数据字典五、元模型导读
请问元数据、数据元、数据字典、数据模型及元模型的区别…
debezium-mysql使用(一)
docker 安装mysql 参考: docker 安装mysql 8.x_大大蚊子的博客-CSDN博客
docker 安装kafka 参考: docker 安装 kafka单节点_docker kafka 单节点_大大蚊子的博客-CSDN博客
docker 安装debezium参考:debezium docker 容器创建_大大蚊子的博…
写多读少的链路跟踪系统
OLTP与OLAP的区别精简总结 OLTP(实时交易库大量短事务对IO要求高) 一、面向交易的实时处理系统OLTP OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,记录即时的增、删、改、查,比如在银行存取一笔款,就是一个事…
Apache Doris 1.2.3 Release 版本正式发布
亲爱的社区小伙伴们,我们很高兴地宣布,Apache Doris 于 2023 年 3 月 20 日迎来 1.2.3 Release 版本的正式发布!在新版本中包含超过 200 项功能优化和问题修复。同时,1.2.3 版本作为 1.2 LTS 的迭代版本,更加稳定易用&…
【SQL开发实战技巧】系列(二十六):数仓报表场景☞聊聊ROLLUP、UNION ALL是如何分别做分组合计的以及如何识别哪些行是做汇总的结果行
系列文章目录
【SQL开发实战技巧】系列(一):关于SQL不得不说的那些事 【SQL开发实战技巧】系列(二):简单单表查询 【SQL开发实战技巧】系列(三):SQL排序的那些事 【SQL开发实战技巧…
Hive数据仓库简介
文章目录Hive数据仓库简介一、数据仓库简介1. 什么是数据仓库2. 数据仓库的结构2.1 数据源2.2 数据存储与管理2.3 OLAP服务器2.4 前端工具3. 数据仓库的数据模型3.1 星状模型3.2 雪花模型二、Hive简介1. 什么是Hive2. Hive的发展历程3. Hive的本质4. Hive的优缺点4.1 优点4.2 缺…
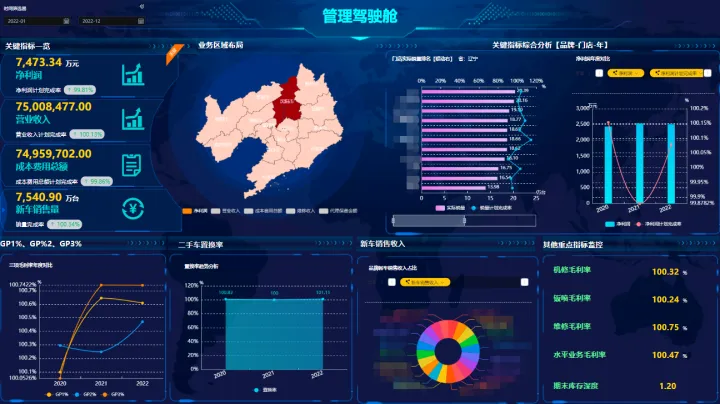
数据处理时代,绕不开的数据分析
数据分析的出现是因为人类难以理解海量数据所呈现出来的信息,不能从中找到相应的规律来对现实中的事物进行对应,我们都知道数据有很高的价值,但不能利用的价值,没有任何意义。
为了解决这一问题,数据分析在长期的数据…
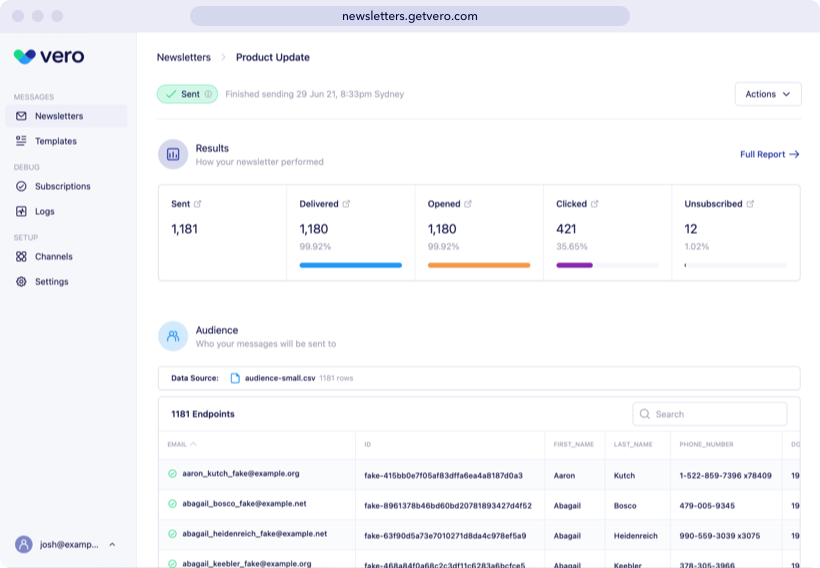
现代数据栈MDS应用落地介绍—Vero营销自动化平台
Dazdata MDS现代数据栈MDS的出现使得中小企业低成本获得大数据处理能力成为可能,技术的进步使得各种基于MDS的大数据应用如雨后春笋般涌现,不同于国内的数据中台更多强调数据处理技术,MDS注重落地和最后一公里的大数据应用。Vero是一款现代数…
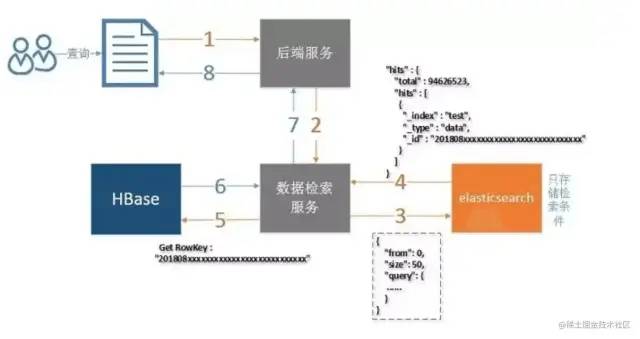
如何在千万级数据中查询 10W 的数据并排序
前言
在开发中遇到一个业务诉求,需要在千万量级的底池数据中筛选出不超过 10W 的数据,并根据配置的权重规则进行排序、打散(如同一个类目下的商品数据不能连续出现 3 次)。
下面对该业务诉求的实现,设计思路和方案优…
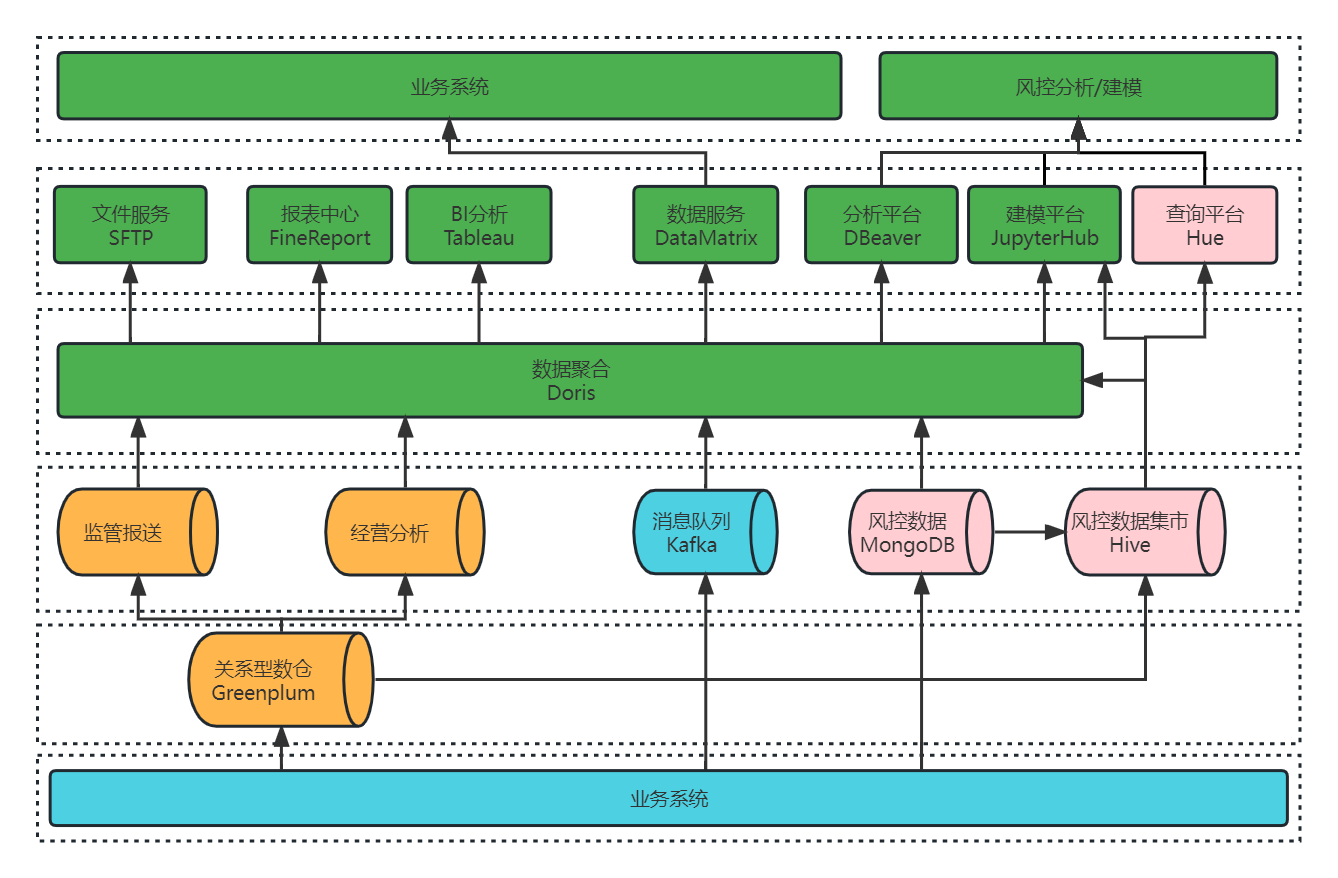
杭银消金基于 Apache Doris 的统一数据查询网关改造
导读: 随着业务量快速增长,数据规模的不断扩大,杭银消金早期的大数据平台在应对实时性更强、复杂度更高的的业务需求时存在瓶颈。为了更好的应对未来的数据规模增长,杭银消金于 2022 年 10 月正式引入 Apache Doris 1.2 对现有的风…
![[架构之路-150]-《软考-系统分析师》- 7-企业信息化战略与实施-7-软件集成技术](https://img-blog.csdnimg.cn/img_convert/7fcbabbfcaf2fbbc8fba4f84dd56cea8.jpeg)
[架构之路-150]-《软考-系统分析师》- 7-企业信息化战略与实施-7-软件集成技术
目录
一、背景介绍
二、企业应用集成(Enterprise Application Integration,EAI)
1、基本概念
2、集成技术分类
3、表示集成
4、数据集成
5、控制集成
6、企业内部不同业务流程之间的集成
7、企业之间的应用集成 一、背景介绍
在企业…
ETL还是ELT:企业如何选择构建数据仓库的最佳工具?
一、企业数据仓库的构建对于数据驱动的决策和业务增长至关重要
在构建数据仓库的过程中,选择合适的工具和方法是实现高效、可靠的数据集成和转换的第一步,构建数据中台最重要的是得先有数据,出来玩最重要的是什么?当然是出来.
而…
[大数据 Sqoop,hive,HDFS数据操作]
目录
🥗前言:
🥗实现Sqoop集成Hive,HDFS实现数据导出
🥗依赖:
🥗配置文件:
🥗代码实现:
🥗控制器调用:
🥗Linux指令导入导出:
🥗使用Sqoop将数据导入到Hive表中。例如&#…
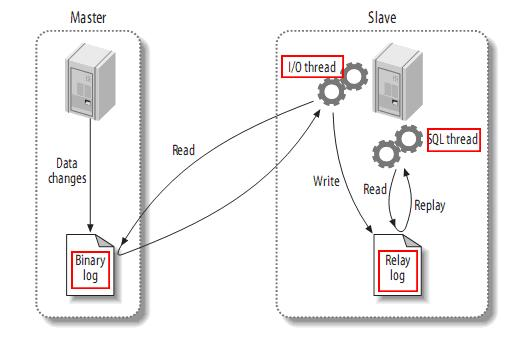
介绍几种主流数据迁移工具技术选型,yyds
前言
最近有些小伙伴问我,ETL数据迁移工具该用哪些。
ETL(是Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业应用来说,我们经常会遇到各种数据的处理、转换、迁移的场景。
今天特地给大家汇总了一些目前…
数据库总结/个人总结
目录数据库数据和信息Data数据数据库数据库管理系统总结常见的数据库管理系统关系型数据库连接查询交叉连接、笛卡尔积内连接左连接右连接嵌套查询Jar在Java项目中使用.jar文件JDBC核心接口单表查询SQL注入简化JDBC视图View创建视图使用视图删除视图事务transaction事务的特性A…

大数据技术之DataX
目录 第一章 业务数据同步策略
1.1 全量同步策略
1.2 增量同步策略
1.3 数据同步策略的选择
第2章 DataX介绍
2.1 DataX概述
第3章 DataX架构原理
3.1 DataX的设计理念
3.2 DataX框架设计
3.3 DataX支持的数据源
3.4 DataX运行流程
3.5 DataX调度策略思路
3.6 Data…

Spark IPmapping方案
使用数据中的uid imei imsi mac androidid uuid 等标识字段,按优先级取一个标识,作为这条数据的用户唯一标识。有严重的漏洞。第一天登陆了,取uid,第二天没登录,取imei 是一个人吗。
在现实的日志数据中,…

数据保管库的数据质量错误
数据保管库的数据质量错误
在过去的几年里,数据仓库发生了巨大的变化,但这并不意味着支撑健全数据架构的基本原理需要被抛在窗外。事实上,随着GDPR等数据法规的日益严格以及对优化技术成本的重新重视,我们现在看到了“Data Vault…
Spark 离线开发框架设计与实现
一、背景
随着 Spark 以及其社区的不断发展,Spark 本身技术也在不断成熟,Spark 在技术架构和性能上的优势越来越明显,目前大多数公司在大数据处理中都倾向使用 Spark。Spark 支持多种语言的开发,如 Scala、Java、Sql、Python 等。…
BI 到底是什么,看看这篇文章怎么说
随着数据价值得到了认可,数据开始成为个人、企业乃至国家的重要战略资产,但数据资产不能直接产生价值,而是需要通过数据分析、数据可视化等数据处理手段将数据转化为信息和知识,才能进行资产的价值化,这时候商业智能BI…

从‘discover.partitions‘=‘true‘分析Hive的TBLPROPERTIES
从’discover.partitions’true’分析Hive的TBLPROPERTIES
前言
Hive3.1.2先建表:
show databases ;use db_lzy;show tables ;create external table if not exists test_external_20230502(id int,comment1 string,comment2 string
)
stored as parquet
;creat…
【SQL开发实战技巧】系列(二十):数据仓库中时间类型操作(进阶)获取季度开始结束时间以及如何统计非连续性时间的数据
系列文章目录
【SQL开发实战技巧】系列(一):关于SQL不得不说的那些事 【SQL开发实战技巧】系列(二):简单单表查询 【SQL开发实战技巧】系列(三):SQL排序的那些事 【SQL开发实战技巧…

Hive中的基础函数(一)
一、hive中的内置函数根据应用归类整体可以分为8大种类型。
1、 String Functions 字符串函数 主要针对字符串数据类型进行操作,比如下面这些:
字符串长度函数:length
•字符串反转函数:reverse
•字符串连接函数:…

Hive中的高阶函数(二)
1、UDTF之explode函数 explode(array)将array列表里的每个元素生成一行; explode(map)将map里的每一对元素作为一行,其中key为一列,value为一列; 一般情况下,explode函数可以直接使用即可,也可以根据需要结…
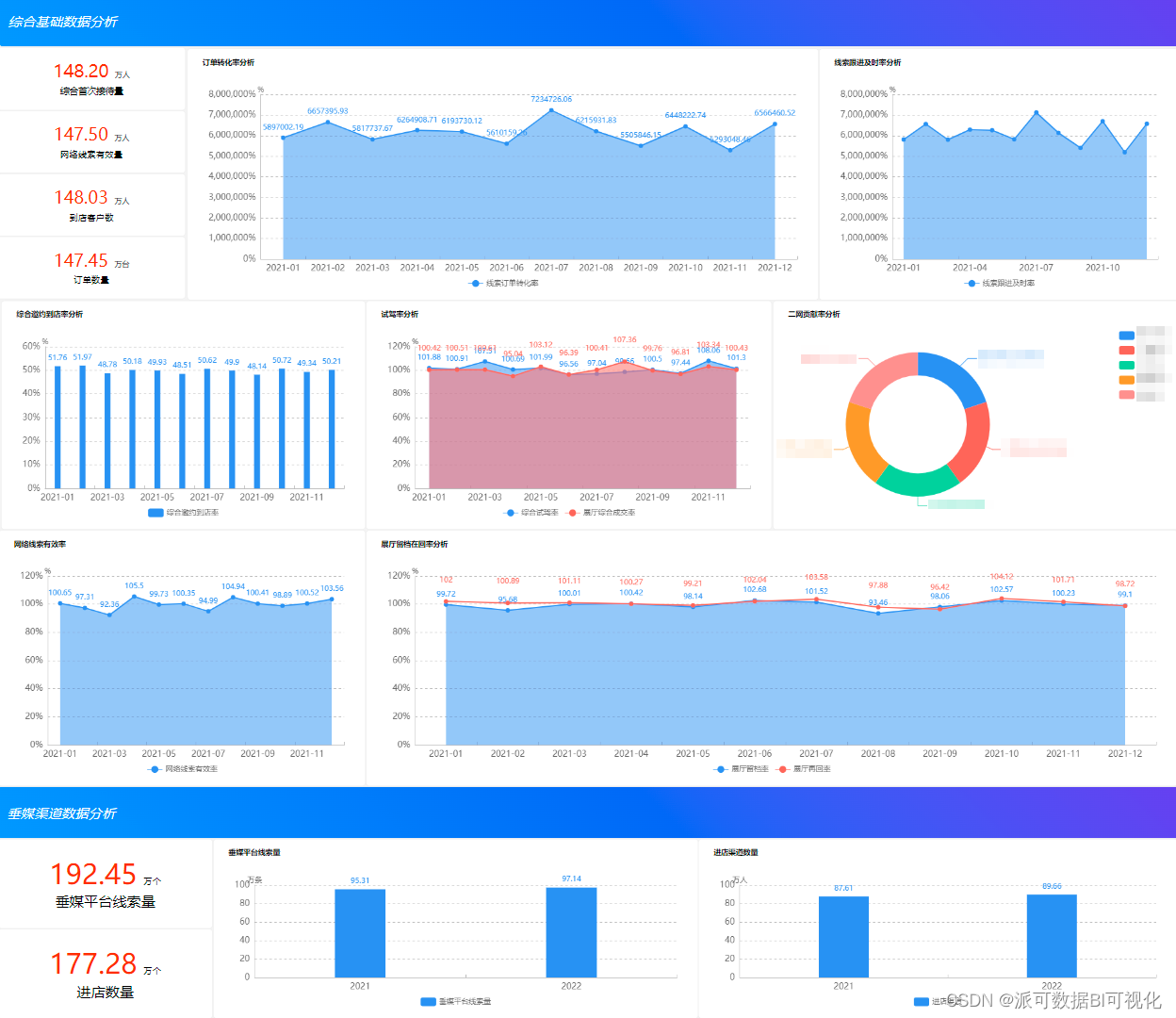
什么是数字化?企业如何实现数字化?
随着社会的发展与时代的进步,以生产为核心的企业也在进行不断的创新,而新一代信息技术的应用深化,制造业迎来了数字化转型新机遇。数字化转型近些年更多的被提及,越来越多的企业想通过数字化的转型,降低企业运营成本&a…
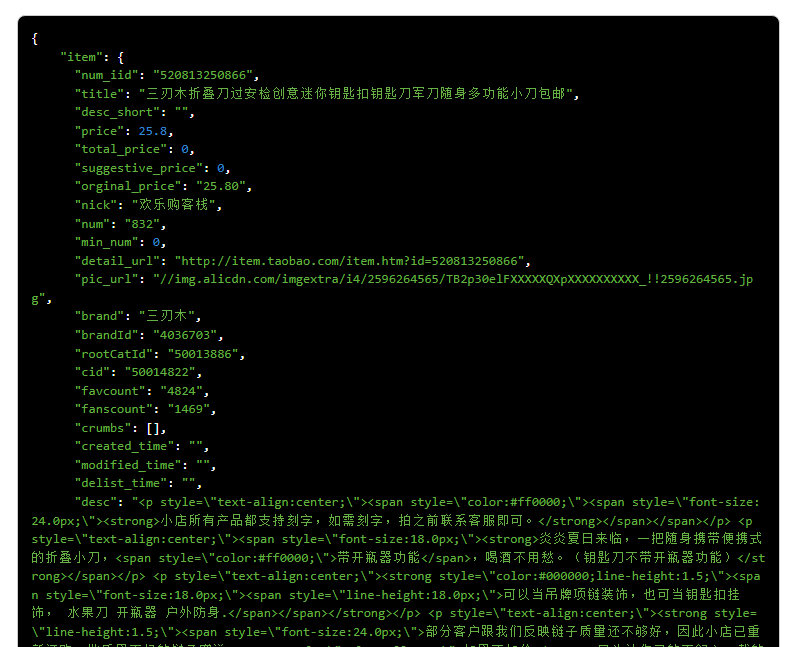
2023最全电商API接口 高并发请求 实时数据 支持定制 电商数据 买家卖家数据
电商日常运营很容易理解,就是店铺商品维护,上下架,评价维护,库存数量,协助美工完成制作详情页。店铺DSR,好评率,提升客服服务等等,这些基础而且每天都必须做循环做的工作。借助电商A…
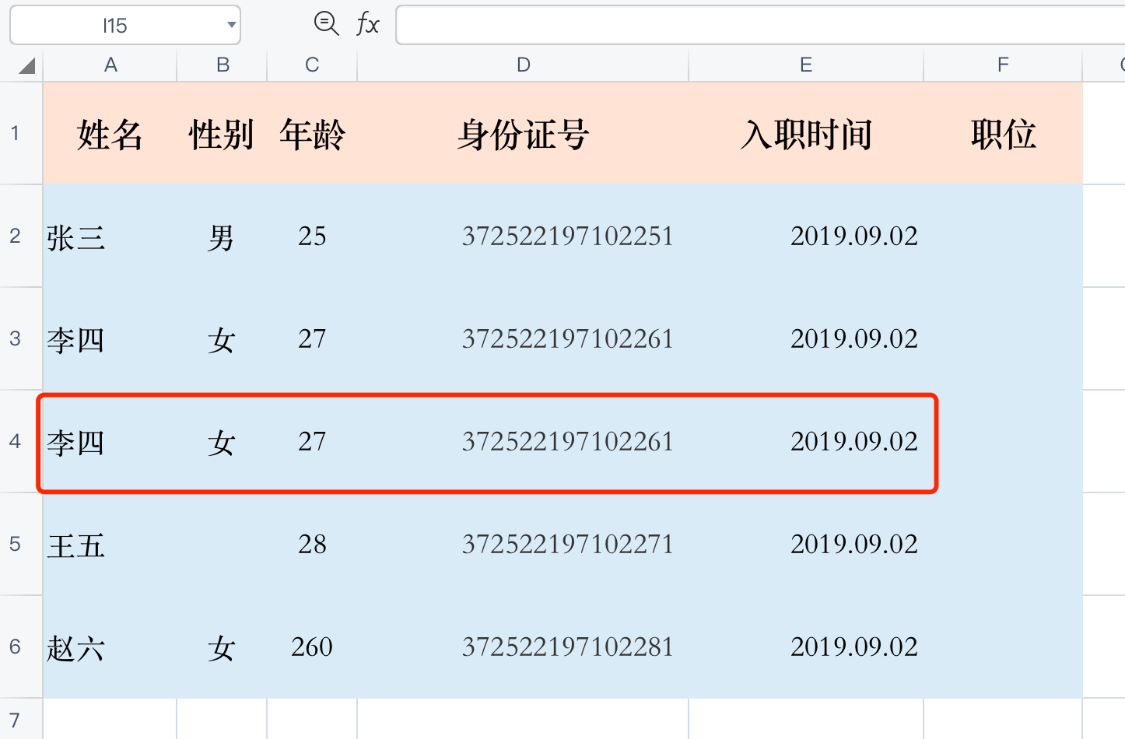
数据清洗是清洗什么?
在搭建数据中台、数据仓库或者做数据分析之前,首要的工作重点就是做数据清洗,否则会影响到后续对数据的分析利用。那么数据清洗到底是做什么事情呢?今天我就来跟大家分享一下。 数据清洗的基本概念
按百度百科给出的解释,“数据清…
ClickHouse(20)ClickHouse集成PostgreSQL表引擎详细解析
文章目录 PostgreSQL创建一张表实施细节用法示例 资料分享参考文章 PostgreSQL
PostgreSQL 引擎允许 ClickHouse 对存储在远程 PostgreSQL 服务器上的数据执行 SELECT 和 INSERT 查询.
创建一张表
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(name…
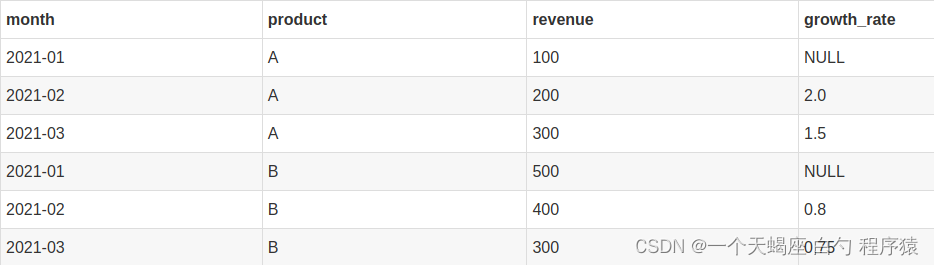
Hive学习(13)lag和lead函数取偏移量
hive里面lag函数
在数据处理和分析中,窗口函数是一种重要的技术,用于在数据集中执行聚合和分析操作。Hive作为一种大数据处理框架,也提供了窗口函数的支持。在Hive中,Lag函数是一种常用的窗口函数,可以用于计算前一行…

iPaaS与ETL:了解它们的主要区别
平均每个组织使用 130 多个应用程序,这一数字同比增长 30%。 随着公司试图充分利用其不断增长的应用程序生态系统,他们已经转向可以集成它们和/或其数据的工具。两个常用选项包括集成平台即服务 (iPaaS) 和提取、传输、加载 &…
2024.1.5 Hadoop各组件工作原理,面试题
目录 1 . 简述下分布式和集群的区别
2. Hadoop的三大组件是什么?
3. 请简述hive元数据服务配置的三种模式?
4. 数据库与数据仓库的区别?
5. 简述下数据仓库经典三层架构?
6. 请简述内部表和外部表的区别?
7. 简述Hive的特点,以及Hive 和RDBMS有什么异同
8. hive中无…
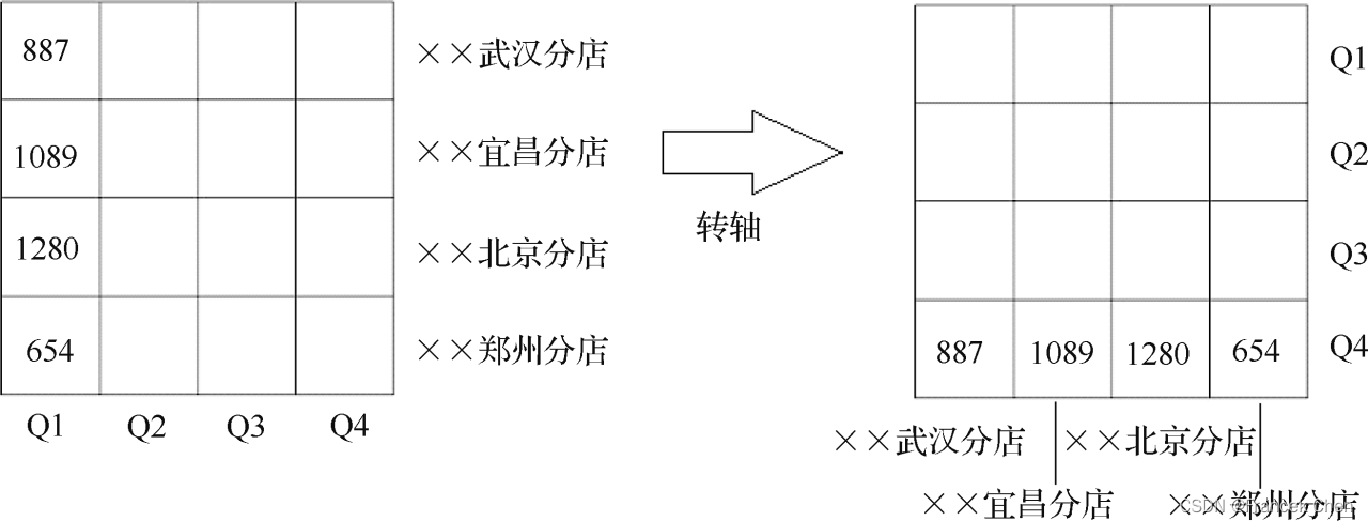
【数据仓库与联机分析处理】多维数据模型
目录
一、数据立方体
二、数据模型
(一)星形模型
(二)雪花模式
(三)事实星座模式
三、多维数据模型中的OLAP操作
(一)下钻
(二)上卷
(三…
数仓工具—Hive进阶之常见的StorageHandler(24)
这里我们介绍一下常见的StorageHandler,但是由于目前StorageHandler的种类还是比较多的,主要包括官方的和非官方的,我们使用的时候需要注意的是版本的兼容性。
常见的StorageHandler
Apache Hive提供了多个存储处理程序(Storage Handler),允许用户集成Hive查询和分析引…

Hive08_分区表
一 分区表
1 概念:
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所
有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据
集。在查询时通过 WHERE 子句中的表达式选择查询…
【大数据进阶第三阶段之DolphinScheduler学习笔记】DolphinScheduler快速上手
1、设置 Dolphinscheduler
在继续之前,您必须先安装并启动 dolphinscheduler。 对于初学者,参考以下博文中的部署起启动服务:【大数据进阶第三阶段之DolphinScheduler学习笔记】深度解析DolphinScheduler(海豚调度)-CSDN博客
2、构建您的第…
Hive基础知识(十):Hive导入数据的五种方式
1. 向表中装载数据(Load) 1)语法 hive> load data [local] inpath 数据的 path[overwrite] into table student [partition (partcol1val1,…)];
(1)load data:表示加载数据
(2)local:表示…
我的大数据之路 - 关于大数据平台上任务管理的思考
本文于2019年7月16日完成,发布在个人博客网站上。 作业,比如提交一个hive脚本到计算平台上运行,这个脚本宏观上称为一个作业。 任务,比如mapper,reducer等。 资源,比如CPU时间,内存,…
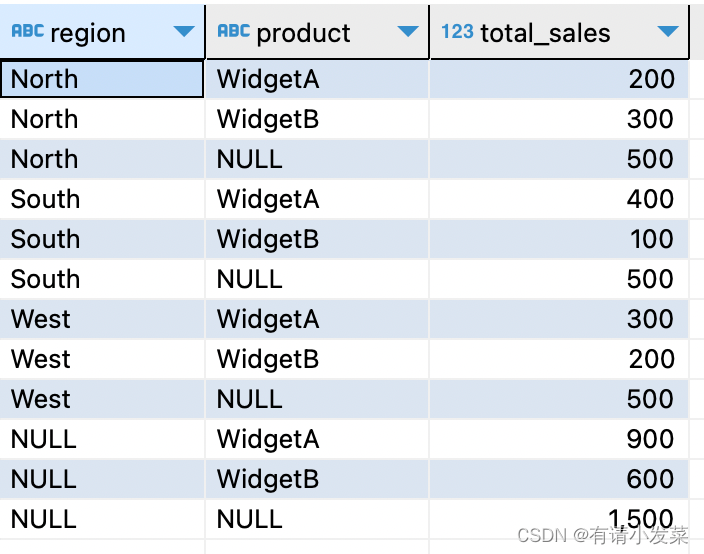
【Databend】分组集:教你如何快速分组汇总
文章目录 分组集定义和数据准备group by grouping setsgroup by rollupgroup by cube总结 分组集定义和数据准备
分组集是多个分组的并集,用于在一个查询中,按照不同的分组列对集合进行聚合运算,等价于对单个分组使用"union all"&…

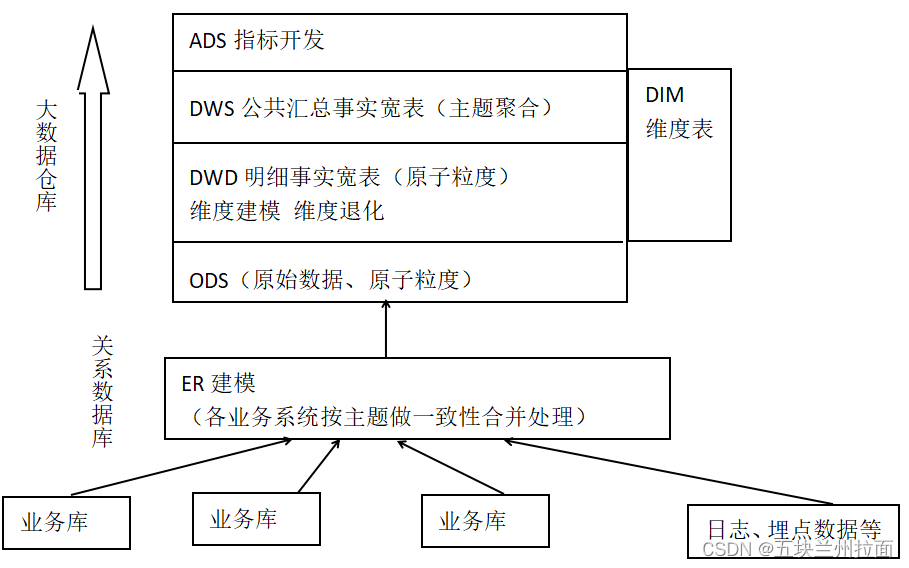
数据仓库(分层和建模方法梳理)
整理不易,转发请注明出处,请勿直接剽窃! 点赞、关注、不迷路! 摘要: 数仓的作用、整体架构、建模方法、分层原理。从整体上梳理数仓、理解数仓架构。 目的
数据仓库的核心是展现层和提供优质的服务。ETL 及其规范、分…
仓库管理系统有哪些作用?选择仓库管理系统要注意这4大问题!
仓库管理系统已经成为很多企业和中小商户必备的工具,选择一款合适的仓库管理系统,可以帮助企业和中小商户提高仓库管理效率、降低管理成本、提高库存周转率。 一、仓库管理系统的作用 1、自动化管理库存
仓库管理系统可以自动识别、跟踪和管理货物的进出…

数据密集型应用存储与检索设计
本文内容翻译自《数据密集型应用系统设计》,豆瓣评分高达 9.7 分。 什么是「数据密集型应用系统」? 当数据(数据量、数据复杂度、数据变化速度)是一个应用的主要挑战,那么可以把这个应用称为数据密集型的。与之相对的是…

字节跳动开源其云原生数据仓库 ByConity
动手点关注 干货不迷路 项目简介 ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的 OLAP 引擎优化…
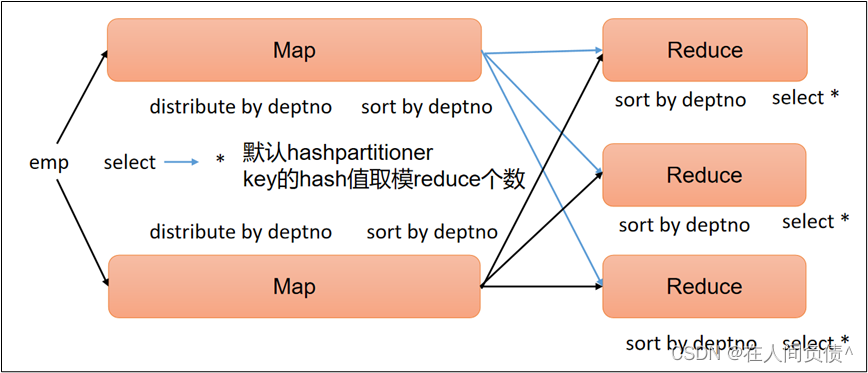
Hive ---- 查询
Hive ---- 查询 1. 基础语法2. 基本查询(Select…From)1. 数据准备2. 全表和特定列查询3. 列别名4. Limit语句5. Where语句6. 关系运算函数7. 逻辑运算函数8. 聚合函数 3. 分组1. Group By语句2. Having语句 4. Join语句1. 等值Join2. 表的别名3. 内连接…
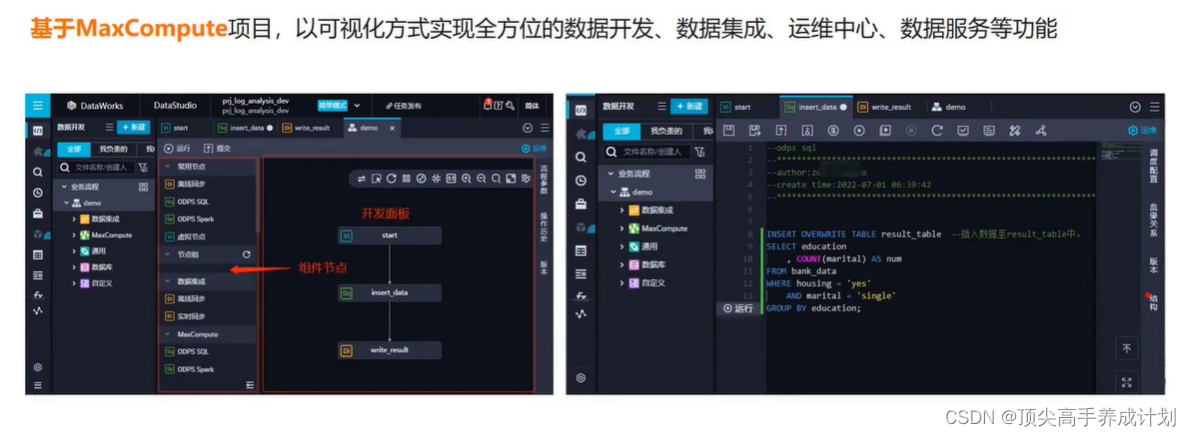
ACP(MaxCompute篇)-MaxCompute开发工具
创建MaxCompute项目 第一种创建项目方式
1.知道MaxCompute服务。 2.创建项目。 3.创建成功。 第二种创建项目的方式
1.进入DataWorks控制台。 2.创建工作空间。 3.创建的类型。 4.创建计算方式。 5.自定义选择。 6.创建成功。 MaxCompute开发工具简介 Odpscmd
安装配置 下…

数据仓库漫谈-前世今生
数据仓库的内容非常多,每一个子模块拎出来都能讲很久。这里没法讲太多细节,大致思考了三个备选议题: 数据仓库的前世今生 数据仓库体系知识介绍 数仓开发者的路在何方? 既然是第一次分享,感觉还是跟大家普及下数仓的…
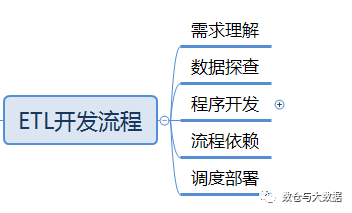
六、数据仓库详细介绍(ETL)经验篇
0x00 前言 日常工作中大多数时候都是在做数据开发,ETL 无处不在。虽然最近两年主要做的大数据开发,但感觉日常干的这些还是 ETL 那点事儿,区别只是技术组件全换了、数据量大了很多。 前几年数仓势微,是因为传统的那些工具数据库等…
美团酒旅数据治理实践
【提醒:公众号推送规则变了,如果您想及时收到推送,麻烦右下角点个在看,或者把本号置顶】正文开始导读:本文主要介绍美团酒旅数据治理的历程和实践经验,以及业务发展各个阶段中数据体系遇到的问题和解决方案…
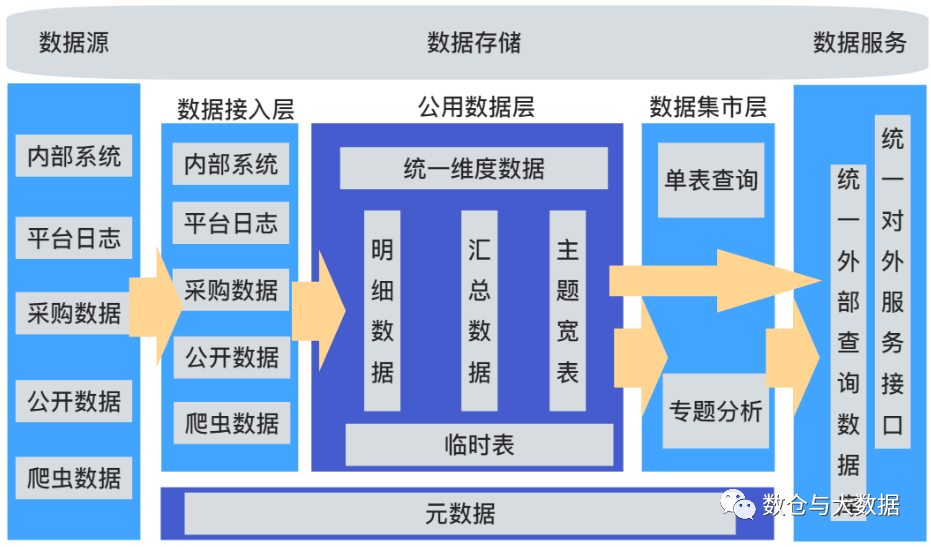
五、数据仓库详细介绍(建模)实践篇
1 数仓建模在数仓建设过程中的位置 这张截图源自之前从 0 到 1 建设数据仓库的经验总结,采用的是瀑布模式的展现方式,但实际操作中经常会使用螺旋迭代模式,因为很难有人能够一步到位的考虑清楚所有细节。 通过业务调研我们熟悉了相关业务过程…

【数据湖仓架构】数据湖和仓库:范式简介
是时候将数据分析迁移到云端了——您选择数据仓库还是数据湖解决方案?了解这两种方法的优缺点。 数据分析平台正在转向云环境,例如亚马逊网络服务、微软 Azure 和谷歌云。云环境提供了多种好处,例如可扩展性、可用性和可靠性。此外࿰…

企业的数据信息值钱吗?如何提升数据信息的价值?
越来越多的企业也将数据视为转型发展、重塑竞争优势和提升组织治理能力的重要战略资产,并对这一重要资产进行系统性、体系化的管理,以便充分挖掘数据的战略、战术价值。鉴于此,对数据资产进行体全面盘点、构建企业级的数据资产目录成为了数据…
数据仓库和数据湖的区别
数据仓库和数据湖是两种不同的数据存储和管理架构,它们有以下区别:
1.数据结构:数据仓库采用结构化的数据模型,通常是规范化的关系型数据库,其中数据以表格形式组织,使用预定义的模式和架构。而数据湖则是…
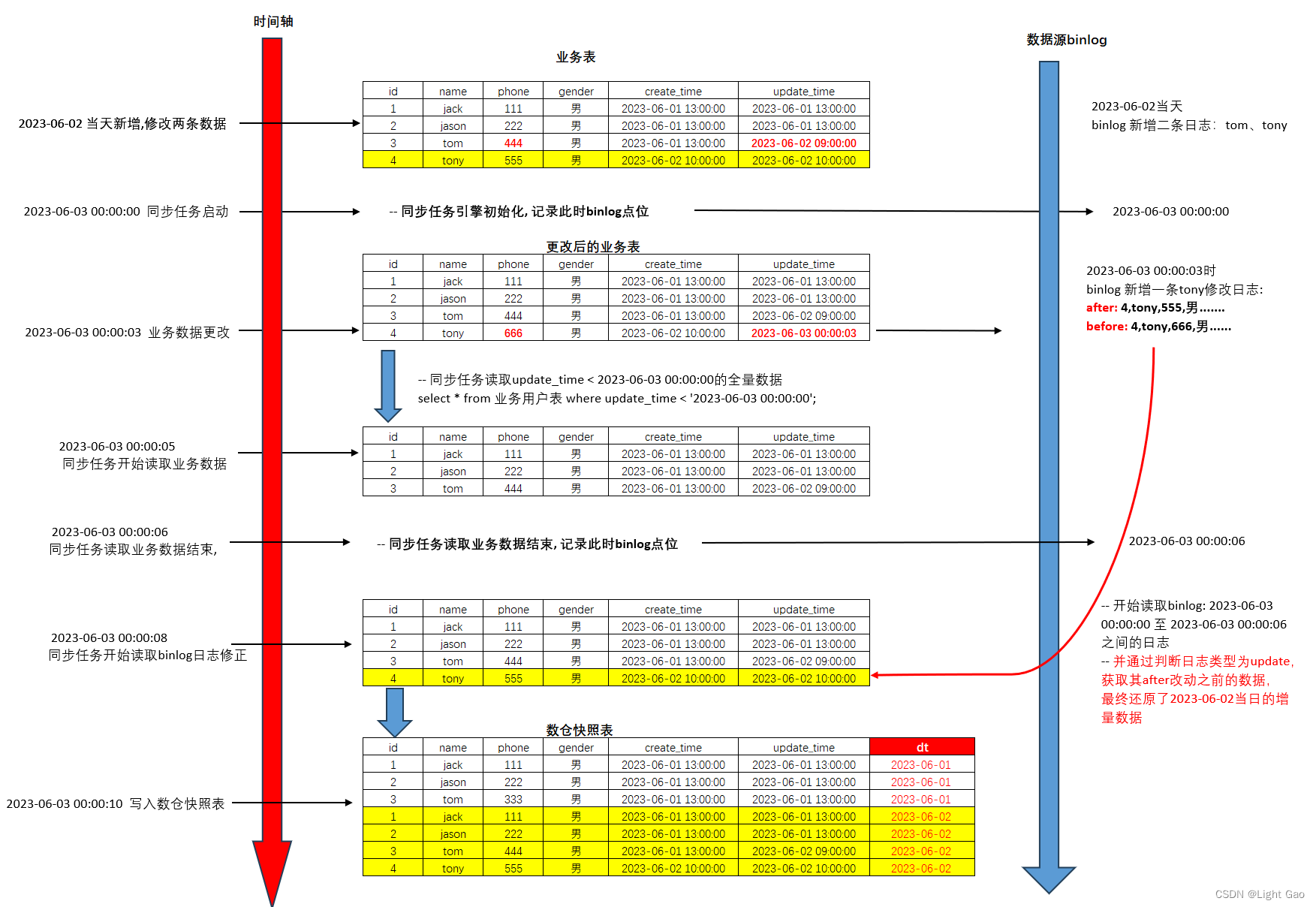
深入数仓离线数据同步:问题分析与优化措施
一、前言
在数据仓库领域,离线数仓和实时数仓是常见的两种架构类型。离线数仓一般通过定时任务在特定时间点(通常是凌晨)将业务数据同步到数据仓库中。这种方式适用于对数据实时性要求不高,更侧重于历史数据分析和报告生成的场景…
数据仓库【指标体系】
指标体系是将零散单点的具有相互联系的指标,系统化的组织起来,通过单点看全局,通过全局解决单点的问题。它主要是由指标和体系两部分组成。 指标是指将业务单元细化后量化的度量值,它使得业务目标可描述、可度量、可拆解ÿ…
Hive 严格模式设置
Hive 在早期使用参数 hive.mapred.mode 来决定是否执行严格模式, 其值为 strict 或者 nostrict. 当其值为 strict 时,执行严格模式,如从分区表查询时,过滤条件必须有分区字段。
在 Hive 3.1.3 中,因为 hive.mapred.mode 比较粗暴…
Hive UDF 札记
低版本的udf就不说了,太老了,说现在主流的。
1:initialize 方法的进一步理解:
在Apache Hive中,用户自定义函数(UDF)的initialize方法是一个可选的方法,它属于Hive UDF的生命周期…
银行数据仓库体系实践(3)--数据架构
狭义的数据仓库数据架构用来特指数据分布,广义的数据仓库数据架构还包括数据模型、数据标准和数据治理。即包含相对静态部分如元数据、业务对象数据模型、主数据、共享数据,也包含相对动态部分如数据流转、ETL、整合、访问应用和数据全生命周期管控治理。…
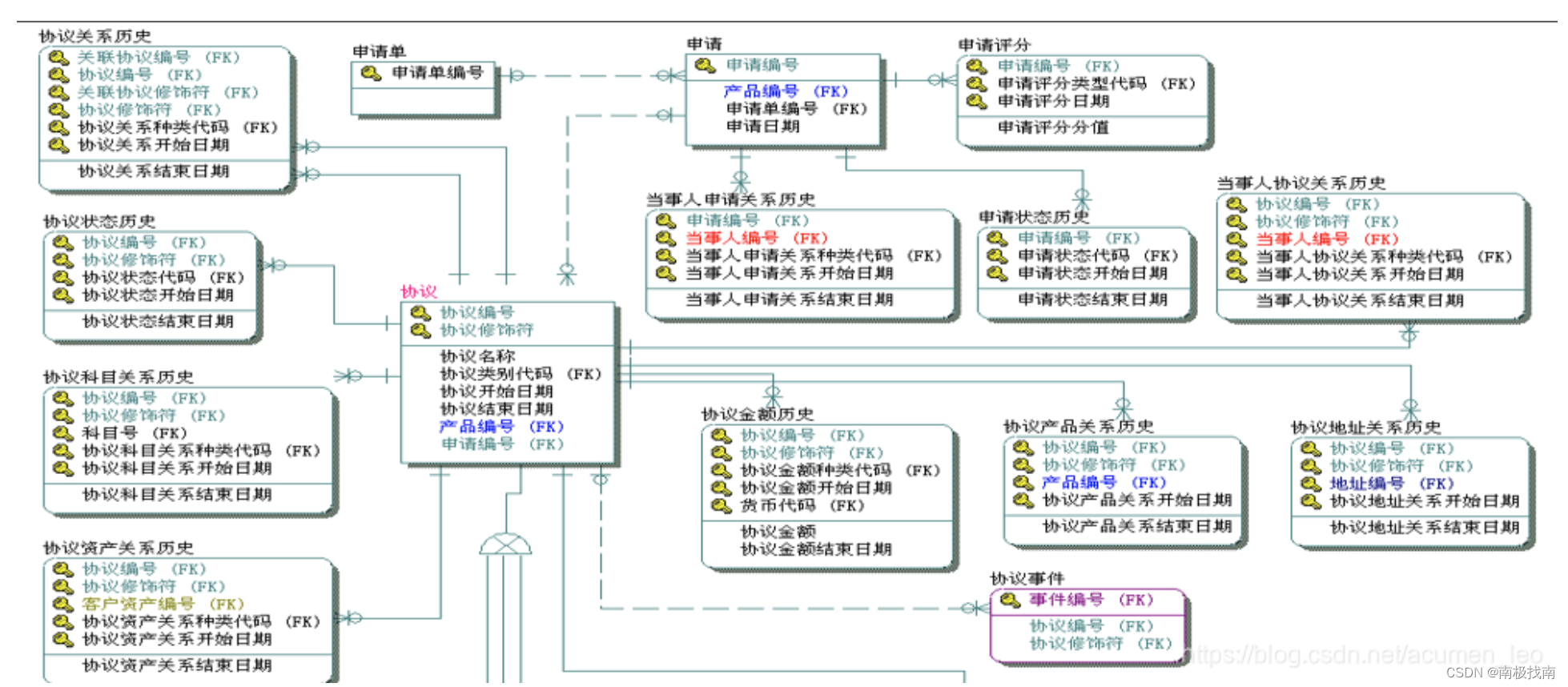
银行数据仓库体系实践(8)--主数据模型设计
主数据区域中保留了数据仓库的所有基础数据及历史数据,是数据仓库中最重要的数据区域之一,那主数据区域中主要分为近源模型区和整合(主题)模型区。上一节讲到了模型的设计流程如下图所示。那近源模型层的设计在第2.3和3这两个步骤…
Hive之set参数大全-15
指定 HiveServer2 使用的认证方式
hive.server2.authentication 是 Hive 中的一个参数,用于指定 HiveServer2 使用的认证方式。该参数决定了 HiveServer2 如何进行用户身份验证。
以下是设置 hive.server2.authentication 参数的一般规则:
SET hive.s…

一文掌握0基础如何体系化学习数仓
1 语数精选简介
语数精选来源于语数社区星球球友提问,主要沉淀一些大家工作和学习过程中存在的一些共性问题,希望能够更好的帮助到球友和粉丝。 欢迎关注公众号:语数 2 本期精选问题
如何校验开发好的数仓指标?如果你是公司的分…
hive - explode 用法以及练习
hive explode 的用法以及练习
一行变多行 explode 例如: 临时表 temp_table ,列名为1st
1st1,2,34,5,6
变为 1 2 3 4 5 6 方式一:直接使用 explode
select explode(split(1st,,)) from temp_table;方式二:使用 lateral view…
ClickHouse(23)ClickHouse集成Mysql表引擎详细解析
MySQL表引擎
MySQL引擎可以对存在远程MySQL服务器上的数据执行SELECT查询。
调用格式:
MySQL(host:port, database, table, user, password[, replace_query, on_duplicate_clause]);调用参数
host:port — MySQL 服务器地址。database — 数据库的名称。table …

大数据项目之电商数仓、用户行为日志、服务器和JDK准备、模拟数据
文章目录3. 用户行为日志3.4 服务器和JDK准备3.4.1 服务器准备3.4.2 编写集群分发脚本xsync3.4.3 SSH无密登录配置3.4.4 JDK准备3.4.5 环境变量配置说明3.5 模拟数据3.5.1 使用说明3.5.1.1 将application.yml、gmall2020-mock-log-2021-10-10.jar、path.json、logback.xml上传到…
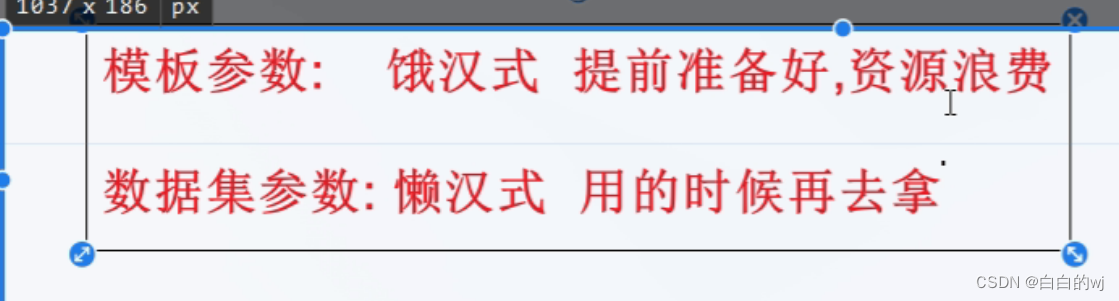
2023.12.15 FineBI与kettle
1.结构化就是可以用schema描述的数据,就是结构化数据,能转为二维表格, 如CSV,Excel,
2.半结构化就是部分可以转换为二维表格,如JSON,XML
3.非结构化数据,就是完全无法用二维表格表示的数据,如Word文档,Mp4,图片,等文件. kettle的流程
新建转换-构建流图-配置组件-保存运行 使…
hive 常见存储格式和应用场景
1.存储格式 textfile、sequencefile、orc、parquet sequencefile很少使用(不介绍了),常见的主要就是orc 和 parquet 建表声明语句是:stored as textfile/orc/parquet行存储:同一条数据的不同字段都在相邻位置ÿ…

大数据项目实战之数据仓库:用户行为采集平台——第4章 用户行为数据采集模块
第4章 用户行为数据采集模块
4.1 数据通道 4.2 环境准备
4.2.1 集群所有进程查看脚本
1)在/home/atguigu/bin目录下创建脚本xcall
[atguiguhadoop102 bin]$ vim xcall2)在脚本中编写如下内容
#! /bin/bashfor i in hadoop102 hadoop103 hadoop104
d…
麒麟Linux操作系统磁盘策略永久调整为deadline
1.前言在安装数据库,比如达梦数据库时,为获取磁盘最佳性能,一般要将数据磁盘设置为deadline。2. 修改磁盘调度算法2.1临时修改假设磁盘为sda,echo deadline > /sys/block/sda/queue/scheduler2.2通用机永久修改grubby --update-kernelALL …

【Hive】——DDL(TABLE)
1 查询指定表的元数据信息
如果指定了EXTENDED关键字,则它将以Thrift序列化形式显示表的所有元数据。 如果指定了FORMATTED关键字,则它将以表格格式显示元数据。
describe formatted student;2 删除表
如果已配置垃圾桶且未指定PURGE&…

该反省了!元数据管理平台为什么会被当成一件“摆设”?
尽管企业越来越意识到元数据管理的重要性,但是在实际中很多应用并没有发挥应有的价值。
前不久与一个行业客户沟通,他提出让他们帮着总结一下元数据管理到底有哪些应用场景,他感觉元数据管理平台就是一种摆设呢? 说者无意听者有心…
2000-2020上市公司全要素生产率LP方法含原始数据和Stata代码
1、时间:2000-2020年
2、指标包括:stkcd、year、证券代码、固定资产净额、营业总收入、营业收入、营业成本、销售费用、管理费用、财务费用、支付给职工以及为职工支付的现金、员工人数、折旧摊销、行业代码、上市日期、AB股交叉码、退市日期、年末是否…
HIVE的数据类型-整型
1、HIVE的数据类型-整型
本次调试用到的hive数据类型:
TINYINT — 微整型,1字节的有符号位整数-128-127。
SMALLINT– 小整型,2个字节的有符号整数,-32768-32767。
INT– 4个字节的带符号整数
BIGINT– 8字节的带符号整数 …
【mysql】MySQL的binlog在数据仓库中的应用
在当今的大数据时代,数据仓库是一个不可或缺的部分。它是一个集中式存储和管理的平台,用于存储、管理和分析大量的数据,以支持决策制定和业务操作。在数据仓库的应用中,MySQL的binlog(二进制日志)扮演着重要的角色。
本文将探讨MySQL的binlog在数据仓库中的应用,包括以…
超分辨数据集:Set5 Set14 BSD100 Urban100 Manga109
DIV2K数据集官网上很好找到,但是网上流传的Set5 14 BSD100,Urban100 Manga109都是私人进行处理过的版本,各个处理方式都不同,为了统一方式写了这篇文章。
官方的DIV2K x2、x3、x4的LR图片使用下面matlab代码生成(已经经过测试最后…
Hive的视图和索引
Hive的视图和索引
1、Hive Lateral View
1、基本介绍
Lateral View用于和UDTF函数(explode、split)结合来使用。 首先通过UDTF函数拆分成多行,再将多行结果组合成一个支持别名的虚拟表。主要解决在select使用UDTF做查询过程中&#…
【Hive】在博客系统中如何应用 Hive 进行离线数据管理
简介: 博客系统作为一个信息发布平台,处理的数据量通常很大。为了更高效地管理和分析这些数据,离线数据处理变得非常重要。Hive 是一个开源的数据仓库基础设施,它能够在博客系统中提供强大的离线数据管理能力。本文将详细介绍如何在博客系统中…
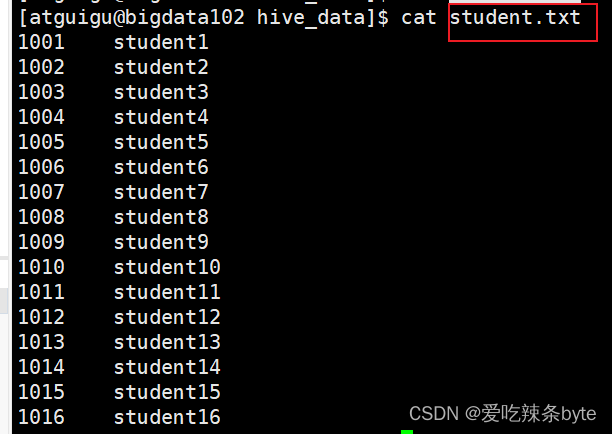
(03)Hive的相关概念——分区表、分桶表
目录
一、Hive分区表
1.1 分区表的概念
1.2 分区表的创建
1.3 分区表数据加载及查询
1.3.1 静态分区
1.3.2 动态分区
1.4 分区表的本质及使用
1.5 分区表的注意事项
1.6 多重分区表
二、Hive分桶表
2.1 分桶表的概念
2.2 分桶表的创建
2.3 分桶表的数据加载
2.4 …

数据库信息速递 数据库基础设施已经不在青睐 ETL (译)
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共…

【专为苛刻的数据环境而构建】上海道宁为您带来世界上先进的矢量原生、时间序列和实时分析数据库——kdb系列产品
kdb是高效的矢量原生
时间序列和实时分析数据库
专为高性能矢量
数据驱动的应用程序而构建
以加速云端、数据仓库和
数据湖中的 AI 和 ML 工具
从而更快、更高效地
制定业务决策 使用数据时间库加速数据
分析和生成 AI 管道
以降低成本
提高性能并提高效率 开发商介绍…
亿级大表毫秒关联,荔枝微课基于Apache Doris 统一实时数仓建设实践
本文导读: Apache Doris 助力荔枝微课构建了规范的、计算统一的实时数仓平台,目前 Apache Doris 已经支撑了荔枝微课内部 90% 以上的业务场景,整体可达到毫秒级的查询响应,数据时效性完成 T1 到分钟级的提升,开发效率更…
数据仓库是什么?什么是列式存储?
事务和分析
在早期的业务数据处理过程中,一次典型的数据库写入通常与一笔 商业交易(commercial transaction) 相对应:卖个货、向供应商下订单、支付员工工资等等。但随着数据库开始应用到那些不涉及到钱的领域,术语 交…
【Hadoop】三、数据仓库基础与Apache Hive入门
文章目录 三、数据仓库基础与Apache Hive入门1、数据仓库基本概念1.1、数据仓库概念1.2、场景案例:数据仓库为何而来1.3、数据仓库主要特征1.4、数据仓库主流开发语言--SQL 2、Apache Hive入门2.1、Apache Hive概述2.2、场景设计:如何模拟实现Hive功能2.…


从数据中台实践,浅谈数据质量管理
时代背景 近20年来,我国的科学技术发展日新月异,各种新兴技术层出不穷,深刻的改变着各行各业,也改变着我们的生活。大数据、云计算、人工智能的出现更是将技术革命推向了高潮。在这种背景下,继农业经济、工业经济之后&…
企业转型在搭建BI时,需要注意什么
如今,商业智能BI在全世界范围内掀起了一股热潮,形成了一个庞大的市场,在信息化时代,企业需要借助BI来进行更好的成长。
在这种全新的社会、商业BI环境下,各行各业的企业都开始寻求探索新的商业模式,通过转…
公司官网在线帮助文档怎么写?
公司官网在线帮助文档,是公司为用户提供的一种在线帮助服务,旨在帮助用户更好地理解和使用公司的产品和服务。这篇文章将介绍在线帮助文档的写作方法和技巧,帮助企业提高帮助文档的质量和效果。
一、明确文档目的和受众
在开始撰写帮助文档…
【Hive实战】Hive治理方向探讨(请留意见)
Hive治理方向探讨 文章目录 Hive治理方向探讨Hive治理项治理临时性质的表控制分区表的分区数量和分区层级限制建表时使用的存储格式表或分区记录的location对应的HDFS路径实际不存在表级路径应是分区路径的前缀内部表使用非内部表路径外部表使用内部表路径表的属性个数异常按时…

数字孪生世界建设核心能力:地理信息数据应用能力
地理信息数据是数字孪生的核心基础之一,它能够把真实世界的空间结构和关系映射到数字世界,包含了静态的地理元素和动态的时空变量,如道路、建筑、水系、交通流量、人口密度、环境质量等,它能够反映真实世界的时空特点和动态变化&a…
商业智能BI软件所涉及的核心技术
现在越来越多的企业开始使用商业智能BI软件,用来整合企业中现有的各种数据,对这些数据按照不同的需求进行处理分析,并快速准确地形成分析报告,为企业决策提供数据支持,帮助企业做出明智的业务经营决策。
目前市面上的…
Datax3.0+DataX-Web部署分布式可视化ETL系统
一、DataX 简介 DataX 是阿里云 DataWorks 数据集成的开源版本,主要就是用于实现数据间的离线同步。DataX 致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源(即不同的数据库&#x…

数据仓库【4】:最佳实践
数据仓库【4】:最佳实践 1、表的分类1.1、事实表1.2、维度表1.3、事务事实表1.4、周期快照事实表1.5、累积快照事实表1.6、拉链表 2、ETL策略2.1、全量同步2.2、增量同步 3、任务调度3.1、为什么需要任务调度?3.2、常见任务类型3.3、常见调度工具 1、表的…
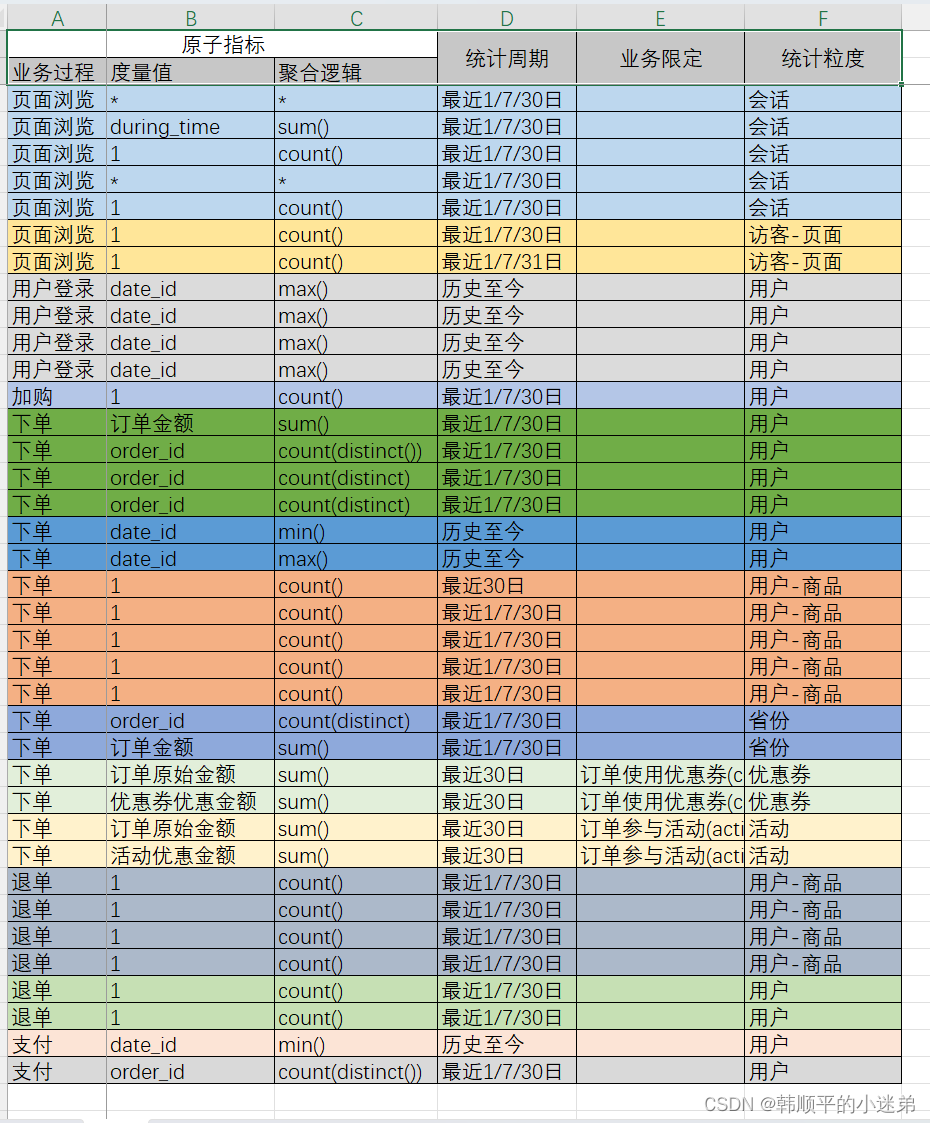
数仓建模维度建模理论知识
0. 思维导图 第 1 章 数据仓库概述
1.1 数据仓库概述 数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的…
Hive调优——count distinct去重优化
离线数仓开发过程中经常会对数据去重后聚合统计,而对于大数据量来说,count(distinct ) 操作消耗资源且查询性能很慢,以下是调优的方式。
解决方案一:group by 替代
原sql 如下:
#7日、14日的app点击的用户数&#x…
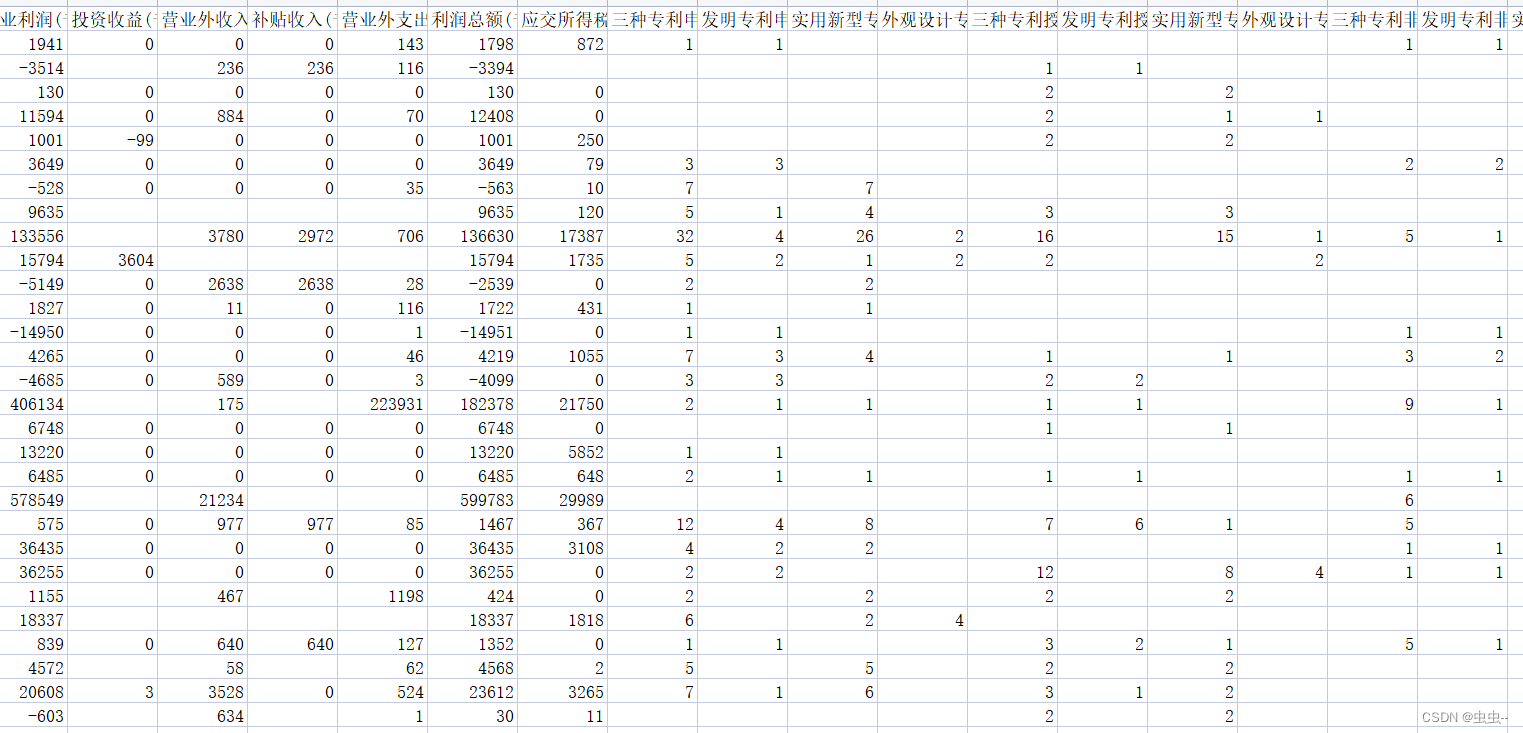
2000-2013年工企专利匹配数据库
2000-2013年工业企业专利匹配数据库
1、时间:2000-2013年
2、指标:
工业企业标识码、创新企业标识码、省地县码、省(自治区、直辖市)、地(区、市、州、盟)、乡(镇)、街道办事处、…

(13)Hive调优——动态分区导致的小文件问题
前言 动态分区指的是:分区的字段值是基于查询结果自动推断出来的,核心语法就是insertselect。 具体内容指路文章:
https://blog.csdn.net/SHWAITME/article/details/136111924?spm1001.2014.3001.5501文章浏览阅读483次,点赞15次…

CDSP考取的价值:成为数据安全认证专家的好处
哈喽IT的朋友们👋,今天想和大家聊聊一个超级有用的专业认证:CDSP,也就是数据安全认证专家。如果你在数据安全领域或者对这方面感兴趣,这个认证绝对值得你去考取哦! 1.🎓提升专业性:获…
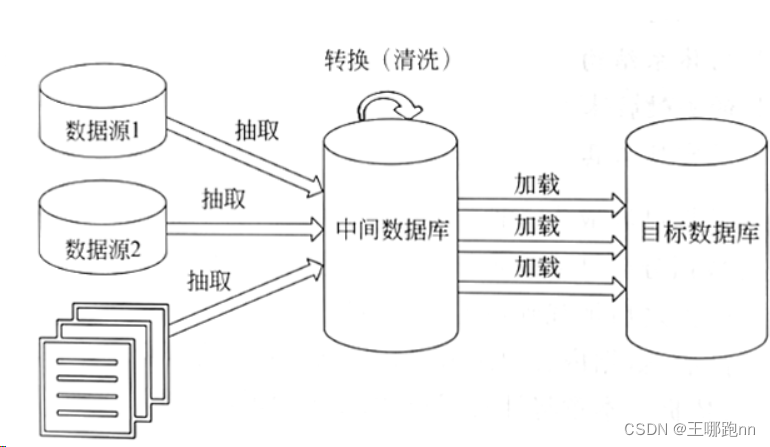
大数据就业方向-(工作)ETL开发
上一篇文章:
大数据 - 大数据入门第一篇 | 关于大数据你了解多少?-CSDN博客 目录
🐶1.ETL概念
🐶2. ETL的用处
🐶3.ETL实现方式
🐶4. ETL体系结构
🐶5. 什么是ETL技术?
&…
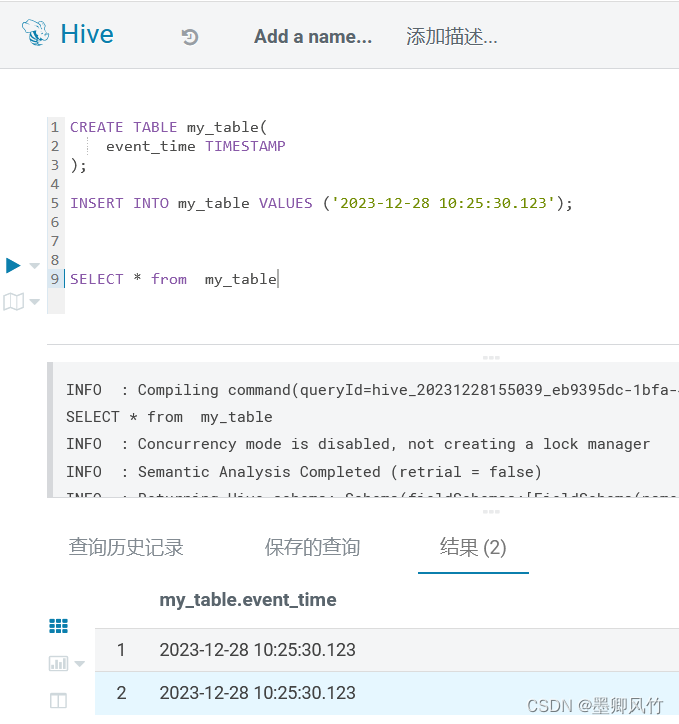
Hive中支持毫秒级别的时间精度
实际上,Hive 在较新的版本中已经支持毫秒级别的时间精度。你可以通过设置 hive.exec.default.serialization.format 和 mapred.output.value.format 属性为 1,启用 Hive 的时间精度为毫秒级。可以使用以下命令进行设置:
set hive.exec.defau…

Windows下hive中insert语句报错
报错信息
我的hadoop和hive版本都是3.0版本(建议hadoop3.x版本、hive2.x版本,我在使用中发现有些问题)
[08S01][2] Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask解决过程 1.查看…
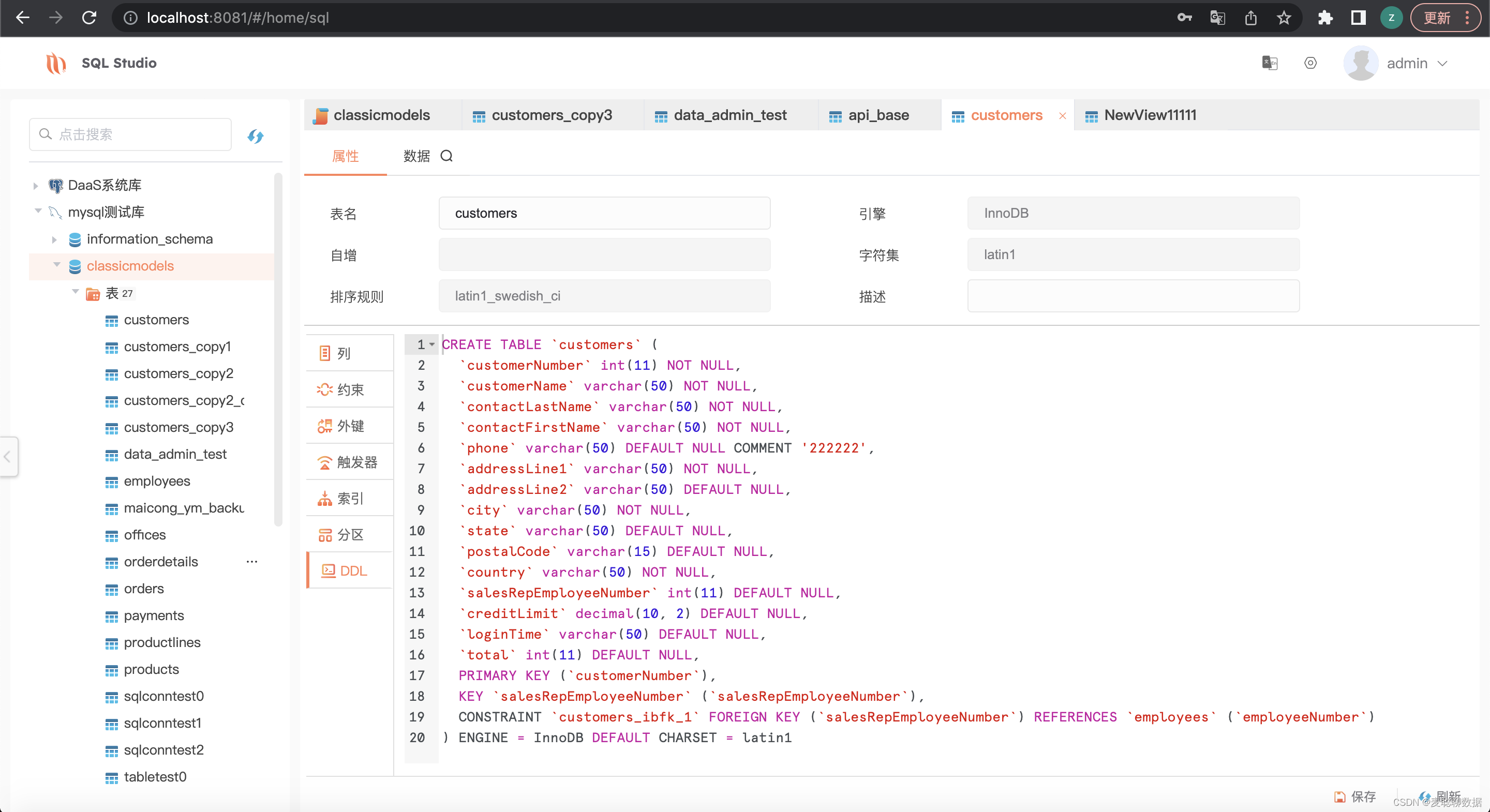
解密Teradata与中国市场“分手”背后的原因!国产数据库能填补空白吗?
2月15日,西方的情人节刚刚过去一天,国内IT行业就爆出一个大瓜。
继Adobe、甲骨文、Tableau、Salesforce之后,又一个IT巨头要撤离中国市场。
Teradata天睿公司官宣与中国市场“分手”,结束在中国的直接运营。目前,多家…

什么是BI ?BI 能给企业带来什么价值?
目前,社会数字化程度还在不断加深,数据量也伴随着一同高速增长,许多人预测未来将是数据处理时代,而作为数据类解决方案的商业智能BI也会持续扩张市场,朝着不同行业BI商业智能的方向发展。
利用BI工具系统,…
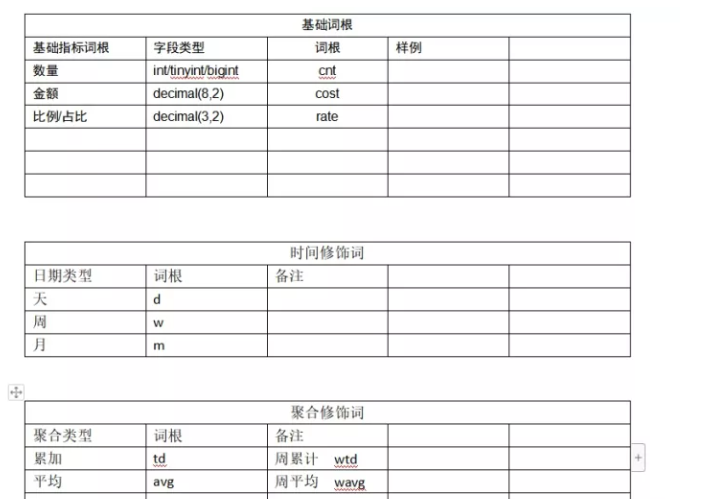
盘点数据仓库建设需要知道的那些事
文章目录 建设规范为何要有规范规范如何落地有哪些规范 数仓分层分层原则常见分层主题域划分原则数据模型设计原则数据类型规范**数据冗余规范**表规范处理规范命名规范生命周期管理 指标管理指标定义指标构成指标分类命名规范 建设规范
为何要有规范 无规矩不成方圆ÿ…

一个简化、落地的实时数据仓库解决方案
从传统的经验来讲,数据仓库有一个很重要的功能是记录数据变化历史。通常,数据仓库都希望从业务上线的第一天开始有数据,然后一直记录到现在。但实时处理技术,又是强调当前处理状态的一门技术,所以当这两个相互对立的方…
系统运维系列 之CSV文件读取时内容中包含逗号的处理方法
问题描述: CSV文件默认逗号分隔,但是如果在内容中包含逗号,则会导致分隔失败或者数组下标匹配越界的问题。
处理方法: (1)正则表达式
//(?pattern)
//非获取匹配,正向肯定预查,在…
五大向量数据库入门横评
本文内容节选自 Paxi.ai 文章分享,Paxi.ai是一个基于GPT-4打造的帮助用户快速使用AI的AI工具,对内容感兴趣的朋友可以上他们官网查看。
从OpenAI发布GPT以来,AI尤其以LLM为代表的项目发展迅速,相信大家已经了解到大语言模型的魅力…
AMEYA360报道:无线MCU中的MCU与无线技术
MCU是我们熟悉的一种集成电路芯片,有着广阔的应用。它是采用超大规模集成电路技术把具有数据处理能力的中央处理器CPU、随机存储器RAM、计数器、USB、A/D转换、UART等等功能集成到一块硅片上构成的一个小而完善的微型计算机系统,在不同的应用场合可以提供…
hive-视图与物化视图
一、视图
1、一句话解释
一张虚表,不存数据,对外暴露真实表的一部分数据,增强数据保密性,查询的时候,底层会转换成对真实表的查询,走MapReduce。
2、参考资料
hive的视图_hive 视图_kcy000的博客-CSDN博…
数据分析师的进阶路径
【与数据同行】已开通综合、数据仓库、数据分析、产品经理、数据治理及机器学习六大专业群,加微信号frank61822701 为好友后入群。新开招聘交流群,请关注【与数据同行】公众号,后台回复“招聘”后获得入群方法。正文开始最近好多人私信问我如…
【无标题】2022年机械式停车设备司机考试试卷及机械式停车设备司机模拟考试
v题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:机械式停车设备司机考试试卷根据新机械式停车设备司机考试大纲要求,安全生产模拟考试一点通将机械式停车设备司机模拟考试试题进行汇编,组成一套机械式停车…

活动邀请| VMware Data Solution专场演讲
近期活动 VMware Explore 中国线上大会即将开幕。 11月18日,众多行业意见领袖和解决方案专家,参与 VMware 管理、技术团队、生态合作伙伴及用户一起为您带来的大会主旨演讲、4场解决方案主题演讲及近150场解决方案分论坛演讲。话题专注多云领域&…
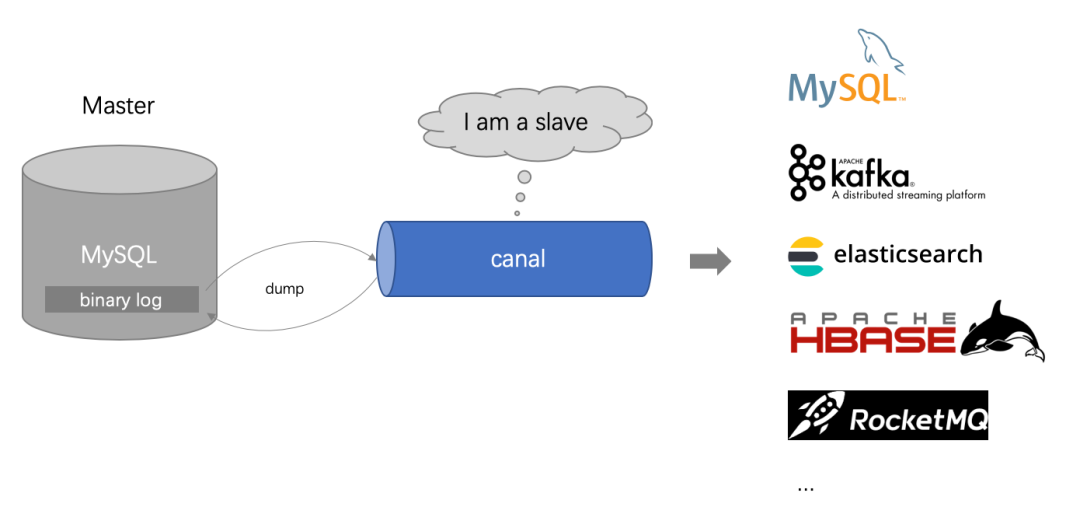
六、数据仓库详细介绍(ETL)工具篇上
0x00 前言
在上篇,我们介绍过,ETL 的实现方式可以分为三种类型:完全依赖数据库、自研、第三方 ETL 工具。 我们需要根据实际情况去选择合适的方案。对于相对简单的 ETL 系统我们可以完全依赖数据库或者内部开发一个小型的的流程控制、调度工…
2021年过氧化工艺考试资料及过氧化工艺考试技巧
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:过氧化工艺考试资料是安全生产模拟考试一点通生成的,过氧化工艺证模拟考试题库是根据过氧化工艺最新版教材汇编出过氧化工艺仿真模拟考试。2021年过氧化工艺考试资料及…
2021年西式面点师(技师)及西式面点师(技师)模拟试题
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:西式面点师(技师)是安全生产模拟考试一点通生成的,西式面点师(技师)证模拟考试题库是根据西式面点师(技师&a…
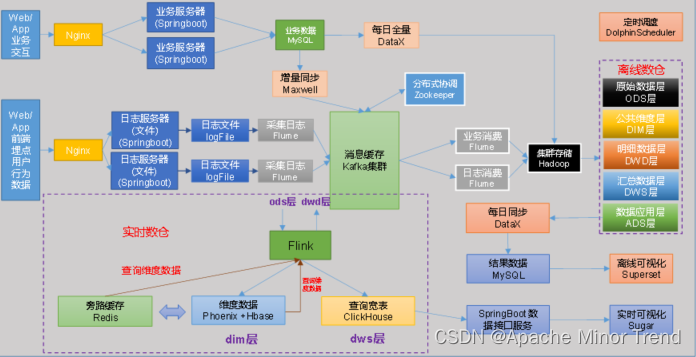
【离线数仓-1-数仓前期建设准备工作】
离线数仓-1-数仓前期建设准备工作离线数仓-1-数仓前期建设准备工作1.数仓概念1. 数据仓库概念2. 数据分类3.数据仓库总视图4.数据仓库项目需求分析5.数仓搭建技术基础分析1.项目技术如何选型:2.框架版本如何选型;3.服务器使用物理机还是云主机࿱…
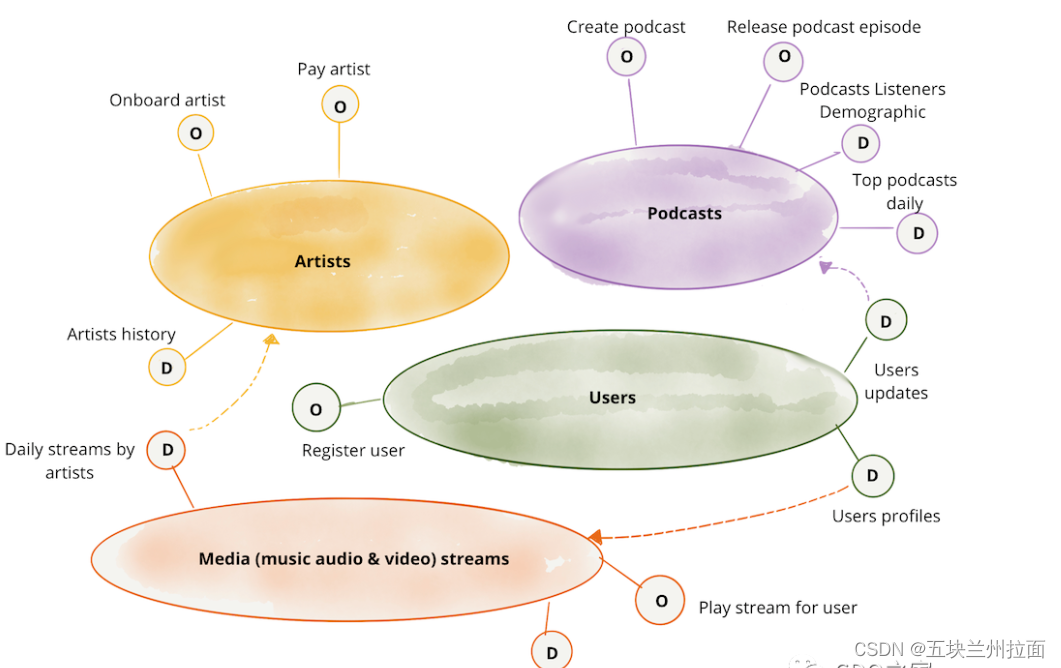
数仓、数据湖、湖仓一体、数据网格
第一代:数据仓库 定义
为解决数据库面对数据分析的不足,孕育出新一类产品数据仓库。数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策和信息的全局共享。
数…

【离线数仓-5-数据仓库环境准备】
离线数仓-5-数据仓库环境准备离线数仓-5-数据仓库环境准备1.数据仓库运行环境1.Hive环境搭建1.Hive引擎2.Hive on Spark配置2.Yarn环境配置2.数据仓库开发环境3.模拟数据准备离线数仓-5-数据仓库环境准备
1.数据仓库运行环境
数仓之外需要做的事情: 数据安全认证&…
Hive行列转换应用:多行转多列、 多行转单列、多列转多行、单列转多行
Hive行列转换应用 文章目录Hive行列转换应用多行转多列多行转单列多列转多行单列转多行多行转多列
通过条件转换CASE WHEN函数实现多行转多列,即取出对应的数据放在对应的位置。例1:
写法一:
SELECTid,CASEWHEN id < 2 THEN aWHEN id …
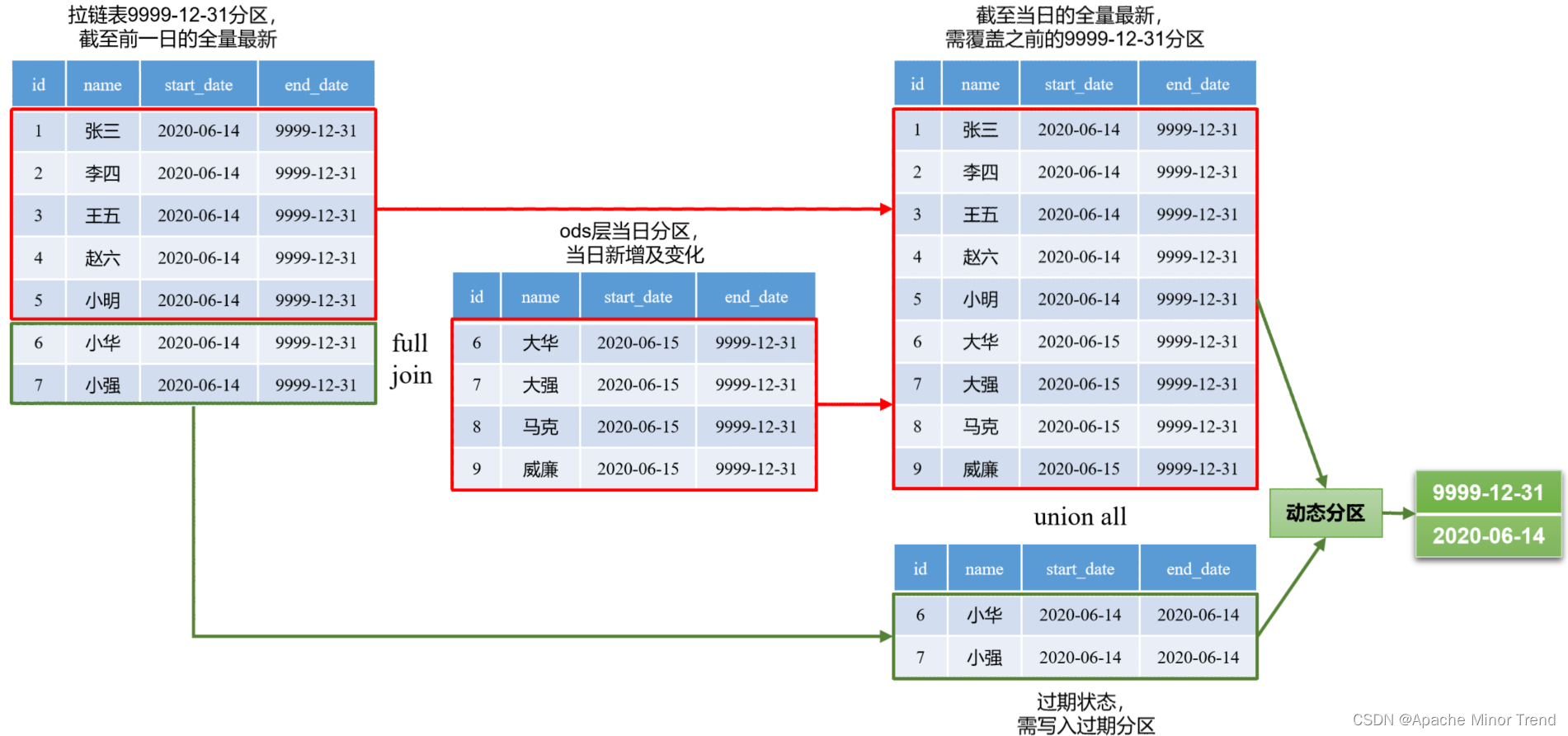
【离线数仓-7-数据仓库开发DIM层设计要点-拉链表同步装载脚本】
离线数仓-7-数据仓库开发DIM层设计要点-拉链表同步&装载脚本离线数仓-7-数据仓库开发DIM层设计要点-拉链表同步&装载脚本一、DIM层 维度模型 设计要点6.用户维度表 -拉链表1.用户维度表 前期梳理2.分析与之关联的每个表格中的具体字段,抽离出来“用户维度表…
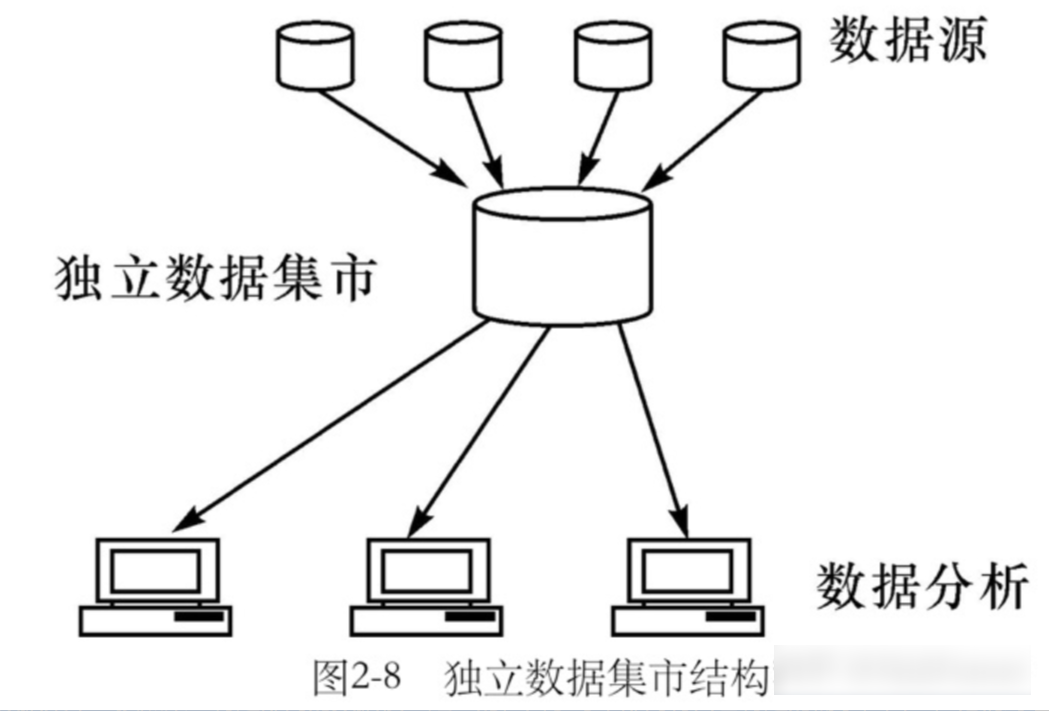
数据集市与数据仓库的区别
数据仓库是企业级的,能为整个企业各个部门的运作提供决策支持;而数据集市则是部门级的,一般只能为某个局部范围内的管理人员服务,因此也称之为部门级数据仓库。
1、两种数据集市结构
数据集市按数据的来源分为以下两种
&#x…
欧文数据建模师 erwin Data Modeler Crack
欧文数据建模师 erwin Data Modeler 是一款屡获殊荣的数据建模工具, 用于查找、可视化、设计、部署和标准化高质量的企业数据资产。从任何地方发现和记录任何数据,以在大规模数据集成、主数据管理、元数据管理、大数据、商业智能和分析计划中实现一致性、…
数据仓库与数据库的区别
数据库与数据仓库的区别实际讲的是 OLTP 与 OLAP 的区别。
操作型处理,叫联机事务处理 OLTP(On-Line Transaction Processing,),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作&…
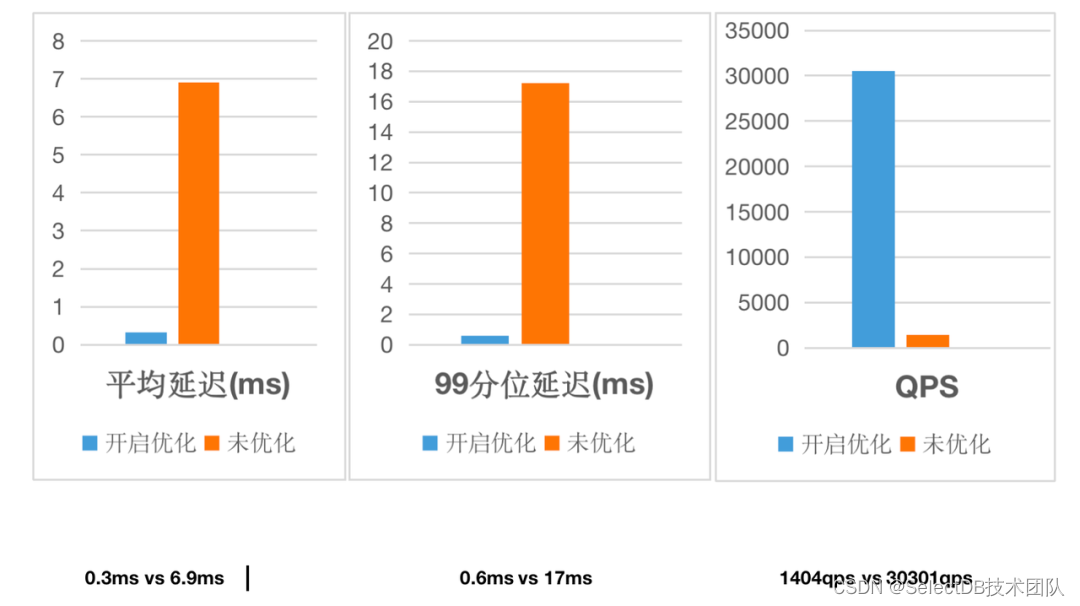
并发提升 20+ 倍、单节点数万 QPS,Apache Doris 高并发特性解读
随着用户规模的极速扩张,越来越多用户将 Apache Doris 用于构建企业内部的统一分析平台,这一方面需要 Apache Doris 去承担更大业务规模的处理和分析——既包含了更大规模的数据量、也包含了更高的并发承载,而另一方面,也意味着需…

Hive 流量分析(含维度和不含维度计算)
流量分析: 指标:PV,UV,访问次数,平均访问时长,人均访问次数、人均访问深度,人均访问时长,回头客占比等... 维度:时间维度,地域维度,设备维度等... pageview:页面浏览事件…
一张图讲清数据中台来龙去脉
阶段2:传统单体架构阶段的数据应用(DB->DW),引入MDM
传统单体应用有一个问题,就是具有主数据属性的数据分散在各个单体应用中。以物料为例,物料在多个系统(SRM、ERP、CRM)中都会…
建设数据资产一体化管控体系,某大型医药集团实现数据长效赋能业务发展
某大型医药集团成立于 1994 年,是一家植根中国、创新驱动的全球化医药健康产业集团,业务覆盖制药、医疗器械、医学诊断、医疗健康服务、医药商业等医药健康全产业链。
01
传统数据应用体系无法满足集团业务发展需求
数字化转型大背景下,该…

Hive知识点的回顾
一、Hive的序列化和反序列化 Hive读取文件机制:读取文件中的每一行 > 反序列化 > 通过分隔符进行切割,返回数据表中的每一行对象。 Hive写文件机制:把数据表中的每一行Row对象 > 调用LazySimpleSerde类中的序列化方法 > 把Row对象…
2021年压力焊复审考试及压力焊模拟考试
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:2021年压力焊复审考试为正在备考压力焊操作证的学员准备的理论考试专题,每个月更新的压力焊模拟考试祝您顺利通过压力焊考试。
1、【单选题】 储能焊时,预先把能量以某…
2023系统分析师---文老师冲刺资料
需求规格说明书: 内容:范围,引用文件、需求、合规性规定、需求可追踪性、尚未解决的问题、注解、附录通俗答法:系统应该提供的功能和服务;非功能需求,包括系统的特征、特点和属性;限制系统开发或者系统运行必须遵守的约束条件;系统必须连接的其他系统的信息。作用:系统…
移动通信客户类主题数据挖掘
移动通信客户类主题数据挖掘
1.业务分类大客户:移动大客户定义根据总部的统一定义,客户积分是评判大客户的依据,每年年末对大客户重新计算,确定下年的大客户积分评判阈值。大客户资格在年内只升不降。年内每月对达到大…

从0到1,数据治理一周年大纪实
在长达近18年的数据生涯中,自己一直从事数据仓库相关工作,去年一次偶然的机会开始做企业数据治理,现在相关工作逐步进入正轨。值此一周年之际,记录下自己做数据治理的22个关键事件,也许对大家也有启示吧。2021年8月19日…

《Kettle构建Hadoop ETL系统实践》简介
#好书推荐##好书奇遇季#《Kettle构建Hadoop ETL系统实践》,京东当当天猫都有发售。定价79元,网店打折销售其实没多少钱。
Kettle是一款国外开源的ETL工具,纯Java编写,无须安装,功能完备,数据抽取高效稳定。…
美团外卖实时数仓建设实践
【与数据同行】已开通综合、数据仓库、数据分析、产品经理、数据治理及机器学习六大专业群,加微信号frank61822701 为好友后入群。新开招聘交流群,请关注【与数据同行】公众号,后台回复“招聘”后获得入群方法。正文开始导读:本文…

2020大厂面试题-数仓篇
1、手写sql问题:连续活跃。。。
-- 第一种解决方案,使用lag(向前)或者lead(向后)
select*
from
(select user_id,date_id,lead(date_id) over(partition by user_id order by date_id) as last_date_idfrom (select user_id,date_idfrom wedw_dw.log_b…

Hive多行转多列,多列转多行
hive中的行列转换包含单行、多行、单列、多列,所以一共有四种组和转换结果。
一、多行转多列
原始数据表 目标结果表 分析:目标表中的a和b是用分组形成,所以groupby字段选用原始表中col1,c、d、e是原始表中的行值,…
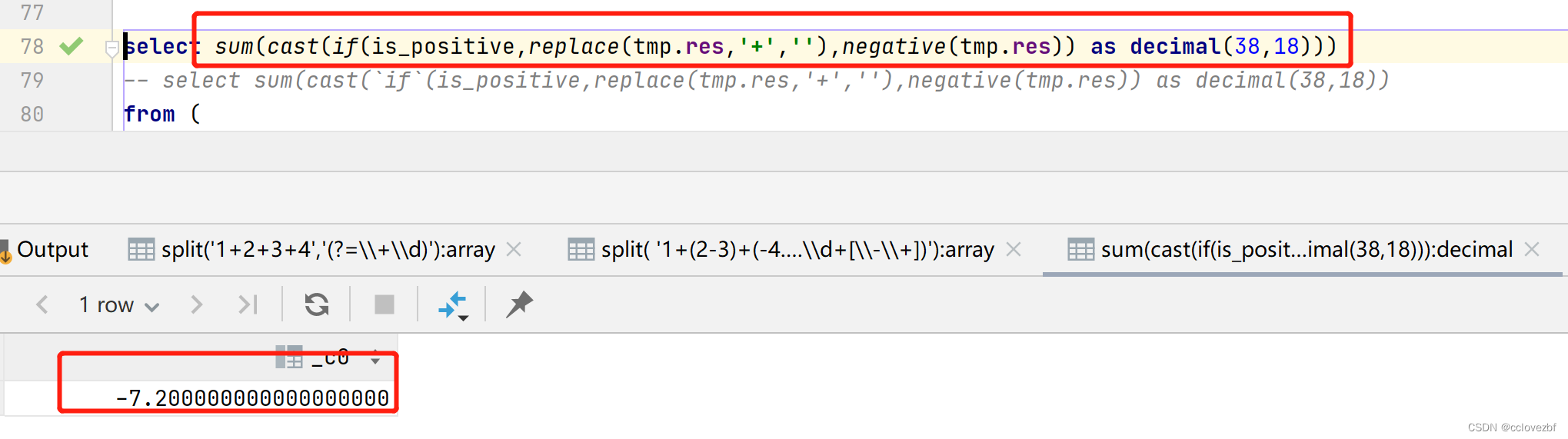
hive中如何计算字符串中表达式
比如 select 1(2-3)(-4.1-3.1)-(4-3)-(-3.34.3)-1 col ,1(2-3)(-4.1-3.1)-(4-3)-(-3.34.3)-1 result \
现在的需求式 给你一个字符串如上述col 你要算出result。
前提式 只有和-的运算,而且只有嵌套一次 -(4-3)没有 -(-4(3-(31)))嵌套多次。
第一步我们需要将运…

如何用数据资产管理,解锁数据新价值
数字经济和数字化转型的发展有什么共通点吗?这个问题的答案也很明显,数据就是数字经济数字化转型的基础,也是推动两者快速发展的核心要素。数字化时代,数据已经成为了个人、机构、企业乃至国家的重要战略资产,所以如何…
redis 中的配置文件 redis.conf 讲解
目录
一、第一部分
二、第二部分include 三、第三部分
ip设置
防火墙设置
端口号设置
tcp-backlog 511
timeout 超时时间
检查心跳时间
四、第四部分
是否同意后台启动 进程号pid 日志级别
日志输出路径
databases 五、第五部分security 今天我们,…
【从0开始离线数仓项目】——数据仓库的环境搭建(1)
目录
一、服务器环境准备
1.2 编写集群分发脚本xsync
1.3 SSH无密登录配置
1.4 JDK准备
1.5 环境变量配置说明
二、集群所有进程查看脚本
三、Zookeeper安装
3.1 分布式安装部署
3.2 ZK集群启动停止脚本
3.3 客户端命令行操作 一、服务器环境准备
CentOS 7 怎么从命…

从数据仓库到数据结构:数据架构的演变之路
在上个世纪,从电子商务巨头到医疗服务机构和政府部门,数据已成为每家组织的生命线。有效地收集和管理这些数据可以为组织提供宝贵的洞察力,以帮助决策,然而这是一项艰巨的任务。 尽管数据很重要,但CIOinsight声称&…
智胜未来——即刻开始为您的S/4HANA迁移做准备
SAP即将结束对ECC的维护 SAP即将结束对ECC的维护,早在 2019 年,SAP 就宣布将在 2025 年之前结束对其 ECC 的维护,随后又延长至 2027 年。尽管距离 2027 年似乎还有很长的路要走,但对于许多企业来说,这个截止日期的到来…
Apache Doris 入门教程26:资源管理
为了节省Doris集群内的计算、存储资源,Doris需要引入一些其他外部资源来完成相关的工作,如Spark/GPU用于查询,HDFS/S3用于外部存储,Spark/MapReduce用于ETL, 通过ODBC连接外部存储等,因此我们引入资源管理机制来管理Do…
StarRocks入门部署
目录
一、StarRocks整体介绍
1.1、系统架构图:
1.2、FE相关
1.3、BE相关
1.4、数据管理特性
二、简单部署
2.1、部署前准备
2.2、手动部署 2.2.1、部署Leader FE节点
2.2.2、部署BE节点
2.2.3、关联FE、BE,搭建StarRocks集群
2.2.4、给root设…
Small Tip: 如何Debug Start Routine
我也不知道咋地,在generated ABAP里面打断点进不去。 我也不晓得怎么弄,今天反正是硬找着去弄。不晓得有没有其他好办法。有知道的小伙伴评论下吧。
1、 在DTP里面选Before Transformation,要去debug start routine选这个就够了。其他的随意…
Hive加密,PostgreSQL解密还原
当前公司数据平台使用的处理架构,由Hive进行大数据处理,然后将应用数据同步到PostgreSQL中做各类外围应用。由于部分数据涉及敏感信息,必须在Hive进行加密,然后在PG使用时再进行单个数据解密,并监控应用的数据调用事情…
Microsoft SQL Server 2008中,语法生成错误“并行数据仓库(PDW)功能未启用“(已解决)
案例:
原表有两列,分别为月份、月份销售额,而需要一条 SQL 语句实现统计出每个月份以及当前月以前月份销售额和 sql 测试数据准备: DECLARE Temp Table
( monthNo INT, --- 月份 MoneyData Float --- 金额
) insert INTO TEM…
大数据ETL工具Kettle
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言最近公司在搞大数据数字化,有MES,CIM,WorkFlow等等N多的系统,不同的数据源DB,需要将这些不同的数据源DB里的数据进行整治统一…
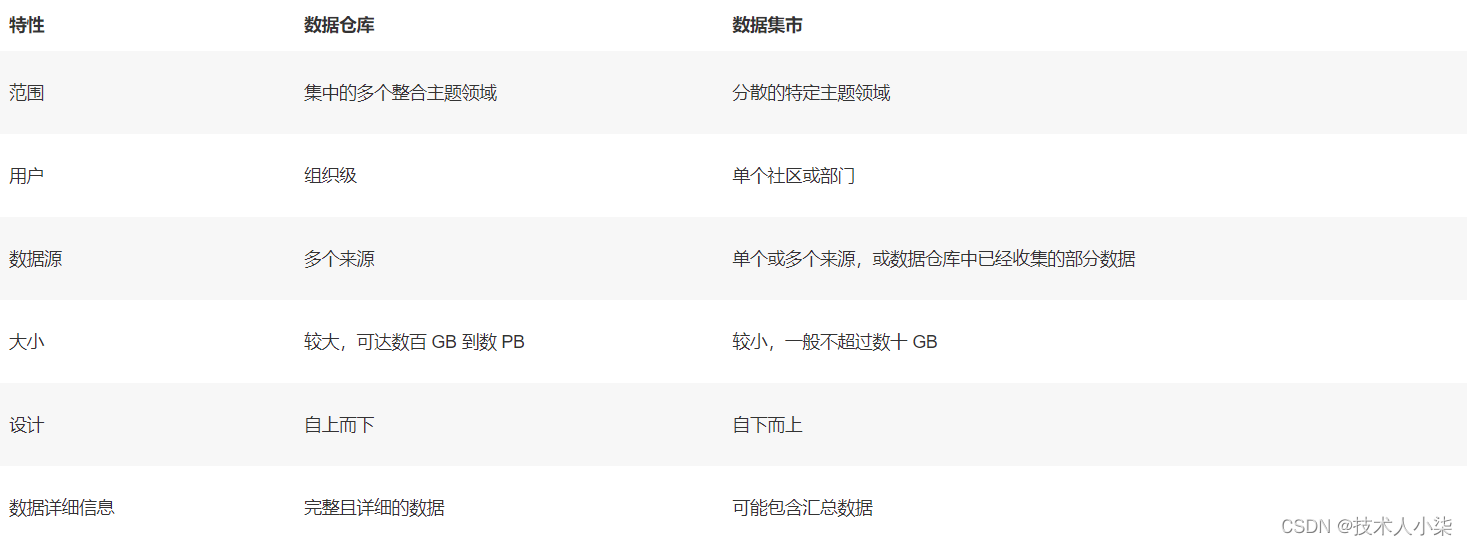
数据仓库的概念及与数据库等对比
1、什么是数据仓库?
数据仓库是信息(对其进行分析可做出更明智的决策)的中央存储库。通常,数据定期从事务系统、关系数据库和其他来源流入数据仓库。业务分析师、数据工程师、数据科学家和决策者通过商业智能 (BI) 工具、SQL 客户…

Kettle7.0同步数据(简单操作步骤hive-hive)
一、Kettle说明介绍和原理说明 Kettle是一款免费的ETL工具。 ETL分别是“Extract”、“ Transform” 、“Load”三个单词的首字母缩写,也就是代表ETL过程的三个最主要步骤:“抽取”、“转换”、“装载”,但我们平时往往简称其为数据抽取。 ET…
大数据项目实战之数据仓库:电商数据仓库系统——第7章 数仓开发之ODS层
文章目录第7章 数仓开发之ODS层7.1日志表7.2 业务表7.2.1 活动信息表(全量表)7.2.2 活动规则表(全量表)7.2.3 一级品类表(全量表)7.2.4 二级品类表(全量表)7.2.5 三级品类表…

系统分析师之信息化技术(十一)
目录
一、企业信息化概述
1.1 信息系统的基本概念
1.1.1 什么是信息
1.1.2 什么是信息化
1.1.3 信息系统分类
二、企业信息化规划
2.1 信息化战略体系
2.2 企业战略与信息化战略集成方法
三、信息系统开发方法
3.1 信息系统开发方法
3.2 系统建模
四、信息系统战略…
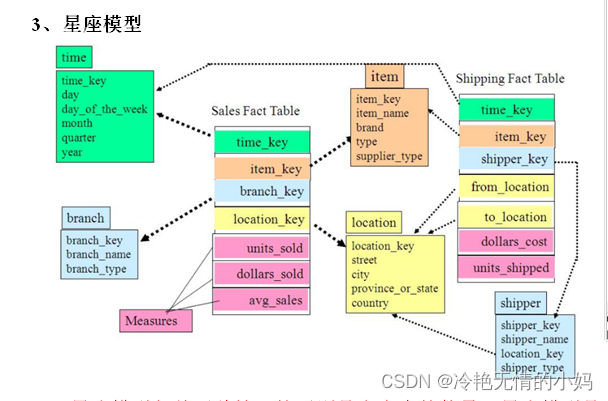
[Hive基本概念之--hive分区]
目录
前言:
添加MyBatis和Hive依赖
配置MyBatis和Hive连接信息
在Spring Boot应用中定义MyBatis Mapper,例如: 定义实体类
MyBatis Mapper接口 Batis Mapper接口,insert方法对应Mapper中的insert方法,selectByPartition方法对…
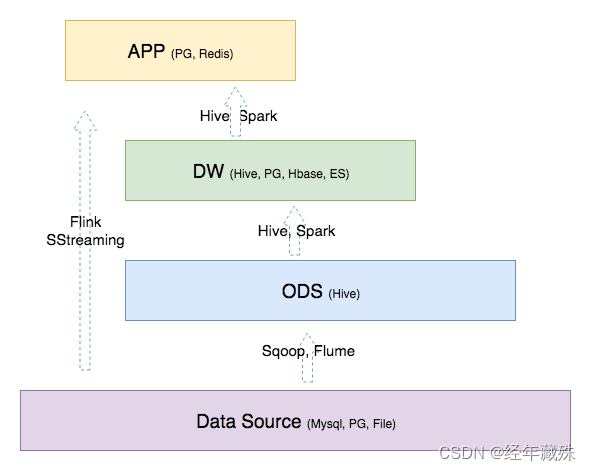

数据挖掘工程师岗位的工作职责
数据挖掘工程师岗位的工作职责1 职责: 1.负责数据分析,数据挖掘相关的算法、应用的设计与开发; 2.负责公司产品各阶段数据的整理、分析、挖掘及提交数据报告,重点对车辆行为数据进行分析和挖掘,利用数据分析结论推动业务产品的优化; 3.对海量…
dataworks取当前时间前一小时时间
set odps.sql.type.system.odps2true;
select DATE_FORMAT(DATEADD(CURRENT_TIMESTAMP(),-1,hh),yyyy-mm-dd hh:mi:ss)
select from_unixtime(unix_timestamp(cast(CURRENT_TIMESTAMP() as datetime))-60*60);
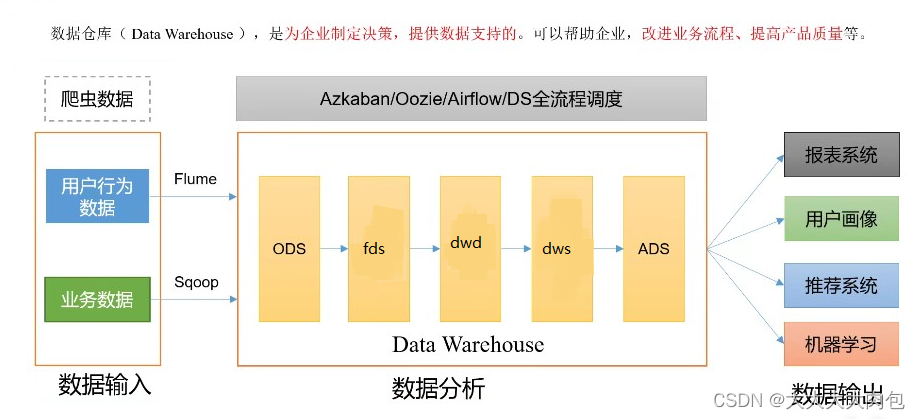
如何成为一名数仓工程师?
如何成为一名数仓工程师?
成为一名数据仓库工程师需要具备以下几个关键技能和知识:
数据库技术:数据仓库是一个数据库系统,因此需要具备扎实的数据库基础知识和数据库编程技能,包括SQL语言、数据库设计和优化等方面的…
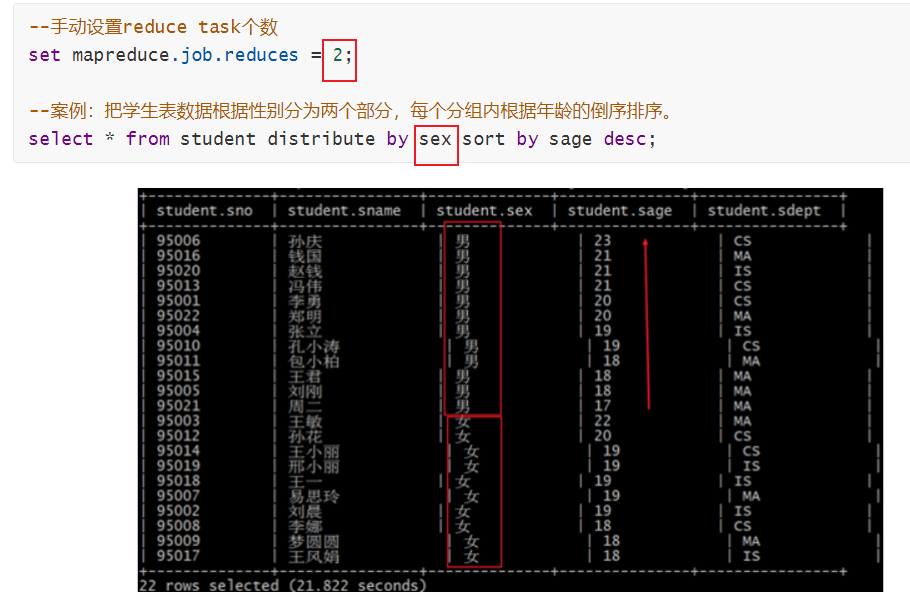
Hive语言2(大数据的核心:窗口函数)
1、Common Table Expressions(CTE)> 重点 公用表达式(CTE)是一个临时结果集,该结果集是从WITH子句中指定的简单查询派生而来的,该查询紧接在SELECT或INSERT关键字之前。 2.inner join(内连接)、left joi…

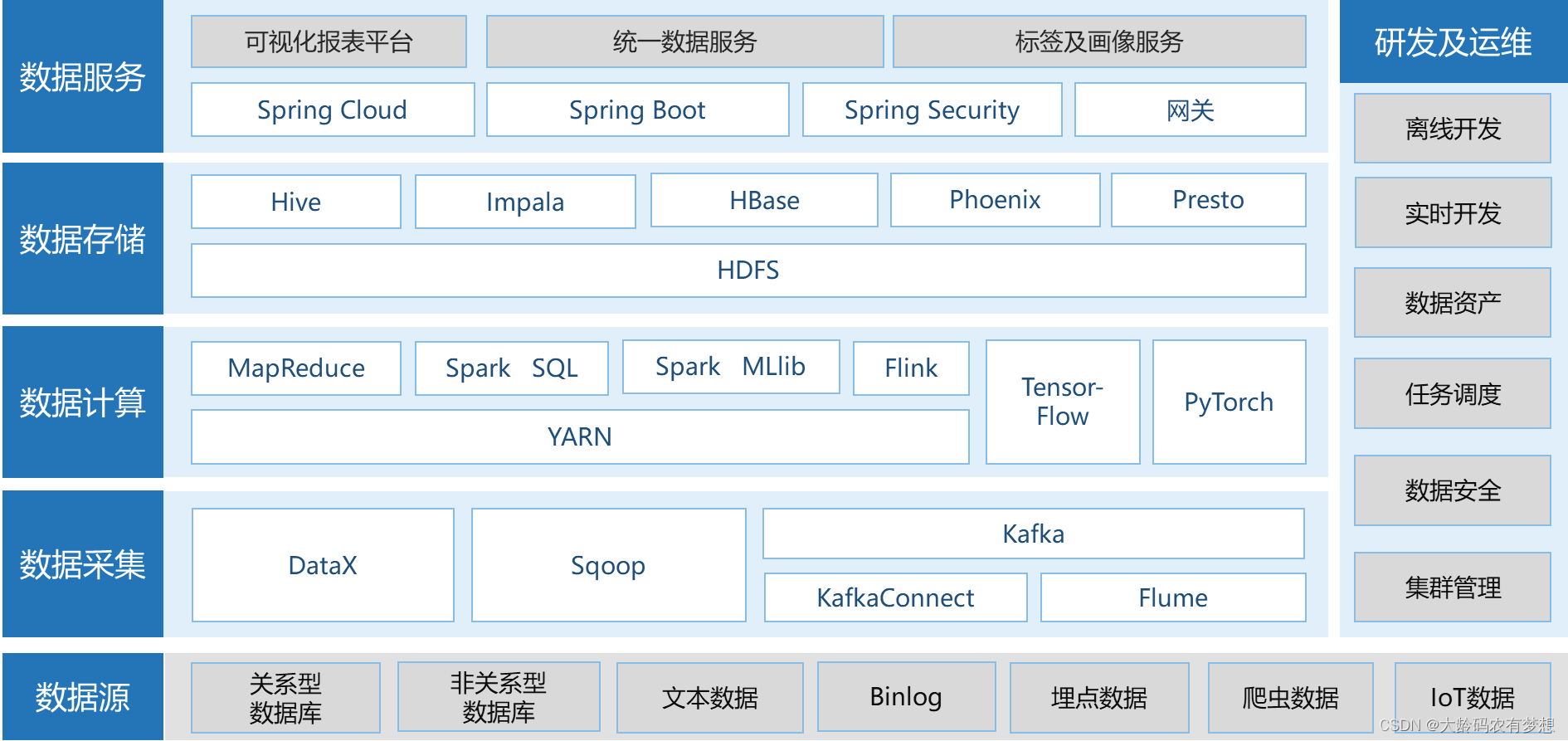
企业级数据中台应用架构和技术架构
一、什么是数据中台
数据中台是一种将企业沉睡的数据变成数据资产,持续使用数据、产生智能、为业务服务,从而实现数据价值变现的系统和机制。通过数据中台提供的方法和运行机制,形成汇聚整合、提纯加工、建模处理、算法学习,并以…
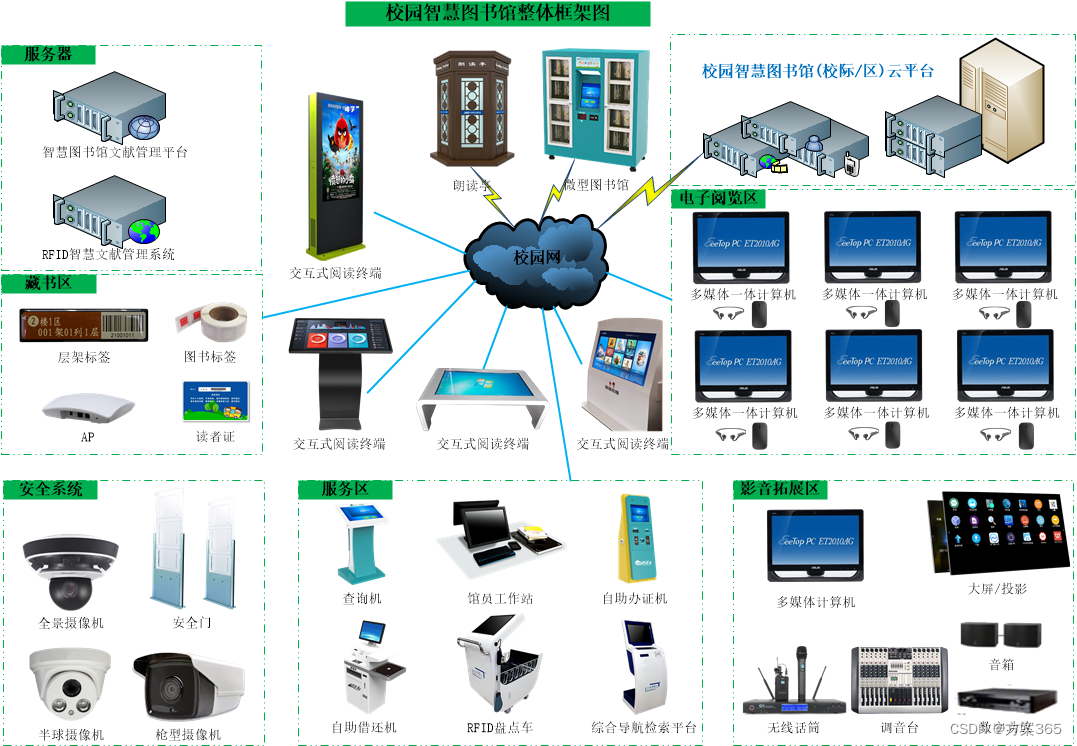
智慧图书馆解决方案-最新全套文件
智慧图书馆解决方案-最新全套文件一、建设背景二、思路架构三、建设方案四、获取 - 智慧图书馆全套最新解决方案合集一、建设背景
现下,传统图书馆已经难以适应时代的发展,图书盘点繁琐、管理模式落后、阅读时间和场地受限等问题,迫使传统图…

ERP+MES集成管理系统重要性有哪些?
随着企业信息化观念的提升,管理方式也愈来愈信息化,因此以信息化推动企业的不断发展趋势已变成企业存活和发展的主要核心理念。其中ERP 系统和 MES 系统在企业发展和改革中起着非常重要的作用。当各种信息化系统在企业内各个部门顺利执行的同…

Hive 之 数据的导入与导出及删除
欢迎大家扫码关注我的微信公众号: Hive 之 数据的导入与导出及删除一、数据导入1.1 向表中加载数据(load): 用的很多1.2 通过查询语句向表中插入数据(insert): 用的很多1.2.1 基本模式插入: &a…
数仓建模理论(二)☆☆☆
学习目录一、ODS层二、DIM层和DWD层三、DWS层与DWT层四、ADS层一、ODS层 ODS层的作用:保存原始数据,不作任何处理 ODS层主要存储的是用户行为日志数据 和 关系型数据库中业务数据
(1)HDFS用户行为日志数据
用户行为数据建表思路…
系统分析师---论企业应用集成
论题:论企业应用集成
企业应用集成(Enterprise Application Integration,EAI)是完成在组织内、外的各种异构系统,应用和数据源之间共享和交换信息和协作的途径,方法学,标准和技术。企业应用集成所连接的应用包括各种电子商务系统,企业资源规划系统,客户关系管理系统,…
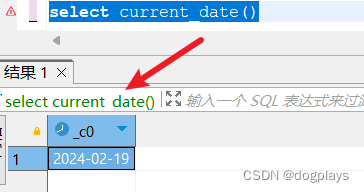
hive load data未正确读取到日期
1.源数据CSV文件日期字段值: 2.hive DDL语句:
CREATE EXTERNAL TABLE test.textfile_table1(id int COMMENT ????, name string COMMENT ??, gender string COMMENT ??, birthday date COMMENT ????,.......)
ROW FORMAT SERDE org.apache.…

OKCC呼叫中心使用中常见问题及处理方法
经常有客户咨询在使用OKCC呼叫中心系统时遇到的一些常见但不复杂的问题,下面整理了一些问题和处理方法给伙伴们参考:一、外呼任务为何启动后会自动暂停?1.检查该账户余额是否充足;2.外呼任务班组中是否有空闲坐席;3.分…
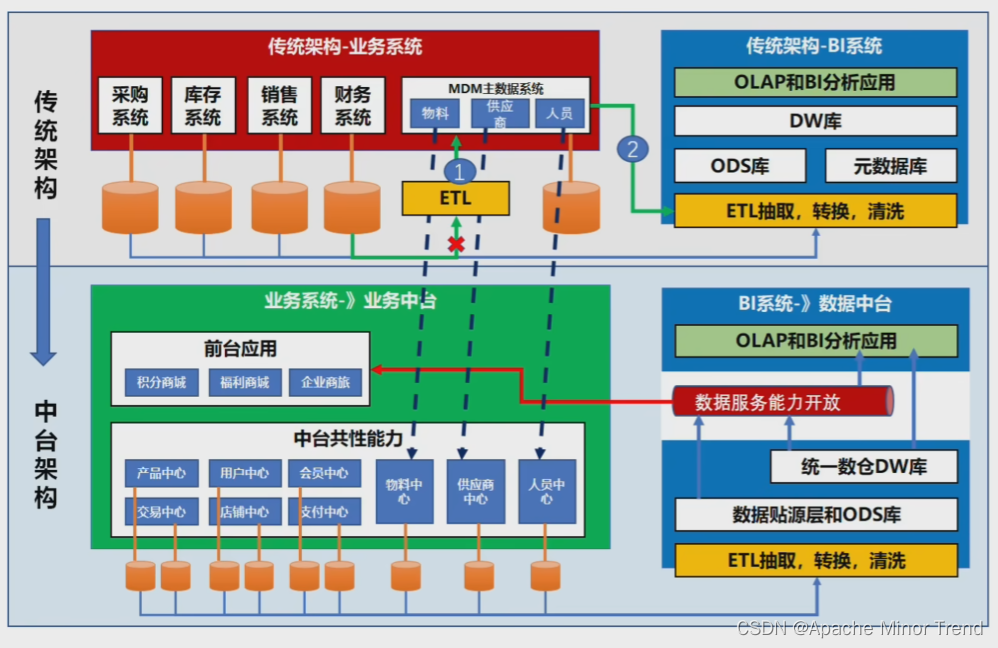
【数据治理-4-主数据和数据中台的区别】
数据治理-4-主数据和数据中台的区别主数据和数据中台的区别1.什么是主数据、数据中台2.主数据、数据中台主要解决的问题主数据和数据中台的区别
1.什么是主数据、数据中台
什么是主数据:跨多个业务系统共享的基础静态数据什么是数据中台:将多个业务系统…
找工作所需数据库基础知识与实际操作(以MySQL为例)
第一章、数据库原理概述 1.1.2 数据库、数据字典、数据库管理系统、数据库系统 1. 数据库(DB)---
(1)概念:按一定结构组织并长期存储在计算机内的、在逻辑上保持一致的、可共享的大量相关数据的集合---存储数据仓库
(2)属性:较小的冗余度、较高的数据独立性、易扩展性…

「数据仓库」怎么选择现代数据仓库?
构建自己的数据仓库时要考虑的基本因素我们用过很多数据仓库。当我们的客户问我们,对于他们成长中的公司来说,最好的数据仓库是什么时,我们会根据他们的具体需求来考虑答案。通常,他们需要几乎实时的数据,价格低廉&…
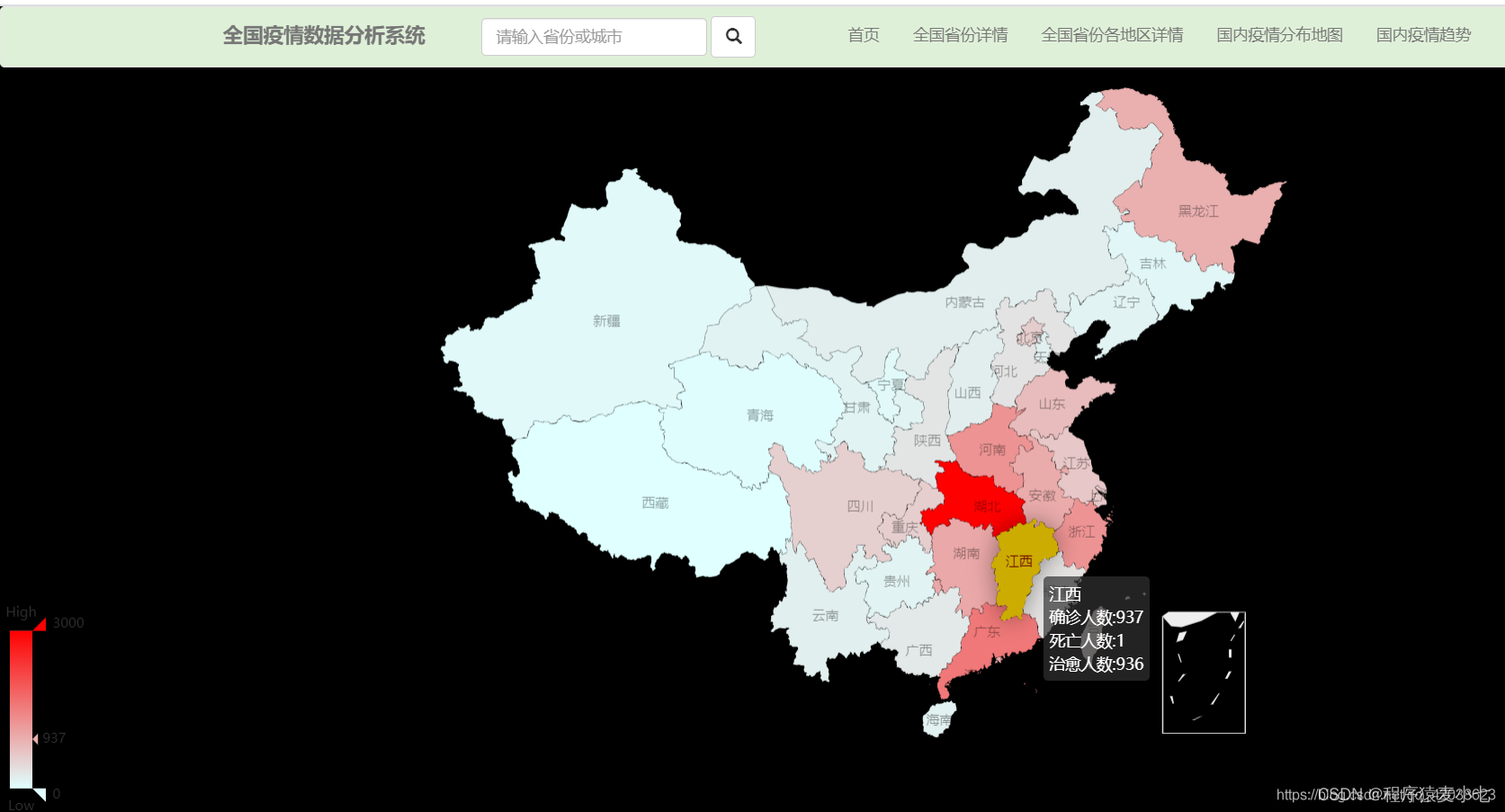
基于Hive的河北新冠确诊人数分析系统的设计与实现
项目描述
临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。这里根据疫情当下,你想解决的问…
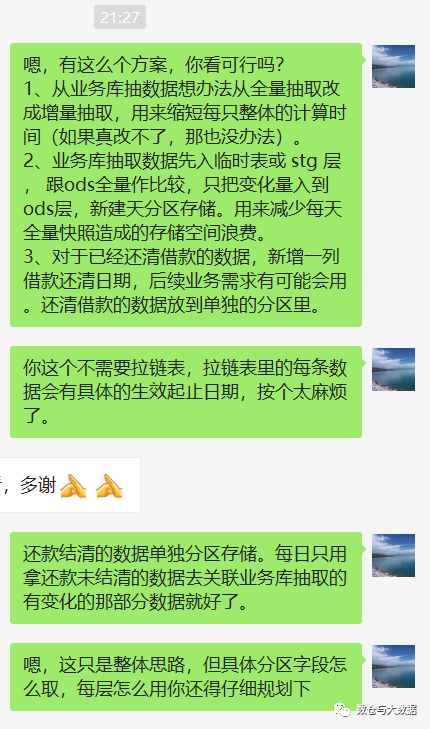
三、数据仓库实践-拉链表设计
1 写在开头的话 拉链表,学名叫缓慢变化维(Slowly Changing Dimensions),简称渐变维(SCD),俗称拉链表,是为了记录关键字段的历史变化而设计出来的一种数据存储模型,常见于…

纵横20年,我所经历的数据开放演化史 by 傅一平
现在数据开放成了数据治理的热点,但数据开放是没法一步到位的,每个企业都要基于实际需要走出自己的路,下面就讲讲我所经历的数据开放演化史,整个过程长达近20年,大致经历了五个阶段:(1&#x…

数据资产治理:元数据采集那点事
正文开始一、介绍数据资产治理(详情见:数据资产,赞之治理)的前提要有数据。它要求数据类型全、量大,并尽可能多地覆盖数据流转的各个环节。元数据采集就变得尤其重要,它是数据资产治理的核心底座。在早…
如何理解《2020年大数据白皮书》的大数据技术最新发展趋势?
正文开始信通院发布的《大数据白皮书2020》(以下简称白皮书,来源:中国信息通信研究院,关注本公众号后,后台回复“big2020”获得PDF),提供了一张非常全面的大数据技术体系图谱,见下图…
Hive学习——分桶抽样、侧视图与炸裂函数搭配、hive实现WordCount
目录
一、分桶抽样
1.抽取表中10%的数据
2.抽取表中30%的数据
3.取第一行
4.取第10行
5.数据块抽样
6.tablesample详解
二、UDTF——表生成函数
1.explode()——炸裂函数
2.posexpolde()——只能对array进行炸裂
3.inline()——炸裂结构体数组
三、UDTF与侧视图的搭…
美团外卖离线数仓建设实践
【与数据同行】已开通综合、数据仓库、数据分析、产品经理、数据治理及机器学习六大专业群,加微信号frank61822701 为好友后入群。新开招聘交流群,请关注【与数据同行】公众号,后台回复“招聘”后获得入群方法。正文开始导读:美团…
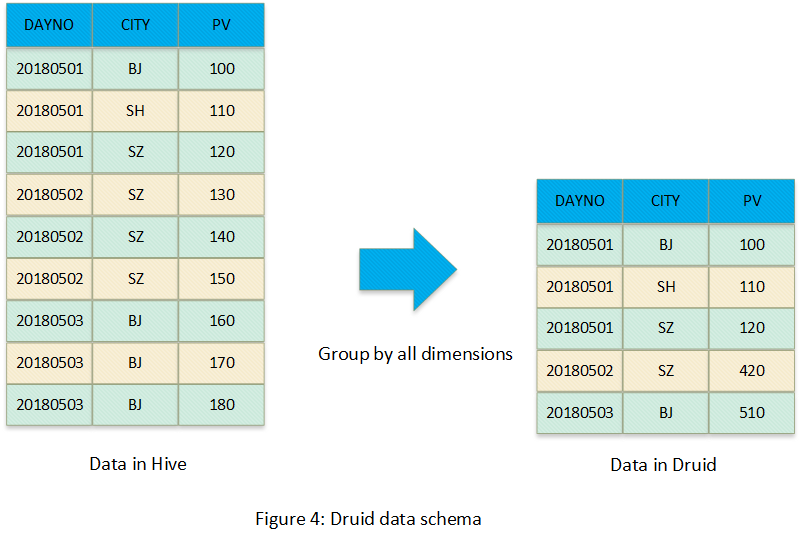
大数据(三)大数据技术栈发展史
-系列目录- 大数据(一)背景和概念 大数据(二)大数据架构发展史 大数据(三)大数据技术栈发展史 前两章,我们分析了大数据相关的概念和发展史,本节我们就讲一讲具体的大数据领域的常见技术栈发展史。对主流技术栈有一个初步的认知。 一、总览 大数据技术栈…

六、数据仓库详细介绍(ETL)工具篇下
0x00 前言
上篇,我们介绍了五种传统 ETL 工具和八种数据同步集成工具。
数据仓库详细介绍(五.ETL)工具篇上 本篇,我们接着介绍两种新型 ETL 工具、大数据发展不同阶段产生的六种主要计算引擎、五种流程控制组件。
最后我们简单…
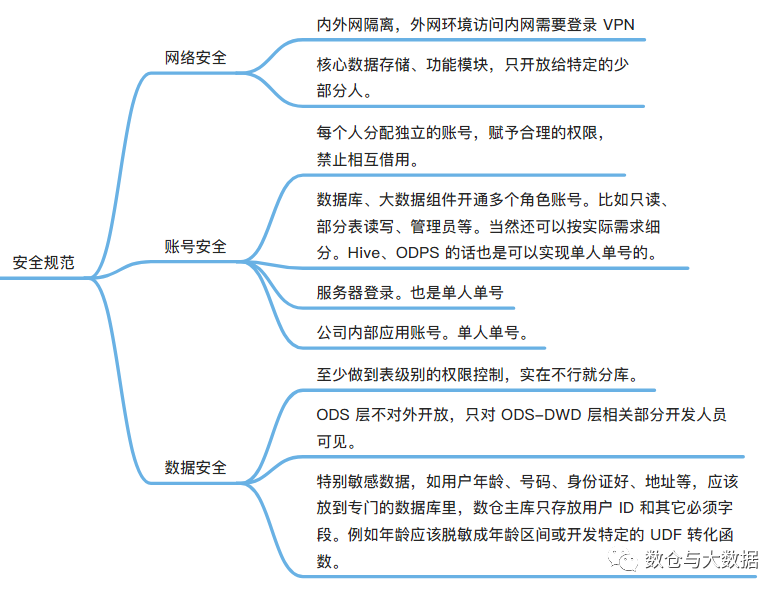
四、数据仓库详细介绍(规范)
大家好,这是数据仓库系列的第三个话题,排序在架构之后、建模之前。为什么会提的这么靠前呢?
因为规范约束的是数仓建设的全流程,以及后续的迭代和运维。事实上,数仓规范文档,应该随着架构设计文档…

一文详解!对于企业来说,商业智能BI到底有什么意义
随着信息化和数字化在社会各方面的推行,数字经济、数据资产成为了当前各行各业企业寻求的新发展。自2020年数据成为第五大生产要素之后,数据就被很多人誉为新时代的“石油”,也让很多人对未来的看法变成了数据处理时代。
这种环境下…
零售行业供应链管理核心KPI指标(一) – 能力、速度、效率和成本
有关零售行业供应链管理KPI指标的综合性分享,涉及到供应链能力、速度、效率和成本总共九大指标,是一个大框架,比较核心也比较综合。
衡量消费品零售企业供应链管理效率和水平的核心KPI通常有哪些? 图片来源-派可数据(…
CDH6.3.2搭建HIVE ON TEZ
参考 https://blog.csdn.net/ly8951677/article/details/124152987
----配置hive运行引擎 在/etc/hive/conf/hive-site.xml中修改如下: hive.execution.engine mr–>tez
hive.execution.engine 设为tez或者运行代码的时候:
set hive.execution.eng…
redis 中的跳跃表(跳表)
目录 一、简介
跳跃表效率体现:
解释 一、简介 跳跃表是一种有序的数据结构,它通过在每个节点中维持多个指向其他的几点指针,从而达到快速访问队尾目的。跳跃表的效率可以和平衡树相媲美了,最关键是它的实现相对于平衡树来说&am…
redis 中Zset(有序集合)介绍 及常用命令(附有示例)
目录
一、Zset有序集合介绍
二、常用命令
三、示例
zadd ...
zrange [WITHSCORES]
zrangebyscore key min max [withscores] [limit offset count]
zrevrangebyscore key max min [withscores] [limit offset count]
zincrby
zrem
zcount
zrank
四、Redis中Zs…
Apache Doris (六) :Doris分布式部署(三) BE部署及启动
进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道,获取高质量博客内容! 本集群中我们在node3、node4、node5上配置并启动BE,下面我们首先在node3节点上部署Doris BE,然后将配置好的BE安装包分…
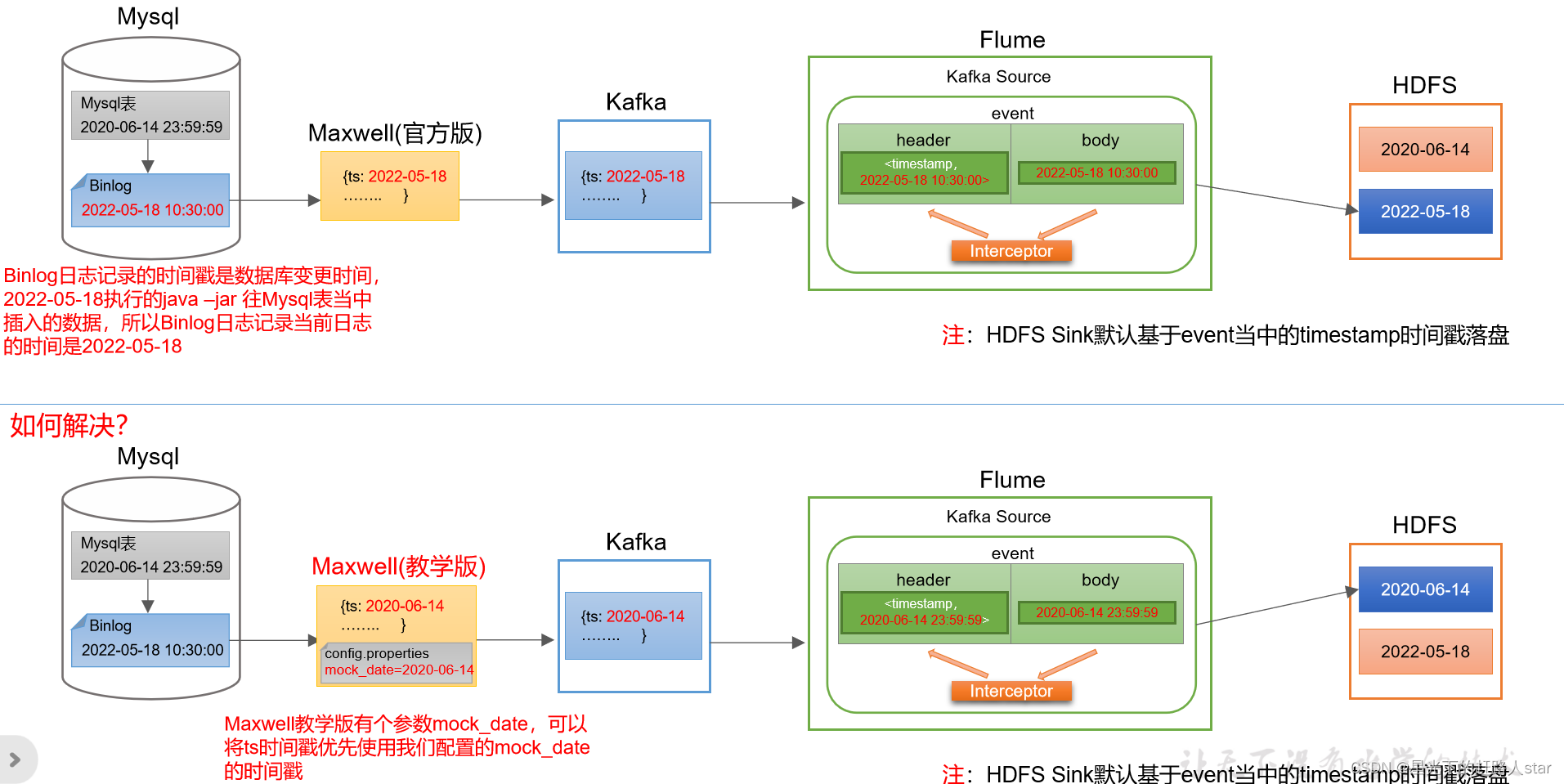
4、离线数仓数据同步策略(全量表数据同步、增量表数据同步、首日同步、采集通道脚本)
1、离线数仓同步数据
1.1 用户行为数据同步
1.1.1 数据通道
用户行为数据由Flume从Kafka直接同步到HDFS,由于离线数仓采用Hive的分区表按天统计,所以目标路径要包含一层日期。具体数据流向如下图所示。
1.1.2 日志消费Flume配置概述
按照规划&…

redis 中键值对的常用命令 (附有示例)
目录 一、redis介绍
二、常见key的命令
三、示例
keys * exists key type key del key
unlink key
expire key 10 select x
dbsize flushdb flushall 一、redis介绍
redis是完全免费的,遵守BSD协议,是一个高性能的键值数据库,是当前最…

redis保姆级安装教学
目录
下载安装包
上传服务器
解压并编译 执行脚本处理
测试
下载安装包
首先我们去到官网
https://redis.io 直接点击Download下载 我们直接将它下载到桌面,方便我们等会安装到服务器上 上传服务器 然后我们连接我们的远程服务器
我选择把redis安装在opt文…
商业智能(Business Intelligence,简称:BI)
商业智能(Business Intelligence,简称:BI),又称商业智慧或商务智能,指用现代数据仓库技术、线上分析处理技术、数据挖掘和数据展现技术进行数据分析以实现商业价值。商业智能的概念在1996年最早由加特纳集团(Gartner Group)提出&a…
基于postgresql传统数据仓库搭建
目录 概述数仓选型对比当前数仓架构问题解决方案 架构设计数据仓库设计命名规范模型设计 PostgreSQL的安装数据仓库的建立创建数据库创建用户组创建用户用户加入到用户组创建模式模式授权用户收回函数的执行权限公开表的select权限动态sql函数集中处理函数 fdw实现数据抽取安装…
Hive(12):View视图
1 View的概念
Hive中的视图(view)是一种虚拟表,只保存定义,不实际存储数据。通常从真实的物理表查询中创建生成视图,也可以从已经存在的视图上创建新视图。
创建视图时,将冻结视图的架构,如果删除或更改基础表,则视图将失败,并且视图不能存储数据,操作数据,只能查…

缓慢渐变维度 (Slowly Changing Dimension) 常见的三种类型及原型设计
目录(?)[] 在从 OLTP 业务数据库向 DW 数据仓库抽取数据的过程中,特别是第一次导入之后的每一次增量抽取往往会遇到这样的问题:业务数据库中的一些数据发生了更改,到底要不要将这些变化也反映到数据仓库中?在数据仓库中ÿ…
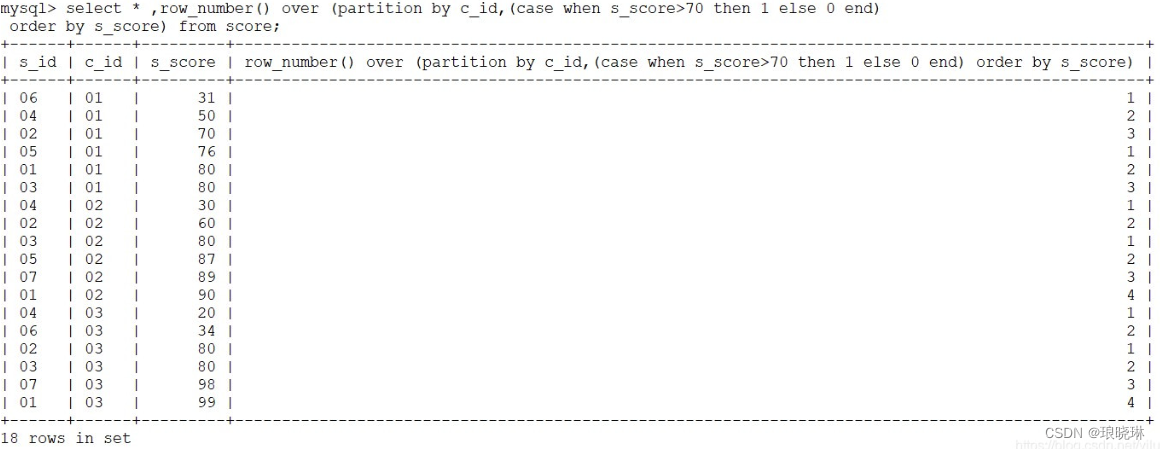
数据仓库系列 之SQL中row_number() over (partition by)的详解
row_number 语法 ROW_NUMBER()函数将针对SELECT语句返回的每一行,从1开始编号,赋予其连续的编号。在查询时应用了一个排序标准后,只有通过编号才能够保证其顺序是一致的,当使用ROW_NUMBER函数时,也需要专门一列用于预先…
数据仓库系列 之使用PreparedStatement执行批量插入sql的三种方式
使用PreparedStatement(方式一):
Testpublic void test1() {Connection conn null;PreparedStatement ps null;try {long start System.currentTimeMillis();conn DBUtil.getConnection();String sql "insert into table1(name) values(?)";ps co…

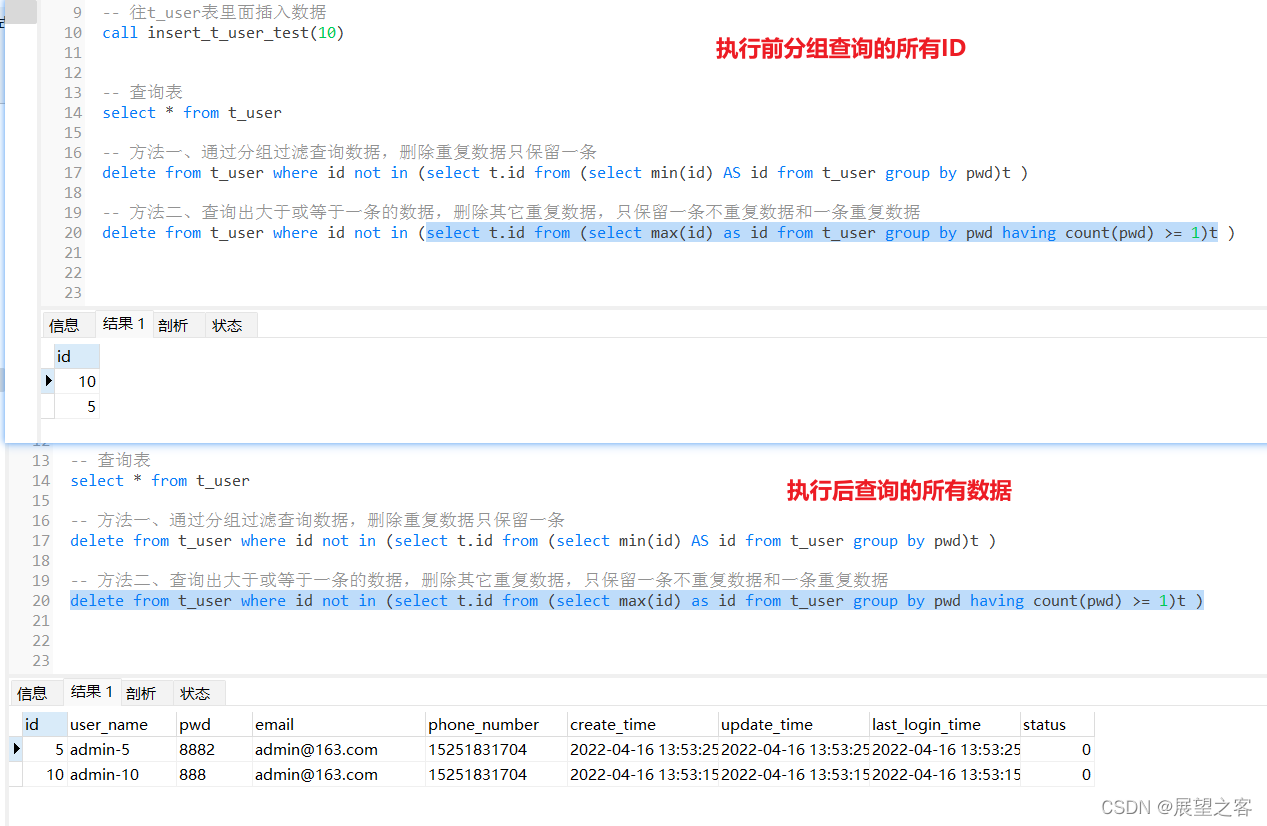
MySQL批量删除所有重复数据只保留一条
-- 1.创建数据库及t_user表
CREATE DATABASE IF NOT EXISTS test DEFAULT CHARACTER SET utf8;USE test;DROP TABLE IF EXISTS t_user;CREATE TABLE t_user (id bigint NOT NULL DEFAULT 0 COMMENT 主键,用户唯一id,user_name varchar(32) NOT NULL DEFAULT COMME…
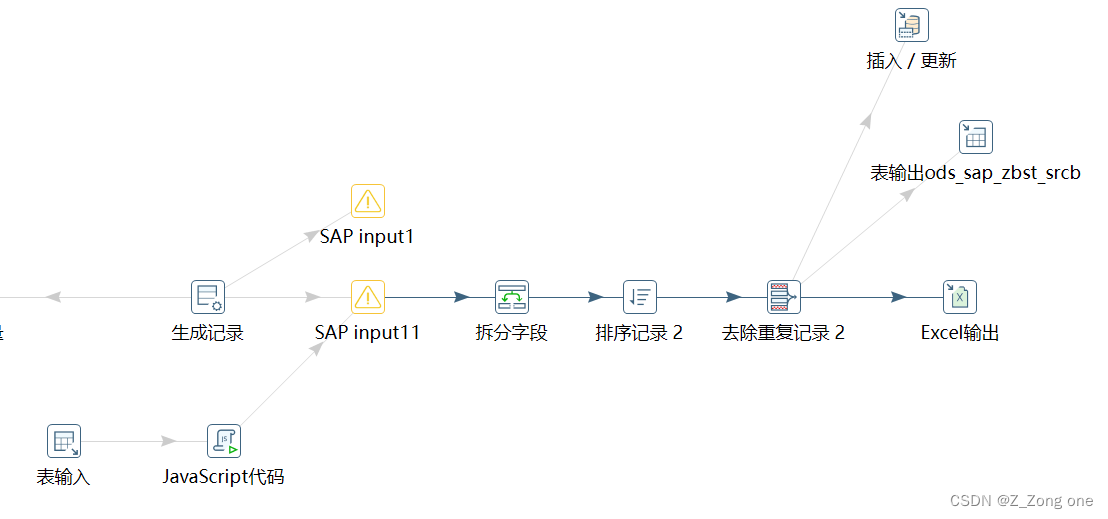
使用kettle连接SAP ERP System
1.连接选 SAP ERP System 填好右侧相关信息 然后点击测试是没有反映的,不管你填的信息对不对点测试都是没有反映的,具体为啥没有反映,不知道。 2.可以使用这两个组件来测试一下有没有连接成功 ①生产记录 组件: ②SAP input 组件&…

九、数据仓库详细介绍(元数据)
元数据的文章,网上已经有很多了,元数据相关概念有限所以重复度很高。 我这里只是做个概念汇集,争取给大家介绍的全面一点。 1. 元数据定义 元数据(Meta-data)是描述数据的数据(The data about data…
【SQL开发实战技巧】系列(二十二):数仓报表场景(上) 从分析函数效率一定快吗聊一聊结果集分页和隔行抽样实现方式
系列文章目录
【SQL开发实战技巧】系列(一):关于SQL不得不说的那些事 【SQL开发实战技巧】系列(二):简单单表查询 【SQL开发实战技巧】系列(三):SQL排序的那些事 【SQL开发实战技巧…
Hive使用注意事项
1)注意表中的数据是存储在hdfs中的,但是表的名称、字段信息是存储在metastore中的 2)中文乱码问题:
中文乱码的原因是因为hive数据库里面的表都是latin1编码的,中文本来就会显示乱码,但是又不能修改整个数据库里面所有…
内行才知道的大数据分析平台
随着这几年来市场需求的增长以及技术的更新,大数据分析平台越来越多地出现在大家的需求采购单上,但面对大数据分析平台,又有多少人知道他们之间的优势区别?今天就从尽量用小白的语言,聊聊内行眼里的大数据分析平台。
…

数据可视化是什么?怎么做?看这篇文章就够了
数据可视化是什么
数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息。也就是说可视化的存在是为了帮助我们更好的去传递信息。
我们需要对我们现有的数据进行分析,得出自己的结论,明确要表达的信息和主题(即你通过…
Hive面试题系列第六题-互为好友问题
视频讲解地址: https://www.bilibili.com/video/BV1at4y1J7Bq/?spm_id_from333.788&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第六题-互为好友问题
题目:根据用户好友列表user_table,求互为共同好友的人有多少对。 表结构:
cre…

八、数据仓库详细介绍(监控告警)
1. 前言 在前边的章节,我们设计完存储模型,开发了 ETL 任务,并且配置好流程依赖,然后上调度系统,至此我们的数据仓库基本搭建完成,而且所有流程任务都可以自动化运转了。 随着公司上线的数据处理任务越来越…

Hive数据分层有哪些优点?具体每一层含义是什么?
为什么要分层?
作为一名数据的规划者,我们肯定希望自己的数据能够有秩序地流转,数据的整个生命周期能够清晰明确被设计者和使用者感知到。直观来讲就是如图这般层次清晰、依赖关系直观。 但是,大多数情况下,我们完成的数据体系却…

一文秒懂BI是什么?
在数字化时代背景下,商业智能(Business Intelligence,简称BI)成为了信息化热词,我们经常能听到企业说“上BI”、“建设BI系统”、“构建BI决策平台”“BI数据分析”“BI可视化”等内容。
一、那么BI到底是什么呢&…
2.项目数仓、项目工具
项目数仓 数仓(Data Warehouse)是指用于存储和管理企业数据的一种大型数据库系统,以支持企业的决策分析活动。它采用了ETL(抽取、转化、加载)等技术来集成和清洗数据,并提供了灵活的查询和报表功能,使得分析师和决策者可以更好地理解企业的业务情况和趋势。 项目工…
尚硅谷大数据项目【电商数仓5.0】学习笔记
尚硅谷大数据项目【电商数仓5.0】学习笔记
大数据学习基础
基础shell编程:大数据之基础shell
集群快速安装教程:大数据集群快速安装教程
注:如果您已经有大数据学习基础,可以通过上面教程快速搭建学习环境,如果您没…
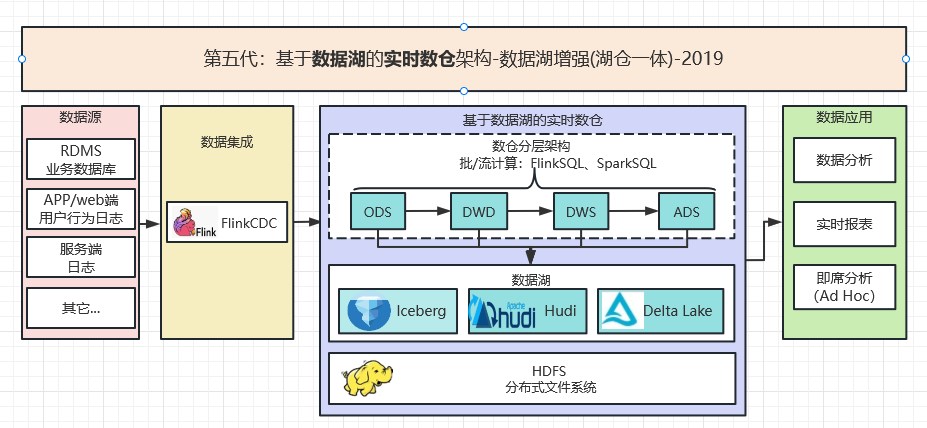
大数据架构(二)大数据发展史
1.传统数仓发展史 传统数据仓库的发展史这里不展开架构细讲,只需快速过一遍即可。了解这个历史发展过程即可。 1.1 传统数仓历史 1.1.1 5个时代 传统数仓发展史可以称为5个时代的经典论证战。按照两位数据仓库大师 Ralph kilmball、Bill Innmon 在数据仓库建设理念上…

如何搭建Mybatis的开发基础环境
如何搭建Mybatis的开发基础环境1. 开篇简介2. 搭建Maven的环境1. 创建maven项目2. 在pom.xml 中配置基础dependencies3. 搭建mybatis的核心配置文件4. 搭建mybatis的接口mapper文件5. 搭建成功6. 总结1. 开篇简介
嗨,大家好! 建议大家先看总结ÿ…
Hive中高频常用的函数和语法梳理及业务场景示例
Hive中高频常用的函数和语法梳理及业务场景示例
聚合函数
collect_list - 收集列值到一个数组
collect_list函数用于将指定列的值收集到一个数组中,并返回该数组作为结果。它通常在GROUP BY子句中使用,以将相同键的值收集到一个数组中进行聚合操作
以…
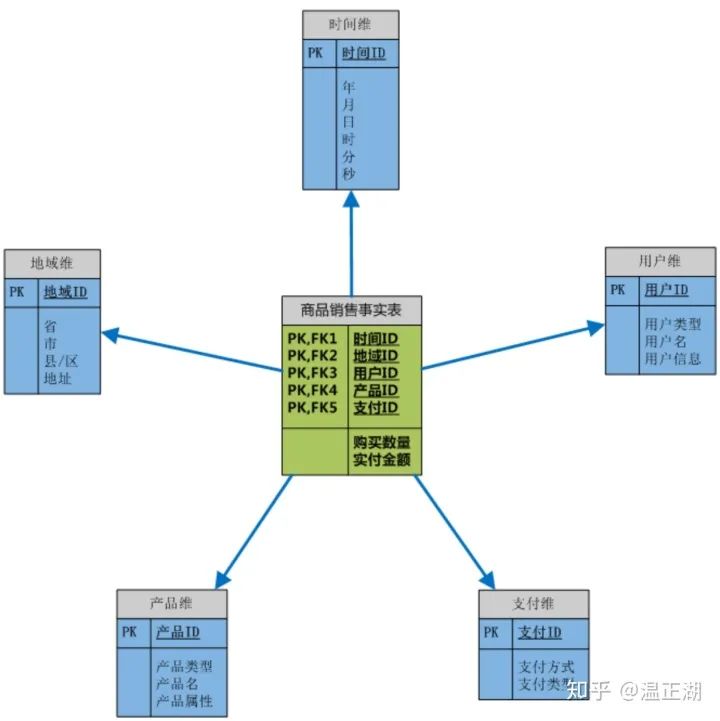
数仓OLAP基础知识
1. OLAP与OLTP的区别?
OLTP(Online transaction processing):在线/联机事务处理。典型的OLTP类操作都比较简单,主要是对数据库中的数据进行增删改查,操作主体一般是产品的用户。
OLAP(Online analytical processing):指联机分析处理。通过分…
Hive group by 数据倾斜问题处理
一、背景
发现一个10.19号的任务下午还没跑完,正常情况下,一般一个小时就已经跑完,而今天已经超过3小时了,因此去观察实际的任务,发现9个map 其中8个已经完成,就一个还在run,说明有明显的数据倾…
INtess客户服务中心的商业智能的应用
INtess客户服务中心的商业智能的应用
2002/10/15 摘要:本文围绕着如何更好地利用客户服务中心的业务数据展开探讨,论述了客户服务中心引入数据分析的必要性,介绍了华为INtess客户服务中心的商业智能的应用。 近年来,客户服务中…
在实施数据仓库过程中应避免的11个错误
在实施数据仓库过程中应避免的11个错误 张晓辉 xiaohuifudan.edu
1. 错误的项目发起:
在数据仓库实施项目经理之上,还有两个关键的人物对整个项目的实施产生重要…
BI在零售业中的应用
BI在零售业中的应用 在国外,BI分析系统作为经营和竞争的有效工具在零售业中的应用已颇为成熟,正在倚仗这一科学而有效的手段,国外的零售巨头们在全球范围内拥有越来越大的经营优势。使用BI分析系统,能跟好的利用BI(Business Intelligent)即商业智能的功能来分析零售经营的各…

Hive的partition问题
查看分区 show partitions td.pt_pmart_kk_SHIPMENT_SETL_ACCOUNT_BILL
hdfs文件按日拉过来了,但是没有数据 (可能是分区没维护要add partition,可能原数据没维护好要analyze,可能表和文件编码不一致)
将数据按partition加载进入这个表
alter table dim.fin_exp_dmn_o…

衡量易操作数据存储(SOD)可扩展性能的十大准则(上)
这篇文章来自作者对Michael Stonebraker和Rick Cattell两位作者所著《10 Rules for scalable Performance in ‘simple operation’ Datastores 》 Communications of The ACM | June 2011 | VOL. 54 | No. 6 的翻译和理解,以飨读者,分为上、…
3、Hive安装部署
1)把apache-hive-3.1.2-bin.tar.gz上传到linux的/opt/software目录下
链接: 百度网盘 请输入提取码 提取码: yded
2)解压apache-hive-3.1.2-bin.tar.gz到/opt/module/目录下面
[shuidihadoop102 software]$ tar -zxvf /opt/software/apache-hive-3.1.…
在线客服系统是一种网页版即时通讯软件的统称
在线客服系统是一种网页版即时通讯软件的统称
在线客服系统是一种网页版即时通讯软件的统称。相比即时通讯软件(如QQ、MSN等),它实现和网站的无缝结合,为网站提供和访客对话的平台,网站访客无需安装任何软件ÿ…

maven下载安装与环境配置
目录
1.下载安装(配置环境)
2.配置仓库路径和镜像: 我现阶段的理解,maven就是一个通过配置文件引入jar包的工具,所以要使用配置文件(pom.xml)去使用框架等,首先就要配置maven。
1…

为什么要建数据仓库,而不是直连数据源?
各位数据的朋友,大家好,我是老周道数据,和你一起,用常人思维数据分析,通过数据讲故事。
今天和大家聊一个话题:为什么BI软件要用构建数据仓库,而不是直连数据源的方式开发报表?&…

leecode 数据库:511. 游戏玩法分析 I
导入数据:
Create table If Not Exists Activity (player_id int, device_id int, event_date date, games_played int);
Truncate table Activity;
insert into Activity (player_id, device_id, event_date, games_played) values (1, 2, 2016-03-01, 5);
insert…
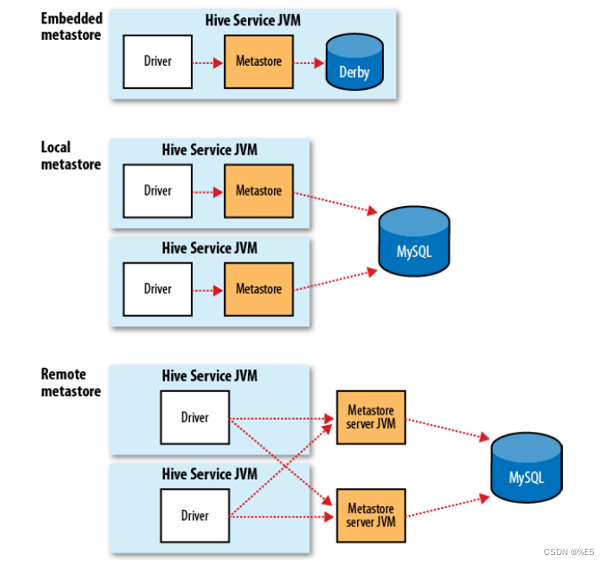
大数据|Hive和数据仓库
前文回顾:HBase基本工作原理 目录
📚数据仓库和OLAP
🐇数据仓库
🥕面向主题
🥕集成的
🥕时变的
🥕非易失的
🐇OLTP(联机事务处理)vs OLAP(…

5个关键词回顾2022年个推技术实践
作为一家数据智能服务商,2022年每日互动(个推)在为开发者和行业客户提供优质服务的同时,不断砥砺创新,追逐技术前沿。个推还持续参与开发者生态建设,积极总结、分享自身技术实战经验,面向行业输…
数据仓库-数据质量管理
一、数据质量管理定义数据质量管理(Data Quality Management),是指对数据从计划、获取、存储、共享、维护、应用、消亡生命周期的每个阶段里可能引发的各类数据质量问题,进行识别、度量、监控、预警等一系列管理活动,并…
百度Doris项目正式进入顶级开源社区Apache孵化器
近日,全球著名开源社区Apache基金会宣布“百度开源的Doris项目全票通过进入Apache孵化器”。这是百度继ECharts后第二个进入Apache基金会的项目,充分彰显了百度“开源速度”。Doris是百度开发的面向在线报表和分析的数据仓库系统,可以对标于商…
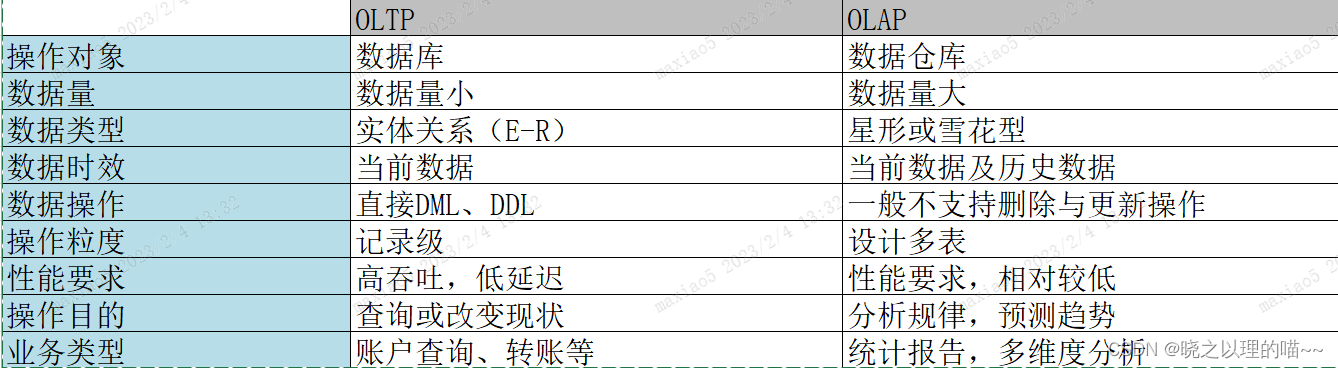
数据仓库的架构以及传统数据库与数据仓库的区别
一、数据仓库的分层架构
数据仓库的数据来源于不同的源数据,并提供多样的数据应用,数据自下而上流入数据仓库后向上层开放应用,而数据仓库只是中间集成化数据管理的一个平台。
1,源数据层(ODS)
操作性数…

hive udf 判断四边形是否为矩形
hive udf中经常要做判断四边形是否为矩形,所以写了这个udf如下: public class RectangularIsNot extends UDF {private static final int LNG_LAT_LENGTH = 2;private static final String SEPARATOR_POINT = "|";private
SQl Server 2008 知识点概括【数据库】
1. 第一章 数据库概述
什么是数据库? 数据库是采用计算机技术统一管理的相关数据的集合,数据库能为各种用户共享,具有冗余度最小、数据之间联系密切、有较高数据独立性等特点。Microsoft SQL Server 系统的体系结构 Microsoft SQL Server 20…

【MySQL】MySQL表的增删改查(进阶版)
📌前言:本篇博客介绍MySQL数据库增删改查的进阶版,学习MySQL之前要先安装好MySQL,如果还没有安装的小伙伴可以看看博主前面的博客,里面有详细的安装教程。
那我们废话不多说,直接进入主体!&…
数据库设计的14个技巧(转)
1. 原始单据与实体之间的关系 可以是一对一、一对多、多对多的关系。在一般情况下,它们是一对一的关系:即一张原始单据对应且只对应一个实体。在特殊情况下,它们可能是一对多或多对一的关系,即一张原始单据对应多个实体࿰…

数字孪生,开启3D智慧园区管理新篇章
在各行各业数字化转型的浪潮中,园区也在转型发展:从传统园区向智慧园区不断演进。传统园区缺乏系统性规划,基于单点功能的建设,导致系统孤立、管理粗放且服务不足等问题,已难以满足人们日益增长的多样化需求。在需求与…

数据应用广场,使用户掌握数据主权
随着企业建设的业务系统越来越多,沉淀的数据体量也愈来愈庞大,而当前数据治理产品大多为技术人员开发使用,客户对治理结果无感知,企业在数据应用方面数据不可见、不可查、难感知、难管理等问题越发明显,极大的降低了数…
oracle 数据仓库提高访问速度方法
压缩数据以节省空间和提高速度作者:Sanjay Mishra
使用表压缩来节省空间并提高查询性能。
很多决策支持系统通常都涉及到存储于几个特大表中的大量数据。随着这些系统的发展,对磁盘空间的需求也在快速增长。在当今的环境下,存储着数百TB&am…
javaweb监听器和juery技术
监听servlet创建
package com.hspedu.listener;import javax.servlet.ServletContext;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;/*** 老韩解读* 1. 当一个类实现了 ServletContextListener* 2. 该类就是一个监听器* 3. 该类可…
【Power BI】数据可视化:使用 Power BI 处理结构化复杂表单数据 | 文末送书
文章目录 前言使用 Power BI 处理结构化复杂表单数据案例一、处理标题与内容同行的数据表案例二、处理标题与内容同单元格的数据表 文末总结Power BI 新书推荐 前言
数据处理是数据分析的奠基石,只有使用处理干净的数据,分析才会产生价值。简单而言&…
计算同比、环比的一些常识性问题
什么鬼
我想在这篇文章中说明的是在计算同比、环比的值的时候,会遇到的一些问题。这些问题如下:
环比月天数不一致同比周数不一致可比&全同比
在这一小节里面,我先不说上面的四个问题,我想说的是什么是同比、环比。
来给同…

数仓建设几个关键问题
数仓的功能
以我当前的认知,数仓应该至少有下面三个职责:
数据整合统一口径提高数据分析的效率
下面详细说说这三点。
数据整合
数据整合是为了解决各系统的异构问题。对于大体量的公司来说,往往会投入大量的资源解决“数据孤岛”问题。当一个公司大…

hive表的全关联full join用法
背景:实际开发中需要用到全关联的用法,之前没遇到过,现在记录一下。需求是找到两张表的并集。
全关联的解释如下; 下面建两张表进行测试
test_a表的数据如下 test_b表的数据如下;
写第一个full join 的SQL进行查询…
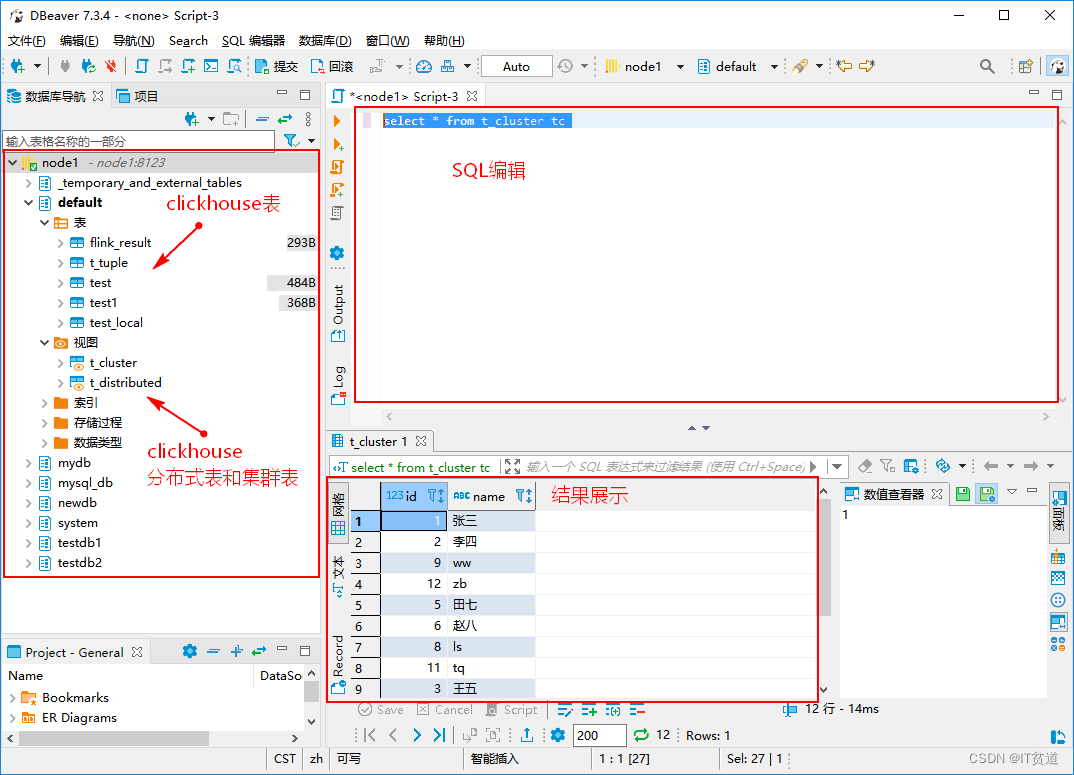
ClickHouse(二十五):ClickHouse 可视化工具操作
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证…
Apache Doris (八) :Doris分布式部署(五) Broker部署及Doris集群启动脚本
目录
1.Broker部署及扩缩容
1.1 BROKER 部署
1.2 BROKER 扩缩容
2. Apache Doris集群启停脚本 进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道,获取高质量博客内容! 1.Broker部署及扩缩容
Broker 是 Doris 集…

漫谈数仓OLAP技术哪家强?
【提醒:公众号推送规则变了,如果您想及时收到推送,麻烦右下角点个在看,或者把本号置顶】正文开始数据应用,是真正体现数仓价值的部分,包括且又不局限于 数据可视化、BI、OLAP、即席查询,实时大屏…
java数据库设计中的14个技巧(zhuang SCDN)
下述十四个技巧,是许多人在大量的数据库分析与设计实践中,逐步总结出来的。对于这些经验的运用,读者不能生帮硬套,死记硬背,而要消化理解,实事求是,灵活掌握。并逐步做到:在应用中发…
数据库中的聚簇索引和非聚簇索引
聚簇索引和非聚簇索引的比较
聚簇索引和非聚簇索引最大的区别就在于数据和索引是否分开储存。 聚簇索引:将数据和索引一起储存,索引结构的叶子节点存的是数据行。非聚簇索引:数据和索引分开储存,索引结构的叶子节点存的是指向数据行的地址。 在InnoDB引…
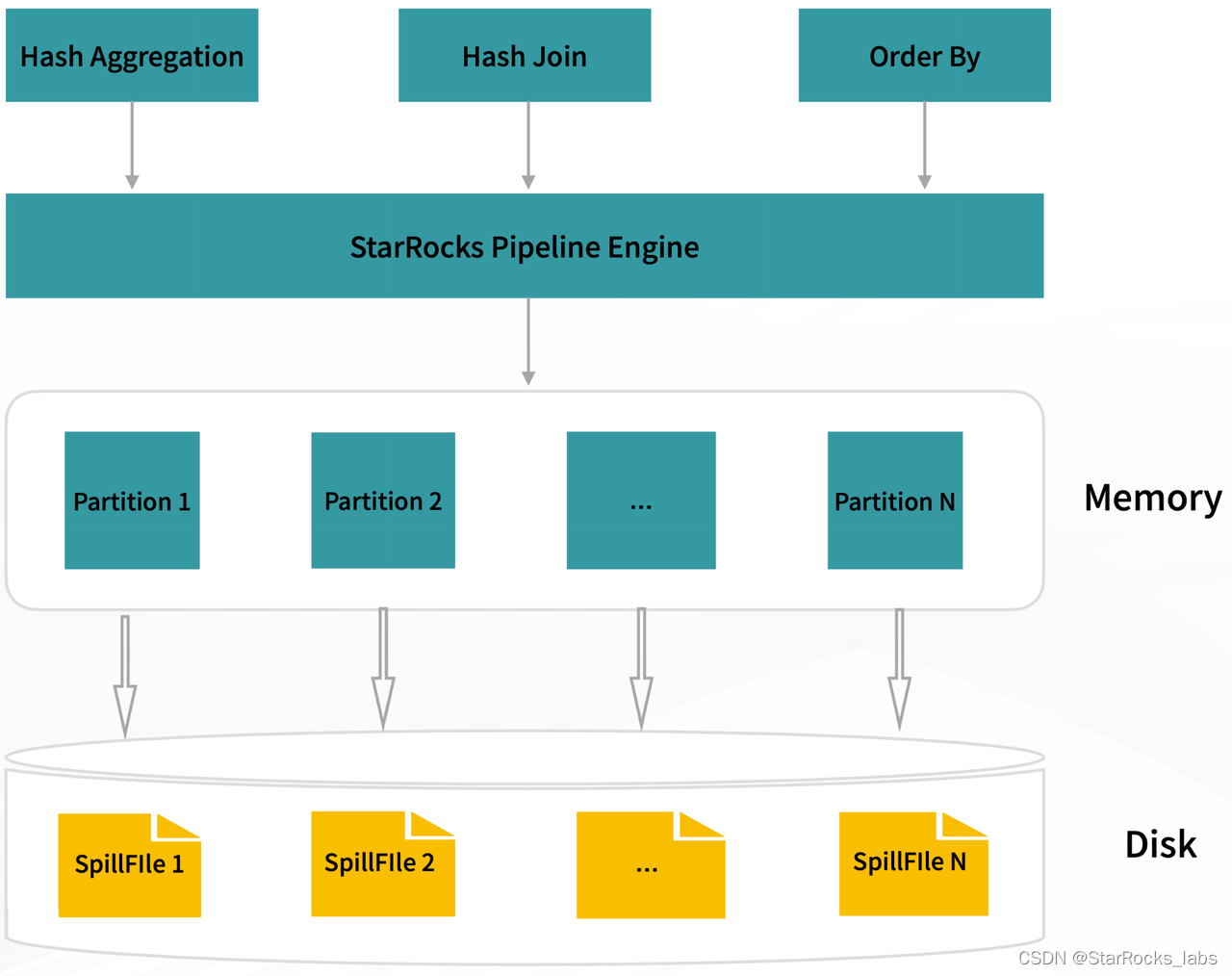
StarRocks 3.1重磅发布,云原生湖仓新范式再升级!
StarRocks 自4月底发布3.0版本,拥抱云原生,开启极速统一的湖仓新范式;8月7日,StarRocks 正式发布全新3.1版本,全面提升云原生存算分离构架、极速数据湖分析、物化视图等重量级特性,让用户更简单的实现极速统…
ETLCloud+MaxCompute实现云数据仓库的高效实时同步
MaxCompute介绍
MaxCompute是适用于数据分析场景的企业级SaaS(Software as a Service)模式云数据仓库,以Serverless架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用…

hive on tez资源控制
sql insert overwrite table dwintdata.dw_f_da_enterprise2 select * from dwintdata.dw_f_da_enterprise; hdfs文件大小数量展示 注意这里文件数有17个 共计321M 最后是划分为了21个task
为什么会有21个task?不是128M 64M 或者说我这里小于128 每个文件一个map…
企业时代下的汽车4S店形势分析
据网上数据显示,2022年约有2000家汽车4S店闭店退网,这一数据不由令人惊叹!
疫情放开后,原以为汽车经销商的春天也即将来临,可它们有些已经死在了半路上。
2023年伊始,经销商大戏以一则破产消息开幕——浙…
大数据扫盲(1): 数据仓库与ETL的关系及ETL工具推荐
在数字化时代,数据成为了企业决策的关键支持。然而,随着数据不断增长,有效地管理和利用这些数据变得至关重要。数据仓库和ETL工具作为数据管理和分析的核心,将帮助企业从庞杂的数据中提取有价值信息。 一、ETL是什么? …
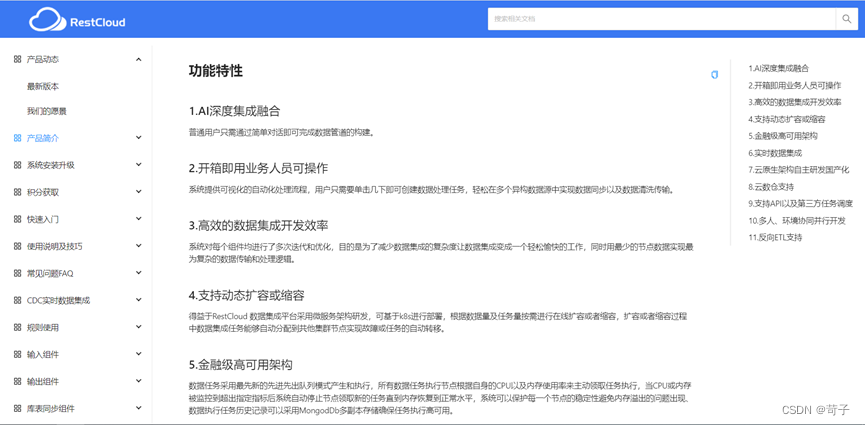
ETL技术入门之ETLCloud初认识
首先ETL是什么?
ETL代表“Extract, Transform, Load”,是一种用于数据集成和转换的过程。它在数据管理和分析中扮演着重要的角色。下面我们将分解每个步骤: Extract(抽取): 这一步骤涉及从多个不同的数据源…

hive 中最常用日期处理函数
hive 常用日期处理函数
在工作中,日期函数是提取数据计算数据必须要用到的环节。哪怕是提取某个时间段下的明细数据也得用到日期函数。今天和大家分享一下常用的日期函数。为什么说常用呢?其实这些函数在数据运营同学手上是几乎每天都在使用的。
技术交…
Apache Doris 入门教程36:文件分析和文件缓存
文件分析
通过 Table Value Function 功能,Doris 可以直接将对象存储或 HDFS 上的文件作为 Table 进行查询分析。并且支持自动的列类型推断。
使用方式
更多使用方式可参阅 Table Value Function 文档:
S3:支持 S3 兼容的对象存储上的文…
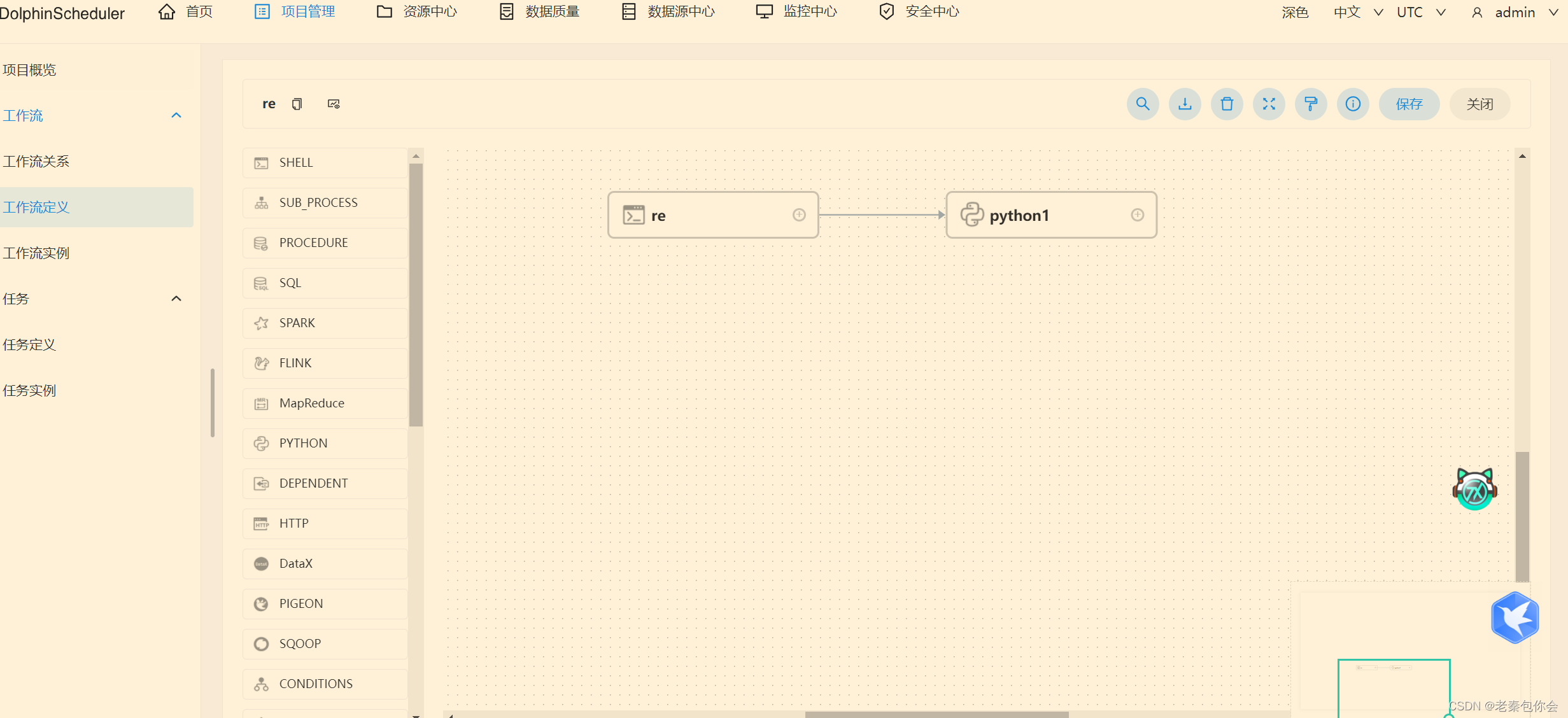
数据库第十七课-------ETL任务调度系统的安装和使用
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…
ClickHouse 相关
ClickHouse 是分布式实时分析型列式数据库服务,查询效率数倍于传统数据仓库,适用于海量数据的实时查询分析。
Notice:
操作语句需要加上ON CLUSTER default!!建表时能用数值型或日期时间型表示的字段,就不…
配置开启Hive远程连接
配置开启Hive远程连接 Hive远程连接默认方式远程连接Hive自定义身份验证类远程连接Hive权限问题额外说明 Hive远程连接
要配置Hive远程连接,首先确保HiveServer2已启动并监听指定的端口
hive/bin/hiveserver2检查 HiveServer2是否正在运行
# lsof -i:10000
COMMA…
数据仓库环境下的超市进销存系统结构
传统的进销存系统建立的以单一数据库为中心的数据组织模式,已经无 法满足决策分析对数据库系统的要求,而数据仓库技术的出现和发展,为上述问题 的解决提供了强有力的工具和手段。数据仓库是一种对多个分布式的、异构的数据 库提供统一查询…
数据仓库性能测试方法论与工具集
目录 文章目录 目录数据仓库 v.s. 传统数据库数据仓库性能测试案例性能指标测试方案测试场景测试数据集测试用例性能指标测试脚本工具 基准环境准备硬件环境软件环境 测试操作步骤Cloudwave 执行步骤导入数据集TestCase 1. 执行 13 条标准 SQL 测试语句TestCase 2. 执行多表联合…
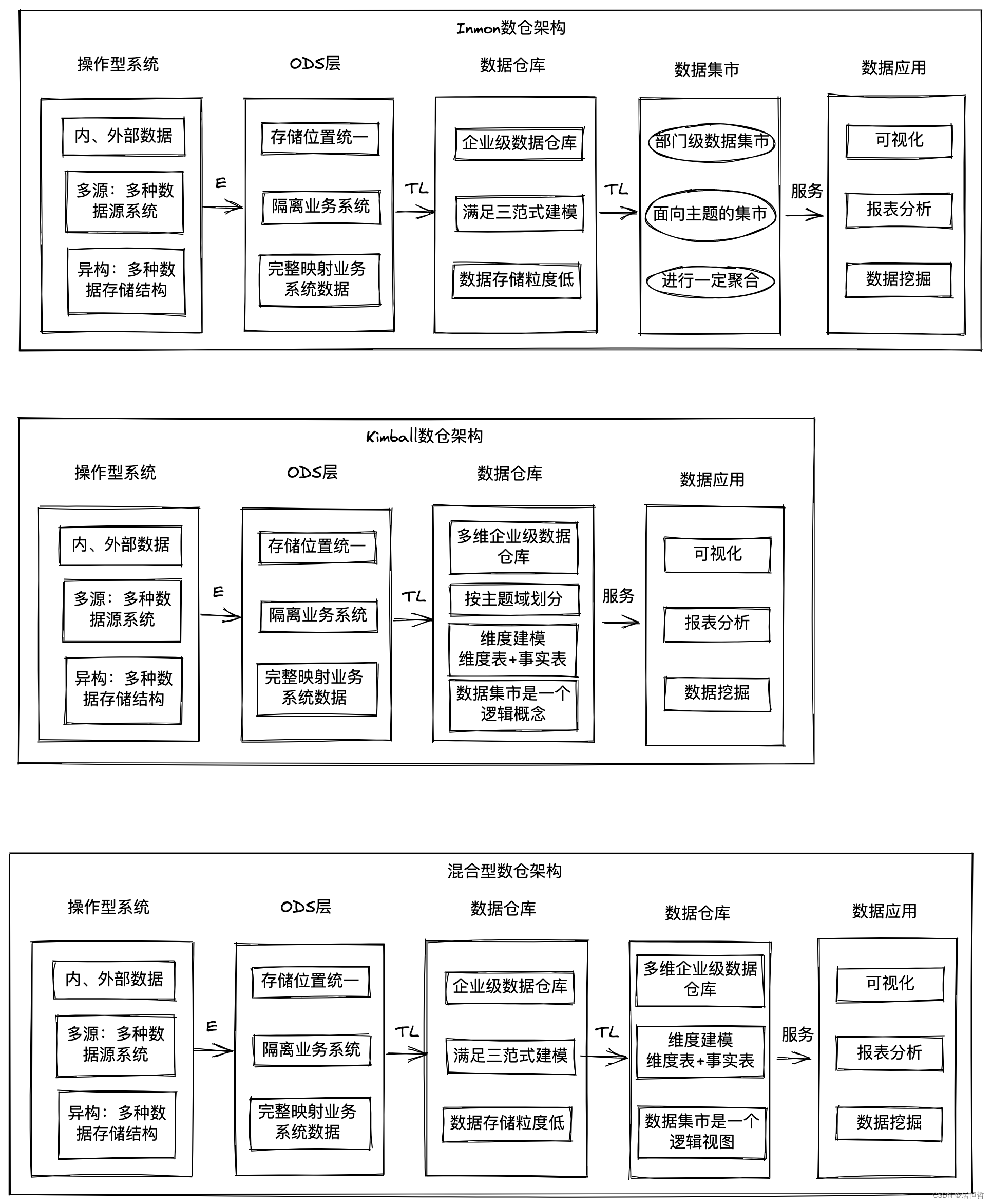
数据仓库的三种建设思路
Inmon企业级数据仓库
关键字:范式建模
数仓:Inmon企业级数据仓库是一个细节数据的集成资源库。数据在物理存储层面满足第三范式设计规范,数据以最低粒度存储。
数据集市:在企业级数仓的基础上,建立部门级数据集市。…

Docker容器镜像上传到DockerHub仓库
Docker容器镜像上传到DockerHub仓库
1. 创建DockerHub账户
dockerhub官方网站,注册一个账户,并创建一个仓库,这里账户名是dc1004,仓库名dc 2. 查看容器
docker ps查看你自己要上传的容器,获取容器ID/容器名
3. 提交…
Codeup代码,如何上传/下载Codeup代码
如何上传/下载Codeup代码
如何把代码上传codeup代码仓库
云开发平台默认集成 云效Codeup 作为项目代码仓库,因此所有云应用的代码都需要提交Codeup代码仓库中,平台将确保您的代码安全。
存量应用搬站场景和本地开发场景,会需要从本地提交代…

《阿里大数据之路》读书笔记:第二章 日志采集
第二章 日志采集
一、浏览器的页面日志采集
浏览器的页面型产品/服务的日志采集可分为两大类: 页面浏览(展现)日志采集 指一个页面被浏览器加载呈现时采集的日志 此类日志是最基础的互联网日志 此类日志是目前所有互联网产品的两大基本指…

什么是API——理解应用程序接口的概念、类型和应用
I. 什么是API API(Application Programming Interface,应用程序接口)是指两个不同软件应用之间进行交互的一组方法。它是现代软件开发中不可或缺的一部分,让不同的应用程序能够相互通信、共享数据,并且以一种有序的方式…
ClickHouse(十九):Clickhouse SQL DDL操作-1
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…
DTCC 2023即将启幕 明天见!
8月16日-18日,由IT168联合旗下ITPUB、ChinaUnix两大技术社区主办的第14届中国数据库技术大会(DTCC2023)将在北京举行
作为国内云原生数据仓库代表厂商,酷克数据受邀亮相DTCC 2023,与广大数据库领域从业人士共同分享云…
651页23万字智慧教育大数据信息化顶层设计及建设方案WORD
导读:原文《651页23万字智慧教育大数据信息化顶层设计及建设方案WORD》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。
目录
一、 方案背景
1.1 以教育…
【hive】hive修复分区或修复表 以及msck命令的使用
【hive】hive修复分区或修复表 以及msck命令的使用 文章目录 【hive】hive修复分区或修复表 以及msck命令的使用问题原因:解决方法:msck命令解析:例子: 问题原因:
之前hive里有数据,后面存储元数据信息的MySQL数据库坏…

大型集团企业数字化管控平台及信息化治理服务体系建设方案PPT
导读:原文《大型集团企业数字化管控平台及信息化治理服务体系建设方案PPT》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。 喜欢文章,您可以点…
企业数字化转型大数据湖一体化平台项目建设方案PPT
导读:原文《企业数字化转型大数据湖一体化平台项目建设方案PPT》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。 喜欢文章,您可以点赞评论转发…
Apache Doris 入门教程33:统计信息
统计信息
统计信息简介
Doris 查询优化器使用统计信息来确定查询最有效的执行计划。Doris 维护的统计信息包括表级别的统计信息和列级别的统计信息。
表统计信息:
信息描述row_count表的行数data_size表的⼤⼩(单位 byte)update_rows收…
Hive学习(12)Hive常用日期函数
1、to_date:日期时间转日期函数
select to_date(2015-04-02 13:34:12);
输出:2015-04-022、from_unixtime:转化unix时间戳到当前时区的时间格式
select from_unixtime(1323308943,’yyyyMMdd’);
输出:201112083、unix_timestam…
数据治理-数据仓库和商务智能
业务驱动因素 数据仓库建设的主要驱动力是运营支持职能、合规需求和商务智能活动。
一个组织建设数据仓库的目标
支持商务智能活动赋能商业分析和高效决策基于数据洞察寻找创新方法。
一个组织应遵循如下指导原则
聚焦业务目标以终为始全局性的思考和设计,局部性…
接入API接口文档1688阿里巴巴获取跨境属性数据参考示例
API接口文档的作用和意义:
明确需要的接口服务
API分为很多种,最基础也是产品最需要的诸如短信API,地图API,语音API等,如果我们的产品涉及到此方面的功能,那就必须了解这方面的API以便于在需求设计阶段考…
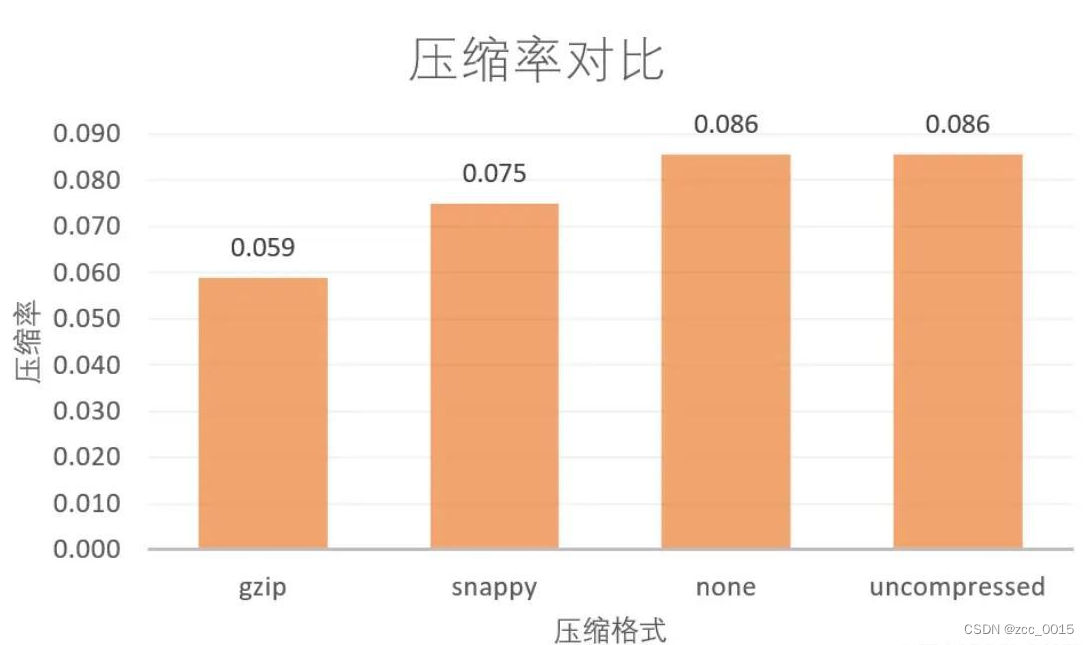
pg数据表同步到hive表数据压缩总结
1、背景 pg库存放了大量的历史数据,pg的存储方式比较耗磁盘空间,pg的备份方式,通过pgdump导出后,进行gzip压缩,压缩比大概1/10,随着数据的积累磁盘空间告警。为了解决pg的压力,尝试采用hive数据…
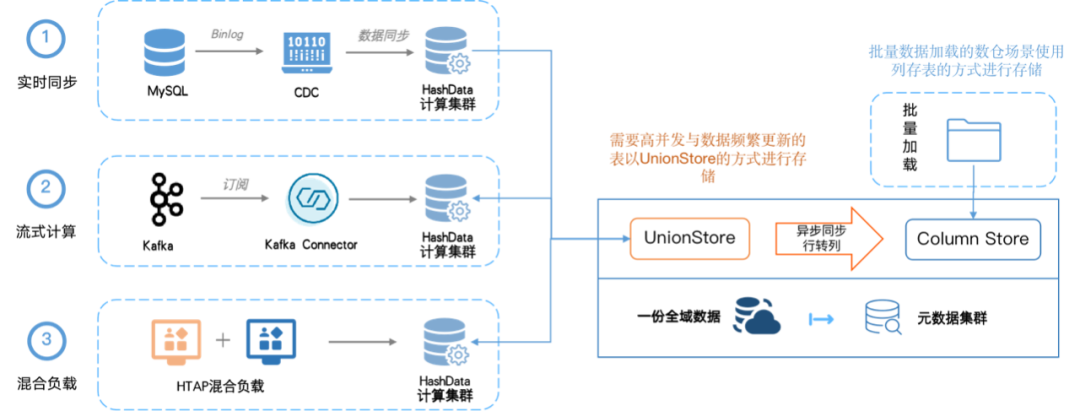
同一份数据全域共享,HashData UnionStore实时性背后的故事
时至今日,数据已经被越来越多的企业视为发展的战略资源,而云数仓则是数据发挥重要价值的关键媒介。云数仓的出现,不仅改变了传统数据仓库的服务模式,更给用户带来了应对海量、新型数据的存储和处理能力,为满足业务现代…
API接口请求电商数据平台参数获取淘宝商品描述示例
淘宝商品描述详细信息API接口是一个用于获取淘宝商品详细信息的API,通过它可以获取到商品的标题、价格、图片等信息。通过淘宝商品描述详细信息API接口,开发者可以方便地获取宝贝的相关信息,并将它们用于各种应用场景中。淘宝商品描述详细信息…
【Power BI】使用 Power BI 处理结构化复杂表单数据 | 文末送书
文章目录 前言使用 Power BI 处理结构化复杂表单数据案例一、处理标题与内容同行的数据表案例二、处理标题与内容同单元格的数据表 文末总结Power BI 新书推荐 前言
数据处理是数据分析的奠基石,只有使用处理干净的数据,分析才会产生价值。简单而言&…

hive高频使用的拼接函数及“避坑”
hive高频使用的拼接函数及“避坑”
说到拼接函数应用场景和使用频次还是非常高,比如一个员工在公司充当多个角色,我们在底层存数的时候往往是多行,但是应用的时候我们通常会只需要一行,角色字段进行拼接,这样join其他…

ClickHouse(十八):Clickhouse Integration系列表引擎
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…
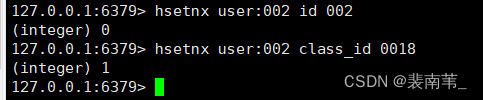
redis 中 Hash哈希介绍 及常用命令 (附有示例)
目录 一、Redis中Hash介绍
二、常用命令
三、示例
hset
hget
hmset .. hexists
hkeys
hvals
hincrbu
hsetnx 四、redis中Hash底层数据结构 一、Redis中Hash介绍
Redis Hash是一个键值对集合 Redis hash 是一个String类型的 field 和 value 的映射表&…

redis 中Set类型 及常用命令(附有示例)
目录
一、Redis中Set介绍
特点:
二、常用命令
三、示例
sadd ..
smembers
simembers
scard
srem ..
spop
srandmember
smove sinter
sunion
sdiff 四、Set底层的数据结构 一、Redis中Set介绍
Redis set 对外提供的功能与lis…
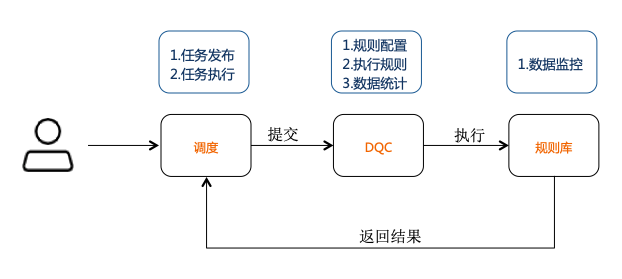
十、数据仓库详细介绍(数据质量)流程与工具
上篇我们主要介绍了以下三部分内容。 第一部分,介绍了五种常见的数据管理知识体系,数据质量在所有的知识体系中都有非常重要的地位,数据应用体现数据价值,数据质量为应用提供支撑。 第二部分,我们介绍了数据质量评判的…
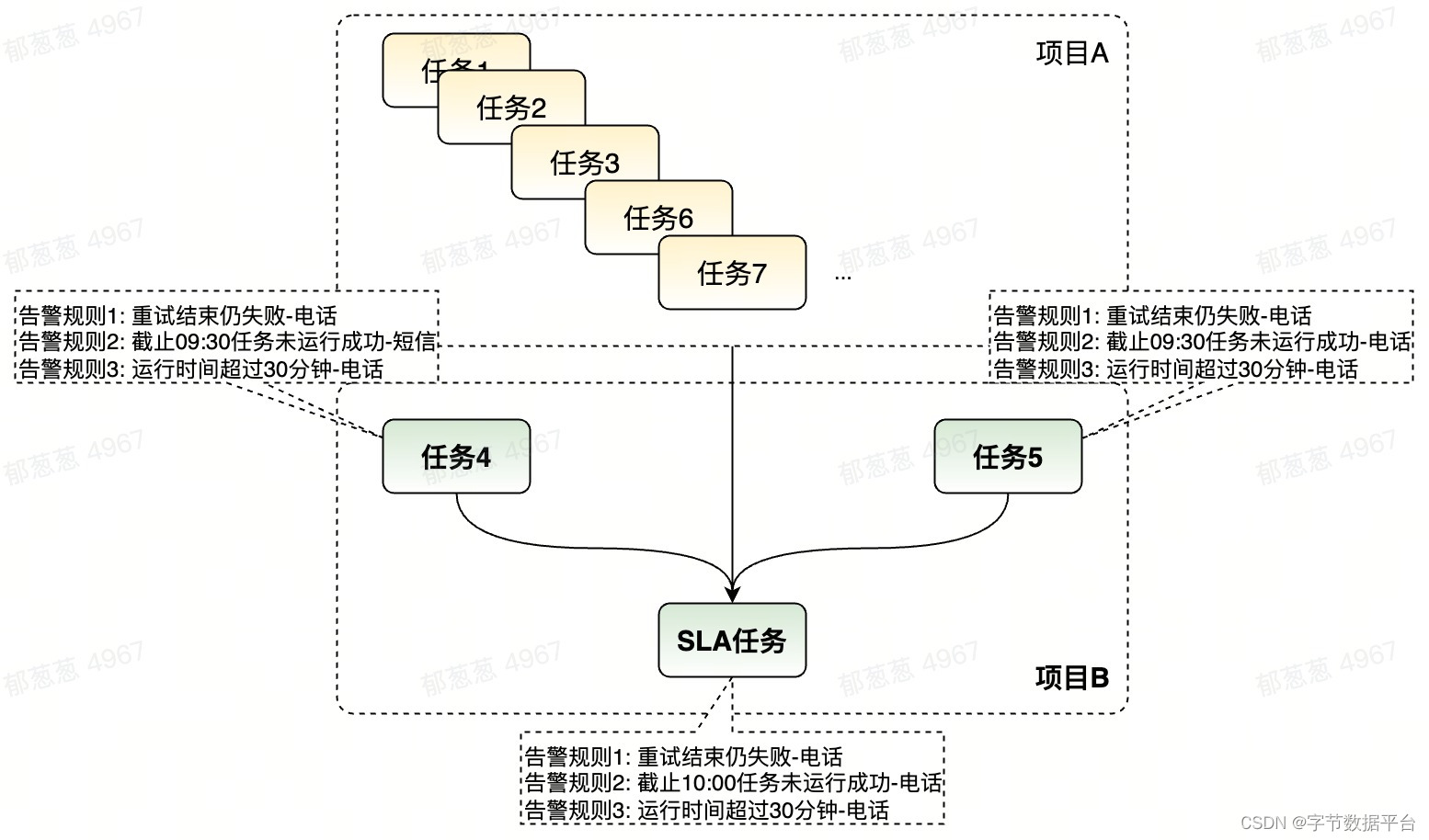
DataLeap的全链路智能监控报警实践(一):常见问题
随着字节跳动业务的快速发展,大数据开发场景下需要运维管理的任务越来越多,然而普通的监控系统只支持配置相应任务的监控规则,已经不能完全满足当前需求,在日常运维中开发者经常会面临以下几个问题: 任务多,…

HiveSQL初级题目
文章目录 Hive SQL题库(初级)第一章 环境准备1.1 建表语句1.2 数据准备1.3 插入数据 第二章 简单查询2.1 查找特定条件2.1.1 查询姓名中带“冰”的学生名单2.1.2 查询姓“王”老师的个数2.1.3 检索课程编号为“04”且分数小于60的学生的课程信息,结果按分数降序排列…

数据湖仓一体化架构:探究新一代数据处理的可能性
一、引言
随着大数据的快速发展,企业不断寻求高效、灵活和经济的方法来处理和管理海量数据。在这种背景下,数据湖和数据仓库这两种不同的架构模式各自展现出其独特的优势。而数据湖仓一体化架构,是对这两种模式优势的综合,为企业…
![[Oracle]高效的PL/SQL程序设计(四)--批量处理](http://images.csdn.net/syntaxhighlighting/OutliningIndicators/None.gif)
[Oracle]高效的PL/SQL程序设计(四)--批量处理
批量处理一般用在ETL操作, ETL代表提取(extract),转换(transform),装载(load), 是一个数据仓库的词汇!
类似于下面的结构: forx (select*from...)loop Process data; insertintotablevalues(...);endloop;一般情况下, 我们处理大笔的数据插入动作, 有2种做法…

大数据时代,商业智能BI的使用规则
商业智能BI的火热程度让很多不了解的企业也在内部部署了BI系统,怎么利用BI创造价值也就成了新的问题。
商业智能面向管理人员
很多人其实不理解,为什么说企业的管理人员想要完全了解企业的各项业务发展情况实际上是很困难的。
一家企业有这么多部门&a…
Hive-命令行CDH访问开启kerberos的hive
1.通过hive用户访问
切换用户为hive
[rootslave conf]# su - hive
上一次登录:五 4月 12 13:59:19 CST 2019pts/1 上
[hiveslave ~]$命令行直接输入hive就可以进入hive
[hiveslave ~]$ hive
log4j:WARN No such property [maxFileSize] in org.apache.log4j.Dail…
hive中如何将存在分隔符号的一列进行拆分,成为多行(可参考之前行转列,列转行笔记第三部分)
hive中如何将存在分隔符号的一列进行拆分,成为多行(可参考之前行转列,列转行笔记第三部分)
三、行转列 split()︰将一个字符串按照指定字符分割,结果为一个array explode():将一列复杂的array或者map拆分为多行,它的参…
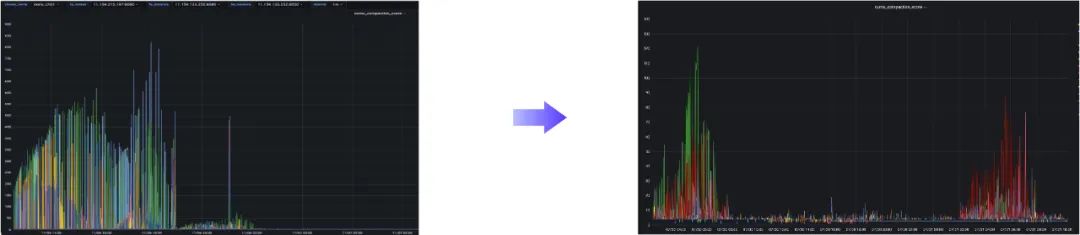
腾讯音乐如何基于大模型 + OLAP 构建智能数据服务平台
本文导读:
当前,大语言模型的应用正在全球范围内引发新一轮的技术革命与商业浪潮。腾讯音乐作为中国领先在线音乐娱乐平台,利用庞大用户群与多元场景的优势,持续探索大模型赛道的多元应用。本文将详细介绍腾讯音乐如何基于 Apach…
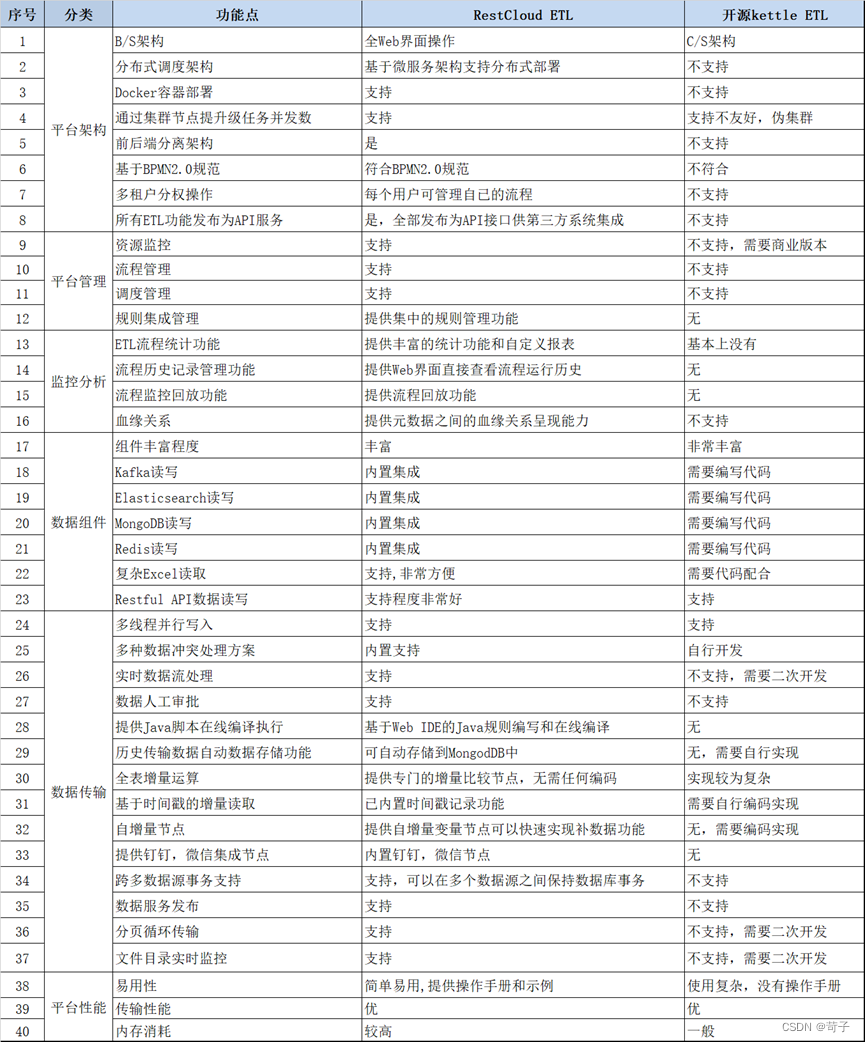
国产ETLCloud VS 开源Kettle ETL对比分析
ETLCloud VS Kettle
ETLCloud和kettle是目前国内使用最广泛的两款免费ETL工具,本文将从多个角色对ETLCloud和kettle进行对比,方便用户快速了解到两款产品的差异并根据自已的需求选择相应的工具。
ETLCloud提供了对kettle流程的迁移功能,所以…
ClickHouse进阶(五):副本与分片-1-副本与分片
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 📌订阅…
Hive 和 HDFS、MySQL 之间的关系
文章目录 HiveHDFSMySQL三者的关系 Hive、MySQL 和 HDFS 是三个不同的数据存储和处理系统,它们在大数据生态系统中扮演不同的角色,但可以协同工作以支持数据管理和分析任务。
Hive Hive 是一个基于 Hadoop 生态系统的数据仓库工具,用于管理和…
外贸erp软件条码管理解决方案,应对外贸客户变化多样性
在国际贸易市场下,仓库对于市场和企业之间是商品的流量和储存是必不可少的。其中,条形码在仓储物流中,主要的作用是对物料跟踪管理、建立完整的产品档案,保障仓储的稳定运行,利用仓储空间,提高服务质量。
…

大数据和数据要素有什么关系?
大数据与数据要素之间存在密切的关系。大数据是指海量、多样化、高速生成的数据,而数据要素是指构成数据的基本元素或属性。数据要素包括但不限于数据的类型、结构、格式、单位、精度等。
大数据的产生和应用离不开数据要素的支持。数据要素确定了数据的基本特征和…
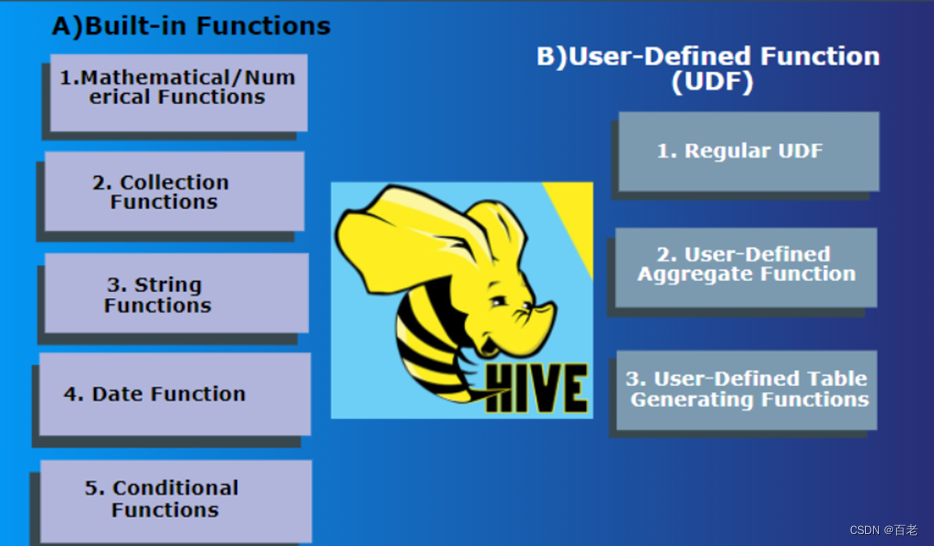
Hive内置函数字典
写在前面:HQL同SQL有很多的类似语法,同学熟悉SQL后一般学习起来非常轻松,写一篇文章列举常用函数,方便查找和学习。
1. 执行模式
1.1 Batch Mode 批处理模式
当使用-e或-f选项运行$ HIVE_HOME / bin / hive时,它将以…
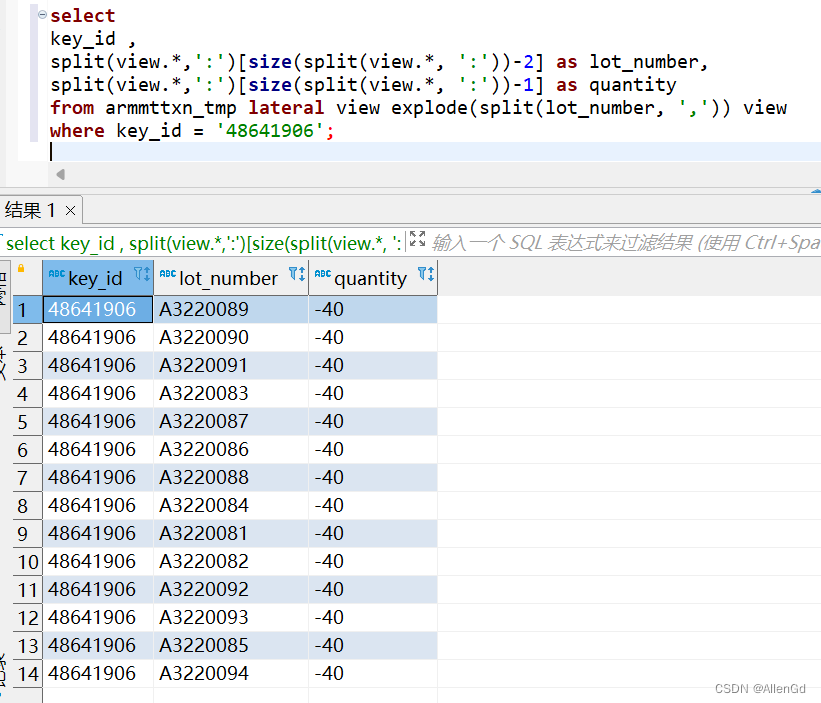
Hive一行拆分成多行/一列拆分成多列
场景:
hive有张表armmttxn_tmp,其中有一个字段lot_number,该字段以逗号分隔开多个值,每个值又以冒号来分割料号和数量,如:A3220089:-40,A3220090:-40,A3220091:-40,A3220083:-40,A3220087:-40,A3220086:-4…

【MySQL】MySQL安装与配置
前言:本篇我们来学习一个新的知识——数据库。对于数据库的学习,我们学习的是MySQL。MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,属于Oracle旗下产品,是最流行的关系型数据库管理系统之一。
看到这里的…
转 数据库设计中的14个技巧
下述十四个技巧,是许多人在大量的数据库分析与设计实践中,逐步总结出来的。对于这些经验的运用,读者不能生帮硬套,死记硬背,而要消化理解,实事求是,灵活掌握。并逐步做到:在应用中发…
Apache Hive2.1.1安装部署
转载请注明出处:http://blog.csdn.net/u012842205/article/details/71713842 一、Apache Hive简介
Apache Hive是基于Hadoop的一个数据仓库工具,用于使用SQL语法查询、读取、写入和管理大数据量的分布式数据结构。可以将结构化的数据文件映射为一张数据…
从呼叫中心通向CRM—数据仓库必不可少
从呼叫中心通向CRM—数据仓库必不可少
段云峰 杨凤年 宋俊德 2002/04/19 在呼叫中心业务系统收集到大量数据之后,要将这些信息进行有效利用,从而为CRM系统提供正确的依据,这个过程中,数据仓库是必不可少的要素。数据仓库是一项基…
CRM发展三个新动态
CRM发展三个新动态
2004/08/18 目前,CRM在银行、电信、保险等行业越来越多地得到应用。纵观国际CRM市场的发展趋势,结合近几年国内CRM的应用的状况,以下几点值得深思和探讨。 1.业务需求方面,企业将关注点越来越多…

智慧社区数字孪生IOC系统
智慧社区数字孪生IOC可汇聚综合态势、事件感知、监督指挥、决策分析、公共服务等功能,通过整合社区“人、地、事、物、组织”等全要素,实现辖区内人口、房屋、车辆、设施设备、突发事件、应急预案等信息及数据联动,实现“一张图”服务的360全…

redis 中 List类型介绍 及常用命令(附有示例)
目录
一、Redis List 列表
单键多值
特点:
二、常用命令
三、示例
lpush/rpush ...
lrange
lpop/rpop
rpoplpush
lindex llen
linsert before/after
lrem
lset 四、底层数据结构 一、Redis List 列表
单键多值
一个key 里面装着多个值…
redis中字符串(String)类型常见命令操作 (附有示例)
目录
一、redis中的常见数据结构
二、redis中字符串(String)介绍
三、常见命令
四、示例
set命令与get命令
setnx
append
strlen
incr
decr
incrby/decrby <步长>
mset ..
mget ... msetnx .... getrange <起始位置> <结束位置> setrang…
怎么搭建大数据平台,这个大数据平台方案值得学习
在大数据的时代,不仅仅是个人,企业的发展也离不开大数据。对于企业来说,一方面用户越来越多从线下转移到线上,用户的特点属性需要通过网络获取,企业需要依靠大数据把握市场变化并了解客户,从而提供满足市场…
Maxwell 概述、安装、数据同步【一篇搞定】!
文章目录 什么是 Maxwell?Maxwell 输出格式Maxwell 工作原理Maxwell 安装Maxwell 历史数据同步Maxwell 增量数据同步 什么是 Maxwell?
Maxwell 在大数据领域通常指的是一个用于数据同步和数据捕获的开源工具,由美国 Zendesk 开源,…
kafka 3.0 离线安装
1.安装zookeeper 解压apache-zookeeper-3.8.0-bin.tar.gz到指定目录,复制conf目录下zoo_sample.cfg到zoo.cfg,并修改配置。 # The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit…
Hive跨集群数据迁移过程
文章目录 环境数据迁移需求迁移过程记录 环境
Hive集群AHive集群B跳转机一台
数据迁移需求
本次迁移数据100G,15亿条,数据流转方向从集群A经过跳转机到集群B,通过HDFS拉取和重新建表导入的方式完成数据库迁移。
迁移过程记录
- 当前操作…
[hive] map
在 Hive 中,MAP 是一种复杂数据类型,用于表示键值对的集合。
它类似于其他编程语言中的字典、哈希表或关联数组。
你可以在 Hive 表中使用 MAP 类型的列,也可以在查询过程中创建和操作 MAP。
以下是一些关于在 Hive 中使用 MAP 的常见操作…

未来数字化转型发展的前景如何,企业又该怎么实现?
商业世界有一个认识,互联网只用看中国和美国,其他国家已经被远远甩在了后边,移动互联网的出现更是将互联网的跨地域、跨国、互联等属性发挥到了极致,让众多互联网巨头开启了争夺世界各国市场的脚步。
移动互联网的飞速发展以及物…

上新啦!请查收云原生虚拟数仓 PieCloudDB 十月动态
PieCloudDB Database 最新动态
PieCloudDB 压缩效率得到提升
为了节省存储空间,降低用户存储费用,PieCloudDB 在压缩率上不断优化,包括:
对 HLL(HyperLogLog)支持游程编码(Run Length Encodi…
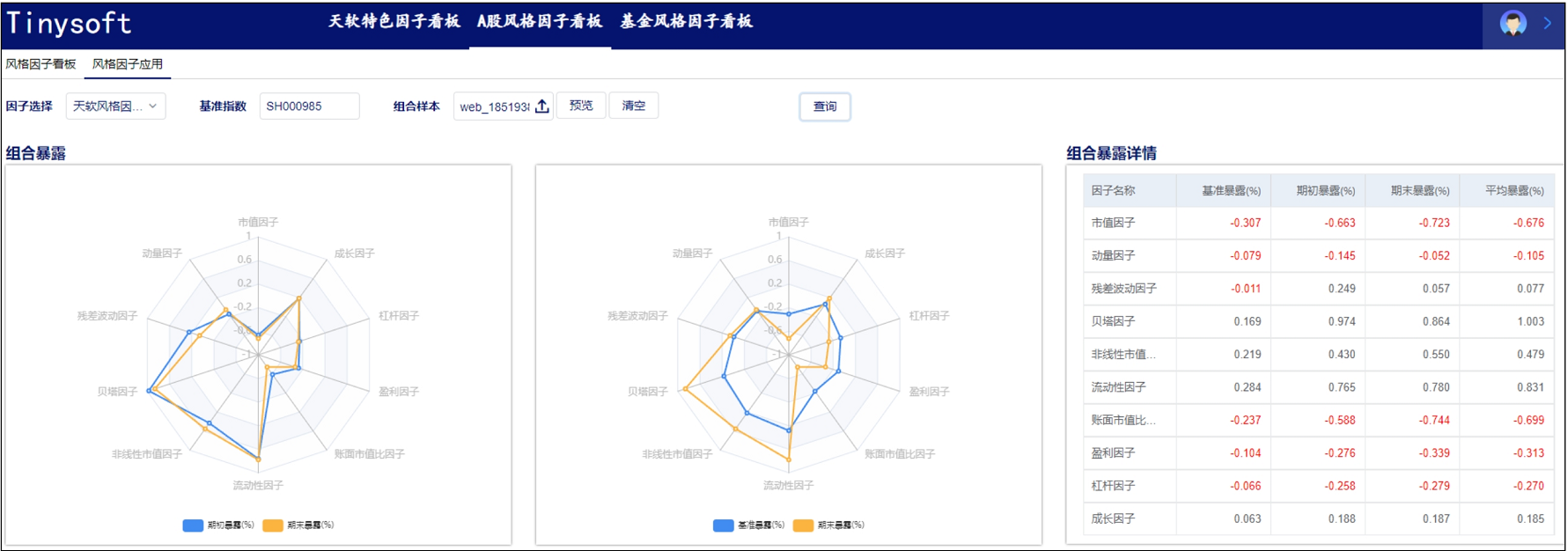
A股风格因子看板 (2023.09 第08期)
要点预告:10月,天软课堂将添加新主题--天软超高频行情数据。针对市场上高频行情数据处理业务的相关痛点,直观的在线演示如何通过天软高频数仓及高性能计算能力,将其逐个击破,期待各位老师的参会。请持续关注天软课堂动态ÿ…
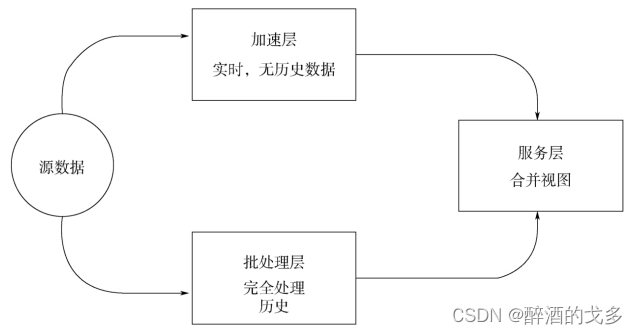
DAMA-DMBOK2重点知识整理CDGA/CDGP——第14章 大数据与数据科学
目录
一、分值分布
二、重点知识梳理
1、引言
1.1 业务驱动因素
1.2 原则
1.3 基本理念
2、活动
2.1 定义大数据战略和业务需求
2.2 选择数据源
2.3 获得和接收数据源
2.4 制定数据假设和方法
2.5 集成和调整数据进行分析
2.6 使用模型探索数据
2.7 部署和监控
…
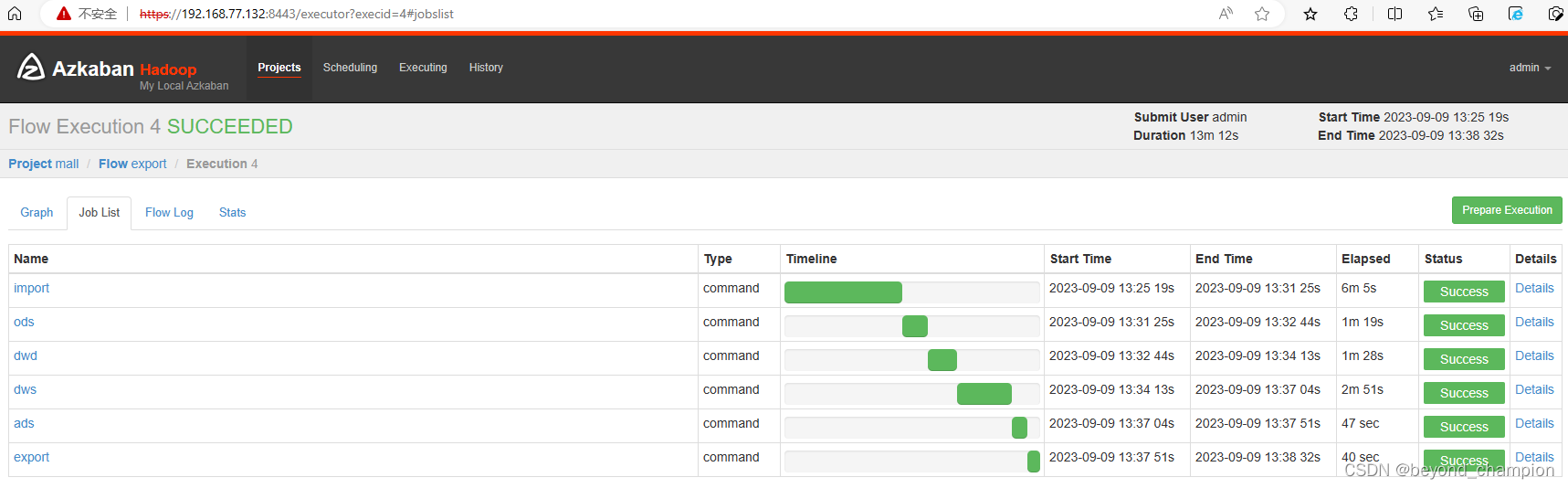
企业级数据仓库-数仓实战
数仓实战
安装包大小 安装清单 环境搭建 一、环境搭建01(机器准备)
准备好三台虚拟机,并进行修改hostname、在hosts文件增加ip地址和主机名映射 。
1、设置每个虚拟机的hostname
vi /etc/sysconfig/network
修改HOSTNAMEnode02修改hostna…

DataX 概述、部署、数据同步运用示例
文章目录 什么是 DataX?DataX 设计框架DataX 核心架构DataX 部署DataX 数据同步 MySQL —> HDFSDataX 数据同步 HDFS —> MySQLDataX 优化同步 MySQL 中 NULL 值数据到 HDFS 出现错误配置文件变量传参 什么是 DataX?
DataX 是阿里巴巴集团开源的、…

SNP Glue:SAP数据导入到其他系统的多种方式
SAP是一款功能强大的企业资源计划(ERP)软件,许多企业依赖SAP来管理和处理其核心业务数据。然而,有时候企业需要将SAP中的数据导入到其他系统中,以实现更广泛的数据共享和集成,便于企业实现数据智能。本文将…
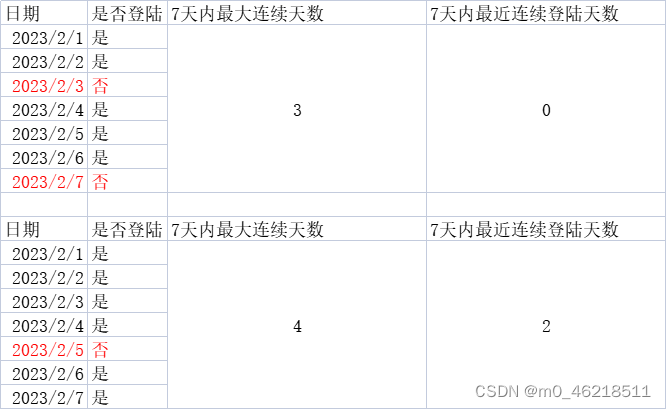
商业智能在中国企业的成熟应用,还需要以业务为核心。
商业智能的中外视角 ---商业智能在中国企业的成熟应用,还需要以业务为核心。 作者:程可 发布于:2009-7-20 10多年前,在美国过着安逸生活的朱宁在阿拉斯加滑雪,看到狗拖雪橇的教练在挑选狗时,所有狗都在竞争…

普通实时计算与实时数仓比较
离线数仓中为什么要分层?
普通实时计算与实时数仓比较
普通的实时计算优先考虑时效性,所以从数据源采集经过实时计算直接得到结果。如此 做时效性更好,但是弊端是由于计算过程中的中间结果没有沉淀下来,所以当面对大量实时 需求…
数据仓库系列 之Clickhouse中的更新和删除操作
测试数据
select count(*) from system.columns where tabletest_update;
select count(*) from test_update;具体删除&更新实现
语法 如下:
ALTER TABLE <table_name> DELETE WHERE <filter>;
ALTER TABLE <table_name> UPDATE col1 expr…
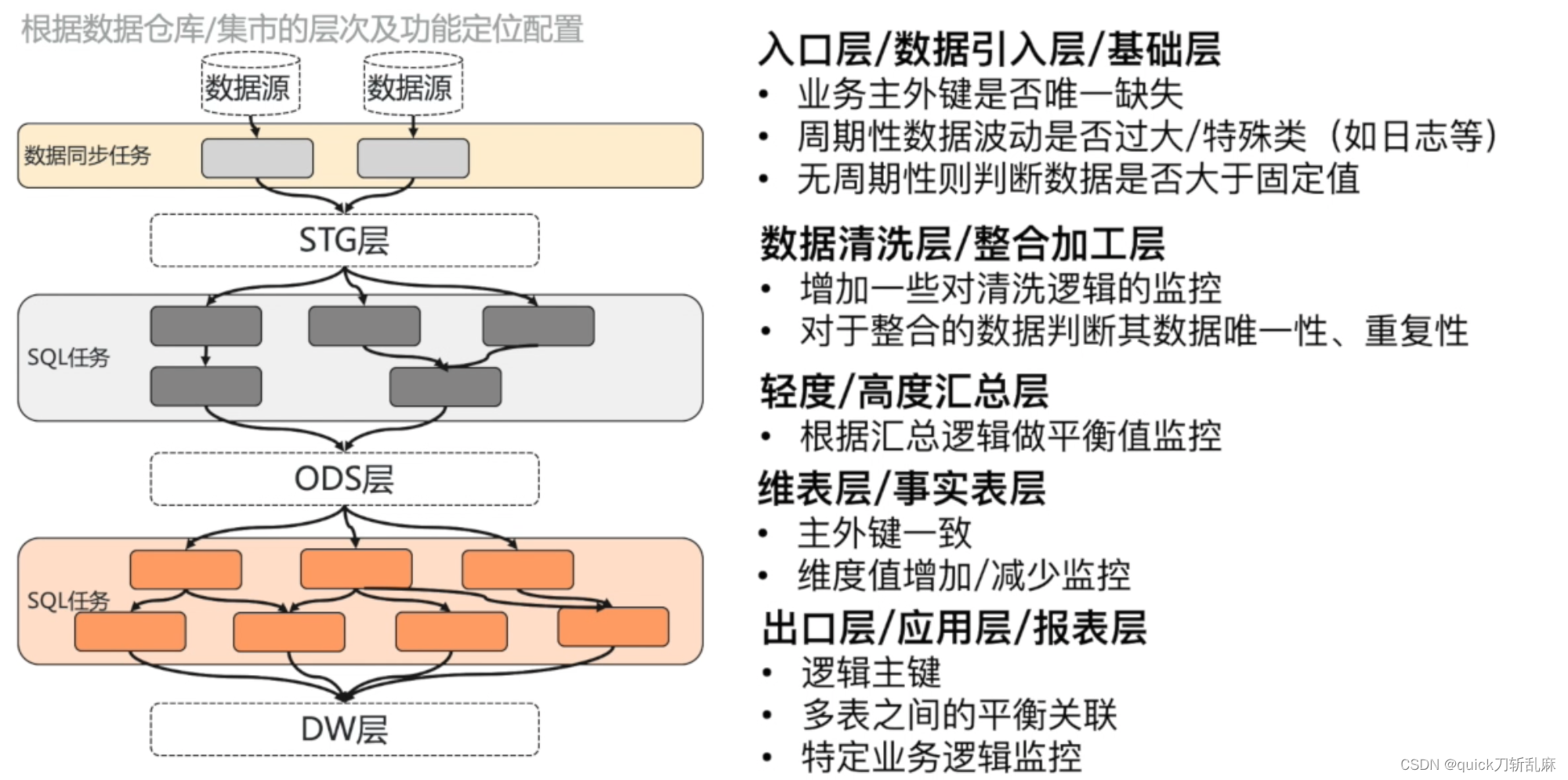

数据中台浅析(之二)
数据中台浅析
1. 引言
在当今的数字化时代,数据被誉为"新的石油",越来越多的企业和组织开始深度挖掘数据的价值。在这个过程中,数据中台逐渐成为了数据管理和分析的核心架构,让我们来深入了解一下它。
1.1 数据中台…
CDH 之 hive 升级至 hive-3.1.3 完美踩坑过程
一、准备工作
1.1 前言 这是博主在升级过程中遇到的问题记录,大家不一定遇到过,如果不是 CDH 平台的话,单是 hive 服务升级应该是不会有这些问题的,且升级前博主也参考过几篇相关 CDH 升级 hive 服务的博文,前面的升级…
hive实战使用文档(一)之hive on hbase知多少
hive对库表的常用命令
查看数据库 :
show database;切换数据库:
use database_name;查看所有的表:
show tables;查询表结构:
desc table_name;创建数据库:
create database database_name;删除数据库
drop database if exists database_name;
dro…
免费下载!调研6万家企业:《智能制造成熟度指数报告》发布
《“十四五”智能制造发展规划》明确提出,到2025年,70%的规模以上制造业企业基本实现数字化网络化,智能制造能力成熟度水平明显提升,并指出要建立长效评价机制,鼓励第三方机构开展智能制造能力成熟度评估,研…
SQL Server创建表和添加列
撰写时间:2022 年 4 月 27日 SQLServer创建表和添加列SQL Server创建表: 表用于在数据库中存储数据;表在数据库和模式中唯一命名。每个表包含一个或多个列。每列都有一个相关的数据类型,用于定义它可以存储的数据类型,…
Greenplum 6.0 版本官方最强解读
Pivotal Greenplum 6.0 已于2019年9月4日正式发布,可从Pivotal Network中下载。 十六年来,Greenplum始终致力于帮助企业更加高效地分析数据,使企业增加了收入,降低了成本,全面提升运营效率,展现了横向扩展的…

【第四届Apache HAWQ 技术研讨会PPT】Apache HAWQ 云端数据仓库架构演进
新年的第一个工作日,小编在这里给大家拜个年,狗年大吉!给大家准备的第一份新年礼物就是我们的HAWQ 干货PPT。在第四届Apache HAWQ 技术研讨会上,Pivotal 资深研发工程师翁岩青和我们的 研发工程师白洁做了《Apache HAWQ 云端数据…
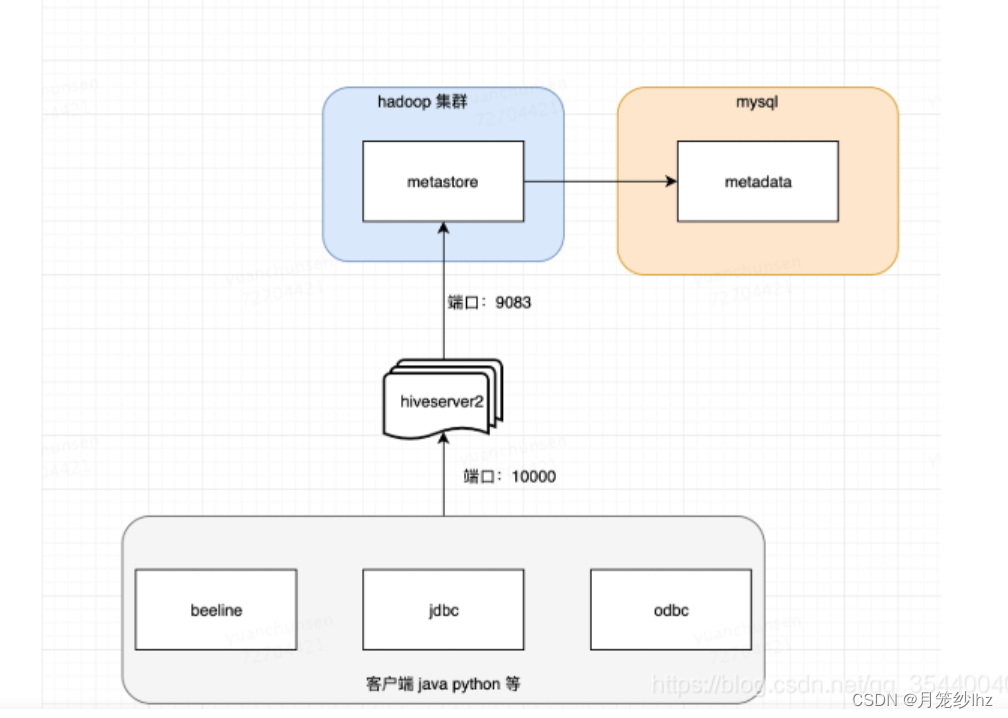
hive add columns 后查询不到新字段数据的问题
分区表add columns 查询不到新增字段数据的问题; 5.1元数据管理 (1)基本架构 Hive的2个重要组件:hiveService2 和metastore,一个负责转成MR进行执行,一个负责元数据服务管理 beeline-->hiveService2/spar…

驶向高效运营,StarRocks 助力蔚来汽车数据分析再升级
作者:蔚来汽车数字化业务发展部大数据团队
小编导读: 蔚来汽车是一家全球化的智能电动汽车公司,是高端智能汽车市场的先驱及领跑者。蔚来致力于通过提供高性能的智能电动汽车与极致用户体验,为用户创造愉悦的生活方式。 为了提升…
ClickHouse进阶(六):副本与分片-2-Distributed引擎
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 📌订阅…
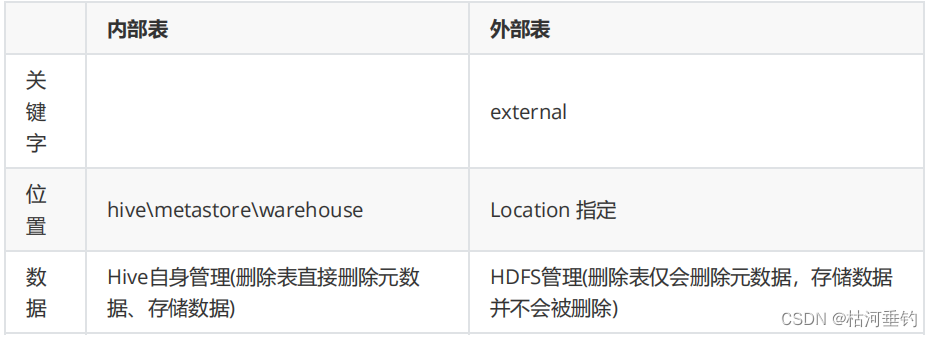
线上问诊:数仓开发(二)
系列文章目录
线上问诊:业务数据采集 线上问诊:数仓数据同步 线上问诊:数仓开发(一) 线上问诊:数仓开发(二) 文章目录 系列文章目录前言一、DWS1.最近1日汇总表1.交易域医院患者性别年龄段粒度问诊最近1日汇总表2.交易域医院患者…
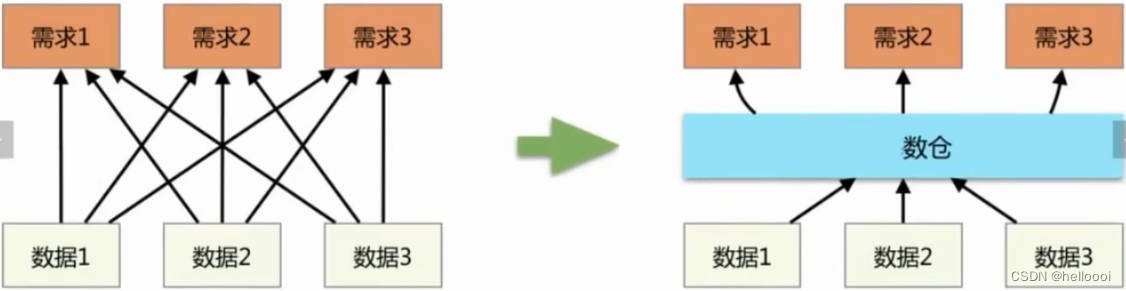
1. 企业大数据开发流程
文章目录 1. 数据建设流程1.1 业务需求(占40%)1.2 需求调研1.3 概要设计1.4 详细设计1.5 数据开发(占20%)1.6 数据交付 学习链接 1. 数据建设流程
即当我们接到一个新的需求后(需求文档),我们应…
流式数据湖平台HudiSQL DML
本文介绍SparkSQL提供的几个数据操作语言(DML)操作,用于与Hudi表交互。这些操作包括插入、更新、合并和删除Hudi表中的数据。 1.Insert Into 使用INSERT INTO语句使用Spark SQL将数据添加到Hudi表中。以下是一些示例: INSERT INTO <table> SELECT <columns> F…

【大数据】Doris 构建实时数仓落地方案详解(二):Doris 核心功能解读
Doris 构建实时数仓落地方案详解(二):Doris 核心功能解读 1.Doris 发展历程2.Doris 三大模型3.Doris 数据导入4.Doris 多表关联5.Doris 核心设计6.Doris 查询优化7.Doris 应对实时数仓的痛点 1.Doris 发展历程
Apache Doris 是由 百度 研发并…

Hive 表注释乱码解决
文章目录 出现原因MySQL 字符集修改调整元数据库字符集测试 出现原因
一般 Hive 的元数据信息都存储在 MySQL 中,但 MySQL 数据库中的 character_set_server 和 character_set_database 参数,默认都为 latin1 字符集,这两个参数决定了服务器…
Hive【Hive(四)函数-单行函数】
函数
函数简介
方便完成我们一些复杂的操作,就好像我们 Spark 中的 UDF 函数,避免用户反复写逻辑。
Hive 提供了大量的内置函数,主要可以分为以下几类:
单行函数聚合函数炸裂函数窗口函数
下面的命令可以查看内置函数的相关…
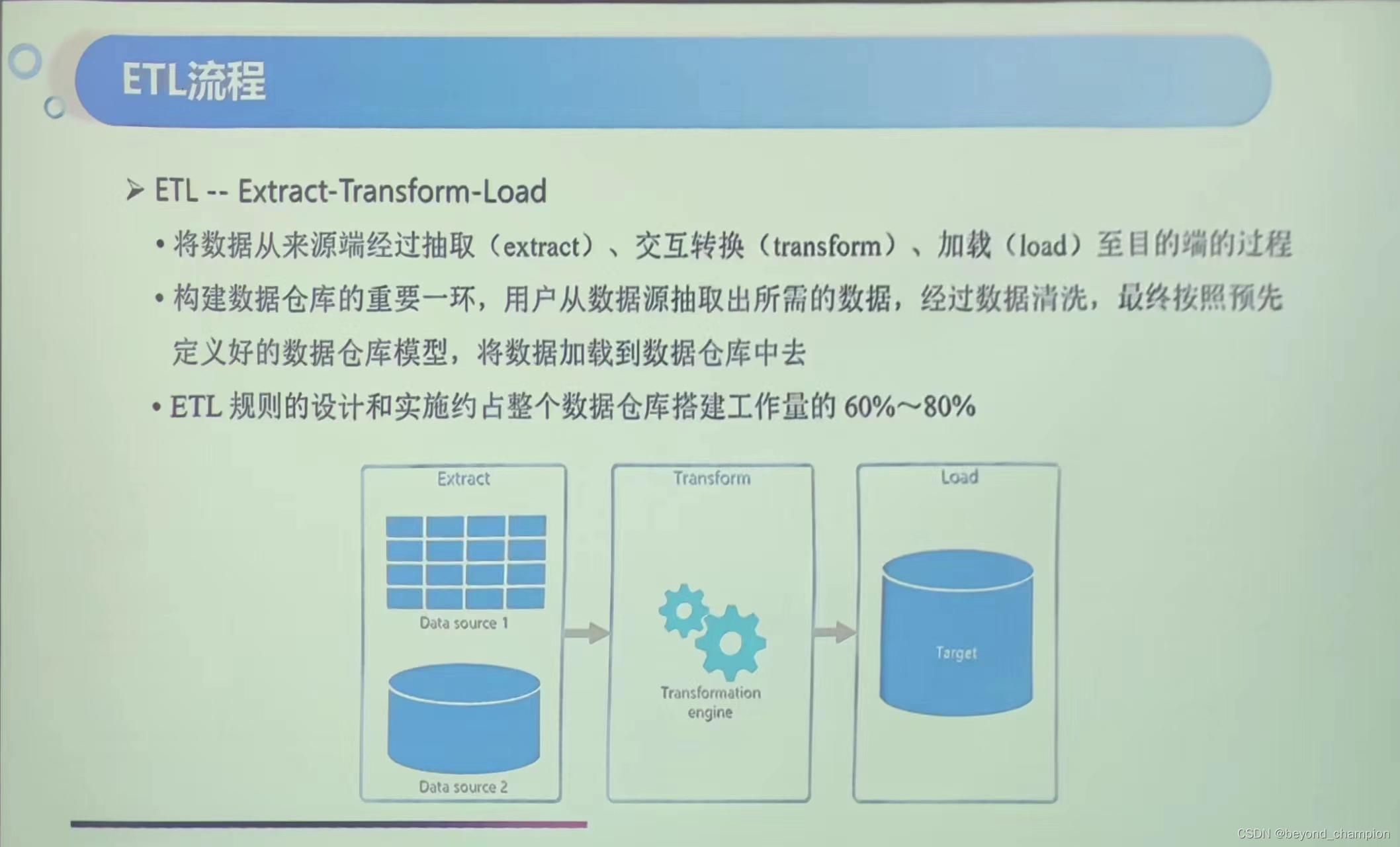
企业级数据仓库-理论知识
D3 AM 大数据中间件
Hive:将SQL转化成分布式Map/Reduce进行运算,也支持转换成Spark,需要单独安装Hive集群才能访问Spark,支持60%的SQL,延迟比较大。SparkSQL:属于Spark生态圈,Hive on Sqark。HBase: NoSQL,高并发读,适…
线上问诊:数仓开发(三)
系列文章目录
线上问诊:业务数据采集 线上问诊:数仓数据同步 线上问诊:数仓开发(一) 线上问诊:数仓开发(二) 线上问诊:数仓开发(三) 文章目录 系列文章目录前言一、ADS1.交易主题1.交易综合统计2.各医院交易统计3.各性…
java面试题(14):Oracle中truncate和delete的区别
(1)Truncate 是DDL 语句,DELETE 是DML语句。
(2)Truncate 的速度远快于DELETE。当执行DELETE操作时所有表数据先被COPY到回滚表空间,数据量不同花费时间长短不一。而TRUNCATE 是直接删除数据,不…

【活动注册】第四届Apache HAWQ技术研讨会
Apache HAWQ是一个完整兼容ANSI-SQL标准的高性能原生Hadoop MPP分析型数据库。提供对Hadoop上PB级数据的高性能交互式查询能力。并且提供对主要BI工具的描述性分析支持,以及支持预测型分析的机器学习库。 为了提供一个可以让大家相互学习交流的平台,我们…
什么是Oracle的物化视图
什么是Oracle的物化视图 物化视图看成是, 一个定时运行的计算JOB一个存计算结果的表 物化视图 实质上就是表 只不过会定时刷新 物化视图是包括一个查询结果的数据库对像,它可以说是远程数据的的本地副本,或者用来生成基于数据表求和的汇总表。物化视…
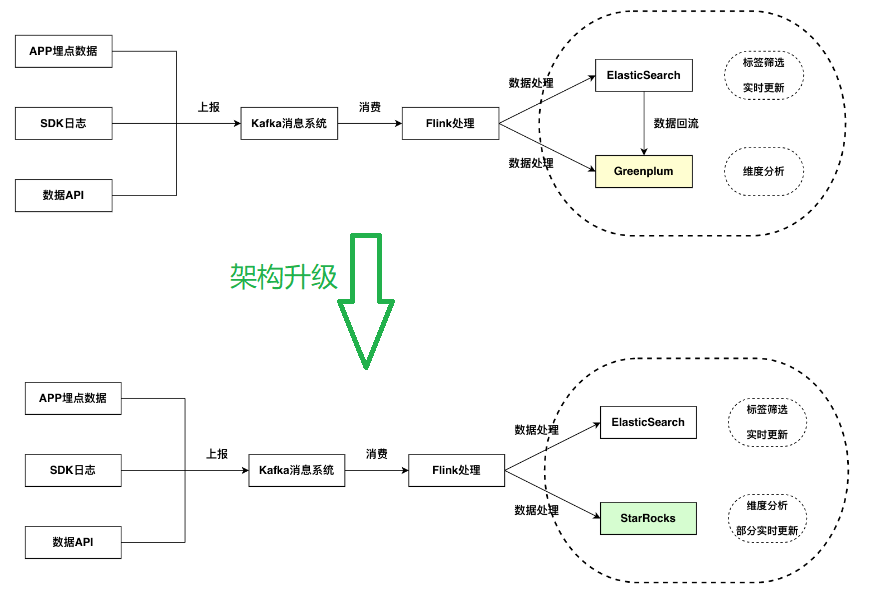
数据仓库系列:StarRocks 入门培训教程
文章目录 1. 什么是StarRocks?1.1. 适用场景1.2. [产品特性](https://docs.starrocks.io/zh-cn/latest/introduction/Features) 2. 系统架构2.1. 系统架构2.1.1. 整体架构2.1.2. 高可用实现方式 2.2. 数据如何管理? 3. 表模型3.1. 明细模型3.2. 聚合模型3.3. 更新模…

如何创建一个Sencha Touch 2应用_笔记本案例(第二部分)
这篇文章很好,包括5部分,但在网上只找到了第一部分的中文版,只有自己一点一点翻译。本人英语不好,所以将原文也贴上来,翻译不通顺的地方请大家参考。 In this second part of the tutorial on how to build a Sencha T…

数据中台之底表驱动开发
数据中台组成
数仓设计中心
按照主题域、业务过程,分层的设计方式,以维度建模作为基本理论依据,按照维度、度量设计模型,确保模型、字段有统一的命名规范。 数据资产中心
梳理数据资产,基于数据血缘,数据的访问热度,做成本的治理 数据质量中心
通过丰富的数据质量监…

大数据平台层级架构图
主流数据平台架构 一般包含三个层级,ODS层、数据仓库层、数据应用层。 业务系统的操作和日志数据抽取到ODS层,ODS的数据经过ETL过程(抽取Extraction,转化Transformation,加载Loading)进入数据仓库ÿ…
复方药物配伍的复杂网络方法研究
http://journal.shouxi.net/html/qikan/zgyx/zgzyyxxzz/2008111511/zyyxxx/20100118091432206_502404.html 【关键词】 复杂网络;中药复方配伍;核心处方配伍结构 方剂是中医临床治疗疾病的主要手段,是在辨证、立法的基础上选药配伍而成的。在辨证确定病…
RFID数据是如何从制造车间通往零售供应链的呢?
在一份数据流的“路线图”上,加密在RFID标签里的数据将经过漫长但路线清晰的旅途,在一个比针头还小的芯片里,穿行数千英里,从制造商的仓库到达零售商的配送中心。但是,当数据在各种中间件以及最终将使这些 数据在零售供…
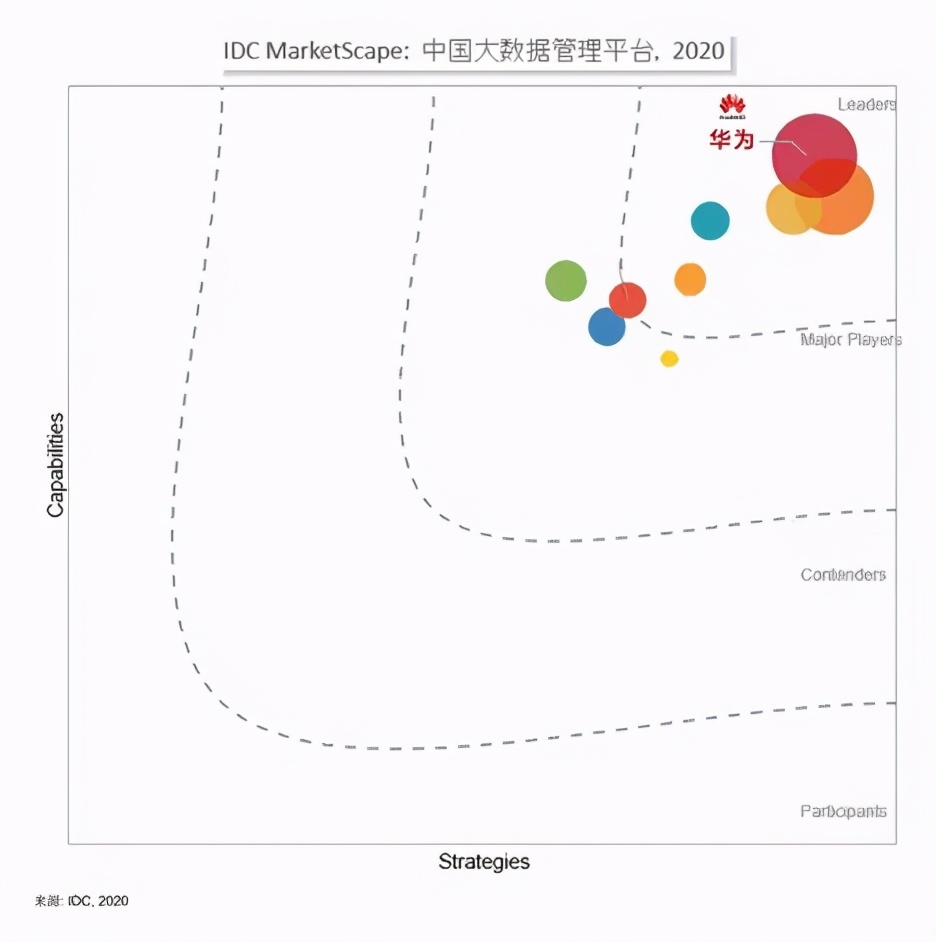
数据要素如何发挥价值,华为云展现新思路
“五年前,我很多客户的平均数据量大约为10TB,以ERP、CRM等数据为主;今天,客户的数据量达到PB级已成新常态,像零售、金融等行业,除了ERP、CRM这些结构化数据之外,还有大量各种行为/社交数据&…
释放数据价值,华为云的大数据之道
如果说石油定义了二十世纪,那么数据正在迅速改变着二十一世纪。尤其是数字化以前所未有的步伐前进,数据正在成为整个社会运转的基础。正如舍恩伯格在《大数据时代》中提到,大数据带来的信息风暴正在变革我们的生活、工作和思维,大…

Facebook 2022 将尸骨无存?
社交网络最红的时候,很多人预言搜索引擎广告要灭亡了,间接宣告Google该让位了;但现在 Google 积极转型,进军硬件已无大碍,Facebook却因为移动化问题开始提早出现衰落迹象,末日论也就接踵而来。Facebook不会…
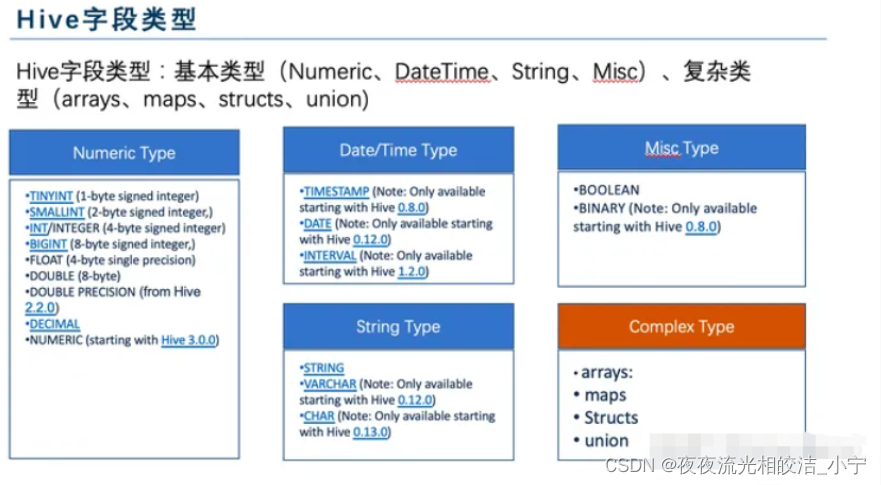
Hive 数据仓库介绍
目录
编辑
一、Hive 概述
1.1 Hive产生的原因
1.2 Hive是什么?
1.3 Hive 特点
1.4 Hive生态链关系
二、Hive架构
2.1 架构图
2.2 架构组件说明
2.2.1 Interface
2.2.1.1 CLI
2.2.1.2 JDBC/ODBC
2.2.1.3 WebUI
2.2.2 MetaData
2.2.3 MetaStore
2.2…
异地容灾系统和数据仓库中数据同步的设计软件的功能模型
( 1)初始同步模块 该模块主要是在表进行初始同步时使用的;它能够根据实际需要生成物化视图 及其索引的创建语句,并完成表的初始同步。如果没有特别的要求,则调用普通初 始同步子模块进行目的端表的初始同步ÿ…
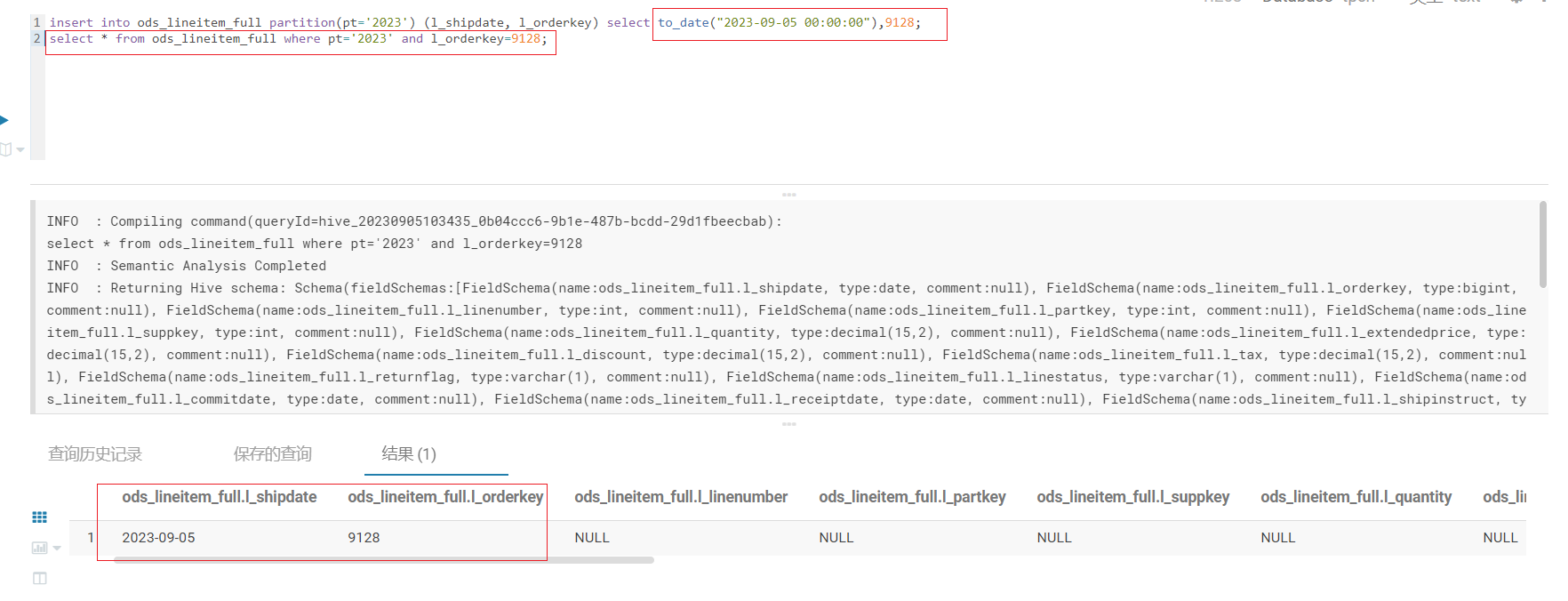
hive指定字段插入数据,包含了分区表和非分区表
1、建表
语句如下:
CREATE EXTERNAL TABLE ods_lineitem_full
(l_shipdate date,l_orderkey bigint,l_linenumber int,l_partkey int,l_suppkey int,l_quantity decimal(15, 2),l_extendedprice decimal(15, 2),l_discount de…

【Hive SQL 每日一题】统计用户连续下单的日期区间
文章目录 测试数据需求说明需求实现 测试数据
create table test(user_id string,order_date string);INSERT INTO test(user_id, order_date) VALUES(101, 2021-09-21),(101, 2021-09-22),(101, 2021-09-23),(101, 2021-09-27),(101, 2021-09-28),(101, 2021-09-29),(101, 20…
API接口与电商平台之间的联系,采集京东平台数据按关键字搜索商品接口示例
关键字搜索商品的重要性:
1.引入精准流量
关键词第一个也是最重要的作用就是为我们宝贝引进精准的流量,这一作用无论是在自然搜索中还是直通车中都是一样的。
第一步关乎的是我们宝贝的展现,而第二步用户是否会点进我们的宝贝,…
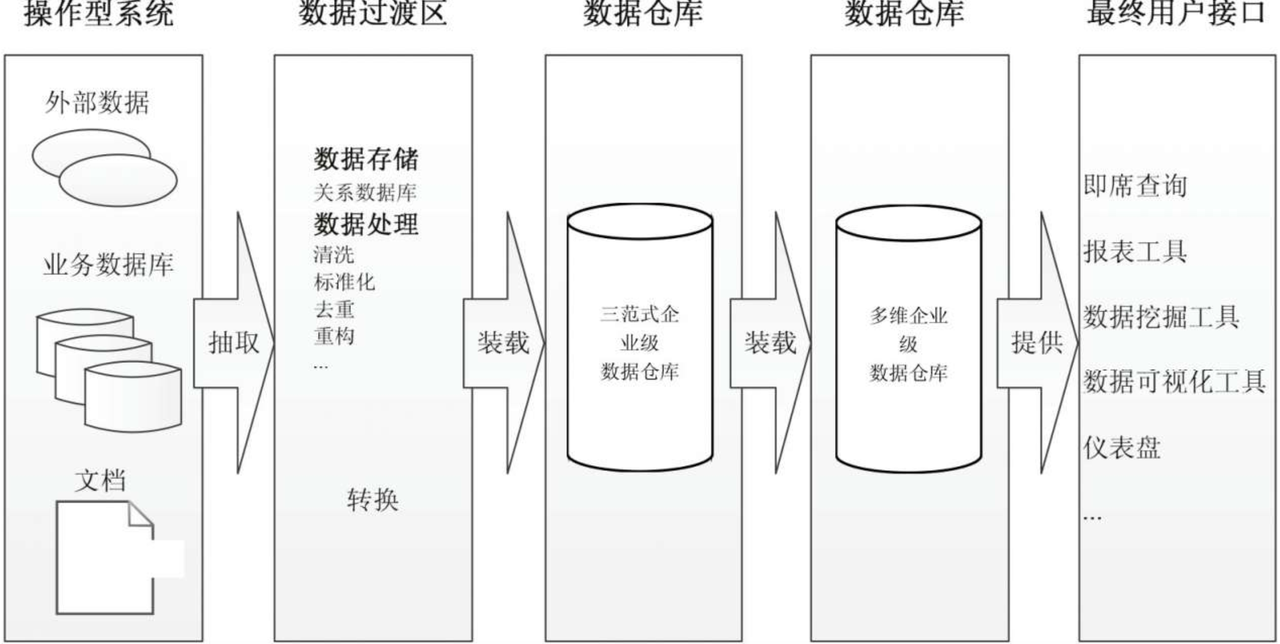
【数据仓库基础(二)】数据仓库架构
文章目录 一. 基本架构二. 主要数据仓库架构1. 数据集市架构1.1. 独立数据集市1.2. 从属数据集市1.3. Inmon企业信息工厂架构 2. Kimball数据仓库架构3. 混合型数据仓库架构 三. 操作数据存储(ODS) 一. 基本架构 架构是指系统的一个或多个结构。结构中包…

ETL增量抽取模式实践与调优
在ETL(Extract, Transform, Load)流程中,增量抽取是一种重要的数据提取方式,允许从源系统中仅提取发生变化的数据,以提高处理效率和减少资源消耗。增量抽取模式有多种实现方式,包括时间戳增量、增量标记和增…
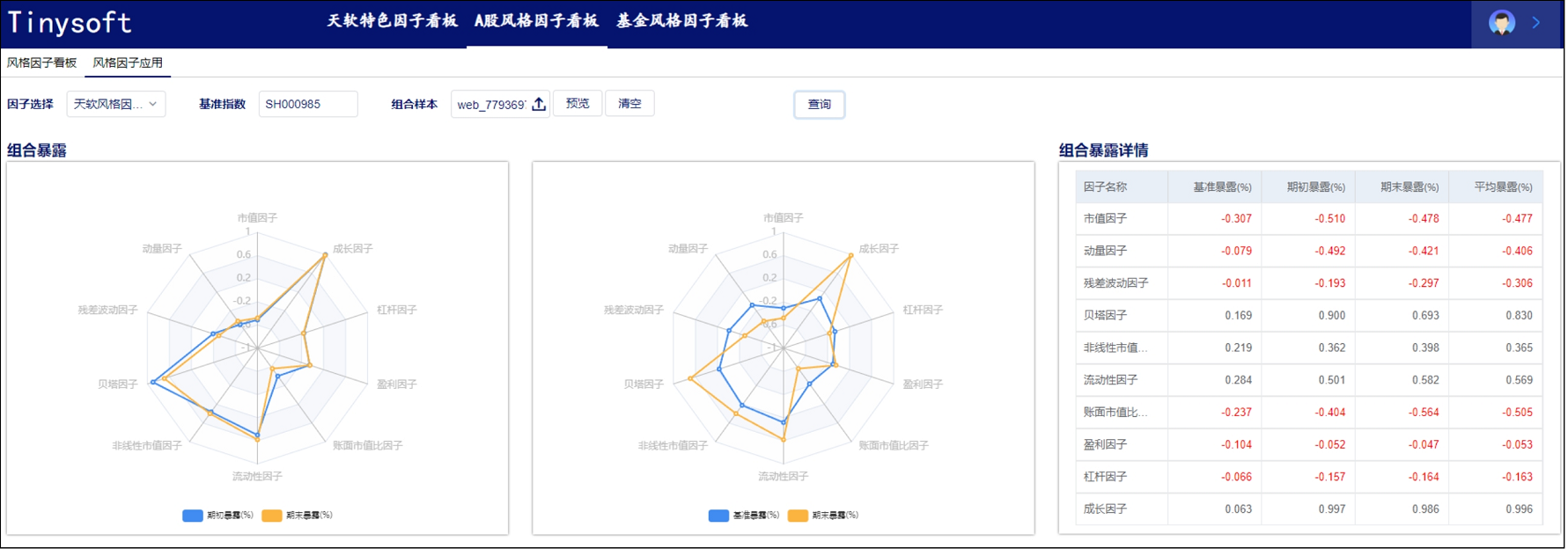
A股风格因子看板 (2023.09 第07期)
该因子看板跟踪A股风格因子,该因子主要解释沪深两市的市场收益、刻画市场风格趋势的系列风格因子,用以分析市场风格切换、组合风格景露等。 今日为该因子跟踪第7期,指数组合数据截止日2023-08-31,要点如下 近1年A股风格因子收益走…
TiDB基础介绍、应用场景及架构
1. 什么是newsql NewSQL 是对各种新的可扩展/高性能数据库的简称,这类数据库不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL等特性。 NewSQL是指这样一类新式的关系型数据库管理系统,针对OLTP(读-写&…

经验分享:企业数据仓库建设方案总结!
导读
在企业的数字化转型浪潮中,数据被誉为“新时代的石油”,而数据仓库作为数据管理与分析的核心基础设施,在企业的信息化建设中扮演着重要的角色。本文将深入探讨企业数据仓库建设过程中所遇到的问题以及解决经验,为正在筹备或…
零售行业供应链管理核心KPI指标(三)
完美订单满足率和退货率
完美订单满足率有三个方面的因素影响:订单按时、足量、无损交货。通常情况下零售企业追求线上订单履行周期慢慢达到行业平均水平,就是交付的速度变快了,这个肯定是一件好事情,趋势越来越好。
同时&#…
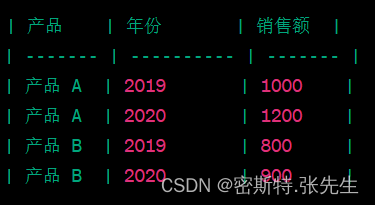
数据治理-选择DMM框架标准
选择DMM框架时,应考虑以下标准:
易用性。实践活动是以非技术性术语来描述的,它传达了活动的功能本质;全面性。该框架涉及到广泛的数据管理活动,包括业务参与,而不仅仅是IT过程;可扩展性和灵活性…
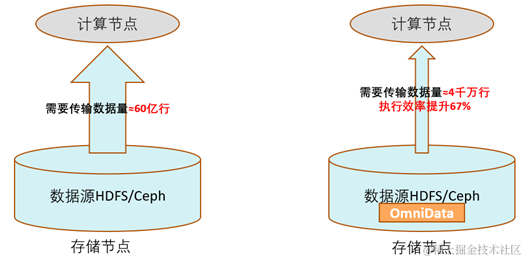
【创新项目探索】大数据服务omnidata-hive-connector介绍
omnidata-hive-connector介绍
omnidata-hive-connector是一种将大数据组件Hive的算子下推到存储节点上的服务,从而实现近数据计算,减少网络带宽,提升Hive的查询性能。目前支持Hive on Tez。omnidata-hive-connector已在openEuler社区开源。 …

解锁学习新方式——助您迈向成功之路
近年来,随着吉林开放大学广播电视大学的崛起,越来越多的学子选择这所优秀的学府来实现自己的梦想。而作为一名学者,我有幸见证了电大搜题微信公众号的诞生,为广大学子提供了一个全新的学习支持平台。 电大搜题微信公众号ÿ…
hive分区表的元数据信息numRows显示为0
创建分区表
CREATE TABLE `dept_partition`(`deptno` int, `dname` string, `loc` string)
PARTITIONED BY (
Hive中窗口函数的基本语法和示例
Hive是一个基于Hadoop的数据仓库解决方案,它允许你执行SQL查询和分析大规模数据集。Hive支持窗口函数,用于在查询中执行各种分析操作,例如排名、累积、分组和聚合,以及许多其他分析任务。窗口函数使你能够在查询结果集的特定窗口&…
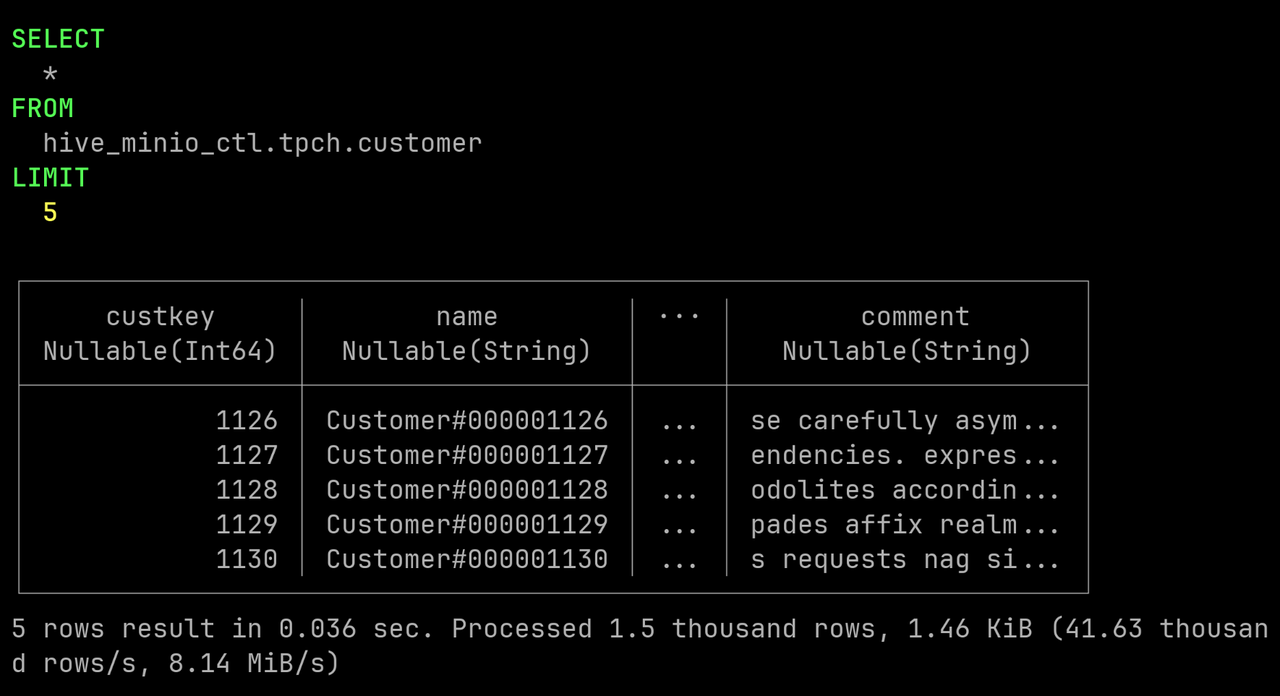
使用 Databend 加速 Hive 查询
作者:尚卓燃(PsiACE) 澳门科技大学在读硕士,Databend 研发工程师实习生 Apache OpenDAL(Incubating) Committer PsiACE (Chojan Shang) GitHub 随着架构的不断迭代和更新,大数据系统的查询目标也从大吞吐量查询逐步转…
Hive中Join优化的几种算法
文章目录 1. Common Join2. Map Join3. Bucket Map Join4. Sort Merge Bucket Map Join ( SMB Map Join ) 1. Common Join
Common Join 是最稳定且默认的Join算法,通过 MR Job 完成 Join 。
需要注意的是,在三个表的 Join 关联中…
流式数据湖平台Hudi核心概念三:索引
1.索引 Hudi通过索引机制将给定的hoodie key(record key+分区路径)映射到文件id,实现了高效的upstart。一旦将记录的第一个版本写入文件,record key和文件组/文件id之间的映射就永远不会改变。简而言之,映射的文件组包含一组记录的所有版本。 对于Copy-On-Write表,可以实…

数据仓库的基本概述之扫盲系列
数据仓库的诞生原因
随着互联网的普及,信息技术已经深入到各行各业,并逐步融入到企业的日常运营中。然而,当前企业在信息化建设过程中遇到了一些困境与挑战。
1、历史数据积存。
过去企业的业务系统往往是在较长时间内建设的,很…

数据仓库Hive(林子雨课程慕课)
文章目录 9.数据仓库Hive9.1 数据仓库的概念9.2 Hive简介9.3 SQL语句转换为MapReduce作业的基本原理9.4 Impla9.4.1 Impala简介9.4.2 Impala系统架构9.4.3 Impala查询执行过程9.4.4 Impala与Hive的比较 9.5 Hive的安装和基本操作9.5.1 Hive安装9.5.2 Hive基本操作 9.数据仓库Hi…
ClickHouse进阶(十三):Clickhouse数据字典-3-文件数据源及Mysql数据源
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_大数据OLAP体系技术栈,Apache Doris,Kerberos安全认证-CSDN博客 📌订阅…
Windows下DataGrip连接Hive
DataGrip连接Hive 1. 启动Hadoop2. 启动hiveserver2服务3. 启动元数据服务4. 启动DG 1. 启动Hadoop 在控制台中输入start-all.cmd后,弹出下图4个终端(注意终端的名字)2. 启动hiveserver2服务
单独开一个窗口启动hiveserver2服务,…

ClickHouse(二十三):Java Spark读写ClickHouse API
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…
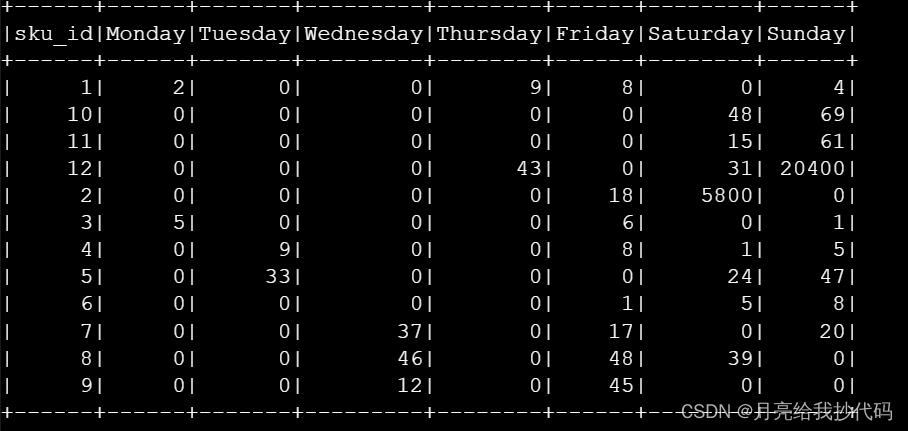
Hive Cli / HiveServer2 中使用 dayofweek 函数引发的BUG!
文章目录 前言dayofweek 函数官方说明BUG 重现Spark SQL 中的使用总结 前言
使用的集群环境为:
hive 3.1.2spark 3.0.2
dayofweek 函数官方说明
dayofweek(date) - Returns the day of the week for date/timestamp (1 Sunday, 2 Monday, …, 7 Saturday).
…

hive 动态分区-动态分区数量太多也会导致效率下降只设置非严格模式也能执行动态分区
hive 动态分区-动态分区数量太多也会导致效率下降&只设置非严格模式也能执行动态分区
结论
在非严格模式下不开启动态分区的功能的参数(配置如下),同样也能进行动态分区数据写入,目测原因是不严格检查SQL中是否指定分区或者…
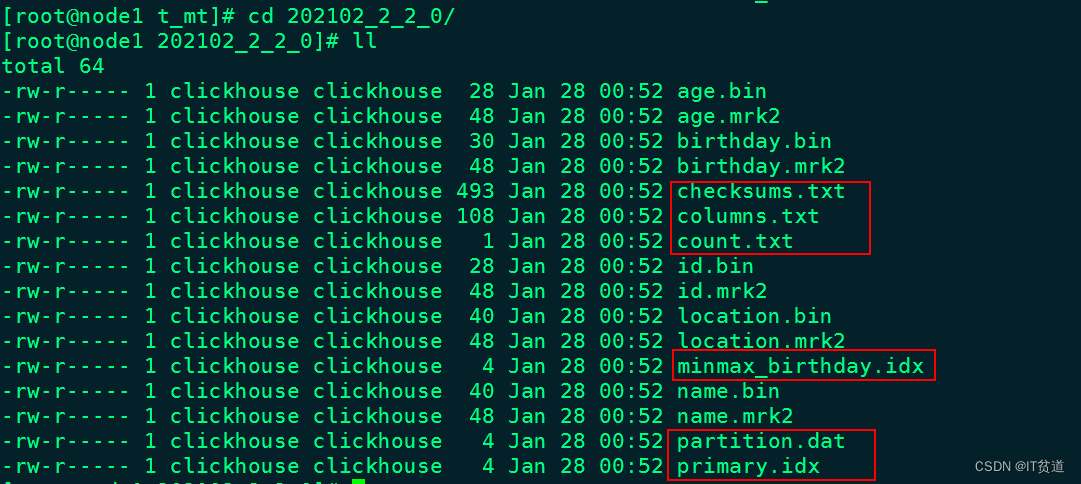
ClickHouse进阶(二):ClickHouse MergeTree表引擎及目录解析
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…

中秋佳节至,ONES 祝你万事圆满!
丹桂飘香,月满中秋!感谢大家一直以来对 ONES 的认可与支持,祝大家中秋快乐,万事圆满!「2022年9月10日 ~ 2022年9月12日」中秋假期期间,ONES 的值班人员将一如既往为您提供服务 :紧急问题若有…
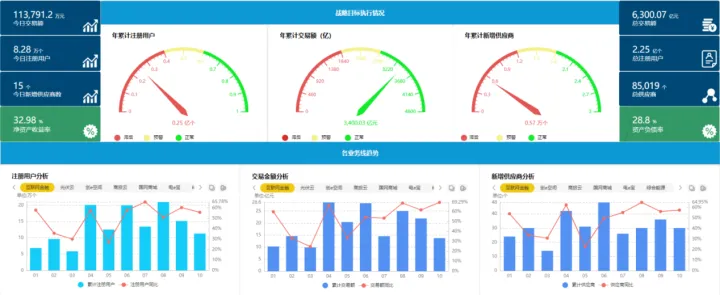
企业中商业智能BI,常见的工具和技术
商业智能(Business Intelligence,简称BI)数据可视化是通过使用图表、图形和其他可视化工具来呈现和解释商业数据的过程。它旨在帮助组织更好地理解和分析他们的数据,从而做出更明智的商业决策。
常见的商业智能数据可视化工具和技…
Hive无法启动的解决方案
关掉虚拟机后,重新启动后,按照Hadoop和Hive的流程重新启动,发现无法启动成功,特别是元数据服务无法启动,出现以下错误: Exception in thread “main” java.lang.RuntimeException: java.net.ConnectException: Call F…

Servlet的使用(JavaEE初阶系列17)
目录
前言:
1.Servlet API的使用
1.1HttpServlet
1.2HttpServletRequest
1.3HttpServletResponse
2.表白墙的更新
2.1表白墙存在的问题
2.2前后端交互接口
2.3环境准备
2.4代码的编写
2.5数据的持久化
2.5.1引入JDBC依赖
2.5.2创建数据库
2.5.3编写数…
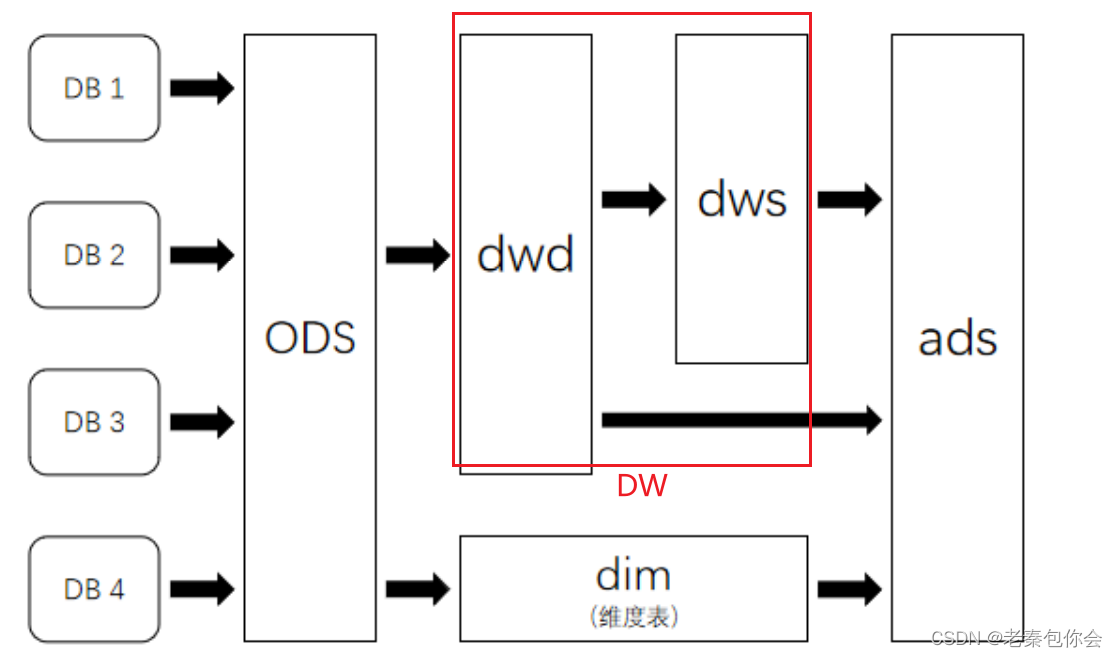
数仓--------简单了解
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…
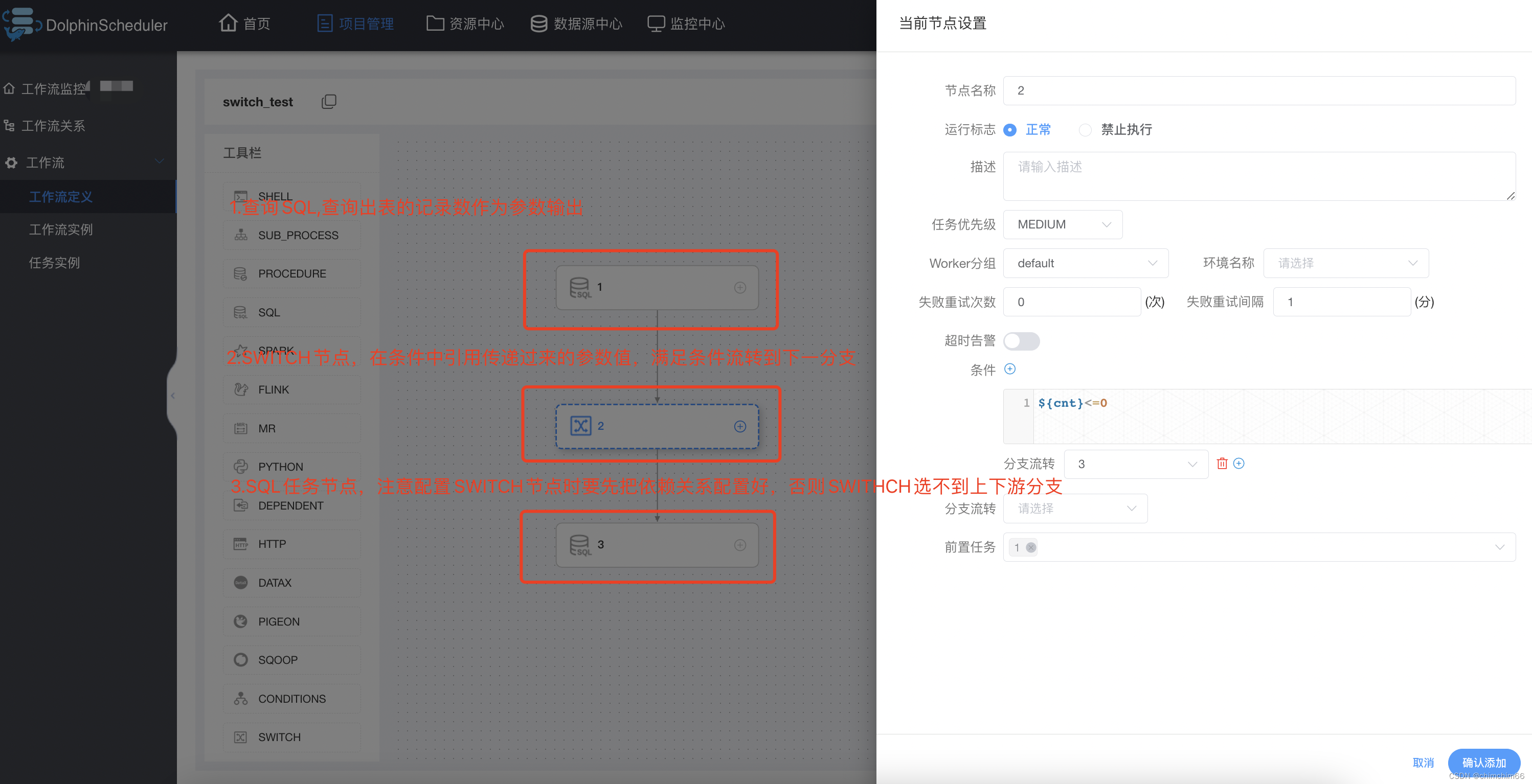
dolphinscheduler的switch组件
目录
一、背景
switch组件官方文档
Switch简介
创建任务
任务参数
二、实操DEMO
SQL任务switch判断DEMO
第一步:新建SQL任务,配置好参数
第二步: 定义SWITCH节点
三、参考资料
默认任务参数 一、背景
Apache DolphinScheduler 是…
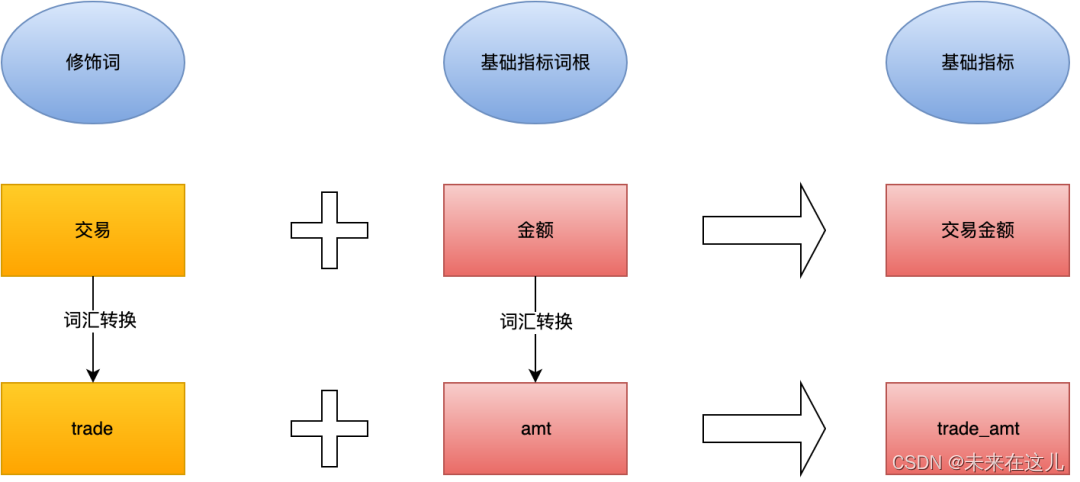
铸坯火焰自动切割系统的设计状况及存在的问题
我国的切割技术长期落后与其他国家,然而近些年来有了快速发展。相关企业包 括生产切割器械的企业在内,已经研制以及开发了多种半、全自动切割器械。国外的 很多著名切割机制造企业,如美国捷锐、德国伊萨、日本田中和梅塞尔等公司࿰…
Hadoop分布式计算框架-MapReduce
本文所有代码链接:https://download.csdn.net/download/shangjg03/88437313 1.MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。 MapReduce 作业通过将输入的数据集拆分为独…

项目知识点总结-过滤器-MD5注册-邮箱登录
(1)过滤器
使用过滤器验证用户是否登录
/**
* Title: NoLoginFilter.java
* Package com.qfedu.web.filter
* Description: TODO(用一句话描述该文件做什么)
* author Feri
* date 2018年5月28日
* version V1.0
*/
package com.gdsdx…

云数据仓库实践:AWS Redshift在大数据储存分析上的落地经验分享
🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月CSDN上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师…
hive字段关键字问题处理
最近在xxl_job部署shell调度任务时,发现在编写Hql时,对一些使用关键字命名的字段无法解析,按开发规范,字段命名不应该有关键字,但是数据来源是第三方,无法修改,需要通过flume对从kafka的数据到hdfs上,数据是json格式,所以需要对关…

CentOS7安装部署CDH6.2.1
文章目录 CentOS7安装部署CDH6.2.1一、前言1.简介2.架构3.环境 二、环境准备1.部署服务器2.安装包准备3.修改机器名4.关闭防火墙5.关闭 SELinux6.Hosts文件7.limits文件8.设置swap空间9.关闭透明巨页内存10.免密登录 三、安装CM管理端1.安装第三方依赖包2.安装Oracle的JDK3.安装…
ETL工具Kettle
1 Kettle的基本概念
一个数据抽取过程,主要包括创建一个作业(Job),每个作业由一个或多个作业项(Job Entry)和连接作业项的作业跳(Job Hop)组成。每个作业项可以是一个转换ÿ…

Hive On Spark 概述、安装配置、计算引擎更换、应用、异常解决
文章目录 Hadoop 安装Hive 安装Hive On Spark 与 Spark On Hive 区别Hive On SparkSpark On Hive 部署 Hive On Spark查询 Hive 对应的 Spark 版本号下载 Spark解压 Spark配置环境变量指定 Hadoop 路径在 Hive 配置 Spark 参数上传 Jar 包并更换引擎 测试 Hive On Spark解决依赖…

【漏洞复现】CNVD-2023-08743
【漏洞复现】
CNVD-2023-08743
【漏洞介绍】
Hongjing Human Resource Management System - SQL Injection
【指纹】
title”人力资源信息管理系统”
【系统UI】 【payload】
/servlet/codesettree?flagc&status1&codesetid1&parentid-1&categories~31…
Doris表的动态分区
动态分区是在Doris 0.12版本中引入的新功能。旨在对表级别的分区实现生命周期管理(TTL),减少用户的使用负担。 目前实现了动态添加分区及动态删除分区的功能。动态分区只支持Range分区。 1 原理 在某些使用场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时…
Doris的分区表和分桶表
1 列定义 以AGGREGATE KEY数据模型为例进行说明。更多数据模型参阅Doris数据模型。 列的基本类型,可以通过在mysql-client中执行HELP CREATE TABLE; 查看。 AGGREGATE KEY数据模型中,所有没有指定聚合方式(SUM、REPLACE、MAX、MIN)的列视为Key列。而其余则为Value列。 定义…
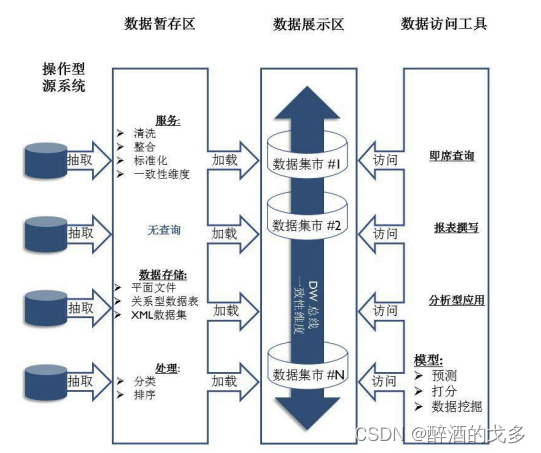
数据仓库模式之详解 Inmon 和 Kimball
目录 一、前言
二、企业信息工厂(Inmon)
2.1 概念
2.2 主要组件
2.3 流程
三、多维数据仓库(Kimball)
3.1 概念
3.2 核心组件
3.3 流程 四、异同及用途对比
4.1 异同对比
4.2 特征比较 一、前言
大部分关于数据仓库构建…
【Hive】join时的小技巧
有时候join或者where两表时会报错: FAILED: SemanticException Cartesian products are disabled for safety reasons. If you know what you are doing, please sethive.strict.checks.cartesian.product to false and that hive.mapred.mode is not set to strict…
数据仓库 ODS->DWD->DWS->ADS
1.数据仓库DW
1.1简介
Data warehouse(可简写为DW或者DWH)数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它是一整套包括了etl、调度、建模在内的完整的理论体系。数据仓库…

【hive】简单介绍hive的几种join
文章目录 前言1. Common Join2. Map Join介绍:使用方法:限制: 3. Bucket Map Join介绍:好处:使用条件:使用方法: 4. Sort Merge Bucket Map Join介绍:如何使用: 5. Skew …

Python 3 使用Hive 总结
启动HiveServer2 服务 HiveServer2 是一种可选的 Hive 内置服务,可以允许远程客户端使用不同编程语言向 Hive 提交请求并返回结果。
Thrift服务配置
假设我们已经成功安装了 Hive,如果没有安装,请参考:Hive 一文读懂 。在启动 H…
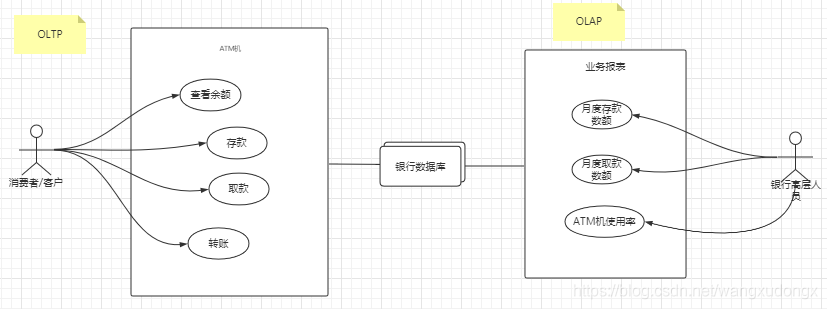
企业数据应用 传统商业智能对比大数据应用
传统商业智能对比大数据应用传统商业智能模式商业智能系统的主要功能大数据的变革BI(商业智能)OLTP(联机事务处理)OLAP(联机分析处理)操作数据库系统和数据仓库系统的区别为什么需要分离的数据仓库ETLMPP&a…
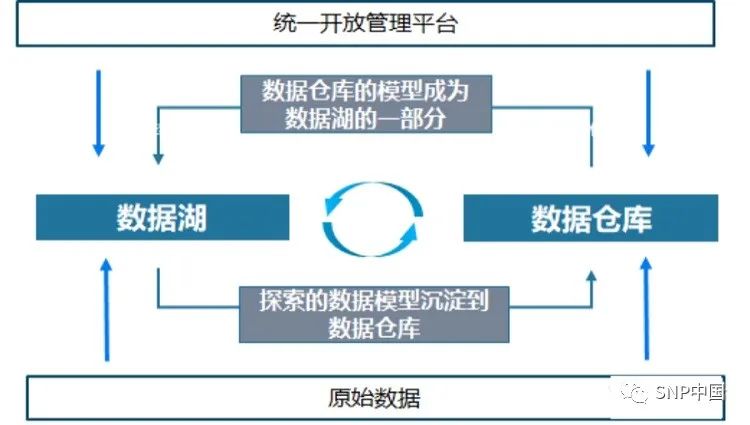
数据湖真的能取代数据仓库吗?【SNP SAP数据转型 】
数据湖和数据仓库的存在并不冲突,也并不是取代的关系,而是相互的融合关系。 数据湖是近两年中比较新的技术在大数据领域中,对于一个真正的数据湖应该是什么样子,现在对数据湖认知还是处在探索的阶段,像现在代表的开源产…
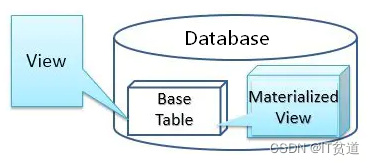
ClickHouse(二十一):Clickhouse SQL DDL操作-临时表及视图
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…
Apache Doris 入门教程32:物化视图
物化视图
物化视图是将预先计算(根据定义好的 SELECT 语句)好的数据集,存储在 Doris 中的一个特殊的表。
物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。 …

【大数据】Doris 构建实时数仓落地方案详解(一):实时数据仓库概述
Doris 构建实时数仓落地方案详解(一):实时数据仓库概述 1.数据仓库的发展历程2.数据仓库技术的发展3.数仓的相关技术栈4.OLAP 查询5.MPP 架构6.实时数仓定义7.实时数仓的难点 数据仓库的概念可以追溯到 20 世纪 80 年代,当时 IBM …

ClickHouse(二十二):Clickhouse SQL DML操作及导入导出数据
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…
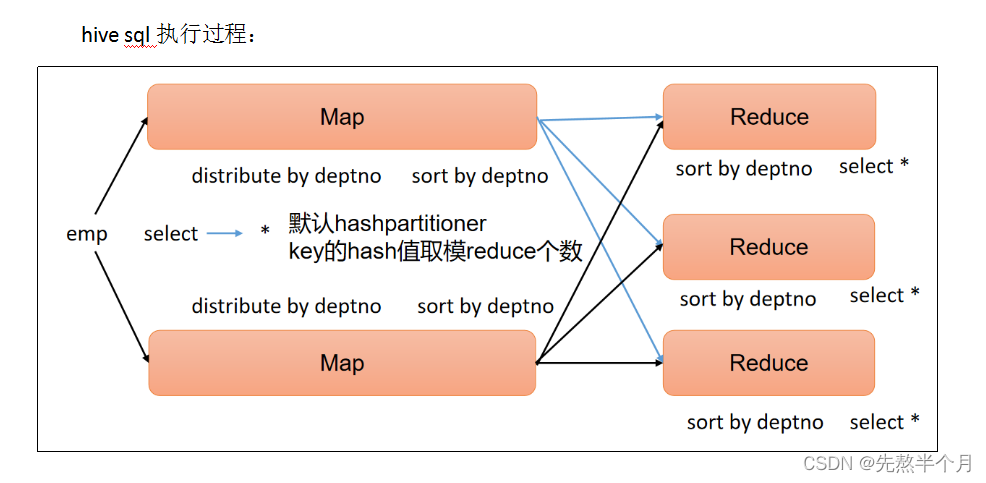
【hive】行转列—explode()/posexplode()/lateral view 函数使用场景
文章目录 一、lateral view函数二、explode()函数三、posexplode()函数四、行转列使用单列转多行多列转多行 一、lateral view函数 功能: 用于和UDTF函数(explode,split)结合使用,把某一行数据拆分成多行数据,再将多行结果组合成一…
超融合数据库:解锁全场景数据价值的钥匙
前言
近日,四维纵横对外官宣已完成上亿元 B 轮融资。作为超融合数据库理念的提出者,三年来 YMatrix 持续在超融合数据库领域中保持精进与迭代,对于超融合数据库在行业、场景中的应用和理解也更为深刻。
本篇文章,我们将基于 YMa…
商品详情API接口对接电商平台数据获取虾皮shopee产品参数销量、销量、库存、商品规格信息列表调用演示
商品详情API接口是一种用于访问和获取商品信息的接口,通常用于连接电商平台和商家应用程序。这个接口可以提供有关商品的各种详细信息,如名称、价格、描述、图片、类别、库存和评价等。它使得开发者能够为平台上的消费者提供更个性化和定制化的购物体验&…
如何利用数字化系统发挥数据的最大价值?
社会日新月异,企业管理也在时刻发生着变化,数字化系统的引入,解决了企业纸质化的汇报形式,简便快捷,一切事物都是有两面性的,数字化也给企业带来了新的挑战,如何利用数字化发挥数据的最大价值&a…
天软特色因子看板(2023.10 第14期)
该因子看板跟踪天软特色因子A05005(近一月单笔流通金额占比(%),该因子为近一个月单笔流通金额占比因子,用以刻画股票在收盘时,主力资金在总交易金额中所占的比重。 今日为该因子跟踪第14期,跟踪其在SW801160 (申万公用事业) 中的表…
记一次大数据事故@用了很久的虚拟机环境突然不能联网了
记一次大数据事故用了很久的虚拟机环境突然不能联网了
背景
今天打开自己电脑上的虚拟机环境打算练习一下flink,结果发现vmware里虚拟机能正常开机,也能正常进图os,但是就是不能ping通主机,主机也不能ping通虚拟机
探查
1、…
SparkSQL - 常见问题
1、广播超时 参考资料:https://www.ai2news.com/blog/3041168/ 报错信息:
Caused by: org.apache.spark.SparkException: Could not execute broadcast in 300 secs. You can increase the timeout for broadcasts via spark.sql.broadcastTimeout or d…
[shell,hive] 在shell脚本中将hiveSQL分离出去
将Hive SQL语句写在单独的.hql文件中,
然后在shell脚本中调用这些文件来执行Hive查询。
这样可以将SQL语句与shell脚本分离,使代码更加清晰和易于维护。
基本用法
以下是一个示例,展示如何在shell脚本中使用.hql文件执行Hive查询…
【数据库技术】金管局计算机岗位——数据仓库(⭐⭐⭐⭐)
数据库技术 数据仓库数据仓库的定义数据仓库的作用数据仓库的特点(⭐⭐⭐⭐)数据仓库的主要功能(⭐⭐⭐⭐)OLTP:联机事务处理(⭐⭐⭐⭐⭐)OLAP:联机分析处理(⭐⭐⭐⭐⭐)OLAP的基本多维分析操作(⭐⭐⭐⭐⭐) 数据仓库与数据库的区别(⭐⭐⭐)数据仓库的三…
【Hive】内部表(Managed Table)和外部表(External Table)相关知识点
在Hive中,有两种类型的表:外部表(External Table)和内部表(Managed Table)。它们在数据存储和管理方式上存在一些重要的区别。 本文就来对这些知识做一个总结。 1、如何在hive中创建内部表和外部表? 2、内部表和外部表的一些区别。 3、怎么查看一个表是内部表还是外部表…
![[Kettle] Excel输入](https://img-blog.csdnimg.cn/6d317d3678314c1b84cf0b42006246c0.png)
[Kettle] Excel输入
Excel文件采用表格的形式,数据显示直观,操作方便
Excel文件采用工作表存储数据,一个文件有多张不同名称的工作表,分别存放相同字段或不同字段的数据
数据源
物理成绩(Kettle数据集2).xls https://download.csdn.net/download/H…
企业如何落地搭建商业智能BI系统
随着新一代信息化、数字化技术的应用,引发了新一轮的科技革命,现代化社会和数字化的联系越来越紧密,数据也变成继土地、劳动力、资本、技术之后的第五大生产要素,这一切都表明世界已经找准未来方向,前沿科技也与落地并…

制造业企业上WMS仓库管理系统的优点
wms都有哪些优点?
从事仓库管理几年,上万界星空科技WMS之前,仓库和配送有30人左右,每天却只能处理100来张订单,每天忙于分拨任务,监督执行,把自己的累得够呛不说,下面的人还总埋怨为…
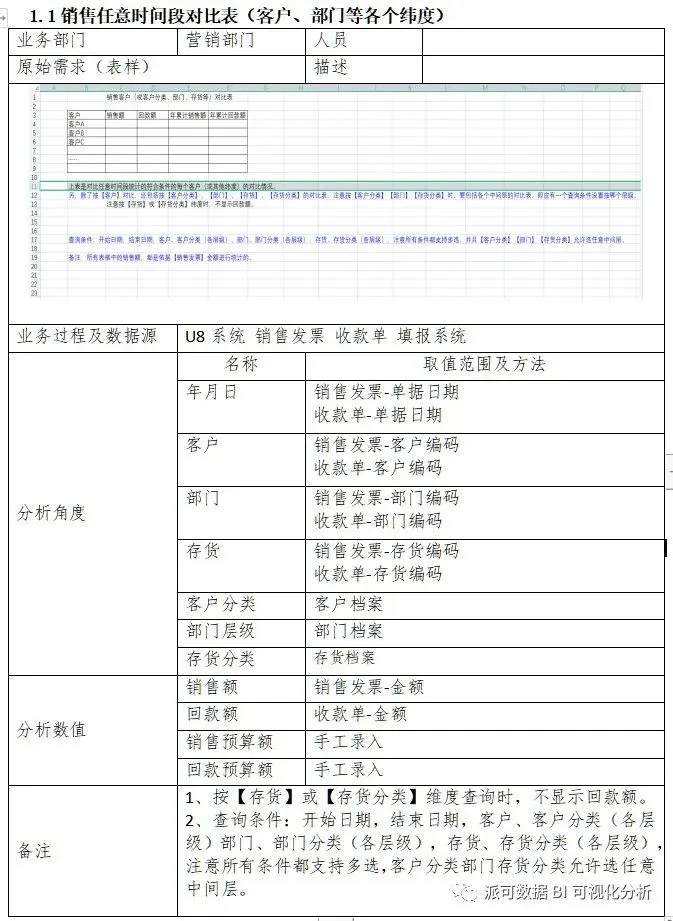
需求调研,是做好商业智能BI的第一步
商业智能BI,一个高大上的名字,一直被很多人认为是企业信息化中的“面子工程”。美其名曰“可视化大屏”,什么经营驾驶舱,什么管理仪表盘,都是花里胡哨的东西,老板不会看,企业不会用,…
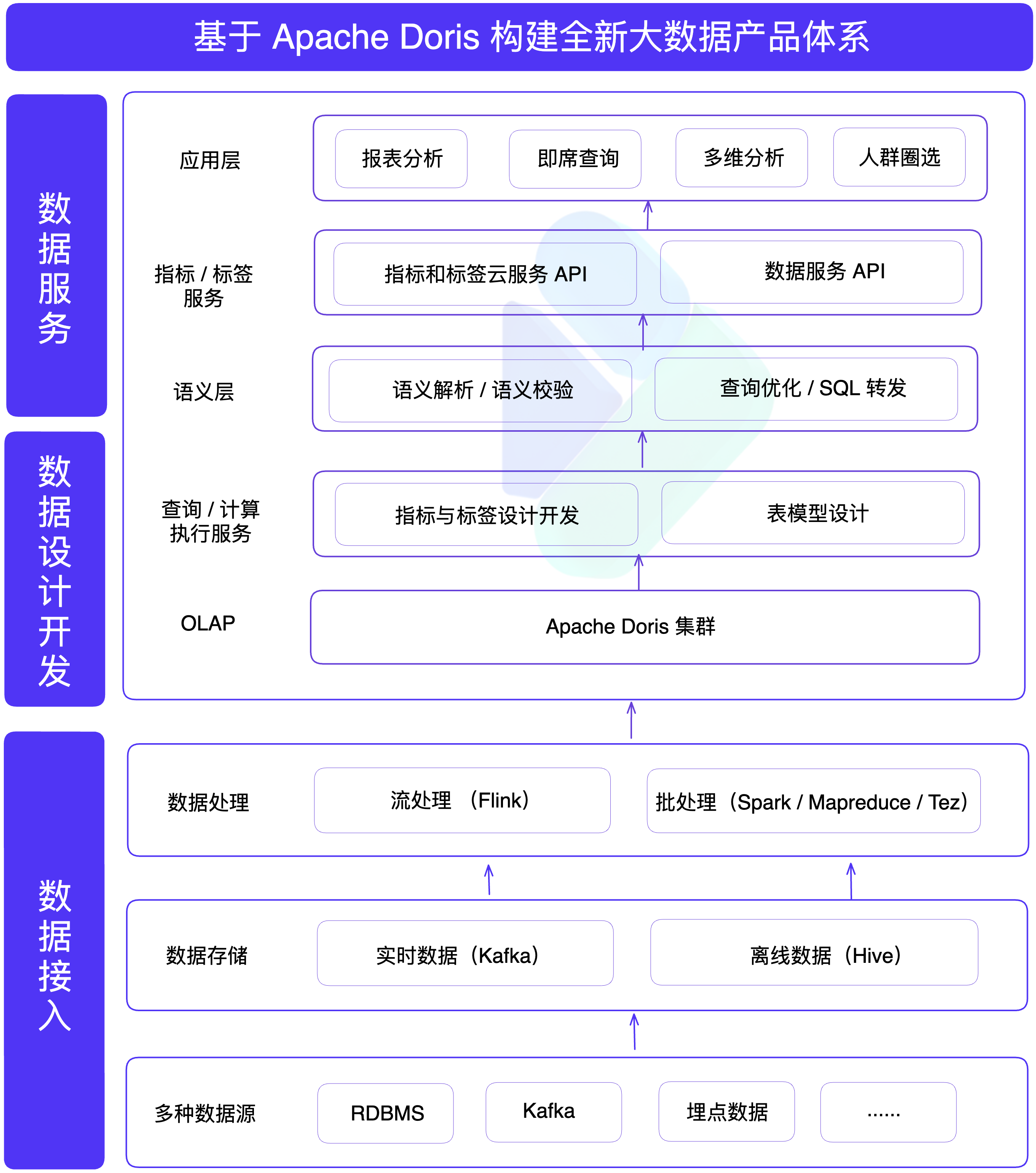
平安人寿基于 Apache Doris 统一 OLAP 技术栈实践
导读:平安人寿作为保险行业领军企业,坚持技术创新,以数据业务双轮驱动的理念和更加开放的思路来应对不断增长的数据分析和应用需求;以深挖数据价值、保障业务用数效率为目标持续升级大数据产品体系。自 2022 年起平安人寿开始引入…

【Java 进阶篇】Java 中 JQuery 对象和 JS 对象:区别与转换
在前端开发中,经常会涉及到 JavaScript(JS)和 jQuery 的使用。这两者都是前端开发中非常重要的工具,但它们之间存在一些区别。本文将详细介绍 Java 中的 JQuery 对象和 JS 对象的区别,并讨论它们之间的转换方法。
1. …
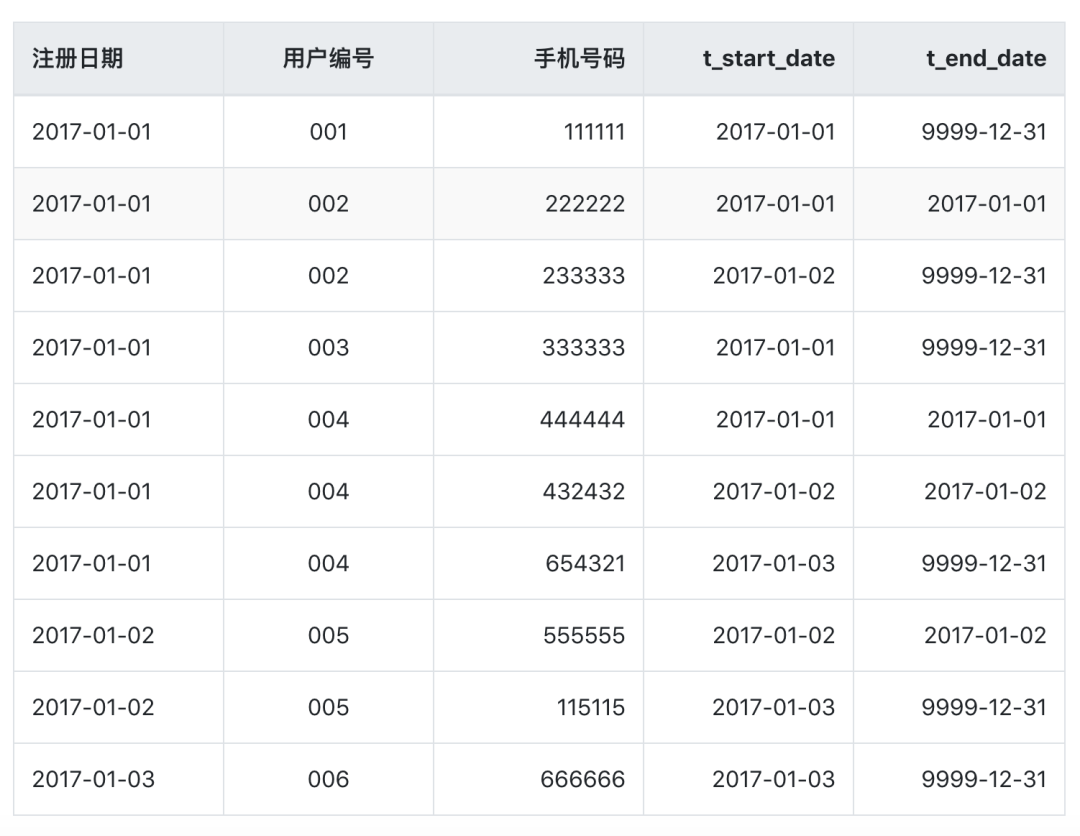
详解数据仓库之拉链表(原理、设计以及在Hive中的实现)
最近发现一本好书,读完感觉讲的非常好,首先安利给大家,国内第一本系统讲解数据血缘的书!点赞!近几天也会安排朋友圈点赞赠书活动(ง•̀_•́)ง 0x00 前言 本文将会谈一谈在数据仓库中拉链表相关的内容,包…

如何化解从数据到数据资源入表的难题
继数据成为生产要素后,各种跟数据相关的概念就出来了,首先我们要弄明白有关数据的几个高频词汇。数据:指“原始数据”,即记录事实的结果,用来描述事实的未经加工的素材。数据资源:指加工后具有经济价值的数…
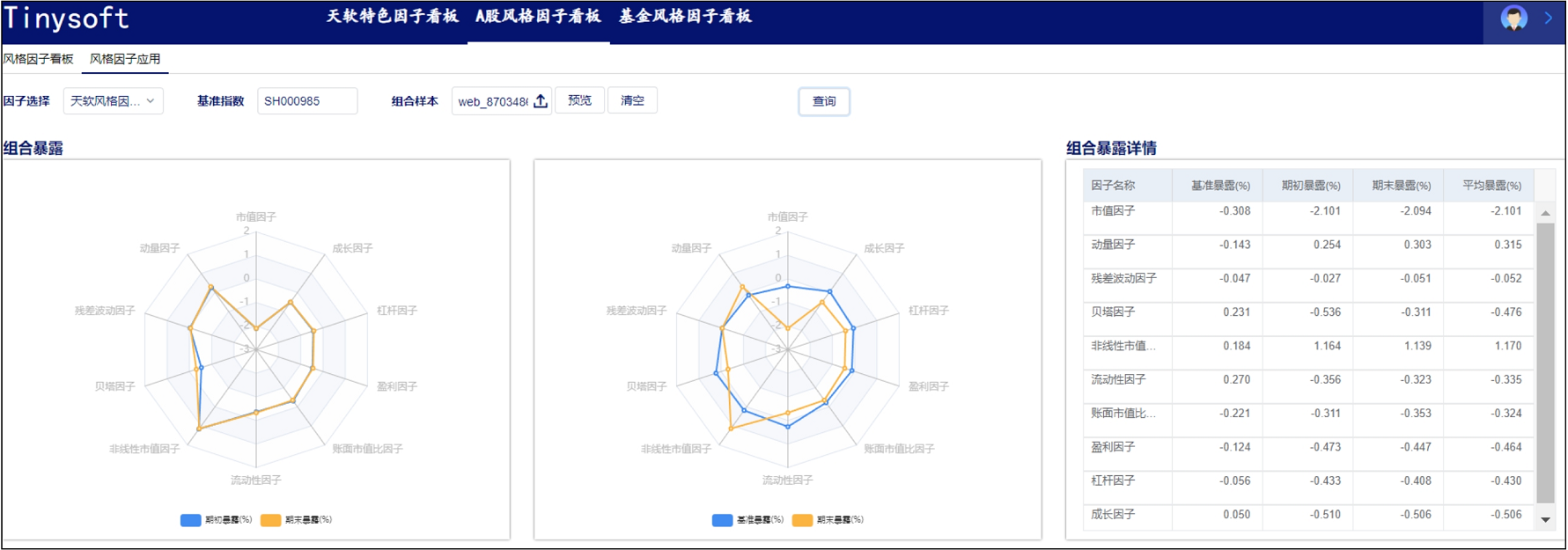
A股风格因子看板 (2023.11 第11期)
该因子看板跟踪A股风格因子,该因子主要解释沪深两市的市场收益、刻画市场风格趋势的系列风格因子,用以分析市场风格切换、组合风格暴露等。 今日为该因子跟踪第11期,指数组合数据截止日2023-10-31,要点如下 近1年A股风格因子收益走…
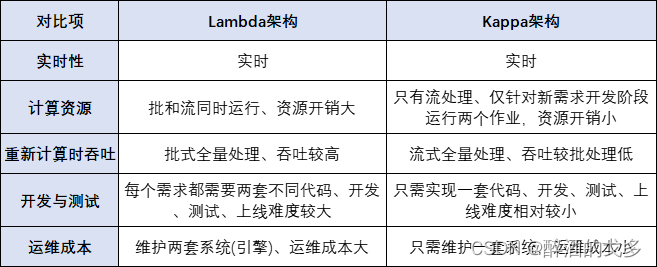
数据仓库架构之详解Kappa和Lambda
目录 一、前言
二、架构详解
1 Lambda 架构
1.1 Lambda 架构组成
1.2 Lambda 特点
1.3 Lambda 架构的优点
1.4 Lambda 架构的不足
2 Kappa 架构
2.1 Kappa 架构的核心组件
2.2 Kappa 架构优点
2.3 Kappa 架构的注意事项
三、区别对比
四、选择时考虑因素 一、前言 …
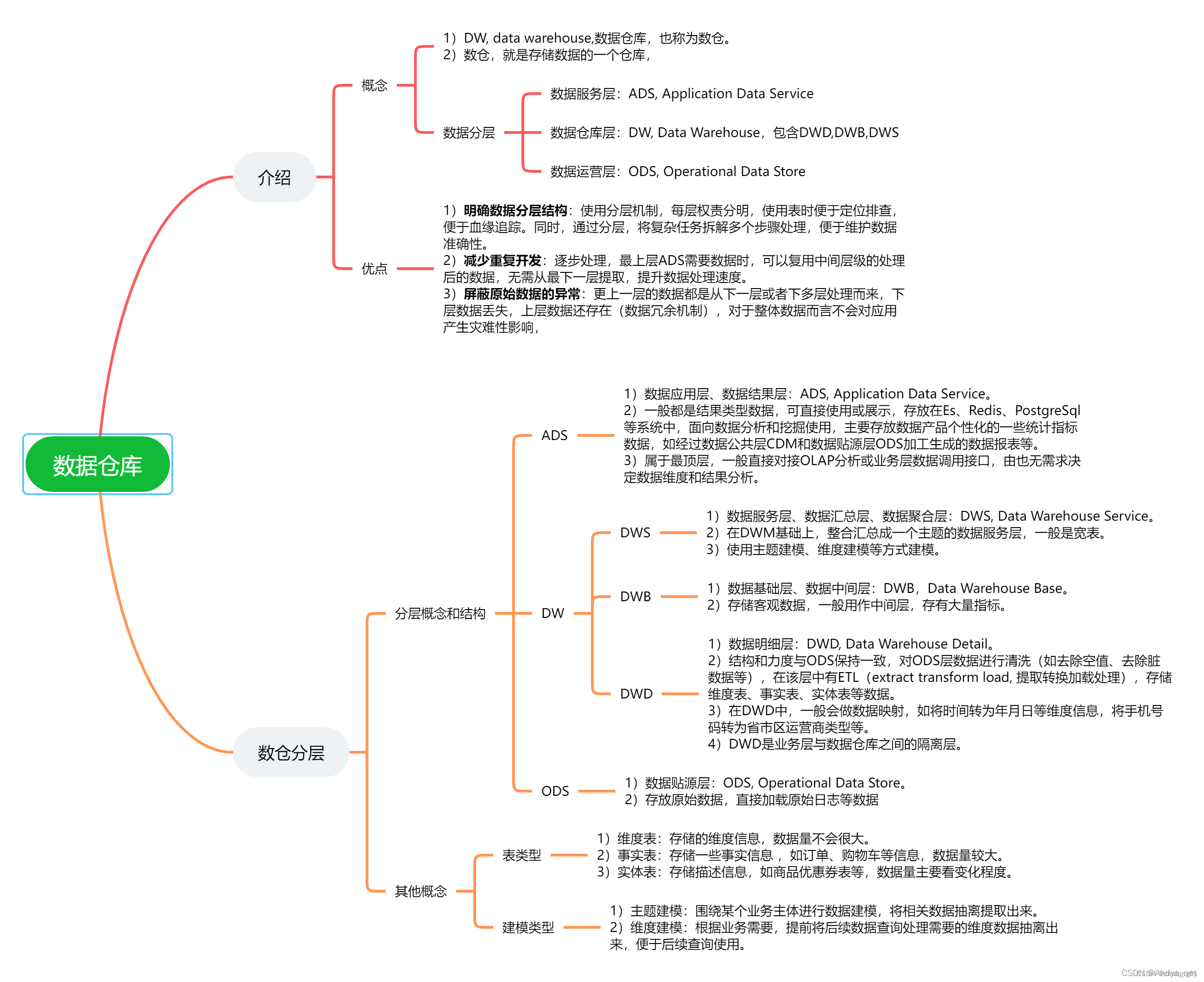
数据仓库数据管理模型
数据仓库分为贴源层、数据仓库层、数据服务层,有人叫做数仓数据模型,或者叫"数据管理模型”。
我们为什么要进行数据分层管理,下图的优点介绍已经说得比较明确,再补充几点:
保障数据一致性:上层的数…

hive-3.1.2环境安装实验
1.修改hadoop相关参数
1-修改core-site.xml
[bigdata@master hive]$ vim /opt/module/hadoop/etc/hadoop/core-site.xml
<!-- 配置该bigdata(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.bigdata.hosts</name><va…
GORM 自定义数据类型json-切片(数组)
文章目录 自定义数据类型自定义json结构体定义Scaner和Valuer接口的实现插入数据&查询数据 自定义切片存储切片json形式存储字符串存储 创建&查询数据 gorm官方文档:自定义数据类型 自定义数据类型 数据空中很多情况下数据是多变的,我们这篇文章…
2023.11.22 -数据仓库
目录
https://blog.csdn.net/m0_49956154/article/details/134320307?spm1001.2014.3001.5501
1经典传统数仓架构
2离线大数据数仓架构
3数据仓库三层
数据运营层,源数据层(ODS)(Operational Data Store)
数据仓库层&#…
企业如何选择一款高效的ETL工具
企业如何选择一款高效的ETL工具?
在企业发展至一定规模后,构建数据仓库(Data Warehouse)和商业智能(BI)系统成为重要举措。在这个过程中,选择一款易于使用且功能强大的ETL平台至关重要,因为数…
Hudi第四章:集成Hive
系列文章目录
Hudi第一章:编译安装 Hudi第二章:集成Spark Hudi第二章:集成Spark(二) Hudi第三章:集成Flink Hudi第四章:集成Hive 文章目录 系列文章目录前言一、环境准备1.拷贝jar包 二、Flink集成hive1.配置模版2.案…
2023.11.22 -数据仓库的概念和发展
目录
https://blog.csdn.net/m0_49956154/article/details/134320307?spm1001.2014.3001.5501
1经典传统数仓架构
2离线大数据数仓架构
3数据仓库三层
数据运营层,源数据层(ODS)(Operational Data Store)
数据仓库层&#…
Java开源ETL工具-Kettle
一、背景 公司有个基于Kettle二次开发产品主要定位是做一些数据ETL的工作, 所谓的ETL就是针对数据进行抽取、转换以及加载的过程,说白了就是怎么对原始数据进行清洗,最后拿到我们需要的、符合规范的、有价值的数据进行存储或者分析的过程。 一般处理ETL的…
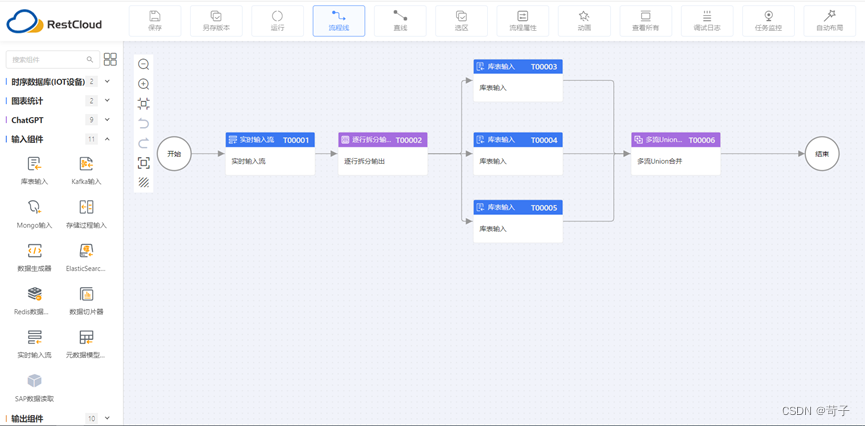
企业建数仓的第一步是选择一个好用的ETL工具
当企业决定建立数据仓库(Data Warehouse),第一步就是选择一款优秀的ETL(Extract, Transform, Load)工具。数据仓库是企业数据管理的核心,它存储、整合并管理各种数据,为商业决策和数据分析提供支…
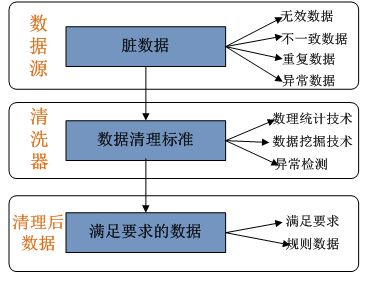
数仓中数据清洗的方法
在数据采集的过程中,需要从不同渠道获取数据并汇集在数仓中,采集的原始数据首先需要进行解析,然后对不准确、不完整、不合理、格式、字符等不规范数据进行过滤清洗,清洗过的数据才能更加符合需求,从而使后续的数据分析…
hive两张表实现like模糊匹配关联
testa表(字段a)aaabbacccddddddaaatestb表(字段b)ab1. 使用likeconcat模糊配对
selecta.a
from testa a ,testb b
where a like concat(%,b.b,%)
group by a.a2. 使用locate函数
selecta.a
from testa a ,testb b
where locate(b.b,a.a)>0
group by a.a3. 使用instr函数
sel…

大数据——一文详解数据仓库概念(数据仓库的分层概念和维度建模详解)
1、ods是什么?
ods层最好理解,基本上就是数据从源表拉过来,进行etl,比如MySQL映射到Hive,那么到了Hive里面就是ods层。ods全称是 Operational Data Store,操作数据存储——“面向主题的”,数据…
Hive客户端和Beeline命令行的基本使用
本专栏案例数据集链接: https://download.csdn.net/download/shangjg03/88478038 1.Hive CLI 1.1 命令帮助Help 使用 `hive -H` 或者 `hive --help` 命令可以查看所有命令的帮助,显示如下: usage: hive-d,--define <key=value> Variable subsitution to ap…

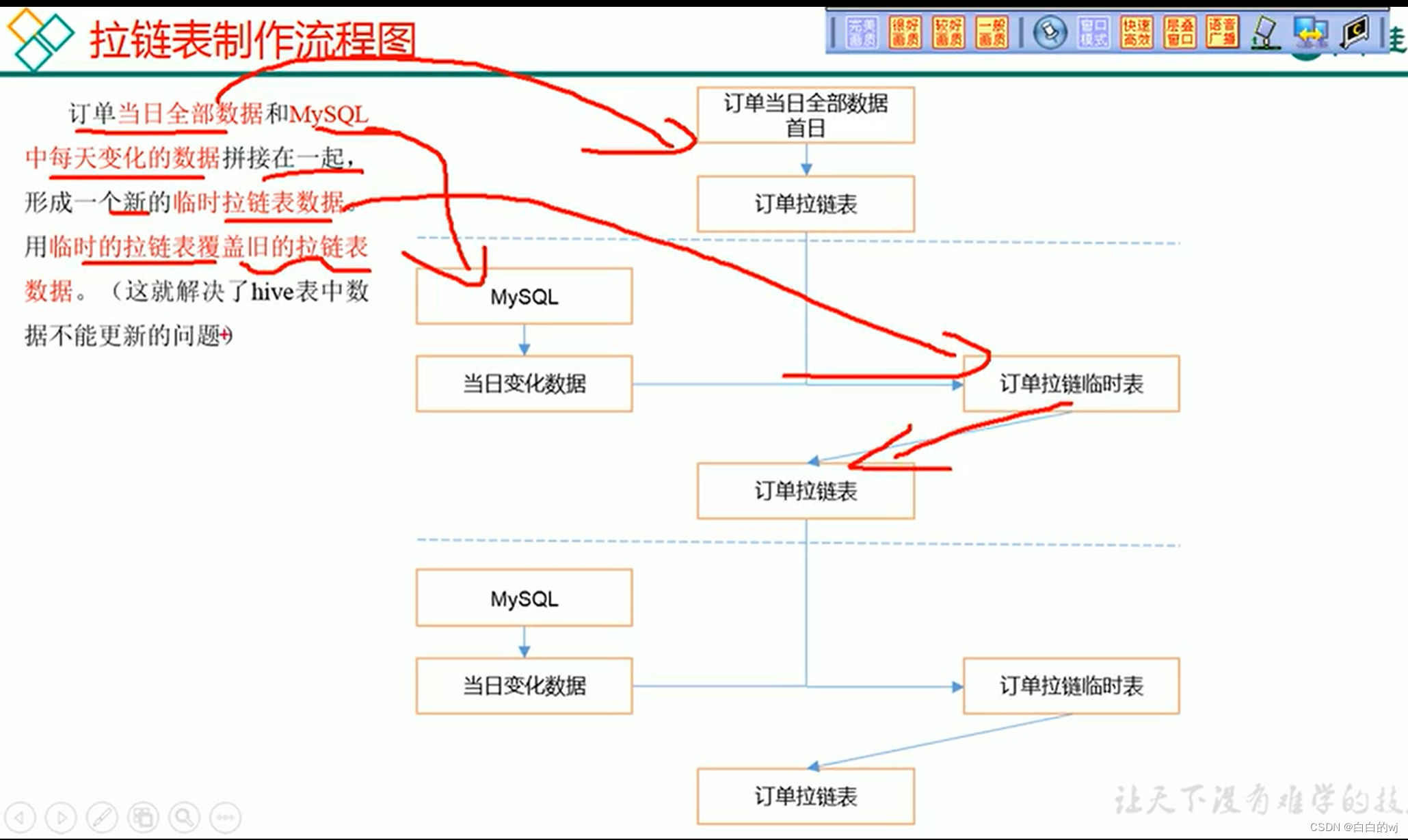
2023.12.1 --数据仓库之 拉链表
目录 什么是拉链表
为什么要做拉链表?
没使用拉链表:
使用了拉链表:
题中订单拉链表的形成过程
实现语句 什么是拉链表 拉链表是缓慢渐变维的一种解决方案.
拉链表,记录每条信息的生命周期,一旦一条记录的生命周期结束,就重新开始一条新的记录,并把当前日期放入生效开始…

WMS仓库管理系统选择指南:如何确保您的仓库提高效率?
如何选择WMS仓库管理系统?仓库管理主要包括以下四个方面: 1.商品出入库管理 2.库存调拨 3.库存盘点 4.虚拟库存/实际库存管理 为了更好地管理仓库,我们需要确保基本的硬件设施得以满足,例如划分存储区域、使用货架以及进行员工培训…
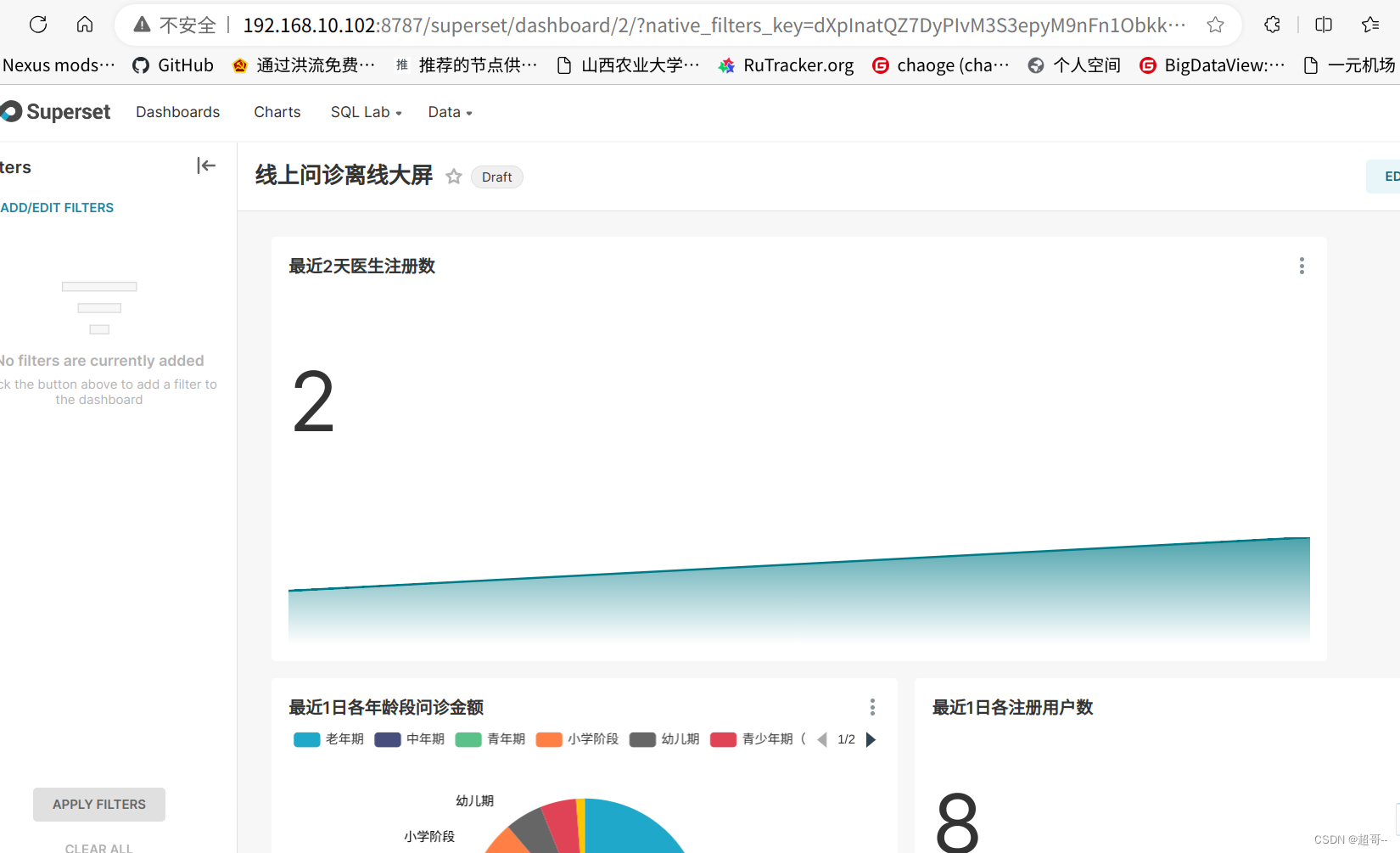
线上问诊:可视化展示
系列文章目录
线上问诊:业务数据采集 线上问诊:数仓数据同步 线上问诊:数仓开发(一) 线上问诊:数仓开发(二) 线上问诊:数仓开发(三) 线上问诊:可视化展示 文章目录 系列文章目录前言一、全流程调度1.生产新…
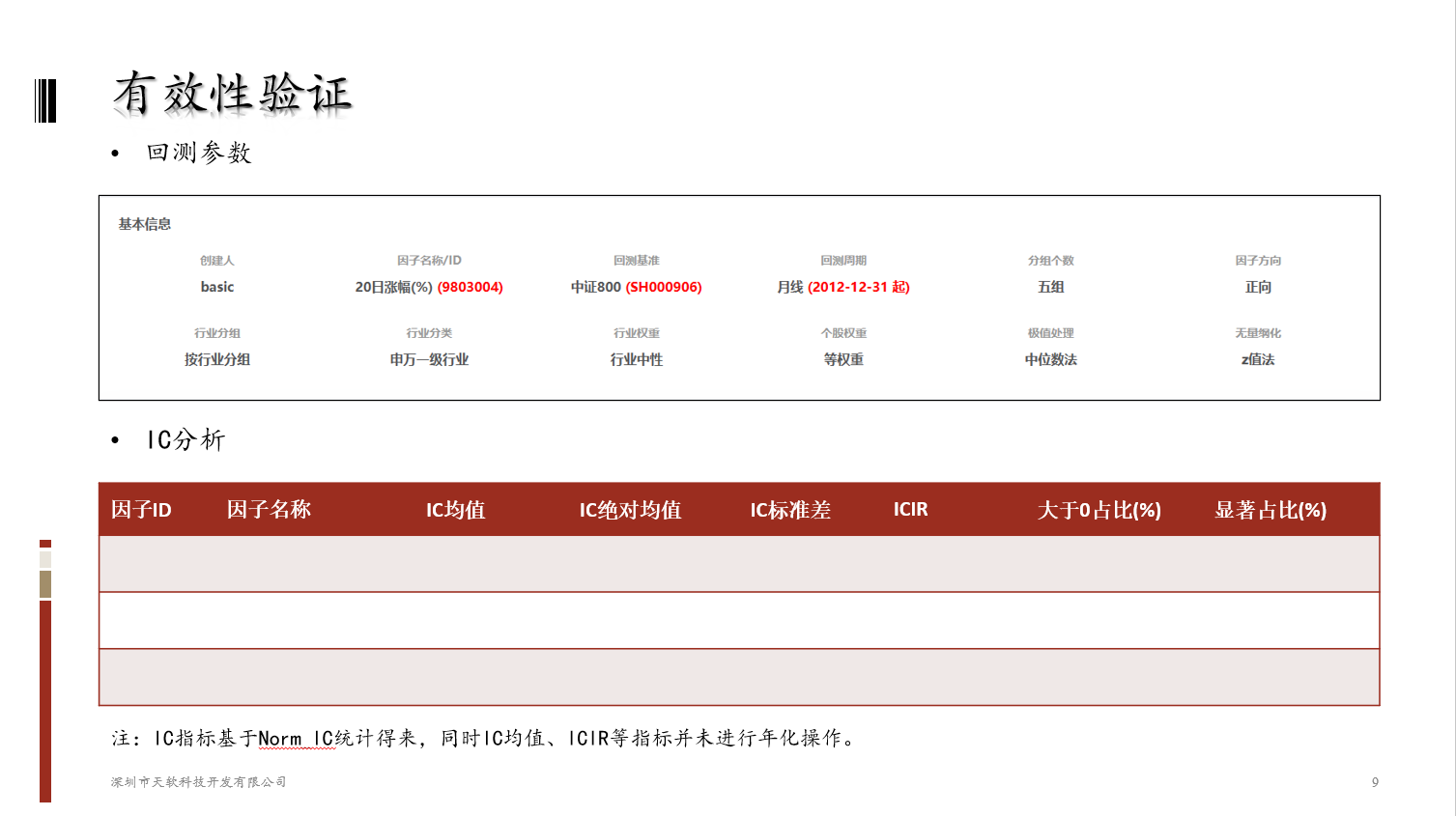
高频微观结构:日内及隔夜动量因子
本周天软因子序列课程暂时结束,感谢大家百忙之中参会交流! 本次会议主要内容有: 1.介绍日内及隔夜动量因子的构造逻辑,如何选择市 场代理变量对动量因子进行改进; 2.结合因子研究平台分别分析动量因子、日内涨幅因 子、隔夜涨幅因…
49. 视频热度问题
文章目录 实现一题目来源 谨以此笔记献给浪费掉的两个小时。
此题存在多处疑点和表达错误的地方,如果你看到了这篇文章,劝你跳过该题。
该题对提升HSQL编写能力以及思维逻辑能力毫无帮助。
实现一
with info as (-- 将数据与 video_info 关联&#x…

hive葵花宝典:hive函数大全
文章目录 版权声明函数1 函数分类2 查看函数列表3 数学函数取整函数: round指定精度取整函数: round向下取整函数: floor向上取整函数: ceil取随机数函数: rand幂运算函数: pow绝对值函数: abs 4 字符串函数字符串长度函数:length字符串反转函数:reverse…
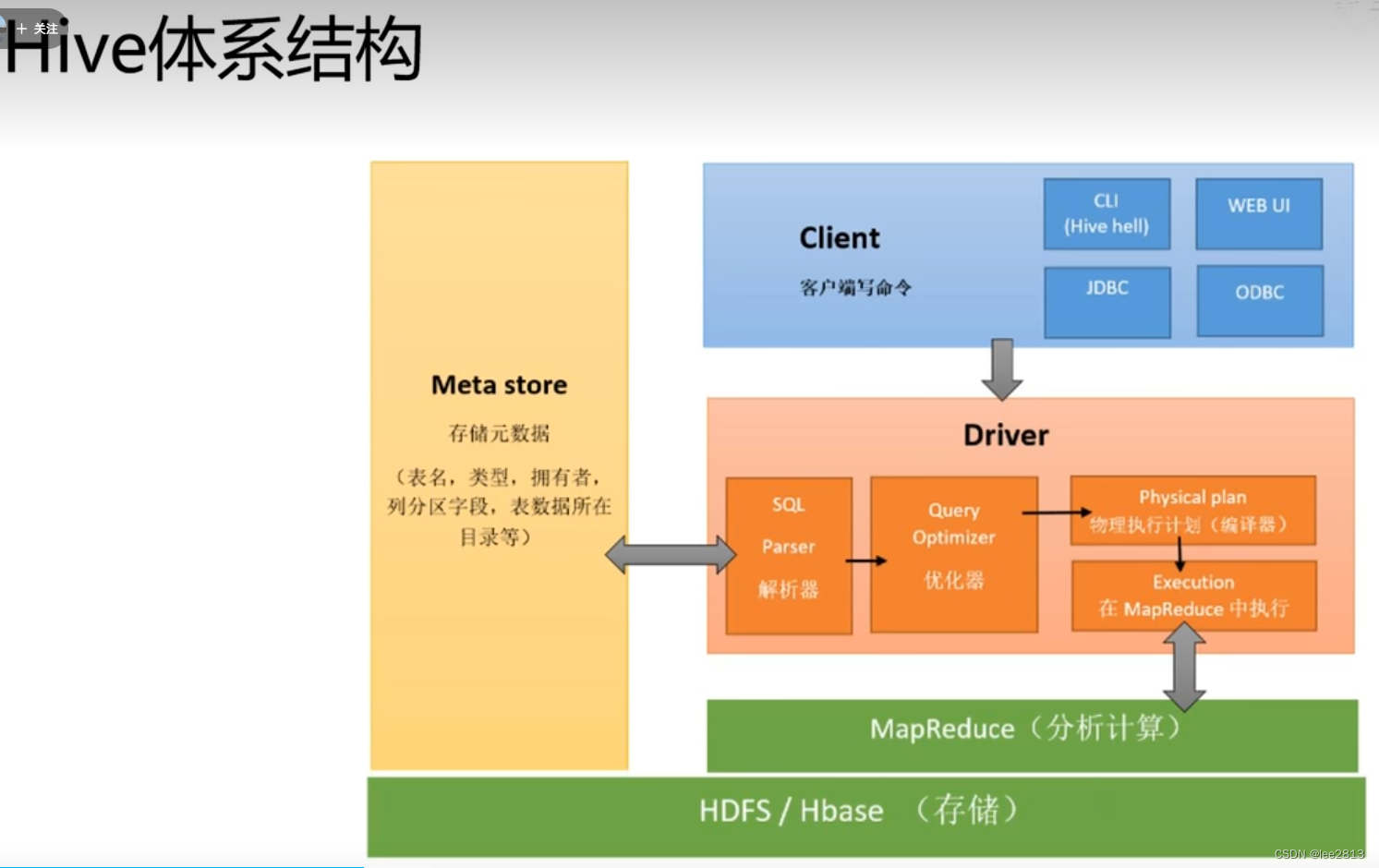
L2 数据仓库和Hive环境配置
1.数据仓库架构
数据仓库DW主要是一个用于存储,分析,报告的数据系统。数据仓库的目的是面向分析的集成化数据环境,分析结果为企业提供决策支持。-DW不产生和消耗数据 结构数据:数据库中数据,CSV文件 直接导入DW非结构…
《阿里大数据之路》读书笔记:第三章 数据同步
第三章 数据同步
数据同步技术含义:不同系统间的数据流转,有多种不同的应用场景。
应用场景:
同类型不同集群数据库之间的数据同步主数据库与备份数据库之间的数据备份主系统与子系统之间的数据更新不同地域、不同数据库类型之间的数据传输…
指标的业务负责人和技术负责人
在一个指标项目中,业务负责人和技术负责人通常扮演不同的角色: 业务负责人:负责确定指标的业务目标和价值,以及如何将指标用于决策和改进业务流程。他们与利益相关者沟通,确保指标与业务目标相一致,并负责推…
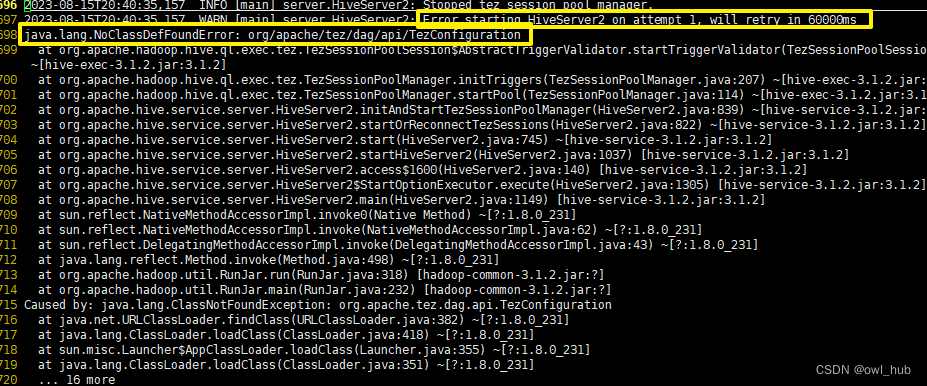
hive-无法启动hiveserver2
启动hiveserver2没有反应,客户端也无法连接( beeline -u jdbc:hive2://node01:10000 -n root)
报错如下
查看hive的Log日志,发现如下报错
如何解决
在hive的hive_site.xml中添加如下代码
<property><name>hive.server2.active.passive…
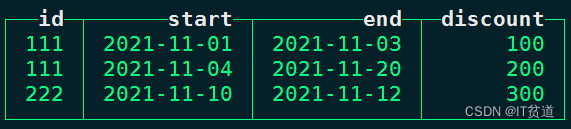
ClickHouse进阶(十二):Clickhouse数据字典-2-字典类型
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_大数据OLAP体系技术栈,Apache Doris,Kerberos安全认证-CSDN博客 📌订阅…
hive分区表 静态分区和动态分区
一、静态分区 现有数据文件 data_file 如下: 2023-08-01,Product A,100.0 2023-08-05,Product B,150.0 2023-08-10,Product A,200.0 1、创建分区表
CREATE TABLE sales (sale_date STRING,product STRING,amount DOUBLE
)
PARTITIONED BY (sale_year INT, sale_mon…
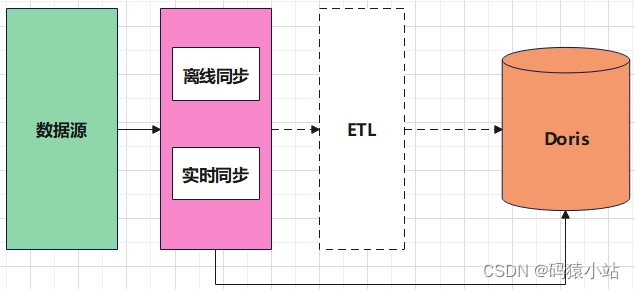
【数仓建设系列之五】数仓选型架构概览
【数仓建设系列之五】实时数仓选型架构概览 离线数仓(Offline Data Warehouse)和实时数仓(Real-time Data Warehouse)是数仓领域两种常见的数据存储和处理架构,它们在数据处理的方式、目标和时间性上有所不同ÿ…
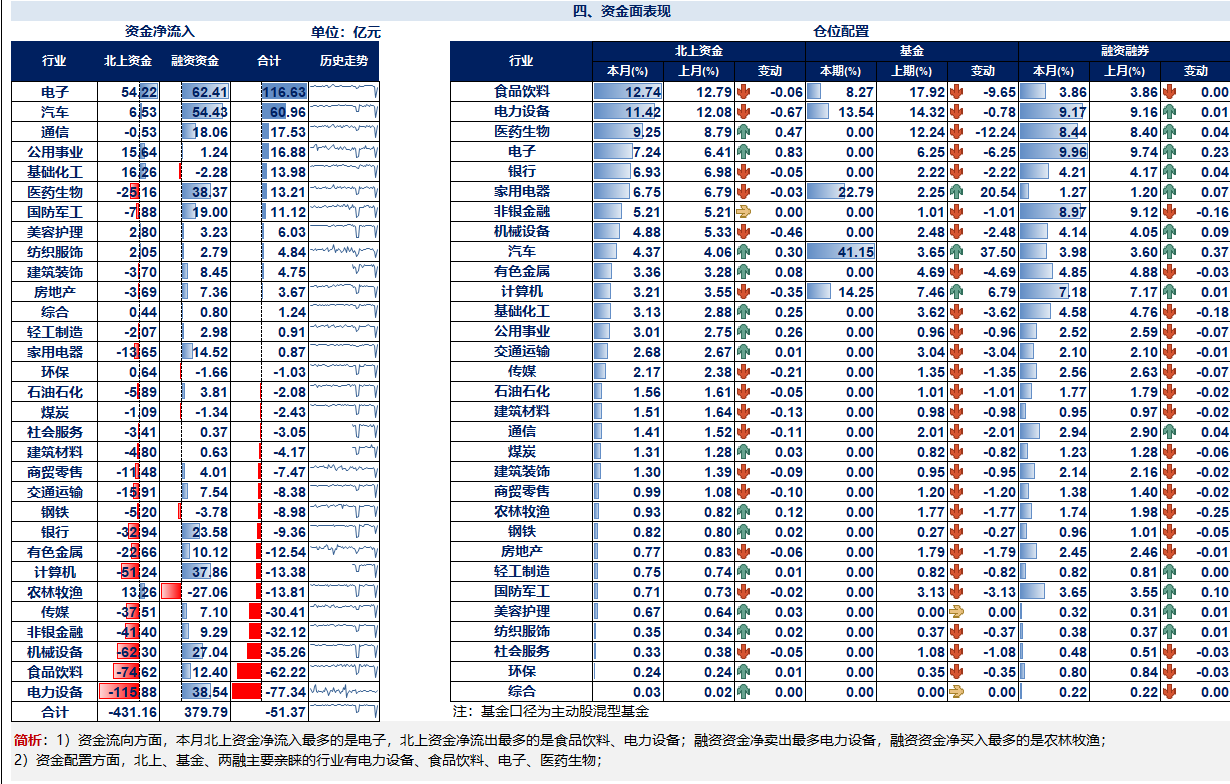
《行业全景画像报告》第3期
本月《行业全景画像报告》第3期: 环保、房地产和非银企账的胡挤度仍然报高,实际投蛋交易应注意:煤是行业动量较强,房地产行业动量疑弱,业绩整体表现较差:房地产、国防军工景气成较高,财务基本面状况较好,而食品饮料、煤…
![[Hive] INSERT OVERWRITE DIRECTORY要注意的问题](https://img-blog.csdnimg.cn/4543ec8a5e0d476faf70a9ab57832ba8.jpeg)
[Hive] INSERT OVERWRITE DIRECTORY要注意的问题
在使用Hive的INSERT OVERWRITE语句时,需要注意以下问题:
数据覆盖:INSERT OVERWRITE语句会覆盖目标目录中的数据。因此,在执行该语句之前,请确保目标目录为空或者你希望覆盖的数据已经不再需要。数据格式:…
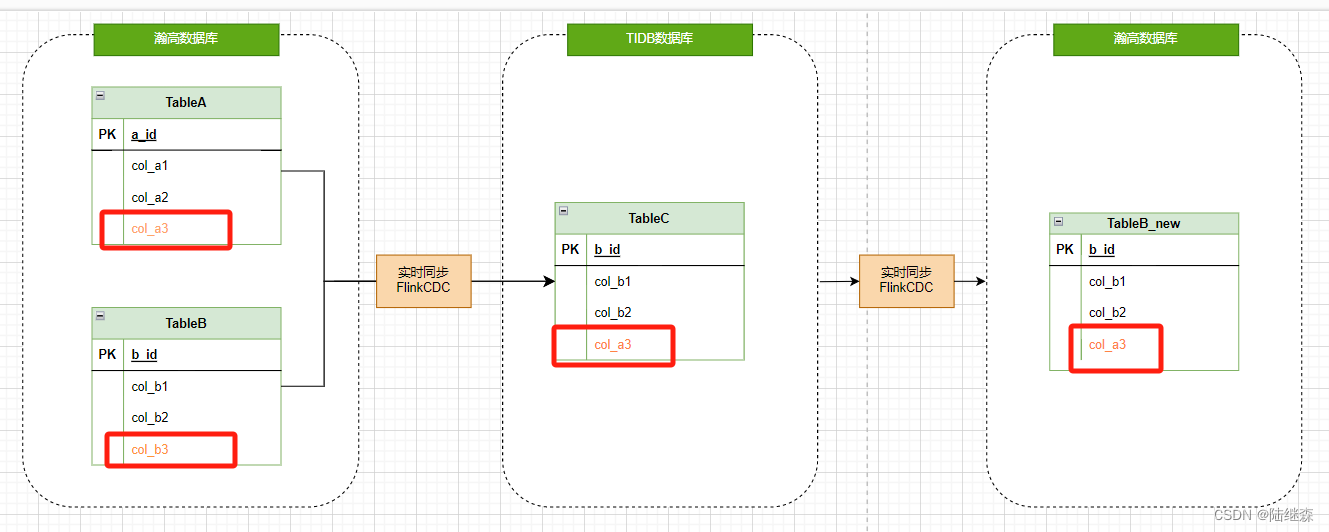
FlinkCDC实现主数据与各业务系统数据的一致性(瀚高、TIDB)
文章末尾附有flinkcdc对应瀚高数据库flink-cdc-connector代码下载地址
1、业务需求 目前项目有主数据系统和N个业务系统,为保障“一数一源”,各业务系统表涉及到主数据系统的字段都需用主数据系统表中的字段进行实时覆盖,这里以某个业务系统的一张表举例说明:业务系统表Ta…
从Hadoop到对象存储,抛弃Hadoop,数据湖才能重获新生?
Hadoop与数据湖的关系 1、Hadoop时代的落幕2、Databricks和Snowflake做对了什么3、Hadoop与对象存储(OSD)4、Databricks与Snowflake为什么选择对象存储5、对象存储面临的挑战 1、Hadoop时代的落幕 十几年前,Hadoop是解决大规模数据分析的“白…

Flink在汽车行业的应用【面试加分系列】
很多同学问我为什么要发这些大数据前沿汇报?
一方面是自己学习完后觉得非常好,然后总结发出来方便大家阅读;另外一方面,看这些汇报对你的面试帮助会很大,特别是面试前可以看看即将面试公司在大数据前沿的发展动向&…
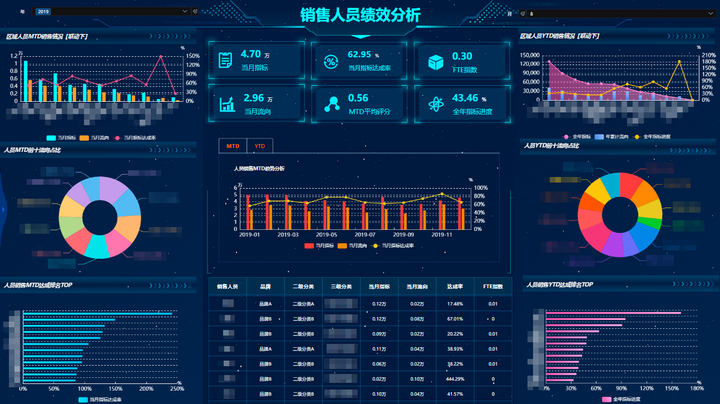
数字化转型时代,商业智能BI到底是什么?
据国际数据公司(IDC)预测,2025年时中国产生的数据量预计将达48.6ZB,在全球中的比例为27.8%。商业智能BI这一专为企业提供服务的数据类解决方案,仅2021年上半年在中国商业智能BI市场规模就达到了3.2亿美元,商…
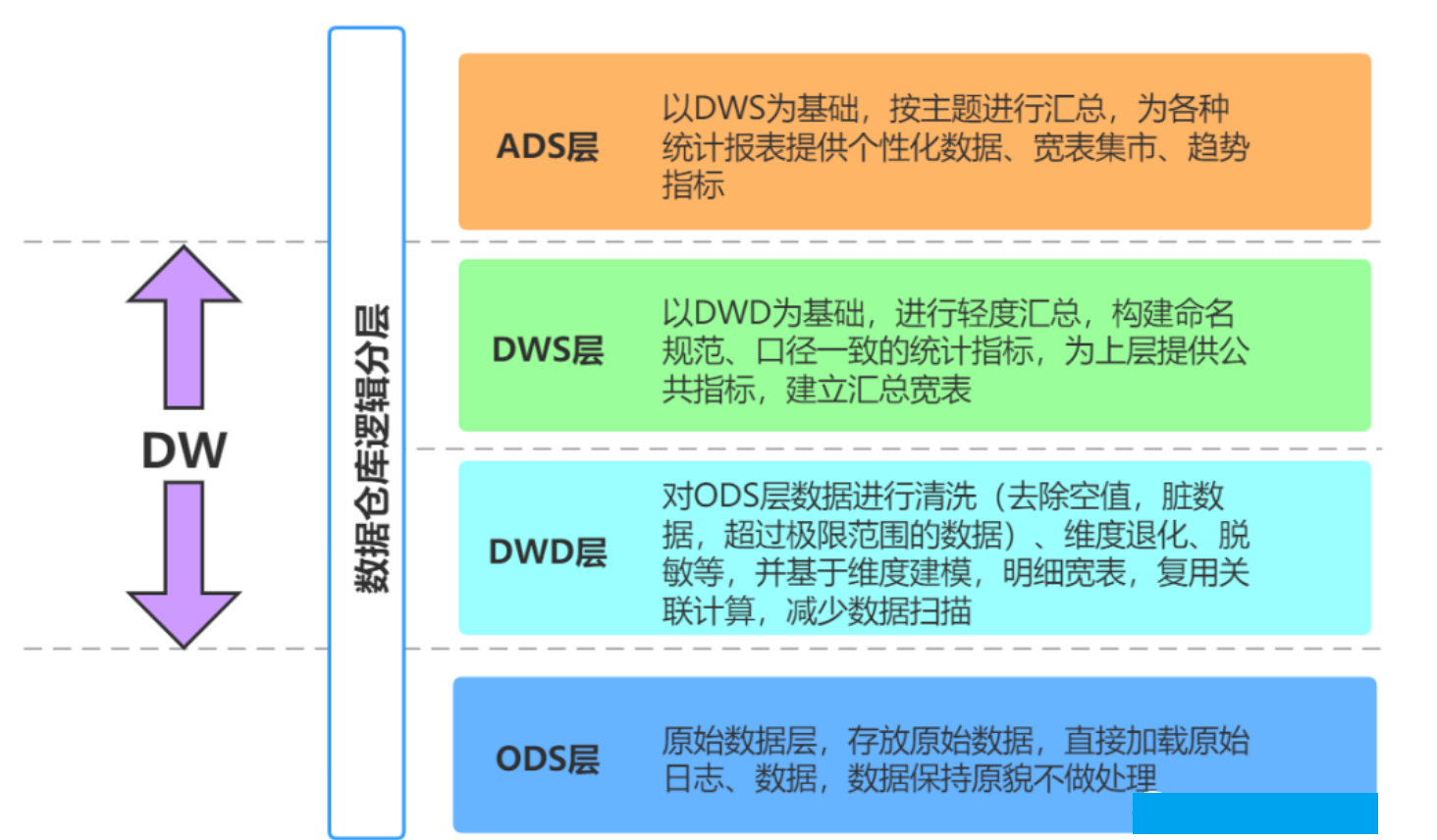
【数据仓库】数仓分层方法详解与层次调用规范
文章目录 一. 数仓分层的意义1. 清晰数据结构。2. 减少重复开发3. 方便数据血缘追踪4. 把复杂问题简单化5. 屏蔽原始数据的异常6. 数据仓库的可维护性 二. 如何进行数仓分层?1. ODS层2. DW层2.1. DW层分类2.2. DWD层2.3. DWS 3. ADS层 4、层次调用规范 一. 数仓分层…
hive sql多表练习
hive sql多表练习
准备原始数据集 学生表 student.csv 讲师表 teacher.csv 课程表 course.csv 分数表 score.csv 学生表 student.csv
001,彭于晏,1995-05-16,男
002,胡歌,1994-03-20,男
003,周杰伦,1995-04-30,男
004,刘德华,1998-08-28,男
005,唐国强,1993-09-10,男
006,陈道…

hive sql 行列转换 开窗函数 炸裂函数
hive sql 行列转换 开窗函数 炸裂函数
准备原始数据集 学生表 student.csv 讲师表 teacher.csv 课程表 course.csv 分数表 score.csv 员工表 emp.csv 雇员表 employee.csv 电影表 movie.txt 学生表 student.csv
001,彭于晏,1995-05-16,男
002,胡歌,1994-03-20,男
003,周杰伦,…
Hive默认分割符、存储格式与数据压缩
目录 1、Hive默认分割符2、Hive存储格式3、Hive数据压缩 1、Hive默认分割符 Hive创建表时指定的行受限(ROW FORMAT)配置标准HQL为:
...
ROW FORMAT DELIMITED
FIELDS TERMINATED BY \u0001
COLLECTION ITEMS TERMINATED BY ,
MAP KEYS TERMI…
ClickHouse SQL 查询优化
1 单表查询 1.1 Prewhere替代where Prewhere和where语句的作用相同,用来过滤数据。不同之处在于prewhere只支持 *MergeTree 族系列引擎的表,首先会读取指定的列数据,来判断数据过滤,等待数据过滤之后再读取select 声明的列字段来补…
iceberg学习笔记(2)—— 与Hive集成
前置知识: 1.了解hadoop基础知识,并能够搭建hadoop集群 2.了解hive基础知识 3.Iceberg学习笔记(1)—— 基础知识-CSDN博客 可以参考: Hadoop基础入门(1):框架概述及集群环境搭建_TH…
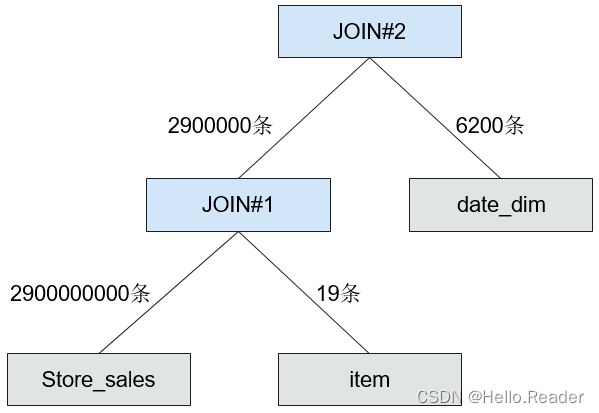
Hive【Hive(二)DML】
启动 hive 命令行:
hive
DML 数据操作
1、数据导入
1.1、向表中装载数据(load)
语法:
hive> load data [local] inpath 数据的path [overwrite] into table student [partition (partcol1val1,…)];(1&#x…

帮助开放大学学子们更好学习的铺助工具
添加图片注释,不超过 140 字(可选) 随着社会的发展和科技的进步,教育领域也在不断创新和改进。广东开放大学作为广东省最具影响力的开放大学之一,一直致力于为学生提供优质的教育资源和学习平台。 在这个信息爆炸的时代…
第1关:Hive 的 Alter Table 操作
相关知识
为了完成本关任务,你需要掌握: 1.Alter Table 命令
Alter Table 命令
Alter Table 命令 可以在 Hive 中修改表名,列名,列注释,表注释,增加列,调整列顺序,属性名等操作。…
【数据仓库设计基础(四)】数据仓库实施步骤
文章目录 1.定义范围2.确定需求3.逻辑设计1)建立需要的数据列表2)识别数据源3)制作实体关系图 4.物理设计1)性能优化2)数仓的拓展性 5.装载数据6.…
Hive【Hive(三)查询语句】
前言 今天是中秋节,早上七点就醒了,干啥呢,大一开学后空教室紧缺,还不趁着假期来学校等啥呢。顺便偷偷许个愿吧,希望在明年的这个时候,秋招不知道赶不赶得上,我希望拿几个国奖,蓝桥杯…
一百八十八、Hive——HiveSQL查询表中的日期是星期几(亲测,附截图)
一、目的
指标需要查询以工作日和周末维度的数据统计,因此需要根据数据的日期判断这一天属于星期几,周一到周五为工作日,周六到周日为周末
二、SQL查询
(一)SQL语句
selectday,case when pmod(datediff(create_tim…
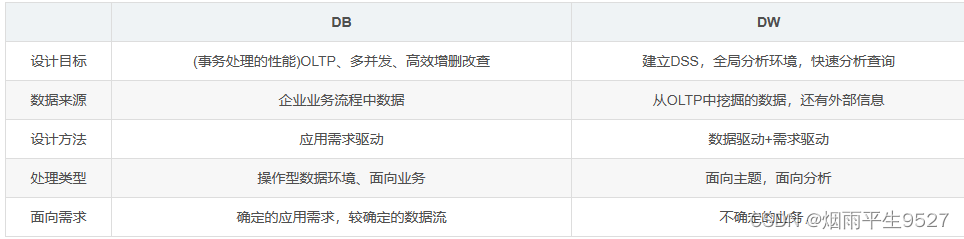
数据仓库与数据挖掘(1)概述
一、数据仓库和数据挖掘概述
1.1 数据仓库的产生
数据仓库与数据挖掘: 数据仓库和联机分析处理技术(存储)。数据挖掘:在大量的数据中心挖掘感兴趣的知识、规则、规律、模式、约束(分析)。数据仓库用于决策分析: 数据仓库:是在数…
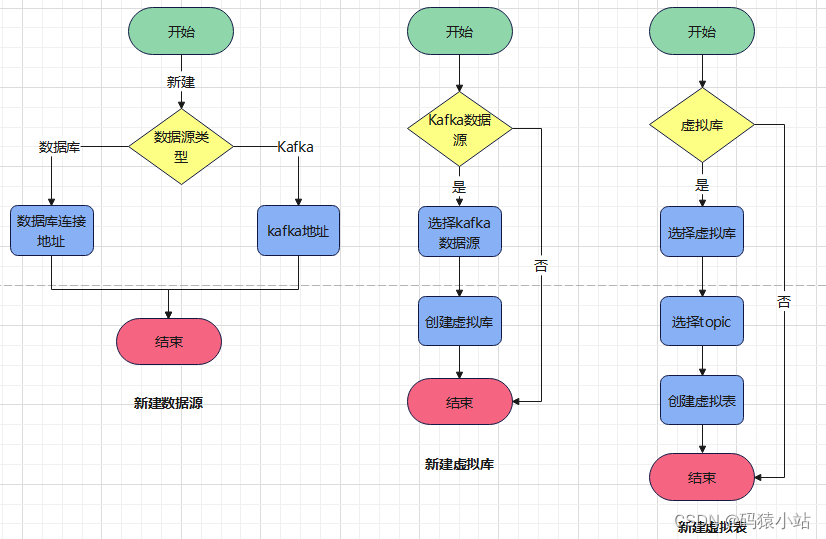
【数据中台建设系列之一】数据中台-元数据管理
本编文章主要介绍数据中台核心模块—元数据模块的一些建设经验分享,供大家一起交流学习。 一、什么是元数据
元数据可以简单理解为是数据的"数据",它描述了数据的特征,属性,来源和其他一些数据的基本信息࿰…
Doris安全删除BE节点
DECOMMISSION 语句如下:
ALTER SYSTEM DECOMMISSION BACKEND "be_host:be_heartbeat_service_port"; DECOMMISSION 命令说明: 该命令用于安全删除 BE 节点。命令下发后,Doris 会尝试将该 BE 上的数据向其他 BE 节点迁移࿰…
Git 基本操作【本地仓库与远程仓库的推送、克隆和拉取】
文章目录 一、Git简介二、Git的下载安装三、Git常规命令四、新建本地仓库五、本地分支操作六、Git远程仓库七、远程仓库克隆、抓取和拉取八、总结九、学习交流 一、Git简介
Git是分布式版本控制系统(Distributed Version Control System,简称 DVCS&…

大数据项目实战(安装Hive)
一,搭建大数据集群环境
1.3 安装Hive
1.3.1 Hive的安装
1.安装MySQL服务
1)检查是否安装MySQL,如安装将其卸载。卸载命令 rpm -qa | grep mysql 2)搜索MySQL文件夹,如存在则删除 find / -name mysql rm -rf /etc/s…
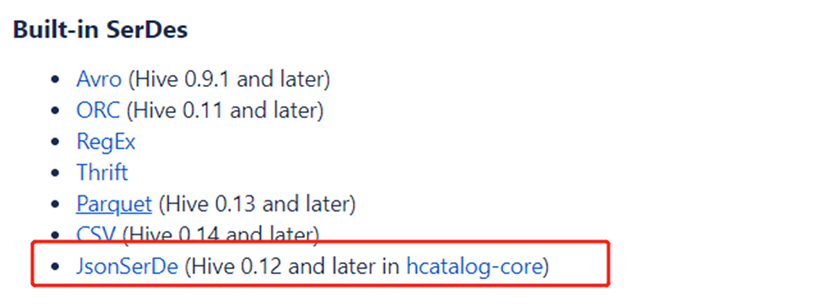
【Hive】——函数案例
1 Hive 多字节分隔符处理
1.1 默认规则
Hive默认序列化类是LazySimpleSerDe,其只支持使用单字节分隔符(char)来加载文本数据,例如逗号、制表符、空格等等,默认的分隔符为”\001”。根据不同文件的不同分隔符…
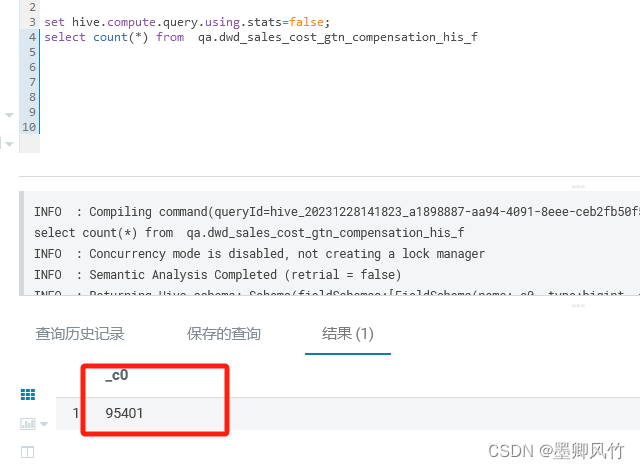
hive在执行elect count(*) 没有数据显示为0(实际有数据)
set hive.compute.query.using.statsfalse; 是 Hive 的一个配置选项。它的含义是禁用 Hive 在执行查询时使用统计信息。
在 Hive 中,统计信息用于优化查询计划和执行。当该选项设置为 false 时,Hive 将不会使用任何统计信息来帮助决定查询的执行计划。这…
Hive中parquet压缩格式分区表的跨集群迁移记录
文章目录 环境与需求集群环境需求描述 操作步骤STEP 1STEP 2STEP 3STEP 4STEP 5STEP 6 环境与需求
集群环境
华为FushionInsight A
华为FushionInsight B
华为集群管理机 local
Hive 3.1.0
HDFS 3.3.1
需求描述
从华为A集群中将我们的数据迁移到华为B集群,其…
spark rdd和dataframe的区别,结合底层逻辑
在 Apache Spark 中,RDD(Resilient Distributed Dataset)和 DataFrame 是处理数据的两种不同的抽象。
RDD (Resilient Distributed Dataset) 底层实现: RDD 是 Spark 最初的数据抽象,表示一个分布式的、不可变的数据集…
Hive的几种排序方式、区别,使用场景
一、几种排序和区别
Hive 支持两种主要的排序方式:ORDER BY 和 SORT BY。除此之外,还有 DISTRIBUTE BY 和 CLUSTER BY 语句,它们也在排序和数据分布方面发挥作用。
1. ORDER BY
ORDER BY 在 Hive 中用于对查询结果进行全局排序࿰…
16. 常用shell之 sort - 排序文本文件中的行 的用法和衍生用法
sort 命令是 Linux 和 Unix 系统中用于排序文本文件行的工具。它可以根据文本文件中的内容进行排序,是文本处理中非常有用的命令。
基本用法
默认排序: 命令:sort filename功能:按照字符编码顺序(通常是 ASCII)排序文…
数据库产品层出不穷,金融行业应该怎么选?|飞轮科技联合创始人连林江
众所周知,金融行业对于数据有着极为严苛的标准和要求,尤其当在线化、实时化业务场景增多以后,金融行业也面临着多重的挑战:既要满足实时数据分析的高性能、高效率需求,又要确保数据的安全性和完整性。基于此࿰…
【Hive】——DDL(CREATE TABLE)
1 CREATE TABLE 建表语法 2 Hive 数据类型 2.1 原生数据类型 2.2 复杂数据类型 2.3 Hive 隐式转换 2.4 Hive 显式转换 2.5 注意 3 SerDe机制 3.1 读写文件机制 3.2 SerDe相关语法 3.2.1 指定序列化类(ROW FORMAT SERDE ‘’) 3.2.2 指定分隔符࿰…

07用户行为日志数据采集
用户行为数据由Flume从Kafka直接同步到HDFS,由于离线数仓采用Hive的分区表按天统计,所以目标路径要包含一层日期。具体数据流向如下图所示。 按照规划,该Flume需将Kafka中topic_log的数据发往HDFS。并且对每天产生的用户行为日志进行区分&am…
运行hive的beelin2时候going to print operations logs printed operations logs
运行hive的beelin2时候going to print operations logs printed operations logs 检查HiveServer2的配置文件hive-site.xml,确保以下属性被正确设置:
<property><name>hive.async.log.enabled</name><value>false</value>…

hive企业级调优策略之Join优化
测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511
本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
Join算法概述
Hive拥有多种join算法,包括Common Join,Map …
ETL-从1学到100(1/100):ETL涉及到的名词解释
本文章主要介绍ETL和大数据中涉及到名词,同时解释这些名词的含义。由于不是一次性收集这些名词,所以这篇文章将会持续更新,更新日志会存放在本段话下面:
12-19更新:OLTP、OLAP、BI、ETL。 1. OLTP
中文称呼ÿ…
Hive Serde
Hive Serde
目的:
Hive Serde用来做序列化和反序列化,构建在数据存储和执行引擎之间,对两者实现解耦。
应用场景:
1、hive主要用来存储结构化数据,如果结构化数据存储的格式嵌套比较复杂的时候,可…
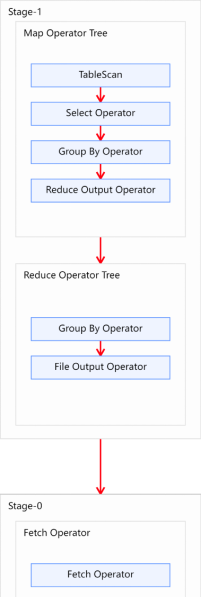
hive企业级调优策略之分组聚合优化
测试用表准备
hive企业级调优策略测试数据 (阿里网盘下载链接):https://www.alipan.com/s/xsqK6971Mrs
订单表(2000w条数据)
表结构 建表语句
drop table if exists order_detail;
create table order_detail(id string comment 订单id,user_id …
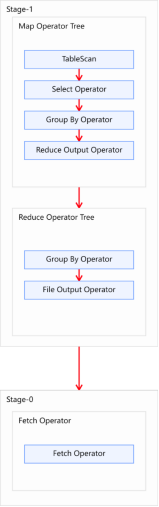
hive企业级调优策略之如何用Explain查看执行计划
Explain执行计划概述
Explain呈现的执行计划,由一系列Stage组成,这一系列Stage具有依赖关系,每个Stage对应一个MapReduce Job,或者一个文件系统操作等。 若某个Stage对应的一个MapReduce Job,其Map端和Reduce端的计算…

CloudCanal x Debezium 打造实时数据流动新范式
简述
Debezium 是一个开源的数据订阅工具,主要功能为捕获数据库变更事件发送到 Kafka。
CloudCanal 近期实现了从 Kafka 消费 Debezium 格式数据,将其 同步到 StarRocks、Doris、Elasticsearch、MongoDB、ClickHouse 等 12 种数据库和数仓,…

利用NPS跟踪客户忠诚度:问卷调查实用指南与技巧分享
许多营销人员表示,净推荐值(NPS)是任何行业成功的主要衡量标准。同时,它也是衡量客户忠诚度的绝佳工具。我们可以将NPS问题引入问卷调查中,从而获取出真实的数据。NPS是怎么衡量顾客的?NPS将顾客分为推荐者…
Hive HWI 配置
前言
1、下载安装好hive后,发现hive有hwi界面功能,研究下是否可以运行,于是使用hive –service hwi命令启动hwi界面报错。 启动hwi功能 2、访问192.168.126.110:9999/hwi,发现访问错误 一、HWI介绍
HWI(Hive Web Int…

初识大数据,一文掌握大数据必备知识文集(6)
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…
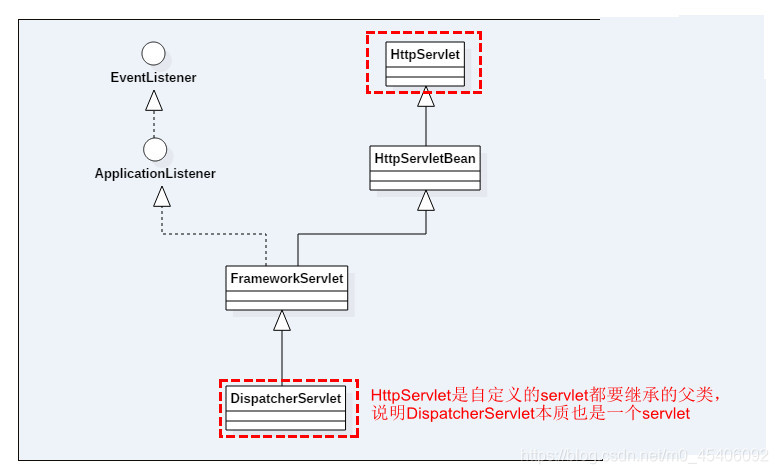
SpringMVC源码解析——DispatcherServlet初始化
在Spring中,ContextLoaderListener只是辅助功能,用于创建WebApplicationContext类型的实例,而真正的逻辑实现其实是在DispatcherServlet中进行的,DispatcherServlet是实现Servlet接口的实现类。Servlet是一个JAVA编写的程序&#…
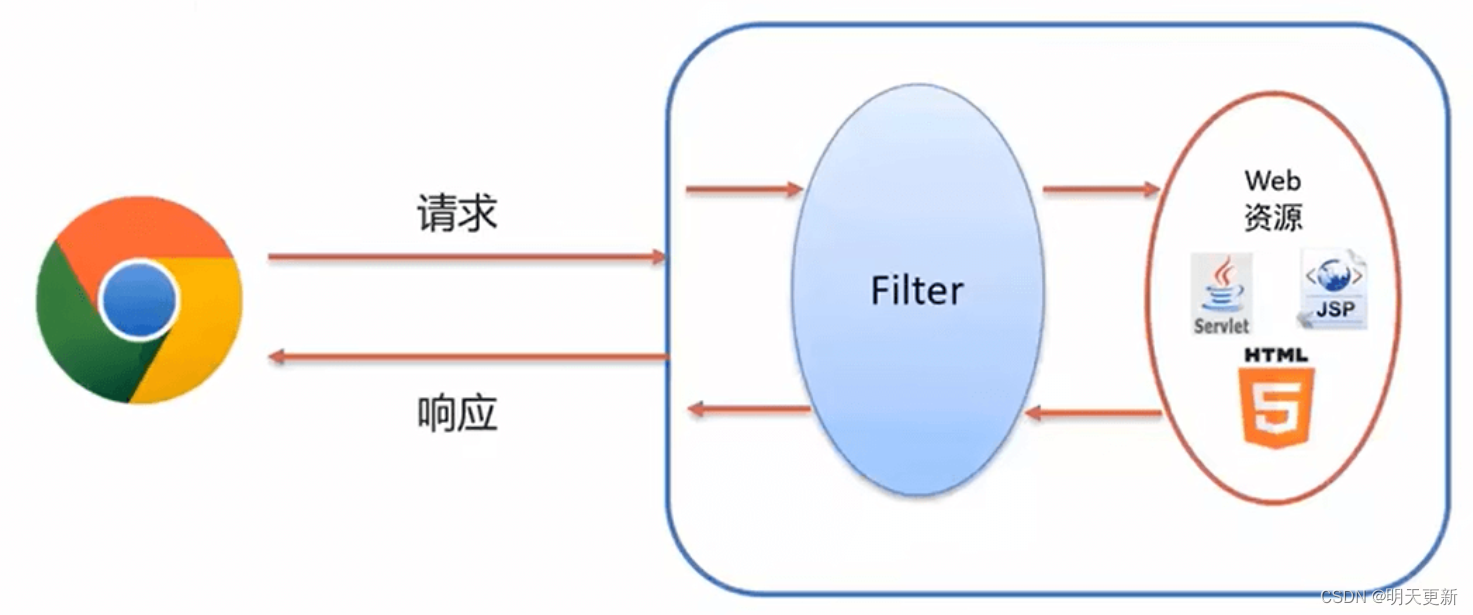
Filter过滤器的使用!!!
什么是过滤器
当浏览器向服务器发送请求的时候,过滤器可以将请求拦截下来,完成一些特殊的功能,比如:编码设置、权限校验、日志记录等。 过滤器执行流程 过滤器的使用:
/** Copyright (c) 2020, 2023, All rights …
Hive自定义函数详解
1.hive函数各种命令
查看系统自带的函数
hive> show functions;
-- 显示自带的函数的用法
hive> desc function upper;
-- 详细显示自带的函数的用法
hive> desc function extended upper;
-- 添加jar包到hive中
add jar /data/xx.jar;
-- 创建自定义函数
create fu…

项目管理工具:媒体制作团队高效管理工作的必备利器
媒体制作机构是为内容创作者提供专业支持的公司,他们会与创作者签订合同,帮助他们管理频道、增加观众和收入。国内许多媒体制作团队依托于抖音、快手、B站、小红书等平台。本文将介绍一家媒体制作团队如何使用Zoho Projects项目管理工具来成功优化工作流…
Doris数仓开发规范
文章目录 一、字符集规范二、建表规范三、数据变更规范四、数据查询规范结尾 一、字符集规范
【强制】数据库字符集指定utf-8,并且只支持utf-8。 二、建表规范
【建议】库名统一使用小写方式,中间用下划线(_)分割,长…

【数据仓库与联机分析处理】数据仓库
目录
一、数据仓库的概念
二、数据仓库与操作性数据库的区别
三、发展前期
四、数据仓库的系统结构
五、建模划分
六、主要案例 一、数据仓库的概念 目前很难给数据仓库(Data Warehouse)一个严格的定义,不准确地说,数据仓库…


HttpSession的使用
1 HttpSession 概述
在 Java Servlet API 中引入 session 机制来跟踪客户的状态。session 指的是在一段时间内,单个客户与 Web 服务器的一连串相关的交互过程。在一个 session 中,客户可能会多次请求访问同一个网页,也有可能请求访问各种不同…

Hive - Select 使用 in 限制范围
目录
一.引言
二.Select Uid Info
1.少量 Uid
2.大量 Uid
◆ 建表
◆ 本地 Load
◆ HDFS Load
◆ Select In
三.总结 一.引言
工业场景下 Hive 表通常使用 uid 作为用户维度构建和更新 Hive 表,当我们需要查询指定批次用户信息时,可以使用 in …

HiveSQL题——collect_set()/collect_list()聚合函数
一、collect_set() /collect_list()介绍 collect_set()函数与collect_list()函数属于高级聚合函数(行转列),将分组中的某列转换成一个数组返回,常与concat_ws()函数连用实现字段拼接效果。 collect_list:收集并形成lis…
软考笔记--数据仓库技术
数据仓库是一个面向主题的,集成的,相对稳定的、反映历史变化的数据集合,用于支持管理决策。数据源是数据仓库系统的基础,是整个系统的数据源泉。OLAP(联机分析处理)服务器对分析需要的数据进行有效集成&…
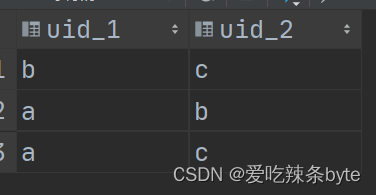
HiveSQL——共同使用ip的用户检测问题【自关联问题】
注:参考文章:
SQL 之共同使用ip用户检测问题【自关联问题】-HQL面试题48【拼多多面试题】_hive sql 自关联-CSDN博客文章浏览阅读810次。0 问题描述create table log( uid char(10), ip char(15), time timestamp);insert into log valuesinsert into l…
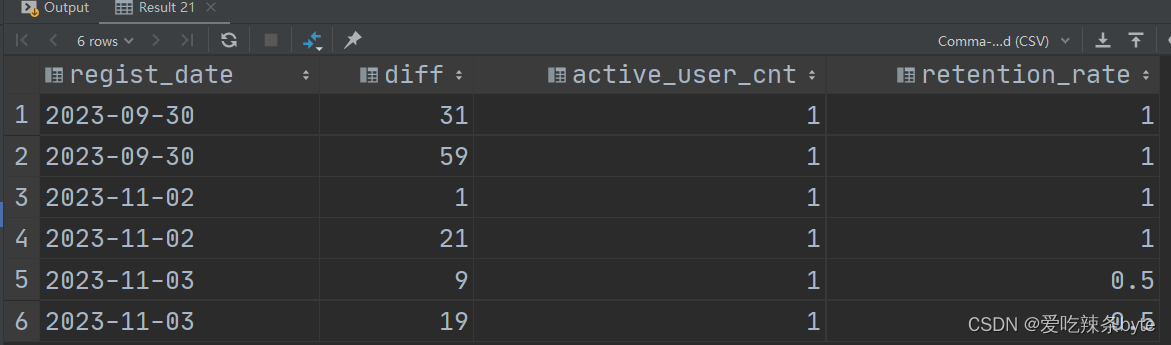
HiveSQL——设计一张最近180天的注册、活跃留存表
0 问题描述 现有一个用户活跃表user_active(user_id,active_date)、 用户注册表user_regist(user_id,regist_date),表中分区字段都为dt(yyyy-MM-dd),用户字段均为user_id; 设计一张 1-180天的注册活跃留存表;表结构如下: 1 数据分…

HiveSQL——sum(if()) 条件累加
注:参考文章:
HiveSql面试题10--sum(if)统计问题_hive sum if-CSDN博客文章浏览阅读5.8k次,点赞6次,收藏19次。0 需求分析t_order表结构字段名含义oid订单编号uid用户idotime订单时间(yyyy-MM-dd)oamount订…

StarRocks 在金融科技行业的存算分离应用实践
小编导读:
自从 2023 年 4 月正式推出 3.0 版本的存算分离功能以来,目前已有包含芒果TV、聚水潭、网易邮箱、浪潮、天道金科等数十家用户完成测试,多家用户也已开始逐步将其应用于实际业务中。目前,StarRocks 存算分离上线的场景…
数据仓库_维度表的两大分类
最近看一篇文章对维度表进行了分类,记录一下。
维度表主要分为两类高基数维度表和低基数维度表。 高基数维度数据
一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。 低基数维度数据
一般是配置表,比如枚举值对应的中文含…

【数据仓库设计基础1】关系数据模型理论与数据仓库Inmon方法论
文章目录 一. 关系数据模型中的结构1.关系2.属性3.属性域4.元组5. 关系数据库6.关系表的属性7.关系数据模型中的键 二. 关系完整性1.空值(NULL)2.关系完整性规…
clickhouse 系列2:clickhouse 离线安装
1.下载rpm包 Altinity/clickhouse - Packages packagecloud 使用wget下载到本地目录 wget --content-disposition https://packagecloud.io/Altinity/clickhouse/packages/el/7/clickhouse-common-static-20.8.3.18-1.el7.x86_64.rpm/download.rpm
wget
ClickHouse进阶(五):副本与分片-1-
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 📌订阅…

数据的真正价值是数据要素市场化开发
随着人工智能、互联网、物联网、大数据、云计算、区块链等新一代信息化、数字化技术的应用,各行各业都开始了新一轮的产业革命和转型升级。在这个过程中,数据伴随着信息化、数字化的推进越发变得重要,到了2020年直接成为了继土地、劳动力、资…
hive电子商务消费行为分析
hive电子商务消费行为分析 1. 掌握Zeppelin的使用 2. 了解数据结构 3.数据清洗 4. 基于Hive的数据分析 1.物料准备 (1)Customer表 customer_details details customer_id Int, 1 - 500 first_name string last_name string email s…
T-ETL和ELT区别
ETL表示提取、转换和加载;ELT表示提取、加载和转换。都是用于数据集成。 两者区别
ETL和ELT在数据集成过程中有着明显的区别。
ETL
ETL,即抽取、转换、加载,是从不同的数据源抽取信息,将其转换为根据业务定义的格式,…
clickhouse系列3:clickhouse分析英国房产价格数据
1.准备数据集 该数据集包含有关英格兰和威尔士自1995年起到2023年的房地产价格的数据,超过2800王条记录,未压缩形式的数据集大小超过4GB,在ClickHouse中需要约306MB。 2.clickhouse中建表 CREATE TABLE uk_price_paid
(price UInt32,

Hadoop-Hive
1. hive安装部署 2. hive基础 3. hive高级查询 4. Hive函数及性能优化 1.hive安装部署 解压tar -xvf ./apache-hive-3.1.2-bin.tar.gz -C /opt/soft/ 改名mv apache-hive-3.1.2-bin/ hive312 配置环境变量:vim /etc/profile #hive export HIVE_HOME/opt/soft/hive…
Hive【非交互式使用、三种参数配置方式】
前言 今天开始学习 Hive,因为毕竟但凡做个项目基本就避不开用 Hive ,争取这学期结束前做个小点的项目。 第一篇博客内容还是比较少的,环境的搭建配置太琐碎没有写。
Hive 常用使用技巧
交互式使用
就是我们正常的进入 hive 命令行下的使用…
Flink+Paimon多流拼接性能优化实战
目录
(零)本文简介
(一)背景
(二)探索梳理过程
(三)源码改造
(四)修改效果
1、JOB状态
2、Level5的dataFile总大小
3、数据延迟
(五&…
线上问诊:数仓开发(一)
系列文章目录
线上问诊:业务数据采集 线上问诊:数仓数据同步 线上问诊:数仓开发(一) 文章目录 系列文章目录前言一、Hive on yarn二、数仓开发1.ODS开发2.DIM开发3.DWD开发 总结 前言
上次我们已经将MYSQL的数据传送到了HDFS,但…
Hive SQL 优化大全(参数配置、语法优化)
文章目录 参数配置优化yarn-site.xml 配置文件优化mapred-site.xml 配置文件优化 分组聚合优化 —— Map-Side优化参数解析优化案例 服务器环境说明
机器名称内网IP内存CPU承载服务master192.168.10.1084NodeManager、DataNode、NameNode、JobHistoryServer、Hive、HiveServer…
小红书官方平台API接口根据关键词获取商品列表页、产品图片、产品销量、价格信息示例
关键词搜索商品API接口可以提供给电商平台一些有用的数据分析。例如,通过分析用户搜索的关键词,电商平台可以了解用户的购物偏好和需求,从而改进自己的商品推荐系统,并且还可以帮助广告主实现精准定位服务。广告主可以利用该接口&…

如何破解企业数字化转型的焦虑
在今年整体的大环境下,焦虑的不仅是个人,还有数字化转型中的企业。
01 焦虑中的企业数字化
焦虑往往不是来源于无知,而是未知!
现阶段还未采取行动的企业会焦虑:现在开始是否会落后,市场红利是否会错过&…
阿里云-AnalyticDB【分析型数据库】总结介绍
一、背景 随着企业IT和互联网系统的发展,产生了越来越多的数据。数据量的积累带来了质的飞跃,使得数据应用从业务系统的一部分演变得愈发独立。物流、交通、新零售等越来越多的行业需要通过OLAP做到精细化运营,从而调控生产规则、运营效率、企…
[Hive] if返回null和0的区别
count(if(pv>1000000,1,0))count(if(pv>1000000,1,null))
区别
count(if(pv>1000000,1,0)) 和 count(if(pv>1000000,1,null)) 之间的区别在于对于不满足条件的情况下的处理方式。 count(if(pv>1000000,1,0)):这个表达式中,如果 pv 的值…

数据仓库扫盲系列(1):数据仓库诞生原因、基本特点、和数据库的区别
数据仓库的诞生原因
随着互联网的普及,信息技术已经深入到各行各业,并逐步融入到企业的日常运营中。然而,当前企业在信息化建设过程中遇到了一些困境与挑战。
1、历史数据积存。
过去企业的业务系统往往是在较长时间内建设的,很…
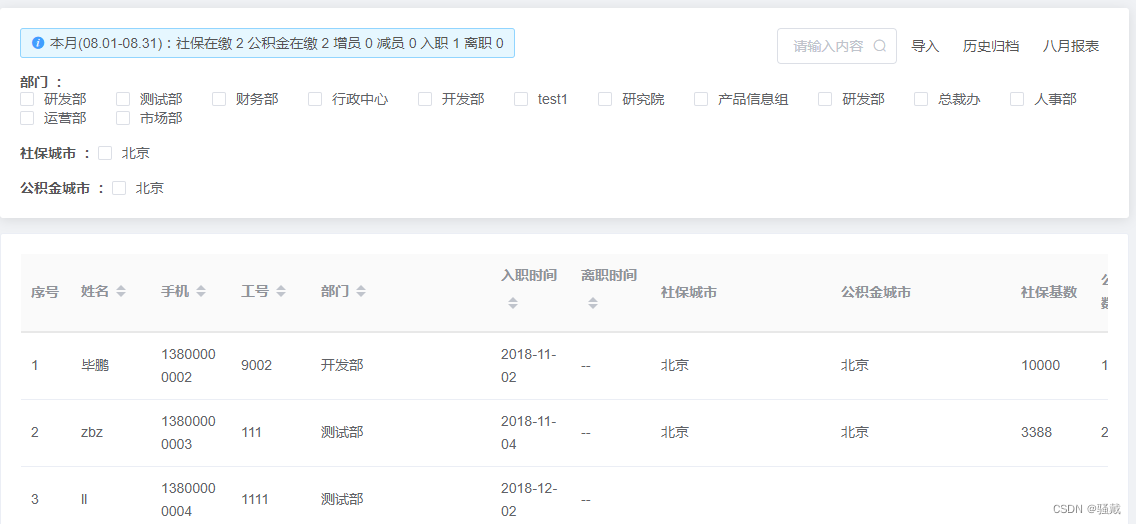
API网关与社保模块
API网关与社保模块 理解zuul网关的作用完成zuul网关的搭建 实现社保模块的代码开发 zuul网关 在学习完前面的知识后,微服务架构已经初具雏形。但还有一些问题:不同的微服务一般会有不同的网 络地址,客户端在访问这些微服务时必须记住几十甚至…

分布式存储 vs. 全闪集中式存储:金融数据仓库场景下的性能对比
作者:深耕行业的 SmartX 金融团队 张德敏
近年来随着金融行业的高速发展,经营决策者及监管机构对信息时效性的要求越来越高,科技部门面临诸多挑战。例如,不少金融机构使用数仓业务系统,为公司高层提供日常经营报表&am…

数据湖Iceberg介绍和使用(集成Hive、SparkSQL、FlinkSQL)
文章目录 简介概述作用特性数据存储、计算引擎插件化实时流批一体数据表演化(Table Evolution)模式演化(Schema Evolution)分区演化(Partition Evolution)列顺序演化(Sort Order Evolution&…
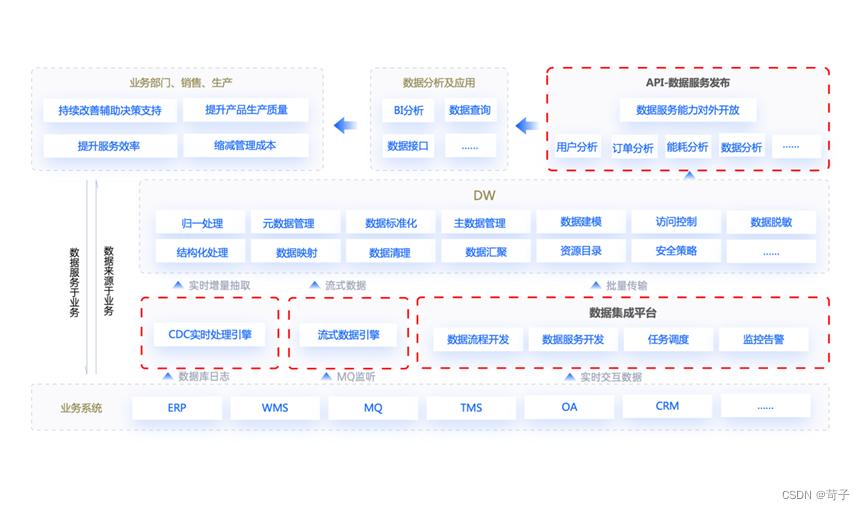
ETLCloud制造业轻量级数据中台解决方案
制造业数据处理特点
制造业在业务发展过程中产生大量的业务交易数据以及设备运行过程中的状态数据,但是制造业有别于其他互联网或零售行业,其数据处理具有以下特点:
数据量不大,大部分业务系统的数据库表在1000W以下数据结构复杂…
Hive的静态分区与动态分区
在 Hive 中,分区是一种组织数据的方式,允许你将表数据划分成更小的子集,以便更有效地管理和查询大型数据集。分区可以分为静态分区和动态分区,它们有不同的特点和用途。
1. 静态分区(Static Partitioning):
静态分区是在创建表时显式定义的分区方式。在静态分区中,你…
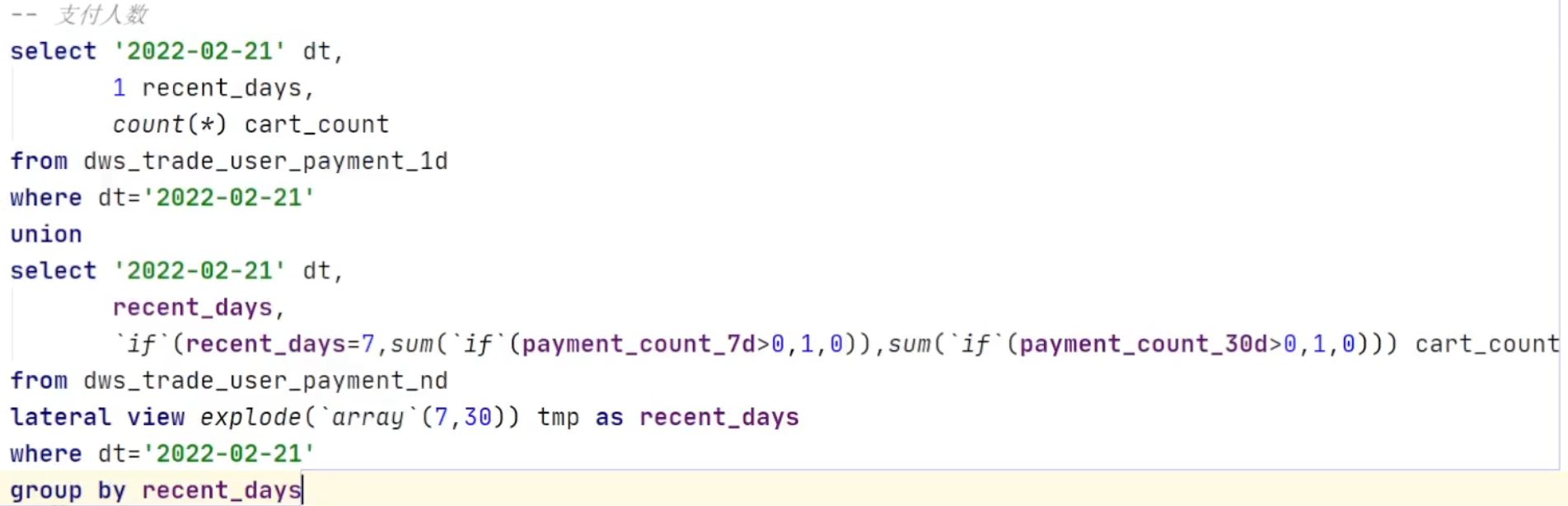
尚硅谷大数据项目《在线教育之离线数仓》笔记006
视频地址:尚硅谷大数据项目《在线教育之离线数仓》_哔哩哔哩_bilibili 目录
第11章 数仓开发之ADS层
P087
P088
P089
P090
P091
P092
P093
P094
P095
P096
P097
P098
P099
P100
P101
P102
P103
P104
P105
P106
P107
P108
P109
P110
P111 …

【ODPS新品发布第1期】DataWorks全新发布:增强分析/数据建模个人版等新能力
阿里云ODPS系列产品以MaxCompute、DataWorks、Hologres为核心,致力于解决用户多元化数据的计算需求问题,实现存储、调度、元数据管理上的一体化架构融合,支撑交通、金融、科研、等多场景数据的高效处理,是目前国内最早自研、应用最…

ClickHouse进阶(七):Clickhouse数据查询-1
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 📌订阅…

四维纵横与用友达成战略合作,携手打造企业数据智能新基座
近日,北京四维纵横数据技术有限公司(四维纵横 YMatrix)与用友网络科技股份有限公司(用友),宣布达成产品战略合作协议。双方将共同致力于为企业提供一站式数据智能解决方案,加速企业应用的全方位…

Hive_Hive统计指令analyze table和 describe table
之前在公司内部经常会看到表的元信息的一些统计信息,当时非常好奇是如何做实现的。
现在发现这些信息主要是基于 analyze table 去做统计的,分享给大家
实现的效果某一个表中每个列的空值数量,重复值数量等,平均长度
具体的指令…

【Hive】drop table需注意外部表
什么是内部表,外部表?
比较专业的定义: 外部表需要转为内部表,执行删除操作才能真的删表结构删表数据。否则drop table仅是删除了表数据,表结构还是存在的。
alter table tb_name set TBLPROPERTIES(EXTERNALfalse);…

ClickHouse 存算分离改造:小红书自研云原生数据仓库实践
ClickHouse 作为业界性能最强大的 OLAP 系统,在小红书内部被广泛应用于广告、社区、直播和电商等多个业务领域。然而,原生 ClickHouse 的 MPP 架构在运维成本、弹性扩展和故障恢复方面存在较大局限性。为应对挑战,小红书数据流团队基于开源 C…
Hive行转列[一行拆分成多行/一列拆分成多列]
场景:
hive有张表armmttxn_tmp,其中有一个字段lot_number,该字段以逗号分隔开多个值,每个值又以冒号来分割料号和数量,如:A3220089:-40,A3220090:-40,A3220091:-40,A3220083:-40,A3220087:-40,A3220086:-4…
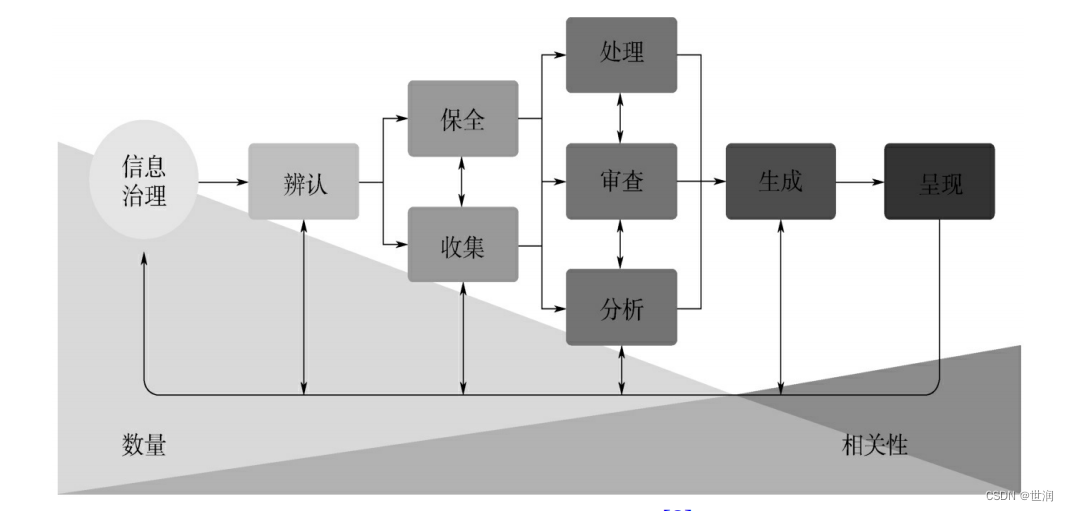
数据治理-EDRM电子取证
EDRM是电子取证标准和指南的组织,该框架提供了一种电子取证的方法,对于涉及确定相关内部数据的存储方式和位置、适用什么保留策略、哪些数据不可访问以及哪些工具可用于协助识别流程的人员来说,这种方法非常方便。 EDRM模型假定数据或信息治理已到位。该模型包括8个…
Hive的Join连接
前言 Hive-3.1.2版本支持6种join语法。分别是:inner join(内连接)、left join(左连接)、right join(右连接)、full outer join(全外连接)、left semi join(左…

Hive11_Rank函数
Rank
1)函数说明
RANK() 排序相同时会重复,总数不会变 DENSE_RANK() 排序相同时会重复,总数会减少 ROW_NUMBER() 会根据顺序计算
2)数据准备 3)需求
计算每门学科成绩排名。
4)创建本地 score.txt&…
数仓工具—Hive进阶之StorageHandler(23)
Storage Handler
引入Storage Handler,Hive用户使用SQL的方式读写外部数据源, 例如ElasticSearch、 Kafka、HBase等数据源的查询对非专业开发是有一定门槛的,借助Storage Handler,他们有了一种方便快捷的手段查询数据,Storage Handler作为Hive的存储插件,我们需要的时候直…
深入理解奥运会大数据架构方案
背景
某网作为某电视台在互联网上的大型门户入口,某一年成为某奥运会中国大陆地区的特权转播商,独家全程直播了某奥运会全部的赛事,积累了庞大稳定的用户群,这些用户在使用各类服务过程中产生了大量数据,对这些海量数…
Hive的四种排序方法
Hive的四种排序方法
hive排序方法,hive的排序方式 hive有四种排序方法: ORDER BY 、SORT BY 、DISTRIBUTE BY 、CLUSTER BY
0. 测试数据准备
--数据准备
WITH t_emp_info AS (
SELECT * FROM (VALUES (1001, 研发部, 16000 ), (1002, 市场部, 17000 ), (1003, 销售部, 1100…
Hive学习(14)json解析get_json_object()函数
一、语法
目的:在一个标准JSON字符串中,按照指定方式抽取指定的字符串。
string get_json_object(string <json>, string <path>)
参数说明 json:必填。STRING类型。标准的JSON格式对象,格式为{Key:Value, Key:Val…

StarRocks Awards 2023 年度贡献人物
2023 年行将结束。这一年,StarRocks 继续全方位大步向前迈进,在 300 贡献者的辛勤建设下,社区先后发布了 50 版本,并完成了从全场景 OLAP 到云原生湖仓的进化。
贡献者们的每一行代码、每一场布道,推动着 StarRocks 社…

【DolphinScheduler】datax读取hive分区表时,空分区、分区无数据任务报错问题解决
问题背景:
最近在使用海豚调度DolphinScheduler的Datax组件时,遇到这么一个问题:之前给客户使用海豚做的离线数仓的分层搭建,一直都运行好好的,过了个元旦,这几天突然在数仓做任务时报错,具体报…

Hive导入数据的五种方法
在Hive中建表成功之后,就会在HDFS上创建一个与之对应的文件夹,且文件夹名字就是表名; 文件夹父路径是由参数hive.metastore.warehouse.dir控制,默认值是/user/hive/warehouse; 也可以在建表的时候使用location语句指定…
物流实时数仓DWD层——1.准备工作
目录
1.创建主程序——DwdOrderRelevantApp类
2.创建DWD层的事实表——来源于订单表和订单明细表
(1)创建订单表实体类
(2)创建订单明细表实体类
(3)创建交易域:下单事务事实表实体类,并整合(1)与(2),采用下单时间
(4)创建交易域&#…

Aloudata 近期荣誉盘点!接连斩获技术创新、案例实践、投资价值等权威认可
近期,Aloudata 凭借持续的技术积累、丰富的产品与解决方案以及多样场景下的最佳实践案例,在数据智能技术创新、案例实践、投资价值等领域全面开花,接连荣获:
2023 金猿榜「大数据产业年度最具投资价值」企业,并携手首…
数据仓库(2)-认识数仓
1、数据仓库是什么
数据仓库 ,由数据仓库之父比尔恩门(Bill Inmon)于1990年提出,主要功能仍是将组织透过资讯系统之联机事务处理(OLTP)经年累月所累积的大量资料,透过数据仓库理论所特有的资料储存架构,做…

构建高效数据生态:数据库、数据仓库、数据湖、大数据平台与数据中台解析_光点科技
在数字化的浪潮中,一套高效的数据管理系统是企业竞争力的核心。从传统的数据库到现代的数据中台,每一种技术都在数据的旅程中扮演着关键角色。本文将深入探讨数据库、数据仓库、数据湖、大数据平台以及数据中台的功能和价值,帮助您构建一个符…
Hive 拉链表详解及实例
拉链表 版本迭代:hive 0.14 slowly changing dimension > hive 2.6.0 merge 事务管理 原来采用分区表,用户分区存储历史增量数据,缺点是重复数据太多 定义:数仓用于解决持续增长且存在一定时间时间范围内重复的数据 存储&…

cdh6.3.2的hive配udf
背景
大数据平台的租户要使用udf,他们用beeline连接, 意味着要通过hs2,但如果有多个hs2,各个hs2之间不能共享,需要先把文件传到hdfs,然后手动在各hs2上create function。之后就可以永久使用了,…

HIVE中关联键类型不同导致数据重复,以及数据倾斜
比如左表关联键是string类型,右表关联键是bigint类型,关联后会出现多条的情况
解决方案: 关联键先统一转成string类型再进行关联
原因:
根据HIVE版本不同,数据位数上限不同,
低版本的超过16位会出现这种…

数据仓库现代化和迁移解决方案Datametica
Datametica利用自动化将数据/工作负载/ETI/分析迁移到云,从而为企业提供支持。 Datametica是一家通过建立数据湖来帮助企业实现数据平台现代化的公司,该数据湖安全地保存结构化和非结构化数据。随着企业数据湖从各种来源收集大量数据,需要利…
Hive之set参数大全-16
配置 HiveServer2 中 Tez Workload Manager (WM) Application Master (AM) 注册的超时时间
在 Hive 中,hive.server2.tez.wm.am.registry.timeout 是一个参数,用于配置 HiveServer2 中 Tez Workload Manager (WM) Application Master (AM) 注册的超时时…
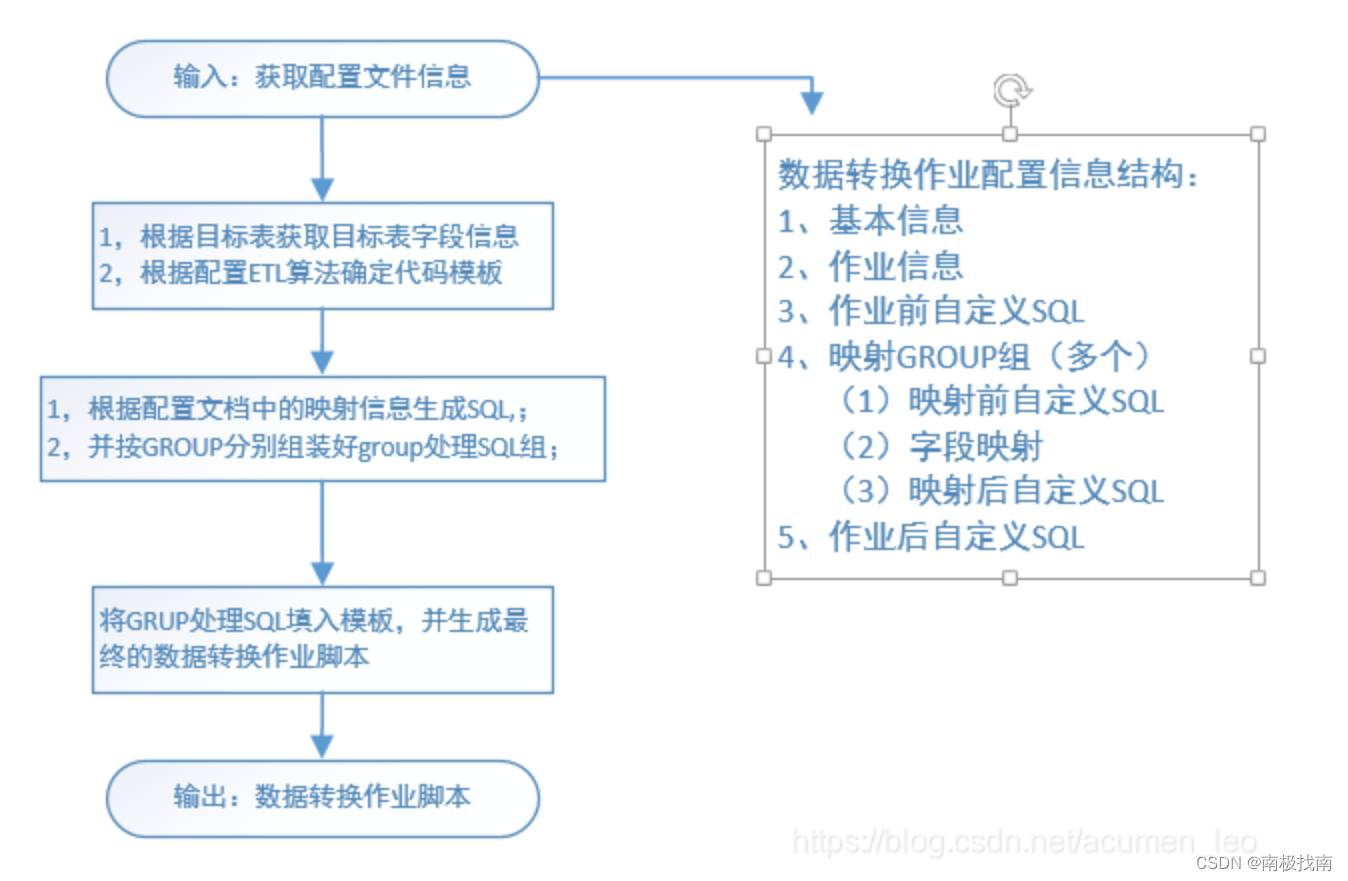
银行数据仓库体系实践(5)--数据转换
数据转换作业主要是指在数据仓库内的结构化数据批量加工,对于非结构化数据以及在线查询接口、数据流的开发主要是遵循代码开发规范以及各中间件的开发规范,如使用java来开发遵守java开发规范,使用Kafka需要遵循Kafka的使用和设计规范。同时做…
Hive中的四种排序
1.order by
全局排序,只有一个Reducer(多个reducer无法保证全局有序),会导致当输入规模较大时,消耗较长的计算时间
hive.mapred.mode strict 模式下 必须指定 limit 否则执行会报错。 2.sort by
不是全局排序&…
Hive基础知识(十一):Hive的数据导出方法示例
1. Insert 导出 1)将查询的结果导出到本地 hive (default)> insert overwrite local directory /opt/module/hive/data/export/student select * from student5;
Automatically selecting local only mode for query
Query ID atguigu_20211217153118_31119102-…
Hive基础知识(十四):Hive的八种Join使用方式与优缺点
1. 等值 Join
Hive 支持通常的 SQL JOIN 语句。 1)案例实操 (1)根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称;
select e.ename,e.empno,d.dname from emp e join dept d on e.deptno d.de…

大数据仓库开发规范示例
大数据仓库开发规范示例 一、前提概要二、数仓分层原则及定义2.1 数仓分层原则2.2 数仓分层定义 三、数仓公共开发规范3.1 分层调用规范3.2 数据类型规范3.3 数据冗余规范3.4 NULL字段处理规范3.5 公共字段规范3.6 数据表处理规范3.7 事实表划分规范 四、数仓各层开发规范4.1 分…
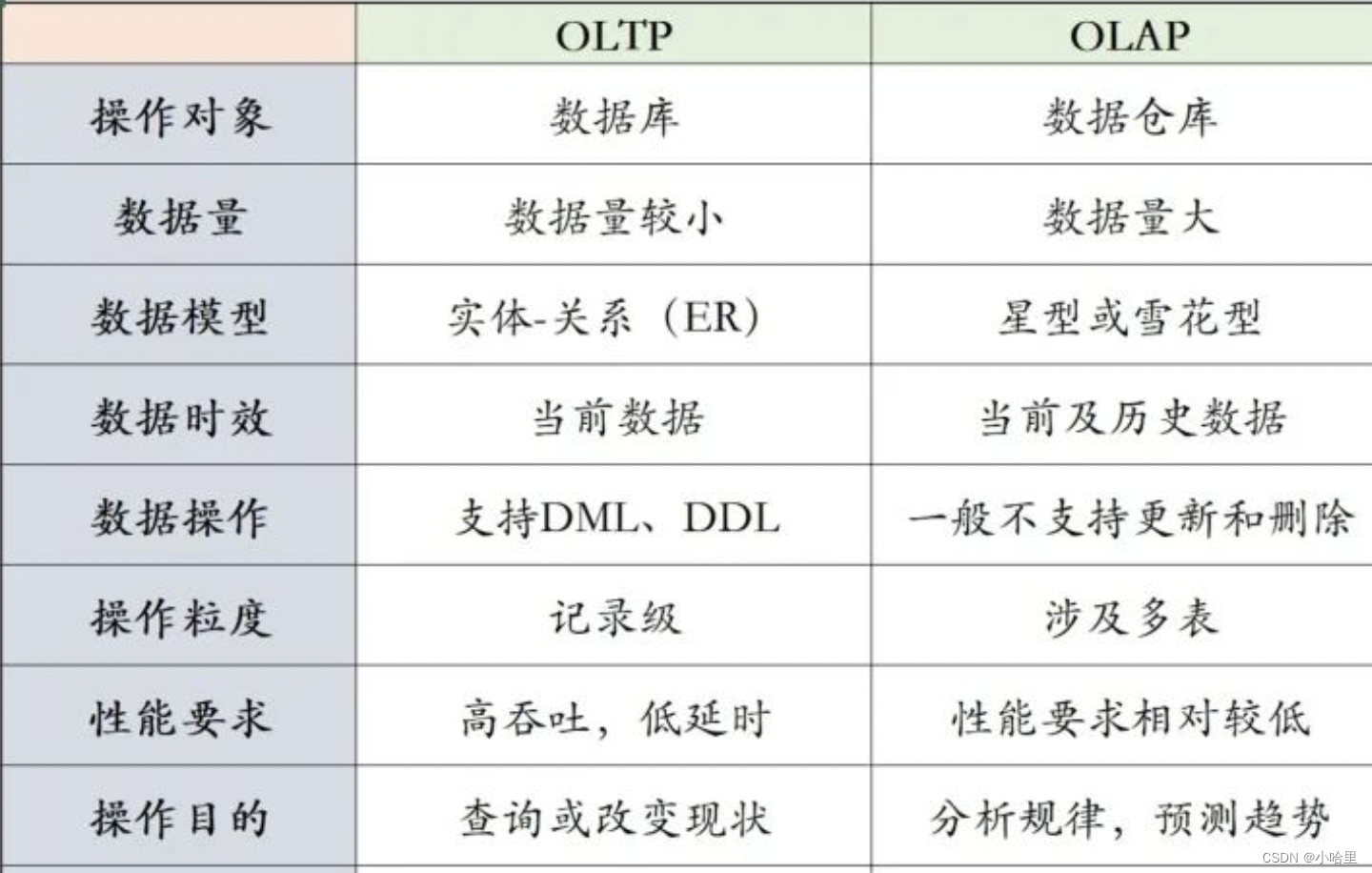
【数据开发】大型离线数仓OLAP数据开发指南(目录)
文章目录 1、什么离线数仓OLAP2、OLAP数仓建设3、OLAP数仓开发指南 1、什么离线数仓OLAP
离线数仓OLAP(Online Analytical Processing)是一种数据分析技术,它通过对离线数据仓库中的数据进行分析,为企业提供决策支持的数据分析服…

数据仓库(3)-模型建设
本文从以下9个内容,介绍数据参考模型建设相关内容。
1、OLTP VS OLAP
OLTP:全称OnLine Transaction Processing,中文名联机事务处理系统,主要是执行基本日常的事务处理,比如数据库记录的增删查改,例如mysql、oracle…
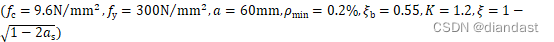
国家开放大学形成性考核 统一资料 参考试题
试卷代号:1174 水工钢筋混凝土结构(本)参考试题 一、选择题(每小题2分,共20分,在所列备选项中,选1项正确的或最好的作为答案,将选项号填入各题的括号中)
1.钢筋混凝土结…
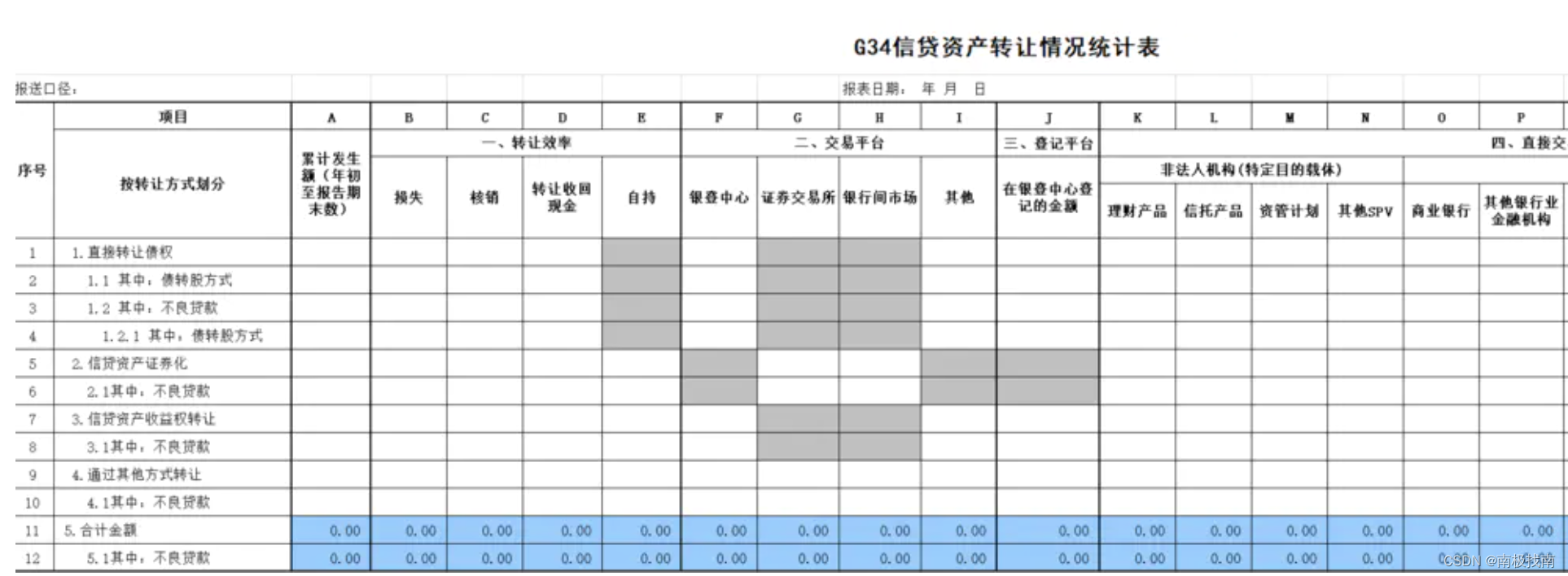
银行数据仓库体系实践(13)--数据应用之监管报送
1、监管报送概览: 我国各类银行已达到4000家左右,管理着亿万资产,已经成为我国金融体系的重要组成部分,它的稳定运行关乎到国家经济走势,关系到每个居民的生活。那在我国金融体系中,银行的主要管理者有人行…
HiveSQL题——数据炸裂和数据合并
目录
一、数据炸裂
0 问题描述
1 数据准备
2 数据分析
3 小结
二、数据合并
0 问题描述
1 数据准备
2 数据分析
3 小结
一、数据炸裂
0 问题描述 如何将字符串1-5,16,11-13,9" 扩展成 "1,2,3,4,5,16,11,12,13,9" 且顺序不变。
1 数据准备
with da…
Hive之set参数大全-20
指定在执行大表半连接操作时的最小表大小,以决定是否启用半连接操作的优化
在 Hive 中,hive.tez.bigtable.minsize.semijoin.reduction 是一个配置参数,用于指定在执行大表半连接操作时的最小表大小,以决定是否启用半连接操作的优…
HiveSQL题——array_contains函数
目录
一、原创文章被引用次数
0 问题描述
1 数据准备
2 数据分析
编辑
3 小结
二、学生退费人数
0 问题描述
1 数据准备
2 数据分析
3 小结 一、原创文章被引用次数
0 问题描述 求原创文章被引用的次数,注意本题不能用关联的形式求解。
1 数据准备 i…
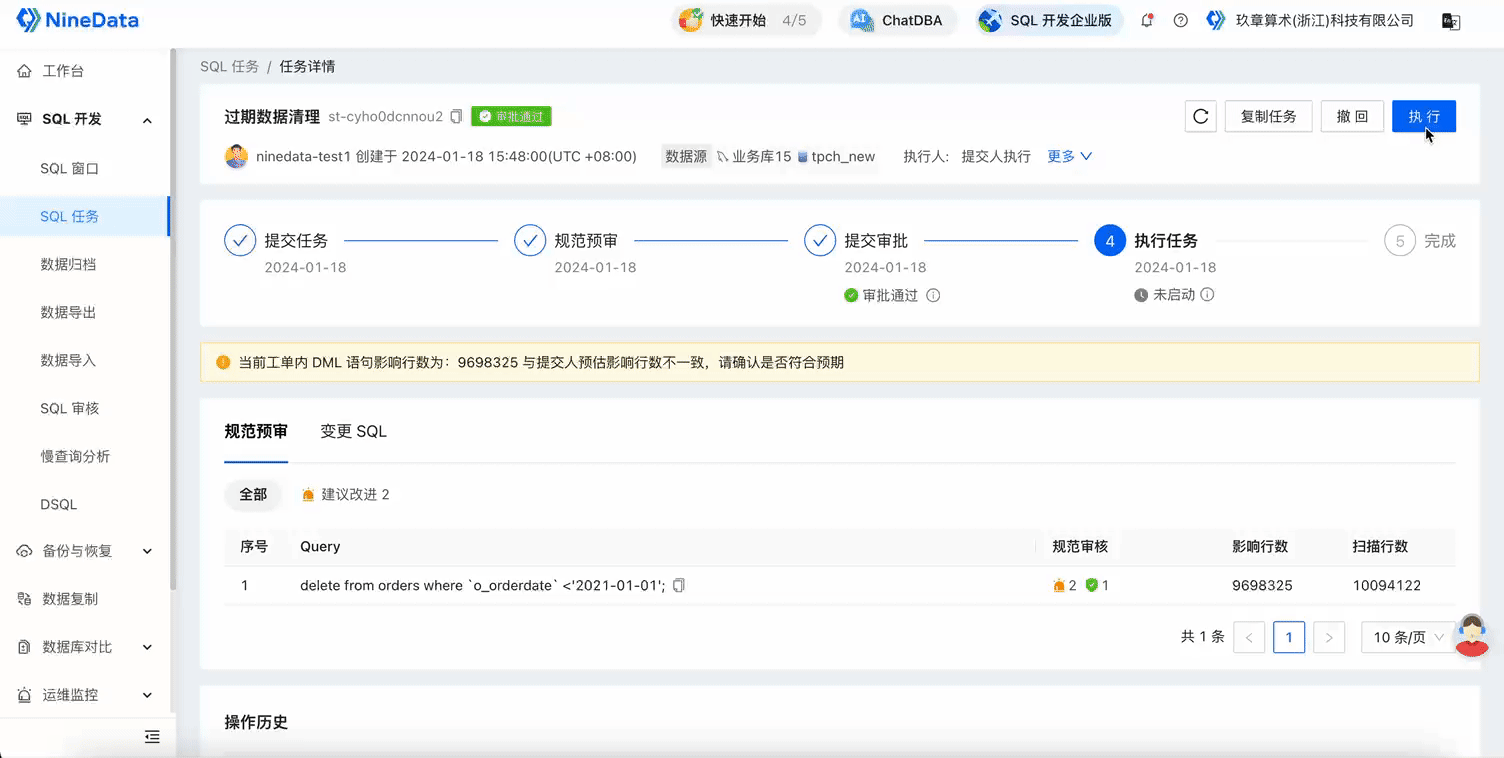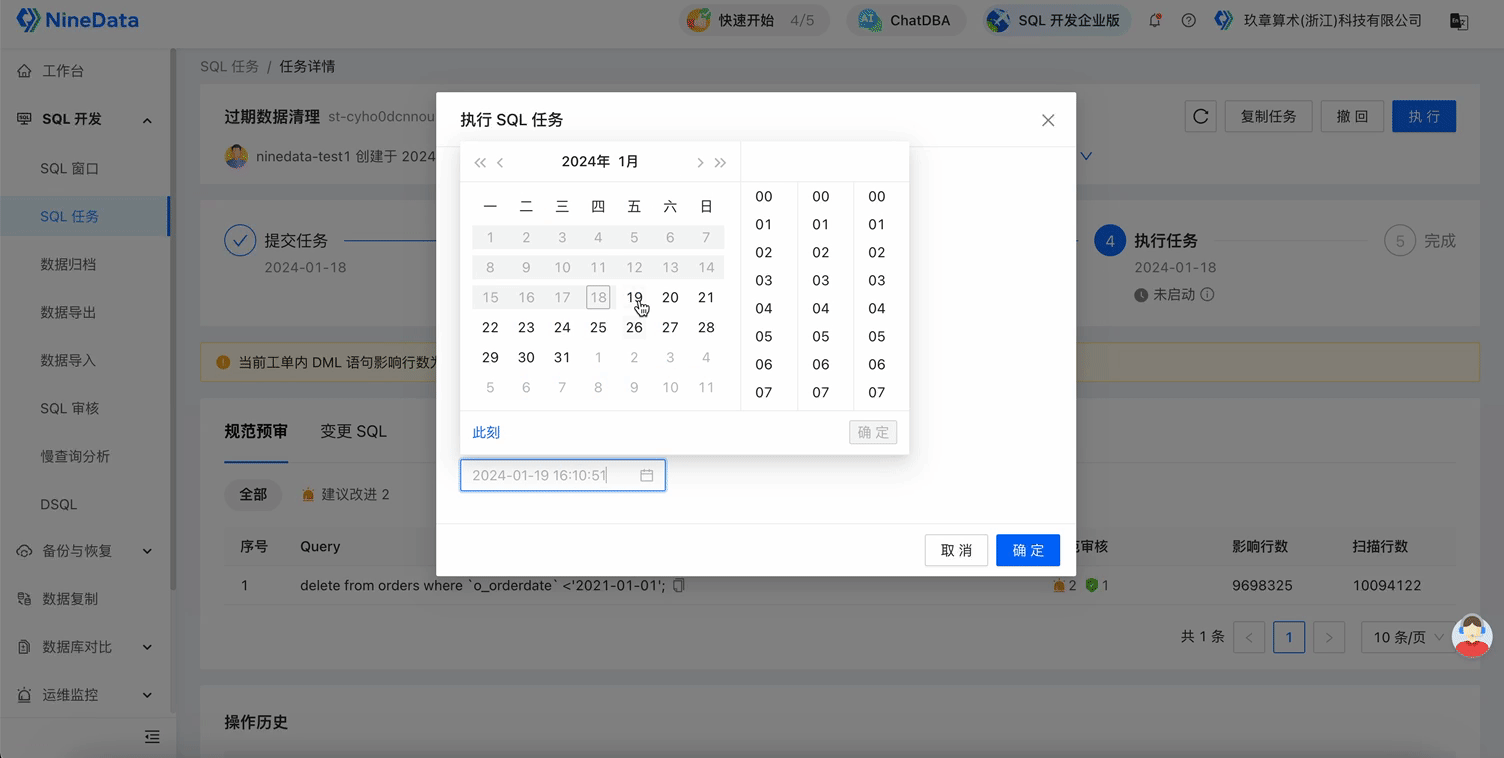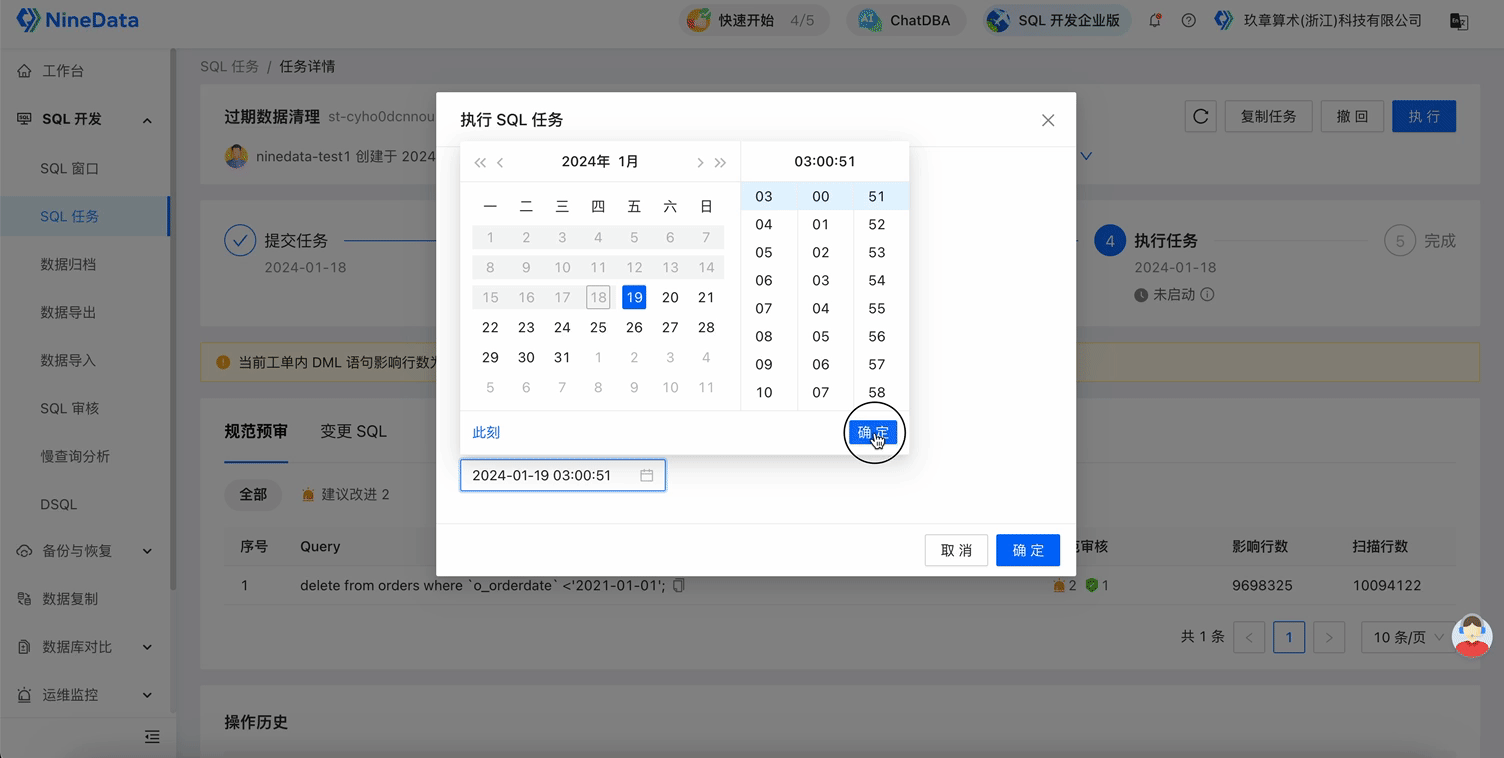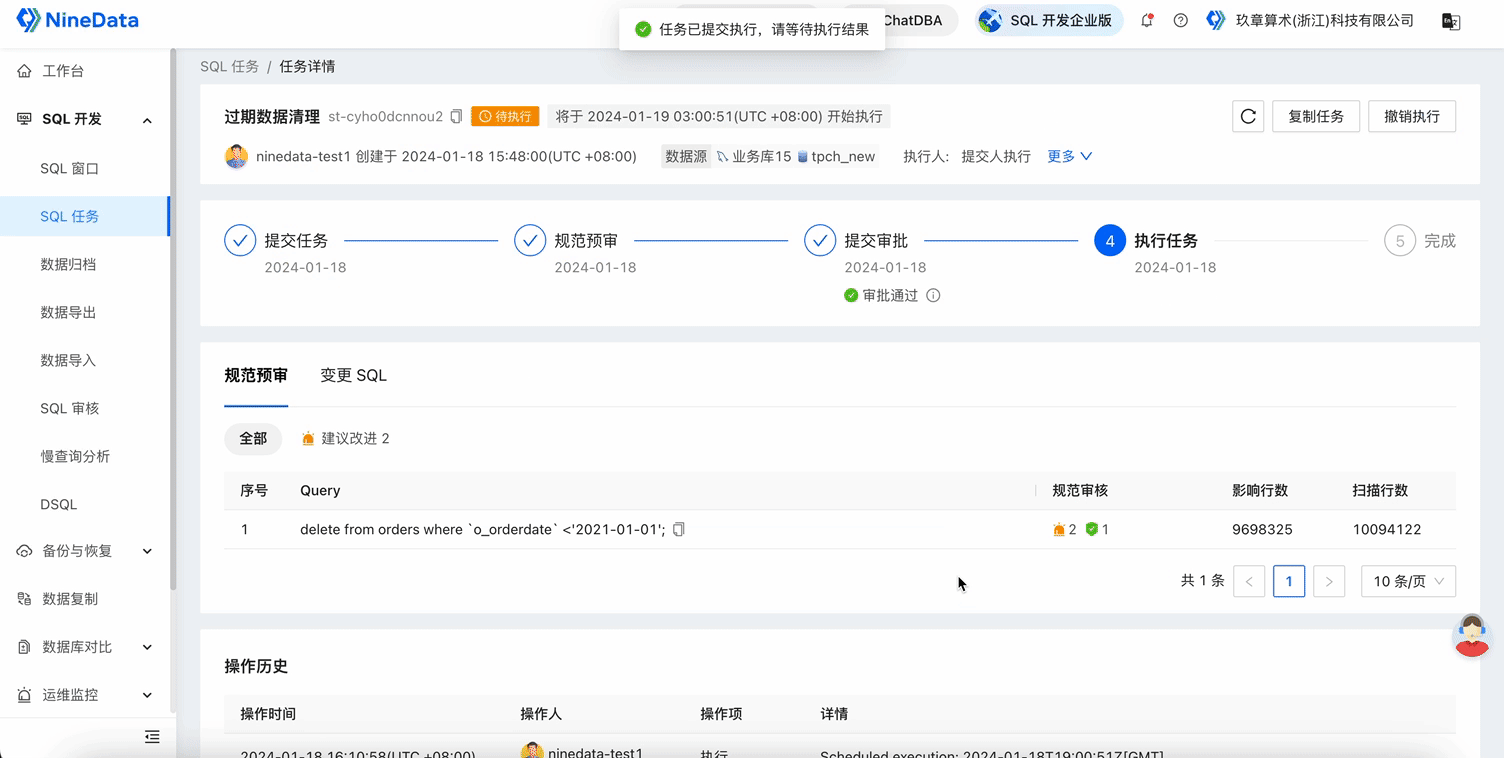
如何在不影响业务的前提下执行大批量数据变更操作?
相信很多 DBA 同学都碰到过这个问题:用一条 DML SQL 语句执行大批量数据更新或删除操作时(例如:定期删除过期的数据或清理无效的数据记录),如果不具备适当的索引,一旦单条 SQL 影响的行数过多,正…
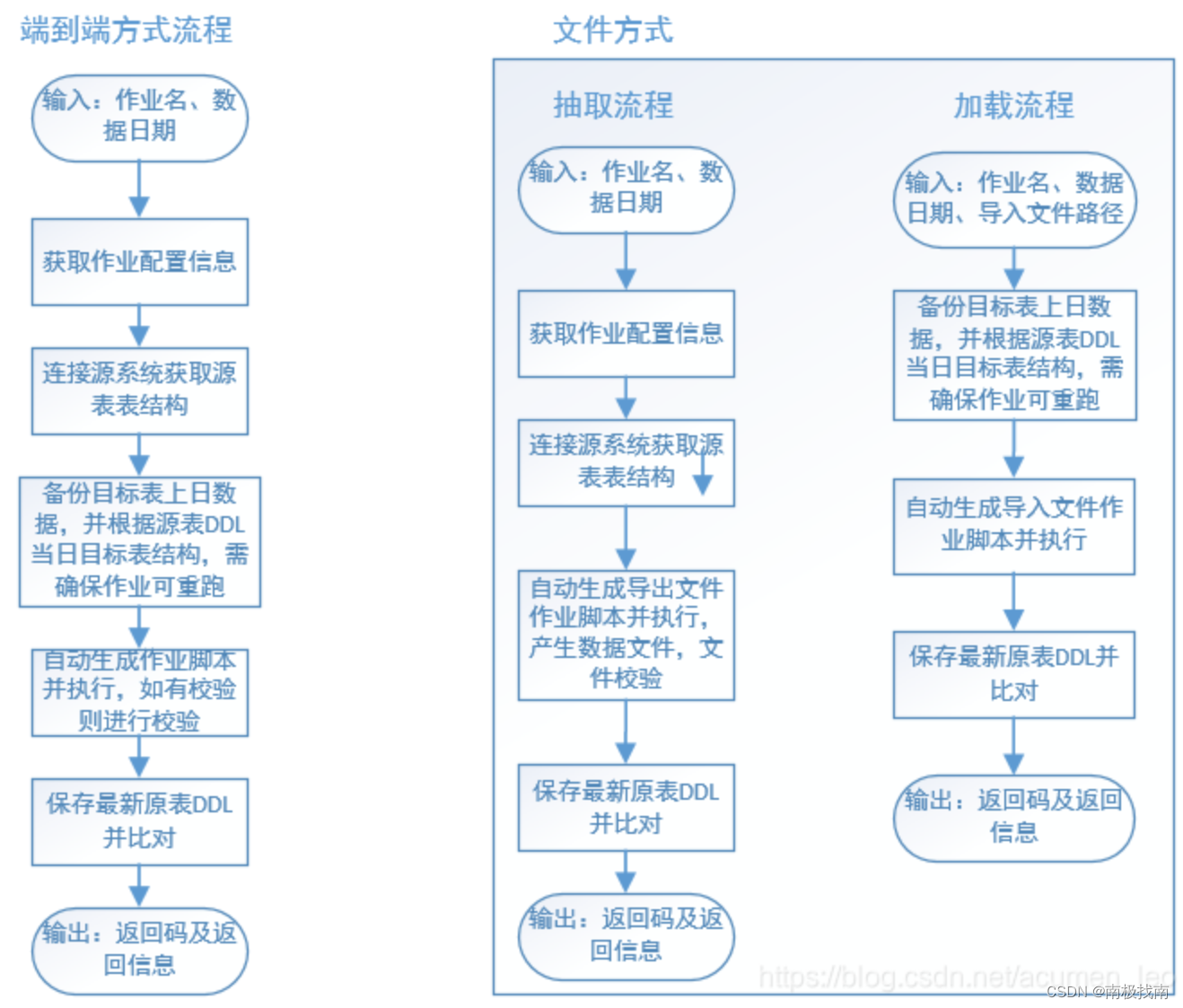
银行数据仓库体系实践(4)--数据抽取和加载
1、ETL和ELT ETL是Extract、Transfrom、Load即抽取、转换、加载三个英文单词首字母的集合: E:抽取,从源系统(Souce)获取数据; T:转换,将源系统获取的数据进行处理加工,比如数据格式转化、数据精…

Hive之set参数大全-14
指定在复制过程中的最大负载任务数的近似值
在 Hive 中,hive.repl.approx.max.load.tasks 是一个配置参数,用于指定在复制过程中的最大负载任务数的近似值。这个参数用于限制 Hive 复制过程中的任务数量,以防止对源系统造成过大的负载。
以…
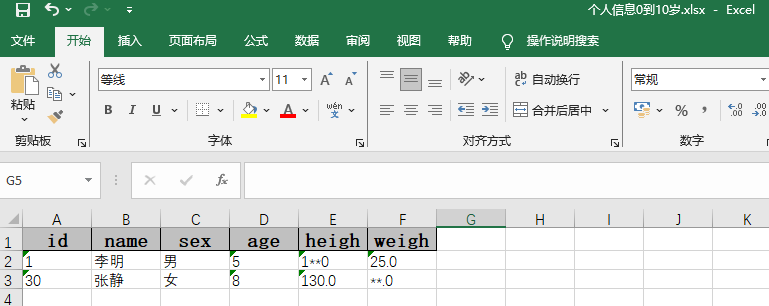
ETL能实现什么流程控制方式?
随着大数据时代的到来,数据处理工具成为各个行业中不可或缺的一部分。运用数据处理工具,能够大幅度帮助开发人员进行数据处理等工作,以及能够更好的为企业创造出有价值的数据。那在使用ETL工具时,我们往往会通过ETL平台所携带的组…
![[hive]搭建hive3.1.2hiveserver2高可用可hive metastore高可用](https://img-blog.csdnimg.cn/b36e0643ebb545ff875c8a963c960f3e.png)
[hive]搭建hive3.1.2hiveserver2高可用可hive metastore高可用
参考:
Apache hive 3.1.2从单机到高可用部署 HiveServer2高可用 Metastore高可用 hive on spark hiveserver2 web UI 高可用集群启动脚本_薛定谔的猫不吃猫粮的博客-CSDN博客
没用里头的hive on spark,测试后发现版本冲突
一、Hive 集群规划(蓝色部分)
ck1ck2ck3Secondary…
JDBC MySQL任意文件读取分析
JDBC MySQL任意文件读取分析
文章首发于知识星球-赛博回忆录。给主管打个广告,嘿嘿。 在渗透测试中,有些发起mysql测试流程(或者说mysql探针)的地方,可能会存在漏洞。在连接测试的时候通过添加allowLoadLocalInfileInPath,allowLoadLocalInf…
四个BY的区别 HIVE中
在Hive中,有四个BY比较:Order By、Sort By、Distribute By和Cluster By。 Order By是全局排序,只有一个Reducer。它可以按照升序(ASC)或降序(DESC)对结果进行排序。Order By子句通常用在SELECT语…
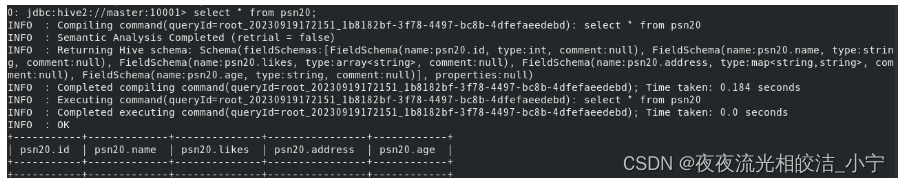
Hive的基本SQL操作(DDL篇)
目录
编辑
一、数据库的基本操作
1.1 展示所有数据库
1.2 切换数据库
1.3 创建数据库
1.4 删除数据库
1.5 显示数据库信息
1.5.1 显示数据库信息
1.5.2 显示数据库详情
二、数据库表的基本操作
2.1 创建表的操作
2.1.1 创建普通hive表(不包含行定义格…
ClickHouse(15)ClickHouse合并树MergeTree家族表引擎之GraphiteMergeTree详细解析
GraphiteMergeTree该引擎用来对Graphite数据(图数据)进行瘦身及汇总。对于想使用ClickHouse来存储Graphite数据的开发者来说可能有用。
如果不需要对Graphite数据做汇总,那么可以使用任意的ClickHouse表引擎;但若需要,那就采用GraphiteMerge…
数据中心与数据仓库的区别
在数字化时代,数据已经成为企业竞争的核心资源,数据处理和数据管理也变得越来越重要。在数据处理方面,数据中台和数据仓库是两种常见的数据处理方式,它们有着不同的特点和适用场景。本文将从技术角度对数据中台和数据仓库的区别进…

大数据时代,数据治理
一、大数据时代还需要数据治理吗?
数据平台发展过程中随处可见的数据问题
大数据不是凭空而来,1981年第一个数据仓库诞生,到现在已经有了近40年的历史,相对数据仓库来说我还是个年轻人。而国内企业数据平台的建设大概从90年代末…

Ubuntu 20.04 安装部署 TiDB DM v7.3.0 集群【全网独家】
文章目录 测试环境说明TiDB 单机环境部署DM 集群部署1. 免密设置2. 组件下载3. DM 配置文件模板获取4.DM 配置文件设置5.部署与启动 DM 集群 前言: 放眼全网,我找不出一篇在 Ubuntu 里面搭建 DM 集群的文章,虽然 TiDB 官方推荐使用 CentOS 系…
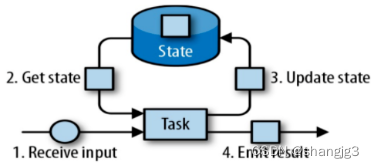
Flink状态管理与检查点机制
1.状态分类 相对于其他流计算框架,Flink 一个比较重要的特性就是其支持有状态计算。即你可以将中间的计算结果进行保存,并提供给后续的计算使用: 具体而言,Flink 又将状态 (State) 分为 Keyed State 与 Operator State: 1.1 算子状态 算子状态 (Operator State):顾名思义…
【数据开发】DW数仓分层设计架构与同步策略(ODS、DWD、DWS等字段含义)
文章目录 1、什么是数据仓库(DW)2、DW分层设计架构(ODS,DWD,DWS)3、数仓同步策略 1、什么是数据仓库(DW)
Data warehouse(可简写为DW或者DWH)数据仓库是什么…
数据治理-文件和内容管理
定义 对任何形式或媒介的数据及信息进行生命周期管理的计划、实施和控制活动;
目标
履行与档案管理有关的法律义务并达到客户的期望;确保能够高速有效的存储、检索、使用文件和内容;确保结构化和非结构化内容之间的集成能力;
文…
数据治理-数据仓库和商务智能-部分内容
数据仓库建设应遵循原则
聚焦业务目标,用于最优级的业务并解决它;以终为始,以业务优先级和最终成果驱动仓库创建;全局性的思考和设计,局部性的行动和建设;总结并持续优化,而不是一开始就这样做…
Hive 优化建议与策略
目录
编辑
一、Hive优化总体思想
二、具体优化措施、策略
2.1 分析问题得手段
2.2 Hive的抓取策略
2.2.1 策略设置
2.2.2 策略对比效果
2.3 Hive本地模式
2.3.1 设置开启Hive本地模式
2.3.2 对比效果
2.3.2.1 开启前
2.3.2.2 开启后
2.4 Hive并行模式
2.5 Hive…
数据中心与数据仓库发展趋势
一、数据中台与数据仓库的概念及作用数据中台是指将企业内外各种数据通过数据采集、数据处理、数据存储、数据分析、数据可视化等方式进行整合、处理和挖掘,为企业提供数据服务的一体化平台。它的主要作用在于实现数据的共享、复用和智能化,以及如何利用…
Hive【Hive(六)窗口函数】
窗口函数(window functions)
概述
定义 窗口函数能够为每行数据划分 一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行数据。
语法 窗口函数的语法主要包括 窗口 和 函数 两个部分。其中窗口用于定义计算范围…
Hudi SQL DDL
本文介绍Hudi在 Spark 和 Flink 中使用SQL创建和更改表的支持。 1.Spark SQL 创建hudi表 1.1 创建非分区表 使用标准CREATE TABLE语法创建表,该语法支持分区和传递表属性。 CREATE TABLE [IF NOT EXISTS] [db_name.]table_name[(col_name data_type [COMMENT col_comment], ..…
HudiSQL DML
本文介绍SparkSQL提供的几个数据操作语言(DML)操作,用于与Hudi表交互。这些操作包括插入、更新、合并和删除Hudi表中的数据。 1.Insert Into 使用INSERT INTO语句使用Spark SQL将数据添加到Hudi表中。以下是一些示例: INSERT INTO <table> SELECT <columns> F…

2023年中国数据存储市场现状及发展前景预测分析
中商情报网讯:当前,新一代信息技术快速发展推动信息产业发生了重大变革,数据存储行业将很快成为信息领域一个重要的产业分支。生成式人工智能催生算力需求,各种新兴应用场景对数据存储的容量、效率、流动性和安全性等方面提出了更…
【Hive SQL 每日一题】环比增长率、环比增长率、复合增长率
文章目录 环比增长率同比增长率复合增长率测试数据需求说明需求实现 环比增长率
环比增长率是指两个相邻时段之间某种指标的增长率。通常来说,环比增长率是比较两个连续时间段内某项数据的增长量大小的百分比。
环比增长率反映了两个相邻时间段内某种经济指标的变…
Redux 数据仓库
Redux 数据仓库
解决React 数据管理(状态管理) ,用于中大型,数据比较庞大,组件之间数据交互多的情况下使用。
作者:如果你不知道是否需要使用Redux,那么你就不需要它!
解决组件的数据通信。 …
Hive创建分区表并插入数据
业务中经常会遇到这种需求:数据每天全量更新,但是要求月底将数据单独保存一份以供后期查询某月节点的信息。这时就要考虑用到Hive的分区表实现,即按照月份创建分区表,相当于新的月份数据保存在新表,进而实现保存了历史…
详解API接口如何安全的传输数据(内附商品详情API接口接入方式)
概述
API接口的安全传输是确保数据在API请求和响应之间的传输过程中不被截获、篡改或泄露的重要步骤。以下是一些用于增强API接口安全传输的常见技术和最佳实践: 使用HTTPS:使用HTTPS协议而不是HTTP,以确保数据在传输过程中的安全性。HTTPS使…
数仓建模—数据中台概论
文章目录 数据中台概论一、什么是中台二、什么是数据中台三、数据中台解决什么问题四、数据中台和数据仓库、数据平台的区别五、业务中台和数据中台的关系六、数据中台为何如此重要1. 回归服务的本质2. 数据中台需要持续的业务滋养3. 数据中台是培育业务创新的土壤4. 数据中台是…
Hive【Hive(八)自定义函数】
自定义函数用的最多的是单行函数,所以这里只介绍自定义单行函数。
Coding
导入依赖
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.3</version></dependency>…
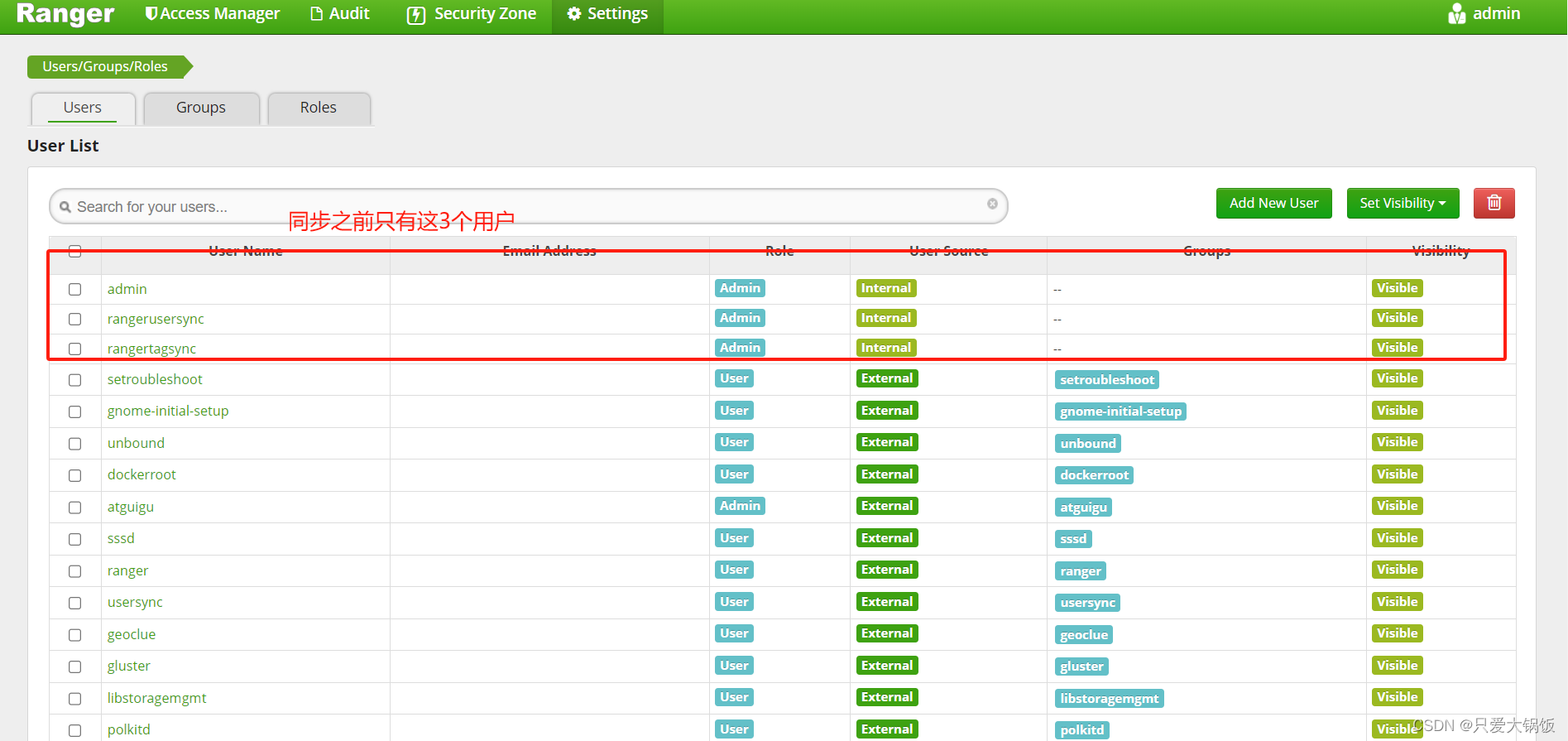
Apache Ranger:(一)安装部署
1.Ranger简介 Apache Ranger提供一个集中式安全管理框架, 并解决授权和审计。它可以对Hadoop生态的组件如HDFS、Yarn、Hive、Hbase等进行细粒度的数据访问控制。通过操作Ranger控制台,管理员可以轻松的通过配置策略来控制用户访问权限。 说白了就是管理大多数框架的授权问题。 …
流式数据湖平台实战 | HudiSQL DML
本文介绍SparkSQL提供的几个数据操作语言(DML)操作,用于与Hudi表交互。这些操作包括插入、更新、合并和删除Hudi表中的数据。 1.Insert Into 使用INSERT INTO语句使用Spark SQL将数据添加到Hudi表中。以下是一些示例: INSERT INTO <table> SELECT <columns> F…
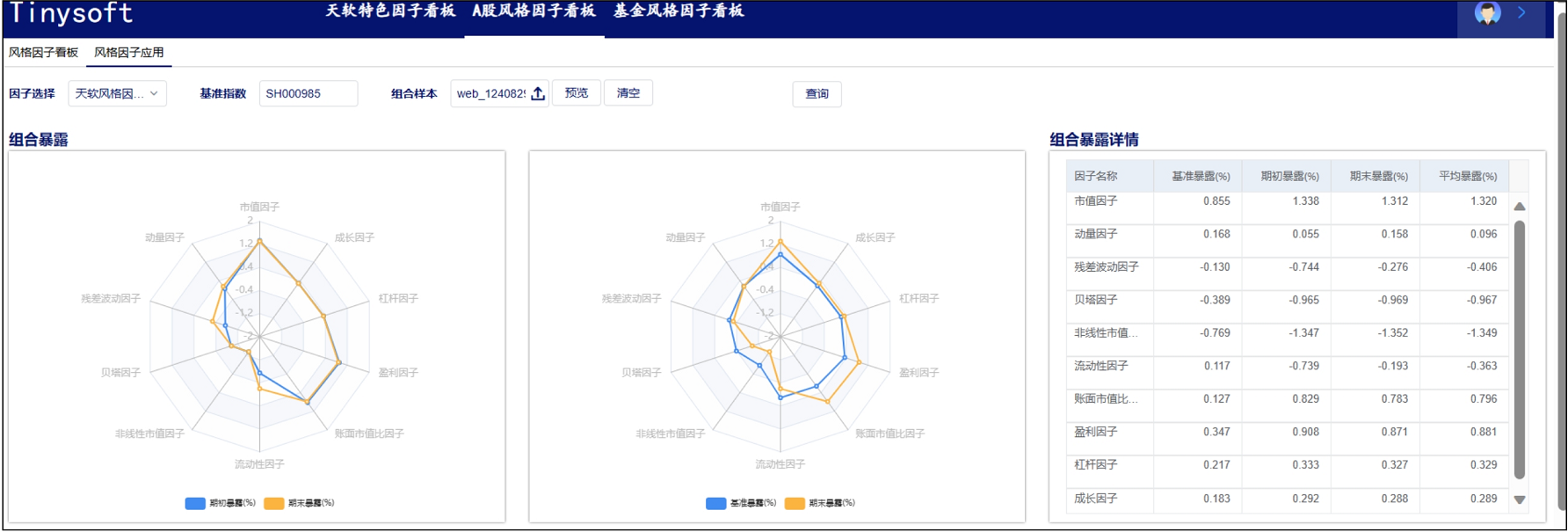
A股风格因子看板 (2023.10 第03期)
该因子看板跟踪A股风格因子,该因子主要解释沪深两市的市场收益、刻画市场风格趋势的系列风格因子,用以分析市场风格切换、组合风格暴露等。 今日为该因子跟踪第03期,指数组合数据截止日2023-09-30,要点如下 近1年A股风格因子检验统…
hive变更数据过程
创建测试表
-- 測試數據集use default;
drop table if exists test3;
CREATE TABLE if not exists test3(id string,name string,create_date string,last_modified_date string,amount double,is_delete int
)partitioned by (dt string)
row format delimited fields term…
关于一篇什么是JWT的原理与实际应用
目录 一.介绍
1.1.什么是JWT
二.结构
三.Jwt的工具类的使用
3.1. 依赖
3.2.工具类
3.3.过滤器
3.4.控制器
3.5.配置
3.6. 测试类
用于生成JWT
解析Jwt
复制jwt,并延时30分钟
测试JWT的有效时间 测试过期JWT的解析
四.应用 今天就到这了,希…
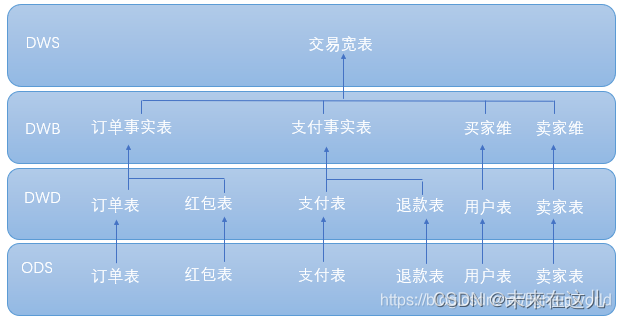
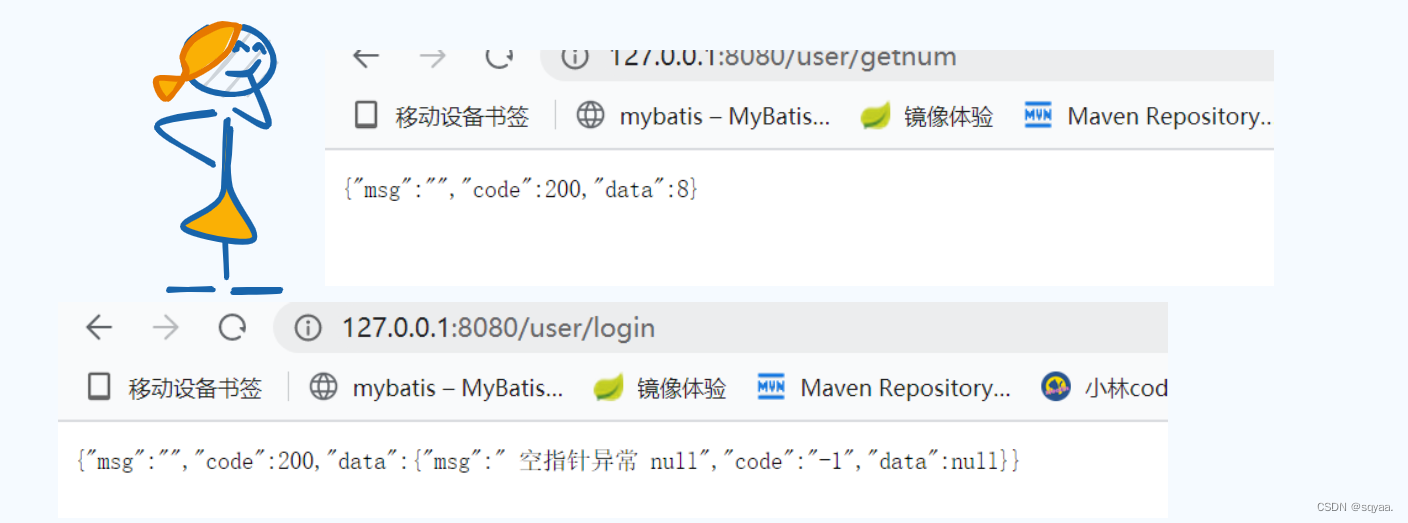
拦截器以及统一功能的实现
目录 引言 实现一个简单的拦截器 拦截器小结 统一访问前缀 统一异常处理 统一返回参数 ControllerAdvice 引言 HandlerInterceptor是Spring MVC框架提供的一个拦截器接口,它用于对请求进行拦截和处理。在Spring MVC中,拦截器可以用于实现一些通用的功能…

onebound电商API接口商品数据采集平台:让数据成为生产力!
随着数字化商业时代的到来,API接口已成为电商资源连接利器,也是全球传统互联网企业转型的基础。
2021年 Google Cloud 研究显示,全球互联网企业近3/4的企业持续投入数字化转型,2/3的企业在持续增加投入,从这组数据可以…
【大数据 - Doris 实践】数据表的基本使用(五):ROLLUP
数据表的基本使用(五):ROLLUP 1.基本概念2.Aggregate 和 Uniq 模型中的 ROLLUP2.1 获得每个用户的总消费2.2 获得不同城市,不同年龄段用户的总消费、最长和最短页面驻留时间 3.Duplicate 模型中的 ROLLUP3.1 前缀索引3.2 ROLLUP 调…

2023.11.17-hive调优的常见方式
目录
0.设置hive参数
1.数据压缩
2.hive数据存储格式
3.fetch抓取策略
4.本地模式
5.join优化操作
6.SQL优化(列裁剪,分区裁剪,map端聚合,count(distinct),笛卡尔积)
6.1 列裁剪:
6.2 分区裁剪:
6.3 map端聚合(group by):
6.4 count(distinct):
6.5 笛卡尔积:
7…
[hive]中的字段的数据类型有哪些
Hive中提供了多种数据类型用于定义表的字段。以下是Hive中常见的数据类型:
布尔类型(Boolean):用于表示true或false。
字符串类型(String):用于表示文本字符串。
整数类型(Intege…
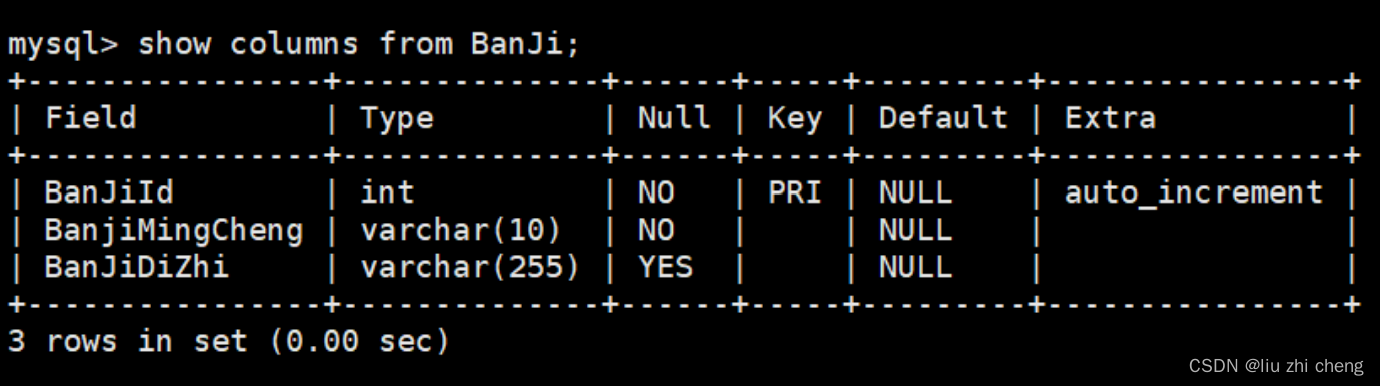
MySQL库表操作 作业
题目:
1. sql语句分为几类?2. 表的约束有哪些,分别是什么,设置的语法分别是什么?3. 做出班级表,学生表的E-R图,数据库模型图,以及核心的sql语句.
1. MySQL致力于支持全套ANSI/ISO SQL标准。在MySQL数据库中,SQL语句主要可以划分为以下几类:
> DD…
Hive使用双重GroupBy解决数据倾斜问题
文章目录 1.数据准备2.双重group by实现 解决数据倾斜2.1 第一层加盐group by2.2 第二层去盐group by 1.数据准备
create table wordcount(a string) row format delimited fields terminated by ‘,’;
load data local inpath ‘opt/2.txt’ into table wordcount;
hive (…

BI 数据分析,数据库,Office,可视化,数据仓库
AIGC ChatGPT 职场案例 AI 绘画 与 短视频制作 PowerBI 商业智能 68集 Mysql 8.0 54集 Oracle 21C 142集 Office 2021实战应用 Python 数据分析实战, ETL Informatica 数据仓库案例实战 51集 Excel 2021实操 100集, Excel 2021函数大全 80集 Excel 2021…
Doris实战——拈花云科的数据中台实践
目录
前言
一、业务背景
二、数据中台1.0—Lambda
三、新架构的设计目标
四、数据中台2.0—Apache Doris
4.1 新架构数据流转
4.2 新架构收益
五、新架构的落地实践
5.1 模型选择
5.1.1 Unique模型
5.1.2 Aggregate模型
5.2 资源管理
5.3 批量建表
5.4 计算实现…

Hive集群出现报错信息解决办法
一、报错信息:hive> show databases;FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient 解决办法:1.删除mysql中的元数据库(metastore࿰…

探索数据宇宙:深入解析大数据分析与管理技术
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua,在这里我会分享我的知识和经验。&#x…

Doris——纵腾集团流批一体数仓架构
目录
前言
一、早期架构
二、架构选型
三、新数据架构
3.1 数据中台
3.2 数仓建模
3.3 数据导入
四、实践经验
4.1 准备阶段
4.2 验证阶段
4.3 压测阶段
4.4 上线阶段
4.5 宣导阶段
4.6 运行阶段
4.6.1 Tablet规范问题
4.6.2 集群读写优化
五、总结收益
六…
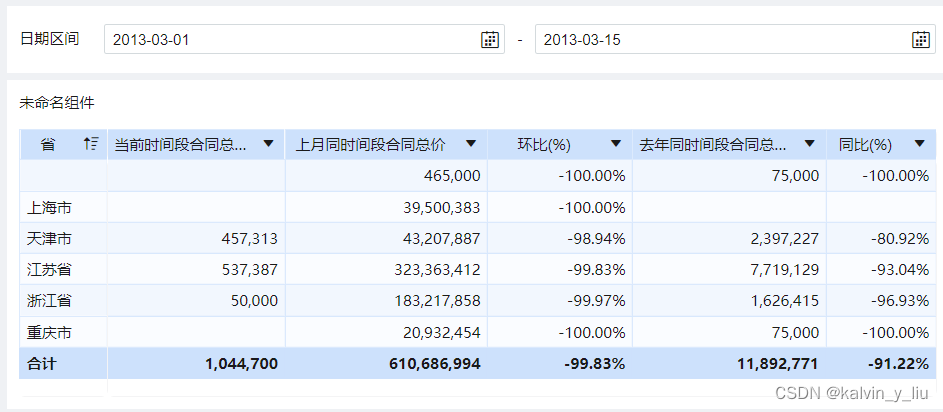
Power BI 和 Fine BI 分析的几个概念
Power BI 和 Fine BI 分析的几个概念
1. 钻取概述
钻取可以让用户在查看仪表板时动态改变维度的层次,它包括向上钻取和向下钻取。 比如可实现:查看省份数据时,可下钻查看到下方具体城市的数据。
1.1 如何设置钻取
按钻取的设置方法&#…
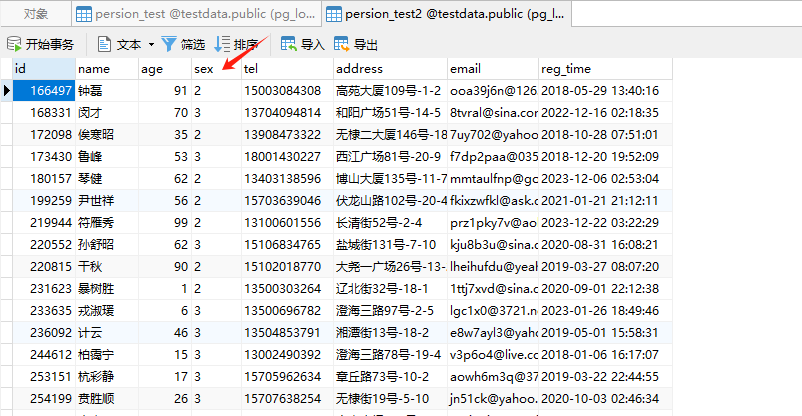
ETL、ELT区别以及如何正确运用
一、 浅谈ETL、ELT ETL与ELT的概念
ETL (Extract, Transform, Load) 是一种数据集成过程,通常用于将数据从一个或多个源系统抽取出来,经过清洗、转换等处理后,加载到目标数据存储中。这种方法适用于需要对数据进行加工和整合后再加载到目标…
Doris实战——美联物业数仓
目录
一、背景
1.1 企业背景
1.2 面临的问题
二、早期架构
三、新数仓架构
3.1 技术选型
3.2 运行架构
3.2.1 数据模型 纵向分域
横向分层
数据同步策略
3.2.2 数据同步策略 增量策略
全量策略
四、应用实践
4.1 业务模型
4.2 具体应用
五、实践经验
5.1 数据…
银行数据仓库体系实践(18)--数据应用之信用风险建模
信用风险 银行的经营风险的机构,那在第15节也提到了巴塞尔新资本协议对于银行风险的计量和监管要求,其中信用风险是银行经营的主要风险之一,它的管理好坏直接影响到银行的经营利润和稳定经营。信用风险是指交易对手未能履行约定契约中的义务而…
hivesql的基础知识点
目录
一、各数据类型的基础知识点
1.1 数值类型
整数
小数
float
double(常用)
decimal(针对高精度)
1.2 日期类型
date
datetime
timestamp
time
year 1.3 字符串类型
char
varchar / varchar2
blob /text tinyblob / tinytext
mediumblob / mediumtext
lon…
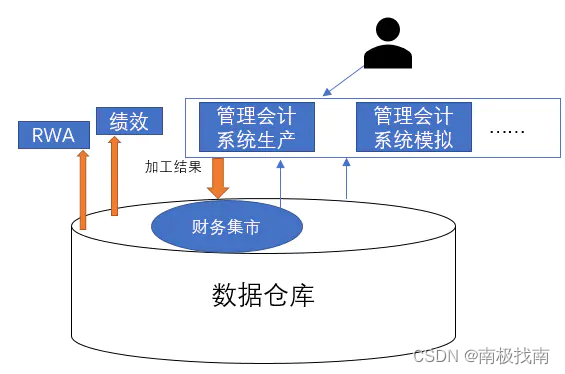
银行数据仓库体系实践(16)--数据应用之财务分析
总账系统 在所有公司中,财务分析的基础都是核算,那在银行的系统体系中,核算功能在业务发生时由业务系统如核心、贷款、理财中实现登记,各业务系统会在每天切日后统计当天各机构的核算科目的发生额与余额,并统一送到总账…

JDK8 和 JDK17 下基于JDBC连接Kerberos认证的Hive(代码已测试通过正常)
0.背景
之前自研平台是基于jdk8开发的,连接带Kerberos的hive也是jdk8,现在想升级jdk到17,发现过Kerberos的hive有点不一样,特地记录 连接Kerberos,krb5.conf 和对应服务的keytab文件以及principal肯定是需要提前准备的,
一般从服务器或者运维那里获取krb5.conf 与 Hive对应的…
多标签用户画像分析跑得快的关键在哪里?
用户画像分析需要使用众多标签来描述用户属性,通常有两类标签。一类用户标签的值可能有多个,比如用户学历是中学、大学、研究生、博士等,年龄段是children、juvenile、youth、middle age、old age,这类标签称为枚举标签。另一类用…
Hive3.1.2——企业级调优
前言 本篇文章主要整理hive-3.1.2版本的企业调优经验,有误请指出~
一、性能评估和优化
1.1 Explain查询计划 使用explain命令可以分析查询计划,查看计划中的资源消耗情况,定位潜在的性能问题,并进行相应的优化。 explain执行计划…
Hive的相关概念——分区表、分桶表
目录
一、Hive分区表
1.1 分区表的概念
1.2 分区表的创建
1.3 分区表数据加载及查询
1.3.1 静态分区
1.3.2 动态分区
1.4 分区表的本质及使用
1.5 分区表的注意事项
1.6 多重分区表
二、Hive分桶表
2.1 分桶表的概念
2.2 分桶表的创建
2.3 分桶表的数据加载
2.4 …
Hive——动态分区导致的小文件问题
目录
0 问题现象
1 问题解决
解决方案一:调整动态分区数
方案一弊端:小文件剧增
解决方案二:distribute by
方案二弊端:数据倾斜
解决方案三:distribute by命令
2 思考
3 小结
0 问题现象
现象:…
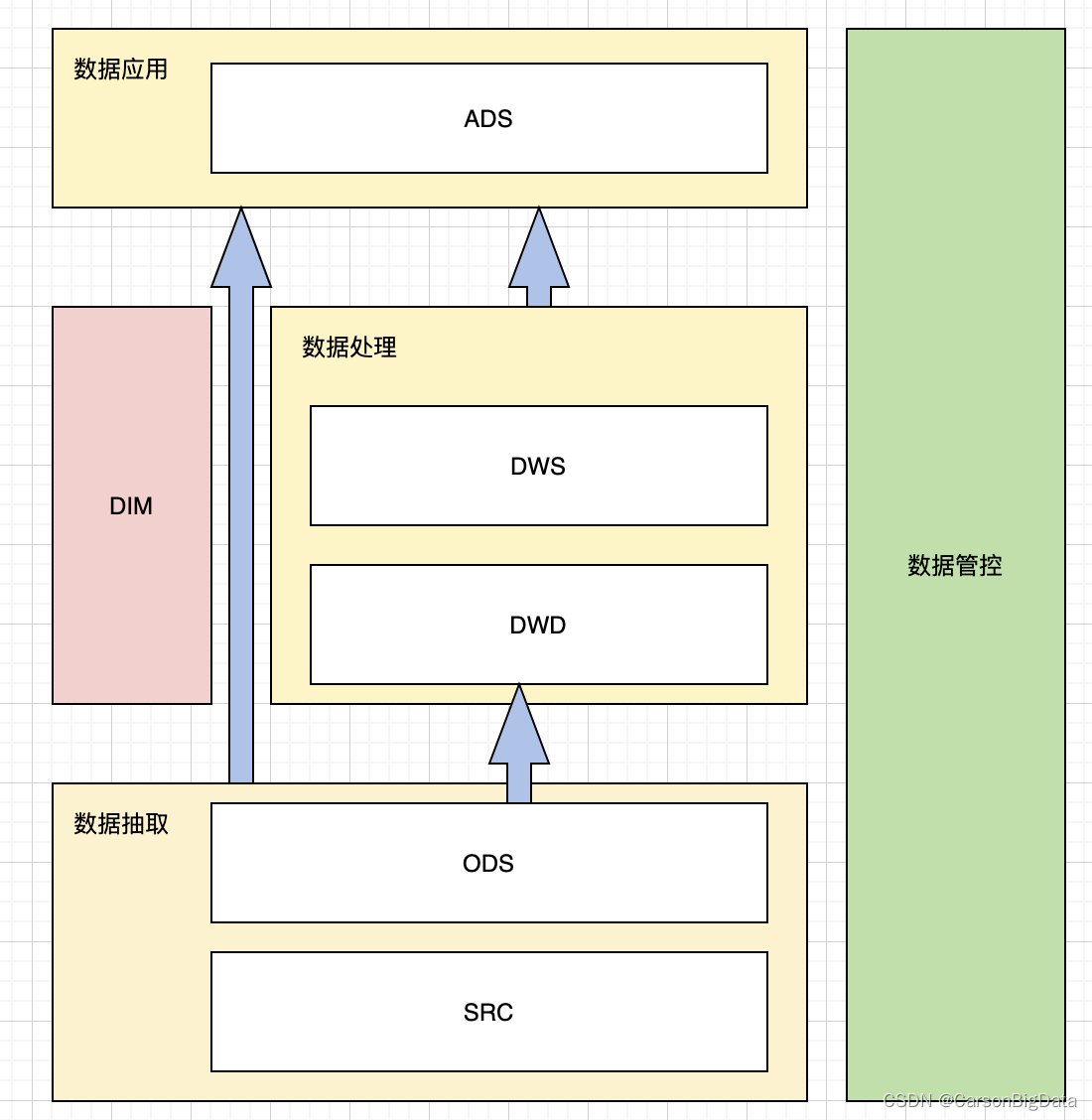
【超详细】HIVE 日期函数(当前日期、时间戳转换、前一天日期等)
文章目录 相关文献常量:当前日期、时间戳前一天日期、后一天日期获取日期中的年、季度、月、周、日、小时、分、秒等时间戳转换时间戳 to 日期日期 to 时间戳 日期之间月、天数差 作者:小猪快跑 基础数学&计算数学,从事优化领域5年&#…
数据治理——滴滴大数据成本治理实践
原文大佬的这篇大数据平台成本治理实践是有借鉴意义的,这些摘抄下来用作沉淀学习。如有侵权,请告知~
一、滴滴大数据成本治理总体框架
1.1 数据体系 从上图所示:最底层是以数据引擎为基础的数据存储,分为离线计算、实时计算、OL…
大数据基础设施搭建 - Doris
文章目录 一、Linux系统要求1.1 设置系统最大打开文件句柄数1.2 设置最大虚拟块的大小1.3 集群中其他安装doris的机器同上调整1.4 重启服务器生效 二、确认需要下载哪个Doris版本三、上传并解压压缩包3.1 创建目录3.2 解压fe3.3 解压be3.4 解压java udf函数3.4.1 解压3.4.2 复制…
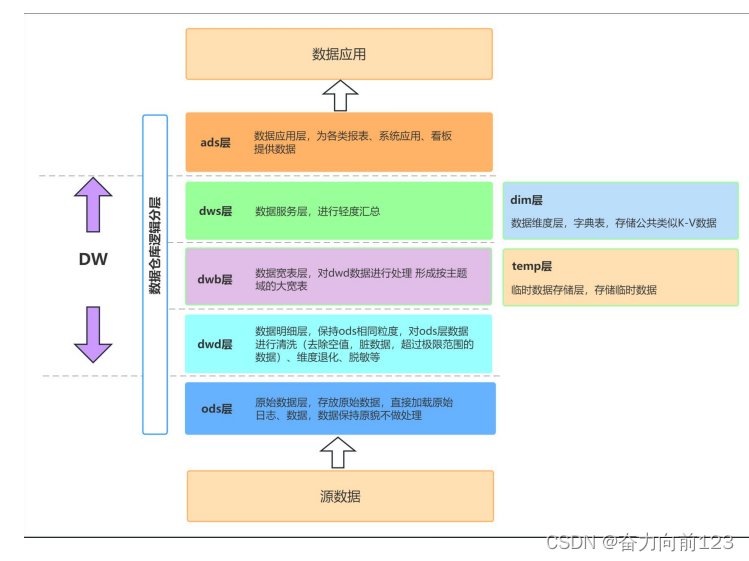
数据仓库数据分层详解
数据仓库中的数据分层是一种重要的数据组织方式,其目的是为了在管理数据时能够对数据有一个更加清晰的掌控。以下是数据仓库中的数据分层详解:
原始数据层(Raw Data Layer):这是数仓中最底层的层级,用于存…
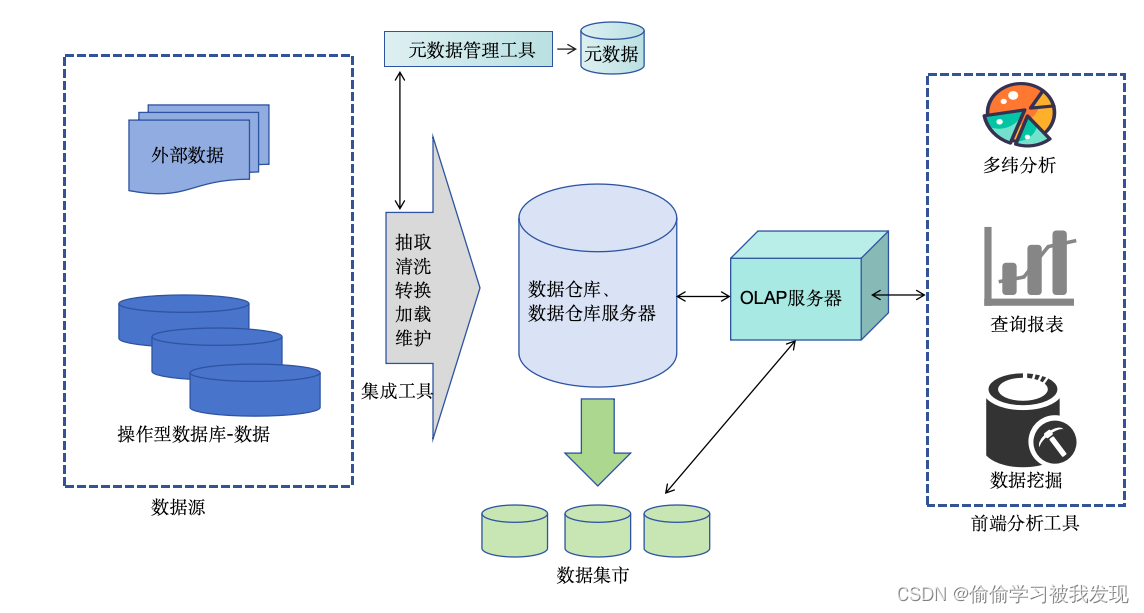
数据仓库的基本概念、基本特征、体系结构
个人看书学习心得及日常复习思考记录,个人随笔。 数据仓库的基本概念、基本特征
数据仓库的定义:数据仓库是一个面向主题的、集成的、不可更新的、随时间不断变化的数据集合,用以更好地支持企业或组织的决策分析处理。
数据仓库中数据的4个…

向量数据库的崛起与多元化场景创新
向量数据库的崛起与多元化场景创新
前言: 在当今数字化时代,数据被认为是黄金,对于企业、科学家和决策者而言都具有巨大的价值。然而,随着数据规模的不断增长,有效地管理、存储和检索数据变得愈发复杂。这就引入了向量…
【Hive】分区表和分桶表相关知识点介绍
Hive中的分区表和分桶表是两种用于优化数据查询和管理的技术。它们可以提高查询性能、减少数据扫描量并提供更精细的数据组织方式。
分区表(Partitioned Table)
Hive的分区表将数据按照一个或多个列的值进行逻辑分区。每个分区都是一个独立的子目录,其中包含符合该分区条件…
Hive的时间操作函数
目录 前言函数使用介绍实际使用判断该天是星期几判断该天对应的周(包含一周开始和结束) 前言
hive 里面的时间函数有很多,今天单讲dayofweek函数,背景:有时候不仅要出日报,还要出周报,需要很多…

淘宝API接口开发系列,获取商品详情,按关键词搜索商品,拍立淘,商品评论销量商品类目,买家卖家订单接口等演示案例
关键词推荐API接口通过提供相关的关键词推荐,能够帮助用户更快捷地搜索、改善用户体验,同时也对于SEO优化、广告投放、内容创作和个性化推荐等方面有着重要的作用。
item_search-按关键字搜索淘宝商品 公共参数
名称类型必须描述keyString是调用key&am…
通过key在数仓里查询dt的时候报错
现象 Query failed (#20231114_080638_00103_iaf4c) in hive: line 3:11: Column tyc_web_company_workright cannot be resolved
原因
key应该被单引号括起来,字段名称才应该被双引号括起来
修改 把单引号换成双引号就好了
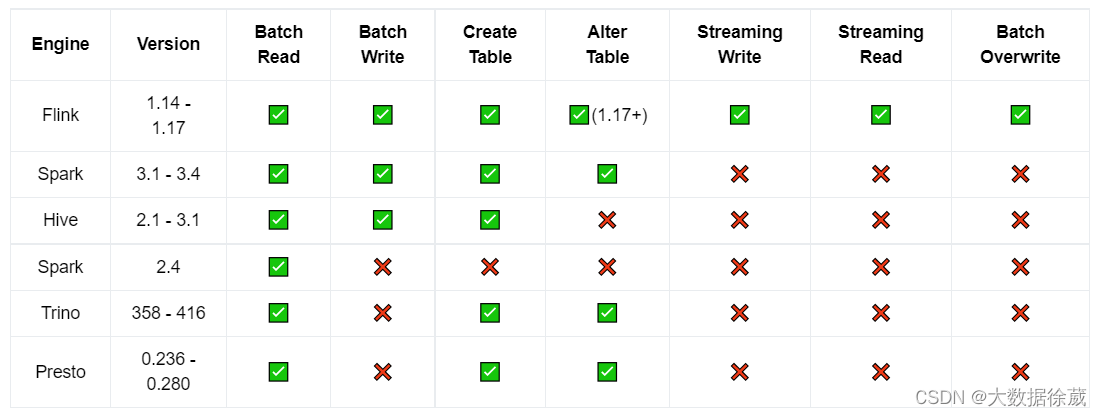
1 快速了解Paimon数据湖核心原理及架构
1.1 什么是Apache Paimon
Apache Paimon的前身属于Flink的子项目:Flink Table Store。
目前业内主流的数据湖存储项目都是面向批处理场景设计的,在数据更新处理时效上无法满足流式数据湖的需求,因此Flink社区在2022年的时候内部孵化了 …

流式数据湖Hudi核心概念四:文件布局
1. Hudi表文件存储结构 Hudi将一个表映射为如下文件结构 Hudi存储分为两个部分:元数据和数据 2. 元数据存储 元数据:.hoodie目录对应着表的元数据信息,包括表的版本管理(Timeline
数据分析:智能企业七步曲(一)
原创: MicroStrategy微策略中国 作者:数据杰论 时间走到2018年最后一个季度,过去几年热炒的大数据概念正在各行各业开始落地并展开实际应用,核心是关注数据如何能为企业带来价值。因此,数据分析及其种种实现手段不断被…
mongodb数据同步到hive
背景
用户需求: 需要将 mongodb 的数据同步到 hive 表,共 2 亿条数据,总数据量约 30G
查阅一些博客后,大致同步方法有以下几种
手动离线
对于比较小的数据,可以先通过 mongoexport 将数据导出到本地 json 文件,再将…
Hive 知识点八股文记录 ——(二)优化
函数
UDF:用户定义函数
UDAF:用户定义聚集函数
UDTF:用户定义表生成函数
建表优化
分区建桶
创建表时指定分区字段 PARTITIONED BY (date string)指定分桶字段和数量 CLUSTERED BY (id) INTO 10 BUCKETS插入数据按分区、分桶字段插入
…
6 Hive引擎集成Apache Paimon
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html
在实际工作中,我们通查会使用Flink计算引擎去读写Paimon,但是在批处理场景中,更多的是使用Hive去读写Paimon,这样操作起来更加方便。
前面我们…

通过商品ID获取到京东商品详情页面数据,京东商品详情官方开放平台API接口,京东APP详情接口,可以拿到sku价格,销售价演示案例
淘宝SKU详情接口是指,获取指定商品的SKU的详细信息。SKU是指提供不同的商品参数组合的一个机制,通过不同的SKU来标识商品的不同组合形式,如颜色、尺寸等。SKU详情接口可以帮助开发者获取指定商品的SKU列表,以及每个SKU的属性、库存…
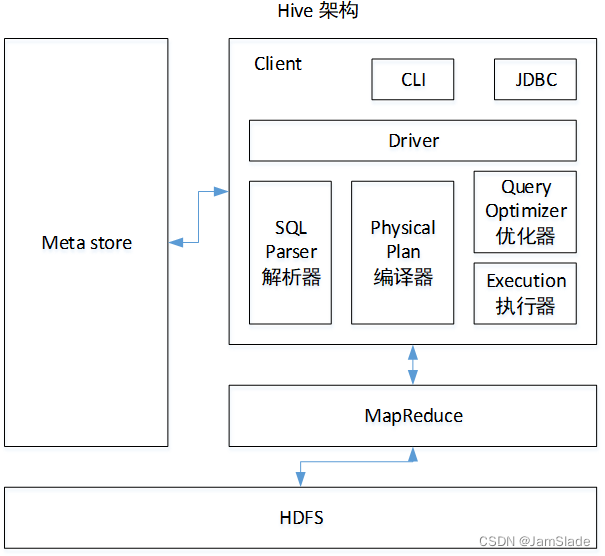
Hive 知识点八股文记录 ——(一)特性
Hive通俗的特性
结构化数据文件变为数据库表sql查询功能sql语句转化为MR运行建立在hadoop的数据仓库基础架构使用hadoop的HDFS存储文件实时性较差(应用于海量数据)存储、计算能力容易拓展(源于Hadoop)
支持这些特性的架构
CLI&…
【hive遇到的坑】—使用 is null / is not null 对string类型字段进行null值过滤无效
项目场景:
查看测试表test_1,发现表字段classes里面有null值,过滤null值。
--查看
> select * from test_1;
-----------------------------
| test_1.id | test_1.classes |
-----------------------------
| Mary | class 1 …
StarRocks实战——云览科技存算分离实践
目录
背景
一、平台现状&痛点
1.1 使用组件多,维护成本高
1.2 链路冗长,数据时效性难以保证
1.3 服务稳定性不足
二、StarRocks 存算分离调研
2.1 性能对比
2.2 易用性
2.3 存储成本
三、StarRocks 存算分离实践
3.1 查询优化
3.1.1 物化…
不可错过的资源:国产数据库openGauss学习网站的无限可能!
介绍:openGauss是一个企业级开源数据库,由华为公司推出,深度融合了华为在数据库领域的多年经验与企业级场景需求。以下是关于openGauss的详细介绍: 企业级定位:openGauss定位为企业级云分布式数据库,旨在提…
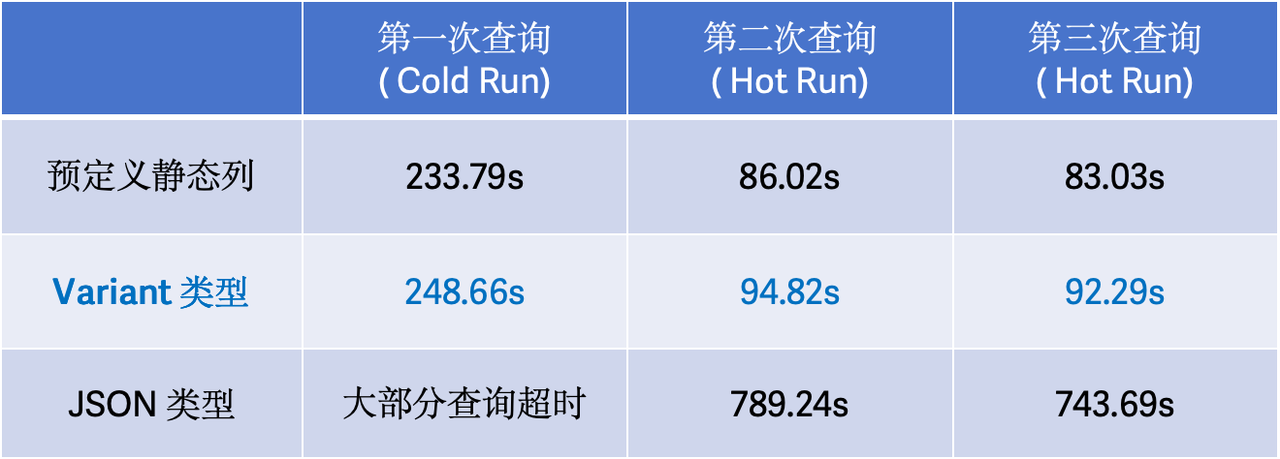
Apache Doris 2.1.0 版本发布:开箱盲测性能大幅优化,复杂查询性能提升 100%
亲爱的社区小伙伴们,我们很高兴地向大家宣布,在 3 月 8 日我们引来了 Apache Doris 2.1.0 版本的正式发布,欢迎大家下载使用。
在查询性能方面, 2.1 系列版本我们着重提升了开箱盲测性能,力争不做调优的情况下取得较好…
Hive集合函数 collect_set 和 collect_list 使用示例
Hive集合函数 collect_set 和 collect_list 使用示例 在Hive中, collect_set 和 collect_list 是用于收集数据并将其存储为集合的聚合 函数。以下是它们的语法:
1. collect_set(expression)- expression : 要收集的数据表达式。collect_set 函数用于将…

BI数据分析案例详解:零售人货场分析该怎么做?
在当今快节奏、高竞争的商业环境中,人货场分析已成为企业成功的关键因素之一。科技的进步和数据的日益丰富使得企业对人流、货物流和场地布局的深入洞察变得愈发重要。通过科学的人货场分析,企业能更好地理解顾客行为、优化供应链、提高运营效率…
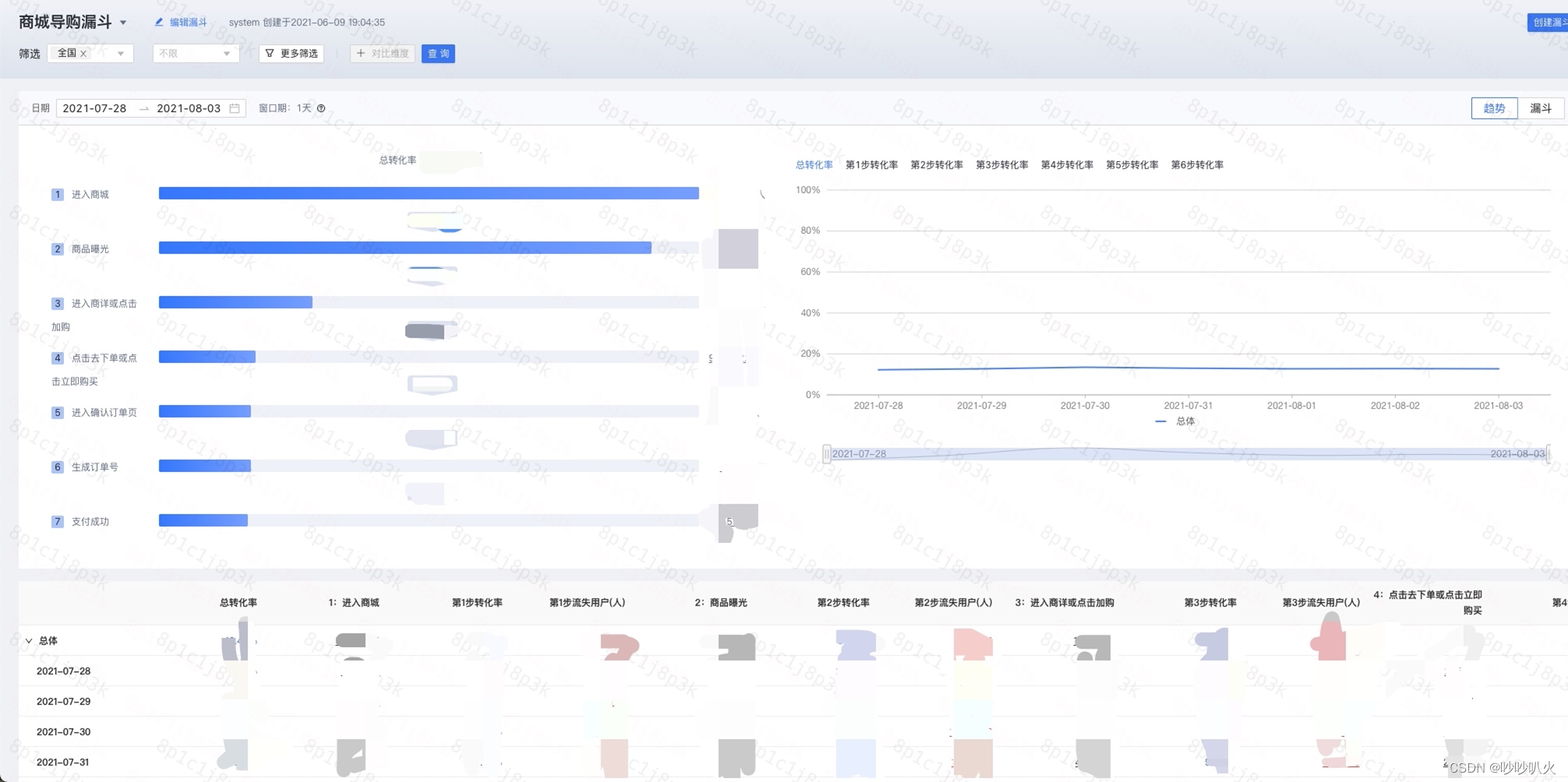
StarRocks——滴滴的极速多维分析实践
背景 滴滴集团作为生活服务领域的头部企业,其中橙心优选经过一年多的数据体系建设,逐渐将一部分需要实时交互查询,即席查询的多维数据分析需求由ClickHouse迁移到了StarRocks中,接下来以StarRocks实现的漏斗分析为例介绍StarRocks…


数据仓库为什么要分层建设?每一层的作用是什么?
在数字化时代,数据已成为企业最宝贵的资产之一。为了更好地管理和利用这些数据,许多企业都建立了数据仓库。然而,数据仓库并非简单的数据存储工具,而是一个复杂的数据处理和分析系统。其中,分层建设是数据仓库设计的重…
某小型外包—ETL工程师面试
没有包装简历,面试感觉跟聊天一样,会就是会,不会就是不会。 1.datax和sqoop的对比,优点与缺点 1.1 datax的组件
2.sql的执行顺序。
select a.* ,b* from a left join b on a.id b.id 先join 再 select。 3.数据采集到数仓中…
DataX-数据迁移Oracle到Mysql-ETL工具
一、安装
https://github.com/WeiYe-Jing/datax-web/blob/master/doc/datax-web/datax-web-deploy.md 1、直接下载DataX工具包:DataX下载地址 下载后解压至本地某个目录,进入bin目录,即可运行同步作业: $ cd {YOUR_DATAX_HOME}/…

ETL工程师——面试,
不包装,简历没有包装,然后直接海投,还是可以,算是有面试机会。
首先是笔试题,两道很简单的关联, sql关联。 1. topN 现在hive 里有一张电信学院所有班级的的期末考试成绩表,表中抽样了6条数…

数据仓库的设计开发应用(二)
目录 四、数据仓库的设计(一)需求分析(二)概念设计(三)逻辑设计(四)物理设计 四、数据仓库的设计 数据仓库的设计包括需求分析、概念设计、逻辑设计和物理设计四个阶段,其…

大数据清洗、转换工具——ETL工具概述
大数据清洗、转换工具——ETL工具概述_etl转换-CSDN博客
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL过程本质上是数据流动的过程,从不同的数据源…
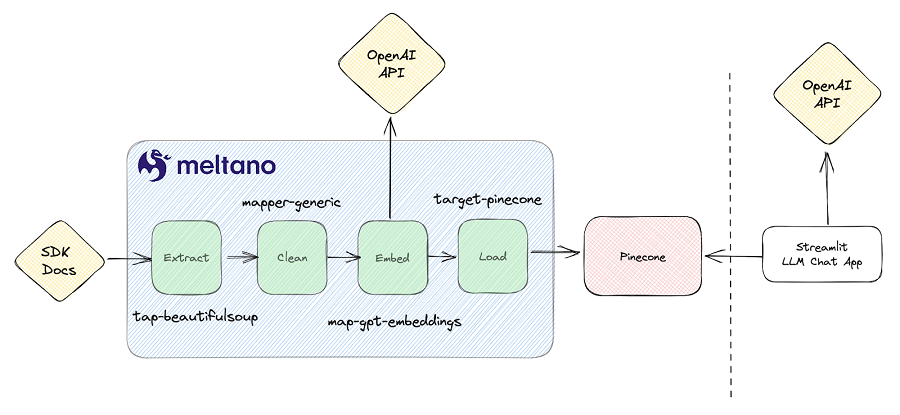
LLM App ≈ 数据ETL管线
虽然现有的 LLM 应用程序工具(例如 LangChain 和 LlamaIndex)对于构建 LLM 应用程序非常有用,但在初始实验之外不建议使用它们的数据加载功能。 当我构建和测试我的LLM应用程序管道时,我能够感受到一些尚未开发和破解的方面的痛苦…
呼叫中心有什么特色功能呢,okcc呼叫系统
随着科技的发展,智能呼叫中系统的出现帮助不少企业解决了问题,那么呼叫中心有什么功能呢? 1、来电弹屏 呼叫中心通话弹出屏功能与系统提供的CRM系统相结合,可根据通话号码自动匹配客户数据,通话显示用户历史服务记录或…
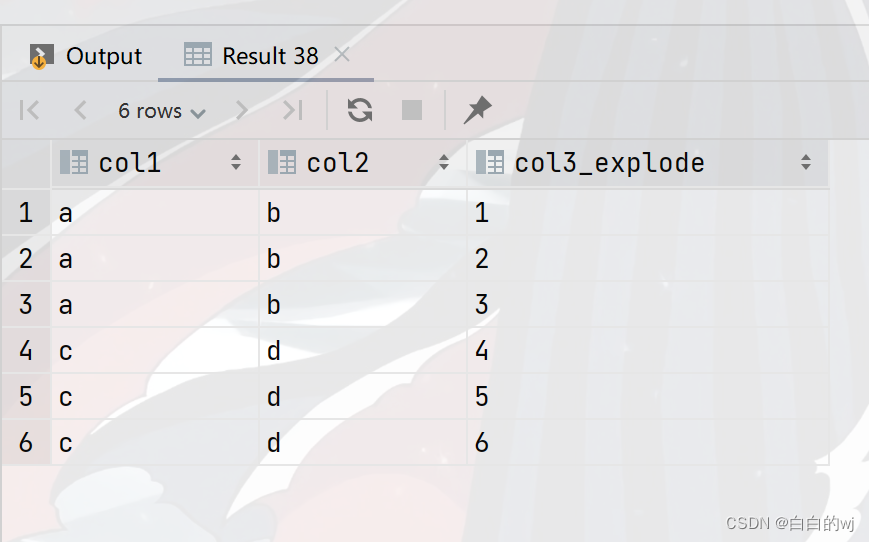
2023.11.16-hive sql高阶函数lateral view,与行转列,列转行
目录 0.lateral view简介
1.行转列 需求1:
需求2:
2.列转行
解题思路: 0.lateral view简介 hive函数 lateral view 主要功能是将原本汇总在一条(行)的数据拆分成多条(行)成虚拟表,再与原表进行笛卡尔积,…

三十分钟学会Hive
Hive的概念与运用
Hive 是一个构建在Hadoop 之上的数据分析工具(Hive 没有存储数据的能力,只有使用数据的能力),底层由 HDFS 来提供数据存储,可以将结构化的数据文件映射为一张数据库表,并且提供类似 SQL …
Google云平台构建数据ETL任务的最佳实践
在数据处理中,我们经常需要构建ETL的任务,对数据进行加载,转换处理后再写入到数据存储中。Google的云平台提供了多种方案来构建ETL任务,我也研究了一下这些方案,比较方案之间的优缺点,从而找到一个最适合我…

金融用户实践|分布式存储支持数据仓库业务系统性能验证
作者:深耕行业的 SmartX 金融团队 闫海涛
估值是指对资产或负债的价值进行评估的过程,这对于投资决策具有重要意义。每个金融公司资管业务人员都期望能够实现实时的业务估值,快速获取最新的数据和指标,从而做出更明智的投资决策。…
Hive用户中文使用手册系列(一)
Apache Hive
在标题为“Information Platforms and the Rise of the Data Scientist”的文章一文中,Jeff Hammerbacher把“信息平台”描述为“企业摄取(ingest)、处理(process)、生成(generate)信息的行为”与“帮助加速从经验数据中学习”的“中心”。 在Facebook…
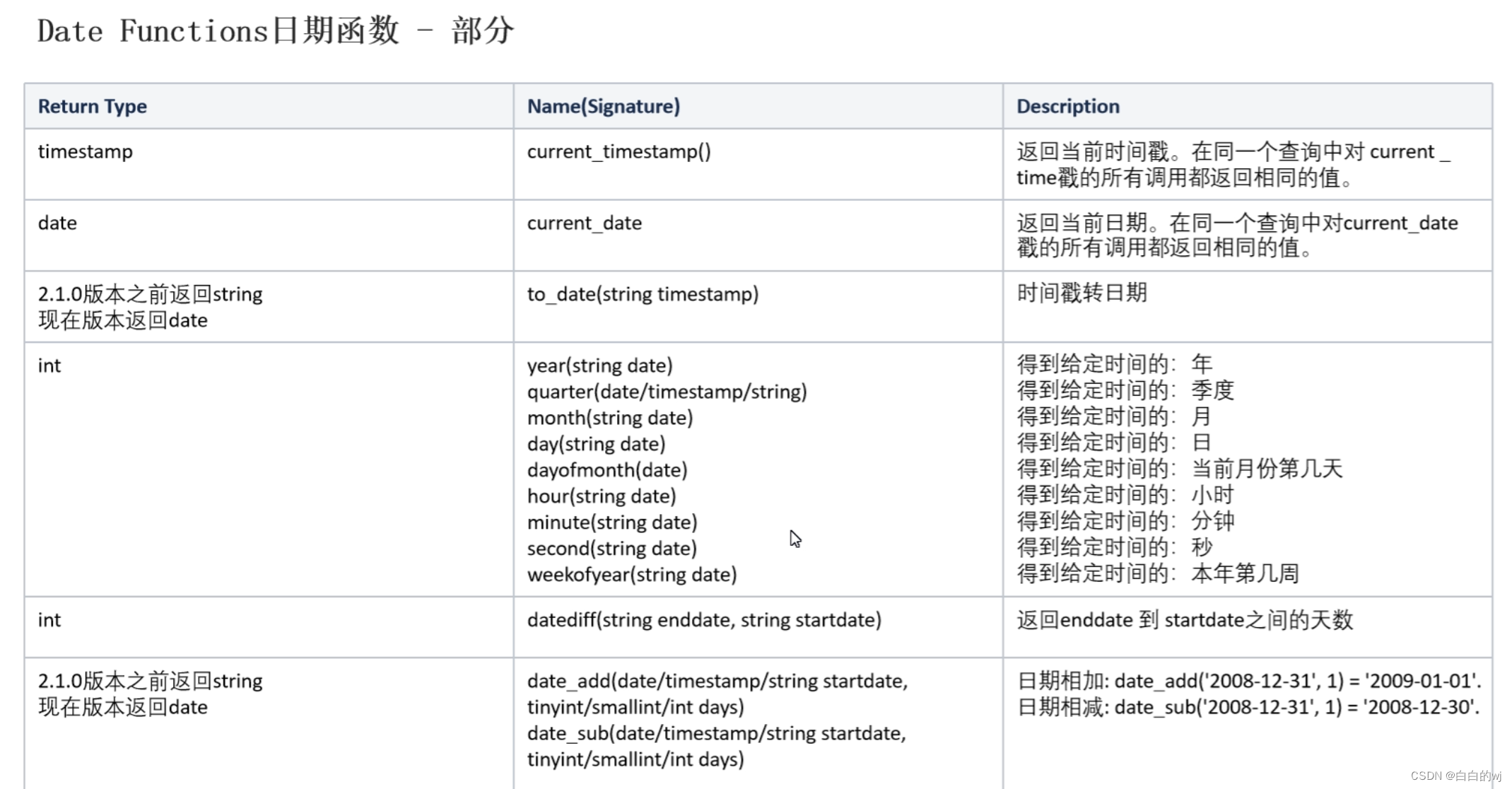
2023.11.15 hive sql之函数标准,字符串,日期,数学函数
目录 一.函数分类标准
二.查看官方函数,与简单演示
三.3种类型函数演示
四.字符串函数
1.常见字符串函数
2.索引函数 解析函数
五.日期函数 1.获取当前时间 2.获取日期相关 3.周,季度等计算
4.时间戳
六.数学函数 一.函数分类标准
目前hive三大标准 UDF:(…
超过5000+企业使用的ETL平台
在当今数据驱动的时代,ETL(Extract, Transform, Load)工具扮演着关键角色,而ETLCloud作为一款脱颖而出的数据集成平台,正以其独特的特性和强大的功能,成为当前国内最活跃的数据集成平台,目前用户…
Hive开窗函数根据特定条件取上一条最接近时间的数据(根据条件取窗口函数的值)
一、Hive开窗函数根据特定条件取上一条最接近时间的数据(单个开窗函数,实际取两个窗口)
针对于就诊业务,一次就诊,多个处方,处方结算时间可能不一致,然后会有多个AI助手推荐用药,会…
hive行转列函数stack(int n, v_1, v_2, ..., v_k)
用stack()函数时,参数中的键值对应按照一对列名和列值进行排使用列
stack(int n, v_1, v_2, ..., v_k)
功能:把k列数据转换成n行,k/n列,其中n必须是正整数,后面的v_1到v_k必须是元素,不能是列名。&#x…
flink重温笔记(十七): flinkSQL 顶层 API ——SQLClient 及流批一体化
Flink学习笔记 前言:今天是学习 flink 的第 17 天啦!学习了 flinkSQL 的客户端工具 flinkSQL-client,主要是解决大数据领域数据计算避免频繁提交jar包,而是简单编写sql即可测试数据,文章中主要结合 hive,即…

Hive-技术补充-初识ANTLR
一、背景
要清晰的理解一条Hql是如何编译成MapReduce任务的,就必须要学习ANTLR。下面是ANTLR的官方网址,下面让我们一起来跟着官网学习吧,在学习的过程中我参考了《antlr4权威指南》,你也可以读下这本书,一定会对你有…
hive逗号分割行列转换
select * from ( select back_receipt_nos,order_no,reject_no from ods_one.ods_us_wms_reject_order_match_all_d where order_no 10150501385980001 ) t1 lateral view explode(split(t1.back_receipt_nos, ,)) t as back_receipt_no where 1 1;
医院为什么需要信息集成平台?有什么数据集成平台推荐?
在现代医疗行业中,信息技术的应用已经成为提高医疗服务质量、提升医院管理效率的关键。信息集成平台作为医院信息化建设的重要组成部分,扮演着连接各类医疗信息系统、整合医疗数据的重要角色。本文将详细探讨医院信息集成平台的必要性,以及集…
StarRocks 易用性全面提升:数据导入可以如此简单
作为新一代分析型数据库,StarRocks 一直因性能卓越、功能全面而深受广大用户喜爱。在追求功能和性能的同时,易用性方面,StarRocks 也在一直围绕一线运维人员的作业细节持续提升,尤其从 V3.0 起,社区投入大量开发资源全…
[数据湖iceberg]-hive集成数据湖读取数据的正确姿势
1 概述
Iceberg作为一种表格式管理规范,其数据分为元数据和表数据。元数据和表数据独立存储,元数据目前支持存储在本地文件系统、HMS、Hadoop、JDBC数据库、AWS Glue和自定义存储。表数据支持本地文件系统、HDFS、S3、MinIO、OBS、OSS等。元数据存储基于…
ETL数据仓库的使用方式
一、ETL的过程
在 ETL 过程中,数据从源系统中抽取(Extract),经过各种转换(Transform)操作,最后加载(Load)到目标数据仓库中。以下是 ETL 数仓流程的基本步骤:…

Doris实战——结合Flink构建极速易用的实时数仓
目录
一、实时数仓的需求与挑战
二、构建极速易用的实时数仓架构
三、解决方案
3.1 如何实现数据的增量与全量同步
3.1.1 增量及全量数据同步
3.1.2 数据一致性保证
3.1.3 DDL 和 DML 同步
Light Schema Change
Flink CDC DML 和DDL同步
3.2 如何基于Flink实现多种数…
hive--字符串连接函数concat(),concat_ws()
一、字符串连接函数:concat 功能:将多个字符串连接成一个字符串
语法: concat(string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果,支持任意个输入字符串
举例: hive> select concat(abc, …
StarRocks实战——表设计规范与监控体系
目录
前言
一、StarRocks表设计
1.1 字段类型
1.2 分区分桶
1.2.1 分区规范
1.2.2 分桶规范
1.3 主键表
1.3.1 数据有冷热特征
1.3.2 大宽表
1.4 实际案例
1.4.1 案例一:主键表内存优化
1.4.2 案例一:Update内存超了,导致主键表导…

StarRocks实战——滴滴OLAP的技术实践与发展方向
原文大佬的这篇StarRocks实践文章整体写的很深入,介绍了StarRocks数仓架构设计、物化视图加速实时看板、全局字典精确去重等内容,这里直接摘抄下来用作学习和知识沉淀。
目录
一、背景介绍
1.1 滴滴OLAP的发展历程 1.2 OLAP引擎存在的痛点
1.2.1 运维…
数据仓库 vs. 数据湖:解析两者的区别与优劣
在当今数字化时代,数据成为了企业最宝贵的资产之一。为了更好地管理和利用数据,企业需要建立合适的数据存储和管理系统。在这个过程中,数据仓库和数据湖成为了两种常见的选择。虽然它们都旨在帮助企业管理数据,但在实际应用中&…
EMR StarRocks实战——猿辅导的OLAP演进之路
目录
一、数据需求产生
二、OLAP选型
2.1 需求
2.2 调研 2.3 对比
三、StarRocks的优势
四、业务场景和技术方案
4.1 整体的数据架构
4.2 BI自助/报表/多维分析
4.3 实时事件分析
4.5 直播教室引擎性能监控
4.4 B端业务后台—斑马
4.5 学校端数据产品—飞象星球
4…
(01)Hive的相关概念——架构、数据存储、读写文件机制
目录
一、架构及组件介绍
1.1 Hive整体架构
1.2 Hive组件
1.3 Hive数据模型(Data Model)
1.3.1 Databases
1.3.2 Tables
1.3.3 Partitions
1.3.4 Buckets
二、Hive读写文件机制
2.1 SerDe 作用
2.2 Hive读写文件流程
2.2.1 读取文件的过程
…
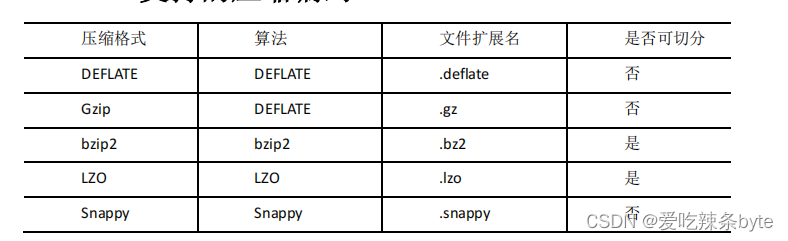
(10)Hive的相关概念——文件格式和数据压缩
目录
一、文件格式
1.1 列式存储和行式存储
1.1.1 行存储的特点
1.1.2 列存储的特点
1.2 TextFile
1.3 SequenceFile
1.4 Parquet
1.5 ORC
二、数据压缩
2.1 数据压缩-概述 2.1.1 压缩的优点 2.1.2 压缩的缺点
2.2 Hive中压缩配置
2.2.1 开启Map输出阶段压缩&…

ServletResponse接口
ServletResponse接口
ServletContext接口向servlet提供关于其运行环境的信息。上下文也称为Servlet上下文或Web上下文,由Web容器创建,用作ServletContext接口的对象。此对象表示Web应用程序在其执行的上下文。Web容器为所部署的每个Web应用程序创建一个ServletContext对象。…
HiveSQL题——用户连续登陆
目录
一、连续登陆
1.1 连续登陆3天以上的用户
0 问题描述
1 数据准备
2 数据分析
3 小结
1.2 每个用户历史至今连续登录的最大天数
0 问题描述
1 数据准备
2 数据分析
3 小结
1.3 每个用户连续登录的最大天数(间断也算)
0 问题描述
1 数据准备
2 数据分析
3 小…
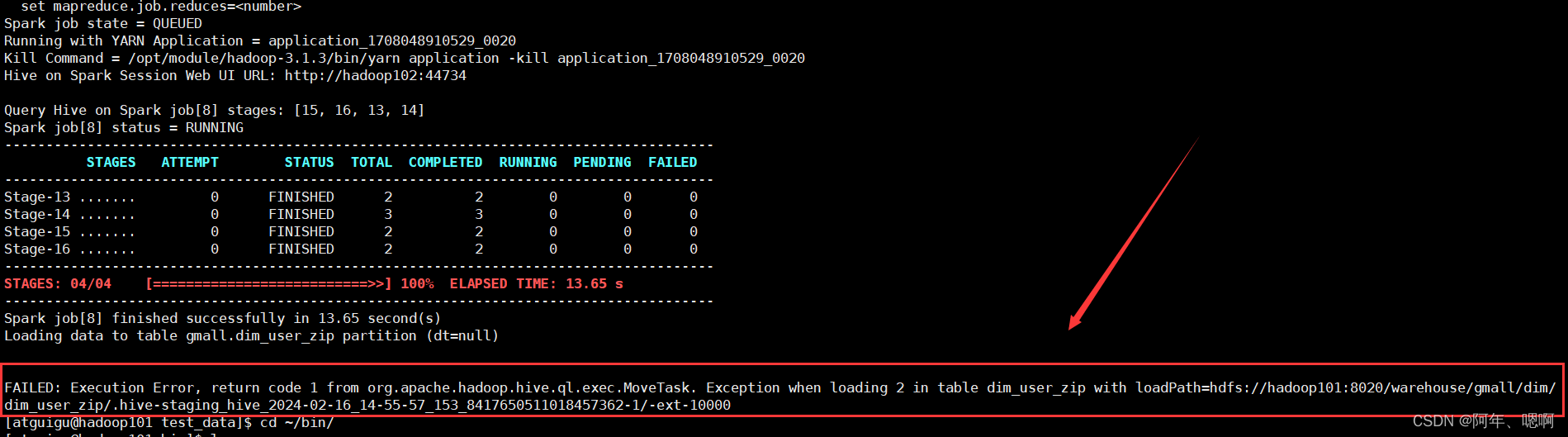
Hive拉链表设计、实现、总结
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 环境介绍实现1. 初始化拉链表2. 后续拉链表数据的更新 总结彩蛋 - 想清空表的数据:转成内部表,清空数据后,再转成外部表,将分区目录删掉&am…
如何构建Hive数据仓库Hive 、数据仓库的存储方式 以及hive数据的导入导出
什么是Hive
hive是基于Hadoop的一个数据仓库工具,可以将结构化数据映射为一张表。 hive支持使用sql语法对存储的表进行查询 (本质上是把sql转成mapreduce的任务执行)
Hive有三个特点:
hive所存储的数据是放在HDFS文件系统中的h…
StarRocks实战——松果出行实时数仓实践
目录
一、背景
二、松果出行实时OLAP的演进
2.1 实时数仓1.0的架构
2.2 实时数仓2.0的架构
2.3 实时数仓3.0的架构
三、StarRocks 的引入
四、StarRocks在松果出行的应用
4.1 在订单业务中的应用
4.2 在车辆方向的应用
4.3 StarRocks “极速统一” 落地
4.4 StarRoc…
HiveSQL题——排序函数(row_number/rank/dense_rank)
一、窗口函数的知识点
1.1 窗户函数的定义 窗口函数可以拆分为【窗口函数】。窗口函数官网指路:
LanguageManual WindowingAndAnalytics - Apache Hive - Apache Software Foundationhttps://cwiki.apache.org/confluence/display/Hive/LanguageManual%20Windowin…
(07)Hive——窗口函数详解
一、 窗口函数知识点
1.1 窗户函数的定义 窗口函数可以拆分为【窗口函数】。窗口函数官网指路:
LanguageManual WindowingAndAnalytics - Apache Hive - Apache Software Foundationhttps://cwiki.apache.org/confluence/display/Hive/LanguageManual%20Windowing…
hive中常见参数优化总结
1.with as 的cte优化,一般开发中习惯使用with as方便阅读,但如果子查询结果在下游被多次引用,可以使用一定的参数优化手段减少表扫描次数 默认set hive.optimize.cte.materialize.threshold-1;不自动物化到内存,一般可以设置为 se…

数据库 与 数据仓库
OLTP 与 OLAP OLTP(On Line Transaction Processing,联机事务处理)
系统主要针对具体业务在数据库联机下的日常操作,适合对少数记录进行查询、修改,例如财务管理系统、ERP系统、交易管理系统等。该类系统侧重于基本的、日常的事务处理&#…
数仓实战——京东数据指标体系的构建与实践
目录
一、如何理解指标体系
1.1 指标和指标体系的基本含义
1.2 指标和和标签的区别
1.3 指标体系在数据链路中的位置和作用
1.4 流量指标体系
1.5 指标体系如何向上支撑业务应用
1.6 指标体系背后的数据加工逻辑
二、如何搭建和应用指标体系
2.1 指标体系建设方法—OS…
(09)Hive——CTE 公共表达式
目录
1.语法 2. 使用场景
select语句
chaining CTEs 链式
union语句
insert into 语句
create table as 语句
前言 Common Table Expressions(CTE):公共表达式是一个临时的结果集,该结果集是从with子句中指定的查询派生而来…
HIVE中的常用和不常用的函数总结及hive中的常见问题(自用)
笛卡尔积
假设A和B是两个集合,存在一个集合,它的元素是用A中元素为第一元素,B中元素为第二元素构成的有序二元组,这个集合称为集合A和集合B的笛卡尔积,记为A X B。
eg:假设集合A{a, b},集合B{0, 1, 2}&am…
CloudCanal x Hive 构建高效的实时数仓
简述
CloudCanal 最近对于全周期数据流动进行了初步探索,打通了Hive 目标端的实时同步,为实时数仓的构建提供了支持,这篇文章简要做下分享。
基于临时表的增量合并方式基于 HDFS 文件写入方式临时表统一 Schema任务级的临时表
基于临时表的…
性能比较:in和exists
当在Hive SQL中使用NOT IN和NOT EXISTS时,性能差异主要取决于底层数据的组织方式、数据量大小、索引的使用情况以及具体查询的复杂程度。下面是对这两种方法的性能分析:
1. NOT IN:- 工作原理:NOT IN子查询会逐个比较主查询中的值…
从Pandas到Polars :数据的ETL和查询
对于我们日常的数据清理、预处理和分析方面的大多数任务,Pandas已经绰绰有余。但是当数据量变得非常大时,它的性能开始下降。
本文将介绍如何将日常的数据ETL和查询过滤的Pandas转换成polars。
图片
Polars的优势 Polars是一个用于Rust和Python的Data…
hive中如何取交集并集和差集
交集 要获取两个表的交集,你可以使用INNER JOIN或者JOIN:
SELECT *
FROM table1
JOIN table2 ON table1.column_name table2.column_name;也可以使用 INTERSECT 关键字
SELECT * FROM table1
INTERSECT
SELECT * FROM table2;并集 要获取两个表的并集…
![[自研开源] 数据集成之分批传输 v0.7](https://img-blog.csdnimg.cn/direct/cc203271f1e94b9186cd195781d39c03.png)
[自研开源] 数据集成之分批传输 v0.7
开源地址:gitee | github 详细介绍:MyData 基于 Web API 的数据集成平台 部署文档:用 Docker 部署 MyData 使用手册:MyData 使用手册 试用体验:https://demo.mydata.work 交流Q群:430089673
介绍
本篇基于…
Hive在虚拟机中的部署
安装Mysql数据库
# 更新密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
# 安装Mysql yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
# yum安装Mysql
yum -y install mysql-community-server
# 启动Mysql设置开机启动…
hive授予指定用户特定权限及beeline使用
背景:因业务需要,需要使用beeline对hive数据进行查询,但是又不希望该用户可以查询所有的数据,希望有一个新用户bb给他指定的库表权限。
解决方案:
1.赋权语句,使用hive管理员用户在终端输入hive进入命令控…
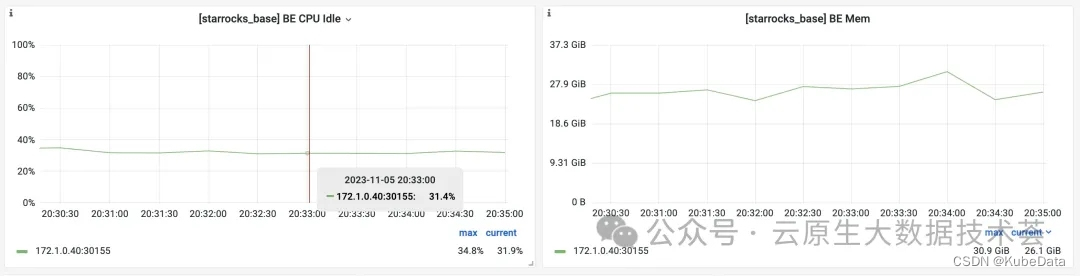
Starrocks基于主机和容器的读写测试
背景介绍
在云原生时代,存算分离架构显然已经是当下大数据架构的必备选型,但是在不同的虚拟化计算资源(主机、容器)之上,是否能有差异点以及对于不同服务的性能损耗程度如何?来判断应该在什么样的场景下选…
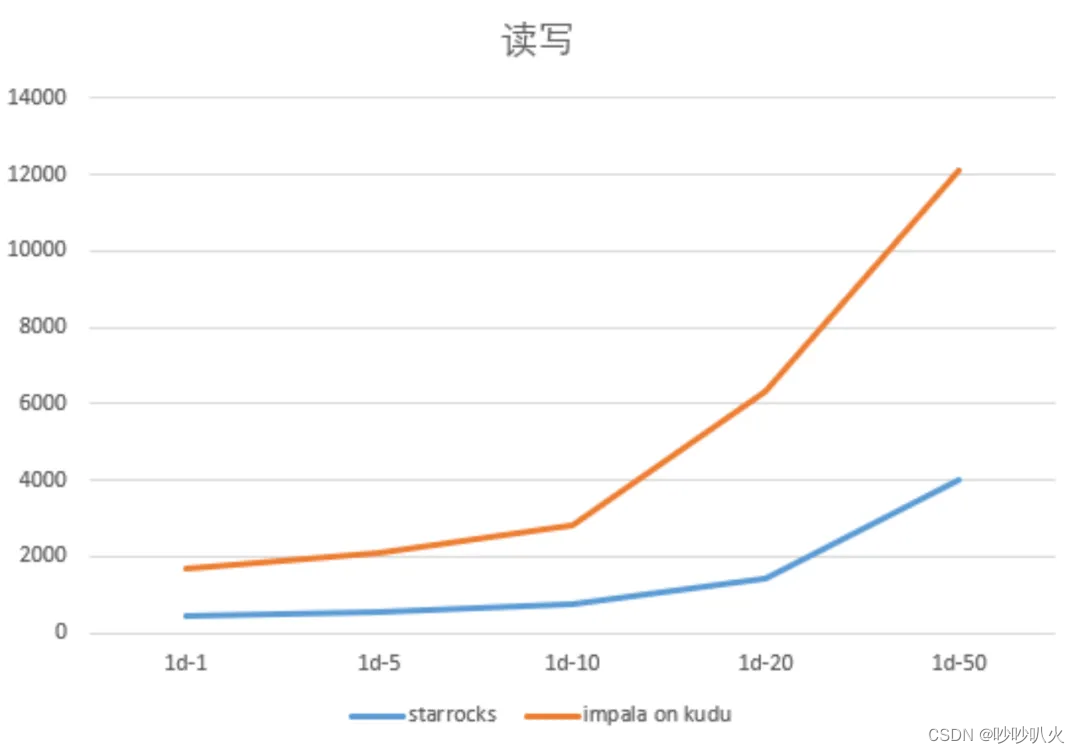
StarRocks实战——多点大数据数仓构建
目录
前言
一、背景介绍
二、原有架构的痛点
2.1 技术成本
2.2 开发成本
2.2.1 离线 T1 更新的分析场景
2.2.2 实时更新分析场景
2.2.3 固定维度分析场景
2.2.4 运维成本
三、选择StarRocks的原因
3.1 引擎收敛
3.2 “大宽表”模型替换
3.3 简化Lambda架构
3.4 模…
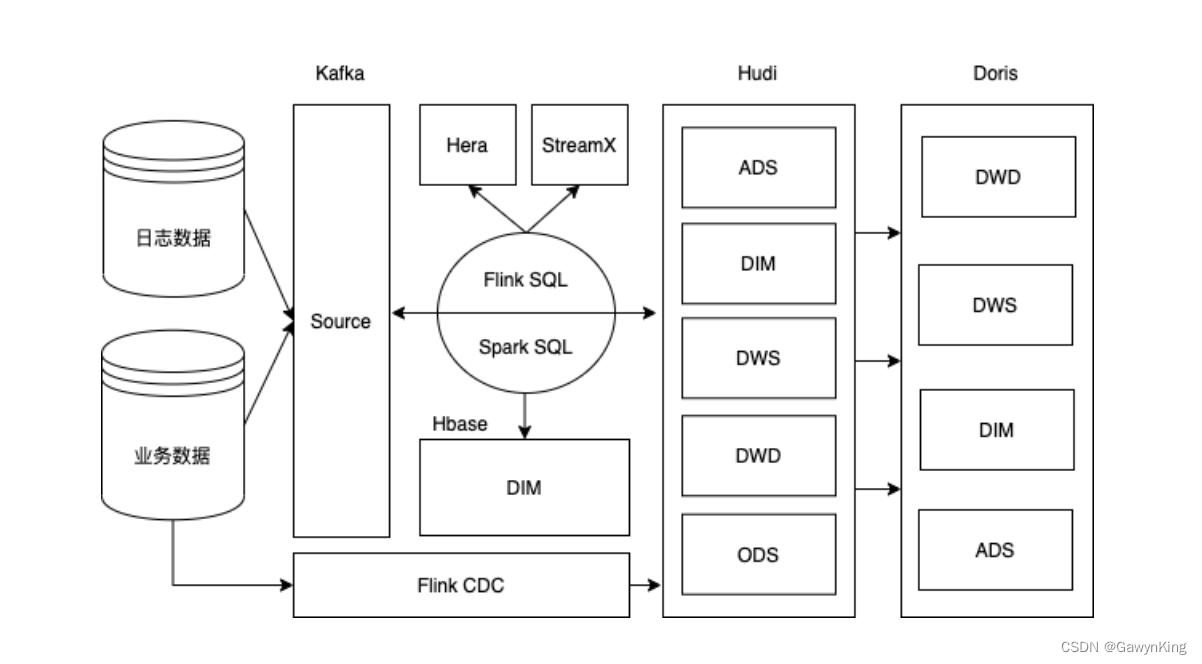
实时数仓之实时数仓架构(Hudi)
目前比较流行的实时数仓架构有两类,其中一类是以FlinkDoris为核心的实时数仓架构方案;另一类是以湖仓一体架构为核心的实时数仓架构方案。本文针对FlinkHudi湖仓一体架构进行介绍,这套架构的特点是可以基于一套数据完全实现Lambda架构。实时数…
数据仓库——事务、快照和累积快照事实表
事务、快照和累积快照
事务事实表跟踪定义业务过程的个体行为,并且支持几种描述这种行为事实。可以提供丰富的分析型能力,时常充当原子数据的粒度化仓库快照事实表周期性地采样状态度量,这些度量与一系列事务的累积效果相当,但是…
多语言接入电商平台API接口【淘宝天猫、京东、拼多多、1688等】获得店铺的所有商品-item_search_shop
要实现多语言接入电商平台API接口(如淘宝天猫、京东、拼多多、1688等)获得店铺的所有商品,可以采用以下步骤: 注册申请API key和API secret,获取相应的API接口权限。 了解各大电商平台API接口的文档,熟悉接…
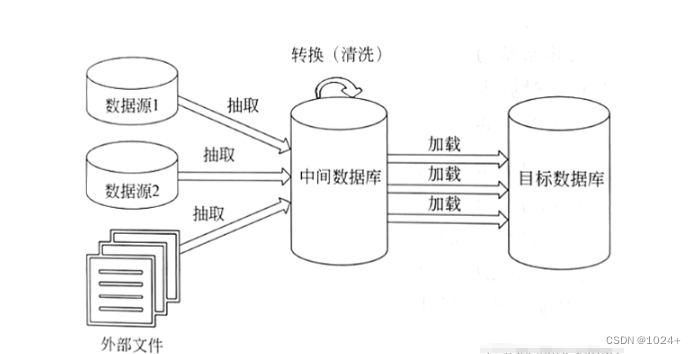
ETL:数据转换与集成的关键过程
ETL:数据转换与集成的关键过程
在现代数据驱动的世界中,有效地管理和处理数据对于企业的成功至关重要。ETL(提取、转换、加载)是一种关键的数据处理过程,有助于将数据从源系统提取、清洗、转换并加载到目标系统中&…

Zoho Bigin斩获PCMag推崇:小企业首选CRM软件
当我们谈论企业怎样选择CRM管理系统时,大型企业、中型企业以及小型或初创等不同规模的企业需求各不相同,很难用一套软件来适配所有公司。以小企业为例,大多面临预算紧张、没有专业的IT部门或支持团队、暂时用不到高级定制功能等现状。基于这个…


Presto简介、部署、原理和使用介绍
Presto简介、部署、原理和使用介绍
1. Presto简介
1-1. Presto概念
Presto是由Facebook开发的一款开源的分布式SQL查询引擎,最初于2012年发布,并在2013年成为Apache项目的一部分;Presto 作为现在在企业中流行使用的即席查询框架&#x…
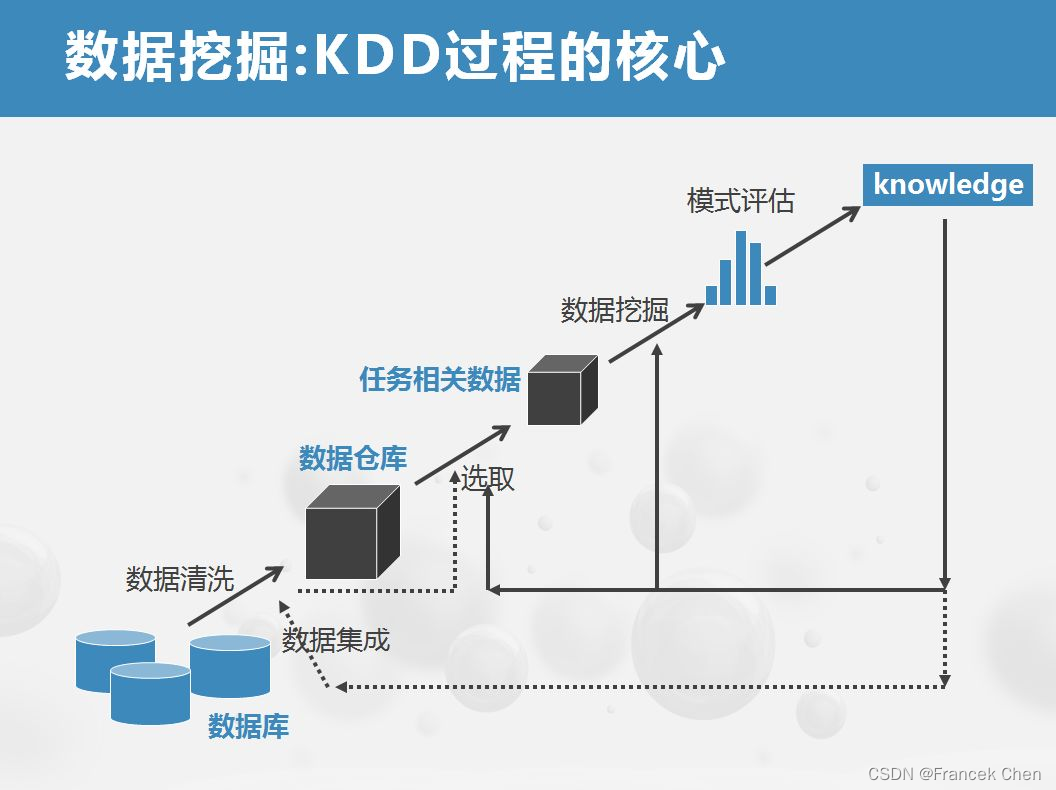
数据仓库与数据挖掘概述
目录
一、数据仓库概述
(一)从传统数据库到数据仓库
(二)数据仓库的4个特征
(三)数据仓库系统
(四)数据仓库系统体系结构
(五)数据仓库数据的粒度与组织…
【错误处理】【Hive】【Spark】ERROR FileFormatwriter: Aborting job null.
问题背景
近日,使用 Spark 在读写 Hive 表时发生了报错:Aborting job null,如果怎么都使用不了那张表的话,大概率是那张表有脏数据,导致整张表无法正常使用。
ERROR FileFormatwriter: Aborting job null.解决方法
…
Doris实践——同程数科实时数仓建设
目录
前言
一、早期架构演进
二、Doris和Clickhouse选型对比
三、新一代统一实时数据仓库
四、基于Doris的一站式数据平台
4.1 一键生成任务脚本提升任务开发效率
4.2 自动调度监控保障任务正常运行
4.3 安全便捷的可视化查询分析
4.4 完备智能的集群监控
五、收益与…
京东业务场景API接口通过商品id获得JD商品详情APIitem_get-获得JD商品详情接入示例
京东业务场景API接口通过商品id获得JD商品详情的接入示例如下: 首先,你需要注册一个ApiKey和ApiSecret。 然后,使用ApiKey和ApiSecret获取访问令牌(access_token)。 最后,使用访问令牌调用item_get接口&a…
数据仓库——特殊类型的星型模式
数据仓库基础笔记思维导图已经整理完毕,完整连接为: 数据仓库基础知识笔记思维导图
特殊类型的星型模式
通过维度表示的事物通常可以按照类别或者类型细分。有时想要在维度表中记录的属性类型是多样的。 尽管类型相同,但是却存在很大差别。…
有关数据开发项目中使用HIVE由于无法update和delete的场景下,如何解决数据增量的思路
解决数据增量问题的思路在Hive中
在数据开发项目中,使用Hive进行数据处理时,由于Hive不支持update和delete语句,处理数据增量可能会变得有些棘手。然而,有几种策略和技术可以帮助我们解决这个问题,并确保数据增量的高…
hive词频统计---文件始终上传不来
目录
准备工作:
文件内容:
创建数据库及表
将文件上传到:上传到/user/hive/warehouse/db1.db/t_word目录下
hive里面查询,始终报错:(直接查询也是不行)
解决方案: 准备工作&am…
湖仓管理系统 Amoro部署
简介
Apache Amoro(incubating) 是一个构建在 Apache Iceberg 等开放数据湖表格之上的湖仓管理系统,提供了一套可插拔的数据自优化机制和管理服务,旨在为用户带来开箱即用的湖仓使用体验。
Amoro 的愿景是依托于 Apache Iceberg、Apache Paimon 等新型数据湖表格式的基础功…
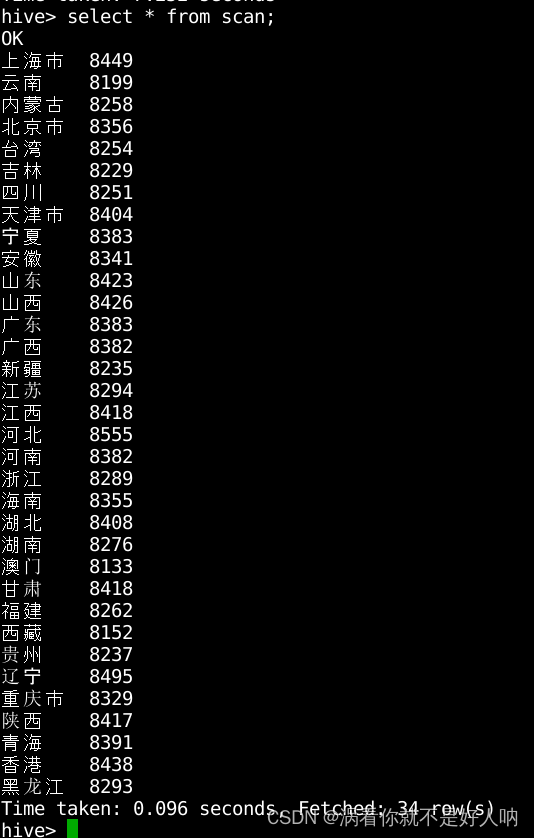

Day2-Hive的多字段分区,分桶和数据类型
Hive
表结构
分区表 多字段分区:需要使用多个字段来进行分区,那么此时字段之间会构成多层目录,前一个字段形成的目录会包含后一个字段形成的目录,从而形成多级分类的效果。例如商品的大类-小类-子类, 省市县、年级班…

StarRocks实战——华米科技埋点分析平台建设
目录
前言
一、原有方案及其痛点
二、引入StarRocks
三、方案改造
3.1 架构设计
3.2 数据流程
3.3 性能指标
3.4 改造收益 前言 华米科技是一家基于云的健康服务提供商,每天都会有海量的埋点数据,以往基于HBase建设的埋点计算分析项目往往效率上…

入门用Hive构建数据仓库
在当今数据爆炸的时代,构建高效的数据仓库是企业实现数据驱动决策的关键。Apache Hive 是一个基于 Hadoop 的数据仓库工具,可以轻松地进行数据存储、查询和分析。本文将介绍什么是 Hive、为什么选择 Hive 构建数据仓库、如何搭建 Hive 环境以及如何在 Hi…

【数据库】SQL简介
SQL(Structured Query Language,结构化查询语言)是一种用于管理关系型数据库管理系统(RDBMS)的标准化语言。它用于访问和操作数据库中的数据,执行各种任务,如插入、更新、删除和检索数据&#x…
Hive分组排序取topN的sql查询示例
Hive分组排序取topN的sql查询示例 要在Hive中实现分组排序并取每组的前N条记录,可以使用 ROW_NUMBER() 窗口函数结合 PARTITION BY 和 ORDER BY 子句。 以下是一个示例SQL查询,用于选择每个部门中工资最高的前3名员工:
SELECT department, e…
专家解读:2024年十大项目管理工具综合排名与评价
2024年涌现出一批新的项目管理工具,各具特色的功能和设计为企业解决了诸多的管理难题。今天我们就来盘点2024年的十款项目管理工具Zoho Projects、AgileMaster、PlanItAll、CommuniQ、WorkFlowRanger、GanttGenius、RiskAssessor、TeamHarmony、BudgetBoss、CloudCo…
Spark连接MySQL表数据
Spark连接MySQL表数据
一、官网语法
http://spark.apache.org/docs/latest/sql-data-sources-jdbc.htmlval jdbcDF spark.read.format("jdbc").option("url", "jdbc:postgresql:dbserver").option("dbtable", "schema.tablena…

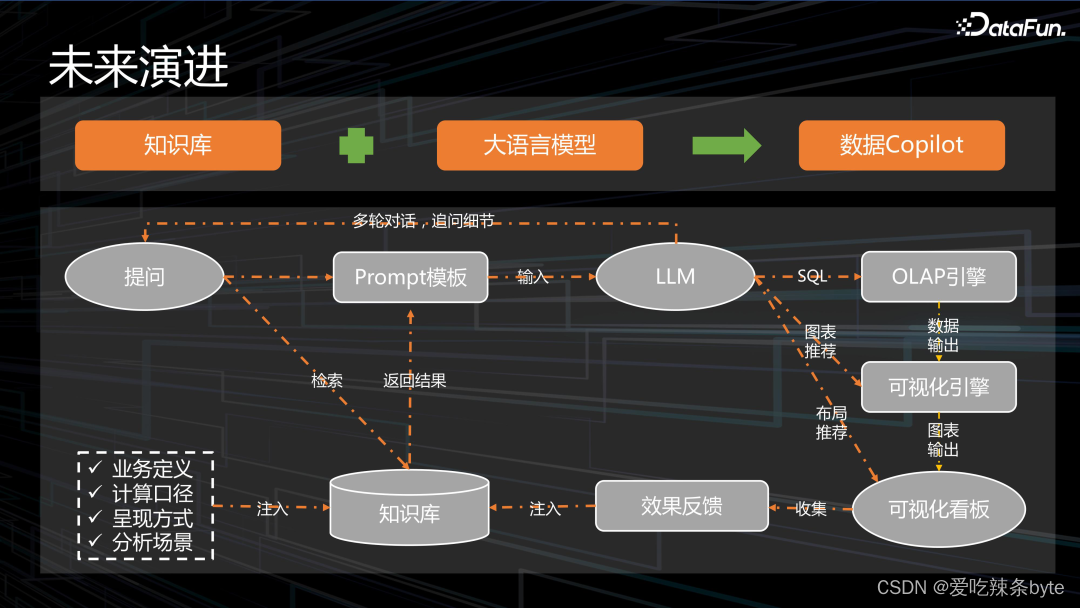
数据治理实践——YY 直播业务指标治理实践
目录
一、问题背景
1.1 问题场景
1.2 问题小结
二、治理方案
2.1 治理目标
2.2 团队协同,共建规范
2.3 指标管理的定位
2.4 指标管理的目标及思路
2.5 指标管理,规范内容落地
2.6 数仓设计-关联指标维度
2.7 数据报表开发-配置口径说明
2.8 …
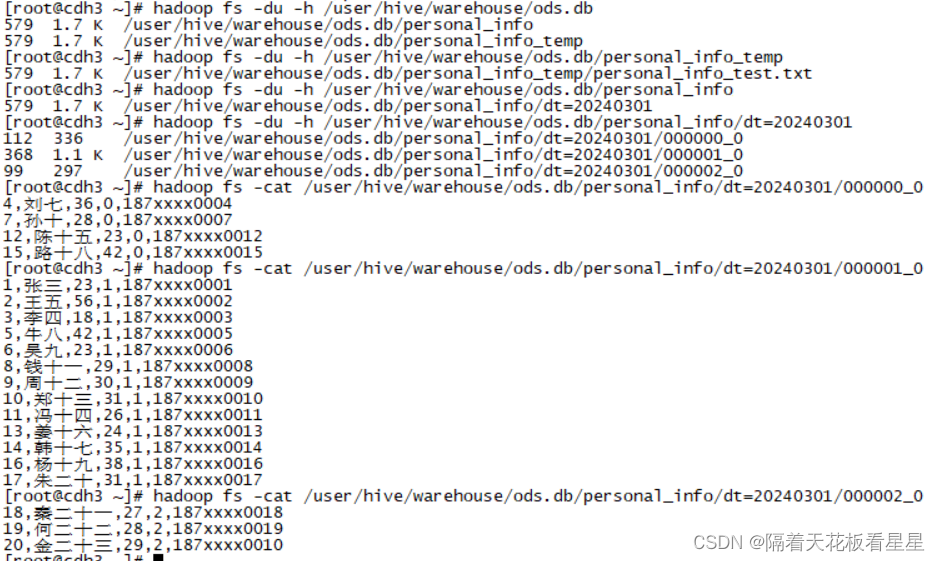
数据仓库作业一:第1章 绪论
目录 一、给出下列英文短语或缩写的中文名称,并简述其含义。二、简述操作型数据与分析型数据的主要区别。三、简述数据仓库的定义。四、简述数据仓库的特征。五、简述主题的定义。六、简述元数据的概念。七、简述数据挖掘的主要任务。八、简述数据挖掘的主要步骤。九…
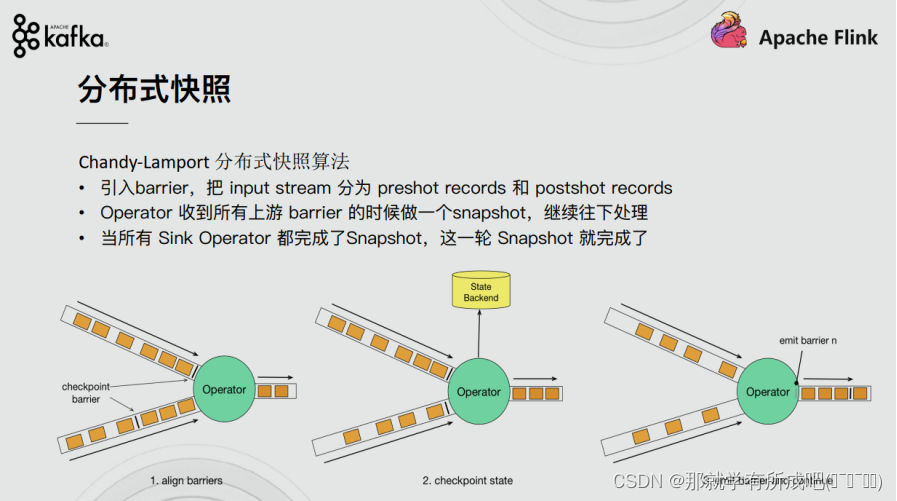
flink重温笔记(十二): flink 高级特性和新特性(1)——End-to-End Exactly-Once(端到端精确一致性语义)
Flink学习笔记 前言:今天是学习 flink 的第 12 天啦!学习了 flink 高级特性和新特性之 End-to-End Exactly-Once(端到端精确一致性语义),主要是解决大数据领域数据从数据源到数据落点的一致性,不会容易造成…
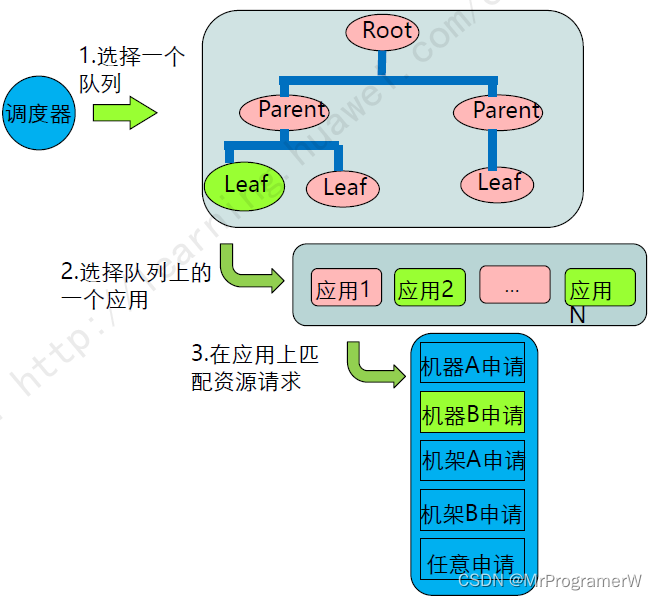
ETL数据倾斜与资源优化
1.数据倾斜实例
数据倾斜在MapReduce编程模型中比较常见,由于key值分布不均,大量的相同key被存储分配到一个分区里,出现只有少量的机器在计算,其他机器等待的情况。主要分为JOIN数据倾斜和GROUP BY数据倾斜。
1.1GROUP BY数据倾…
数据仓库——维度表一致性
维度一致性问题
从逻辑层面来看,当一系列星型模型共享一组公共维度时,所涉及的维度称为一致性维度。当维度表存在不一致时,短期的成功难以弥补长期的错误。 维度时确保不同过程中信息集成起来实现横向钻取货活动的关键。
造成横向钻取失败的…
【大数据】-- maxcompute/odps 存储优化之小文件合并
1、背景 在 flink 写入 odps 表时,发现抛出了异常。经过查询知道原因是该 odps table 表的小文件过多,超过了最大数量,导致写入失败。
2、小文件的定义 分布式文件系统按块(Block)存放数据,文件大小比块大小(64MB)小的文件称为小文件。分布式系统不可避免会产生小文件…
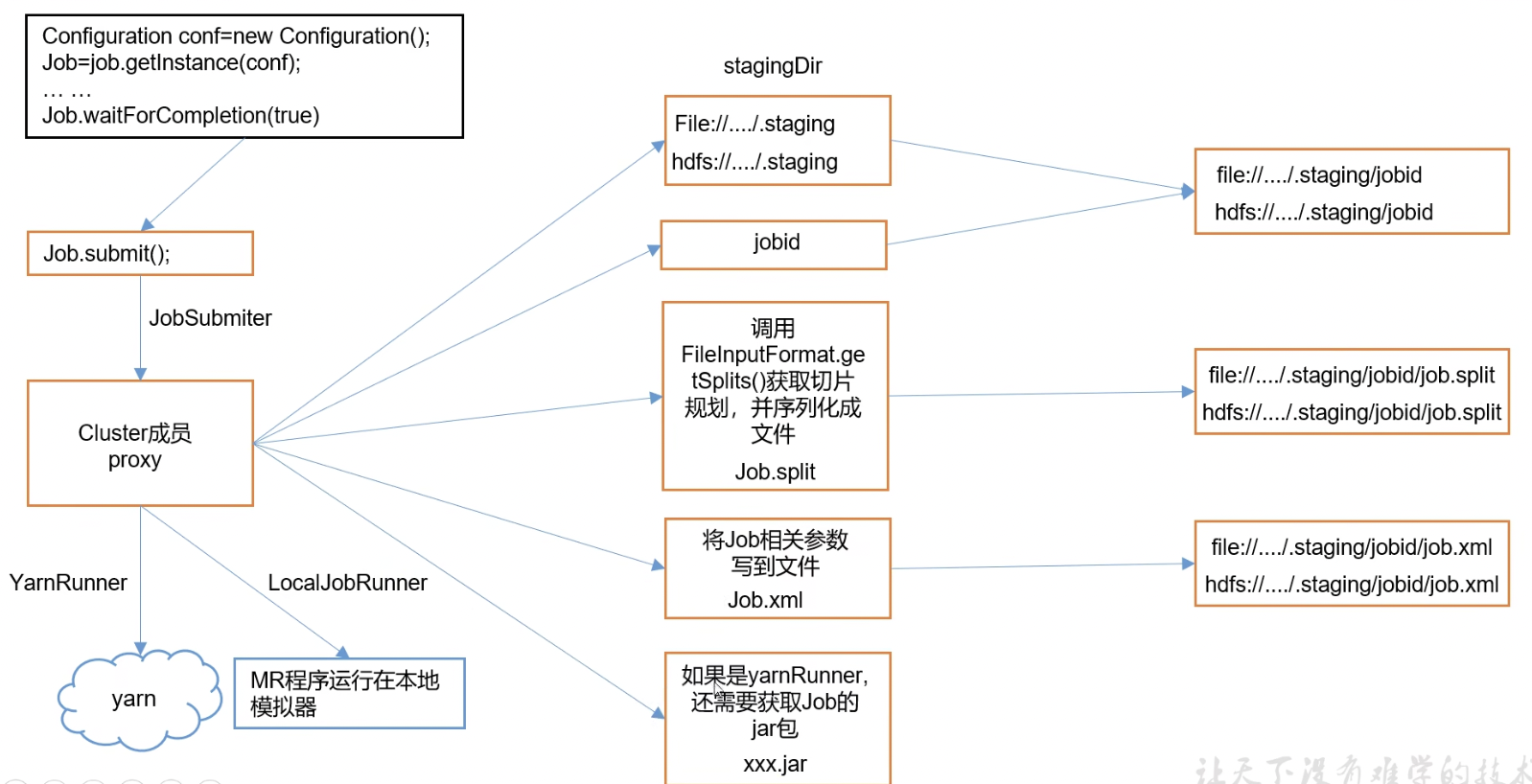
【MapReduce】03.MapReduce框架原理
1.InputFormat数据输入
1.1.切片与MapTask并行度决定机制 MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
MapTask并行度决定机制 数据块:Block是HDFS物理上的数据分割,数据块是HDFS存储数据单位 数据切片&…

Hive中增量插入的处理
增量数据采集,目前实现的方式是hive中按某个字段创建分区表, insert override的时候where语句带上对应的增量过滤条件。 我一般选取日期字段ETL_DATE。
hive建立分区表,hql如下:
CREATE TABLE IF NOT EXISTS product_sell( cate…
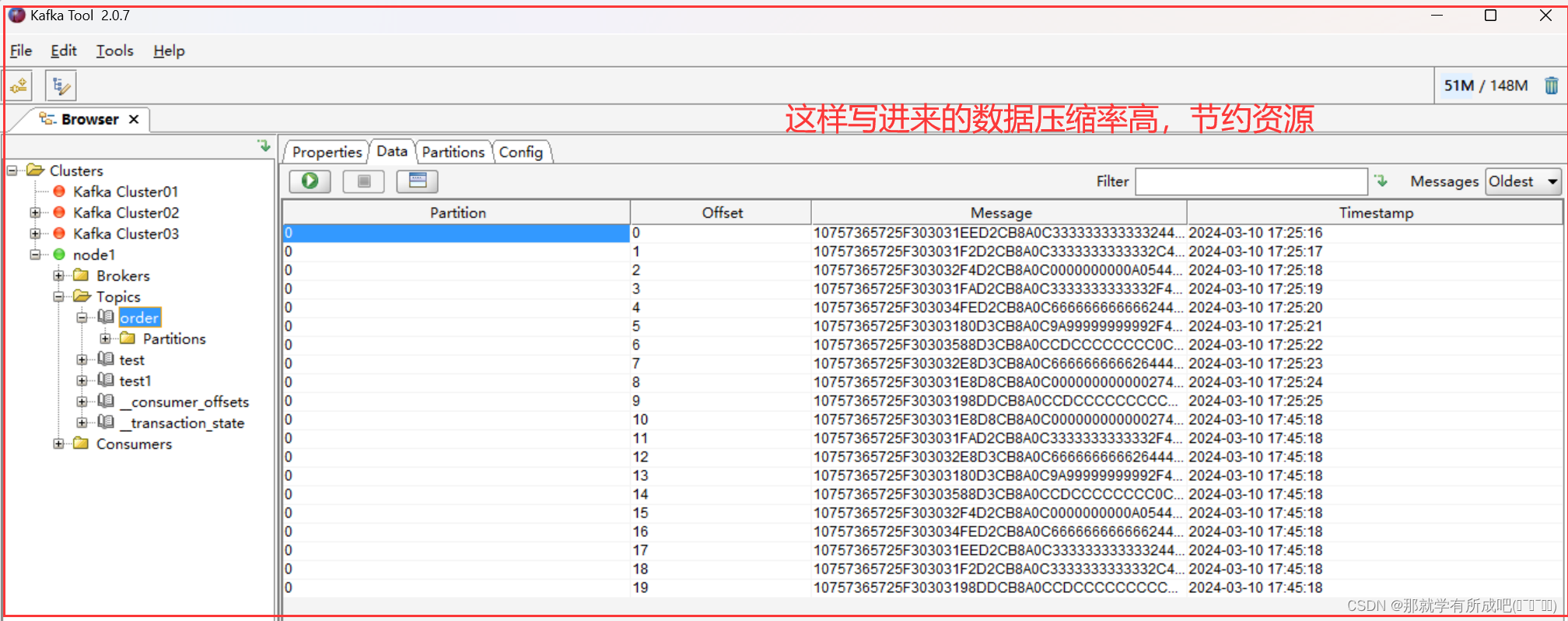
flink重温笔记(十四): flink 高级特性和新特性(3)——数据类型及 Avro 序列化
Flink学习笔记 前言:今天是学习 flink 的第 14 天啦!学习了 flink 高级特性和新特性之数据类型及 avro 序列化,主要是解决大数据领域数据规范化写入和规范化读取的问题,avro 数据结构可以节约存储空间,本文中结合企业真…
数据仓库的作用和价值
支持管理决策分析
支持管理决策分析 数据仓库集成了企业各类运营和外部数据,为管理者提供了全面透明的数据视图,帮助他们洞察业务动态,发现问题和机遇。 通过多维度的数据分析、预测建模等,能够为企业未来战略制定、投资规划等重大决策提供依据。
案例:沃尔玛的数据仓库囊括了…
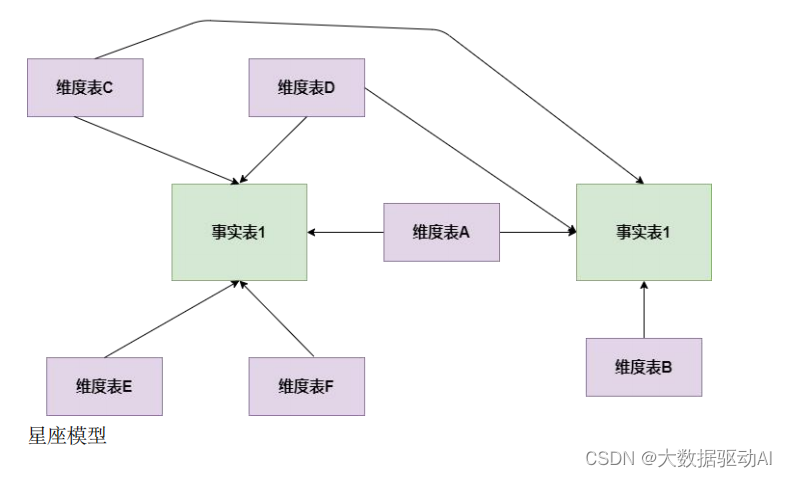

深入浅出Hive性能优化策略
我们将从基础的HiveQL优化讲起,涵盖数据存储格式选择、数据模型设计、查询执行计划优化等多个方面。会的直接滑到最后看代码和语法。
目录
引言
Hive架构概览
示例1:创建表并加载数据
示例2:优化查询
Hive查询优化
1. 选择适当的文件格…

OLAP与数据仓库和数据湖
OLAP与数据仓库和数据湖
本文阐述了OLAP、数据仓库和数据湖方面的基础知识以及相关论文。同时记录了我如何通过ChatGPT以及类似产品(通义千问、文心一言)来学习知识的。通过这个过程让我对于用AI科技提升学习和工作效率有了实践经验和切身感受。
预热 …
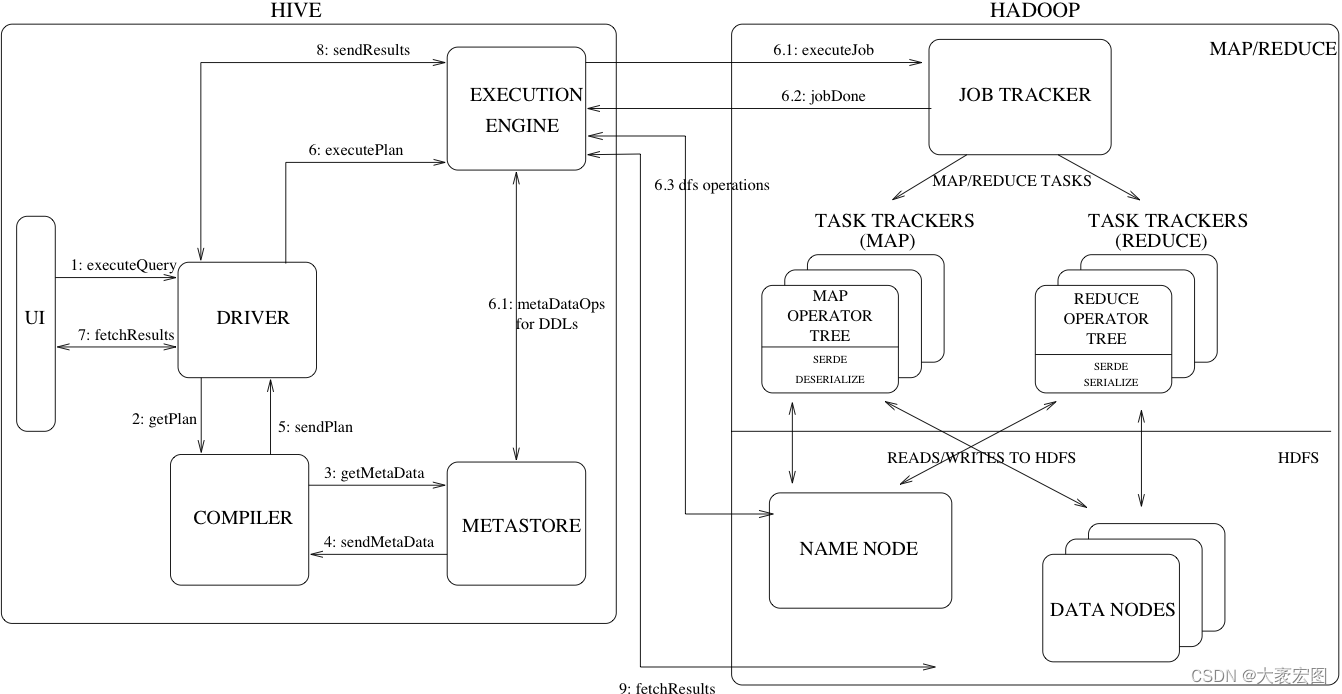
Hive:数据仓库利器
1. 简介
Hive是一个基于Hadoop的开源数据仓库工具,可以用来存储、查询和分析大规模数据。Hive使用SQL-like的HiveQL语言来查询数据,并将其结果存储在Hadoop的文件系统中。
2. 基本概念
介绍 Hive 的核心概念,例如表、分区、桶、HQL 等。
…
如何通过ETL做数据转换
在数字化时代,数据被誉为新时代的石油,而数据的价值往往隐藏在海量数据背后的信息中。然而,海量的原始数据并不总是直接可用的,这就需要一种有效的工具来对数据进行提取、转换和加载(ETL),从而将…
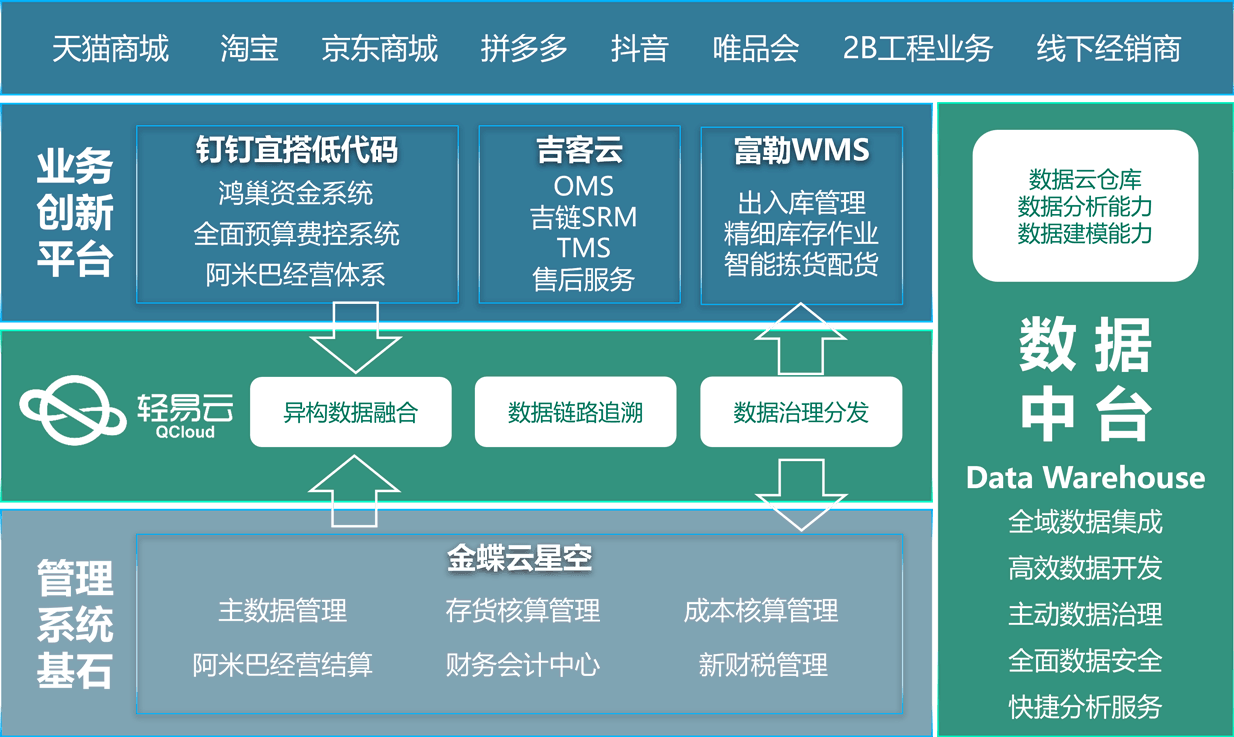
从四化智造MES(WEB)到金蝶云星空通过接口配置打通数据
从四化智造MES(WEB)到金蝶云星空通过接口配置打通数据
来源系统:四化智造MES(WEB) MES建立统一平台上通过物料防错防错、流程防错、生产统计、异常处理、信息采集和全流程追溯等精益生产和精细化管理,帮助…
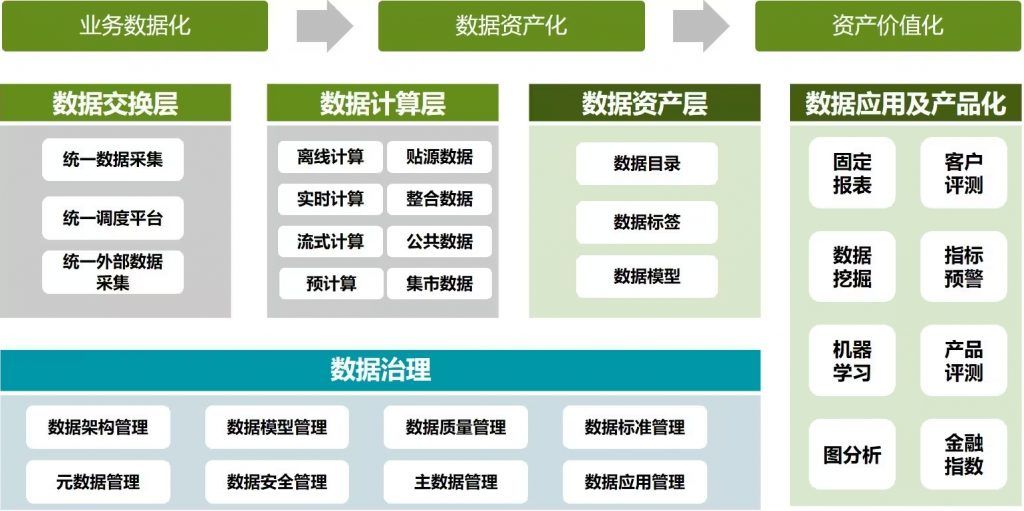
解析什么是数据中台:企业数字化转型的核心引擎
在当今这个快速变化的商业环境中,数字化转型已成为企业持续增长和保持竞争力的必由之路。数据中台作为这一转型过程中的关键策略,正逐渐受到越来越多企业的关注和重视。本文将深入探讨数据中台的核心能力,分析企业为何需要这一战略࿰…
FlinkSQL之保序任务对于聚合SQL影响分析
本文以一个示例说明FlinkSQL如何针对上游乱序数据源设计保序任务,从而保证下游数据准确性。废话不多说,这里以交易数据场景为例. 数据表结构为: create table tbl_order_source(order_id int comment 订单ID,shop_…
Doris安装使用(基于Doris 2.0.6)
第 1 章Doris简介
1.1、 Doris 概述
Apache Doris由百度大数据部研发(之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris),在百度内部,有超过200个产品线在使用,部署机器超过1000台…
模型设计和跑数优化1:开发数据仓库耗时复杂报表的策略
在使用Spark和Doris进行数据仓库开发时,报表生成的效率对于业务分析和决策支持至关重要。当报表复杂且数据量大时,任何改动都可能导致需要重新从零开始处理数据,这不仅耗时而且资源消耗巨大。更为严重的时,可以导致项目延期,影响了绩效,甚至因此失业。为了优化这一过程,…
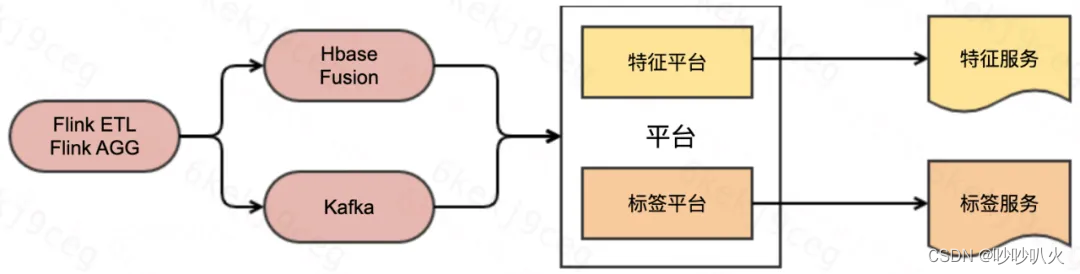
实时数仓建设实践——滴滴实时数据链路组件的选型
目录
前言
一、实时数据开发在公司内的主要业务场景
二、实时数据开发在公司内的通用方案
三、特定场景下的实时数据开发组件选型
3.1 实时指标监控场景
3.2 实时BI分析场景
3.3 实时数据在线服务场景
3.4 实时特征和标签系统
四、各组件资源使用原则
五、总结和展望…

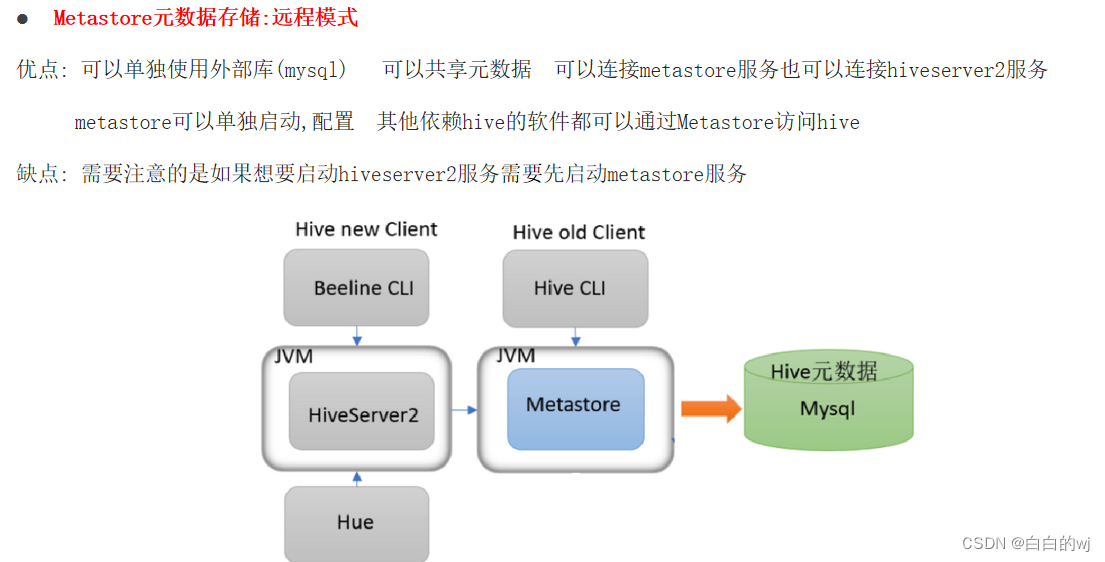
2023.11-9 hive数据仓库,概念,架构,元数据管理模式
目录 0.数据仓库和数据库
数据仓库和数据库的区别 数据仓库基础三层架构
一.HDFS、HBase、Hive的区别
二.大数据相关软件
三. Hive 的优缺点
1)优点
2)缺点
四. Hive 和数据库比较
1)查询语言
2)数据更新
3)…
[Hive] 常见函数
文章目录 字符串函数数值函数随机函数日期和时间函数字符串转时间 聚合函数数组函数结构体函数数组函数映射函数 map正则处理JSON 字符串函数
CONCAT(string1, string2, …):将多个字符串连接成一个字符串。
LENGTH(string):返回字符串的长度。
LOWER…

2023.11.13 hive数据仓库之分区表与分桶表操作,与复杂类型的运用
目录 0.hadoop hive的文档
1.一级分区表
2.一级分区表练习2 3.创建多级分区表
4.分区表操作
5.分桶表
6. 分桶表进行排序
7.分桶的原理 8.hive的复杂类型
9.array类型: 又叫数组类型,存储同类型的单数据的集合 10.struct类型: 又叫结构类型,可以存储不同类型单数据的集合…
[hive] 窗口函数 ROW_NUMBER()
文章目录 ROW_NUMBER() 示例窗口函数 ROW_NUMBER()
在 Hive SQL 中,ROW_NUMBER()是一个用于生成行号的窗口函数。
它可以为查询结果集中的每一行分配一个唯一的行号。
以下是 ROW_NUMBER() 函数的基本语法:
ROW_NUMBER() OVER (PARTITION BY column…

hive数仓-数据的质量管理
版本20231116 要理解数据的质量管理,应具备hive数据仓库的相关知识 文章目录 1.理解什么是数据的质量管理:2.数据质量管理的规划数据质量标准的分类 3.数据质量管理解决方案1.ods层的数据质量校验1)首先在hive上建立一个仓库,添加…

构建 hive 时间维表
众所周知 hive 的时间处理异常繁琐且在一些涉及日期的统计场景中会写较长的 sql,例如:周累计、周环比等;本文将使用维表的形式降低时间处理的复杂度,提前计算好标准时间字符串未来可能需要转换的形式。 一、表设计
结合业务场景常…
国家开放大学期末统一测试题
试卷代号:1494 员工劳动关系管理 参考试题 一、单项选择题(在各题的备选答案中,只有1项是正确的,请将正确答案的序号填写在题中的括号内,每小题2分,共10分)
1.工伤保险的投保人是( )。 …
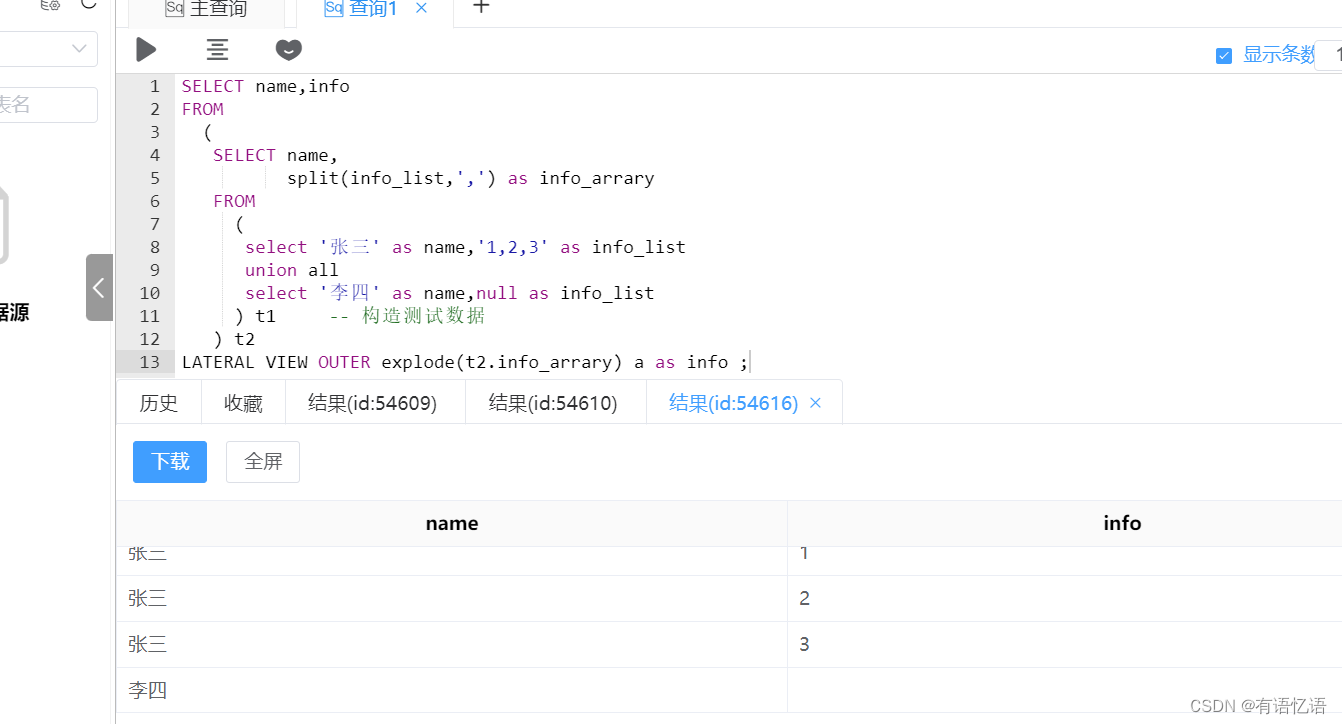
Hive Lateral View explode列为空时导致数据异常丢失
一、问题描述
日常工作中我们经常会遇到一些非结构化数据,因此常常会将Lateral View 结合explode使用,达到将非结构化数据转化成结构化数据的目的,但是该方法对应explode的内容是有非null限制的,否则就有可能造成数据缺失。
SE…
【hive基础】hive常见操作速查
文章目录 一. hive变量操作1. 查看当前hive配置信息2. 设置变量3. 修改变量4. 进入hive终端重新加载配置 二. 执行hive sql三. 启动hive 一. hive变量操作
1. 查看当前hive配置信息
# 查看当前所有配置信息
hive > set ;# 查看某一项配置信息
hive >set hive.metastore…
【数据仓库】数仓分层方法
文章目录 一. 数仓分层的意义1. 清晰数据结构。2. 减少重复开发3. 方便数据血缘追踪4. 把复杂问题简单化5. 屏蔽原始数据的异常6. 数据仓库的可维护性 二. 如何进行数仓分层?1. ODS层2. DW层2.1. DW层分类2.2. DWD层2.3. DWS 3. ADS层 4、层次调用规范 一. 数仓分层…
数据仓库及ETL的理论基础
数据仓库(Data Warehouse)是一个用于存储和管理大量结构化数据的系统,旨在支持企业的决策制定过程。它是一个集成的、主题导向的、时间变化的、非易失性的数据集合,用于支持企业的决策制定过程。数据仓库的设计目标是提供高性能的…
《数据仓库入门实践》
前言: 1、问什么要写这篇博客? 随着自己在数仓岗位工作的年限增加,对数仓的理解和认知也在发生着变化 所有用这篇博客来记录工作中用到的知识点与经验 2、这篇博客主要记录了哪些内容? 在日常工作中,发现刚接触不久数仓…
生产计划数据模型,实现能源企业数字化高效管理
随着市场经济的快速发展,能源企业在经济发展中的地位也随之提高。但由于能源企业在生产计划经济管理上存在指标不平衡、市场观念落后和环保意识欠缺等问题,导致企业的经济效益降低。目前,提高企业的生产计划管理是改善能源企业现状最有利的途…
数据仓库——雪花模式以及层次递归
层次结构
钻取
向下钻取:对某些代表事实的报表中添加维度细节 向上钻取:从某些代表事实的报表中去除维度细节
属性层次
提供了一种自然方法,用于顺序地在不断深入的层次上组织事实。许多维度可以被理解为包含连续主从关系的属性层次。此类…
Kimball维度模型之迟到的事实
在数据仓库建设的过程中,面对不断涌现的数据和信息,处理“迟到的事实”是一个至关重要的挑战。所谓“迟到的事实”,指的是在数据仓库已经建立并开始运行后,新增的数据或信息却具有之前时间戳的情况。这可能由于数据采集的延迟(比如…
Doris实战——天眼查Doris实时数仓构建
目录
前言
一、业务背景
二、原有架构及痛点
三、理想架构
四、技术选型
五、新数仓架构
六、应用场景优化
6.1 人群圈选
6.2 C端分析数据及精准营销线索场景
七、优化经验
八、规模和收益
九、未来规划 原文大佬的这篇实时数仓构建有借鉴意义的,这些摘…
数仓-hive DDL (带你手敲秒懂hive三种常见分区)
hive 数仓DDL 分区
分区是将表的数据以分区字段的值作为目录去存储
---> 减少磁盘IO, 方便数据管理
静态分区 创建外表同时指定静态分区字段 create table if not exists table_name(id int,name string)partitioned by (day string,h string); …
Kudu面试题及参考答案详解
Kudu是一个开源的列式存储系统,专为快速分析大量数据而设计。它结合了Hadoop生态系统中HDFS的可扩展性、Kudu的快速插入和更新能力以及Impala等SQL引擎的快速查询性能。作为一名大数据架构师,了解Kudu的工作原理和常见面试题对于构建高效的大数据处理系统至关重要。本文将为您…
Hive自定义GenericUDF函数
Hive自定义GenericUDF函数 当创建自定义函数时,推荐使用 GenericUDF 类而不是 UDF 类,因为 GenericUDF 提供了更灵活的功能和更好的性能。以下是使用 GenericUDF 类创建自定义函数的步骤: 编写Java函数逻辑:编写继承自 GenericUDF…
db2数据仓库集群的搭建
db2数据仓库集群的搭建
DB2 集群的搭建通常涉及到多个环节,包括网络配置、DB2 软件安装、集群配置和数据库创建等。以下是搭建DB2集群的基本步骤,并不是实际的命令和配置,因为每个环境的具体配置可能会有所不同。
1、网络配置:确…
hive中split函数相关总结
目录 split函数示例实战注意事项 split 函数一直再用,居然发现没有总结,遂补充一下;
split函数
在Hive中,split函数用于将一个字符串根据指定的分隔符进行分割,并返回一个数组。它的语法如下:
split(str…
安装CDH平台的服务器磁盘满了,磁盘清理过程记录
1.使用hdfs命令查看哪个文件占用最大
hdfs dfs -du -h /tmp
2.我的服务器上显示/tmp/hive/hive文件夹下的,一串字符串命名的文件特别大几乎把磁盘占满了
网上查到/tmp文件是临时文件,由于hiveserver2任务运行异常导致缓存未删除,正常情况下…
flink重温笔记(十八): flinkSQL 顶层 API ——实时数据Table化(涵盖全面实用的 API )
Flink学习笔记 前言:今天是学习 flink 的第 18 天啦!很多小伙伴私信说,自己只会SQL语法来编写flinkSQL,如何使用代码来操作呢?因为工作中都是要用到代码编写的。还有小伙伴说,想要实现表是动态变化的&#…
实时数仓的另一种构建方法starRocks的物化视图
一、 StarRocks是什么
StarRocks是一个分布式的、高性能的OLAP(联机分析处理)数据库,物化视图在StarRocks中具有重要作用。
二、 StarRocks物化视图能干啥
物化视图(Materialized Views)是数据库中的预先计算结果的存储。它们是由一个或多个基础表的聚合数据组成的,这…
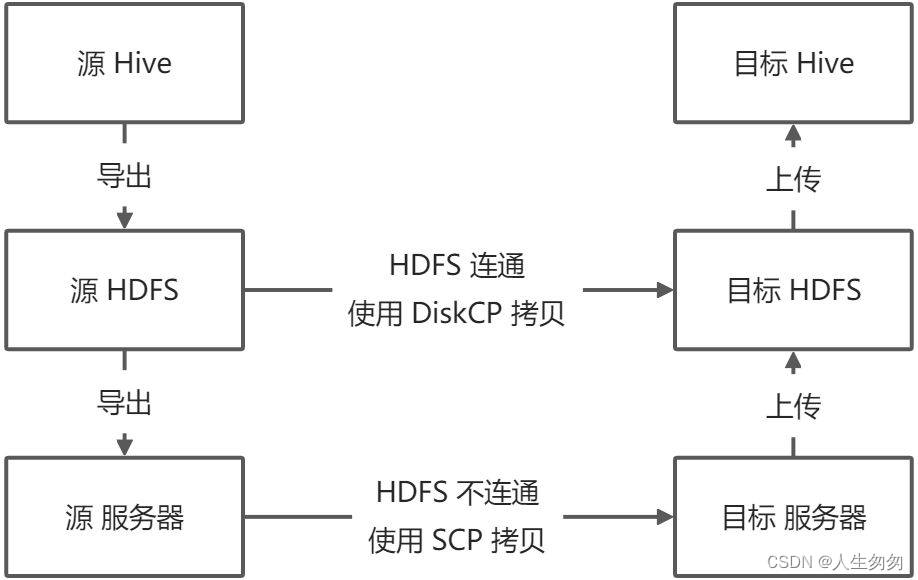
Hive 数据迁移与备份
迁移类型
同时迁移表及其数据(使用import和export)
迁移步骤
将表和数据从 Hive 导出到 HDFS将表和数据从 HDFS 导出到本地服务器将表和数据从本地服务器复制到目标服务器将表和数据从目标服务器上传到目标 HDFS将表和数据从目标 HDFS 上传到目标 Hiv…
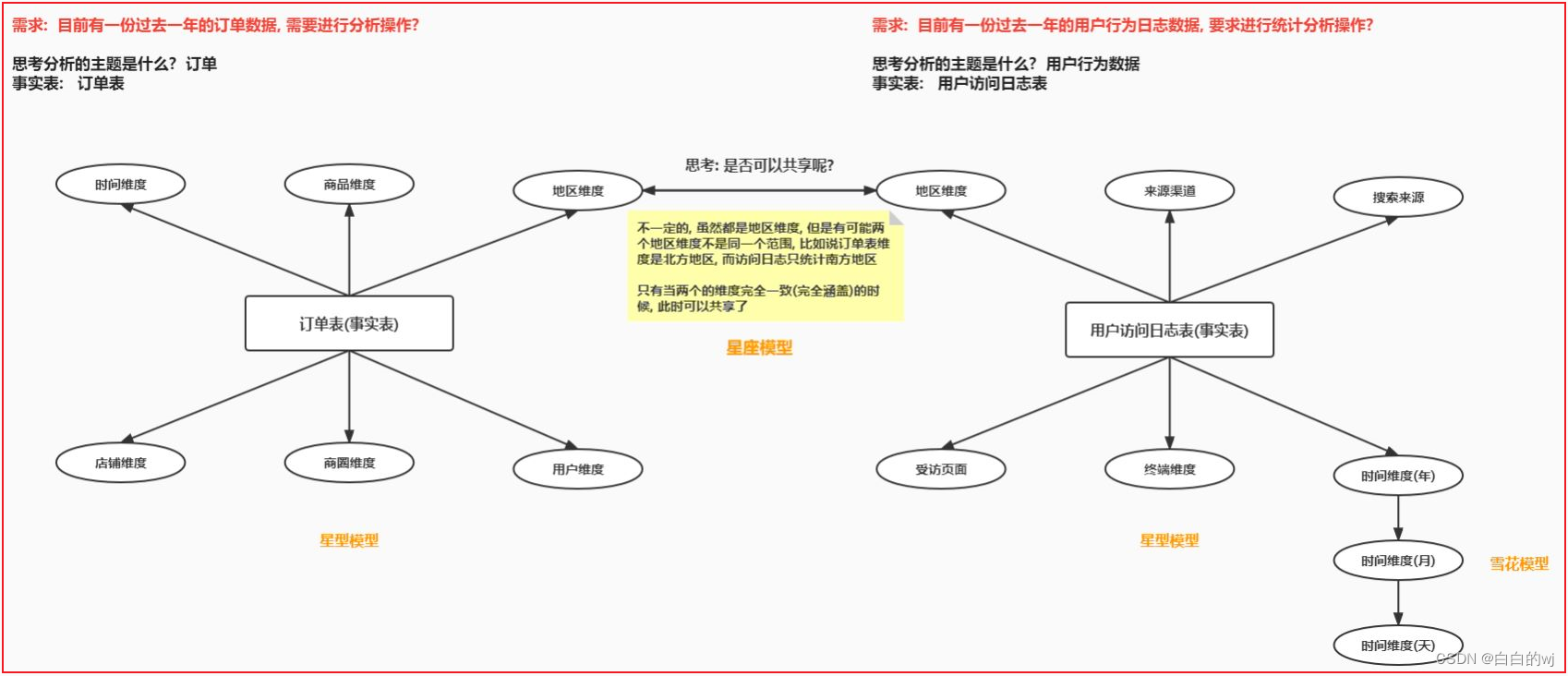
2023.11.22 数据仓库2-维度建模
目录 1.数仓建设方案
2.数仓结构图,项目架构图
2.1项目架构图 2.2数仓结构图 3.建模设计
4.维度建模 什么是事实表: 什么是维度表: 数据发展模式y以及对应的模型
5.数仓建设规范
数据库划分规范
表命名规范
表字段类型规范 1.数仓建设方案 ODS: 源数据层(临时存储层) 贴…
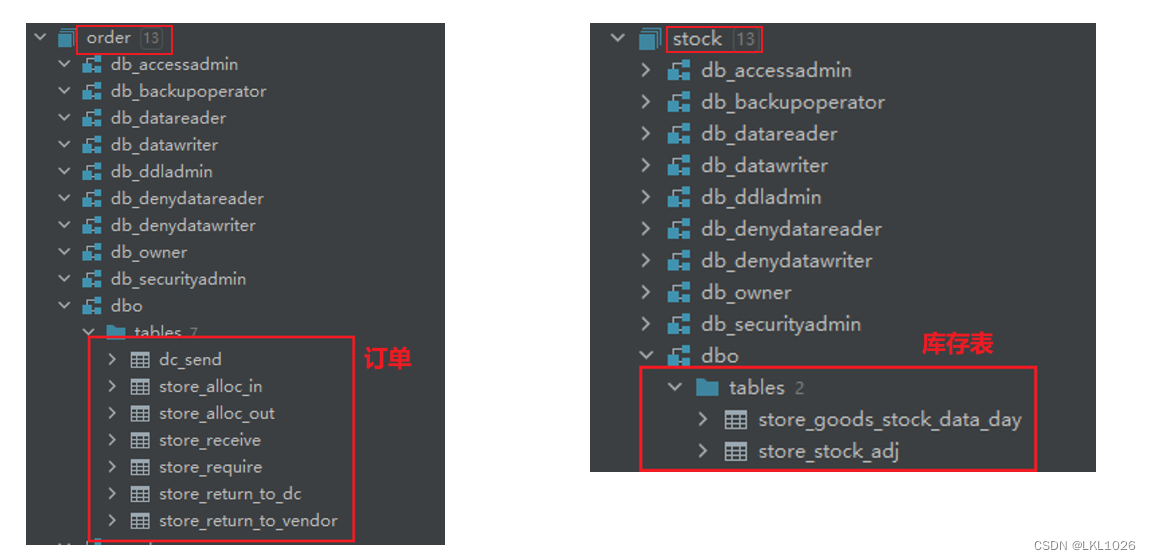
【黑马甄选离线数仓day01_项目介绍与环境准备】
1. 行业背景
1.1 电商发展历史
电商1.0: 初创阶段20世纪90年代,电商行业刚刚兴起,主要以B2C模式为主,如亚马逊、eBay等
电商2.0: 发展阶段21世纪初,电商行业进入了快速发展阶段,出现了淘宝、京东等大型电商平台&a…
Hive csv文件导入Hive
一、如何把csv文件导入Hive
(1) 在Hive中建立与csv相对应的表
create table if not exists tmp.tmp_wenxin_20231123
(redeem_code_id string comment
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ,
STORED AS TEXTFILE;创建了一张名为tmp_wenxin_20231123的hive表&am…

电线电缆、漆包线工厂开源MES/生产管理系统/云MES
万界星空科技专业的漆包线MES系统功能介绍:
从原材料出入库-拉丝机等设备管理-漆包线称重打印系统自动入库(支持多台秤同时称重)-建立销售报价、销售订单-生产订单-支持扫码出库及自动拣货出库-应收应付账款-对接各种其他系统及财务系统。
…
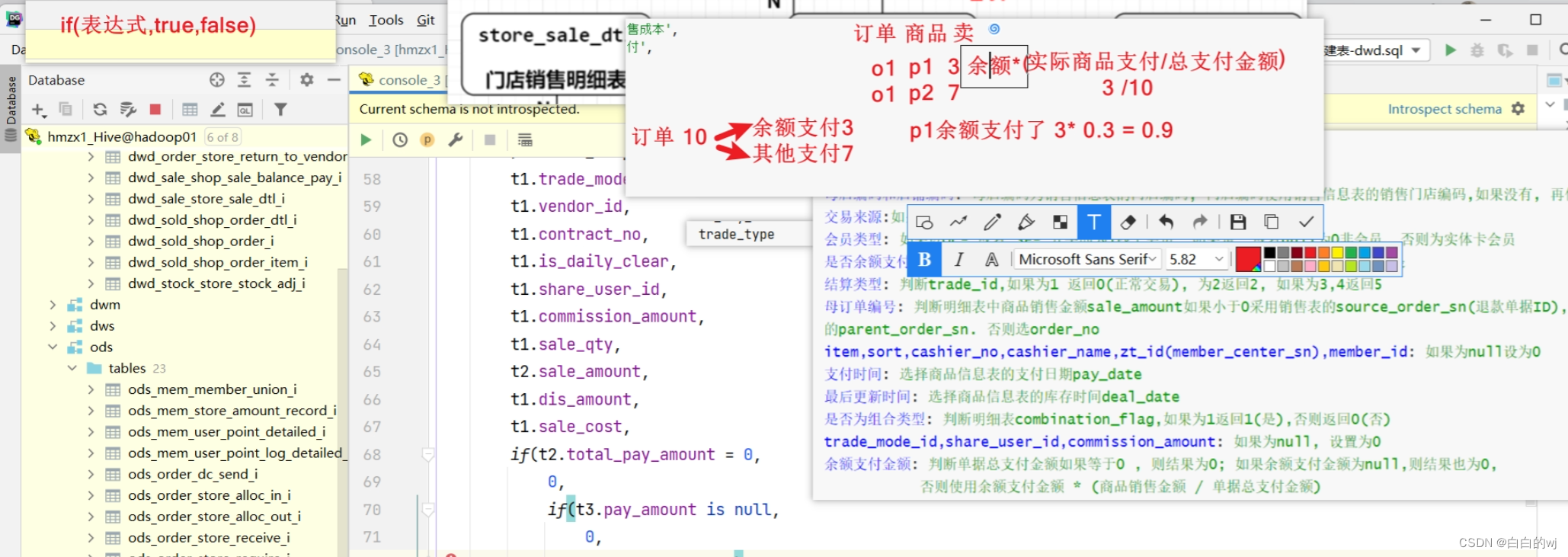
2023.11.25电商项目平台建设2 -四大业务之核销主题建模
1.数仓建模步骤
自下而上 ADS-DWS-DWM-DWD 2.DWD方案(清洗转换,降维拉宽) DWD层的表 dwd_sale_store_sale_dtl_i 门店销售明细宽表 维度dim 销售sale合成成的宽表 dwd_dim_date_f 日期表 store_sale_dtl 门店销售明细表 dwd_sale_store_sale_dtl_i 门店销售明细表 …
day02 hive 实操练习
一、某高校图书管理系统中有如下三个数据模型:
create table book(
book_id string,
sort string,
book_name string,
writer string,
output string,
price decimal(10,2));INSERT INTO TABLE book VALUES (001,TP391,information_processing,author1,machinery_i…
Doris的数据模型
Doris 的数据模型主要分为3类:Aggregate、Uniq、Duplicate 1 Aggregate 模型 表中的列按照是否设置了AggregationType,分为 Key(维度列)和 Value(指标列)。没有设置AggregationType的称为 Key,设置了AggregationType的称为Value。 当我们导入数据时,对于Key列相同的行会…

【黑马甄选离线数仓day06_核销主题域开发】
1. 核销主题_DWD和DWM层
1.0 ODS层
操作数据存储层: Operate Data Store 核心理念: 几乎和源数据保持一致,粒度相同 注意事项: 同步方式(全量同步,全量覆盖,增量仅新增,增量新增和更新) 内部表 分区表(部分) 指定字符分隔符 orc zlib 第二天的时候已经完成了从mysql以及sq…
Hive进阶函数:SPACE() 一行炸裂指定行
数据一行如何转多行
假如有一张表,字段有两个,分别是name 和 number,代表含义为名字 和 名字出现的次数,现在需要把一行数据转为number行
举例: 输入: tom|3jery|4输出:…
Hive_last_value()
在SQL中,LAST_VALUE()函数是一个窗口函数,用于返回窗口内的最后一个值。窗口函数允许你在一组行上执行计算,这组行与当前行有某种关系。可以将它们想象为与当前行相关的“窗口”。
LAST_VALUE()函数通常与OVER()子句一起使用,后者…
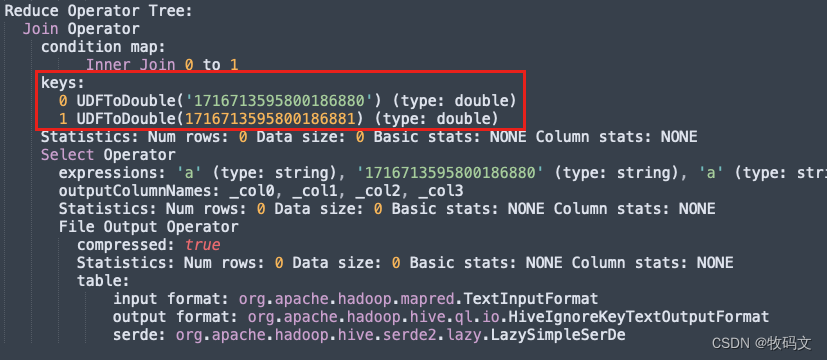
Hive数据倾斜之:数据类型不一致导致的笛卡尔积
Hive数据倾斜之:数据类型不一致导致的笛卡尔积 目录 Hive数据倾斜之:数据类型不一致导致的笛卡尔积一、问题描述二、原因分析三、精度损失四、问题解决 一、问题描述
如果两张表的jion,关联键分布较均匀,没有明显的热点问题&…
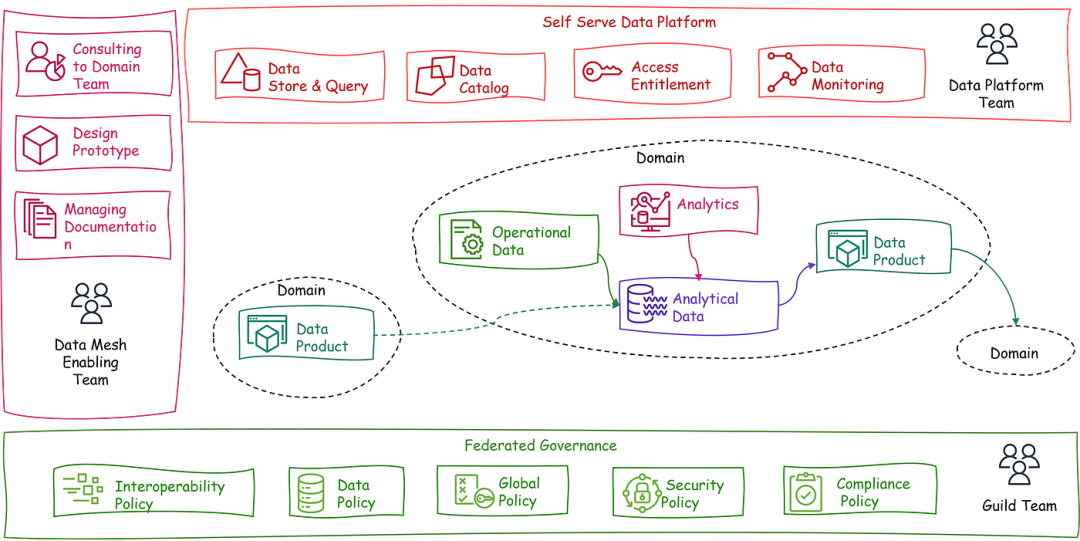
数据湖和中央数据仓库的设计
设计数据湖或中央数据仓库是许多大型组织的主要职能,这些组织每天处理数百万笔交易,并对这些交易进行进一步的报告、预测或机器学习项目分析。 为了将所有来自源系统(我们称之为“上游”)到其他业务应用(所谓“下游”&…
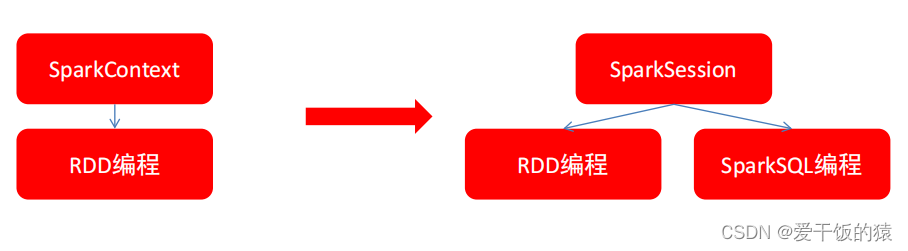
【SparkSQL】基础入门(重点:SparkSQL和Hive的异同、SparkSQL数据抽象)
【大家好,我是爱干饭的猿,本文重点介绍Spark SQL的定义、特点、发展历史、与hive的区别、数据抽象、SparkSession对象。
后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一…
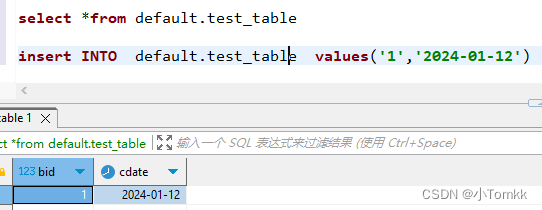
Docker Desktop 安装 ClickHouse 超级简单教程
Docker desktop 安装 clickhouse 超级简单 文章目录 Docker desktop 安装 clickhouse 超级简单 什么是 Docker ?安装下准备安装Docker配置安装 ClickHouse配置数据库密码DBeaver 测试创建表总结 什么是 Docker ?
下载 Docker desktop
Docker Desktop …
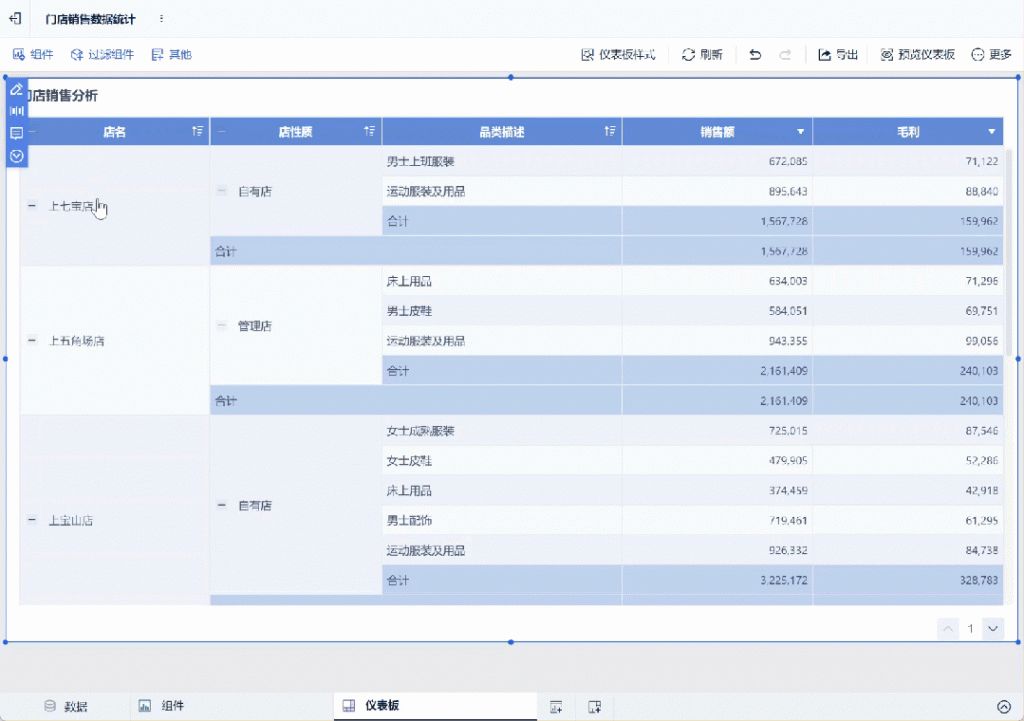
怎么建设数据中台?详解数据中台架构内的三大平台
一、什么是数据中台?
要知道“中台”是什么,就得先了解“前台”和“后台”。
前台,就是我们日常使用的过程中可以直接看到和感知到的东西,比如你打开某东app买了个3080显卡,在这个过程中你看到的页面以及搜索、点击详…
FlinkSQL之Flink SQL Join二三事
Flink SQL支持对动态表进行复杂而灵活的连接操作。 为了处理不同的场景,需要多种查询语义,因此有几种不同类型的 Join。默认情况下,joins 的顺序是没有优化的。表的 join 顺序是在 FROM 从句指定的。可以通过把更新频率最低的表放在第一个…
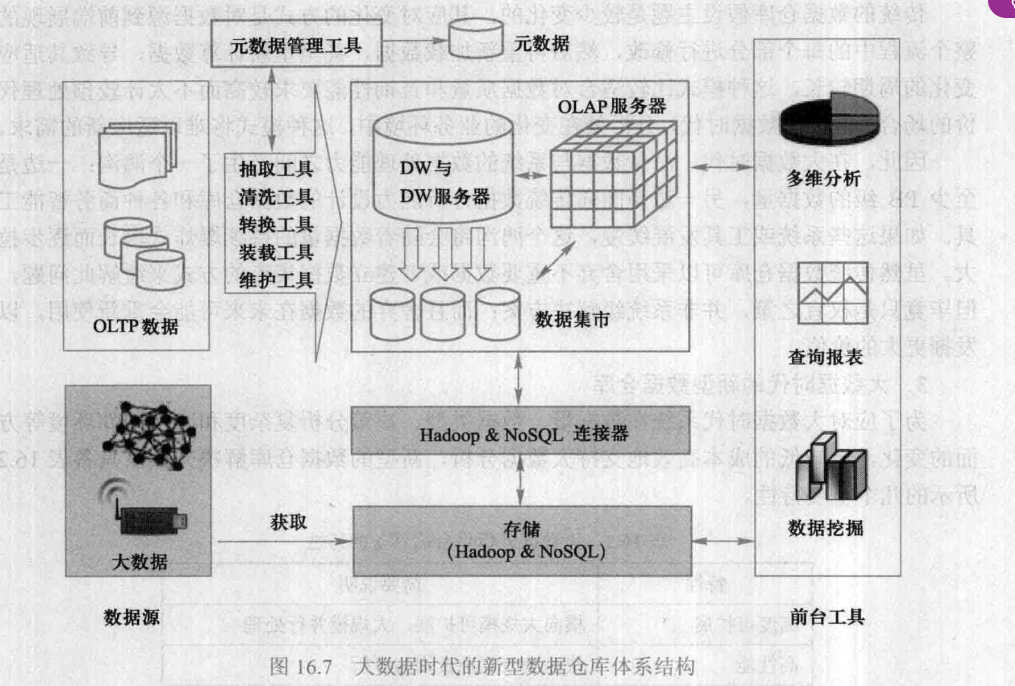
数据库系统概论-第16章 数据仓库与联机分析处理技术
概念性的介绍,一略而过,不重要。 16.1 数据仓库技术 16.2 联机分析处理技术 16.3 数据挖掘技术 16.4 大数据时代的新型数据仓库 16.5 小结
2023.12.3 分布式SQL查询引擎-Presto
目录 1.Prosto简介
Apache Hadoop-MapReduce
Apache Hive
2.Presto的优缺点
3.个人自用启动服务
个人自用启动服务
4.presto和hive的区别
5.presto优化 1.Prosto简介 Apache Hadoop-MapReduce 优点:统一、通用、简单的编程模型,分而治之思想处理…
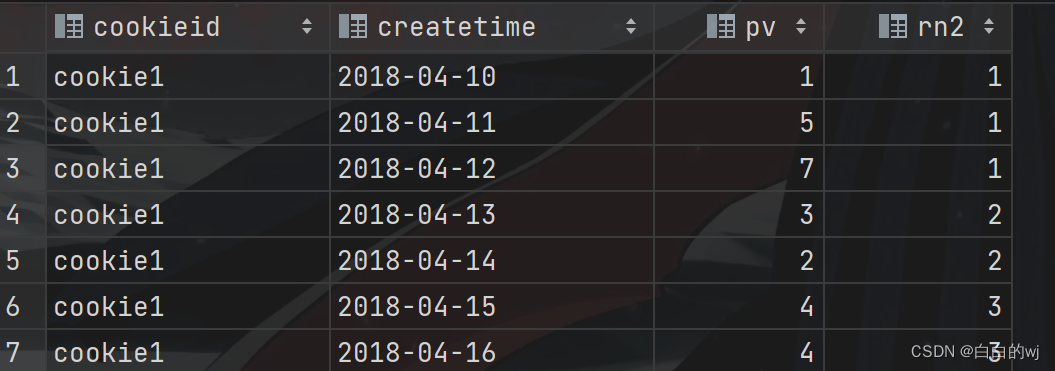
2023.11.16 hivesql高阶函数之开窗函数
目录 1.开窗函数的定义
2.数据准备
3.开窗函数之排序 需求:用三种排序方法查询学生的语文成绩排名,并降序显示 4.开窗函数分组
需求:按照科目来分类,使用三种排序方式来排序学生的成绩 5.聚合函数与分组配合使用
6.聚合函数同时和分组以及排序关键字配合使用
--需求1&…
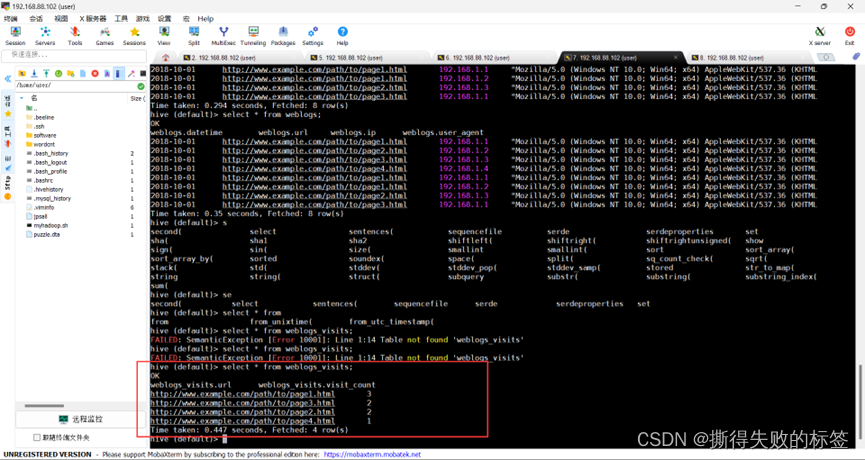
使用 Kettle 完成数据 ETL
文章目录 使用 Kettle 完成数据 ETL数据清洗数据处理 使用 Kettle 完成数据 ETL
现在我们有一份网站的日志数据集,准备使用Kettle进行数据ETL。先将数据集加载到Hadoop集群中,然后对数据进行清洗,最后加载到Hive中。
在本地新建一个数据集文…

Kettle 安装配置
文章目录 Kettle 安装配置Kettle 安装Kettle 配置连接 Hive Kettle 安装配置
Kettle 安装
在安装Kettle之前,需要确定已经安装Java运行环境。Kettle需要Java的支持才能运行,JDK的版本最好是8.x的太新的也会出现bug。Kettle的7.1版本的太旧了࿰…

维度建模与数据仓库设计:理论与实践案例
文章目录 定义案例:零售销售数据仓库实践创建维度表创建事实表插入维度表数据插入事实表数据增改查 定义
维度建模是一种用于数据仓库设计的技术,它的目标是使数据库结构更加直观,易于理解和使用,特别是对于那些进行数据查询和报…
8-Hive原理与技术
单选题 题目1:按粒度大小的顺序,Hive数据被分为:数据库、数据表、桶和什么 选项: A 元祖 B 栏 C 分区 D 行 答案:C ------------------------------ 题目2:以下选项中,哪种类型间的转换是被Hive查询语言…
Hive效率优化记录
Hive是工作中常用的数据仓库工具,提供存储在HDFS文件系统,将结构化数据映射为一张张表以及提供查询和分析功能。 Hive可以存储大规模数据,但是在运行效率上不如传统数据库,这时需要懂得常见场景下提升存储或查询效率的方法&#x…

2023.11.19 hadoop之MapReduce
目录
1.简介
2.分布式计算框架-Map Reduce
3.mapreduce的步骤
4.MapReduce底层原理
map阶段
shuffle阶段
reduce阶段 1.简介
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是…

Hive 定义变量 变量赋值 引用变量
Hive 定义变量 变量赋值 引用变量
变量
hive 中变量和属性命名空间
命名空间权限描述hivevar读写用户自定义变量hiveconf读写hive相关配置属性system读写java定义额配置属性env只读shell环境定义的环境变量
语法 Java对这个除env命名空间内容具有可读可写权利; …

【黑马甄选离线数仓day07_常见优化手段及核销主题域开发】
1.常见优化手段
1.1 分桶表基本介绍 分桶表: 分文件的, 在创建表的时候, 指定分桶字段, 并设置分多少个桶, 在添加数据的时候, hive会根据设置分桶字段, 将数据划分到N个桶(文件)中, 默认情况采用HASH分桶方案 , 分多少个桶, 取决于建表的时候, 设置分桶数量, 分了多少个桶最终…
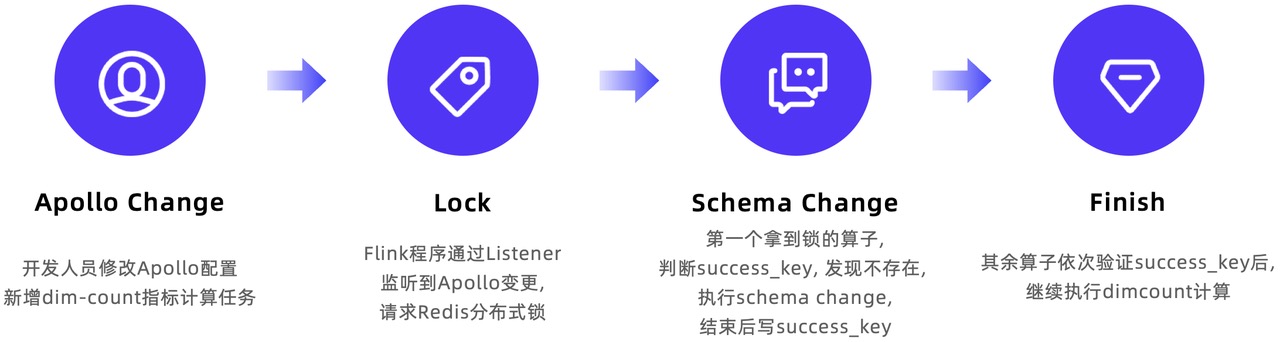
Apache Doris 在某工商信息商业查询平台的湖仓一体建设实践
本文导读: 信息服务行业可以提供多样化、便捷、高效、安全的信息化服务,为个人及商业决策提供了重要支撑与参考。本文以某工商信息商业查询平台为例,介绍其从传统 Lambda 架构到基于 Doris Multi-Catalog 的湖仓一体架构演进历程。同时通过一…
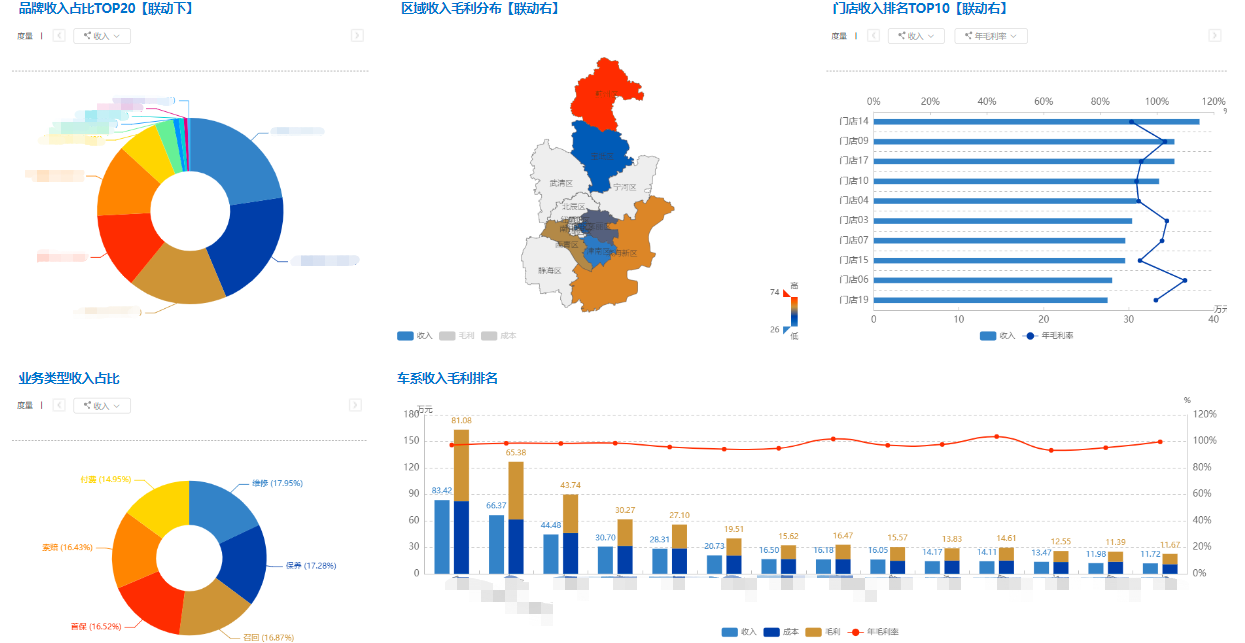
数据资产入表,给企业带来的机遇和挑战
作为推动数字经济发展的核心要素,近年来,数据资源对于企业特别是相关数据企业的价值和作用正日益凸显。 数据资产入表之后,能够为企业经营带来实质性的收益。“随着数据资产的纳入,企业的资产也出现了新标的。在资产负债表中&…
Doris Hive外表
Hive External Table of Doris 提供了 Doris 直接访问 Hive 外部表的能力,外部表省去了繁琐的数据导入工作,并借助 Doris 本身的 OLAP 的能力来解决 Hive 表的数据分析问题: 支持 Hive 数据源接入Doris支持 Doris 与 Hive 数据源中的表联合查询,进行更加复杂的分析操作1 基…
![[Kettle] 生成记录](https://img-blog.csdnimg.cn/1e271ac5647c4a33ad5aac86387692c8.png)
[Kettle] 生成记录
在数据统计中,往往要生成固定行数和列数的记录,用于存放统计总数
需求:为方便记录1~12月份商品的销售总额,需要通过生成记录,生成一个月销售总额的数据表,包括商品名称和销售总额两个字段,记录…
阿里云实时数据仓库HologresFlink
1. 实时数仓Hologres特点
专注实时场景:数据实时写入、实时更新,写入即可见,与Flink原生集成,支持高吞吐、低延时、有模型的实时数仓开发,满足业务洞察实时性需求。亚秒级交互式分析:支持海量数据亚秒级交…
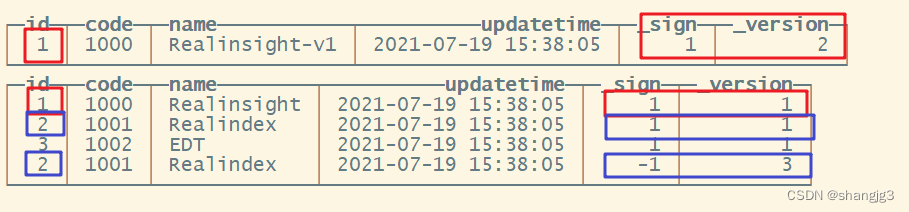
ClickHouse的 MaterializeMySQL引擎
1 概述 MySQL 的用户群体很大,为了能够增强数据的实时性,很多解决方案会利用 binlog 将数据写入到 ClickHouse。为了能够监听 binlog 事件,我们需要用到类似 canal 这样的第三方中间件,这无疑增加了系统的复杂度。 ClickHouse 20.…
Hive增强的聚合、多维数据集、分组和汇总
Hive多维分析 1、多维分析概述2、GROUPING SETS多维分组3、GROUPING__ID函数4、ROLLUP与CUBE语法糖5、多维分析常见问题与解决春雨惊春清谷天,夏满芒夏暑相连;秋处露秋寒霜降,冬雪雪冬小大寒。今天是2023年的最后一个节气:大雪。大雪节气之后,全国气温显著下降,北方冷空气…

PrestoSQL语法及优化
PrestoSQL语法及优化 1、PrestoSQL概述2、PrestoSQL语法2.1、PrestoSQL数据类型2.2、关键字和标识符2.3、PrestoSQL注释2.4、PrestoSQL语法2.5、PrestoSQL例程2.6、PrestoSQL使用常见问题3、PrestoSQL优化3.1、存储优化3.2、查询优化3.3、多数据源联合查询1、PrestoSQL概述 202…
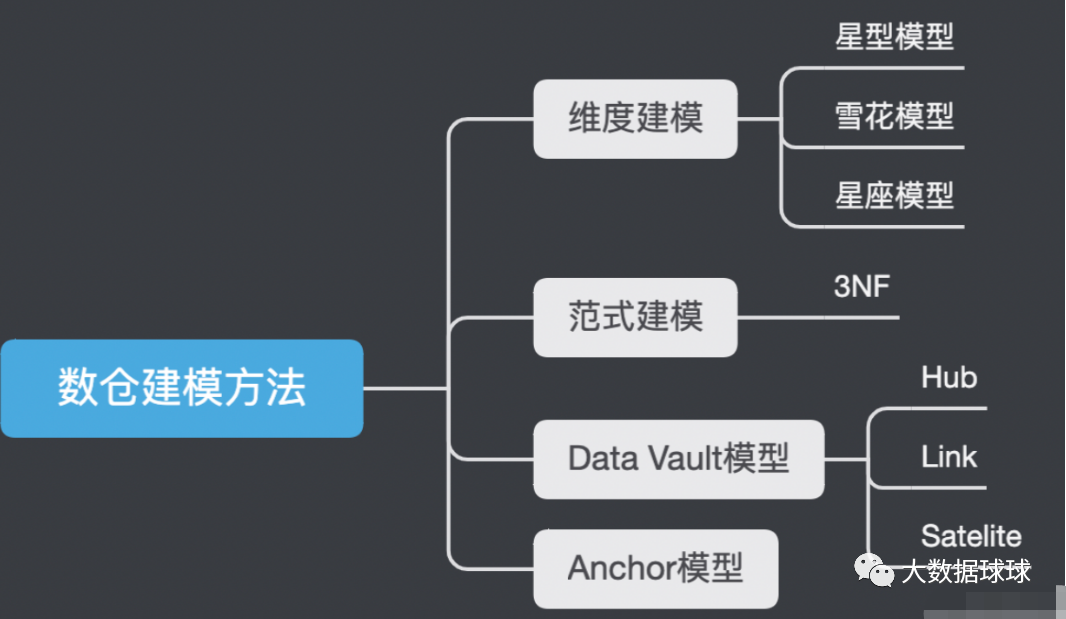

揭示 ETL 系统架构中的 OLAP、OLTP 和 HTAP
探索 ETL 系统设计需要了解 OLAP、OLTP 和不断发展的 HTAP。让我们试图剖析这些范式的复杂性。 1. OLAP(联机分析处理): OLAP 是商业智能的中流砥柱,通过 OLAP 立方体进行多维数据分析。这些立方体封装了预先聚合、预先计算的数据…
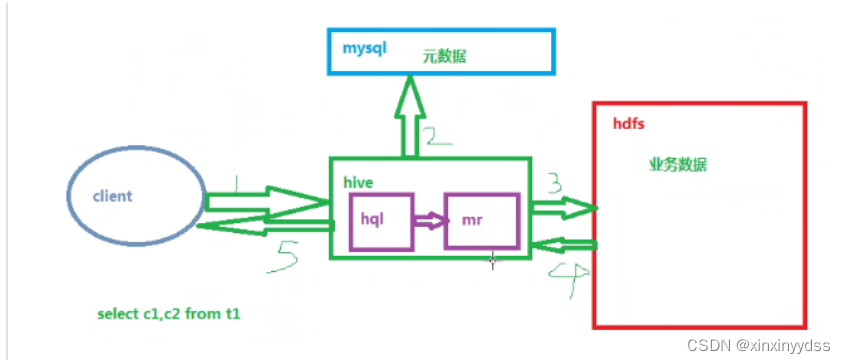
hive数据仓库工具
1、hive是一套操作数据仓库的应用工具,通过这个工具可实现mapreduce的功能 2、hive的语言是hql[hive query language] 3、官网hive.apache.org 下载hive软件包地址 Welcome! - The Apache Software Foundationhttps://archive.apache.org/ 4、hive在管理数据时分为元…
[hive] posexplode函数
在Hive SQL中,posexplode是一个用于将数组(array)拆分为多行的函数。
它返回数组中的每个元素以及其在数组中的位置(索引)作为两列输出。
这是posexplode函数的语法:
posexplode(array)其中,…
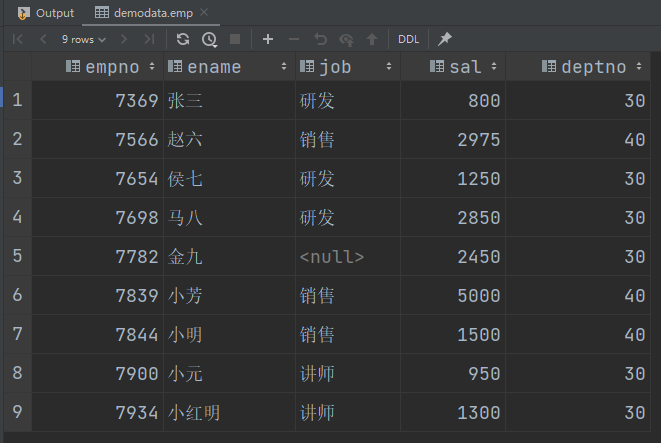
hive聚合函数之JOIN原理及案例
1.数据准备
原始数据 创建dept.txt文件,并赋值如下内容,上传HDFS。
部门编号 部门名称 部门位置id
10 行政部 1700
20 财务部 1800
30 教学部 1900
40 销售部 1700创建emp.txt文件,并赋值如下内容,上传HDFS。
员工编号 姓名 岗…
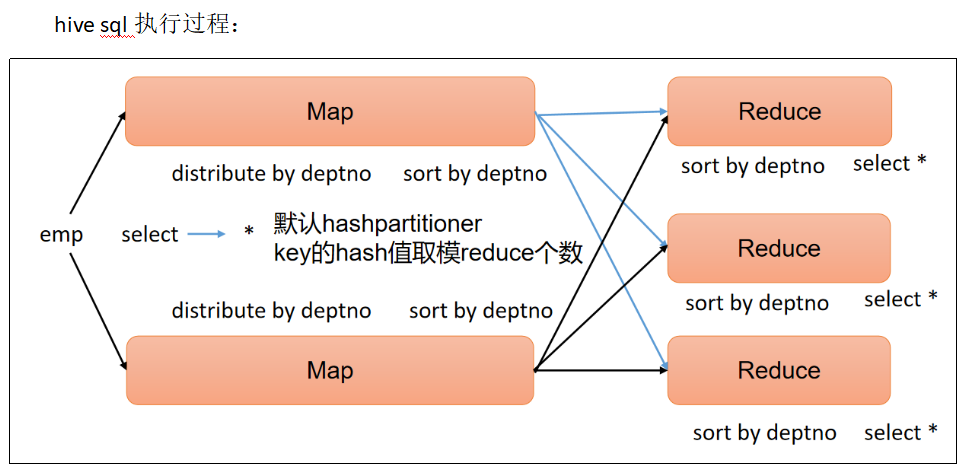
hive聚合函数之排序
1 全局排序(Order By)
Order By:全局排序,只有一个Reduce。 (1).使用Order By子句排序 asc(ascend):升序(默认) desc(descend)&#…

大数据技术12:Hive简介及核心概念
前言:2007年,编写Pig虽然比MapReduce编程简单,但是还是要学习。于是Facebook发布了Hive,支持使用SQL语法进行大数据计算,写个Select语句进行数据查询,Hive会将SQL语句转化成MapReduce计算程序。这样&#x…

【Hive】——DDL(PARTITION)
1 增加分区
1.1 添加一个分区 ALTER TABLE t_user_province ADD PARTITION (provinceBJ) location/user/hive/warehouse/test.db/t_user_province/provinceBJ;必须自己把数据加载到增加的分区中 hive不会帮你添加
1.2 一次添加多个分区 ALTER TABLE table_name ADD PARTITION…
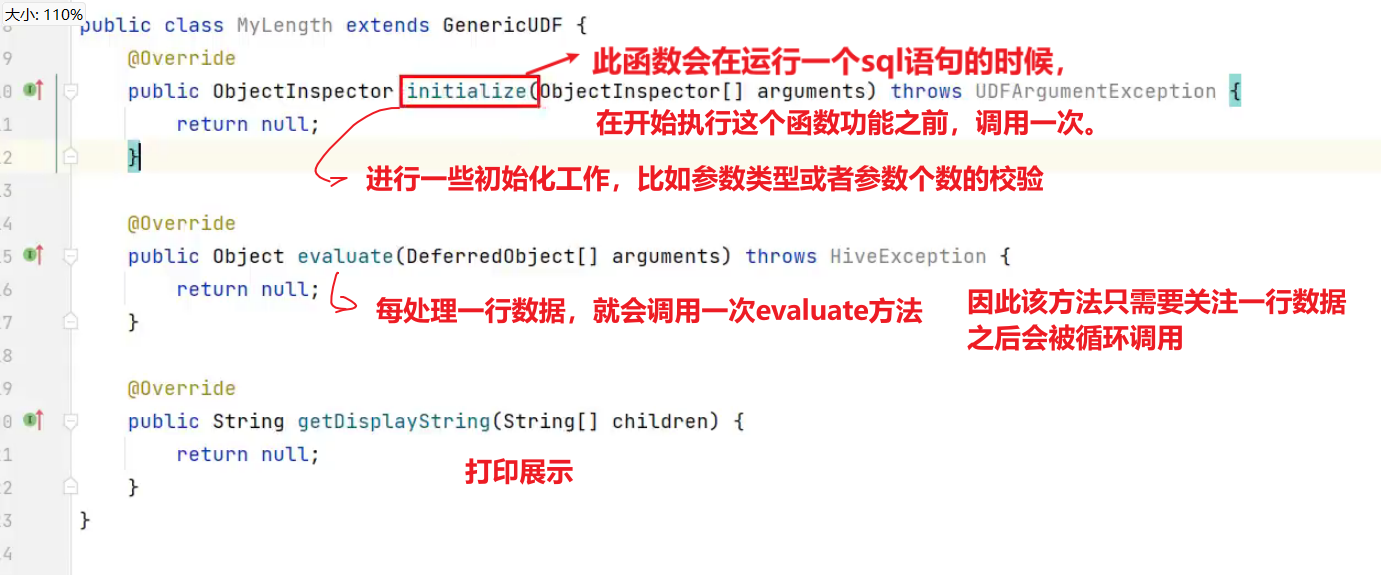
【Hive_03】单行函数、聚合函数、窗口函数、自定义函数、炸裂函数
1、函数简介2、单行函数2.1 算术运算函数2.2 数值函数2.3 字符串函数(1)substring 截取字符串(2)replace 替换(3)regexp_replace 正则替换(4)regexp 正则匹配(5ÿ…

数据仓库与数据挖掘c5-c7基础知识
chapter5 分类
内容 分类的基本概念 分类 数据对象 元组(x,y) X 属性集合 Y 类标签 任务 基于有标签的数据,学习一个分类模型,通过这个分类模型,可以把一组属性x映射到一个特定的类别y上 类别y 提前设定好的--如:学生…

hive企业级调优策略之数据倾斜
测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511 本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
数据倾斜概述
数据倾斜问题,通常是指参与计算的数据分布不均࿰…

数据仓库-数据治理小厂实践
一、简介 数据治理贯穿数仓中数据的整个生命周期,从数据的产生、加载、清洗、计算,再到数据展示、应用,每个阶段都需要对数据进行治理,像有些比较大的企业都是有自己的数据治理平台或者会开发一些便捷的平台,对于没有平…
【hive】Hive中的大宽表及其底层详细技术点
简介: 在大数据环境中,处理大规模数据集是常见的需求。为了满足这种需求,Hive引入了大宽表(Large Wide Table)的概念,它是一种在Hive中管理和处理大量列的数据表格。本文将详细介绍Hive中的大宽表概念以及其底层的详细…
hive中array相关函数总结
目录 hive官方函数解释示例实战 hive官方函数解释
hive官网函数大全地址: hive官网函数大全地址
Return TypeNameDescriptionarrayarray(value1, value2, …)Creates an array with the given elements.booleanarray_contains(Array, value)Returns TRUE if the a…

Hive文件存储与压缩
压缩和存储
1、 Hadoop压缩配置
1) MR支持的压缩编码
压缩格式工具算法文件扩展名是否可切分DEFAULT无DEFAULT.deflate否GzipgzipDEFAULT.gz否bzip2bzip2bzip2.bz2是LZOlzopLZO.lzo否LZ4无LZ4.lz4否Snappy无Snappy.snappy否
为了支持多种压缩/解压缩算法,Hadoop…
doris基本操作,01-创建表,插入数据
创建表
-- 创建表 --
create table t001 {siteid int default 0,citycode smallint,username varchar(32) default ,-- 预聚合 --pv bigint sum default 0
}
-- 预处理用的,插入相同siteid, citycode, username的记录不会新增行,而将sum的pv增加 --
agg…
Flink实时数仓同步:快照表实战详解
一、背景
在大数据领域,初始阶段业务数据通常被存储于关系型数据库,如MySQL。然而,为满足日常分析和报表等需求,大数据平台采用多种同步方式,以适应这些业务数据的不同存储需求。这些同步存储方式包括离线仓库和实时仓…
大数据领域的数据仓库
在大数据领域,数据仓库(Data Warehouse)是一个用于存储、管理和分析大量数据的集中式系统。它从多个异构数据源收集数据,对数据进行清洗、转换和整合,然后将其存储在一个集中的位置,以支持复杂的查询、报告…

银行数据仓库体系实践(17)--数据应用之营销分析
营销是每个银行业务部门重要的工作任务,银行产品市场竞争激烈,没有好的营销体系是不可能有立足之地,特别是随着互联网金融发展,金融脱媒”已越来越普遍,数字化营销方兴未艾,银行的营销体系近些年也不断发展,…
HiveSQL——借助聚合函数与case when行转列
一、条件函数
if 条件函数 if函数是最常用到的条件函数,其写法是if(xn,a,b), xn代表判断条件,如果xn时,那么结果返回a ,否则返回b。 selectif(age < 25 or age is null, 25岁以下, 25岁以上) as age_cnt,count(1) as number
from table…

使用REQUESTDISPATCHER对象调用错误页面
使用REQUESTDISPATCHER对象调用错误页面 问题陈述
InfoSuper公司已经创建了一个动态网站。发生错误时,浏览器中显示的堆栈跟踪很难理解。公司的系统分析师David Wong让公司的软件程序员Don Allen创建自定义错误页面。servlet引发异常时,应使用RequestDisapatcher对象向自定义…
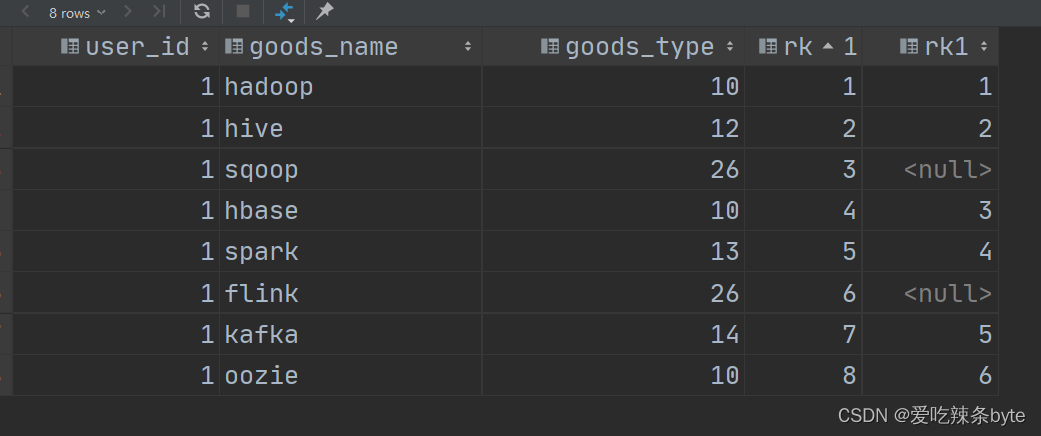
HiveSQL——条件判断语句嵌套windows子句的应用
注:参考文章:
SQL条件判断语句嵌套window子句的应用【易错点】--HiveSql面试题25_sql剁成嵌套判断-CSDN博客文章浏览阅读920次,点赞4次,收藏4次。0 需求分析需求:表如下user_idgood_namegoods_typerk1hadoop1011hive1…
大数据思考:面对海量数据时,选择哪种模式才是更适合自己的?
如果您从事科技行业或者您不在这个行业,也许您已经听说过很多关于 AI 的信息。 我所说的不仅仅是多年来我们都喜欢的科幻小说中“天网正在接管地球”式的人工智能,而是人工智能和机器学习已经逐渐成为我们日常生活中的实际应用 .
大数据是人工智能与机器…
HiveSQL——连续增长问题
注:参考文章:
SQL连续增长问题--HQL面试题35_sql判断一个列是否连续增长-CSDN博客文章浏览阅读2.6k次,点赞6次,收藏30次。目录0 需求分析1 数据准备3 小结0 需求分析假设我们有一张订单表shop_order shop_id,order_id,order_time…
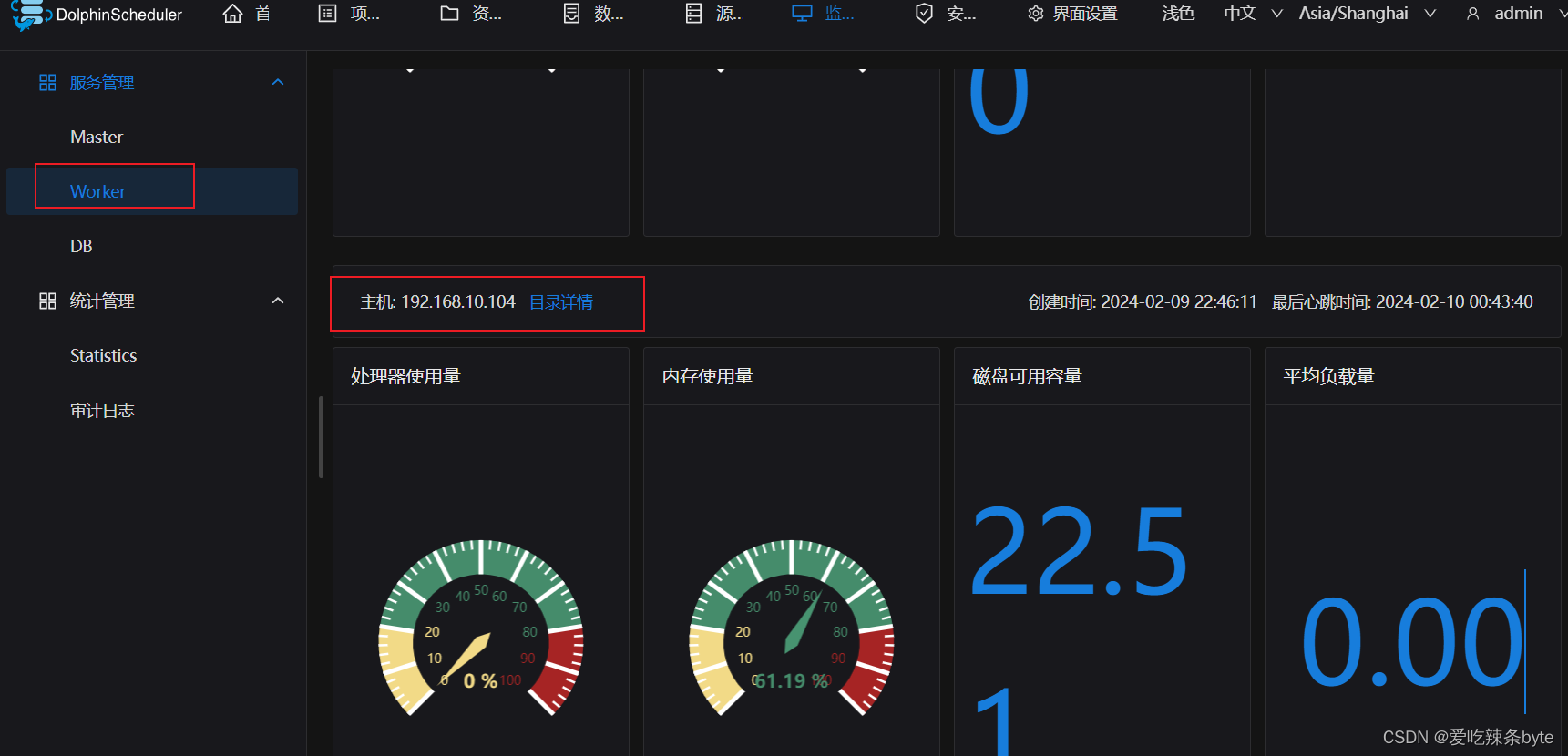
DolphinScheduler-3.2.0 集群搭建
本篇文章主要记录DolphinScheduler-3.2.0 集群部署流程。
注:参考文档:
DolphinScheduler-3.2.0生产集群高可用搭建_dophinscheduler3.2.0 使用说明-CSDN博客文章浏览阅读1.1k次,点赞25次,收藏23次。DolphinScheduler-3.2.0生产…
HiveSQL——不使用union all的情况下进行列转行
参考文章:
HiveSql一天一个小技巧:如何不使用union all 进行列转行_不 union all-CSDN博客文章浏览阅读881次,点赞5次,收藏10次。本文给出一种不使用传统UNION ALL方法进行 行转列的方法,其中方法一采用了concat_wsposexplode()方…

问卷调查反应偏差消除技巧:提高数据准确性的实用方法
回应偏差会对您的调查结果产生不利影响。以下是您可以采取的措施来对抗偏差。调查之所以成为一个有力的工具,是因为它能够获取关于目标受众的真实信息和数据,而不是依靠试错方法。然而,为了使这些数据有用,它必须是无误差的&#…
Cookie的详解使用(创建,获取,销毁)
文章目录 Cookie的详解使用(创建,获取,销毁)1、Cookie是什么2、cookie的常用方法3、cookie的构造和获取代码演示SetCookieServlet.javaGetCookieServlet.javaweb.xml运行结果如下 4、Cookie的销毁DestoryCookieServletweb.xml运行…
Hive的CTE 公共表达式
目录
1.语法 2. 使用场景
select语句
chaining CTEs 链式
union语句
insert into 语句
create table as 语句
前言 Common Table Expressions(CTE):公共表达式是一个临时的结果集,该结果集是从with子句中指定的查询派生而来…
Hive的Join连接、谓词下推
前言 Hive-3.1.2版本支持6种join语法。分别是:inner join(内连接)、left join(左连接)、right join(右连接)、full outer join(全外连接)、left semi join(左…
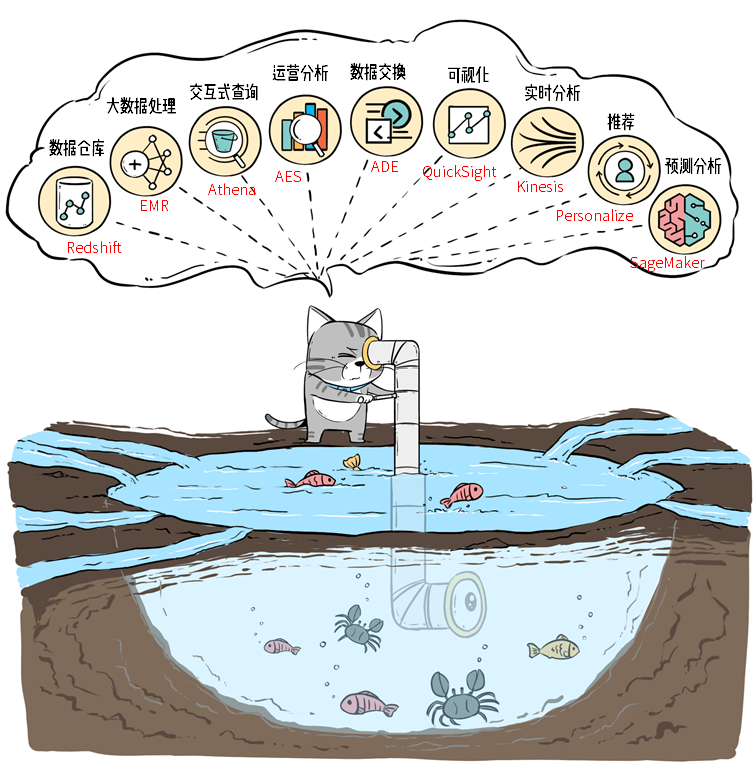
大数据技术16:数据湖和湖仓一体
前言:近几年大数据概念很多,数据库和数据仓库还没搞清楚,就又出了数据湖,现在又开始流行湖仓一体。互联网公司拼命造高大上概念来忽略小白买单的能力还是可以的。 1、数据库 数据库是结构化信息或数据的有序集合,一般以…
浅识数据库与数据仓库的区别
通常我们会认为数据库与数据仓库都是用来存储数据的一个库,好像并没有什么明显区别,下面就从几个方面简单认识一下两者的区别。
从名称角度区分
数据库(Database):用来存储一些基础的、核心的数据。
数据仓库(Data Warehouse):…

re:Invent 2023技术上新|Amazon DynamoDB与OpenSearch Service的Zero-ETL集成
Amazon DynamoDB 与 Amazon OpenSearch Service 的 Zero-ETL 集成已正式上线,该服务允许您通过自动复制和转换您的 DynamoDB 数据来搜索数据,而无需自定义代码或基础设施。这种 Zero-ETL 集成减少了运营负担和成本,使您能够专注于应用程序。这…
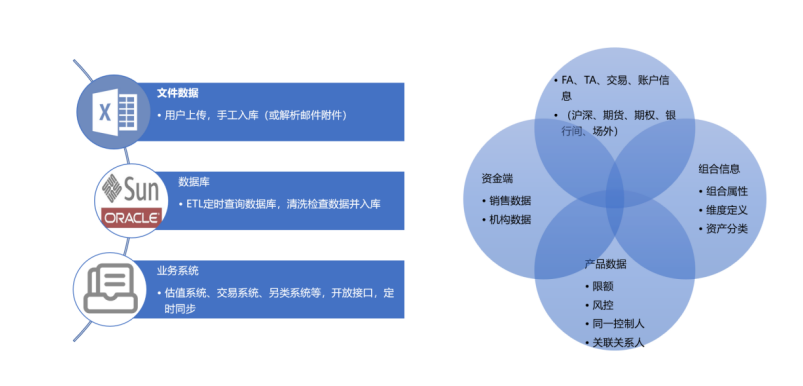
天软高频时序数据仓库
1天软高频时序数仓的独特优势 1.1大比例压缩存储 TS数据仓库支持压缩存储,能极大的节省用户的数据存储成本; 压缩传输能获取更快的数据传输性能; 压缩存储支撑无障碍自由访问,无需解压缩; l对于Level-1高频行情数据&am…
Chatgpt为什么像打字机逐字输出?磨洋工,防止数据库被盗
在他后台的数据库里肯定是完整的结果,每次只给你一个单词一个单词的输送,一方面是为了耍酷,好像真的是一个人在那给你说话,另一方面也是防止第三方的抄袭者最快速度盗取采集偷走数据库。防止他们的服务器崩溃,可以多收几个月会员费。
都说搞…

从零开始了解大数据(七):总结
系列文章目录 从零开始了解大数据(一):数据分析入门篇-CSDN博客 从零开始了解大数据(二):Hadoop篇-CSDN博客 从零开始了解大数据(三):HDFS分布式文件系统篇-CSDN博客 从零开始了解大数据(四):MapReduce篇-CSDN博客 从零开始了解大…

Hive10_窗口函数
窗口函数(开窗函数)
1 相关函数说明
普通的聚合函数聚合的行集是组,开窗函数聚合的行集是窗口。因此,普通的聚合函数每组(Group by)只返回一个值,而开窗函数则可为窗口中的每行都返回一个值。简单理解,就是对查询的结果多出一列…
Zoho Mail企业邮箱:跨境协作的利器,荣登Top榜单
在全球化的商业环境中,高效的协作工具对于企业及个人来说都至关重要。邮件因其自身规格正式、全球通用等特点,在跨境通信场景中仍然是最高频使用的工具之一。 Zoho Mail企业邮箱因邮件抵达率高,数据加密严,纯净无广告,…
13.仿简道云公式函数实战-逻辑函数-NOT
1. NOT函数
NOT 函数可用于对其参数的逻辑求反,当逻辑为 true 时,返回结果 false;当逻辑为 false 时,返回结果 true。
2. 函数用法
NOT(logical)
3. 函数示例
1)NOT(A),表示如果 A 为 true 时,则返回 false;A 为 false 时,则返回 true。例如: NOT(50<60),返…
10Maxwell 增量表首日全量同步
通常情况下,增量表需要在首日进行一次全量同步,后续每日再进行增量同步,首日全量同步可以使用Maxwell的bootstrap功能,方便起见,下面编写一个增量表首日全量同步脚本。
在~/bin目录创vim mysql_to_kafka_inc_init.sh …
HiveSQL题——炸裂函数(explode/posexplode)
目录
一、炸裂函数的知识点
1.1 炸裂函数 explode
posexplode
1.2 lateral view 侧写视图
二、实际案例
2.1 每个学生及其成绩
0 问题描述
1 数据准备
2 数据分析
3 小结
2.2 日期交叉问题
0 问题描述
1 数据准备
2 数据分析
3 小结
2.3 用户消费金额
0 问题…
Hive collect_set()、collect_list()列转行,并对转换后的行值排序
Hive collect_set()、collect_list()列转行,和concat_ws()使用,并对转换后的行值排序 1、需求描述
对列值分组,并按一定顺序排序,最后多行合并一行,合并值左到右逆序排列。
2、考点:
sort_array(e: colu…
创建第一个SpringMVC项目,入手必看!
文章目录 创建第一个SpringMVC项目,入手必看!1、新建一个maven空项目,在pom.xml中设置打包为war之前,右击项目添加web框架2、如果点击右键没有添加框架或者右击进去后没有web框架,点击左上角file然后进入项目结构在模块…
Hive 日期处理函数汇总
Hive 日期处理函数汇总
最近项目处理日期操作比较繁杂,使用Hive的日期函数也较频繁
1. 加减日期 date_add(‘日期字符串’,int值) :把一个字符串日期格式加n天,n为int值 select date_add(‘2023-12-31’,7); 结果: 2024-01-07 date_sub(‘日期字符串’,int值) :把一个字符串…
Hive之set参数大全-5
I
限制外部表数据插入
set hive.insert.into.external.tablestrue;在Apache Hive中,通过INSERT INTO语句向外部表(External Table)插入数据时,有一些注意事项和限制。外部表是Hive中的一种特殊表,它与Hive管理的存储…
Apache Doris 聚合函数源码阅读与解析|源码解读系列
笔者最近由于工作需要开始调研 Apache Doris,通过阅读聚合函数代码切入 Apache Doris 内核,同时也秉承着开源的精神,开发了 array_agg 函数并贡献给社区。笔者通过这篇文章记录下对源码的一些理解,同时也方便后面的新人更快速地上…
【Databend】行列转化:数据透视和逆透视
文章目录 数据准备数据透视数据逆透视总结 数据准备
学生学科得分等级测试数据如下:
drop table if exists fact_suject_data;
create table if not exists fact_suject_data
(student_id int null comment 编号,subject_level varchar null comment …

如何创作出优秀的电子邮件营销(EDM)?
EDM出现的时间很早,是非常传统的一种推广方式。即便是其他推广方式的蓬勃兴起,EDM依旧深受很多行业的喜爱。主要源于它极高的性价比,据可靠数据,EDM的投资回报比达1:48。 那一封优秀的EDM应该是怎么样的呢?…
中国硝酸异辛酯行业调研与投资预测报告(2024版)
内容介绍:
硝酸异辛酯是一种常用的柴油添加剂,用于改进柴油的十六烷值,其分子式为(C8H17O)NO2,外观为无色(或淡黄色)透明液体。
十六烷值是衡量柴油着火性能和抗爆性能的指标。一般…
Hive数据导出的四种方法
hive数据仓库有多种数据导出方法,我在本篇文章中介绍下面的四种方法供大家参考:Insert语句导出、Hadoop命令导出、Hive shell命令导出、Export语句导出。
一、Insert语句导出
语法格式
Hive支持将select查询的结果导出成文件存放在文件系统中。语法格…
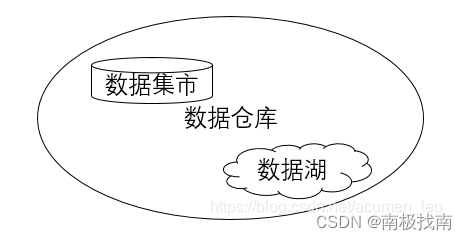
银行数据仓库体系实践(1)--银行数据仓库简介
银行数据仓库简介 数据仓库之父比尔(Bill Inmon)在1991年出版的“Building the Data Warehouse”(《建立数据仓库》)一书中所提出的定义被广泛接受:数据仓库(Data Warehouse)是一个面向主题的&a…
一文了解数据库,数据仓库,数据湖,数据集市,数据湖仓
目录
一、定义
1. 数据库(Database)
2. 数据仓库(Data Warehouse)
3. 数据湖(Data Lake)
4. 数据集市(Data Mart)
5. 数据湖仓(Data Lakehouse)
二、相…
Hive之set参数大全-9
指定LLAP(Low Latency Analytical Processing)引擎中的IO(输入/输出)线程池的大小
hive.llap.io.threadpool.size 是Apache Hive中的一个配置属性,用于指定LLAP(Low Latency Analytical Processing&#x…

元数据管理在数据仓库中的实践应用
一、什么是数据仓库的元数据管理?
1、什么是元数据?
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data)。
抽象的描述:一组用于描述数据的数据组,该数据组的一切信息都描述了该数据的某方面特征,则该数据组即可被称为元数据。
举几个…

银行数据仓库体系实践(7)--数据模型设计及流程
数据仓库作为全行或全公司的数据中心和总线,汇集了全行各系统以及外部数据,通过良好的系统架构可以保证系统稳定性和处理高效性,那如何保障系统数据的完备性、规范性和统一性呢?这里就需要有良好的数据分区和数据模型,…
银行数据仓库体系实践(10)--汇总指标层和集市模型设计
建立多层次的数据访问服务体系,有力提升数据仓库的价值。基于指标汇总层、集市层、可以提供面向业务人员的即席数据查询、以及面向应用开发者的数据接口、应用访问接口,满足不同类型应用的需要。
1、汇总指标层模型设计原则及步骤 1.1建设目标ÿ…
Hive之set参数大全-12
指定是否尝试在 Hive Metastore 中使用直接 SQL 查询执行 DDL(数据定义语言)操作
hive.metastore.try.direct.sql.ddl 是 Hive 的配置参数之一,用于指定是否尝试在 Hive Metastore 中使用直接 SQL 查询执行 DDL(数据定义语言&…
ClickHouse(22)ClickHouse集成HDFS表引擎详细解析
文章目录 HDFS用法实施细节配置可选配置选项及其默认值的列表libhdfs3 支持的ClickHouse 额外的配置限制 Kerberos 支持虚拟列 资料分享系列文章clickhouse系列文章知乎系列文章 HDFS
这个引擎提供了与Apache Hadoop生态系统的集成,允许通过ClickHouse管理HDFS上的…
Hive(15)中使用sum() over()实现累积求和和滑动求和
目的:
三个常用的排序函数row_number(),rank()和dense_rank()。这三个函数需要配合开窗函数over()来实现排序功能。但over()的用法远不止于此,本文咱们来介绍如何实现累计求和和滑动求和。
1、数据介绍
三列数据,分别是员工的姓名、月份和…

问卷发放实战指南:提高问卷回收率与数据质量的技巧
进行问卷调查分为四步:制作问卷、发放问卷、收集问卷、分析问卷。其中,发放问卷起到了关键性的作用。他关乎到我们后续收集问卷是否顺利,收集到的问卷数据是否具备真实性和有效性。那么,怎么有效地进行问卷发放呢?
…
HiveSQL题——聚合函数(sum/count/max/min/avg)
目录
一、窗口函数的知识点
1.1 窗户函数的定义
1.2 窗户函数的语法
1.3 窗口函数分类
聚合函数
排序函数
前后函数
头尾函数
1.4 聚合函数
二、实际案例
2.1 每个用户累积访问次数
0 问题描述
1 数据准备
2 数据分析
3 小结
2.2 各直播间最大的同时在线人数 …
ClickHouse(24)ClickHouse集成mongodb表引擎详细解析
文章目录 MongoDB创建一张表用法示例 资料分享系列文章clickhouse系列文章 MongoDB
MongoDB 引擎是只读表引擎,允许从远程 MongoDB 集合中读取数据(SELECT查询)。引擎只支持非嵌套的数据类型。不支持 INSERT 查询。
创建一张表
CREATE TABLE [IF NOT EXISTS] [db…
百川终入海 ,一站式海量数据迁移工具 X2Doris 正式发布
在大数据分析领域,Apache Doris 作为广受认可的开源实时数据仓库,已经在越来越多行业用户的真实业务场景中得到广泛应用,成为许多企业数据分析基础设施的重要基座。尤其在过去一年多的时间里,越来越多企业选择基于 Apache Doris 进…
Apache Doris 2.0.4 版本正式发布
亲爱的社区小伙伴们,Apache Doris 2.0.4 版本已于 2024 年 1 月 26 日正式发布,该版本在新优化器、倒排索引、数据湖等功能上有了进一步的完善与更新,使 Apache Doris 能够适配更广泛的场景。此外,该版本进行了若干的改进与优化&…
Hive之set参数大全-22(完)
指定是否启用矢量化处理复杂数据类型
在 Hive 中,hive.vectorized.complex.types.enabled 是一个配置参数,用于指定是否启用矢量化处理复杂数据类型。以下是有关该参数的一些解释: 用途: 该参数用于控制是否启用 Hive 的矢量化执…
银行数据仓库体系实践(12)--数据管理及治理
数据仓库作为全行数据中心能高效支持全行或全公司的统计 、数据分析工作,除了稳定的ETL架构、高效的数据处理能力,流畅的开发管理流程,还需要有全面的数据管理体系,确保提供的数据准确性和高质量。数据管理主要有数据标准…
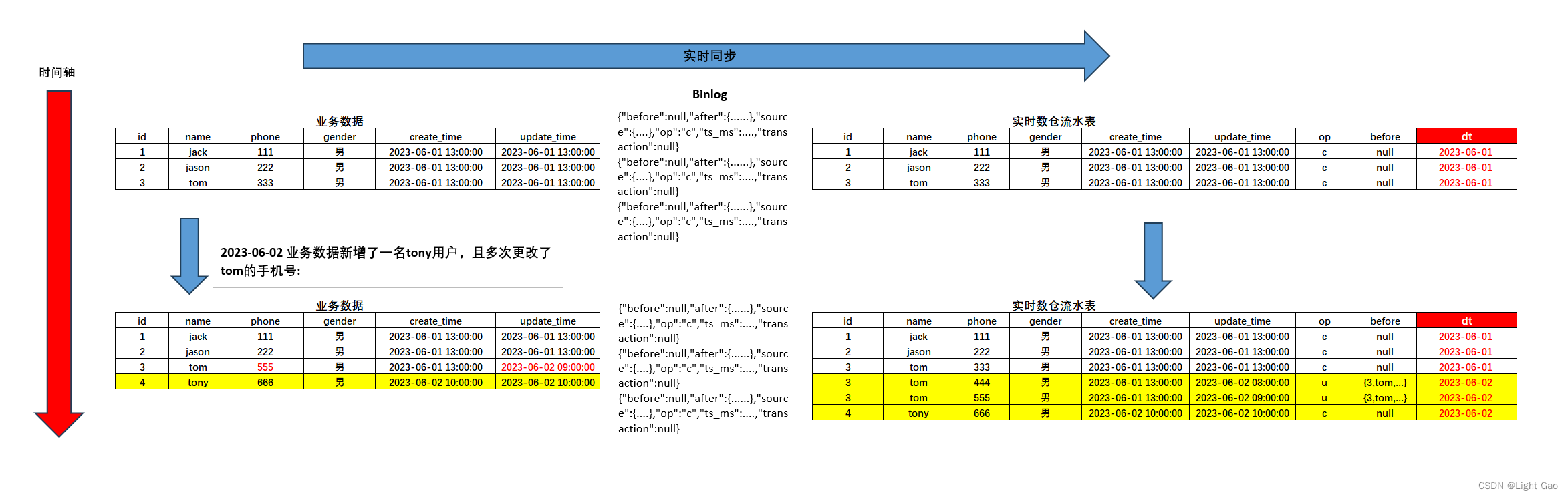
Flink实时数仓同步:流水表实战详解
一、背景
在大数据领域,初始阶段业务数据通常被存储于关系型数据库,如MySQL。然而,为满足日常分析和报表等需求,大数据平台采用多种同步方式,以适应这些业务数据的不同存储需求。这些同步存储方式包括离线仓库和实时仓…
(四)hive的搭建2
在(三)hive的搭建1中我们搭建好了hive环境,但是只能本地访问,在本节中配置Hive的访问方式。
1.元数据服务的方式
1.1 编辑hive-site.xml sudo vi hive-site.xml
在文件最后增加以下内容
<!– 指定存储元数据要连接的地址 –…
HiveSQL——用户行为路径分析
注:参考文档:
SQL之用户行为路径分析--HQL面试题46【拼多多面试题】_路径分析 sql-CSDN博客文章浏览阅读2k次,点赞6次,收藏19次。目录0 问题描述1 数据分析2 小结0 问题描述已知用户行为表 tracking_log, 大概字段有&…
Hive调优——explain执行计划
一、explain查询计划概述 explain将Hive SQL 语句的实现步骤、依赖关系进行解析,帮助用户理解一条HQL 语句在底层是如何实现数据的查询及处理,通过分析执行计划来达到Hive 调优,数据倾斜排查等目的。 官网指路:
https://cwiki.ap…
CDH6.3.2,不互通的cdh平台互导hive数据
1、先导出所有建表语句,在源CDH服务器命令行输入下面命令,该库下所有建表语句保存至hive目录中的tables.sql文件中,不知道具体路径可以全局搜索一下,拿到源库hive的建表语句后,稍微处理一下,去目标库把表建…
Hive之set参数大全-17
配置是否启用 HiveServer2 的 Web 用户界面(WebUI)中的跨源资源共享(CORS)
在 Hive 中,hive.server2.webui.enable.cors 是一个参数,用于配置是否启用 HiveServer2 的 Web 用户界面(WebUI&…
Hive之set参数大全-18
指定在执行 Spark 上的动态分区裁剪时,用于评估分区数据大小的最大限制
在 Hive 中,hive.spark.dynamic.partition.pruning.max.data.size 是一个配置参数,用于指定在执行 Spark 上的动态分区裁剪时,用于评估分区数据大小的最大限…
hive表中导入数据 多种方法详细说明
文章中对hive表中导入数据 方法目录 方式一:通过load方式加载数据 方式二:直接向分区表中插入数据 方式三:查询语句中创建表并加载数据(as select) 方式四:创建表时通过location指定加载数据路径 1. 创建表…
Doris实战——金融壹账通指标中台的应用实践
目录
前言
一、业务痛点
二、早期架构挑战
三、架构升级
四、一体化指标数据平台
4.1 构建指标体系
4.2 构建指标平台功能
五、Doris指标应用实践
六、未来规划 原文大佬的这篇指标中台的应用实践有借鉴意义,这里摘抄下来用作学习和知识沉淀。 前言 在搭建…
hive表中的数据导出 多种方法详细说明
文章中对hive表中的数据导出 多种方法目录 方式一:insert导出 方式二:hive shell 命令导出
方式三:export导出到HDFS上 目标:
将hive表中的数据导出到其他任意目录,例如linux本地磁盘,例如hd…
Hive的相关概念——架构、数据存储、读写文件机制
目录
一、架构及组件介绍
1.1 Hive整体架构
1.2 Hive组件
1.3 Hive数据模型(Data Model)
1.3.1 Databases
1.3.2 Tables
1.3.3 Partitions
1.3.4 Buckets
二、Hive读写文件机制
2.1 SerDe 作用
2.2 Hive读写文件流程
2.2.1 读取文件的过程
…
(14)Hive调优——合并小文件
目录 一、小文件产生的原因
二、小文件的危害
三、小文件的解决方案
3.1 小文件的预防
3.1.1 减少Map数量 3.1.2 减少Reduce的数量
3.2 已存在的小文件合并
3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…
(04)Hive的相关概念——order by 、sort by、distribute by 、cluster by
Hive中的排序通常涉及到order by 、sort by、distribute by 、cluster by
一、语法 selectcolumn1,column2, ...
from table
[where 条件]
[group by column]
[order by column]
[cluster by column| [distribute by column] [sort by column]
[limit [offset,] rows];
…
(06)Hive——正则表达式
Hive版本:hive-3.1.2
一、Hive的正则表达式概述 正则表达式是一种用于匹配和操作文本的强大工具,它是由一系列字符和特殊字符组成的模式,用于描述要匹配的文本模式。 Hive的正则表达式灵活使用解决HQL开发过程中的很多问题,本篇文…

(17)Hive ——MR任务的map与reduce个数由什么决定?
一、MapTask的数量由什么决定? MapTask的数量由以下参数决定
文件个数文件大小blocksize 一般而言,对于每一个输入的文件会有一个map split,每一个分片会开启一个map任务,很容易导致小文件问题(如果不进行小文件合并&…
(16)Hive——企业调优经验
前言 本篇文章主要整理hive-3.1.2版本的企业调优经验,有误请指出~
一、性能评估和优化
1.1 Explain查询计划 使用explain命令可以分析查询计划,查看计划中的资源消耗情况,定位潜在的性能问题,并进行相应的优化。 explain执行计划…
SparkUI任务启动参数介绍(148个参数)
SparkUI任务启动参数介绍(148个参数)
1 spark.app.id: Spark 应用程序的唯一标识符。 2 spark.app.initial.jar.urls: Spark 应用程序的初始 Jar 包的 URL。 3 spark.app.name: Spark 应用程序的名称。 4 spark.app.startTime: Spark 应用程序的启动时间…
(08)Hive——Join连接、谓词下推
前言 Hive-3.1.2版本支持6种join语法。分别是:inner join(内连接)、left join(左连接)、right join(右连接)、full outer join(全外连接)、left semi join(左…
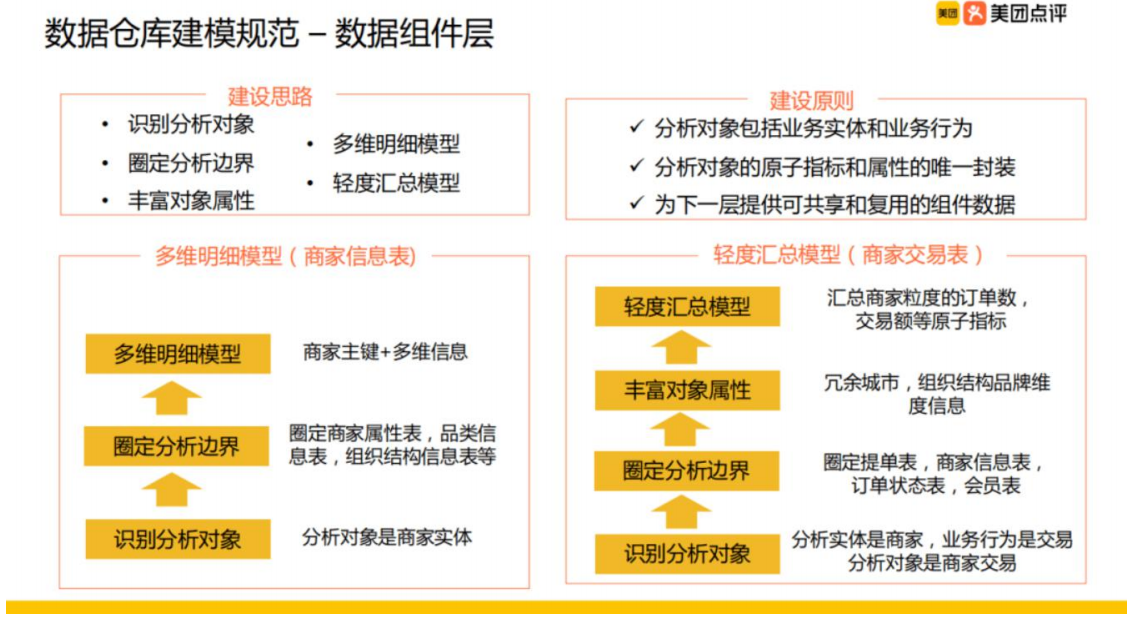
大数据02-数据仓库
零、文章目录
大数据02-数据仓库
1、数据仓库介绍
(1)基本概念
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Sup…
【dbeaver】win环境的kerberos认证和Clouders/cdh集群中Kerberos认证使用Dbeaver连接Hive、Impala和Phoenix
一、配置Mit kerberos
1.1 下载安装MIT KERBEROS客户端
MIT KERBEROS 下载较新的版本即可。 下载之后一路默认安装即可。注意:不要修改软件安装位置。 修改系统环境变量中的Path。将刚刚的安装路径置顶。(不置顶,也要比%JAVA_HOME%\bin和a…
hive内置函数--floor,ceil,rand三种取整函数
文中三种取整函数操作目录:
一、向下取整函数: floor
二、向上取整函数: ceil
三、取随机数函数: rand 一、向下取整函数: floor
语法: floor(double a)
返回值: BIGINT
说明:返回等于或者小于该doubl…

DeepBI实现AI结合数据仓库做智能数据分析VS传统BI工具
#AI数据分析#
传统数据分析如同一座巍峨的大山,每一步都让人感到沉重和艰难。从数据采集、存储、筛选、整合,到人工预测和技术实现,这些繁琐的过程如同攀登峭壁,既艰难又耗时。
然而,随着AI时代的到来,De…
StarRocks实战——携程酒店实时数仓
目录
一、实时数仓
二、实时数仓架构介绍
2.1 Lambda架构
2.2 Kappa架构
三、携程酒店实时数仓架构
3.1 架构选型
3.2 实时计算引擎选型
3.3 OLAP选型
四、携程酒店实时订单
4.1 数据源
4.2 ETL数据处理
4.3 应用效果
4.4 总结 原文大佬的这篇实时数仓建设案例有借…
Hive表使用ORC格式和SNAPPY压缩建表语句示例
Hive表使用ORC格式和SNAPPY压缩建表语句示例
下面是一个sql示例:
-- 创建数据库
CREATE DATABASE IF NOT EXISTS mydatabase;-- 使用数据库
USE mydatabase;-- 创建分区表,使用ORC文件格式,采用Snappy压缩算法
CREATE TABLE IF NOT EXISTS …
hive执行select count(1)返回0
背景: 做数据质量检核任务的时候,有些数据表有数据,直接查hive执行select count(1) from table返回的值一直是0 问题原因: hive通过select count(1)或者select count(*) 查询的是元数据库里面的rownum,如果数据表数据是通过load、…
Apache Doris 2.0.5 版本正式发布
亲爱的社区小伙伴们,Apache Doris 2.0.5 版本已于 2024 年 2 月 27 日正式与大家见面。这次更新带来一系列行为变更和功能更新,并进行了若干的改进与优化,旨在为用户提供更为稳定高效的数据查询与分析体验。新版本已经上线,欢迎大…
Hive分组取满足某字段的记录
在SQL分组后取第一条记录中介绍了分组取满足条件的第一条记录的方法,现在业务上面临如此需求:在做公司流程监控时,要求监控每个流程每个节点的用时情况。其中有个字段isend可以判断流程是否结束,但是流程结束后可能还会有操作&…

银河麒麟V10SP3操作系统-网络时间配置
1、动态网络配置
打开终端,以网口 eth0 为例:
nmcli conn add connection.id eth0-dhcp type ether ifname eth0
ipv4.method auto其中“eth0-dhcp”为连接的名字,可以根据自己的需要命名方便记忆和操作 的名字;“ifname eth0”…
Hive函数 EXPLODE 和 POSEXPLODE 使用示例
Hive函数 EXPLODE 和 POSEXPLODE 使用示例
在Hive中, explode 和 posexplode 是两个常用的函数,用于处理复杂数据类型,如数组和map。以下是它们的具体应用示例和介绍:
1. 创建了一个名为 students 的表,包括 group_n…
北京保险服务中心携手镜舟科技,助推新能源车险市场规范化
2022 年,一辆新能源汽车在泥泞的小路上不慎拖底,动力电池底壳受损,电池电量低。车主向保险公司报案,希望能够得到赔偿。然而,在定损过程中,保司发现这辆车的电池故障并非由拖底事件引起,而是由于…

hive-批量导出表结构,导入表结构
1、导出hive表结构
datastudio可以连接hive库,通过show databases 语句可以显示hive下建了多少数据库名。
使用use 数据库名,进入某个数据库下,通过show tables可显示该数据库下建了多少张表。
将所有库的表数据整理成库名.表名的形式放入…
Hive连接函数 concat 和 concat_ws 使用示例
Hive连接函数 concat 和 concat_ws 使用示例 concat 函数的语法: concat(str1, str2, …) :将多个字符串连接成一个字符串,中间使用空格进行分隔。 concat_ws 函数的语法: concat_ws(sep, str1, str2, …) :将多个字符…
Hive中的CONCAT、CONCAT_WS与COLLECT_SET函数
1.CONCAT与CONCAT_WS函数
1.1 CONCAT函数
-- concat(str1, str2, ... strN) - returns the concatenation of str1, str2, ... strN or concat(bin1, bin2, ... binN) - returns the concatenation of bytes in binary data bin1, bin2, ... binN
Returns NULL if any argum…
Hive中的explode函数、posexplode函数与later view函数
1.概述 在离线数仓处理通过HQL业务数据时,经常会遇到行转列或者列转行之类的操作,就像concat_ws之类的函数被广泛使用,今天这个也是经常要使用的拓展方法。
2.explode函数
2.1 函数语法
-- explode(a) - separates the elements of array …

逻辑数据平台的 NoETL 之道(内含QA)
作者简介: 余俊,Aloudata 合伙人 & 技术副总裁。拥有 18 年互联网技术和大数据平台相关架构经验。作为主架构师及核心研发主导并完成了 Alibaba B2B 首个海量分布式 KV 存储系统,作为网站架构师负责 Aliexpress 全球买全球卖交易系统的第…

数据仓库的设计开发应用(一)
目录 一、数据仓库设计的特点二、数据仓库系统开发过程三、数据仓库系统的规划 一、数据仓库设计的特点
1、“数据驱动” 的设计 数据仓库是从已有数据出发的设计方法,即从数据源抽取数据,经转换形成面向主题,支持决策的数据集合。 以全面了…
某项目公司-——ETL工程师岗位——二面
1.自我介绍
2.如果给你一个数仓项目,你应该从那些方面向你的上级汇报。
3.对自己的未来职业生涯规划。
4.平常下班之后做那哪些事情。
5.对于写PPT,写文档这块是否可以。
6.遇到工作中的压力,该如何处理。
7.你曾经是做什么的。为什么想着向互联网…

印度交易所股票行情数据API接口
1. 历史日线 # Restful API
https://tsanghi.com/api/fin/stock/XNSE/daily?token{token}&ticker{ticker}默认返回全部历史数据,也可以使用参数start_date和end_date选择特定时间段。 更新时间:收盘后3~4小时。 更新周期:每天。 请求方式…
数据仓库的设计开发应用(三)
目录 五、数据仓库的实施(一)数据仓库的创建(二)数据抽取转换加载 六、数据仓库系统的开发(一)开发任务(二)开发方法(三)系统测试 七、数据仓库系统的应用&am…
flink重温笔记(十八): flinkSQL 顶层 API ——时态表实现表数据动态变化(涵盖全面实用的 API )
Flink学习笔记 前言:今天是学习 flink 的第 18 天啦!很多小伙伴私信说,自己只会SQL语法来编写flinkSQL,如何使用代码来操作呢?因为工作中都是要用到代码编写的。还有小伙伴说,想要实现表是动态变化的&#…
![[自研开源] MyData 数据集成之数据过滤 v0.7.2](https://img-blog.csdnimg.cn/direct/f591fda5bf7249949f14701d37165cce.png)
[自研开源] MyData 数据集成之数据过滤 v0.7.2
开源地址:gitee | github 详细介绍:MyData 基于 Web API 的数据集成平台 部署文档:用 Docker 部署 MyData 使用手册:MyData 使用手册 试用体验:https://demo.mydata.work 交流Q群:430089673
概述
本篇基于…
大数据时代的电商:如何利用API进行高效的数据采集与分析
在大数据时代,电商平台积累的数据量是前所未有的。有效地采集、分析和利用这些数据对于提升商家的竞争力至关重要。API(应用程序编程接口)作为连接不同系统和数据的桥梁,在此过程中发挥着核心作用。以下是如何利用API进行高效数据…
hive--字符串截取函数substr(),substring()
一、字符串截取函数:substr,substring
语法: substr(string A, int start),substring(string A, int start)
返回值: string
说明:返回字符串A从start位置到结尾的字符串
举例: hive> select substr(abcde,3); cde hive…
【大数据】-- dataworks 创建odps 的 hudi 外表
文档:创建OSS外部表_云原生大数据计算服务 MaxCompute(MaxCompute)-阿里云帮助中心
举例:创建 odps 的 hudi 外表
CREATE EXTERNAL TABLE IF NOT EXISTS my_project.ods_hudi_mysql_words_h_all
(id BIGINT COMMENT 主键id,`words` STRING COMMENT 词…
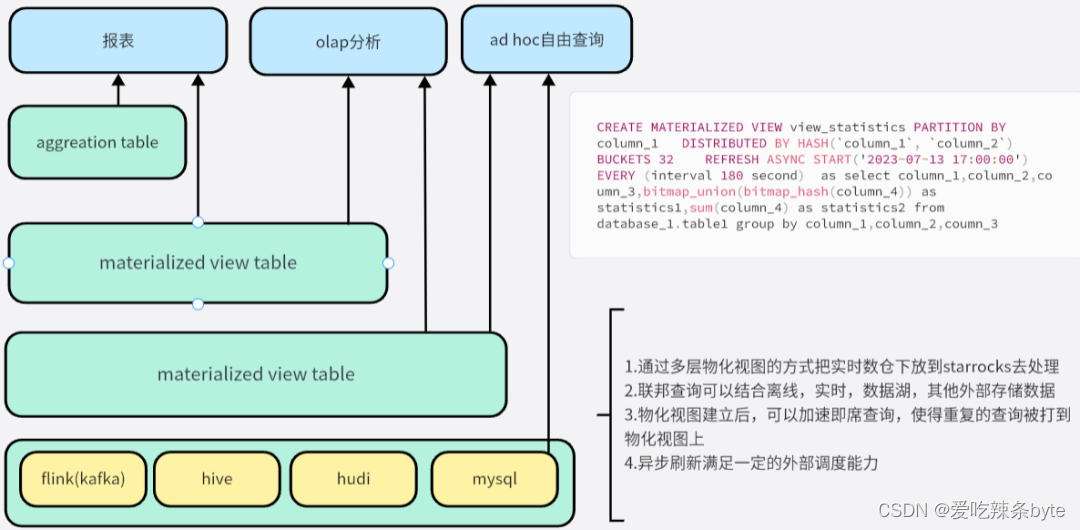
Flink——芒果TV的实时数仓建设实践
目录
一、芒果TV实时数仓建设历程
1.1 阶段一:Storm/Flink JavaSpark SQL
1.2 阶段二:Flink SQLSpark SQL
1.3 阶段三:Flink SQLStarRocks
二、自研Flink实时计算调度平台介绍
2.1 现有痛点
2.2 平台架构设计
三、Flink SQL实时数仓分…
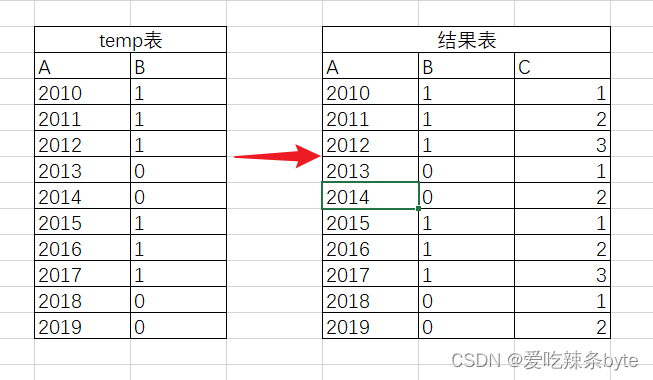
HiveSQL题——窗口函数(lag/lead)
目录
一、窗口函数的知识点
1.1 窗户函数的定义
1.2 窗户函数的语法
1.3 窗口函数分类
1.4 前后函数:lag/lead
二、实际案例
2.1 股票的波峰波谷
0 问题描述
1 数据准备
2 数据分析
3 小结
2.2 前后列转换(面试题)
0 问题描述
1 数据准备 …

FineBI与DeepBI针对用9行数据分析一篇完整的数据报告的速度对比
#数据分析报告#
在我们的理想化构想中,数据分析师如同诸葛亮一般,运筹帷幄之中,决策千里之外。他们似乎拥有无尽的资源,可以随心所欲地运用各种方法和模型。在这样的前提下,数据分析师理应能轻松驾驭复杂的数据&#…

Hive【内部表、外部表、临时表、分区表、分桶表】【总结】
目录 Hive的物种表结构特性 一、内部表
建表
使用场景 二、外部表
建表:关键词【EXTERNAL】
场景:
外部表与内部表可互相转换 三、临时表
建表 临时表横向对比编辑
四、分区表
建表:关键字【PARTITIONED BY】
场景:
五、分桶表
…
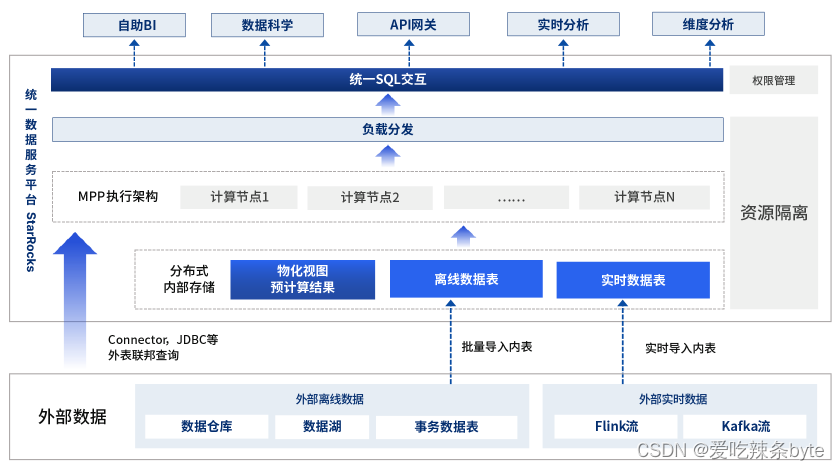
StarRocks——中信建投统一查询服务平台构建
目录
一、需求背景
1.1 数据加工链路复杂
1.2 大数据量下性能不足,查询响应慢
1.3 大量实时数据分散在各个业务系统,无法进行联合分析
1.4 缺少与预计算能力加速一些固定查询
二、构建统一查询服务平台
三、落地后的效果与价值
四、项目经验总结…

Hive案例分析之消费数据
Hive案例分析之消费数据
部分数据展示
1.customer_details
customer_id,first_name,last_name,email,gender,address,country,language,job,credit_type,credit_no
1,Spencer,Raffeorty,sraffeorty0dropbox.com,Male,9274 Lyons Court,China,Khmer Safety,Technician III,jc…
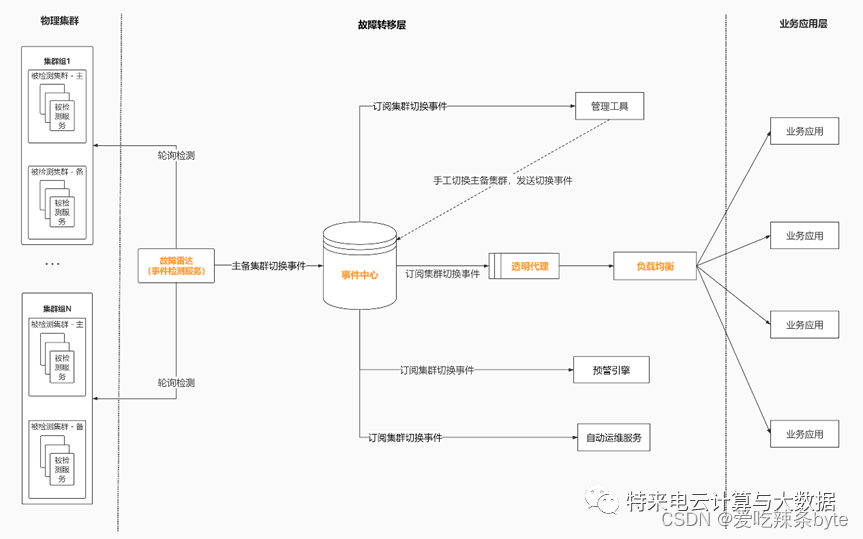
StarRocks实战——特来电StarRocks应用实践
目录
一、为何引入StarRocks
二、主要应用场景
三、封装或扩展
四、集群监控预警
五、总结规划展望
5.1 使用经验分享
5.2 下一步计划
5.2.1 StarRocks集群自动安装
5.2.2 StarRocks集群高可用架构 原文大佬的这篇StarRocks应用实践有借鉴意义,这里摘抄下来…
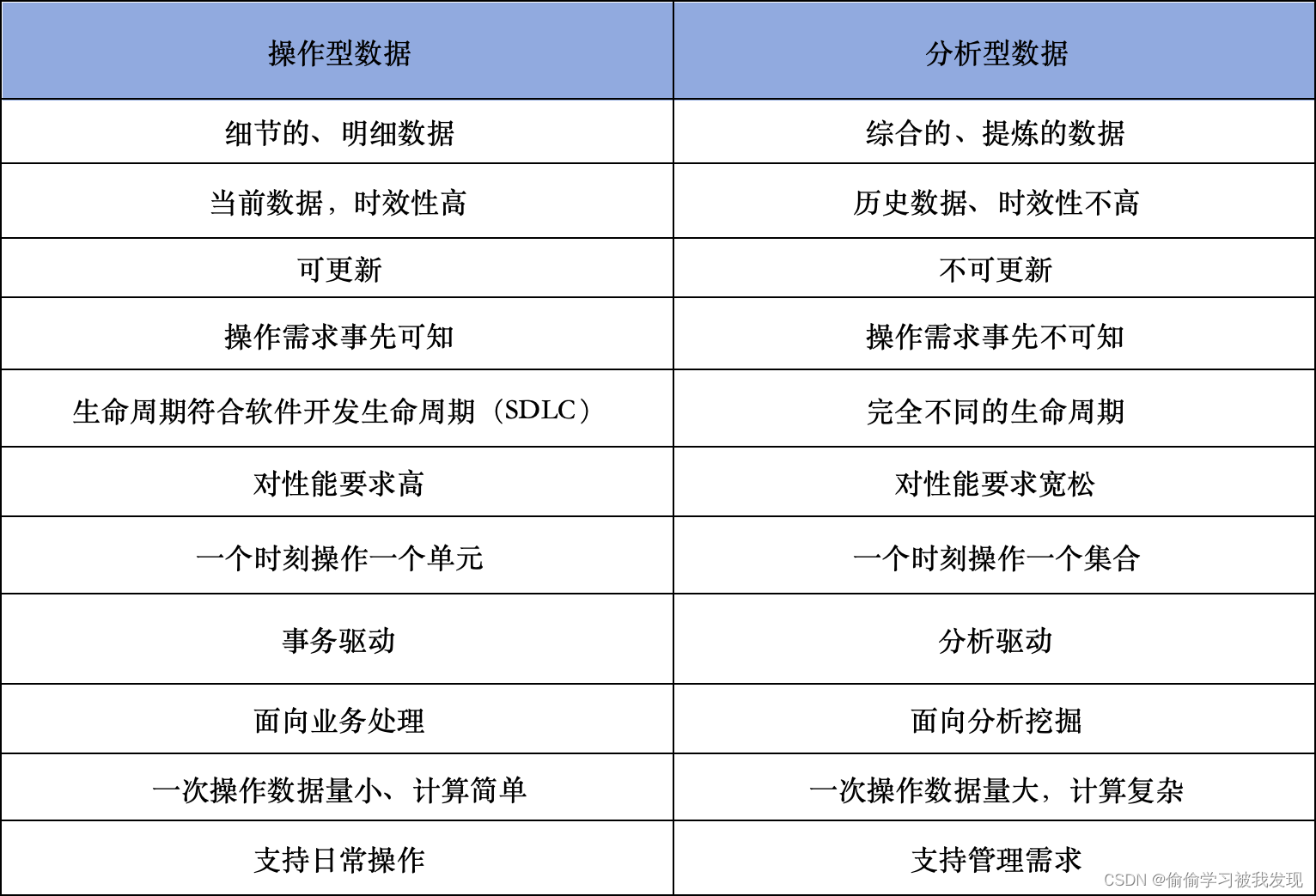
数据处理分类、数据仓库产生原因
个人看书学习心得及日常复习思考记录,个人随笔。 数据处理分类
操作型数据处理(基础)
操作型数据处理主要完成数据的收集、整理、存储、查询和增删改操作等,主要由一般工作人员和基层管理人员完成。
联机事务处理系统ÿ…

服装品牌升级必备:智能商品计划管理系统带来的五大惊喜!
随着科技的不断发展,智能商品计划管理系统已成为服装品牌升级不可或缺的工具。这种先进的管理系统为服装品牌带来了前所未有的五大惊喜,为品牌升级提供了强有力的支持。
精准的市场预测与分析
智能商品计划管理系统通过运用大数据和人工智能算法&#…
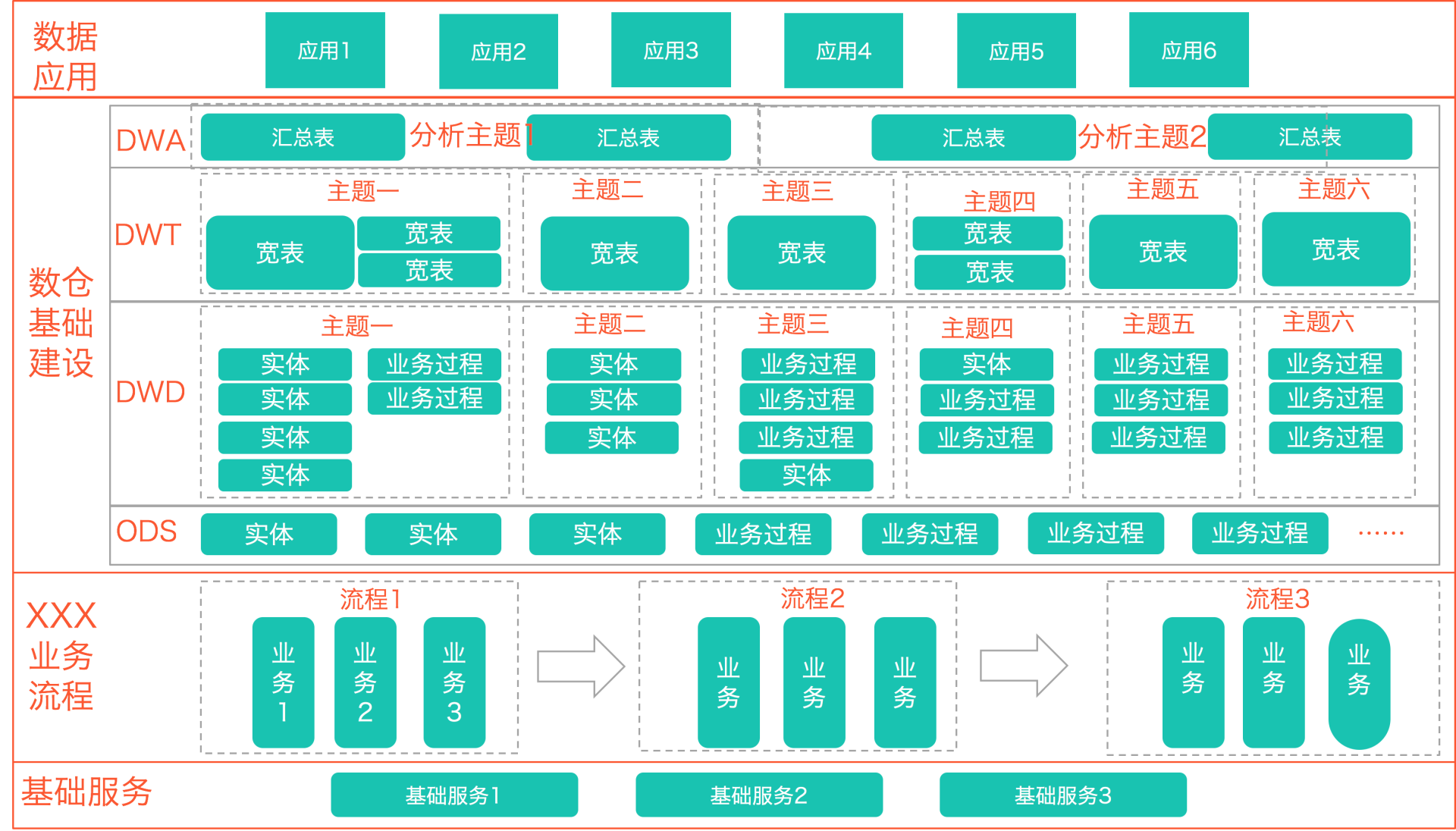
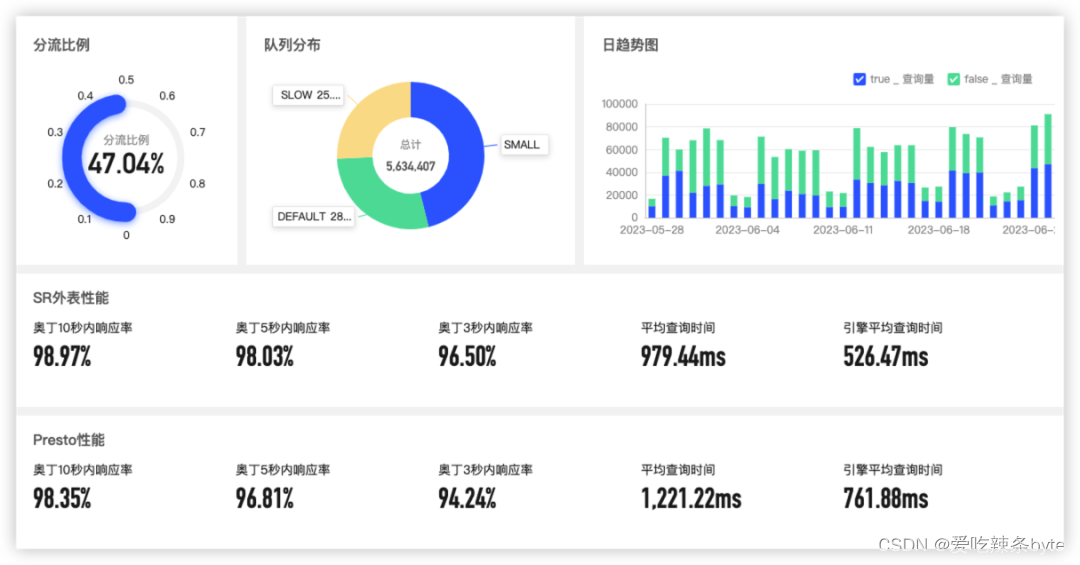
StarRocks实战——贝壳找房数仓实践
目录
前言
一、StarRocks在贝壳的应用现状
1.1 历史的数据分析架构
1.2 OLAP选型
1.2.1 离线场景
1.2.2 实时场景
1.2.3 StarRocks 的引入
二、StarRocks 在贝壳的分析实践
2.1 指标分析
2.2 实时业务
2.3 可视化分析
三、未来规划
3.1 StarRocks集群的稳定性
3…
DolphinScheduler——蔚来汽车数据治理开发平台的应用改造
目录
一、业务痛点
二、应用现状
三、技术改造
3.1 稳定性
3.1.1 滚动重启黑名单机制精准路由
3.2 易用性
依赖节点优化
补数任务优化
多 SQL 执行 原文大佬的这篇基于调度系统的数据治理案例有借鉴意义,这里摘抄下来用作学习和知识沉淀。
一、业务痛点 蔚…

hive报错:FAILED: NullPointerException null
发现问题
起因是我虚拟机的hive不管执行什么命令都报空指针异常的错误 我也在网上找了很多相关问题的资料,发现都不是我这个问题的解决方法,后来在hive官网上与hive 3.1.3版本相匹配的hadoop版本是3.x的版本,而我的hadoop版本还是2.7.2的版本…
hive 中少量数据验证函数的方法-stack
可以使用 stack 将少量数据直接写在sql中,然后用于验证是否正确
1、每个省累计销量前1名的城市 t1(pro_name,city_name,sale_num,sale_date) 源数据: ‘河北’,‘石家庄’,‘1’,‘2022-01-01’ ,‘河北’,‘石家庄’,‘2’,‘2022-01-02’ ,‘河北’,‘…
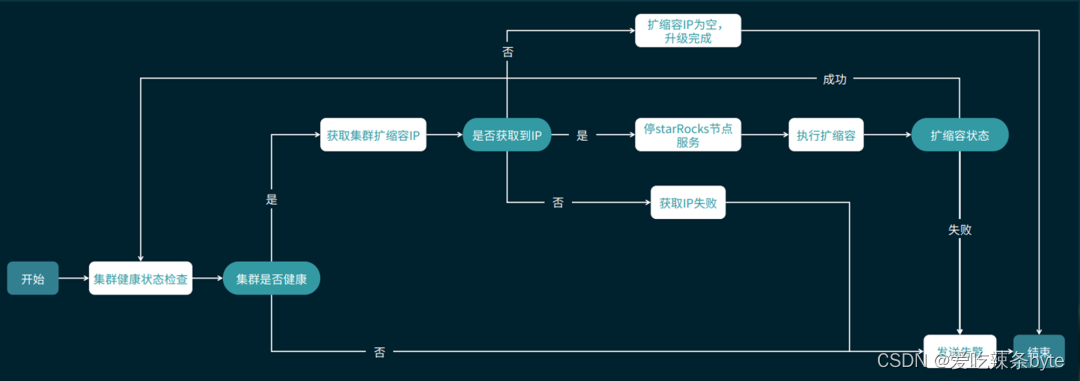
StarRocks实战——vivo基于 StarRocks 构建实时大数据平台
目录
前言
一、数据挑战
1.1 时效性挑战,业务分析决策需加速
1.2 访问量挑战,性能与稳定性亟待提高,支撑业务稳定运行
1.3 计算场景挑战,难以满足业务复杂查询需求
1.4. 运维挑战,用户查询体验需优化
二、OLA…
数据库与数据仓库关联和区别
数据库(Database)和数据仓库(Data Warehouse)都是用于存储和管理数据的重要工具,但它们之间存在明显的区别和用途。
数据库(Database)
数据库是一个结构化的数据集合,它允许用户存…

Hive Thrift Server
hive-site.xml配置文件
<property><name>hive.server2.thrift.bind.host</name><value>node1</value>
</property>hive.server2.thrift.bind.host: This property determines the host address to which the HiveServer2 Thrift service …

【hive Hadoop】踩坑 记录
【hive & Hadoop】踩坑 记录
平台部署知识 本文记录的配置 hive Hadoop 时可能会出现的问题以及解决方案。
目录 文章目录 【hive & Hadoop】踩坑 记录目录Hive记录hive 启动报错 Permission denied Unable to determine Hadoop version information.原因解释本次的解…
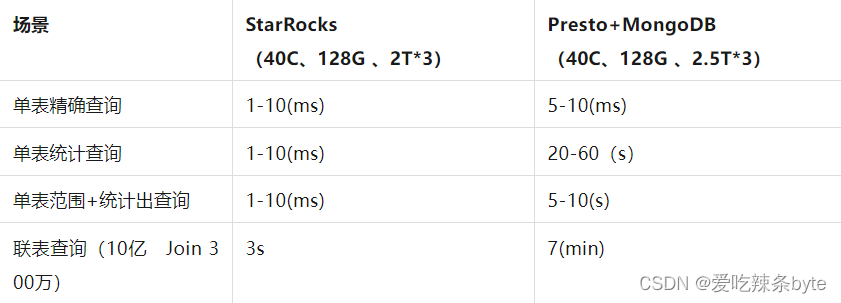
StarRocks实战——首汽约车实时数仓实践
目录
前言
一、引入背景
二、OLAP引擎选型
三、架构演进
四、实时数仓构建
五、业务实践价值未来规划 原文大佬的这篇首汽约车实时数仓实践有借鉴意义,这里摘抄下来用作学习和知识沉淀。 前言 首汽约车(以下简称“首约”)是首汽集团打造…
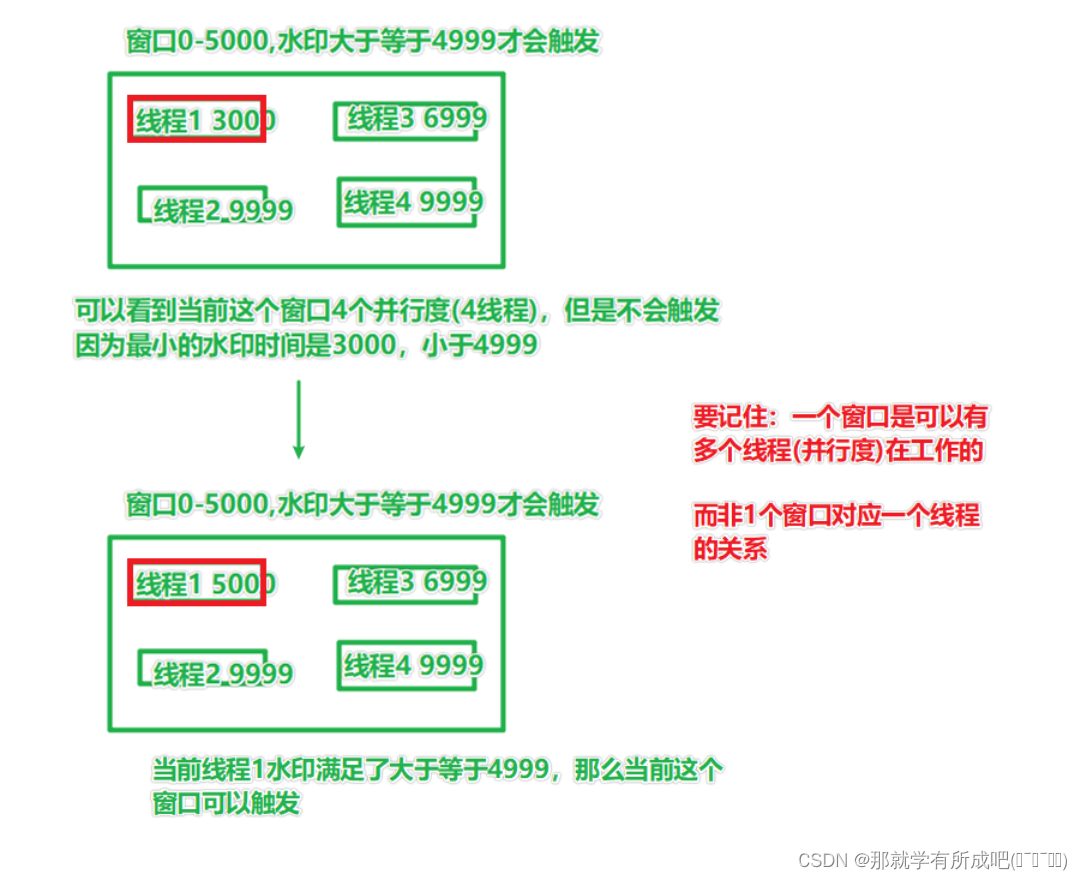
flink重温笔记(九):Flink 高级 API 开发——flink 四大基石之WaterMark(Time为核心)
Flink学习笔记 前言:今天是学习 flink 的第 9 天啦!学习了 flink 四大基石之 Time的应用—> Watermark(水印,也称水位线),主要是解决数据由于网络延迟问题,出现数据乱序或者迟到数据现象&…
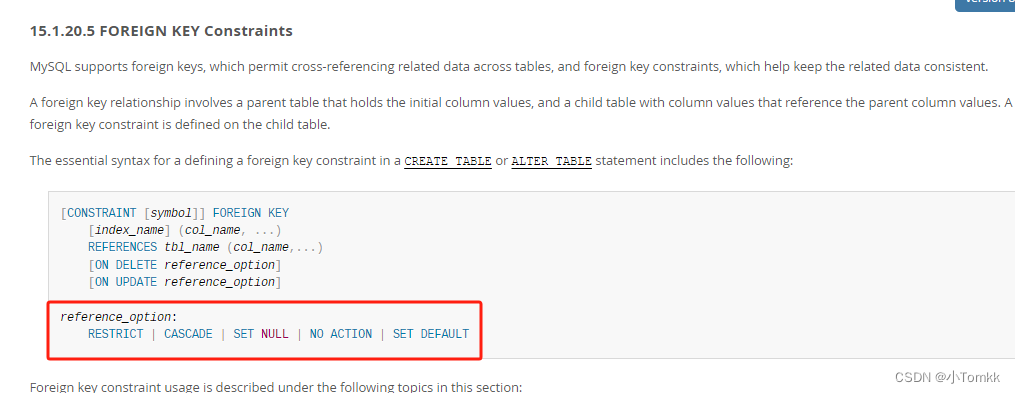
大工程 从0到1 数据治理 之数据模型和设计篇(sample database classicmodels _No.7)
大工程 从0到1 数据治理 之数据模型和设计篇
我这里还是sample database classicmodels为案列,可以下载,我看 网上还没有类似的 案列,那就 从 0-1开始吧! 文章目录 大工程 从0到1 数据治理 之数据模型和设计篇什么是数据模型设计…
DolphinScheduler——调度系统数仓任务编排规范
原文大佬的这篇DS数仓任务编排规范有借鉴意义,这里摘抄下来用作学习和知识沉淀。
前言 在使用DolphinScheduler(以下简称DS)做数仓任务管理时,数据建模分层落地到调度上缺少规范,往往比较随意,例如将所有任…
DolphinScheduler——工作流实例的生命周期
目录
一、DolphinScheduler架构原理
1.1 系统架构图
1.2 DolphinScheduler核心概念
1.2 创建工作流
1.2.1 如何触发一个工作流实例
1.2.2 任务调度链路监控
1.2.3 Workflow-DAG解析
DAG解析 Dispatch分发流程
Master和Worker的交互过程
1.3 任务运行状态 该篇文章主…
Doris实战——特步集团零售数据仓库项目实践
目录
一、背景
二、总体架构
三、ETL实践
3.1 批量数据的导入
3.2 实时数据接入
3.3 数据加工
3.4 BI 查询
四、实时需求响应
五、其他经验
5.1 Doris BE内存溢出
5.2 SQL任务超时
5.3 删除语句不支持表达式
5.4 Drop 表闪回
六、未来展望 原文大佬的这篇Doris数…
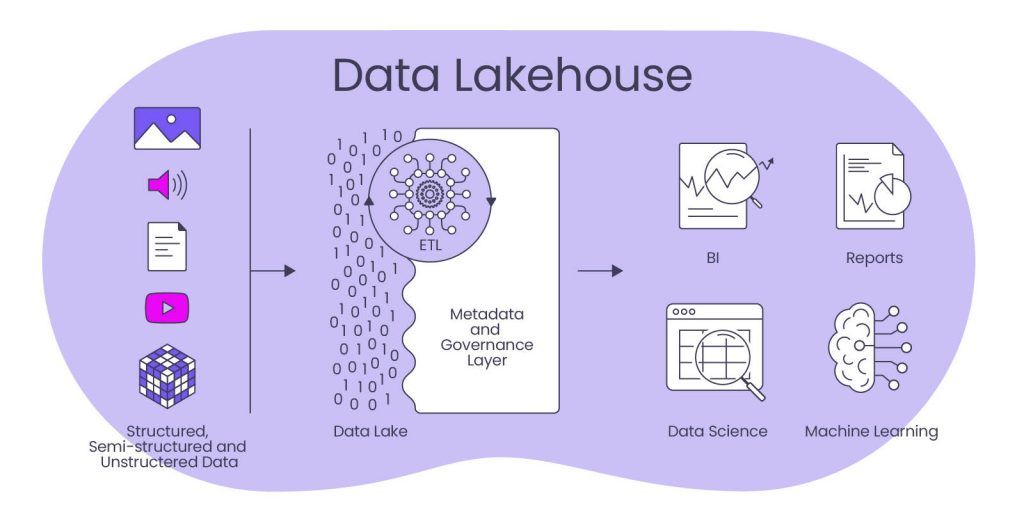
数据湖与湖仓一体是如何演变而来的?详谈大数据存储架构的变迁
在大数据存储架构的发展历程中,可以划分为三个显著的演进阶段。首先,随着Hadoop和Hive等初期项目的出现,数据仓库(Data Warehouse)的概念得以确立;随着数据仓库的不断演化,同时有了云与对象存储…
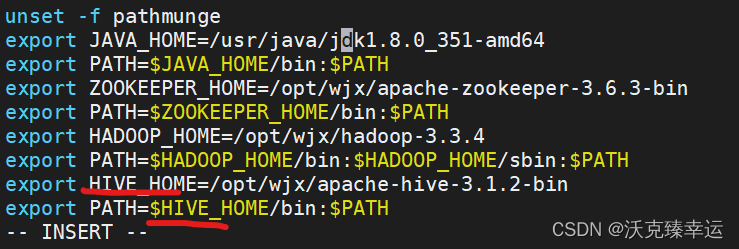
搭建hive环境,并解决后启动hive命令报 hive: command not found的问题
一、问题解决
1、问题复现 2、解决问题 查阅资料得知该问题大部分是环境变量配置出了问题,我就输入以下命令进入配置文件检查自己的环境变量配置:
[rootnode03 ~]# vi /etc/profile 检查发现自己的hive配置没有问题 ,于是我就退出…
Hive-技术补充-ANTLR语法编写
一、导读
我们学习一门语言,或外语或编程语言,是不是都是要先学语法,想想这些语言有哪些相同点 1、中文、英语、日语......是不是都有 主谓宾 的规则 2、c、java、python、js......是不是都有 数据类型 、循环 等语法或数据结构
虽然人们在…
数仓项目总结--持续更新中
业务及需求调研
应详细调研业务流程,确定各个业务领域中业务线对应的业务模块,以及所有的业务活动。。进行需求调研,其一,提取出现有报表系统中的需求指标,其二与运营、分析人员沟通获知常用的需求指标。 开发过程中应…
数仓建设实践——58用户画像数仓建设
目录
一、数据仓库&用户画像简介
1.1 数据仓库简介
1.2 数据仓库的价值
1.3 用户画像简介
1.4 用户画像—标签体系
二、用户画像数仓建设过程
2.1 画像数仓—背景&现状
2.2 画像数仓—整体架构
2.3 画像数仓—研发流程
2.4 画像数仓—指标定义
2.5 画像数仓…
离线数仓(八)【DWD 层开发】
前言 1、DWD 层开发
DWD层设计要点:
(1)DWD层的设计依据是维度建模理论(主体是事务型事实表(选择业务过程 -> 声明粒度 -> 确定维度 -> 确定事实),另外两种周期型快照事实表和累积型…
SQL的事务及其ACID属性
目录 SQL中的事务简介事务和ACID属性SQL事务中的关键命令示例SQL事务的隔离层级1. 未提交读取2. 提交后读取3. 可重复读取4. 可序列化脏读、不可重复读或虚读脏读取不可重复读取(未提交读取)虚读取推荐超级课程: Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速…
数据仓库——无事实的事实表
无事实的事实表
不包含事实的事实表被称作无事实的事实表。虽然没有明确地记录事实,但是却能够支持度量。
为事件而设的无事实的事实表,记录活动的发生,虽然没有事实被明确地存储,但是这些事件能够被计算出来,产生有…
Flink基于Hudi维表Join缺陷解析及解决方案
Hudi,这个近年来备受瞩目的数据存储解决方案,无疑是大数据领域的一颗耀眼新星。其凭借出色的性能和稳定性,以及对于数据湖场景的深度适配,赢得了众多企业和开发者的青睐。然而,正如任何一项新兴技术,Hudi在…
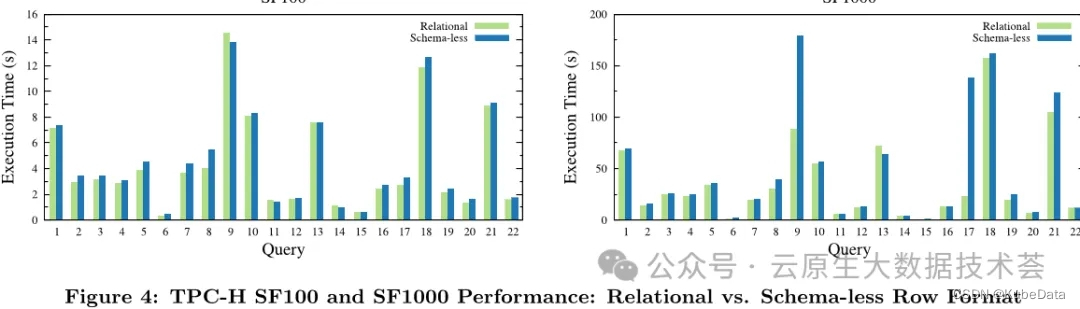
云数据仓库Snowflake论文完整版解读
本文是对于Snowflake论文的一个完整版解读,对于从事大数据数据仓库开发,数据湖开发的读者来说,这是一篇必须要详细了解和阅读的内容,通过全文你会发现整个数据湖设计的起初原因以及从各个维度(架构设计、存算分离、弹性…
数据仓库——维度表特性
企业信息化工厂
数据集市中的一致性,由于企业信息化工厂的数据集市是从集成仓库中获得信息的,因此至少从维度建模的角度来看,一致性维护的问题减少了。尽管合并不同数据源的问题依然在,但是负担主要在设计者身上。尽管压力降低了…
API接口开发1688阿里巴巴官方API接口按关键词采集ALIBABA商品api接入演示
要按关键词采集阿里巴巴商品,你需要使用1688API接口。以下是一个简单的Python示例,展示了如何使用requests库调用阿里巴巴API并解析返回的数据:
# coding:utf-8
"""
Compatible for python2.x and python3.x
requirement: pi…
activiti7 工作流中的方法
零、根据具体应用场景设计出适当的流程图 一、启动任务流程
首先获取申请表,用于启动流程(如果前端回传值是ID可忽略)
1.修改状态变为审批中 2.获取登入人,用于启动流程 具体实现是:基于登录时传给前端的token中携带…
Streampark 入门到生产实践
Streampark 入门到生产实践 1.StreamPark初探1.1 什么是StreamPark1.2 Features1.3 架构2.环境安装要求如何插入一段漂亮的代码片3.安装apache-streampark 最新版4. 使用教程4.1配置Flink_home4.2 git 拉取项目和构建项目4.3 企业微信告警4.4 相关参数配置4.5 相关参数配置yarn…
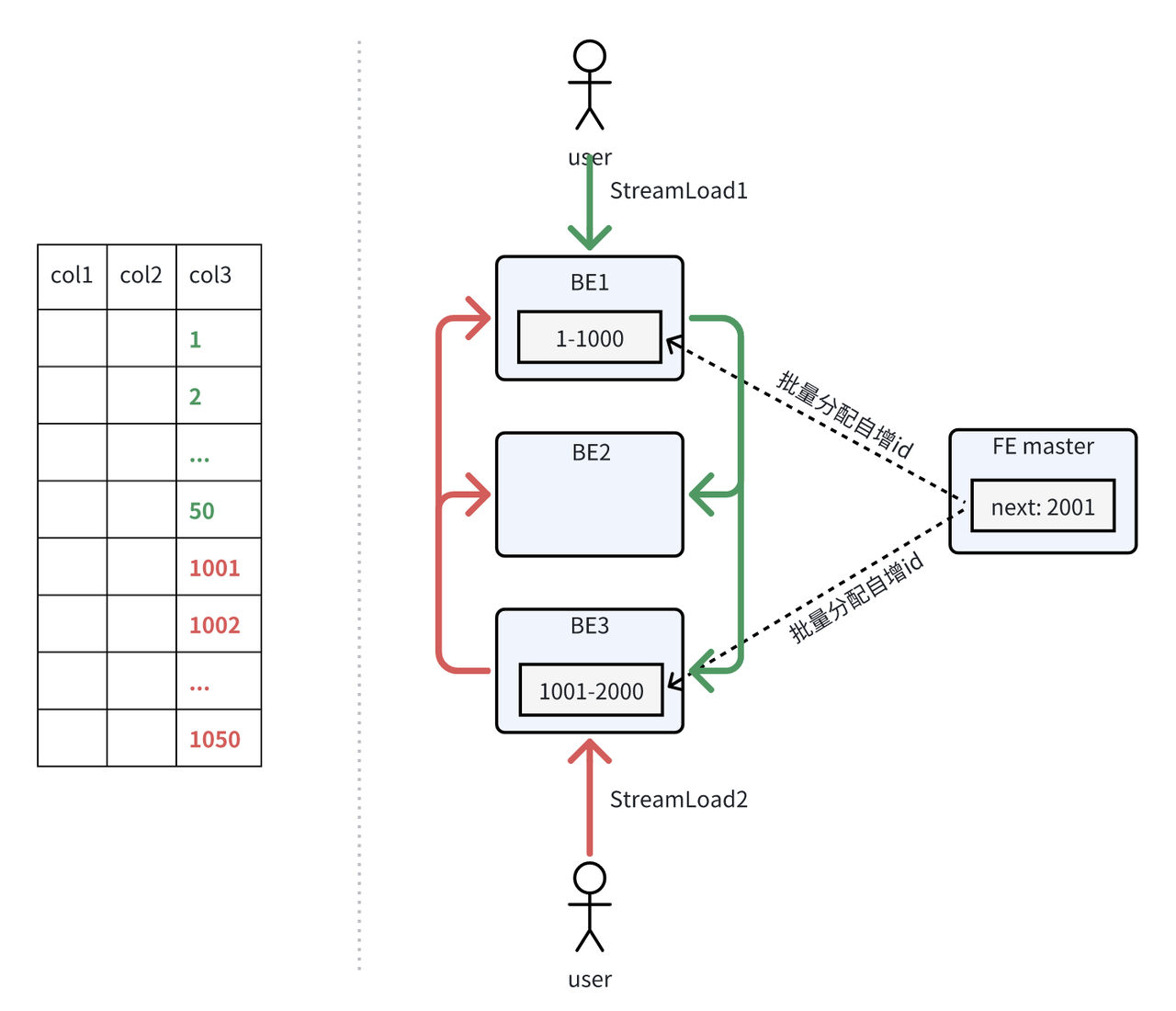
Apache Doris 如何基于自增列满足高效字典编码等典型场景需求
自增列(auto_increment)是数据库中常见的一项功能,它提供一种方便高效的方式为行分配唯一标识符,极大简化数据管理的复杂性。当新行插入到表中时,数据库系统会自动选取自增序列中的下一个可用值,并将其分配…
Hive 使用 LIMIT 指定偏移量返回数据
Hive 使用 LIMIT 指定偏移量返回数据 LIMIT 子句可用于限制SELECT语句返回的行数。 LIMIT 接受一个或两个数字参数,这两个参数必须都是非负整数常量。第一个参数指定要返回的第一行的偏移量(从Hive 2.0.0开始),第二个参数指定要返…
![[自研开源] MyData 数据集成之任务调度模式 v0.7](https://img-blog.csdnimg.cn/direct/85ed36e6d8464b7ba19c13b50e43e271.png)
[自研开源] MyData 数据集成之任务调度模式 v0.7
开源地址:gitee | github
详细介绍:MyData 基于 Web API 的数据集成平台
部署文档:用 Docker 部署 MyData
使用手册:MyData 使用手册
试用体验:http://demo.mydata.work
交流 Q 群:430089673
概述
本…

Spark 搭建模式(本地、伪分布、全分布模式)
Spark搭建模式
Standalone模式
环境搭建
1.伪分布式
#1.进入$SPARK_HOME/conf
[rootmaster ~] cd $SPARK_HOME/conf#2.拷贝spark-env.sh.template
[rootmaster conf] cp spark-env.sh.template spark-env.sh
[rootmaster conf] vi spark-env.sh# Options for the daemons u…
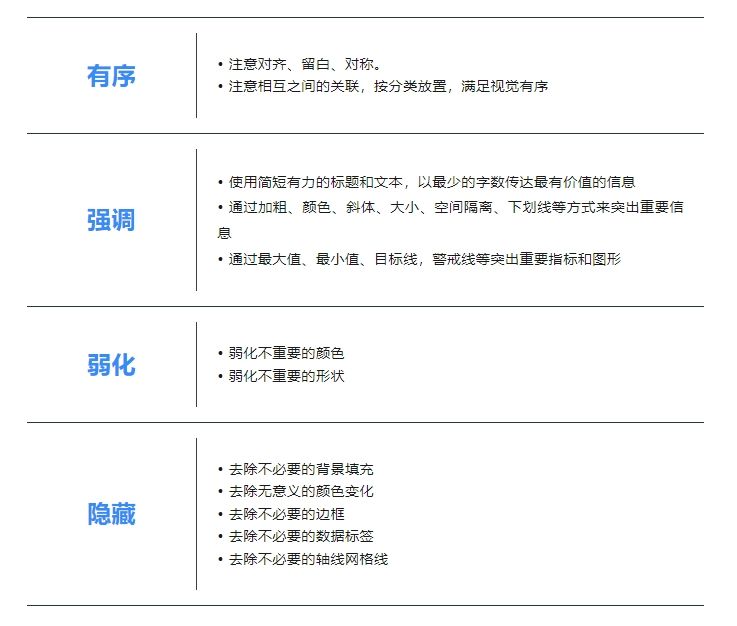
如何制作一份精美的数据分析可视化报告?详细教程
在数据可视化分析的最后阶段,所有的分析、研究、推导以及得出的结论,都汇总成了一份详实的报告。这份报告不仅是对整个数据分析旅程的总结,更是向读者展示这段旅程所取得的成果。
那么,数据分析报告该如何制作呢?不用…
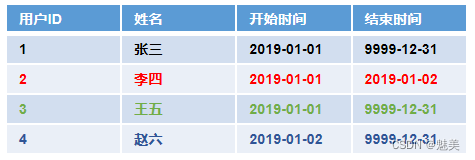
维度建模理论之维度表
维度表概述
维度表是维度建模的基础和灵魂。前文提到,事实表紧紧围绕业务过程进行设计,而维度表则围绕业务过程所处的环境进行设计。维度表主要包含一个主键和各种维度字段,维度字段称为维度属性。
维度表设计步骤
1)确定维度&…
Hive招聘数据分析
招聘数据分析
一、部分数据展示
鞍山易升科技有限公司,大专,1年工作经验,数据分析师,1,6000,少于50人,计算机软件,鞍山,辽宁
河北展源新能源科技有限公司,大专,3-4年工作经验,数据分析师,2,7000,150-500人,新能源,保定,河北
河北奥润顺达窗业有限公司,本科,1年工作经验,数据分…
金蝶云星空与植隆业务中台对接集成物料查询打通新增/更新产品接口
金蝶云星空与植隆业务中台对接集成物料查询打通新增/更新产品接口
接入系统:金蝶云星空 金蝶K/3Cloud在总结百万家客户管理最佳实践的基础上,提供了标准的管理模式;通过标准的业务架构:多会计准则、多币别、多地点、多组织、多税…
江苏开放大学2024年春《大学英语(D) 060108》第二次过程性考核作业参考答案
答案:更多答案,请关注【电大搜题】微信公众号
答案:更多答案,请关注【电大搜题】微信公众号
答案:更多答案,请关注【电大搜题】微信公众号 单选题
1从选项中选出翻译最为准确的一项。
We cannot help …
高项(2)信息化和信息系统基础知识1-软件测试-软件需求-软件架构-中间件-数据仓库-七层协议
1.国家信息化体系6要素 法律法规,是保障信息资源,信息资源的开发和利用是核心任务,是国家信息化取得实效的关键信息网络,是基础信息技术应用,是6要素中的龙头信息技术和产业,是物质保障信息化人才ÿ…
Apache Doris 2.1.1 版本正式发布!
亲爱的社区小伙伴们,Apache Doris 2.1.1 版本已于 2024 年 4 月 3 日正式发布。该版本针对 2.1.0 版本出现的问题进行较为全面的优化,提交了若干改进项以及问题修复,进一步提升了系统的性能及稳定性,欢迎大家下载体验。 立即下载&…
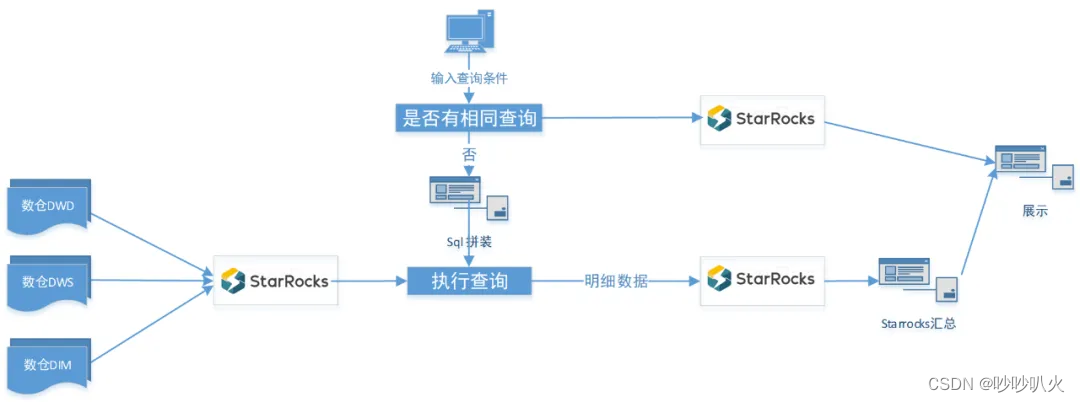
StarRocks实战——携程火车票指标平台建设
目录
前言
一、早期OLAP架构与痛点
二、指标平台重构整体设计
2.1 指标查询过程
2.1.1 明细类子查询
2.1.2 汇总类子查询
2.1.3 “缓存”
2.2 数据同步
三、Starrocks使用经验分享
3.1 建表经验
3.2 数据查询
3.3 函数问题
四、查询性能大幅提升
五、 后续优化方…
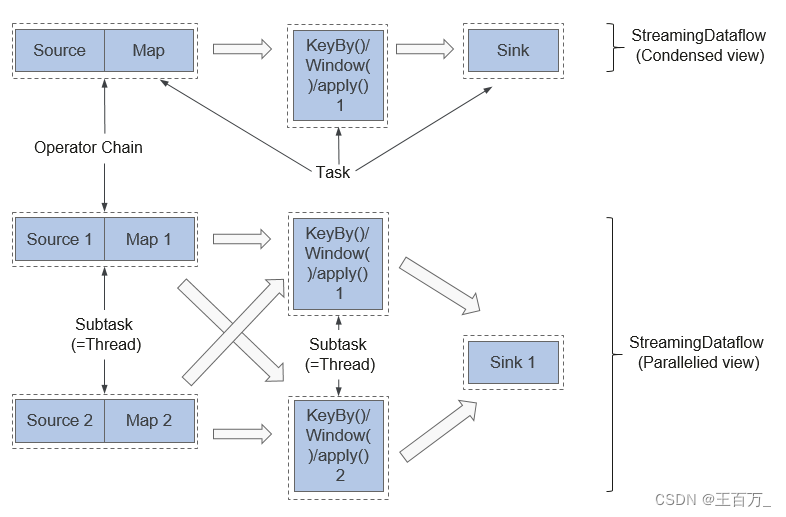
【Flink技术原理构造及特性】
1、Flink简介
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
Flink最适合的应用场景是低时延的数据处理(Data Processin…
【数据仓库】血缘关系分析工具适用场景、常见产品、功能介绍
血缘关系分析工具是用于跟踪数据在系统中的流动和转换过程,帮助用户理解数据的来源、去向以及数据之间的关系。以下是关于血缘关系分析工具的详细介绍:
适用场景:
数据治理和合规性: 帮助组织跟踪敏感数据的流动,确保…
一文了解和区分数据中台、数据平台、数据湖、数据仓库
在当今数字化时代,数据已经成为推动科技发展和商业创新的关键要素之一。数据中台、数据平台、数据湖和数据仓库是构建现代数据架构的重要组成部分。然而,这些概念之间往往容易混淆。本文将深入介绍并区分这些概念,通过生动的例子帮助读者更好…
HBase面试题及参考答案:深入理解大数据存储技术(2万字长文)
在大数据时代,HBase作为一种分布式、可扩展的NoSQL数据库,受到了广泛的关注和应用。本文将为您提供一系列HBase面试题及参考答案,帮助您全面深入地理解HBase,为您的职业生涯增添亮点。
目录
1. HBase的架构组成是怎样的?
2. HBase的读写流程是怎样的?
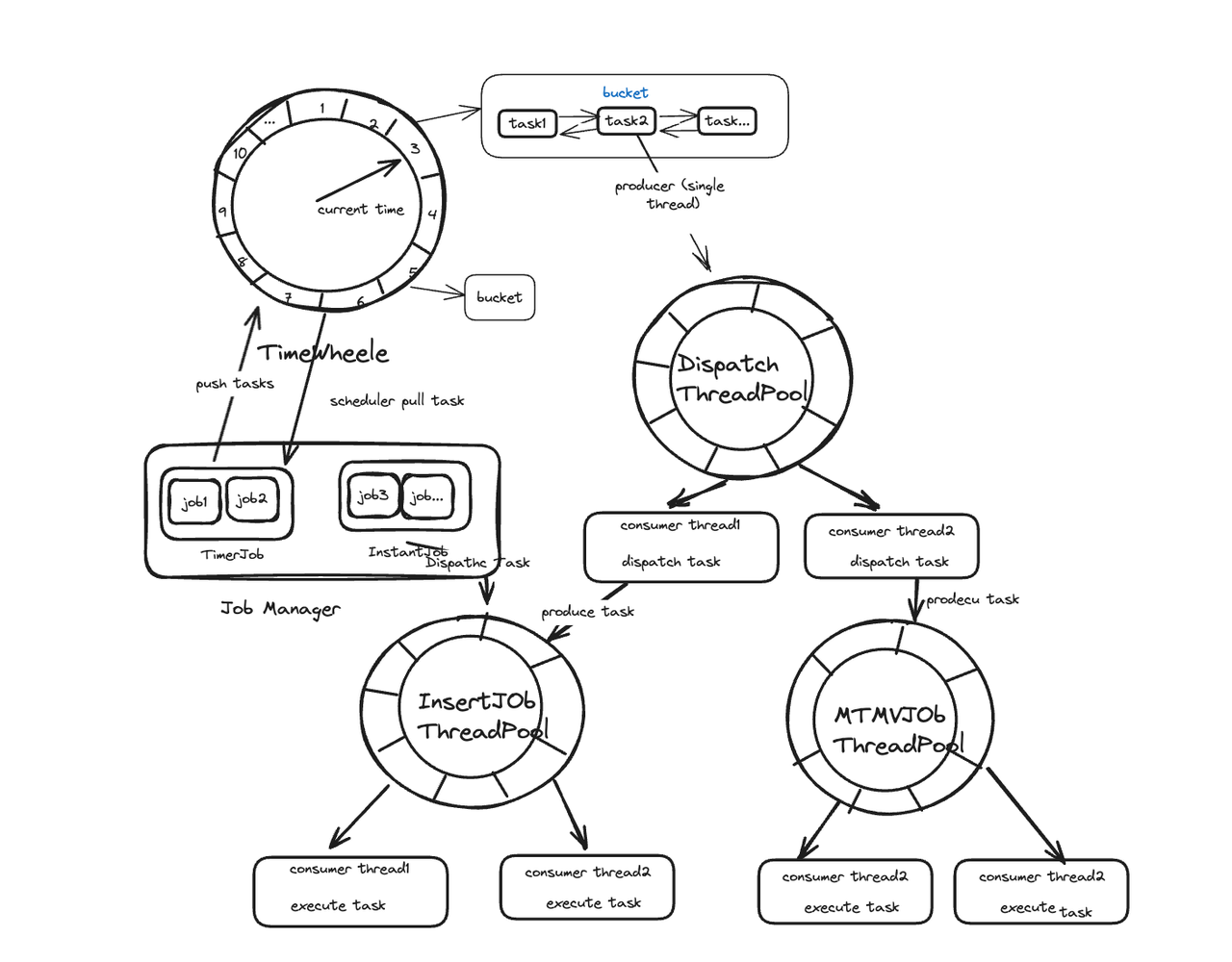
Apache Doris 基于 Job Scheduler 实现秒级触发任务调度能力
作者|SelectDB 技术团队
在数据管理愈加精细化的需求背景下,定时调度在其中扮演着重要的角色。它通常被应用于以下场景:
定期数据更新,如周期性数据导入和 ETL 操作,减少人工干预,提高数据处理的效率和准…
Hive-生产常用操作-表操作和数据处理技巧-202404
hive语句操作 我这个只涉及到hive的对表的操作,包括建表,建分区表,加载数据,导出数据,查询数据,删除数据,插入数据,以及对hive分区表的操作,包括查看分区,添加…
hive-分桶-索引(初篇)
hvie - 分桶 创建分桶表之前要先设置hive允许进行强制分桶配置
set hive.enforce.bucketingtrue 创建分桶表
create table tmp_bucket(id int,name String) clustered by (id) into 4 buckets 建表 其中x表示分几个桶进行抽样,y表示间隔几个桶进行一次分桶…
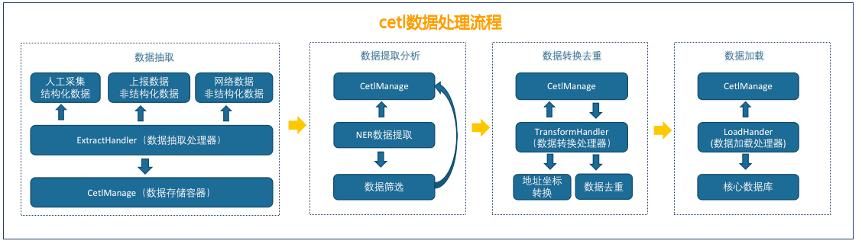
数据仓库的概念和作用?如何搭建数据仓库?
随着企业规模的扩大和数据量的爆炸性增长,有效管理和分析海量数据成为企业数字化转型的关键。而在互联网的普及过程中,信息技术已深入渗透各行业,逐渐融入企业的日常运营。然而,企业在信息化建设中面临了一系列困境和挑战…

hive管理之ctl方式
hive管理之ctl方式 hivehive --service clictl命令行的命令 #清屏
Ctrl L
#或者
! clear
#查看数据仓库中的表
show tabls;
#查看数据仓库中的内置函数
show functions;#查看表的结构
desc表名
#查看hdfs上的文件
dfs -ls 目录
#执行操作系统的命令
!命令…
如何构建基于Flink+Hologres的实时数仓
构建基于Flink和Hologres的实时数仓可以通过以下几个步骤来实现: 了解核心组件:需要对Flink和Hologres的核心能力有所了解。Flink是一个强大的流式计算引擎,支持对海量实时数据的高效处理。而Hologres是一站式实时数据仓库引擎,支持海量数据实时写入、更新和分析,兼容Post…
StarRocks实战——欢聚集团极速的数据分析能力
目录
一、大数据平台架构
二、OLAP选型及改进
三、StarRocks 经验沉淀
3.1 资源隔离,助力业务推广
3.1.1 面临的挑战
3.1.2 整体效果
3.2 稳定优先,监控先行,优化运维
3.3降低门槛,不折腾用户
3.3.1 与现有的平台做打通 …
Hive中UNION ALL和UNION的区别
1.概述 Hive官方提供了一种联合查询的语法,原名为Union Syntax,用于联合两个表的记录进行查询,此处的联合和join是不同的,join是将两个表的字段拼接到一起,而union是将两个表的记录拼接在一起。 换言之, jo…

深入理解Hive:探索不同的表类型及其应用场景
文章目录 1. 引言2. Hive表类型概览2.1 按照数据存储位置2.2 按照数据管理方式2.3 按照查询优化2.4 按照数据的临时性和持久性 3. 写在最后 1. 引言
在大数据时代,Hive作为一种数据仓库工具,为我们提供了强大的数据存储和查询能力。了解Hive的不同表类型…
Hive超市零售案例
超市零售案例
一、部分数据展示
Fiskars 剪刀| 蓝色,61,中国,华东,杭州,用品,曾惠,2,浙江,办公用品,US-2019-1357144,130
GlobeWeis 搭扣信封| 红色,43,中国,西南,内江,信封,许安,2,四川,办公用品,CN-2019-1973789,125
Cardinal 孔加固材料| 回收,4,中国,西南,内江,装订机,许…
数据挖掘方向研究生常用网站
目录
一:数据挖掘领域大佬网站和博客
二:数据挖掘教育领域
三:数据挖掘技术网站
四:基础变成工具和平台
五:一些技术csdn网站
六:机器学习
七:机器学习经典文章
八:数据挖掘…
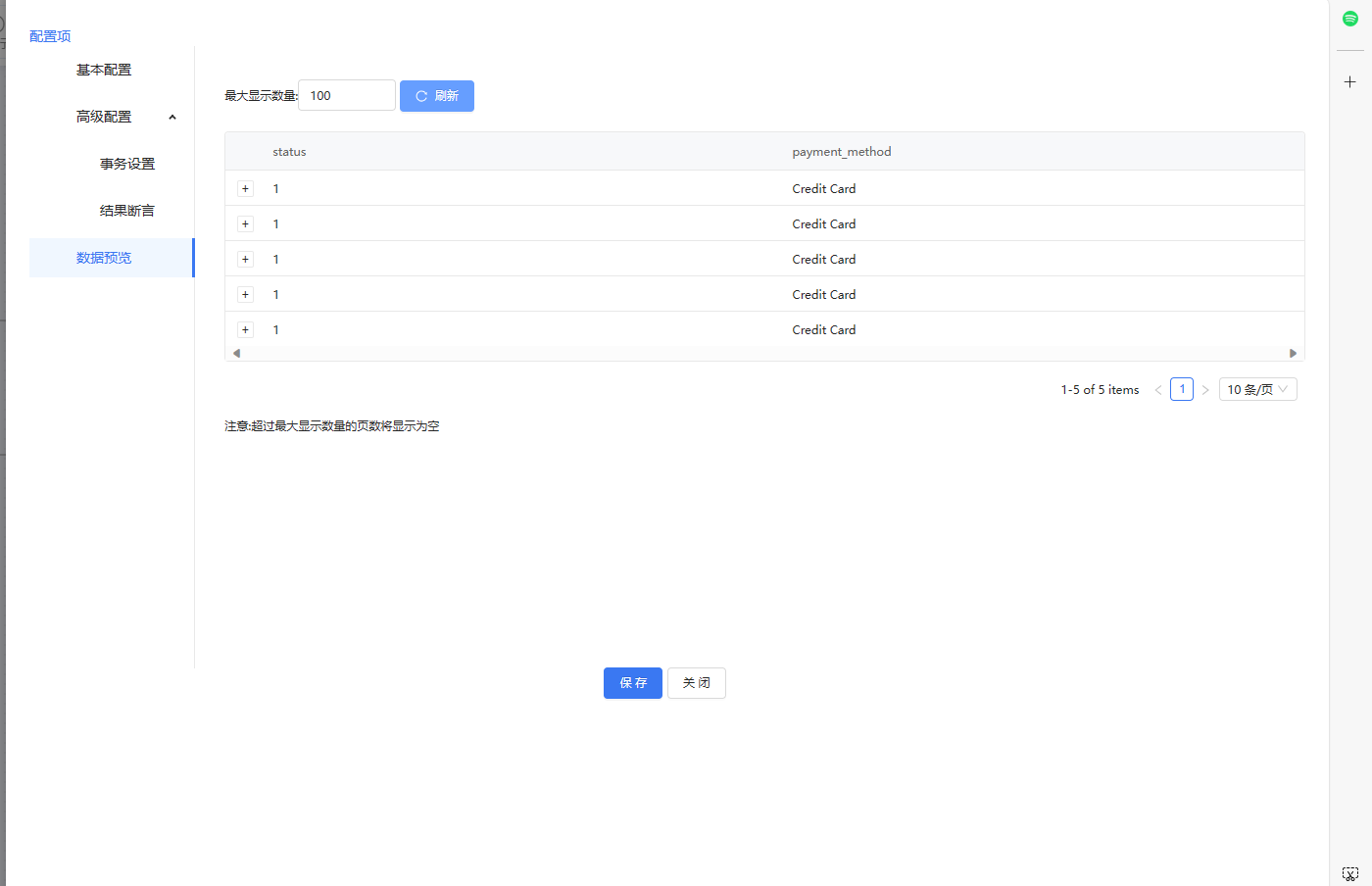
ETL的数据挖掘方式
ETL的基本概念 数据抽取(Extraction):从不同源头系统中获取所需数据的步骤。比如从mysql中拿取数据就是一种简单的抽取动作,从API接口拿取数据也是。 数据转换(Transformation):清洗、整合和转…

【数仓建设系列之一】什么是数据仓库?
一、什么是数据仓库?
数据仓库(Data Warehouse,简称DW)简单来讲,它是一个存储和管理大量结构化和非结构化数据的存储集合,它以主题为向导,通过整合来自不同数据源下的数据(比如各业务数据,日志文件数据等)…
Hive自定义UpperGenericUDF函数
Hive自定义UpperGenericUDF函数 当创建自定义函数时,推荐使用 GenericUDF 类而不是 UDF 类,因为 GenericUDF 提供了更灵活的功能和更好的性能。以下是使用 GenericUDF 类创建自定义函数的步骤: 编写Java函数逻辑:编写继承自 Gener…

企业数据管理新纪元:数据中台VS传统数据仓库的决胜之战-亿发
在数字化时代,数据的管理成为企业成功的关键。传统的数据仓库一度是主导数据管理的工具,但随着技术的演进,数据中台崭露头角,引领着一场革命。让我们深入研究数据中台与传统数据仓库之间的关键区别,揭示革新数据管理的…
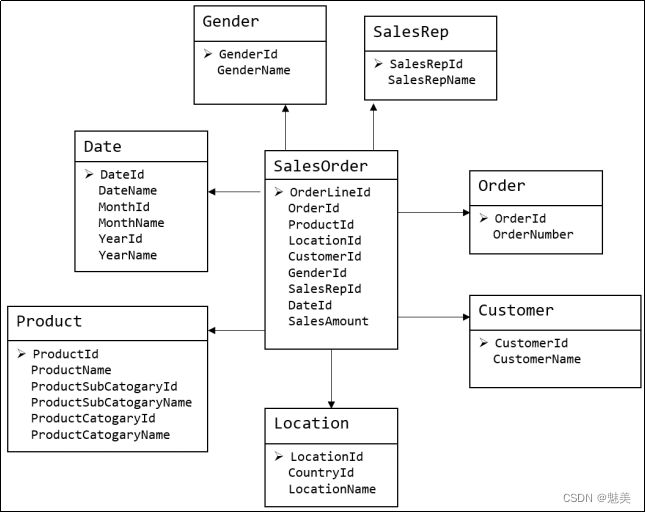

数据治理实践——金融行业大数据治理的方向与实践
目录
一、证券数据治理服务化背景
1.1 金融数据治理发展趋势
1.2 证券行业数据治理建设背景
1.3 证券行业数据治理目标
1.4 证券行业数据治理痛点
二、证券数据治理服务化实践
2.1 国信证券数据治理建设框架
2.2 国信证券数据治理建设思路
2.3 数据模型管理
2.4 数据…
Apache Hive(三)
一、Apache Hive
1、ETL数据清洗
数据问题 问题1:当前数据中,有一些数据的字段为空,不是合法数据
解决:where 过滤 问题2:需求中,需要统计每天、每个小时的消息量,但是数据中没有天和小时字段…
[hive面试真题]-基础理论篇
hive的工作流程 hive中分区表,分桶表 工作中hive分区表的应用示例 发现hive分区中的数据不对怎么处理 hive出现code 1 2 3 什么原因 ,怎么处理 工作中hive常见的文件格式 .压缩格式 工作时常用的hive函数 谈谈对窗口函数的理解 hive中如果出现数据倾斜 ,怎么发现 ,怎么…
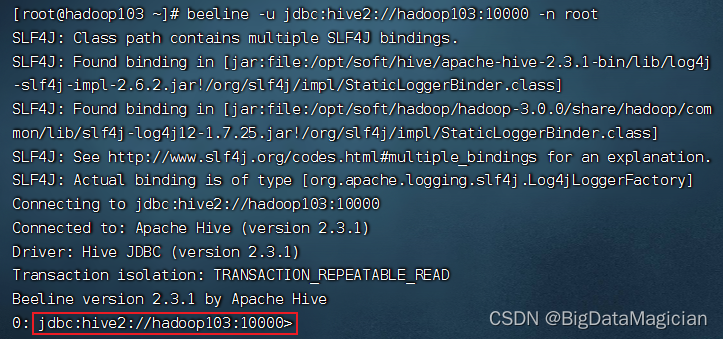
Hive安装教程-Hadoop集成Hive
文章目录 前言一、安装准备1. 安装条件2. 安装jdk3. 安装MySQL4. 安装Hadoop 二、安装Hive1. 下载并解压Hive2. 设置环境变量3. 修改配置文件3. 创建hive数据库4. 下载MySQL驱动5. 初始化hive数据库6. 进入Hive命令行界面7. 设置允许远程访问 总结 前言
本文将介绍安装和配置H…

详解:如何利用BI工具进行生产管理分析?
作为专业数据分析师,相信大家都深谙数据在决策制定和业务优化中的至关重要性。而高效的生产管理分析不仅仅是对企业内部生产过程的监控和预警,更是推动企业优化生产效率、提升产品质量以及促进创新的不可或缺的关键要素。
关注我们的个人读者与企业客户…
hive进行base64 加密解密函数
加密
select base64(cast(abcd as binary))YWJjZA
解密
-- 直接解密(结果字段格式为比binary格式)
select unbase64(YWJjZA)
-- 格式转换
select cast(unbase64(YWJjZA) as string) abcd

什么是ETL?什么是ELT?怎么区分它们使用场景
在大数据处理的领域中,ETL和ELT是两个经常被数据工程师提到的工具,而有很多数据工程师对这两种工具的区别和使用和定位有一定的模糊,其实它们分别代表了两种不同的数据集成方法。尽管这两种方法看起来都是从源系统提取数据,转换数…

数据仓库核心:揭秘事实表与维度表的角色与区别
文章目录 1. 引言2. 基本概念2.1 事实表(Fact Table)2.2 维度表(Dimension Table) 3. 两者关系4. 为什么要有做区分5. 写在最后 1. 引言
前篇我们深入探讨了Hive数据仓库中的表类型,包括内部表、外部表、分区表、桶表…
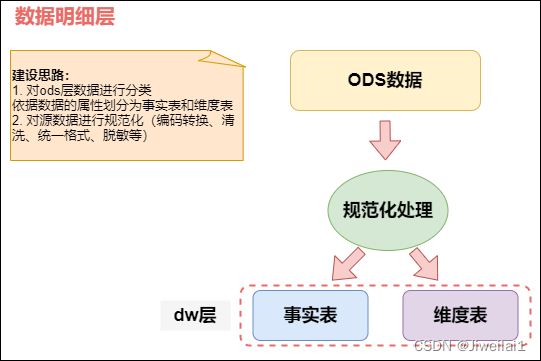
【大数据面试题】 018 数据仓库的分层了解吗?说说你的理解
一步一个脚印,一天一道面试题。
数据仓库是比较常见的考点。今天就介绍一下数据仓库的分层。本篇文章会较多的图片是来自尚硅谷的。
数据仓库的背景和好处
数据仓库的诞生就和大数据的诞生有很大的相似。大数据的诞生是为了处理超大的数据,并在其中探…
Hive实现查询左表有右表没有的记录
工作中遇到这样一个场景,业务逻辑是:如果一个主体发生了某一问题,就不再统计该主体的其他问题。 思路:首先想到的方法就是not in方法,但是Hive并不不支持。那么使用left join对两个表进行连接,右表主键为空…
hive 3.1.3 搭建
部署准备
一台机器,一个mysql数据库 可以访问的 web 页面全部绑定了 127.0.0.1。禁止外部访问,需要访问可以使用 nginx 反向代理 增加鉴权之后暴露出去。如果不需要可以替换 IP 。
安装
Hive 安装包准备
hive 下载页面
配置文件修改
配置文件位于 …
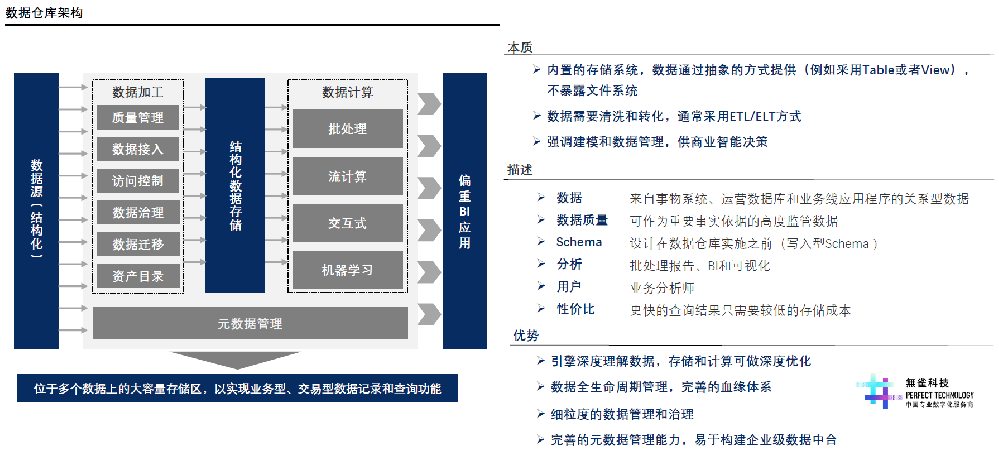
数据仓库的魅力及其在企业中的应用实践
数据仓库,这一创新性的概念来自于比尔恩门,从1980年代末提出以来,便凭借其独特的架构设计和强大的数据处理能力,在全球商业领域中掀起了一场革命。它不仅是解决企业海量数据存储和查询需求的关键技术,更是推动企业实现…
电商API接口淘宝/天猫获得获得淘宝/天猫商品评论API请求接入演示
要获取淘宝/天猫商品评论,你可以使用开放平台提供的API接口。以下是一个示例的API请求接入演示: 注册账号:首先,你需要在开放平台注册一个账号并成为开发者。 创建应用:在开放平台创建一个新的应用,获取Ap…
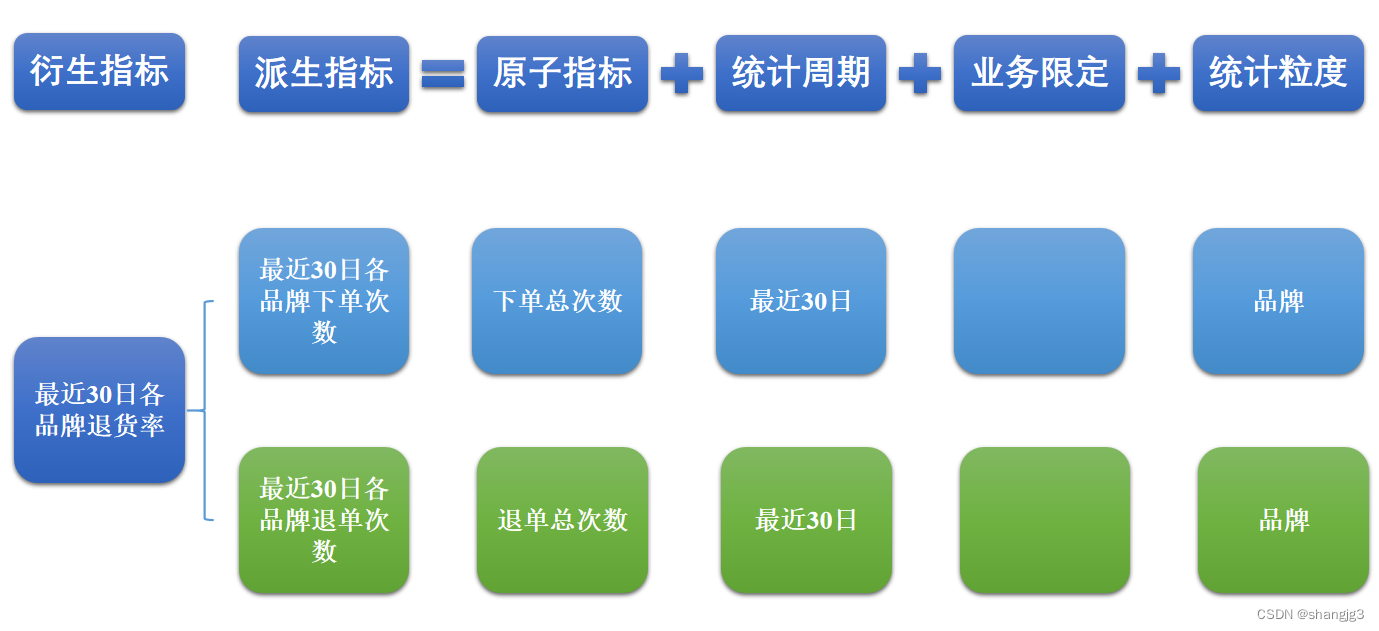
Hive自定义GenericUDTF函数官网示例
Hive自定义GenericUDTF函数官网示例 原文翻译:可以通过扩展 GenericUDTF 抽象类并实现initialize、process以及可能的close方法来创建自定义UDTF。initialize方法由Hive调用,通知UDTF应该期望的参数类型。然后,UDTF必须返回一个对象检查器&am…
Doris实践——叮咚买菜基于OLAP引擎的应用实践
目录
前言
一、业务需求
二、选型与对比
三、架构体系
四、应用实践
4.1 实时数据分析
4.2 B端业务查询取数
4.3 标签系统
4.4 BI看板
4.5 OLAP多维分析
五、优化经验
六、总结 原文大佬介绍的这篇Doris数仓建设实践有借鉴意义的,这些摘抄下来用作沉淀学…

深入解析大数据体系中的ETL工作原理及常见组件
**
引言
关联阅读博客文章:探讨在大数据体系中API的通信机制与工作原理 关联阅读博客文章:深入理解HDFS工作原理:大数据存储和容错性机制解析
**
在当今数字化时代,大数据处理已经成为了企业成功的重要组成部分。而在大数据处…

Hive 之 UDF 运用(包会的)
文章目录 UDF 是什么?reflect静态方法调用实例方法调用 自定义 UDF(GenericUDF)1.创建项目2.创建类继承 UDF3.数据类型判断4.编写业务逻辑5.定义函数描述信息6.打包与上传7.注册 UDF 函数并测试返回复杂的数据类型 UDF 是什么?
H…
全面解析十七种数据分析方法,具象数据分析思维
本文干货信息汇总:FineBI自助式BI数据分析工具下载>>https://s.fanruan.com/vfp40FineBI数据分析模板库>>https://s.fanruan.com/fnbjg 一、介绍 在当今数据驱动的商业环境中,数据分析已经成为了企业获取竞争优势的关键工具。无论是为了优化…
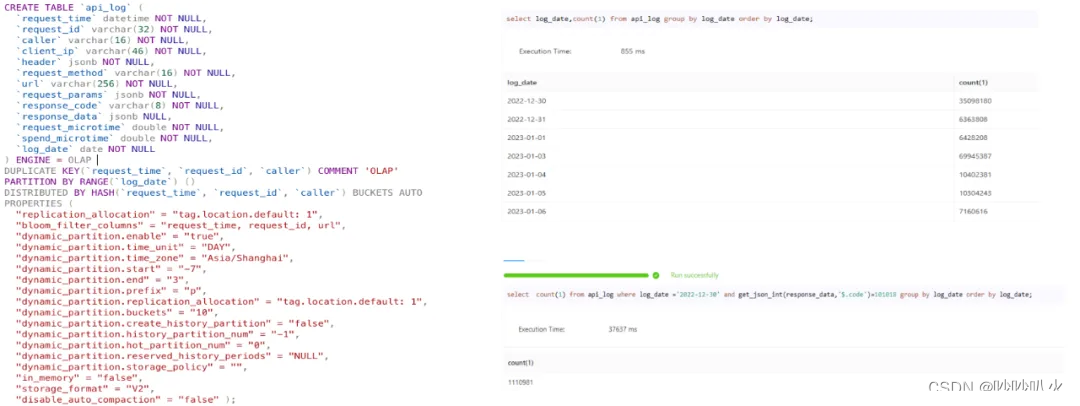
Doris实践——信贷系统日志分析场景的实践应用
目录
前言
一、早期架构演进
1.1 架构1.0 基于Kettle MySQL离线数仓
1.2 架构2.0 基于 Presto / Trino统一查询
二、基于Doris的新一代架构
三、新数仓架构搭建经验
3.1 并发查询加速
3.2 数仓底座建设
四、Doris助力信DolphinScheduler 和 Shell 贷业务场景落地
4.…

HiveSQL如何生成连续日期剖析
HiveSQL如何生成连续日期剖析
情景假设: 有一结果表,表中有start_dt和end_dt两个字段,,想要根据开始和结束时间生成连续日期的多条数据,应该怎么做?直接上结果sql。(为了便于演示和测试这里通过…
AI智能电销机器人获客的方法
随着计算机和AI技术的发展,普通的电话营销已经逐步脱离人工操作的方法,转向电脑智能拨打。很多电销智能机器人已经达到让客户分辨不出真假人工的效果,电销智能机器人的获客价值有哪些?电销智能机器人的获客渠道包括哪些࿱…

开源数据湖iceberg, hudi ,delta lake, paimon对比分析
Iceberg, Hudi, Delta Lake和Paimon都是用于大数据湖(Data Lake)或数据仓库(Data Warehouse)中数据管理和处理的工具或框架,但它们在设计、功能和适用场景上有所不同。 Iceberg: Iceberg是用于大型分析表的高性能格式。Iceberg将SQL表的可靠性和简易性带入到大数据领域,同…
hive窗口函数数据范围
window的内包括:
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN…
【SQL】数据操作语言(DML):学习插入、更新和删除数据
数据查询语言(DQL)用于从数据库中检索数据,主要通过SELECT语句来实现。SELECT语句允许用户指定要检索的数据列、表以及任何筛选条件。以下是对DQL的详细介绍以及多个示例:
SELECT语句基础结构:
sql
SELECT column1,…
最全手写SQL面试题及代码实现(万字长文持续更新)
在当今数据驱动的时代,掌握SQL(Structured Query Language)对于任何希望在大数据领域发展的专业人士来说都是至关重要的。SQL不仅是一种查询语言,更是一种强大的工具,能够帮助我们从海量数据中提取有价值的信息。因此,编写优质的SQL面试题及参考答案,不仅可以帮助读者巩…
汽车4S行业的信息化特点与BI建设挑战
汽车行业也是一个非常大的行业,上下游非常广,像主机厂,上游的零配件,下游的汽车流通,汽车流通之后的汽车后市场,整个链条比较长。今天主要讲的是汽车流通,汽车4S集团。一个汽车4S集团下面授权代…
数据仓库与数据挖掘(第三版)陈文伟思维导图1-5章作业
第一章 概述 8.基于数据仓库的决策支持系统与传统决策支持系统有哪些区别? 决策支持系统经历了4个阶段。 1.基本决策支持系统 是在运筹学单模型辅助决策的基础上发展起来的,以模型库系统为核心,以多模型和数据库的组合形成方案辅助决策。 它…

数据仓库发展历史与架构演进
从1990年代Bill Inmon提出数据仓库概念后经过四十多的发展,经历了早期的PC时代、互联网时代、移动互联网时代再到当前的云计算时代,但是数据仓库的构建目标基本没有变化,都是为了支持企业或者用户的决策分析,包括运营报表、企业营…
Apache Doris 2.0.6 版本正式发布
亲爱的社区小伙伴们,Apache Doris 2.0.6 版本已于 2024 年 3 月 12 日正式与大家见面,该版本在物化视图、统计信息收集、JDBC Catalog 等方面进行了更新优化,并提交了 114 个改进项以及问题修复,欢迎大家下载体验。
官网下载&…
可视化设计:一文读懂桑基图,从来处来,到去出去。
一、什么是桑基图
桑基图(Sankey diagram)是一种图表类型,用于可视化流量、能量、资源或数量的流动。它通过使用有向箭头连接不同的节点来显示流动的路径和量级。
桑基图常用于可持续能源、物流、人口流动、资源分配等领域的数据可视化。它…
Hive函数 date_format 使用示例总结
Hive函数 date_format 使用示例总结
Hive函数 date_format 用于将日期或时间戳格式化为指定的输出格式。假设要对时间 2024-03-18 18:18:18.008 进行格式化,以下是一些常见的时间提取格式,这些格式可以在 date_format 函数中使用:
1. yyyy …
Hive常用函数_20个字符串处理
Hive常用函数_20个字符串处理 以下是Hive中常用的字符串处理函数,可用于执行各种字符串处理转换操作。 1. CONCAT():将多个字符串连接在一起。
SELECT CONCAT(Hello, World);
-- Output: HelloWorld2. SUBSTR():从字符串中提取子字符串&…
Hive常用函数_16个时间日期处理
在Hive中,常用的时间处理函数包括但不限于以下几种:
1. current_date(): 返回当前日期,不包含时间部分
SELECT current_date();
-- Output: 2024-09-152. current_timestamp(): 返回当前时间戳,包含日期和时间部分
SELECT curr…
Day1 - Hive基础知识
Hive
简介
概述
Hive是由Facobook开发的后来贡献给了Apache的一套用于进行数据仓库管理的工具,使用类SQL语言来对分布式文件系统中的PB级别的数据来进行读写、管理以及分析Hive基于Hadoop来使用的,底层的默认计算引擎使用的是MapReduce。Hive利用类SQ…
数据治理-平台详细措施
这里讲平台治理的具体措施,并不是从具体架构来说,而是从详细方法。
名词定义 1.待治理成本 2.浪费量:可以优化计算或者存储 3.累计浪费量:发现时距离今天数*当日浪费量 4.节省成本:完成治理成本 5.白名单管理成本 治理…

ETL工具-nifi干货系列 第六讲 处理器JoltTransformJSON
1、处理器作用
使用Jolt转换JSON数据为其他结构的JSON,成功的路由到success,失败的failure。处理JSON的实用程序不是基于流的,因此大型JSON文档转换可能会消耗大量内存。
Jolt:JSON 到 JSON 转换库,用 Java 编写,其中转换的 &qu…
数据仓库数据质量监控
每日同步的表数据进行表行数非0校验:通过编写脚本或者工具,定期检查每个表的行数是否大于0,以确保数据同步的完整性。业务主键唯一性校验:对每个表的业务主键字段进行唯一性校验,避免重复数据的插入。下面的代码就是对生产环境和测试环境,对主键id验证是否有重复值。 im…
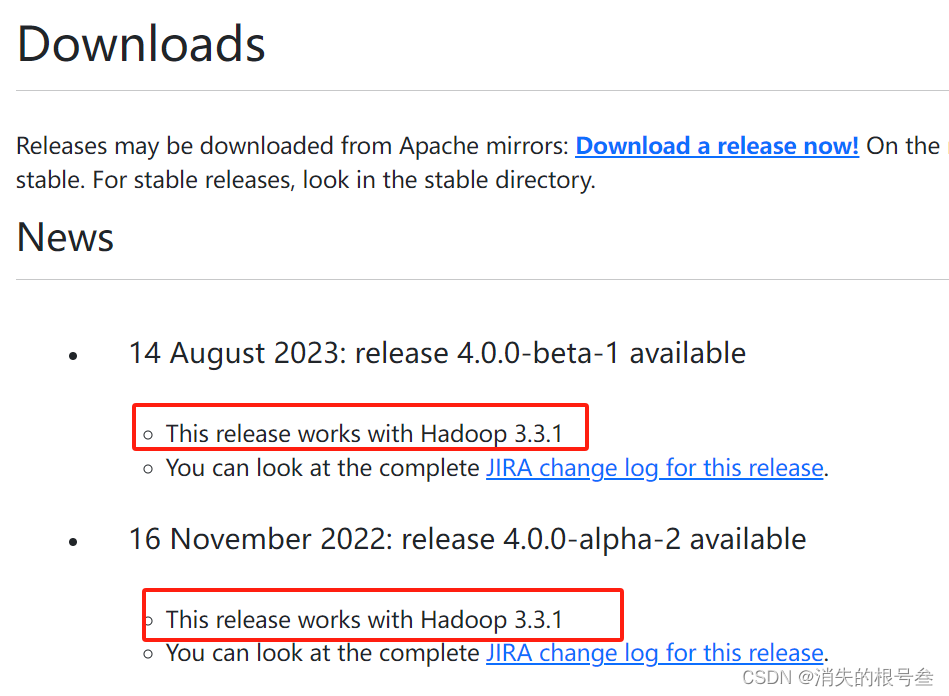
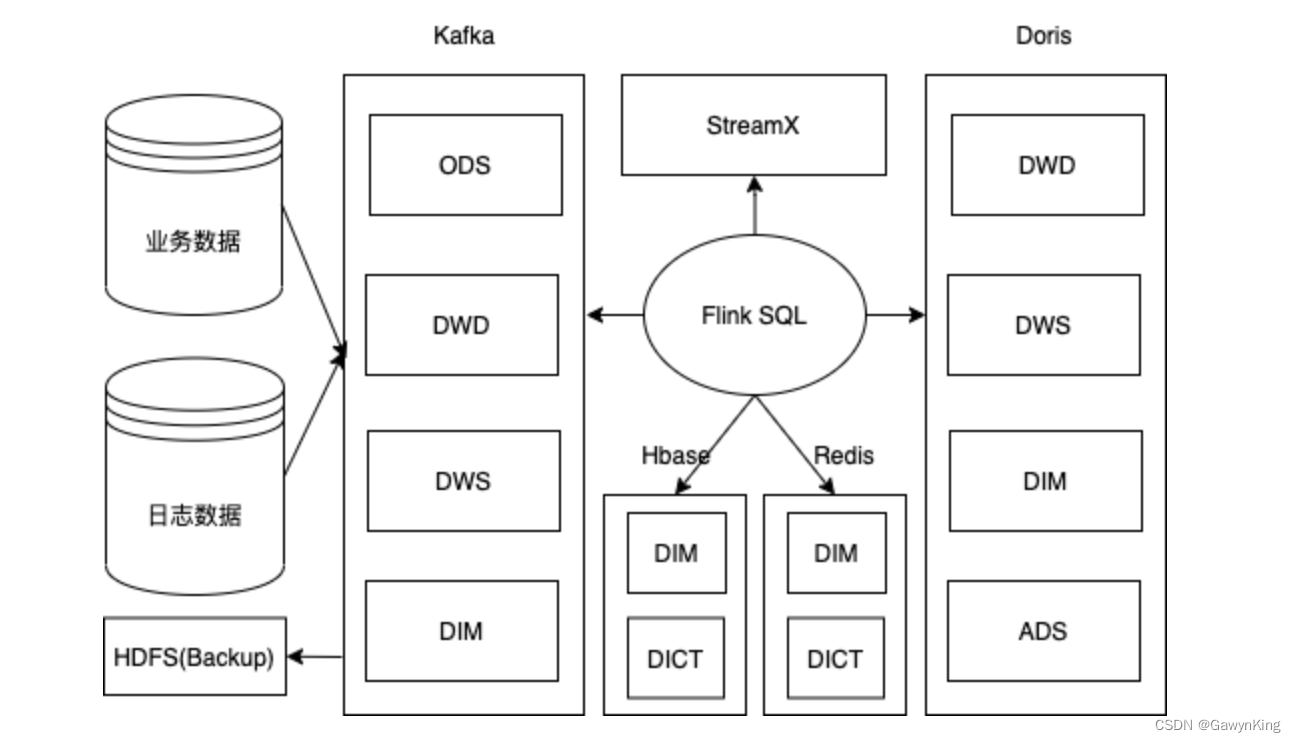
实时数仓之实时数仓架构(Doris)
目前比较流行的实时数仓架构有两类,其中一类是以Flink+Doris为核心的实时数仓架构方案;另一类是以湖仓一体架构为核心的实时数仓架构方案。本文针对Flink+Doris架构进行介绍,这套架构的特点是组件涉及相对较少,架构简单,实时性更高,且易于Lambda架构实现,Doris本身可以支…
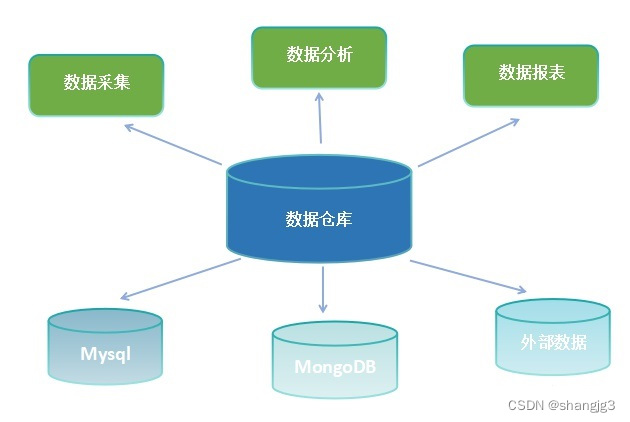
数据仓库的数据处理架构Lambda和Kappa
1.数据仓库 数据仓库(Data Warehouse),简写DW。顾名思义,数据仓库是一个很大的数据存储集合,为企业分析性报告和决策支持而创建,是对多元业务数据的筛选与整合,具备一定的BI能力,主要用于企业的数据分析、数据挖掘、数据报表等方向,指导业务流程改进、监视时间、成本、…
Hive常用函数 之 数值处理
Hive常用函数 之 数值处理 以下是Hive中常用的数值处理函数,可用于执行各种数学运算和数值转换操作。 1. ABS():返回一个数的绝对值。
SELECT ABS(-10);
-- 输出: 102. ROUND():对一个数进行四舍五入。
SELECT ROUND(10.56);
-- 输出: 113.…
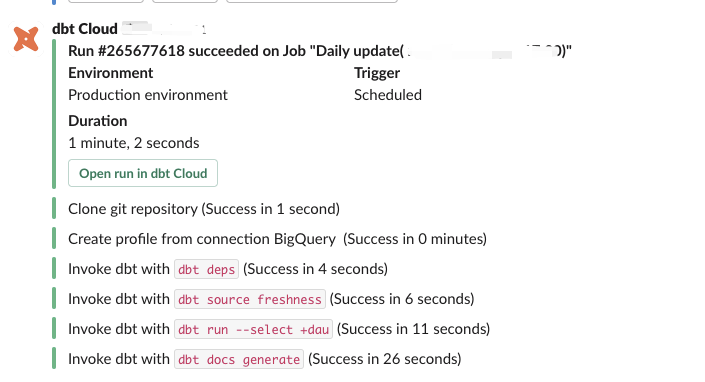
从零开始的 dbt 入门教程 (dbt cloud 自动化篇)
一、引
在前面的几篇文章中,我们从 dbt core 聊到了 dbt 项目工程化,我相信前几篇文章足够各位数据开发师从零快速入门 dbt 开发,那么到现在我们更迫切需要解决的是如何让数据更新做到定时化,毕竟作为开发我们肯定没有经历每天定…
用DataGrip连接hive时报错:User: root is not allowed to impersonate plck5,解决方法
你可以尝试关闭主机校验 修改hive安装目录下conf/hive-site.xml,将hive.server2.enable.doAs设置成false
<property><name>hive.server2.enable.doAs</name><value>false</value><description>Setting this property to true will have H…
开源 OLAP 及其在不同场景下的需求
目录
一、开源 OLAP 综述
二、OLAP场景思考
2.1 面向客户的报表
2.2 面向经营的报表
2.3 末端运营分析
2.4 用户画像
2.5 订单分析
2.6 OLAP技术需求思考
三、开源数据湖/流式数仓解决方案
3.1 离线数仓体系——Lambda架构
3.2 实时数据湖解决方案
3.3 实时分析解决…
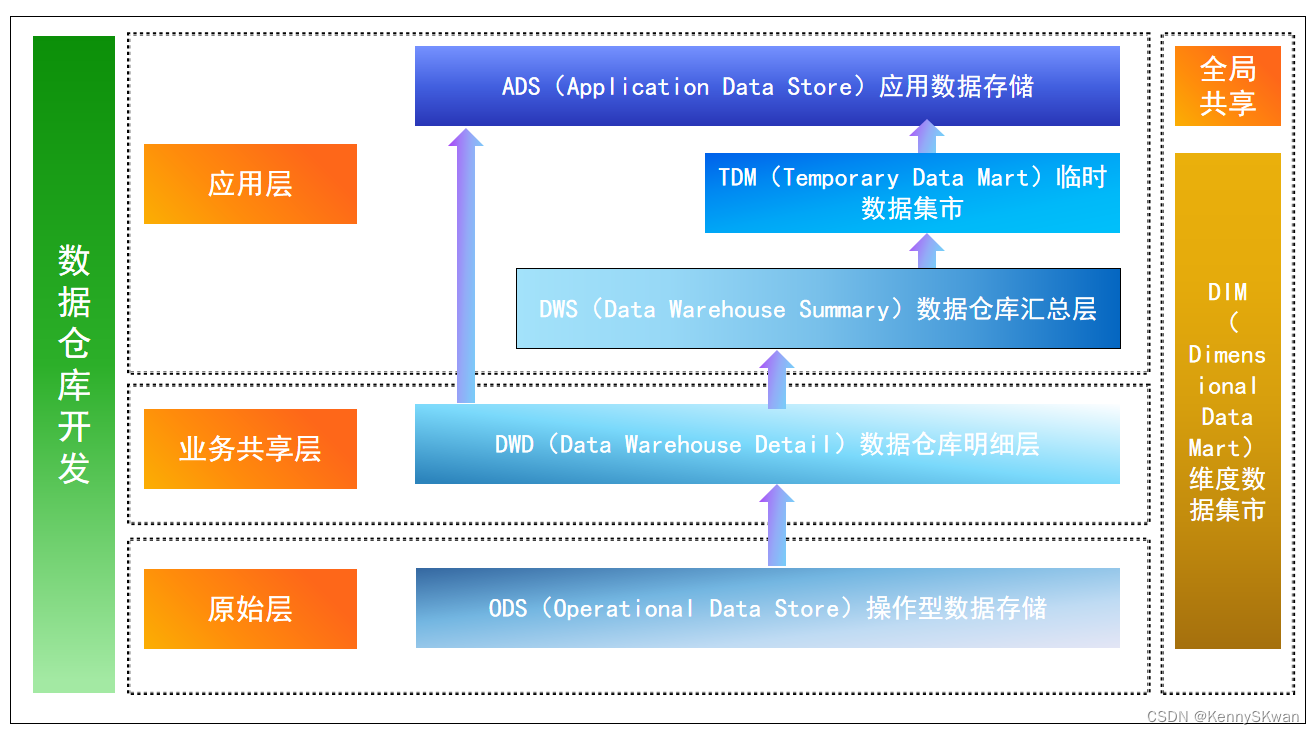
大数据设计为何要分层,行业常规设计会有几层数据
大数据设计通常采用分层结构的原因是为了提高数据管理的效率、降低系统复杂度、增强数据质量和可维护性。这种分层结构能够将数据按照不同的处理和应用需求进行分类和管理,从而更好地满足不同层次的数据处理和分析需求。行业常规设计中,数据通常按照以下…
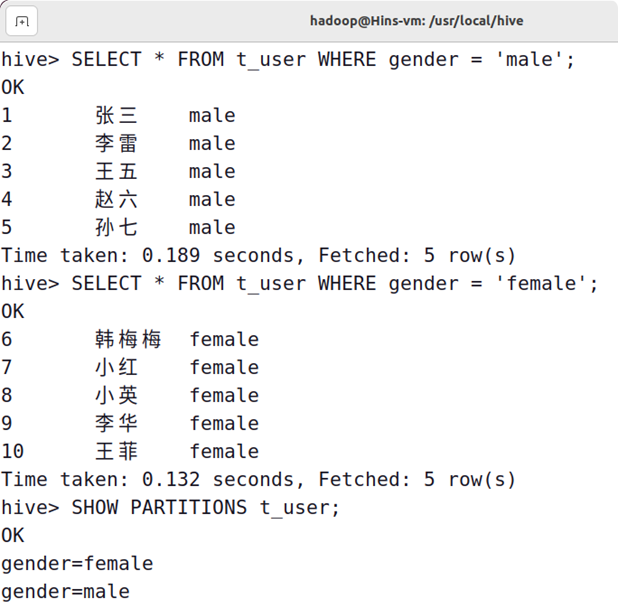
【Hadoop大数据技术】——Hive数据仓库(学习笔记)
📖 前言: Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但…

Tapdata Connector 实用指南:数据入仓场景之数据实时同步到 BigQuery
【前言】作为中国的 “Fivetran/Airbyte”, Tapdata 是一个以低延迟数据移动为核心优势构建的现代数据平台,内置 60 数据连接器,拥有稳定的实时采集和传输能力、秒级响应的数据实时计算能力、稳定易用的数据实时服务能力,以及低代码可视化操作…
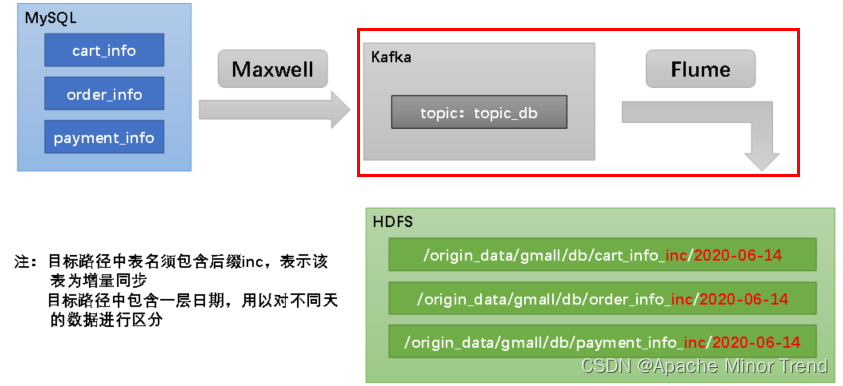
【离线数仓-2-数据采集】
离线数仓-2-数据采集离线数仓-2-数据采集1.用户行为日志数据模拟1.用户行为日志的介绍2.埋点有哪些3.用户行为日志内容4.用户行为日志格式5.用户行为日志数据采集1.节点之间配置免密登录2.linux环境变量说明3.用户行为日志模拟脚本4.Hadoop的搭建5.Hadoop在项目中的优化6.Zooke…
数据仓库工作问题总结
1. ODS 层采用什么压缩方式和存储格式?
压缩采用 Snappy ,存储采用 orc ,压缩比是 100g 数据压缩完 10g 左右。
2. DWD 层做了哪些事?
1.、数据清洗
空值去除过滤核心字段无意义的数据,比如订单表中订单 id 为 nul…
运营-15.涉及促销活动的计算原则
1.是否 参与促销活动 如果商品参加促销活动,则在订单结算的时候显示已经参加的活动,否 则不显示; 2.是否 满足促销条件 如果有参加某个活动,则还要判断是否满足活动的条件,比如满200减 10,但是商品价格不足…

代码思路分享 计算机毕业设计Python+Hadoop+Spark+Hive音乐可视化 音乐数据分析 音乐大数据 音乐推荐系统 音乐数据仓库 大数据毕业设计 大数据毕设
涉及技术
hadoop
hive
azkaban
python爬虫
hue
sqoop
mysql
运行截图

数据仓库项目分享思路 计算机毕业设计Python+Hadoop+Spark+Hive招聘可视化 招聘数据分析 数据仓库 招聘推荐系统 招聘大数据 大数据毕业设计 大数据毕设
涉及技术
hadoop
hive
azkaban
python爬虫
hue
sqoop
mysql
运行截图
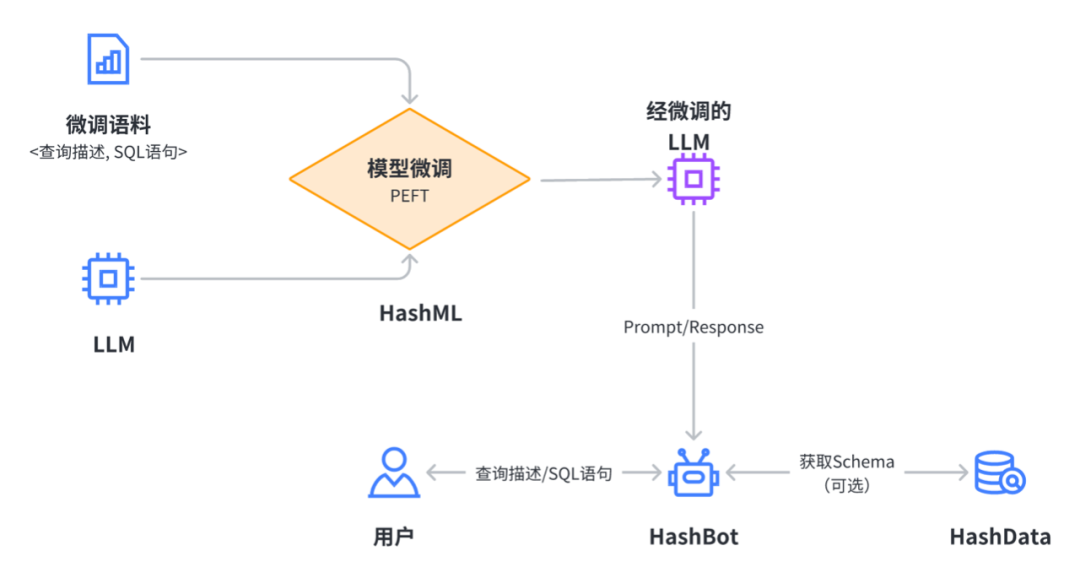
当大模型遇到数据仓库 HashData助力LLM规模化应用
6月30日,由 IT168主办的第十六届中国系统架构师大会(SACC2023)在北京开幕。本届大会以“数字转型 架构演进”为主题,议题涵盖AIGC大数据、多云多活、云成本等多个热门领域。
在会上,酷克数据首席科学家杨胜文发表了题…
Hive on Spark (1)
spark中executor和driver分别有什么作用?
Spark中Executor
在 Apache Spark 中,Executor 是分布式计算框架中的一个关键组件,用于在集群中执行具体的计算任务。每个 Executor 都在独立的 JVM 进程中运行,可以在集群的多台机器上…
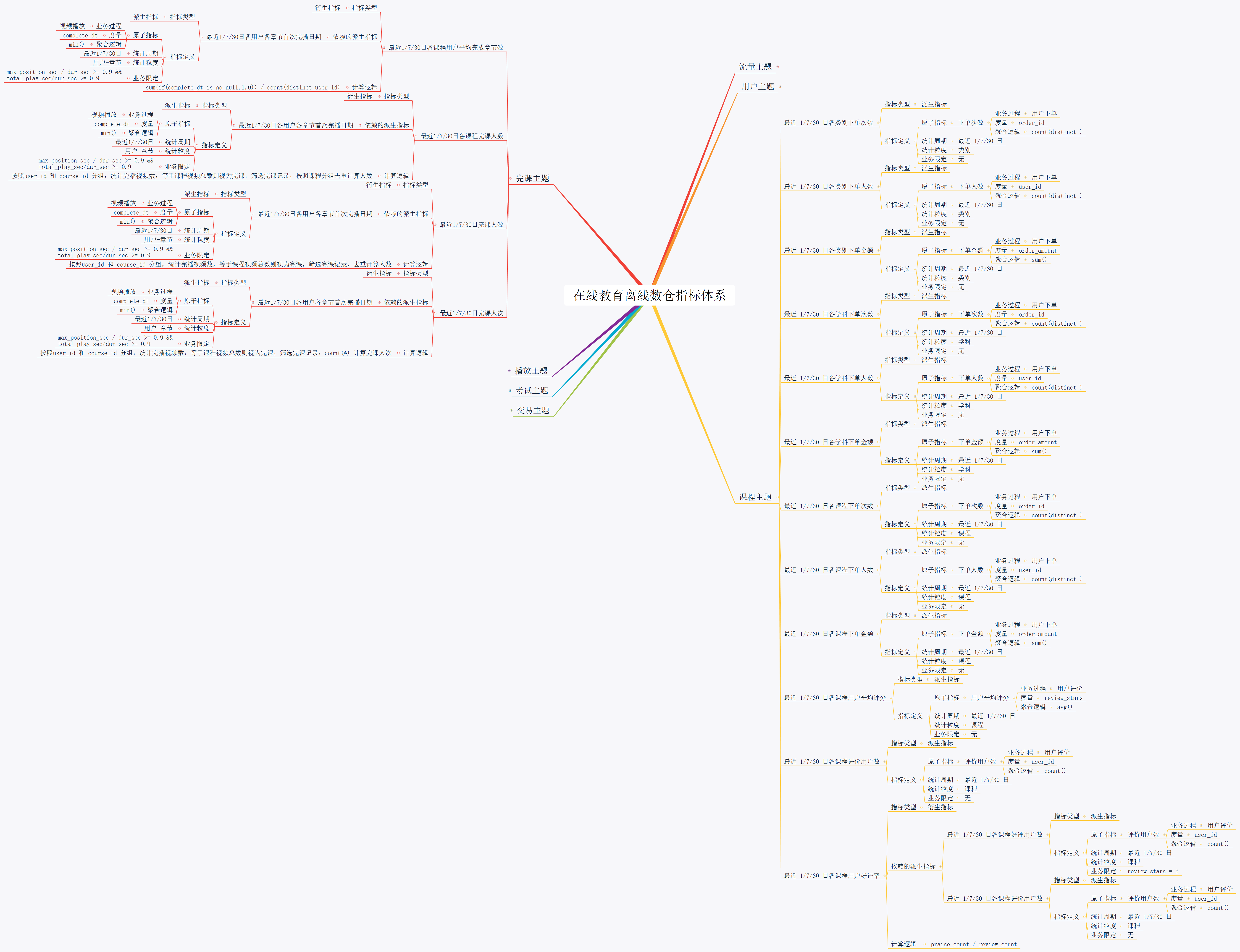
尚硅谷大数据项目《在线教育之离线数仓》笔记001
视频地址:尚硅谷大数据项目《在线教育之离线数仓》_哔哩哔哩_bilibili 目录
P003
P004【数仓概念讲的颇为详细】
P018
P019
P020
P021
P022
P023
P024 P003 时间切片:时间回溯,找回以前的数据。 P004【数仓概念讲的颇为详细】 核心架…

异地容灾系统和数据仓库系统设计和体系结构
( 1)生产系统数据同步到异地容灾系统 生产系统与异地容灾系统之间是通过百兆网连接的;生产系统的数据库是 Oracle 9i RAC,总的数据量大约为 3 TB,涉及五千多张表。对这些表进行分析归 类,发现容灾系统真正…
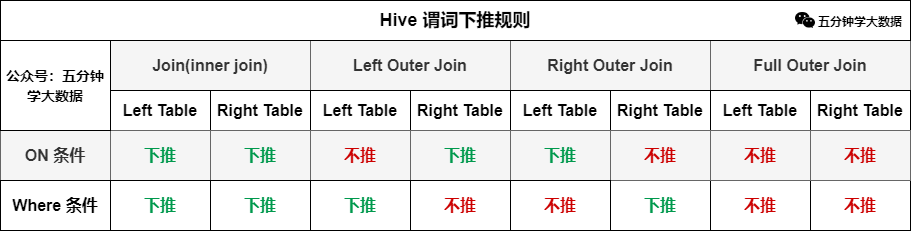
Hive参数与性能调优-V2.0
Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一。
但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数仓,所以Hive性能调优是我们大数据从业…

DAMA-DMBOK2重点知识整理CDGA/CDGP——第17章 数据管理和组织变革管理
目录
一、分值分布
二、重点知识梳理
1、引言
2、变革法则
3、并非管理变革:而是管理转型过程
4、科特的变革管理八大误区
5、科特的重大变革八步法
6、变革的秘诀
7、创新扩散和持续变革
8、持续变革
9、数据管理价值的沟通 一、分值分布 CDGAÿ…
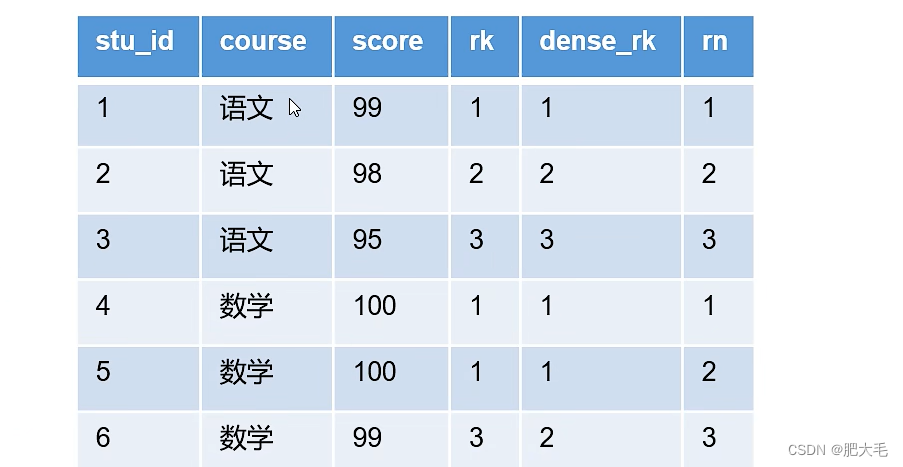
Hive窗口函数回顾
1.语法 1.1 基于行的窗口函数
Hive的窗口函数分为两种类型,一种是基于行的窗口函数,即将某个字段的多行限定为一个范围,对范围内的字段值进行计算,最后将形成的字段拼接在该表上。 注意:在进行窗口函数计算之前&#…
淘宝天猫1688以图搜图接口,按图搜索商品,API接口调用展示(拍立淘API)
淘宝拍立淘图片搜索接口技术主要基于图像识别和内容匹配。图像识别是利用计算机视觉技术,对上传的图片进行特征提取和识别,从而找到与该图片相似的商品。内容匹配则是通过文本与图片内容的关联性,对商品标题、描述等信息进行匹配,…
【Java 进阶篇】Java Listener 使用详解
在 Java Web 应用程序中,监听器(Listener)是一种强大的机制,用于在 Web 容器中监听和响应各种事件。通过监听器,我们可以在应用程序生命周期中执行特定的任务,如在应用启动时初始化资源,在会话创…
![[Kettle] 获取系统信息](https://img-blog.csdnimg.cn/aa0aa17db82e4de2a9ab4ea24e724b77.png)
[Kettle] 获取系统信息
系统信息是指Kettle系统环境的信息,包括了计算机系统的日期、星期等时间类型信息,计算机名称、IP地址等设备信息,Kettle系统转换过程中的信息等
需求:为方便读取计算机上的本月最后一天的交易数据文件,需要通过获取系…
hive 命令记录(随时更新)
1.进入 hive 数据库: hive 2.查看hive中的所有数据库: show databases; 3.用 default 数据库 use default; 4.查看所有的表 show tables; 5.查询 book 表结构: desc book ; 6.查询 book 表数据 select * from book; 7.创建 shop 数据库 creat…
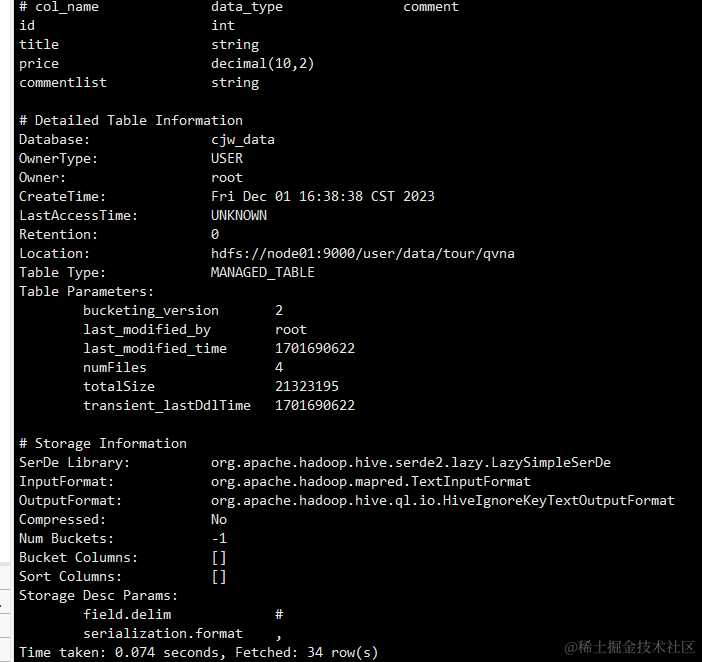
解决 Hive 外部表分隔符问题的实用指南
简介:
在使用 Hive 外部表时,分隔符设置不当可能导致数据导入和查询过程中的问题。本文将详细介绍如何解决在 Hive 外部表中正确设置分隔符的步骤。
问题描述:
在使用Hive外部表时,可能会遇到分隔符问题。这主要是因为Hive在读…
Hive数学函数讲解
Hive 是一个基于 Hadoop 的数据仓库工具,它支持类似于 SQL 的查询语言 HiveQL,并且提供了许多内建的数学函数来处理数值数据。下面我将逐一讲解您提到的这些数学函数,并提供一些使用案例和注意事项。 ROUND() 功能:四舍五入到指定…
Doris实战——银联商务实时数仓构建
目录
前言
一、应用场景
二、OLAP选型
三、实时数仓构建
四、实时数仓体系的建设与实践
4.1 数仓分层的合理规划
4.2 分桶分区策略的合理设置
4.3 多源数据迁移方案
4.4 全量与增量数据的同步
4.5 离线数据加工任务迁移
五、金融级数仓稳定性最佳实践
5.1 多租户资…

外贸企业财务难点分析:解决之道一览
在国际宏观环境越来越复杂,市场竞争越来越激烈的情况下,外贸公司面临的挑战也越来越大,外贸企业的资金管理也因此有着很大压力。与其他公司的财务记账工作对比,外贸企业的财务记账工作有着独特的考验。 在这种情况下,外…
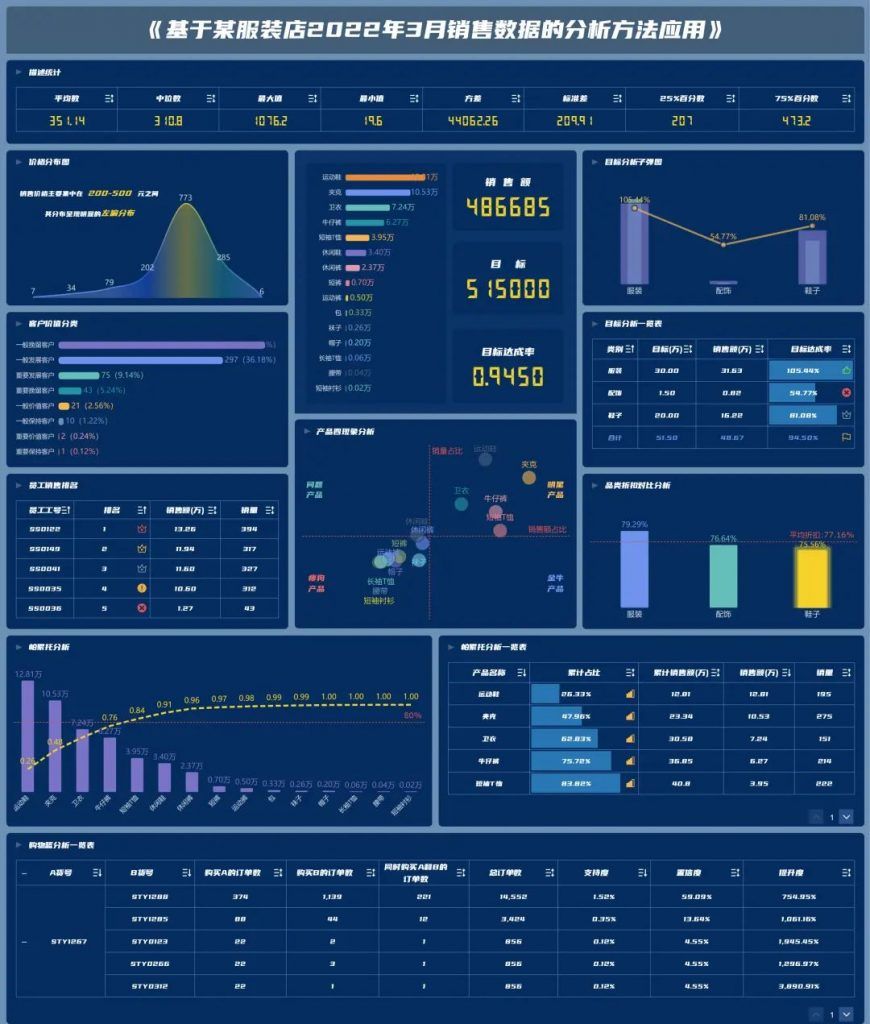
销售数据分析怎么做?用好这5个数据分析方法与模型就足够了。
企业经营其实简单来说就是做买卖,有了买卖自然就产生了销售数据,那怎么能让这些销售数据产生价值呢?答案就是数据分析。通过对销售数据的分析,可以帮助企业及时洞察市场动向,发现企业销售过程中的问题,调整…
(一)、Doris安装使用(基于Doris 2.0.6)
第 1 章Doris简介
1.1、 Doris 概述
Apache Doris由百度大数据部研发(之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris),在百度内部,有超过200个产品线在使用,部署机器超过1000台…
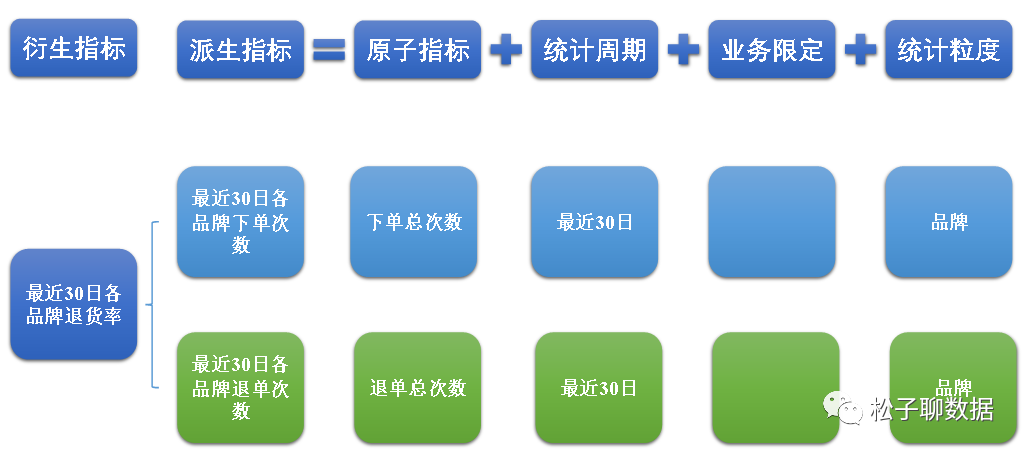
数据仓库模型设计V2.0
一、数仓建模的意义
数据模型就是数据组织和存储方法,它强调从业务、数据存取和使用角度合理存储数据。只有将数据有序的组织和存储起来之后,数据才能得到高性能、低成本、高效率、高质量的使用。 高性能:良好的数据模型能够帮助我们快速查询…
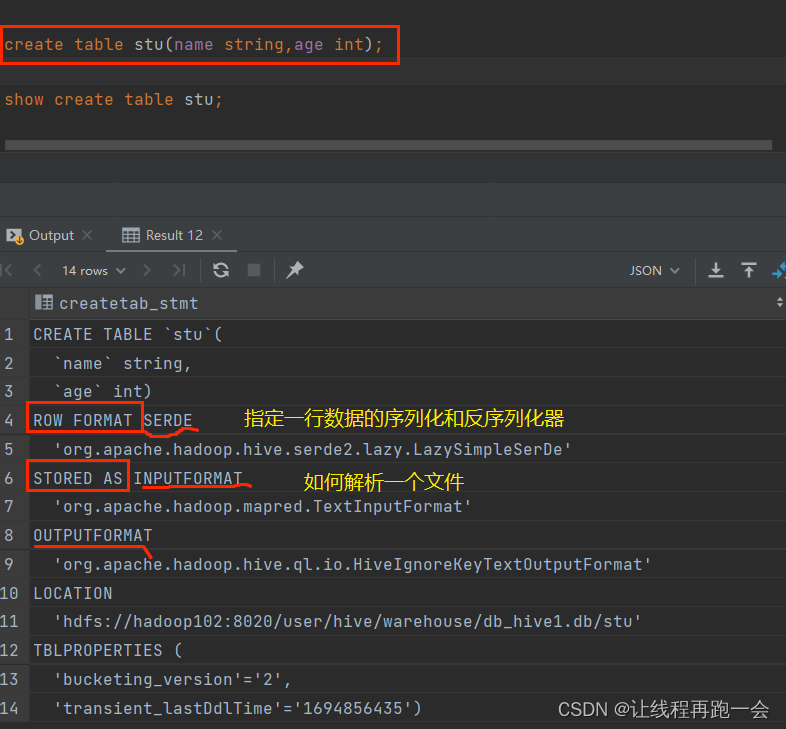
Hive【Hive(一)DDL】
前置准备 需要启动 Hadoop 集群,因为我们 Hive 是在 Hadoop 集群之上运行的。 从DataGrip 或者其他外部终端连接 Hive 需要先打开 Hive 的 metastore 进程和 hiveserver2 进程。
Hive DDL 数据定义语言
1、数据库(database)
创建数据库
c…